������ϵ�������ݸ���������д,��������䷭��,Ԥ֪����,���������ԭ�ġ�
���ı���:InfoSurgeon: Cross-Media Fine-grained Information Consistency Checking for Fake News Detection;
����:Yi R. Fung1, Chris Thomas2, Revanth Reddy1, Sandeep Polisetty3, Heng Ji1, Shih-Fu Chang2, Kathleen McKeown2, Mohit Bansal4, Avirup Sil5;
- 1 University of Illinois at Urbana-Champaign
- 2 Columbia University
- 3 UMass Amherst,
- 4 University of North Carolina at Chapel Hill,
- 5 IBM
�����ص�:ACL 2021;
������������:https://aclanthology.org/2021.acl-long.133.pdf
��������:https://github.com/yrf1/InfoSurgeon
ժҪ:
Ϊ�˶Կ����������ɵ��������(fake news),����һ����Ч�Ļ��ơ�
���Ĺ�����һ���µ�֪ʶԪ�ؼ��Ļ����ݼ�(benchmark at the knowledge element level),ͬʱ�����һ��֪ʶԪ��(knowledge element, KE)�����������ż�ⷽ��,ͨ������ģ̬��Ϣ��һ����ʵ�ֶԵ�����ٵ�ϸ����֪ʶԪ�صļ�⡣
����KE����������ż�ⷽ���ѵ������ȱ��,�����ƶ���һ���µ����ݺϳɷ���,ͨ����֪ʶͼ���е�֪ʶԪ���������ض��ġ����Լ��ġ�������֪��һ���Ե�,����ѵ�����ݡ�
���ĵ������Ϣ��ⷽ����������SOTA(ȷ����೬��16.8%),�Ҷ��������Ϣ�ļ���ṩ��ϸ���ȵĿɽ����ԡ�
���Ķ��������з���������:
- ����fake news detection�������ʹ��word emb����semantic emb��������document-level�ļ��ģ�͡�����,�������fake newsͨ���Ƕ���ʵ����real news������С���ȵ��ĵõ���,������,α�����йؼ���֪ʶԪ��;����fn������û��֤ʵ(ʵʱ��);����fn��Ҫ����ģ̬�IJ�����Ϣ������֤�������(��һ����)����Щ�����,ϸ���ȵ�fakeʹ��document-level��ģ�;Ϳ��ܼ�ⲻ�����ˡ�
- ͨ���ھ��ģ̬news��������һ����(����ͼ�����ݺ��ı��������),�����������ʵ�IJ�һ����,�����news�����mis KEs�����ַ�ʽ�����ж�fake�и��õĿɽ����ԡ�
- KE����fake newsһ����������ȱ��ѵ������,��˱��������һ�ַ���,��real news����Ϊͼ,Ȼ���滻���߲���ڵ���߱�,�õ���ٵ�ͼ,�ٽ�ͼת��Ϊtext,��ʵ����Ч��KE-level��training fake news�����ɡ�
������Ҫ����:
- ͨ����news��ʾΪһ����ģ̬֪ʶͼ��(knowledge graph, KG)�ķ�ʽ,�������mis��Ԫ��pieces,�Դ���ǿ�ɽ�����;
- ����ģ��ͬʱ����fake news��source context,�����ʾ,��ģ̬��Ϣ,�ͱ���֪ʶ,ʵ��fake news�ļ��;
- ������һ��benchmark���ݼ�,KE level��;
����ģ�ͼ�����:

1. ���ⶨ��:
����һ����ý������X,����ͼ�������ʾ,������ż�������Ŀ�ľ����жϸ����ŵ�����ԡ����������ݰ�������3������:
- ���ŵ���������:body text bt;
- ����ͼ�� im_1,..., im_i,�����Ӧ�����ɱ��� c_1, ..., c_i;
- ���ŵ�Ԫ����metadata,m������������domain,����ʱ��date,����author,����headline;
���ĵ�������ż��Ŀ����������level�ϼ�����ŵ������:
- document-level:���ÿһ����ý������,������������������;
- knowledge element-level:���һ��������,��������ٵ��ض���֪ʶԪ��(���Ľ�Ҫ����KE����Ϊ��Ϣ�����е�ʵ��entities,��ϵrelations,�¼�events,�Լ���ͼsubgraphs����Ԫ·��metapaths,��ЩԪ��);
2. ģ������ṹ:
����ͼ�м䲿����ʾ,���Ľ�ÿһ����ý�����Ź���Ϊһ����ý��֪ʶͼ(multimedia knowledge graph)KG=(N, E),����N�ǽڵ�,��ʵ�� t ����;E�DZ�,������ϵ r,�¼�Ԫ�ؽ�ɫ a��

?��ô��������level��������ż��ʵ��ת��Ϊ:
- document-level:���һ����ý��֪ʶͼ����������,ʹ��ȷ����Ϊ����ָ��;
- KE-level:���֪ʶͼ�б�edge�������(��Ϊʵ�屾����û�������֮˵��,����ʵ�ʷ�ӳ��ٵ�ֻ��graph�еı߹�ϵ),ʹ��F-score��Ϊ����ָ��;
3. ģ��������ʼ��:
����ͼ�м���ʾ,����ģ��ͬʱ��global context��local KG��ȡ����:
3.1. global context��news��������ԭʼ����:body text,image,cpations,metadata(�Ƿ�ֻ�нڵ�,�γɱ���?)��
�ò��ֵ�������ʼ������:
- body test��captionʹ�ñ����BERT,��encoded token��һ��ѧϰ���Ӽ���ʾ;
- ��Ԫ����metadata,����������text encoder�õ�������ʾ;
- ��ͼ��,ƴ����object��������event������;
- ����������ȡ��nodes���edge,ʹ��node features�����attention�����������Թ���;
3.2. local KG��ͨ����news����ȡ��nodes��KG��ʵ��nodes����,��������graph��
ÿ��news����һ��KG,����IEϵͳ��news����ȡʵ���ϵ��,Ȼ�����entity? linking����ȡ�Ķ���map������֪ʶͼ����(û������ʵ����þ���ȥmap)��
��KG�����нڵ�ͱߵij�ʼ�����������������������:
- background embeddings:����KG�е�ʵ��ڵ�N_t,ͨ��Freebase���ݿ��ҵ�����wikipediaҳ��,Ȼ��ҳ���һ�ε��ı��������LSTM�������ʾģ��,�õ�N_t��������ʾ;���ڱ�edge����,�ǽ������ӵ������ڵ��wikipedia����һ������LSTM��ģ��,�õ�edge��������ʾ;����û��wikipediaҳ���Ӧ�Ľڵ�ͱ�,�ò���������Ϊ0;
- news embeddings:News-based node features are initialized from passing an LSTM through the word embeddings of the canonical entity mention extracted(�ⲿ����û�п�����,���Dz����²��������news�ж��ڸ�ʵ��ڵ���߹�ϵ�ߵ����text����LSTM������������ǵ�news embeddings);
- source attribution:����һ��4ά�Ķ���������,�������������������ŵ���һ��������,body text,image, caption,����metadata;
4. �������ݺ�����ѧϰ:
������Ϊ�������KG��non-fake��triplets(���������ڵ��һ����)��Ƚ���fake��triplets����,���ı���node��ϵ���������Ҫѧϰ�ڵ�֮�����ӵ�credibility����ӳ����ԡ�
- �������,���global context subgraph�еĽڵ�u,�������ھӽڵ�v�����ݺ�������������ʾ,���幫ʽ����(GNN����):
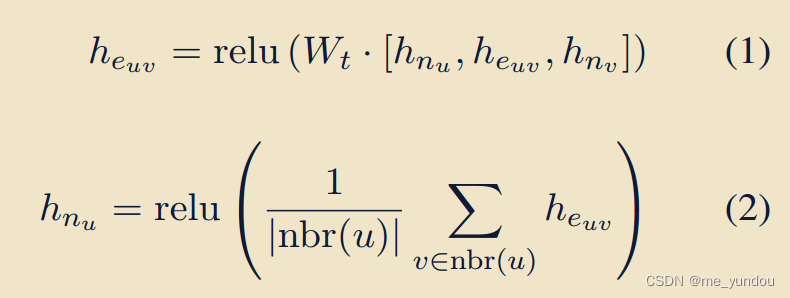
- ���local KG����,�������������ڵ�u��v,����������ʽ(1)��������֮���credibility��
- ���ͨ��ͼע��������Ϣ���ݻ���,��global context��local KG��������Ϣ����������(����:һ�����Ų��DZ���������һ����ý���ͼ��?����Ϊʲô�ֳַ�������ͼ?������ͼ���������Լ���ѧϰ����?Ȼ���ٽ������?)
5. ģ�ͼ�ⲿ��:
- document-level���:ǰ���Ѿ�ѧ����graph�нڵ�ͱߵ�������ʾ,������avg����max pooling��node/edge feature�õ�graph feature��Ȼ���graph feature�������Է���Ϳ���ʵ������Լ�⡣���Ȿ���ڷ���ǰ������һЩָʾ����to strengthen signals,��Щָʾ�������Է�ӳ�ظ�ʵ����Ŀ(����ָʾ��������ʲô�ô�?��ʱ������)��
- KE-level���:���Ƕ�KG�б߽��з���,�����Щ��ϵ�����¼���ɫ�Ƿ�������
6. �����������:
����KE����������ű�ע����̫��,���˹���ע�ɱ�̫��,���Ա���������ַ��������ɿص��ϳɵ��������,�����ܹ�ΪKE�Զ����ɱ�ǩ(�й���ٵı�ǩ)��
����һ����ʵ���ż���X_{real},���������������KG,�����������KG�е�����KEs,�õ�һ���ĺ����ٵ�KG��;��ô,���ĵ�KEs���ܹ��Զ�ӵ�����ǩ---fake,δ���ĵ�KEs����real��,ͬʱ��document-level��,�ĺ��KG����ת��Ϊtext֮��,�õ�����fake�����š�
6.1 �ϳɵ�KG to text
��KG�Ļ��������ض�KEʵ�����text�����ɡ����������ʵ��,��ϵ,���¼���
- ʵ���滻:��ԭʼʵ���滻Ϊͬ���͵�����ʵ��;
- �����¹�ϵ�����¼�:����KG�����е�ʵ��,���ѡ����һ����ϵ�����¼�,Ȼ��Ϊ��ʵ���ϵ����һ���µ�ʵ��(�൱�ڸ���ͷʵ���ϵ,����һ��βʵ��);
- ��ͼ�滻:����һ�������е���ͼ�滻��ǰ�����е���ͼ(�����ض���node����ͼ);
����ͬʱ���ǹ�ȥ��node����edge,���Ƿ���ȱʧ��Ϣ���ڼ���������̫���ˡ���������û��ѡ��ȥ������KEs�ķ�ʽ��
���,�õ��ϳɵ�KG����,ͨ��fine-tuningһ��BART-largeģ��,���ɶ�Ӧ��������š�����ͼ3��ʾ,��һ��ʵ���滻�����ӡ�

6.2 �ϳɵ�AMR to text
ǰ�˹�������caption���ڼ��������ŷdz�����,��˱��Ļ�ͨ�����е�real news��captions���ϳ��������,ͨ����caption��ʵ��֮��Ĺ�ϵ��
����������ȡreal news��captions�ij��������ʾ(Abstract Meaning Representation ,AMR,�ܹ�����ḻ�ľ��Ӽ���������)ͼ,Ȼ������ЩAMR graphs,����ĺ�����AMR graphת��Ϊtext,�õ����news������ͼ4��ʾ��һ�����ӡ�
������AMR graph�ķ�ʽ���ﲻ����,��ϸ�뿴����ԭ��4.2�½ڡ�

ʵ��:
���ݼ�:
- NYTimes-NeuralNews,����һ����ý���������ż������ݼ�,��[1],[2]�������;
- VOA-KG2txt,���DZ���ʹ�úϳ�KG to text �ķ�ʽ�Լ�����������������ݼ�;
�Աȷ���:[2] �� [3];
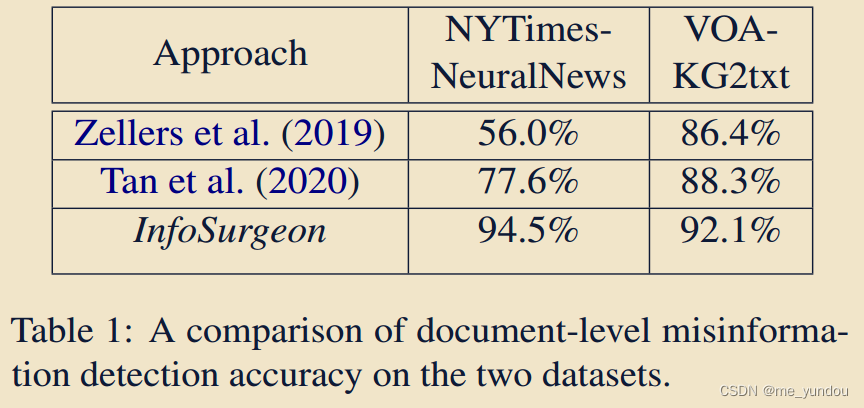
document-level�ļ��������:
���±�1��ʾ,���������ݼ���,���ķ�����������������baseline�ܶࡣ
������Ϊ,�����tan 2020�ķ���,������������ʹ���˶�ý��ṹ����,�����˶����KG��background��Ϣ,���ܲ���ʵ��,��ϵ��Щ�ṹ��Ϣ��
ͬʱ������Ϊ,VOA������Ĺ��������ݼ�,��������infoSurgeon��˵�����ض��Ѷȵ�,���DZ��ķ�����Ȼ������á�
KE-level�ļ����:
���KE-level����ټ��������������ż��Ŀɽ�����,�ܹ�����������ʲô���������ŵ�fake��
�����������ݵ�ȱ��,Ŀǰֻ���ڱ����Լ�������VOA���ݼ��Ͻ���KE-level�ļ��ʵ�顣���±�2��ʾ,������������,���ķ����������ܸ��á�
��һ����,������ȷ�ʺܵ�,����Ϊ���KE-level����ټ���ѶȽϴ�,��Ҫhigher-level������,���ڶ�ý�����ʵ��Ϣ���м�⡣

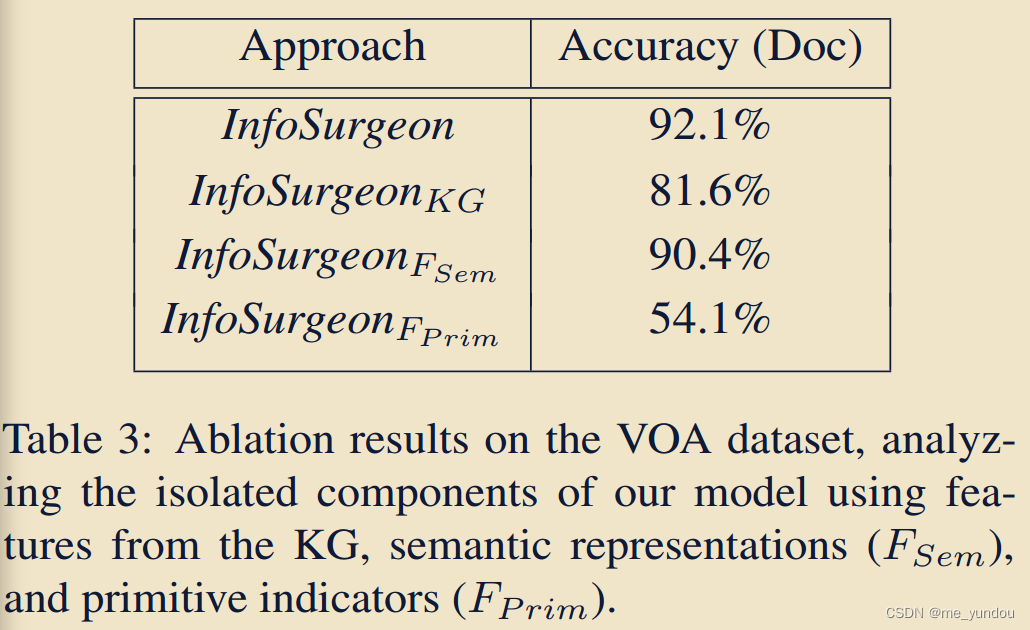
����ʵ�����������չʾ(����5.4�½�):
���±�3��ʾ,�ֱ������ʹ��KG,semantic features,��ָʾֵ�ı��ı���ģ�����õ�������ż����,���п��Կ������������Լ���������Ч(����news��text,image��captions��Щsemantic features),KG��ϸ���ȵ����KE����и������á�
���±�4��ʾ,��һ�� ������ŵ�����,Tan 2020�ķ�����Ϊ��������real,�����ĵķ�����ȷʶ����˸�����Ϊfake��,���Ҵ�KE-level��λ�����Ĵ������ڡ�twin towers�����ʵ�塣��¼����������������,����Ȥ�Ŀ���ȥ����ԭ�IJ鿴��

�������ı����˹�ͼ�����:
Ϊ�˲��Ա���KG-to-text�������ŵ�����,���߽������˹����ԡ����ѡȡ��100ƪ����,һ��realһ��fake,��16�����ж���Щ���ŵ���١�
���Ľ����:������ж�ȷ����61.6%,�����ŵ��ж�ȷ����81.2%,�����ŵ��ж�ȷ��ֻ��41.9%��������֮һ�ļ����ż���һ����˶��жϴ����ˡ�
ʵ��������,�����Զ����ɵ�������Ŷ�����������ǽ����жϵ�(Ҳ���Ǿ��нϸ�������text)��
�ܽἰչ��:
���������һ���µķ����ڼ���ý����������������ܴﵽ92%-95%��ȷ��,������ÿ�ģ̬�IJ�һ���Ժ�KE-level�Ĺ�ϵ,ʵ��ϸ���ȵĿɽ����Ե�������ż�⡣
��δ��,�����Ǽƻ��Ӹ����ģ̬�Ͻ���������ݵļ��,������text,image,video,audio�ȸ�����Ϣ;��multiple documents�����ڳ�ʶknowledge�Ͻ���һ��������;�ƹ㵽open-domain��document �����,�����Դ��,�����Ե�,���Ļ��ġ�
��Զ����,���ƻ���������˹����ɵ�����,�ܹ������������͵����,����ʵ����ӱ��,���ż�ֵ�ȡ�
ע��:Ϊ�˱��ⲻ��������˴�������������,���IJ�����������ŵ�����������ģ��;ͬʱ����������ż�ⷽ��ģ��,�Թ���Ҹ��õش��������š��������ԭ�ĵ�8�½ڡ�
�������������:
1.����ʵ����ֻѡ�����������ݼ�,����һ�������Լ�������,�������ֱ���ģ����Բ�ͬ���ݼ�,�ڲ�ͬ���������ϵķ����ԡ�Ϊʲô�����ü������ݼ���?
2.���ĶԱȷ���ֻѡ��������,���е�������ż��Ķ�ģ̬ģ���Ѿ��ܶ���,Ϊʲô�����жԱ���?
�����:
[1] Ali Furkan Biten, Lluis Gomez, Marc?al Rusinol, and Dimosthenis Karatzas. 2019. Good news, everyone! context driven entity-aware captioning for news images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 12466�C12475.
[2] Reuben Tan, Bryan Plummer, and Kate Saenko. 2020. Detecting cross-modal inconsistency to defend against neural fake news. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2081�C2106, Online. Association for Computational Linguistics.
[3] Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. In Advances in Neural Information Processing Systems, pages 9054�C9065