2021年发布在ICML,称为最简单的多模态模型。
论文题目:ViLT:不带有卷积和区域建议的视觉语言转换器
研究问题:
研究动机:现有的VLP方法严重依赖图像特征提取过程,大多包含区域监督(如目标检测)和卷积的结构(如ResNet)。一方面需要更多的计算,影响了速度和效率;另一方面表达能力欠佳,为它是视觉嵌入器及其预定义的视觉词汇的表达能力上限。
主要贡献:ViLT是目前参数量最小的多模态Transformer方法。ViLT使用预训练的ViT来初始化交互的transformer,这样就可以直接利用交互层来处理视觉特征,不需要额外增加一个视觉encoder(如Faster-RCNN)。
研究思路:提出了一种视觉和语言Transformer(ViL),以统一方式处理两个模态。与以前VLP模型的不同在于其浅层、无卷积嵌入像素级输入,删除仅用于视觉输入的深度嵌入器,可以显著减少模型的尺寸和运行时间。
研究方法:其将VE设计的如TE一样轻量的方法,该方法的主要计算量都集中在模态交互上,如图2(d)。提出一种基于以下两点的视觉和语言模型的分类法:1)两个模态在专用参数和/或计算方面是否具有均匀的表达水平;2)两个模态是否在一个深度网络中交互。这些点的组合将得到图2中的四个原型。
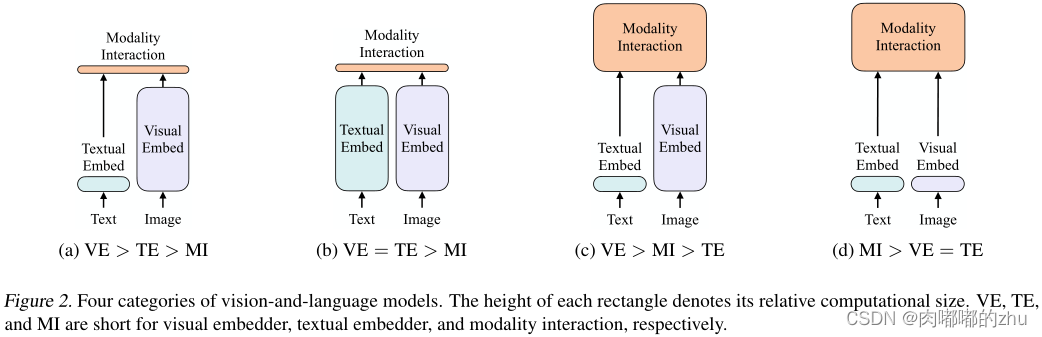
?
研究过程:
这个预训练模型共有三种有预训练任务。
Image Text Matching
随机以0.5的概率将文本-图片对中的图片替换其他图片,然后对文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像和文本是否匹配。
同时ViLT借鉴UNITER,设计了一个word patch alignment (WPA)来计算textual subset和visual subset的对齐分数。(这个需要研究一下UNITER的论文)
其思想是计算得到的word embedding和图像区域块 vision embedding之间的相关性(这里没有公示,估计真的论文还没放上去)。
Mask Languge modeling
随机mask掉15%的词,使用视觉-文本联合表示来预测。
Whole Word Masking
这是一种将词的tokens进行mask的技巧,其目的是使模型充分利用其他模态的信息。
这个预训练任务的训练方式是:
比如“giraffe”一词,
- 分词器会将成3个部分["gi", "##raf", "##fe"]。
- 如果并非所有标记都被屏蔽,例如 ["gi", "[MASK]", "##fe"],则模型可能仅依赖附近的两个语言标记 ["gi", "##fe"] 来预测被屏蔽的“##raf”而不是使用图像中的上下文信息。
实验结果:
? ? ? ? 数据集:Microsoft COCO, Visual Genome, SBU Captions, Google Conceptual Captions? ? ? ? ? ? ? (四个数据集进行预训练)
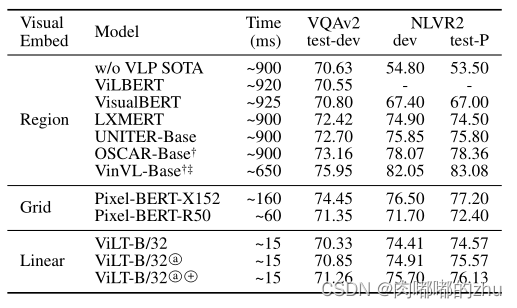
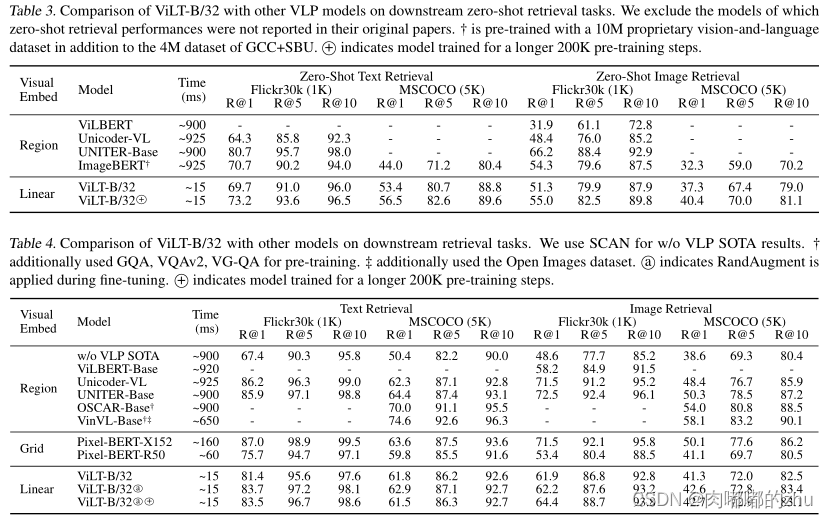 ?
?
?消融实验部分,主要验证模型预训练中采取的两个预训练任务以及一个微调时使用的技术的效果。
- Whole word masking
- Masked patch predition
- 图像增强技技术:RandAugment
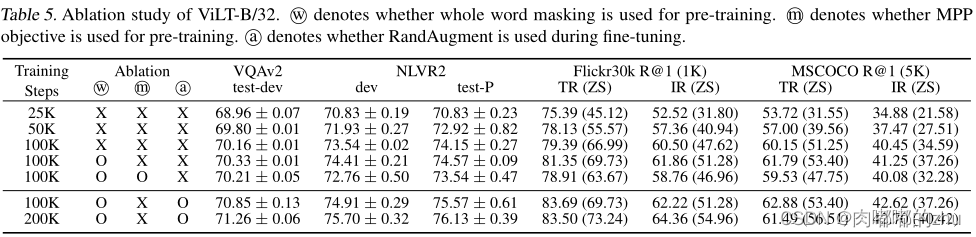
?实验体现了Whole word masking在预训练时以及图像增强在微调时的重要性
总结:本文提出的方法在效率上大大提升且表现出相似的性能,相比于region feature的方法速度快了60倍,相比于grid feature的方法快了4倍,而且下游任务表现出相似甚至更好的性能。
ViLT能够胜任那些配备卷积视觉嵌入网络(如Faster R-CNN、ResNets)的竞争对手。将来关于VLP的工作更多是关注transformer模块内部的模态交互。
? ? ? ? 尽管ViLT-B/32非常引人注目,但它更多地证明了没有卷积和区域监督的高效VLP模型仍然是可以胜任的。
? 可测量性? ? 如关于大规模transformer的论文所示,给定适当的数据量,预先训练过的transformer具有良好的性能。这一观察为更好地执行ViLT的变体(如ViLT-L和ViLT-H)铺平了道路。我们在将来会训练更大的模型,因为对齐的视觉和语言数据集仍然稀缺。
? 视觉输入的掩码建模? ? ??我们认为,可以应用在视觉非监督研究中的交替聚类或同时聚类方法。鼓励未来的工作不使用区域监督来设计一个更复杂的视觉形态的掩码目标。
? ?增强策略? ? 之前关于对比视觉表示学习的工作表明,与更简单的增强策略相比,不使用RandAugment的高斯模糊比下游性能带来了显著的收益。为文本和视觉输入探索适当的增强策略将是一个有价值的补充。