ФПТМ
ШЮЮё
-
ШЮЮё3:TFIDFгыЮФБОЗжРр
Just Do It!?
1.TF-IDF
ДЫДІЪЙгУСЫSklearnАцЕФTF-IDFЪЕЯж,ЕБШЛвВПЩвдгУnltkЛђепДПPythonАцБОЪЕЯжЁЃ
TF-IDFЕФЪЕЯжПЩвдВЮПМ:TF-IDFЫуЗЈНщЩмМАЪЕЯж_Asia-LeeЕФВЉПЭ-CSDNВЉПЭ_tf-idf
дкЁОCoggle 30 Days of MLЁПЦћГЕСьгђЖргяжжЧЈвЦбЇЯАЬєеНШќ(2)жавбОЕУЕНСЫбЕСЗМЏКЭВтЪдМЏЗжДЪжЎКѓЕФdataframeСЫЁЃЯТУцОЭгУsklearnжаЕФPipelineНЋTF-IDFКЭТпМЛиЙщетСНИіЙРМЦЦїДђАќ,дйДђбЕСЗМЏЕФШегяКЭгЂЮФЦДЦ№РД(етЪЧвЛжжКмАєЕФДІРэЗНЪН)ДЋШыPipelineНјааfitЁЃ
#бЕСЗTFIDFКЭТпМЛиЙщ
pipeline = make_pipeline(TfidfVectorizer(),LogisticRegression())
pipeline.fit(
train_jp['words'].tolist() + train_eg['words'].tolist(),
train_jp['втЭМ'].tolist() + train_eg['втЭМ'].tolist()
)етРяжЕЕУвЛЬсЕФЪЧTF-IDFЕФЪЕЯжгУСЫ TfidfVectorizer ,ЮвзЂвтЕНsklearnЕФЙйЗНЮФЕЕжаВЛжЙетвЛИіЗНЗЈШЅЪЕЯжTF-IDF,ЛЙгаЯТЭМЕФfeature_extraction.text.TfidfTransformer(*)ЁЃ

ФЧЫћСЉгаЩЖЧјБ№Фи?
ЮвУЧРДПДвЛЯТЙйЗНЮФЕЕЪБШчКЮУшЪіЕФЁЃ
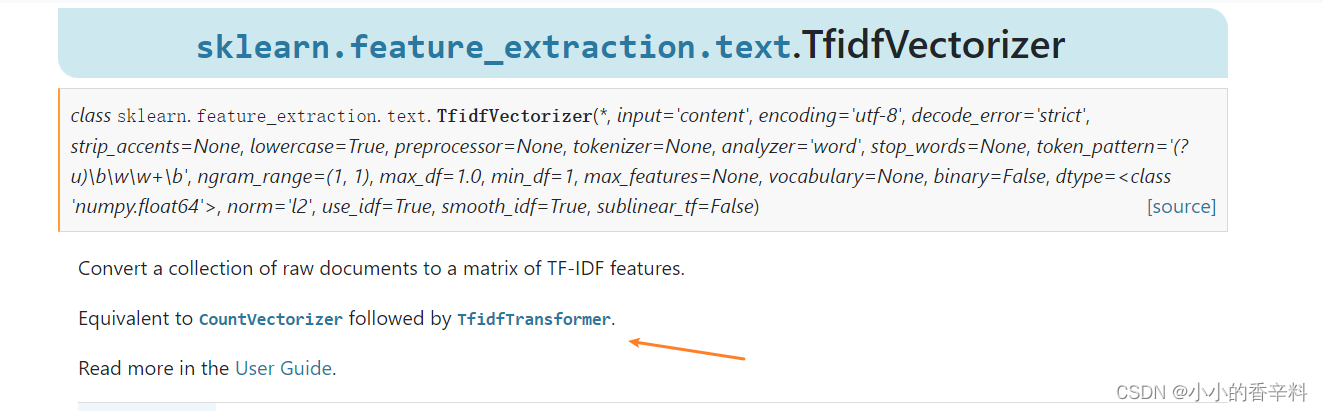
ПЩвдЧхГўЕФПДЕН,TfidfVectorizerЦфЪЕОЭЯрЕБгкЯШНЋЮФБОЭЈЙ§feature_extraction.text.CountVectorizerзЊЛЏЮЊДЪЦЕЙВЯжОиеѓ,дйНЋЙВЯжОиеѓДЋШыTfidfTransformerЁЃЖјЮветИіРСШЫдѕУДПЩФмЗжСНВНШЅзі,ЙћЖЯбЁдёСЫTfidfVectorizer,вЛВНЕНЮЛ!
ОйИіР§згПДвЛЯТtf-idfЕФЙ§ГЬ:
ИјЖЈбЕСЗМЏcorpusКЭВтЪдМЏcorpus_test,ЪЙгУtf-idfЫуЗЈЕУЕНЖдгІгяСЯЕФtf-idfжЕЁЃ
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
corpus_test = [
'This is a test.',
'This is a super man.',
'I will be stronger.',
'What is your name?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print('tf-idfЕУЕНЕФЬиеїга:',vectorizer.get_feature_names())
print('tf-idfЕУЕНЕФаЮзДЮЊ:',X.shape)
print(X)
#зЊЛЛЮЊОиеѓаЮЪН
x_train_tfidf = X.toarray()
print('tf-idfОиеѓЮЊ:\n',x_train_tfidf)
#ЪЙгУЩЯУцбЕСЗЕФtf-idfЙРМЦЦїФтКЯВтЪдМЏ
x_test_tfidf = vectorizer.transform(corpus_test).toarray()
print('ВтЪдМЏЕФtf-idfОиеѓЮЊ:\n',x_test_tfidf)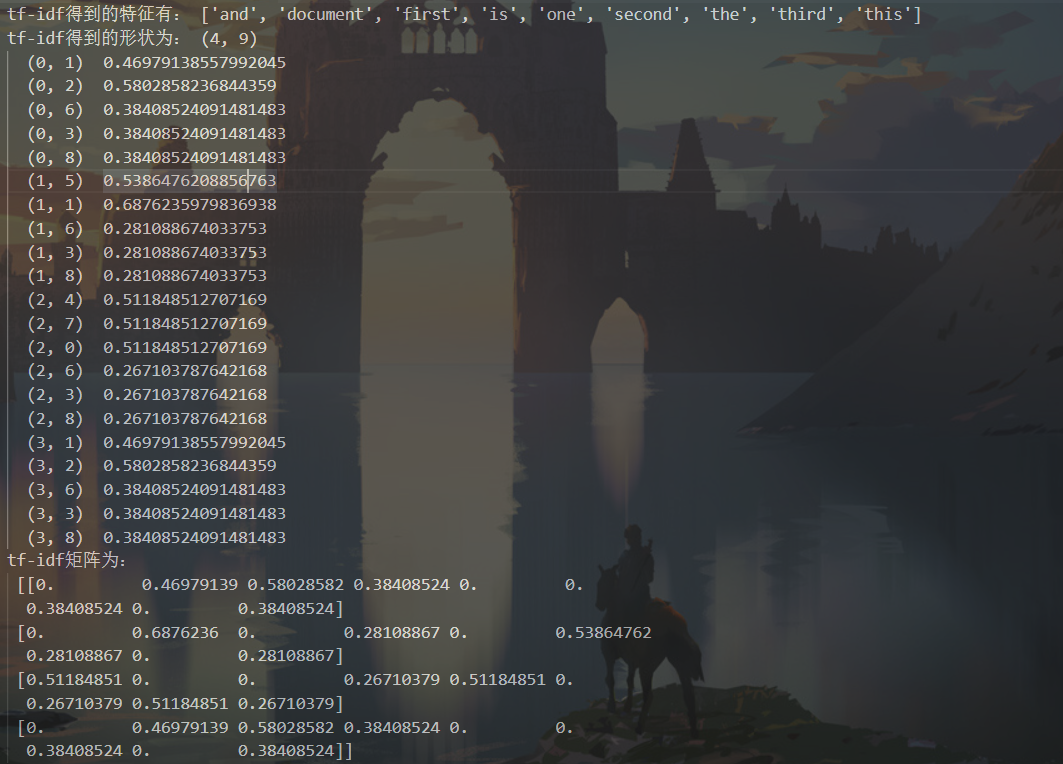
2.ЙмЕРЙЙНЈ(make_pipeline)
СэЭтвЛИіжЕЕУЫЕЕФЕуЪЧЙмЕРЙЙНЈ,ЮвPythonЛљДЁвЛАу,ЙмЕРЙЙНЈжЎЧАКмЩйгіЕН,етДЮЫуЪЧgetЕНСЫЁЃ
МђЕЅРДЫЕОЭЪЧНЋЖрИіВйзїДђАќ,ПЩвдХњСПжДааЁЃМѕЩйСЫДњТыСП,ИќживЊЕФЪЧ,ПЩвддкЭјИёЛЏЫбЫїжаЪЙгУpiplineЁЃ
ВЮПМ:ЁЖPythonЛњЦїбЇЯАЛљДЁНЬГЬЁЗЙЙНЈЙмЕР(make_pipeline)_elma_twwЕФВЉПЭ-CSDNВЉПЭ
дкЛњЦїбЇЯАжавЊЖрГЂЪдШЅгУЫќ,ФмЬсЩ§ПЊЗЂаЇТЪЁЃ
?3.ФЃаЭдЄВт
ИљОнБШШќУшЪі,ЬсНЛЕФЪЧвЛИіexcelЮФМў(.xlsxКѓзК),АќКЌ2Иіsheet(ШегяКЭгЂЮФ)ЁЃ
УПИіsheetАќКЌ4Са,дЪМЮФБОЁЂвтЭМЁЂВлжЕ1ЁЂВлжЕ2 ЁЃ
ЖдгІДњТыШчЯТ:
#ФЃаЭдЄВт
test_jp['втЭМ'] = pipeline.predict(test_jp['words'])
test_eg['втЭМ'] = pipeline.predict(test_eg['words'])
test_eg['ВлжЕ1'] = np.nan
test_eg['ВлжЕ2'] = np.nan
test_jp['ВлжЕ1'] = np.nan
test_jp['ВлжЕ2'] = np.nan ЕУЕНЕФtest_jpНсЙћШчЯТ:?
гЂЮФвВЪЧвЛбљЕФаЮЪН

?ЕЋЮвУЧwordsетвЛСаЪЧВЛашвЊЬсНЛЕФ,ЫљвдЩњГЩЬсНЛЮФМўЕФДњТыЮЊ:
writer = pd.ExcelWriter('../result/submit_tfidf_logistic1.xlsx')
test_eg.drop('words',axis=1).to_excel(writer,sheet_name='гЂЮФ_testA',index=False)
test_jp.drop('words',axis=1).to_excel(writer,sheet_name='Шегя_testA',index=False)
writer.save()
writer.close()OK,Fine!?