-
- 文本挖掘概要
- 文本挖掘的应用:(有实际案例)
- 文本挖掘概要
- 运用文本挖掘进行公司治理(台湾证券交易所的案例)
证券交易所的功能就是监管上市公司的问题(财务不实,内部被掏空的问题)。但是会出现一个盲点
比如一家公司宣布自己公司要停止发行。台湾证券交易公司不能及时进行处理。
证交所在进行数据分析,得到的数据都是延后的信息,都是用公司的年报,季度报告,半年报的信息不全。年报虽然信息全,但是它的年报都是比较落后的数据,没法实时预警。那怎么办呢?
于是就准备向非结构化的咨询来源进行入手(文本),因为媒体会对公司的情况进行公开,报道一下重大信息咨询宣告。能不能给我们当做文本挖掘的数据。
非结构化数据是每天都会发布的。可能你会担心是不是媒体会故意报告公司好的一面,和公司勾结,其实我们分析的其实并不是分析词的含义,好还是坏,我们不会特别关注,主要分析的是词与之前的关系
比如一家公司一直被报道:盈收创新高,如果报道次数比较少,一般都不会出现财务问题。如果频繁报道营收创新高,反而会出现问题。我们不关心这个词好坏,
我们不关心它股价高低,我们只关心它是不是有问题,还活着就好。
再比如,一家公司不断更换总经理,我们可能会担心会不会有问题,其实这个问题对后来股市结果关联性不强,但是一家公司一直更换会计师,那一般财务就会有问题。因为财务处问题,第一个处理的就是会计师。这个关系就很密切。
我们是根据词与目标的关系,判断公司是不是会出现财务问题。分析出其中重要的关键因子,来建立我们的预警模型。
结构化的资源也要进行,因为这个部分已经很完善了,所以就主要起到辅助的作用。原因一般概况为4个因素。也建立一个预警模型
之后会说如何将二者模型合并起来。
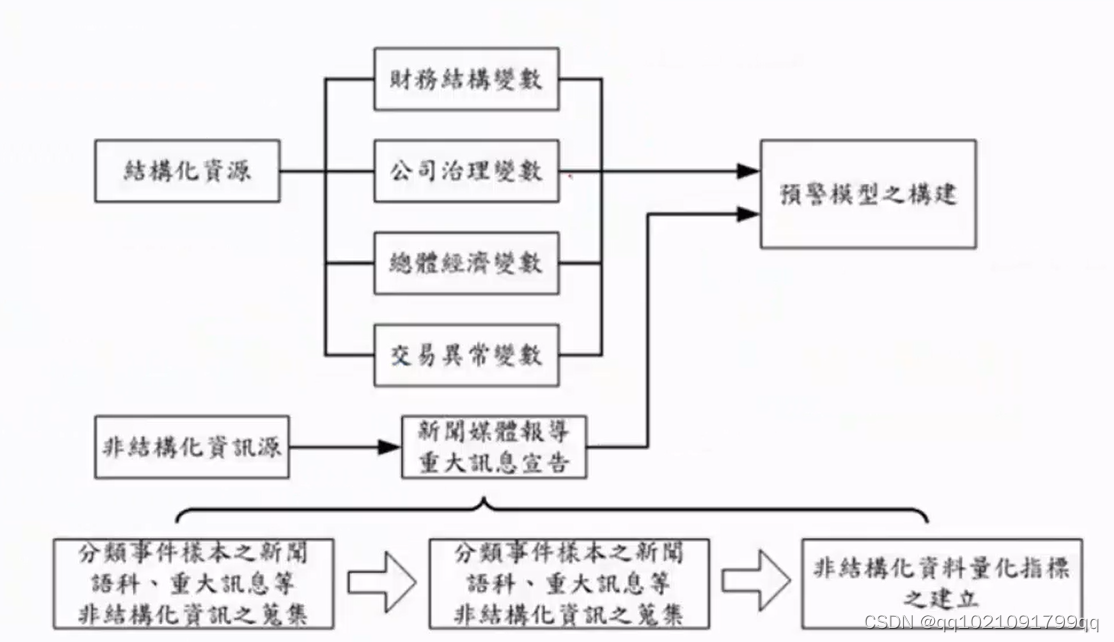
证券交易所但是有些疑虑,这些事件是否真的会影响公司情况吗。于是我们要把退市,出现问题的公司,和没有出现问题的公司是否出现重大讯息。先用简单的分析,来查看重大讯息是否有影响。
正常公司的词云图:
最经常出现的词是,董事会决议发放红利。等等
正常公司讯息好像大部分看起来都是偏正面的
这个词云图:对词出现进行了定义,这里面董事会决议发放红利,视作一个词。这里面的定义不一定要完全重复。中间可以有字体插入。符合规则的就引入。这是证交所的认知,我们进行的调整。必须要按企业的要求进行调整。

退市公司词云图

这里面就有充实运营资金,这个就是不好的行为。表面上看起来是好的,其实一般这种情况发生,停止营业的概率就会提高。大部分都是比较不好的词语出现。
因为每家公司都必须进行重大讯息宣告,否则就是违法。这个就可以当做我们的实时预警,结果发现非常的准确。和公司内部关系太直接,所以就换成新闻语料。
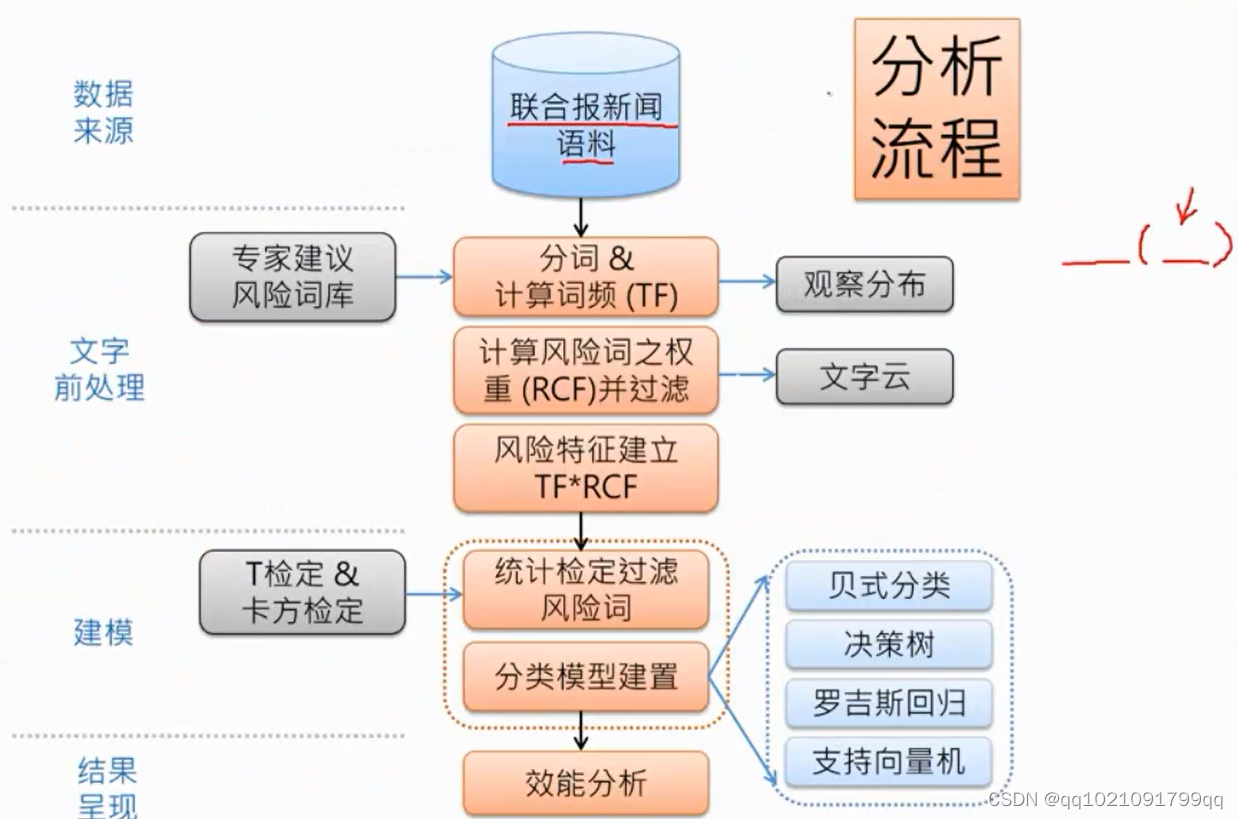
数据来源:
语料来源:
重大讯息宣告的杂讯很少,证交所决定太简单了,不乐意,所以我们就用媒体新闻的语料。购买了联合报的新闻语料。
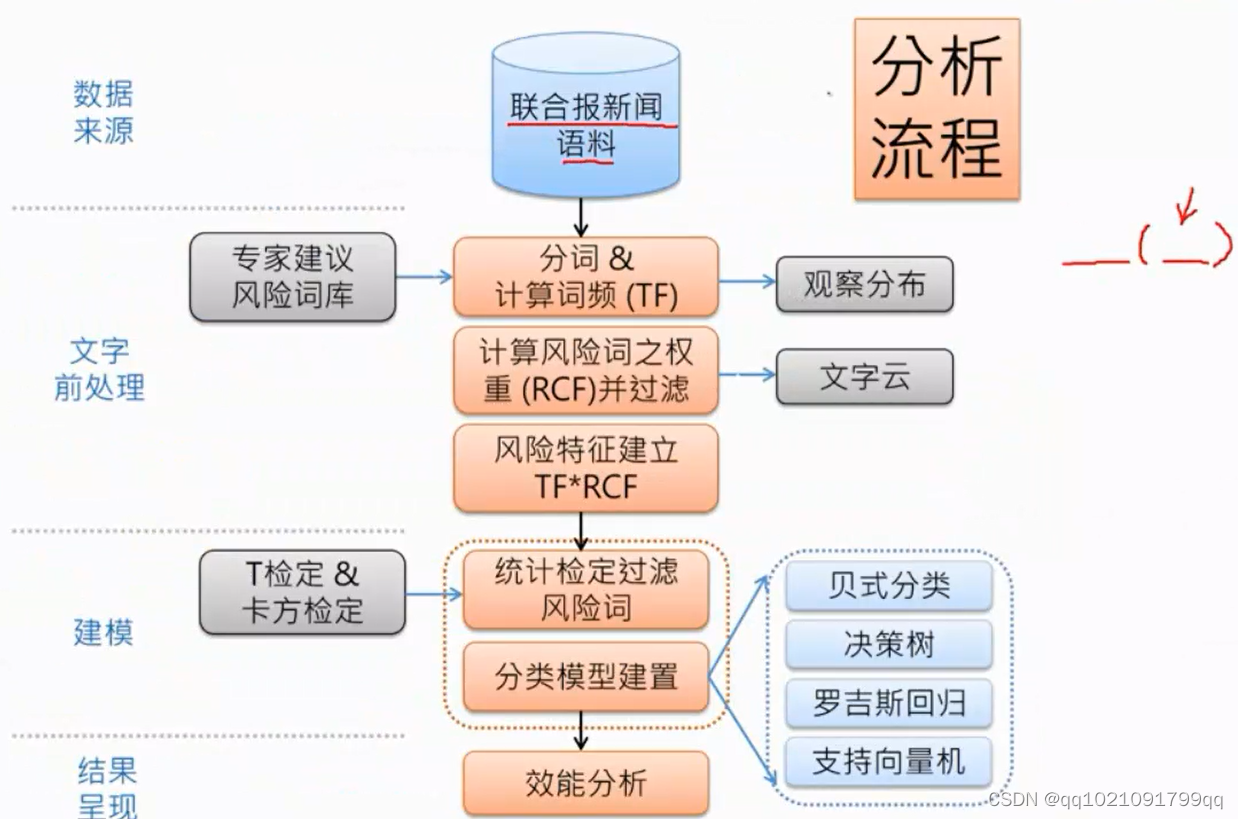
文字预处理
购买的是,其中有上市公司的其中一家或多家的信息我们才需要。结果其中杂讯非常多。
比如:有一家公司叫嘉张。结果还有一个地区也叫嘉张。于是只要有地区报道,就会被归入上市公司?
再比如:有一家公司叫电脑界面。
为什么不购买更好的数据呢。因为证交所,只给了6个月时间,如果购买的另一家更好的报社,数据需要3个月的时间。谈不拢,30万。于是就和联合报合作。还只花了9万。
17年的报纸数据:量很大,还得清除杂讯。
分词:之前说的公司与地区重名,公司名称很常用。就会出现分词困难
利用专家建议建立风险词库:
要建立自己的分词系统
这篇报道新闻中间的一大段情感词是很没用的,如果直接进行分词研究,那我们就会发现父母务农之类凑巧出现的词与公司财务出现问题有关,数据挖掘本身就是寻找关联性,但是不一定有因果关系。无法解释。
红字标出风险词,剩下的词就不用考虑。于是让财务专家对这些词标准出来,得到更合适的语料库。专家列不出来,只能看文章说是不是风险词。然后再标注出来。于是就打印了几十份,让专家用荧光笔进行标注,然后我们在进行提取。
然后分词的时候仅存留风险词,剩下的排除,风险词也不一定与企业财务风险相关,数据不支持的话也要过滤掉。
风险词权重处理
RCF指标,评估一个词是否是权重词的指标,越趋近与0越无用,趋近与负数就是越可能有风险。越趋近正数越可能正常。
词云图:
按照处理之后筛选的分析图,进行词云分析。得到了上面那个图。
风险特征建立:
标准是TF*IDF(我们使用的是TF*RCF)后面课程会具体说明是如何计算的。
建模:
统计检定:
T检定&卡方检定
过滤风险词
分类模型建立:利用算法:贝式分类,决策树,逻辑回归,支持向量机
或者深度模型来跑(后面发现深度学习效果更好。)
因为有些时候,深度学习效果在数值型,分类型结果型数据,效果不好
深度学习在图像识别,文本分析的时候效果会比较好。
最后写出效能分析。
异常公司:
财务不实,掏空
财务不实,掏空,停止公发,下市
及早预警:半年内的数据不能用,不能忽略执行面。要
出现危机前出现异常概率分布模型:
半年
一年
一年半:
分析架构是利用深度学习,神经网络来提高销量。
神经网络如下
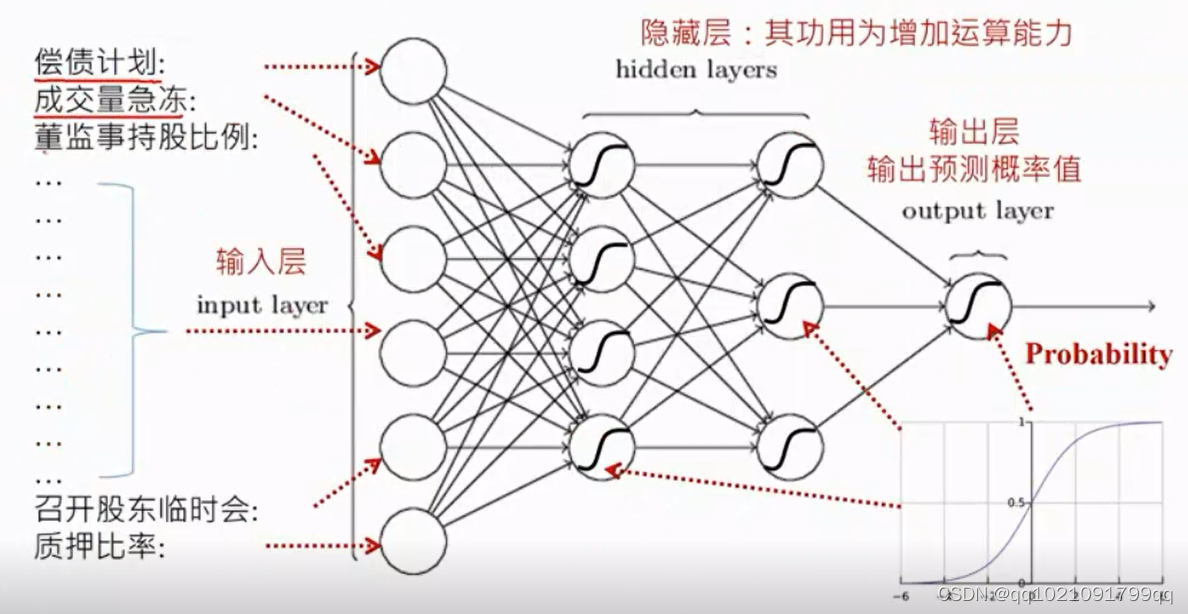
董监事持股比例是很重要的输入字段
然后得到输出预测概率值。
然后这个时候我们要同时考虑结构化数据的预测概率值和非结构化的预测概率值
就利用散点图分块的方法:

要优先预警非结构化的模型,因为非结构化模型的预测概率很高。
结构化模型预测概率相对较低。
右上角是必然出问题了
左上角是证交所自己就了解有风险的对象
左下角是结构化和非结构化的模型预测概率都较低。
右下角的情况,是证交所感兴趣的公司群。
出现直线的点,就是因为没有任何报道的情况。就会把它判定为正常公司。结构化是是一定有数据。但是我们不了解,没有数据,所以还是得依赖结构化数据。
预测异常公司在一年半前的情况。
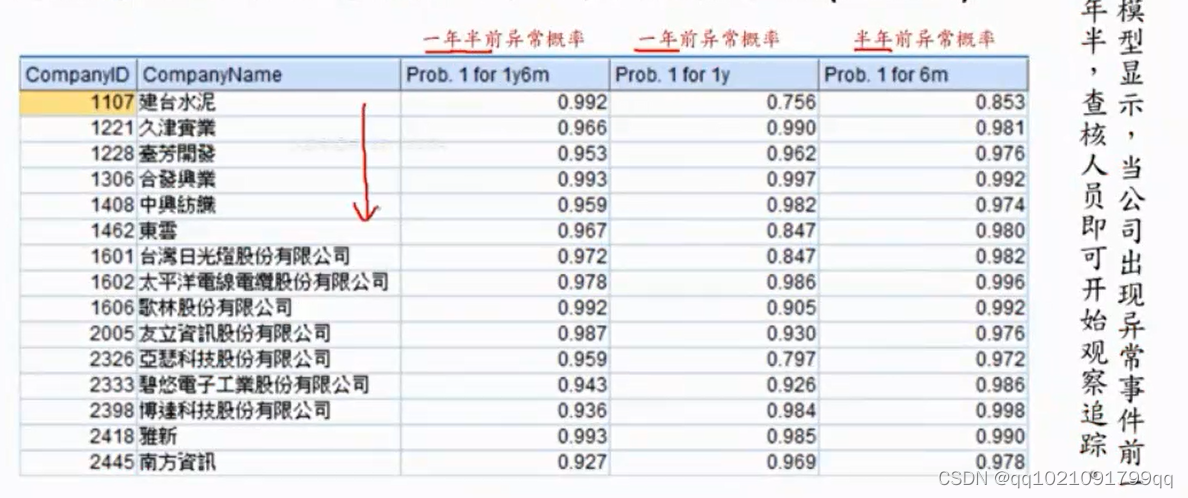
模型表明,一年半之前就可以看出他可能有异常问题
比如建台水泥。一年半前异常概率都挺高的。
不过随着时间的推进没有越来越高的趋势。预估已经异常的公司
目前我们说的都是理论,后面实操在具体说明。
2.Social Bot 互动模式设计(深度学习,进阶技术)
陪伴机器人:有很多图书,10万册左右。
机器人会收集孩子的反馈,(不是为了隐私阿)
发现全是吐槽的反馈,傻,笨脏话之类的。
明明人都离开了,还在念图书。
于是这家公司就很沮丧,想能不能提供互动选项(比如不同的题目。)。互动够多就可以提供赠品。
现在希望能不能让机器AI自动提出问题。
要考虑看看机器能问出什么问题
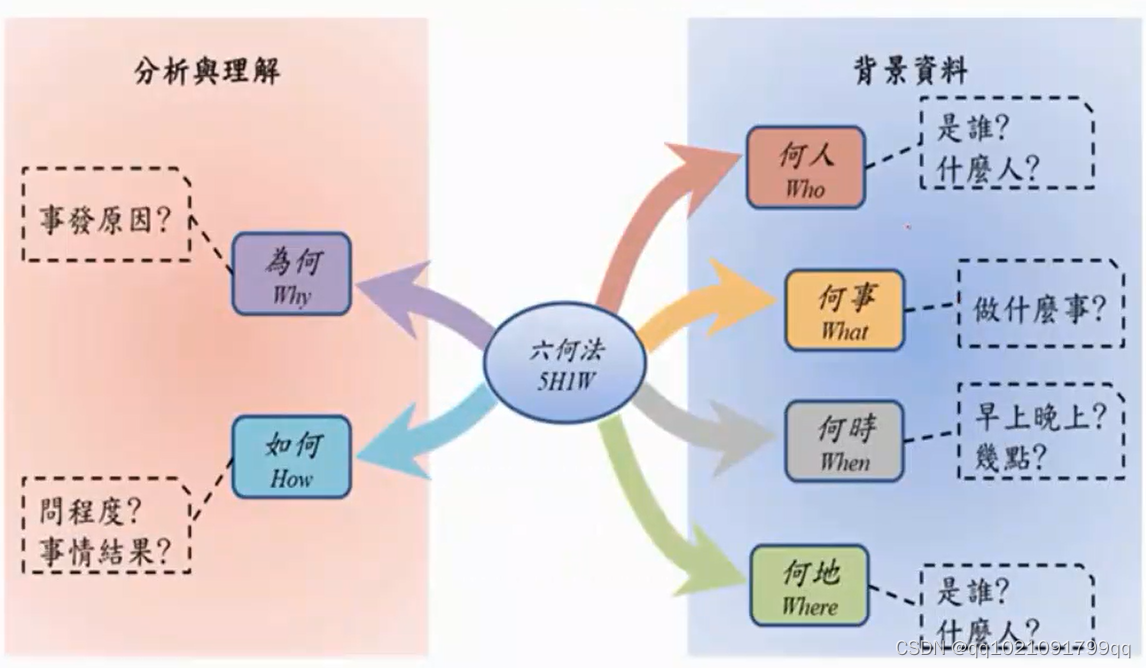
于是就提出理论5h1w,人,事,时,地,为何,如何
分析与理论这边,难度很高,就算使用机器学习也很难进行。

问人Who




人事地物,是比较简单的
但是要跨段落比较难,比如哪些人帮荷花找珍珠,先做简单的人事地物:
下面这些都是不能做的很好。


为什么月亮说珍珠明天就回来
荷花妹妹的珍珠是什么
从哪里可以知道。
文内没有答案,十分困难。
可以研究,但是没法做出。方向就是这样。
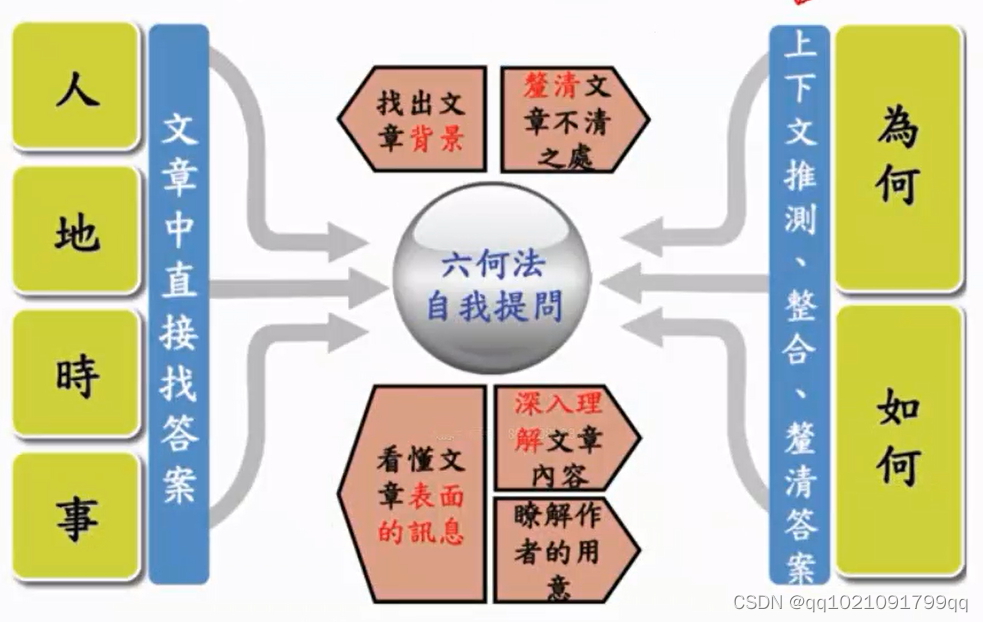
需要用到的技术:
深度学习为基础的命名实体辨识:
人时地物
深度学习为基础的情绪分析。
正评,负评
深度学习为基础的文本摘要。
DNN CNN RNN LSTM Attention
题目选项要尽量在题目中有,
比如白雪公主吃的是有毒的什么东西:
苹果,图钉,
之后会用实际案例介绍。