DeBERTa:���з���ע�����Ľ�����ǿ�� BERT
ժҪ
Ԥѵ��������ģ�͵����½�չ���������������Ȼ���Դ��� (NLP) ��������ܡ�
�ڱ�����,���������һ���µ�ģ�ͼܹ� DeBERTa(Decoding-enhanced BERT with disentangled attention),��ʹ�������¼����Ľ��� BERT �� RoBERTa ģ�͡���һ���������ע��������,����ÿ�����ʷֱ�ʹ�������������ݺ�λ�ý��б����������ʾ,����֮���ע����Ȩ�طֱ�ʹ�������ݺ����λ�õķ�����������㡣���,ʹ����ǿ�����������������λ�úϲ����������,��Ԥ��ģ��Ԥѵ���е������ǡ�����,һ���µ�����Կ�ѵ�����������������ģ�͵ķ���������
���DZ���,��Щ�������������ģ��Ԥѵ����Ч���Լ���Ȼ�������� (NLU) ����Ȼ�������� (NLG) ������������ܡ��� RoBERTa-Large ���,��һ��ѵ��������ѵ���� DeBERTa ģ���ڹ㷺�� NLP ������ʼ�ձ��ָ���,�� SQuAD v2.0 �ϵ� MNLI ��ʵ���� +0.9% �ĸĽ�(90.2% �� 91.1%) +2.3%(88.4% �� 90.7%),RACE ���� +3.6%(83.2% �� 86.8%)��ֵ��ע�����,����ͨ��ѵ��һ������İ汾����չ DeBERTa,�ð汾�� 48 ���任��� 15 �ڸ�������ɡ����ŵ���������ʹ�õ��� DeBERTa ģ���ں��ƽ���÷�(89.9 �� 89.8)�����״γ����� SuperGLUE ��(Wang ����,2019a)�ϵ��������,���Ҽ��� DeBERTa ģ��λ�� SuperGLUE ֮�Ͻ��� 2021 �� 1 �� 6 �յ����а�,�Կɹ۵����Ƴ������������(90.3 �� 89.8)��Ԥѵ���� DeBERTa ģ�ͺ�Դ���뷢����:https://github.com/microsoft/DeBERTa1��
����
Transformer �ѳ�Ϊ�����Խ�ģ����Ч��������ܹ����밴˳�����ı���ѭ�������� (RNN) ��ͬ,Transformers Ӧ����ע���������м��������ı��е�ÿ�����ʵ�ע����Ȩ��,�Ժ���ÿ�����ʶ���һ�����ʵ�Ӱ��,����ڴ�������� RNN ��������IJ��л����ģģ��ѵ��(Vaswani et al., 2017)���� 2018 ������,���ǿ�����һ����ģ�Ļ��� Transformer ��Ԥѵ������ģ�� (PLM) ������,���� GPT (Radford et al., 2019; Brown et al., 2020)��BERT (Devlin et al., 2020) al., 2019), RoBERTa (Liu et al., 2019c), XLNet (Yang et al., 2019), UniLM (Dong et al., 2019), ELECTRA (Clark et al., 2020), T5 (Raffel et al., al., 2020)��ALUM (Liu et al., 2020)��StructBERT (Wang et al., 2019c) �� ERINE (Sun et al., 2019)����Щ PLM ��ʹ���ض�������ı�ǩ��������,��������������Ȼ���Դ��� (NLP) �����д��������µļ���ˮƽ(Liu ����,2019b;Minaee ����,2020;Jiang ����,2020; He et al., 2019a;b; Shen et al., 2020)��
�ڱ�����,���������һ���µĻ��� Transformer ��������ģ�� DeBERTa(Decodingenhanced BERT with disentangled attention),��ʹ�������¼����Ľ�����ǰ���Ƚ��� PLM:һ�ַ����ע�������ƺ�һ����ǿ�������������
Disentangled attention(��ɢע����) ����������е�ÿ������ʹ���䵥��(����)Ƕ���λ��Ƕ��֮�͵���������ʾ��BERT��ͬ,DeBERTa�е�ÿ������ʹ�÷ֱ�������ݺ�λ�ý��б����������������ʾ,����ʹ�÷ֱ���ڵ��ʵ����ݺ����λ�õĽ������������㵥��֮���ע����Ȩ�ء� �������ڹ۲쵽���ʶԵ�ע����Ȩ�ز���ȡ�������ǵ�����,��ȡ�������ǵ����λ�á�����,��deep���͡�learning�������������ڳ���ʱ,����֮���������Ҫ�ȳ����ڲ�ͬ�ľ�����ʱǿ�öࡣ
Enhanced mask decoder(��ǿ�����������)���� BERT һ��,DeBERTa ʹ���������Խ�ģ (MLM) ������Ԥѵ���� MLM ��һ���������,���н̵�ģ��ʹ����������Χ�ĵ�����Ԥ�����뵥��Ӧ����ʲô�� DeBERTa �������Ĵʵ����ݺ�λ����Ϣ���� MLM�����ע������Ѿ������������Ĵʵ����ݺ����λ��,��û�п�����Щ�ʵľ���λ��,������������¶�Ԥ��������Ҫ�����Ǿ��ӡ�a new store opening beside the new mall��,б���֡�store���͡�mall���������Խ���Ԥ�⡣��Ȼ�������ʵľֲ�����������,�������ھ����а��ݲ�ͬ�ľ䷨��ɫ�� (����,����,���ӵ������ǡ�store�������ǡ�mall����)��Щ�䷨�ϵ�ϸ����ںܴ�̶���ȡ���ڵ����ھ����еľ���λ��,�����Ҫ����Ҫ����һ���������Խ�ģ�����еľ���λ�á� DeBERTa �� softmax ��֮ǰ����˾��Դ�λ��Ƕ��,�ڸò���,ģ���ݴ����ݺ�λ�õľۺ�������Ƕ�������ʽ��н�����
����,���ǻ������һ���µ�����Կ���ѵ������,������PLM�����ε�NLP���÷�����Ч�������ģ�͵ķ�������
����ͨ��һ��ȫ���ʵ֤�о�����,��Щ������������Ԥѵ����Ч�ʺ�������������ܡ���NLU������,��Roberta-Large���,����һ��ѵ�����ݵ�DeBERTaģ���ڹ㷺��NLP�����б���һ�¸���,MNLI�����+0.9%(90.2%��91.1%),���v2.0�����+2.3%(88.4%��90.7%),���������+3.6%(83.2%��86.8%)����NLG������,DeBERTa��Wikitext-103���ݼ��ϵ������21.6���͵�19.5������ͨ��Ԥ��ѵ��һ�������ģ������һ������DeBERTa,��ģ����48����ѹ�����15�ڸ�������ɡ�����1.5B������DeBERTaģ����Superglue��(Wang����,2019a)�ϴ���˾���110�ڸ�������T5,�߳�0.6%(89.3%��89.9%),���״γ����������(89.9vs.89.8)������2021��1��6��,DeBERTa�ϳ���ģ��λ��Superglue���а����,���൱������Ƴ��������(90.3��89.8)��
2 ����
2.1 TRANSFORMER
����Transformer������ģ���ɶѵ���Transformer�����(Vaswani����,2017)��ÿ�������һ����ͷ�Թ�ע��,�����һ����ȫ���ӵ�λ��ǰ�����硣��������ע�����ȱ��һ����Ȼ�ķ�ʽ�����뵥��λ����Ϣ�����,���з�����Ƕ���ÿ�����������λ��ƫ��,ʹ��ÿ�����������ֵȡ���������ݺ�λ�õ�ʸ������ʾ��λ��ƫ�����ʹ�þ���λ��Ƕ��(Vaswani����,2017;Radford����,2019;Devlin����,2019)�����λ��Ƕ��(Huang����,2018;Yang����,2019)��ʵ�֡��о�����,���λ�ñ���������Ȼ��������������������Ч(Dai����,2019��;Shaw����,2018��)�������е�ע�������Ʋ�ͬ����,����ʹ��������������������ʾÿ�������,�����������ֱ��ʾ�ʵ����ݺ�λ��,����֮���ע����Ȩ����ֱ�ʹ�ý�����������㡣
2.2 MASKED LANGUAGE MODEL(��������ģ��)
���ģ���� Transformer �� PLM ͨ���ڴ����ı��Ͻ���Ԥѵ��,��ʹ�ó�Ϊ�ڱ�����ģ�� (MLM) �����ҼලĿ����ѧϰ�����Ĵʱ�ʾ (Devlin et al., 2019)��������˵,����һ������ X = {xi},����ͨ��������� 15% �ı�ǽ����ƻ�Ϊ X,Ȼ��ѵ��һ���� �� ������������ģ��,ͨ��Ԥ���� X Ϊ���������α��?x ���ؽ� X
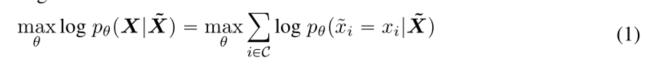
���� C �������б����α�ǵ��������� BERT �����߽��鱣�� 10% �������Dz���,���� 10% �滻Ϊ���ѡ��ı��,������滻Ϊ [MASK] ��ǡ�
3 THE DEBERTA ARCHITECTURE
3.1 DISENTANGLED ATTENTION: A TWO-VECTOR APPROACH TO CONTENT AND POSITION EMBEDDING(�ע����:���ݺ�λ��Ƕ���˫��������)
����������λ��i���ı��,����ʹ���������� { H i } \{H_i\} {Hi?}�� { P i �O j } \{P_{i|j}\} {Pi�Oj?}����ʾ��,�����������ֱ��ʾ�����ݺ���λ��j���ı�������λ�á�����i��j֮��Ľ���ע������ļ�����Էֽ�Ϊ�����ĸ���ɲ���
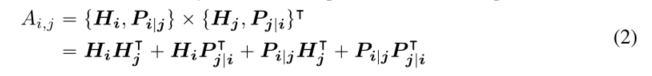
Ҳ����˵,�ʶԵ�ע����Ȩ�ؿ���ͨ��ʹ�������ݺ�λ���ϵ�ȥ����������Ϊ���ݶ����ݡ����ݶ�λ�á�λ�ö����ݺ�λ�ö�λ�õķ������������Ϊ�ĸ�ע��������֮����
���е����λ�ñ��뷽���ڼ���ע��Ȩ��ʱʹ�õ�����Ƕ��������������λ��ƫ��(Shaw����,2018��;Huang����,2018��)�����൱��ֻʹ�ù�ʽ2�е����ݵ����ݺ�����λ����������ע����Ȩ�ء�������Ϊλ�õ�������Ҳ����Ҫ,��Ϊ�ʶԵ�ע����Ȩ�ز���ȡ�������ǵ�����,����ȡ�������ǵ����λ��,��ֻ��ʹ�����ݵ�λ�����λ�õ�����������ȫ��ģ����������ʹ�����λ��Ƕ��,λ�õ�λ����ṩ̫�����Ϣ,���������ǵ�ʵ���дӹ�ʽ2��ɾ����
�Ե�ͷע��Ϊ��,��������ע�����(Vaswani����,2017)�ɱ���Ϊ:
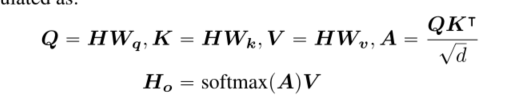

����,H P RN?d��ʾ������������,HO P RN?d��ʾ����ע������,Wq,Wk,WV P Rd?d��ʾͶӰ����,A P RN?N��ʾע�����,N��ʾ�������еij���,�Լ�d��ʾ����״̬��ά�ȡ�
��ʾkΪ�����Ծ���,��pi,jq P r0,2kqΪ����i������j����Ծ���,�䶨��Ϊ: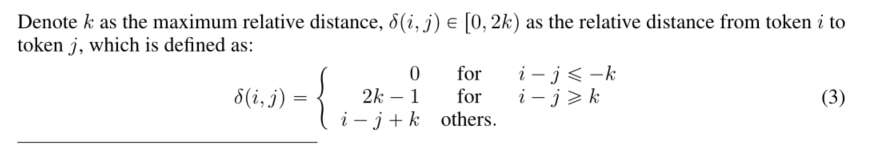
���ǿ��Խ��������λ��ƫ���δ����������ע���ʾΪ��ʽ4,����Qc��Kc��Vc�ֱ���ʹ��ͶӰ����Wq��c��wk��c��Wv��c��c P Rd?d���ɵ�ͶӰ��������,P P R2k?d��ʾ�����в�֮�乲�������λ��Ƕ������(��,��ǰ���ڼ䱣�̶ֹ�),�Լ�Qr��KRare�ֱ�ʹ��ͶӰ����Wq��r��wk��r P Rd?d���ɵ�ͶӰ���λ��������
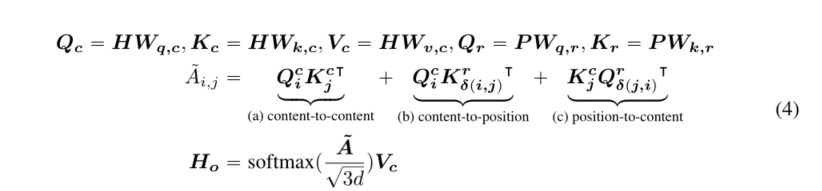
���������ͼƬ����
����
���������һ���µ�ģ�ͼܹ� DeBERTa(Decoding-enhanced BERT with disentangled attention),��ʹ�������¼����Ľ��� BERT �� RoBERTa ģ�͡�
��һ���������ע��������,����ÿ�����ʷֱ�ʹ�������������ݺ�λ�ý��б����������ʾ,����֮���ע����Ȩ�طֱ�ʹ�������ݺ����λ�õķ�����������㡣�ڶ�������ǿ�����������,���ڽ�����н�Ͼ���λ����Ԥ��ģ��Ԥѵ���е������ǡ�
����,һ���µ�����Կ�ѵ������������,�����ģ�Ͷ���������ķ�������������ͨ��ȫ���ʵ֤�о�����,��Щ�������������ģ��Ԥѵ����Ч�ʺ�������������ܡ����� 15 �ڸ������� DeBERTa ģ���ں��ƽ���÷ַ����״γ�Խ�� SuperGLUE �������е�������֡� DeBERTa �� SuperGLUE �ϳ�Խ����ı��ֱ�־������ͨ�� AI ����Ҫ��̱��������� SuperGLUE ��ȡ���˿�ϲ�ijɹ�,����ģ�;�����ﵽ NLU ����������ˮƽ������dz��ó����ôӲ�ͬ������ѧ����֪ʶ�����������,�������������ض��������ʾ���ⱻ��Ϊ��Ϸ���,����������Ϥ�ɷ�(�����������������ļ���)�������(������)��������չ��δ��,ֵ��̽�����ʹ DeBERTa �Ը���ȷ�ķ�ʽ�����Ͻṹ,�����������������������������Ȼ���Ե��ͷ��ż�����������