本次学习笔记主要记录学习深度学习时的各种记录,包括吴恩达老师视频学习、花书。作者能力有限,如有错误等,望联系修改,非常感谢!
卷积神经网络(三)- 目标检测
- 一、目标定位(Object localization)
- 二、特征点检测(Landmark detection)
- 三、目标检测(Object detection)
- 四、滑动窗口的卷积实现(Convolutional implementation of sliding windows)
- 五、Bounding Box预测(Bounding Box predictions)
- 六、交并比(Intersection over union)
- 七、非极大值抑制(Non-max suppression)
- 八、Anchor Boxes
- 九、YOLO算法(Putting it together:YOLO algorithm)
- 十、(选)候选区域(Region proposals)
第一版???????2022-07-18????????初稿
一、目标定位(Object localization)

图片分类任务是算法遍历图片,判断对象是不是汽车;
次节为定位分类问题,不仅有单个的定位和分类,还有多个对象的定位。
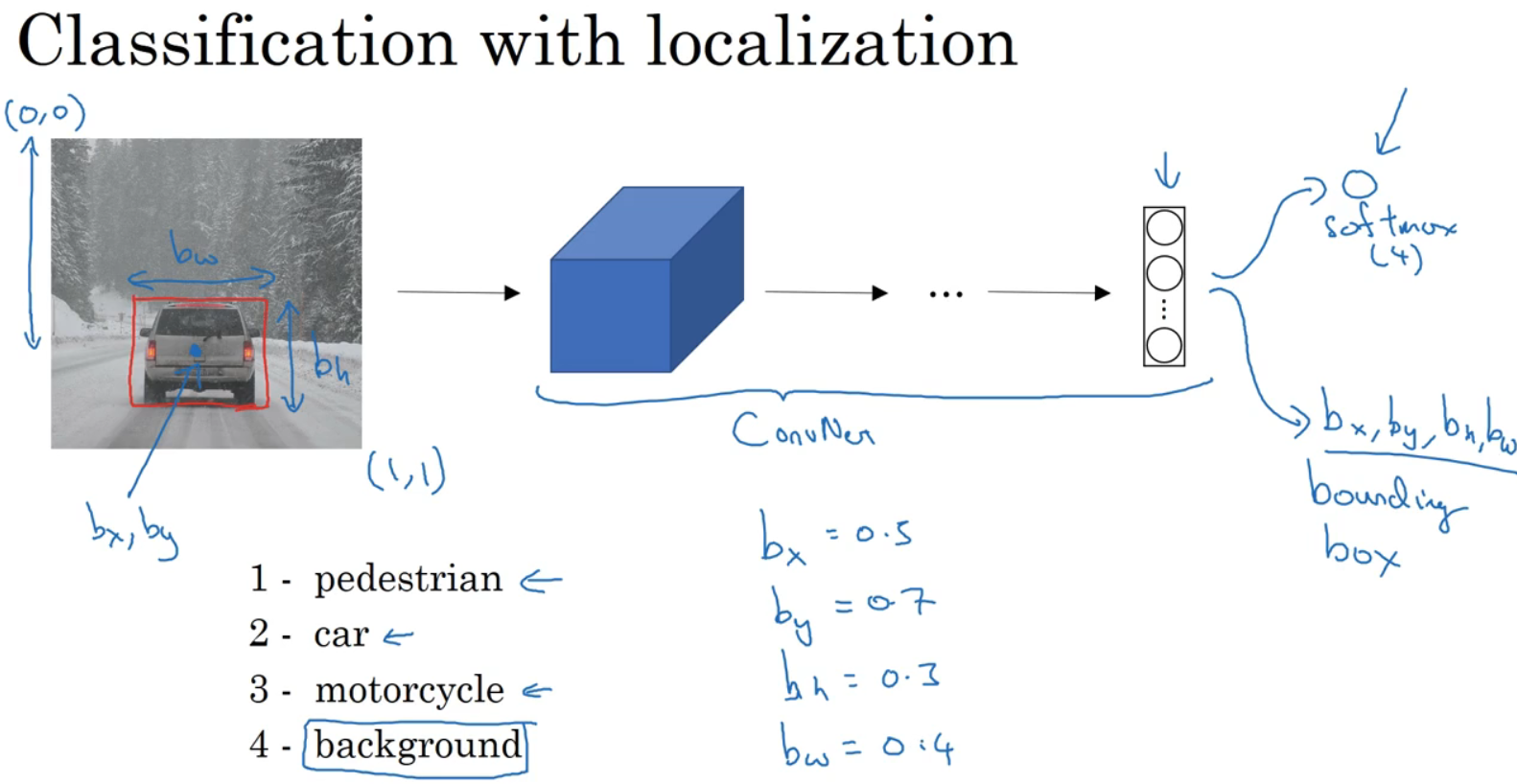
图片分类并不陌生,输入图片到卷积神经网络,输出一个特征向量,反馈给softmax单元来预测图片类型。
若正在构建汽车自动驾驶系统,对象可能包括:行人、汽车、摩托车和背景。定位可以让神经网络多输出4个数字,记为bx,by,bh,bw,是被监测对象的边界框的参数化表示。
图左上角为(0,0),右下角为(1,1),确定边界框具体位置,需指定红色方框的中心点(bx,by),边界框高度bh,宽度bw。
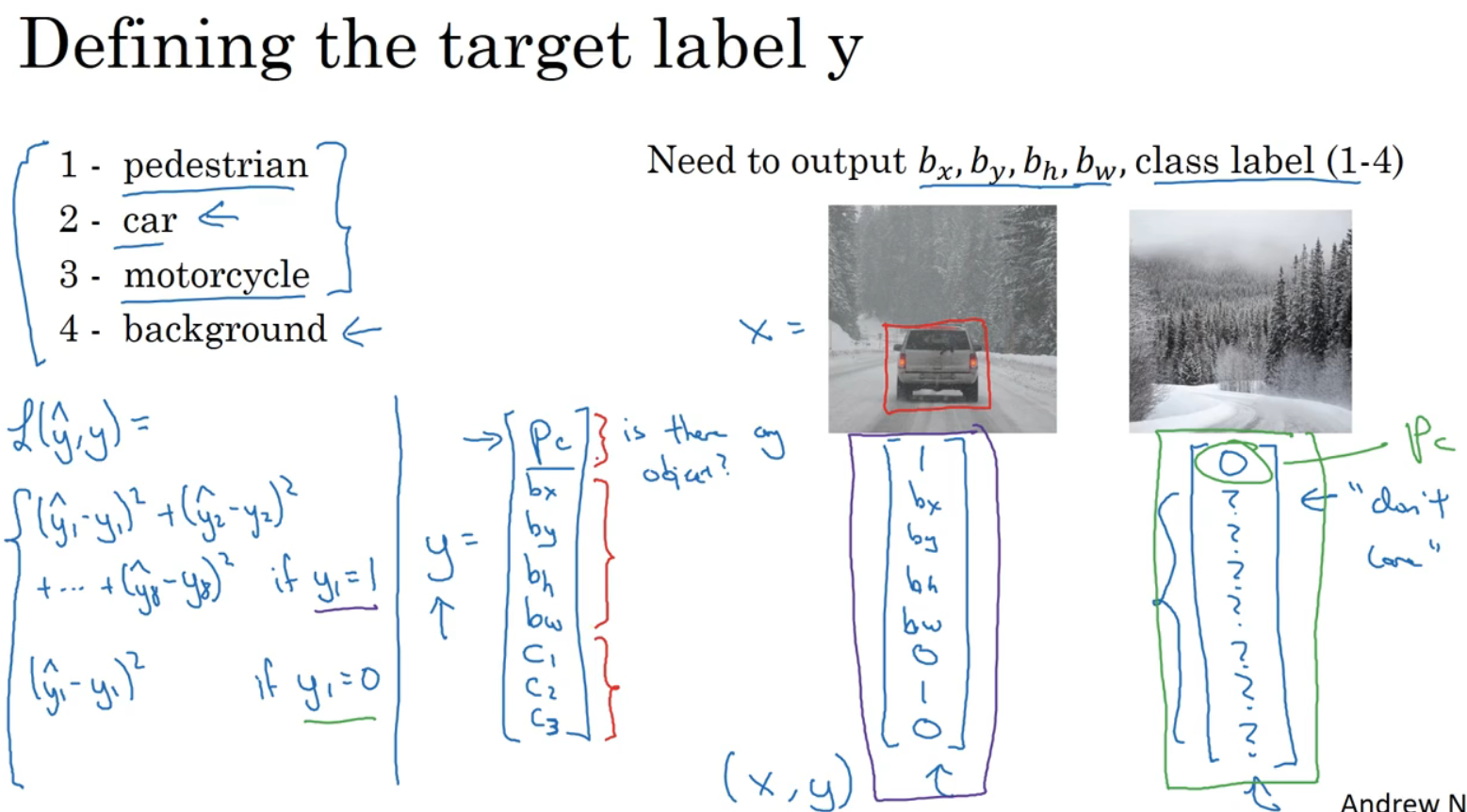
为监督学习任务定义目标标签:
目标标签y的定义如下:
y
=
(
p
c
b
x
b
y
b
h
b
w
c
1
c
2
c
3
)
y=\left( \begin{array}{l} pc\\ bx\\ by\\ bh\\ bw\\ c1\\ c2\\ c3\\ \end{array} \right)
y=?
??pcbxbybhbwc1c2c3??
??
pc表示是否含有对象,若对象属于前3类,则pc=1,背景则为pc=0。检测到对象输出边框四个参数,判断从c1,c2,c3。
如图的汽车图片,如其下方;没有检测对象时,如汽车图片右方图片下方,pc=0,其他参数则毫无意义。
最后定义神经网络的损失函数,参数为类别y和网络输出yhat,采用平方误差策略。
二、特征点检测(Landmark detection)
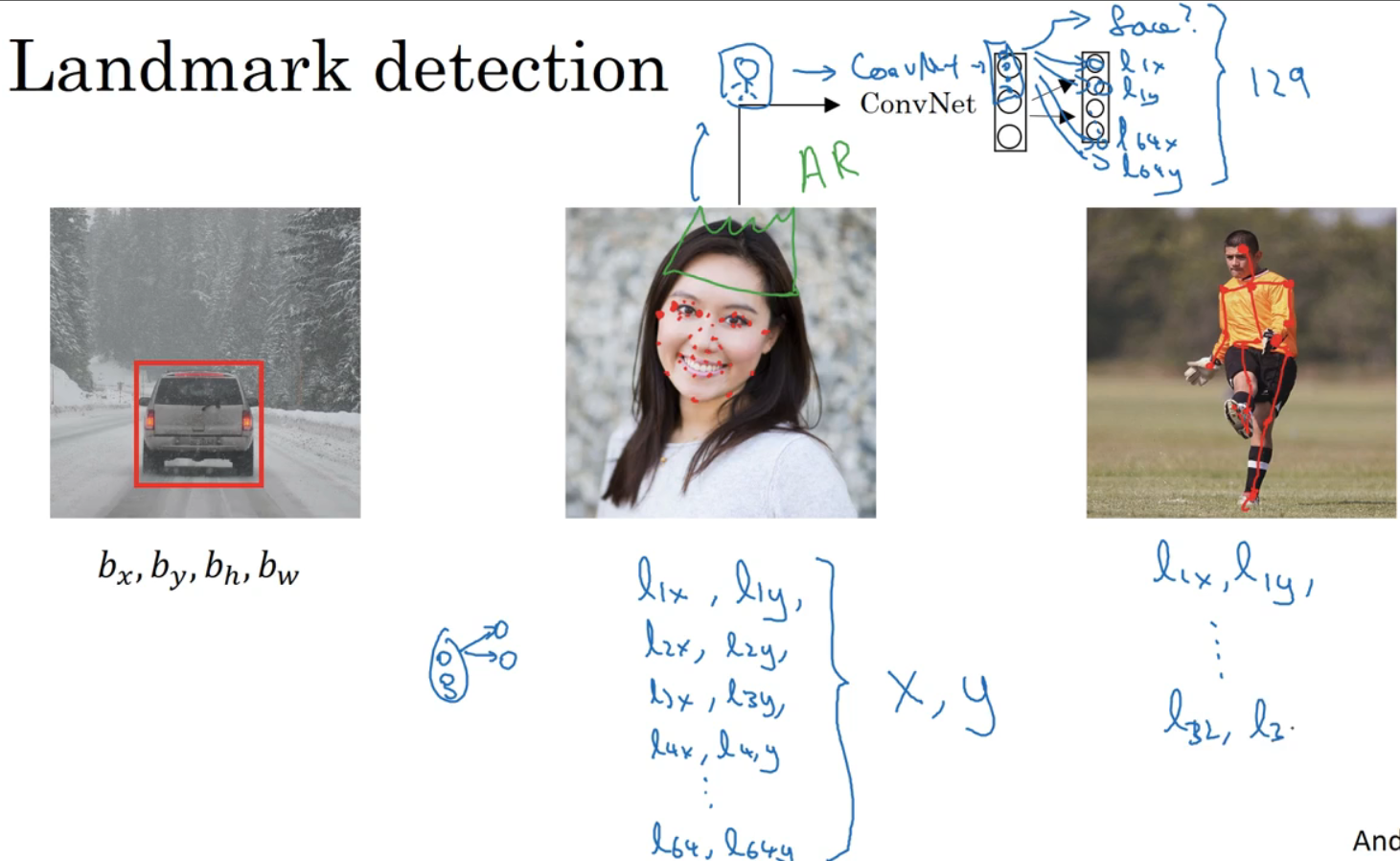
神经网络可以通过输出图片上特征点的(x,y)坐标来实现对目标特征的识别。
假设正在构建一个人脸识别应用,给出眼角定位,可让输出层多输出lx和ly,作为眼角的坐标值。想知道两个眼睛的四个眼角位置,有(l1x,l1y)和(l2x,l2y),以此类推。还可关注其他特征点,如嘴判断是否微笑,或是否皱眉。
具体做法:
准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,输出1或0,表示是否有人脸,然后输出(l1x,l1y)…(l64x,l64y),会有129(64x2+1)个输出单元。
最后一个例子,若对人体姿态感兴趣,可定义一些关键特征点。特征点1的特性在所有图片中必须保持一致。
三、目标检测(Object detection)

加入构建一个汽车检测算法:
1.创建一个标签训练集,
2.训练卷积网络,
3.卷积网络输出y,0或1表示图片中有汽车或没有汽车。
训练完,就可以用它实现滑动窗口目标检测。

如图测试图,一个特定大小窗口,将其输入卷积神经网络,判断红色框内有没有汽车。
第一张判断后,会处理第二个图片,选用步幅大滑动更快,以固定步幅移动窗口。然后用更大的红框。
此算法叫做滑动窗口目标检测。缺点是计算成本。
四、滑动窗口的卷积实现(Convolutional implementation of sliding windows)
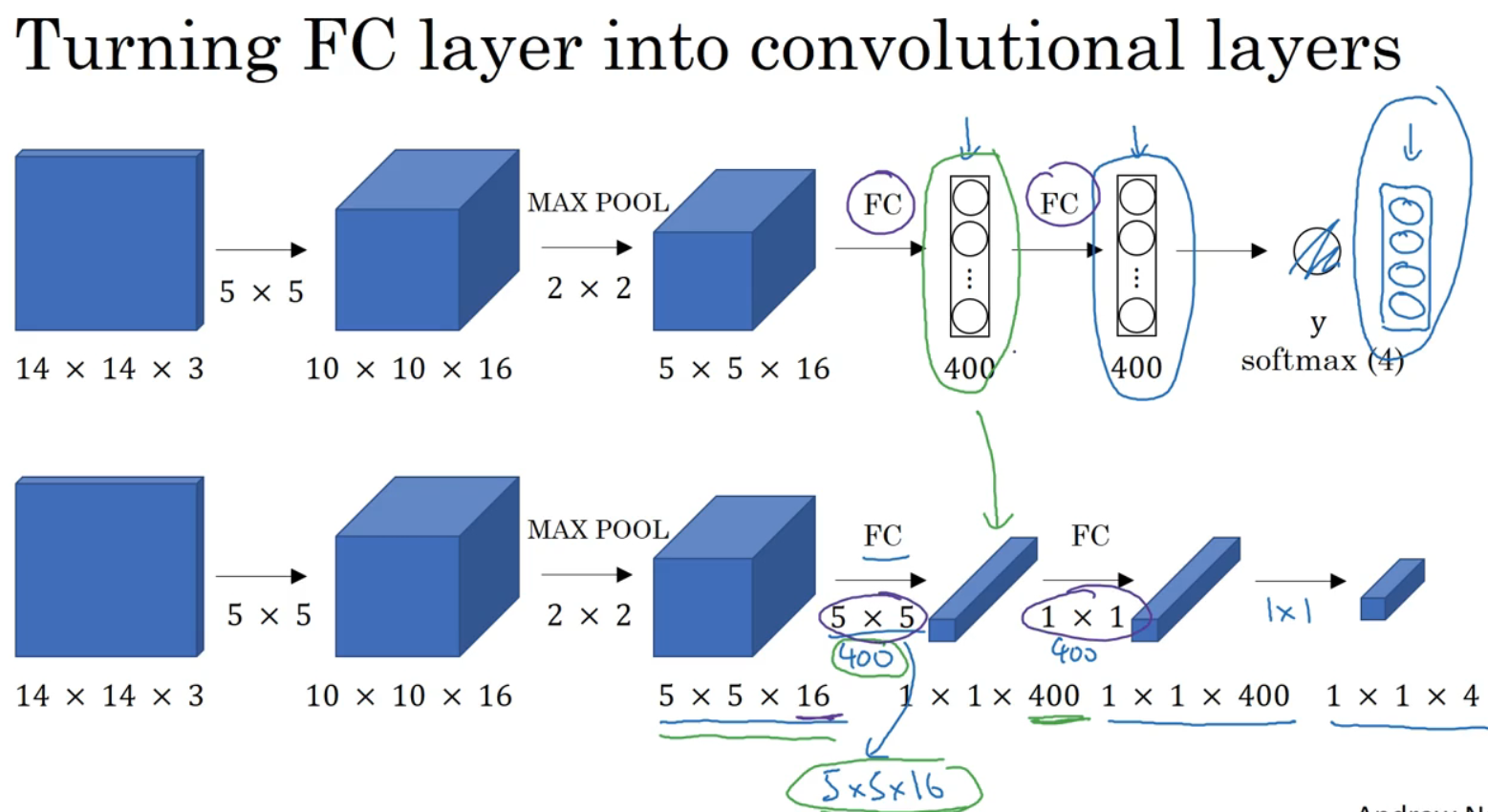
将神经网络的全连接层转换为卷积层:
可将上图FC换为5x5的过滤器,应用400个5x5x16的过滤器;
接着添加一个1x1的卷积层,输出1x1x400,
最后经由1x1的过滤器处理,得到一个softmax激活值,通过卷积网络得到1x1x4的输出层。
论文参考:[Sermanet,Pierre,et al.“OverfFeat:Integrated Recognition,Localization and Detection using Convolutional Networks.”]
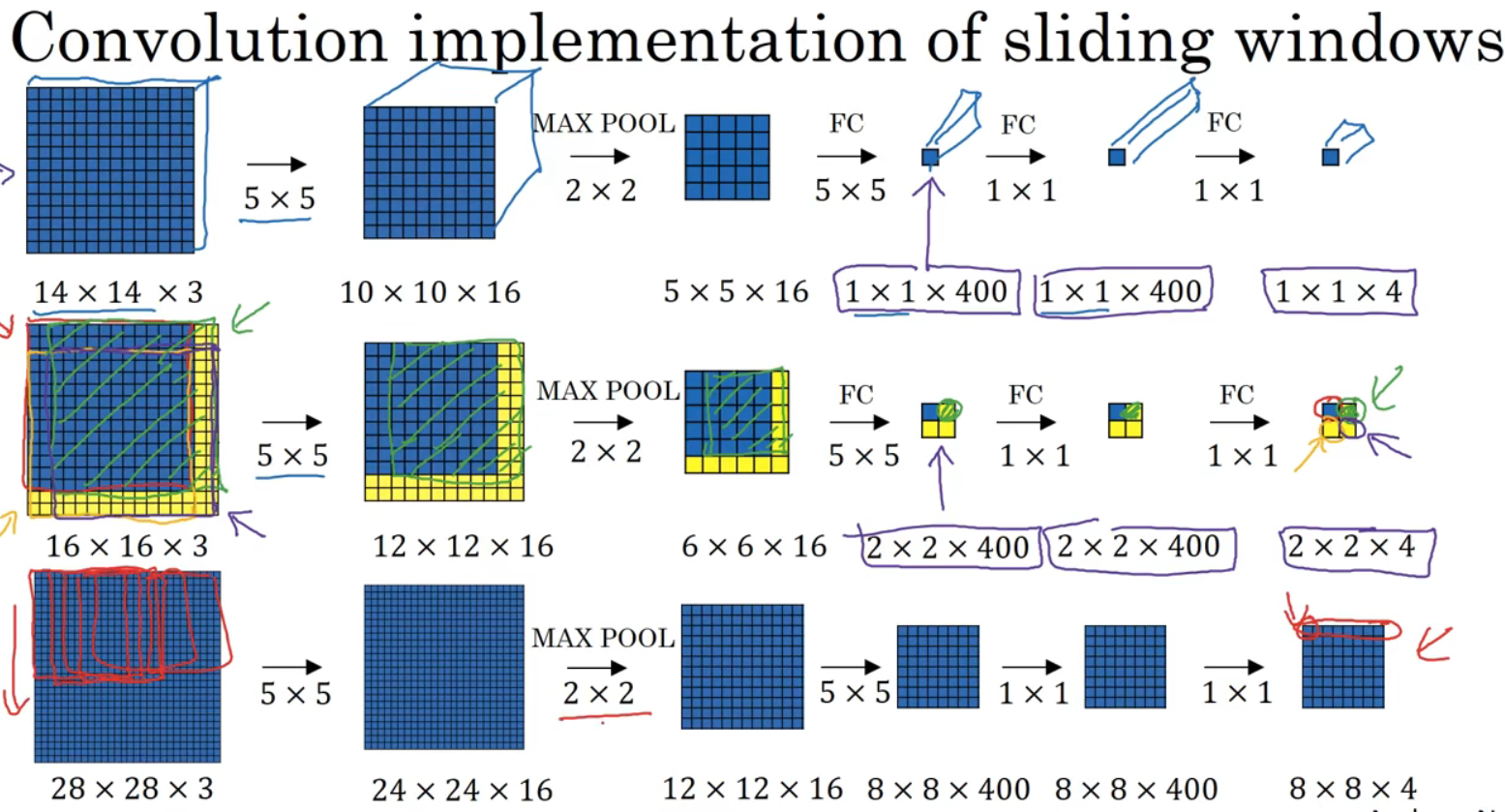
假设训练集为14x14x3,测试集为16x16x3,给输入图片加上黄色条块,在16x16x3的小图像上滑动窗口,卷积网络运行4次,于是输出了4个标签。
如图第2行,卷及操作很多计算都是重复的,最终输出为2x2x4.
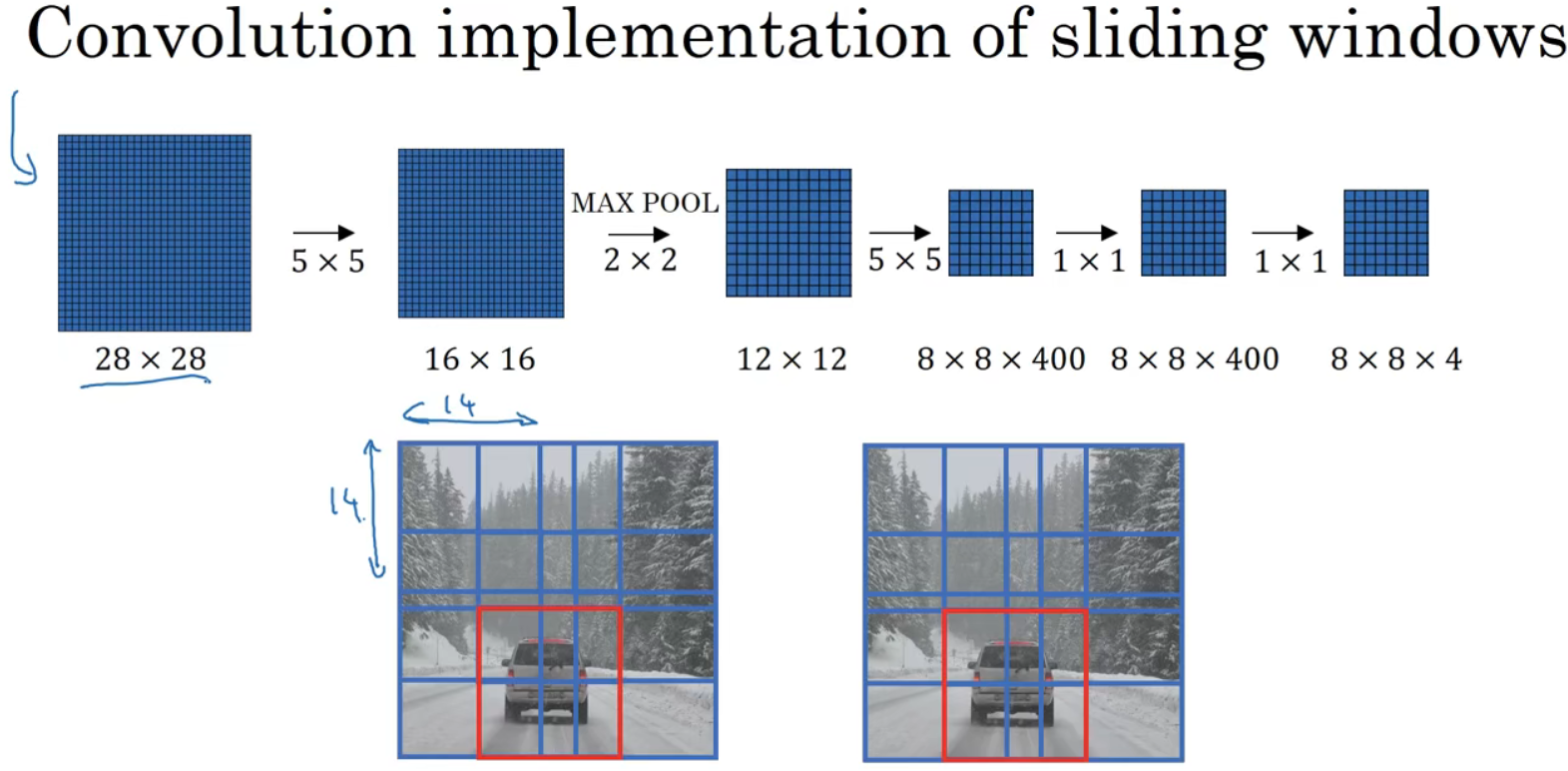
假如对28x28x3的图片应用滑动窗口操作,最终得到8x8x4的结果。
不能依靠连续的卷积操作来识别图片中的汽车。
五、Bounding Box预测(Bounding Box predictions)

如图蓝框可能是最匹配的检测框。
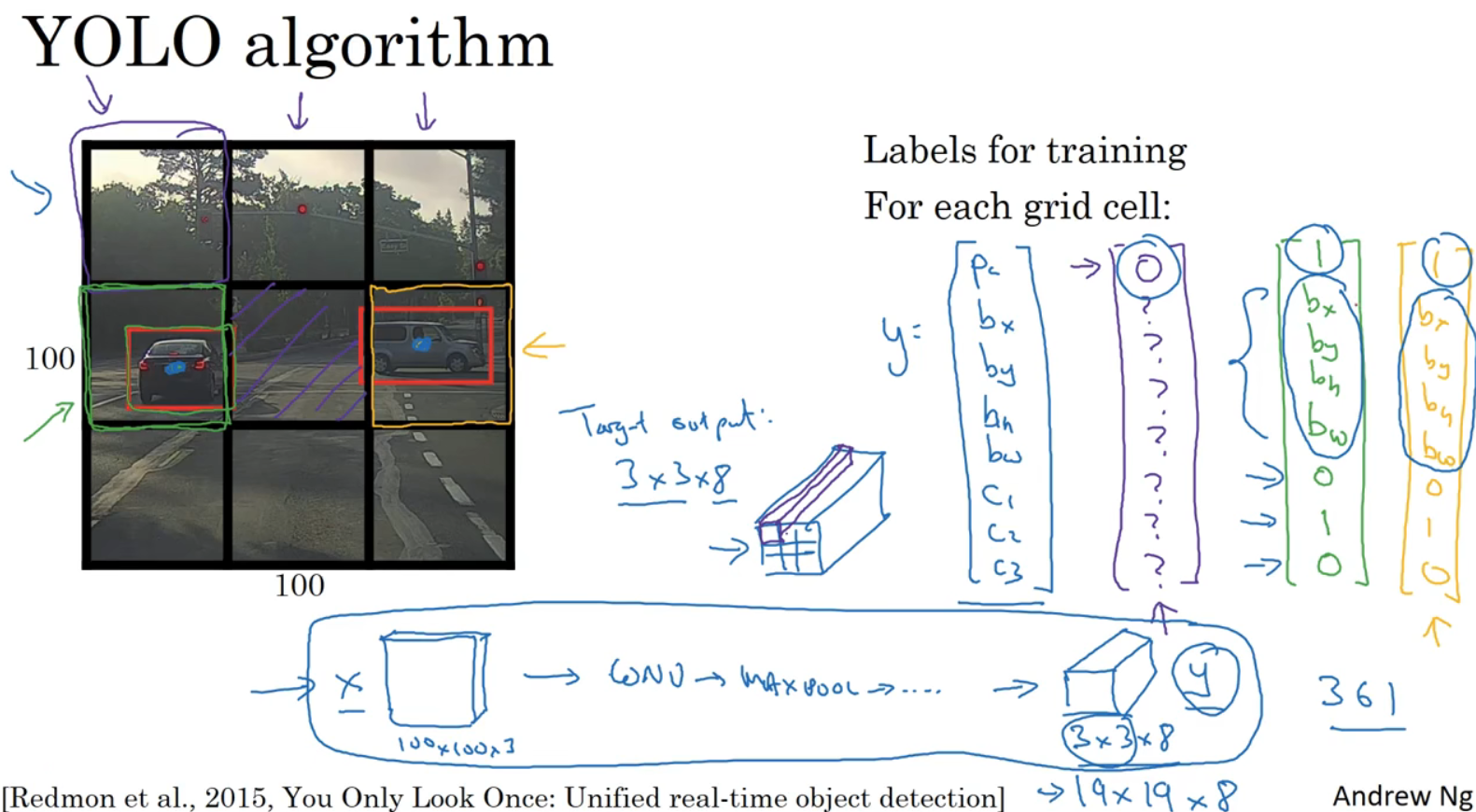
其中一个更精准边界框的算法是TOLO(you only look once)算法。在图像上放网格,如图用3x3的网格,将图像分类和定位算法应用到9个格子上。对9个框的每个框,定义训练标签为:
y
=
(
p
c
b
x
b
y
b
h
b
w
c
1
c
2
c
3
)
y=\left( \begin{array}{l} pc\\ bx\\ by\\ bh\\ bw\\ c1\\ c2\\ c3\\ \end{array} \right)
y=?
??pcbxbybhbwc1c2c3??
??
这张图片有两个对象,YOLO算法做的是,取两个对象的中点,然后将这个对象分配给包含对象中点的格子。所以虽然第5个框同时包含两个车,但我们取4和6。
因为有3x3的网格,所以总输出为3x3x8。
若训练100x100x3的神经网络,经过卷积层,最大池化等,最后得到3x3x8输出尺寸。当使用反向传播训练神经网络时,将任意输入x映射到这类输出向量y。
这个算法优点在于神经网络可以输出精确的边界框,所以测试时,做的是喂入图像x,然后跑正向传播,直到得到输出y。实践中常用19x19x8,网格精细的多,多个对象分配到同一个格子的概率就小得多。
YOLO算法有个优点就是其是个卷积实现,运行速度非常快,可以达到实时识别。
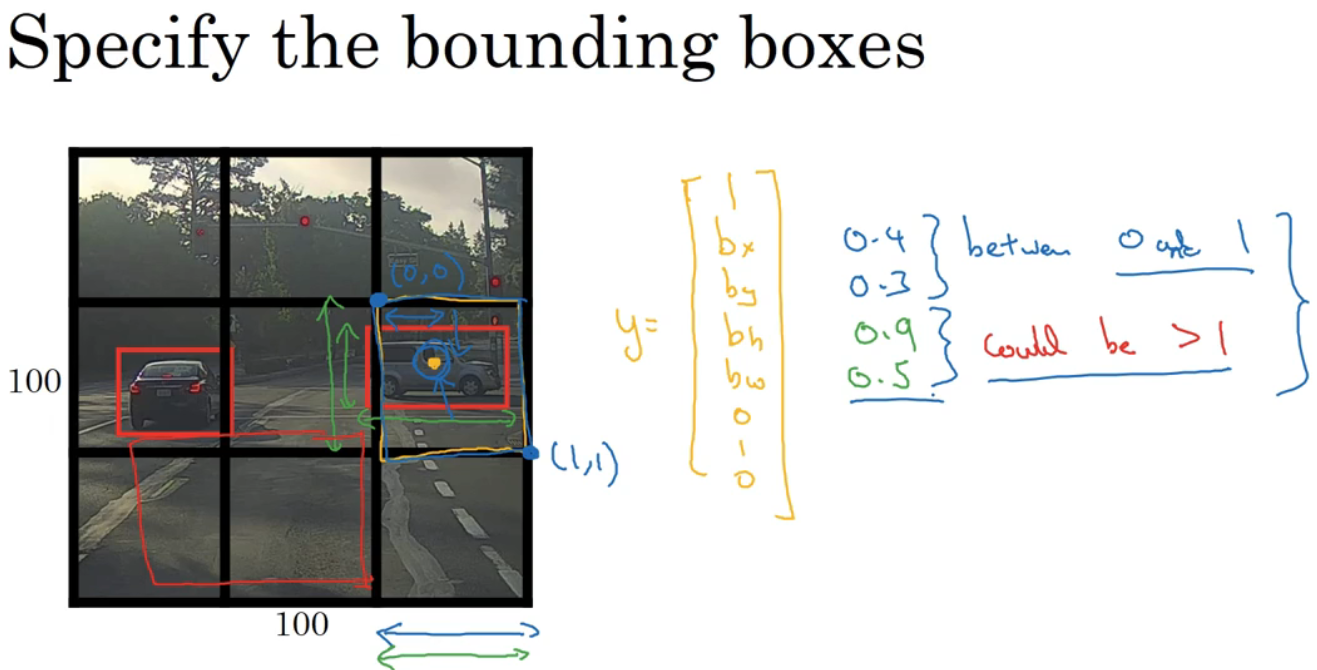
有两辆汽车,以右边车为例子,红色格子有对象,pc为1,对于其边框,左上角为(0,0),右下角为(1,1),bx大概0.4,by约为0.3,bh为0.5,bw为0.9。bx和by必须在0-1之间,bh和bw可能会大于1。
还有其他参数化方式,涉及到sigmoid函数,确保0-1之间。指数参数化确保bh和bw都是非负数。
六、交并比(Intersection over union)

给出紫色框,结果是好是坏?
交并比函数做的是计算两个边界框的交集和并集之比。IOU=(A∩B)/(A∪B)。一般约定,如果IOU大于等于0.5,就说检测正确,完美重叠则IOU为1,跟严格可以设置更高。
七、非极大值抑制(Non-max suppression)

目前所学目标检测,可能对同一个对象做出多次检测。非极大值抑制可以确保算法对每个对象只检测一次。

假设在图中检测行人和汽车,放一个19x19的网格,很多格子会认为有车。
分步介绍非极大值抑制:
在361个格子都运行一次图像检测和定位算法。首先看看每次报告每个检测结果相关的概率pc,实际是pc乘以c1、c2、c3。先看概率最高的,高亮标记。非极大值抑制会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比的,这些输出会被抑制。
然后审视剩下的矩形,接下来操作和上相似。这就是最后两个预测结果。
如图例子,只做汽车检测,会得5个参数。
1.去掉所有边界框,就将所有预测值,所有边界框pc小于等于某个阈值,比如pc小于等于0.6的边界框去掉。
2.然后就是上述的高亮展示。
八、Anchor Boxes
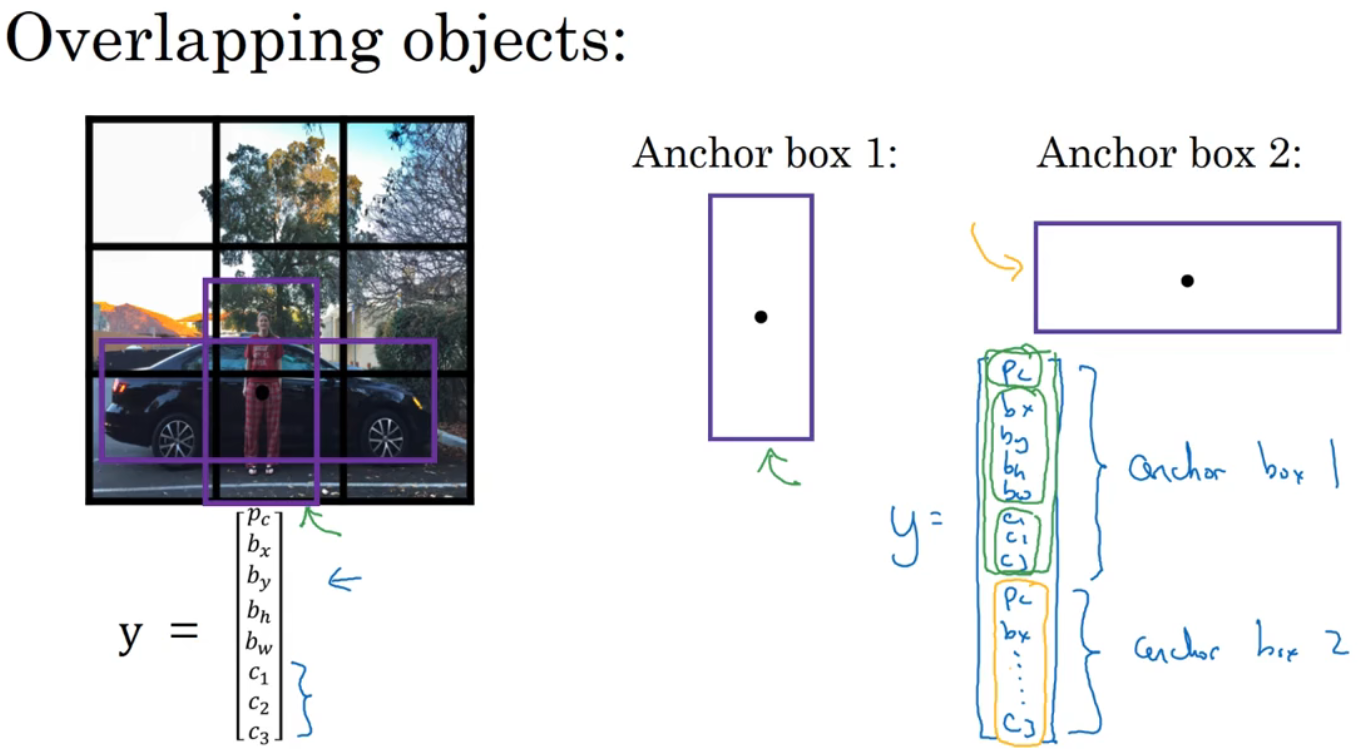
若想一个格子检测出多个对象,可用anchor box。
如图,行人中点和汽车中点几乎在同一个地方,将无法检测结果。
anchor box思想:
预先定义两个不同形状的anchor box,可以定义如图的类别标签。

1.使用anchor box之前,对于训练集图像中的每个对象,根据那个对象中点位置分配到对应的格子中。
2.训练图像中的每个对象都被分配给包含对象中点的网格单元,以及IoU最高的网格单元的锚定框。
现在有两个框,可看成是3x3x2x8。
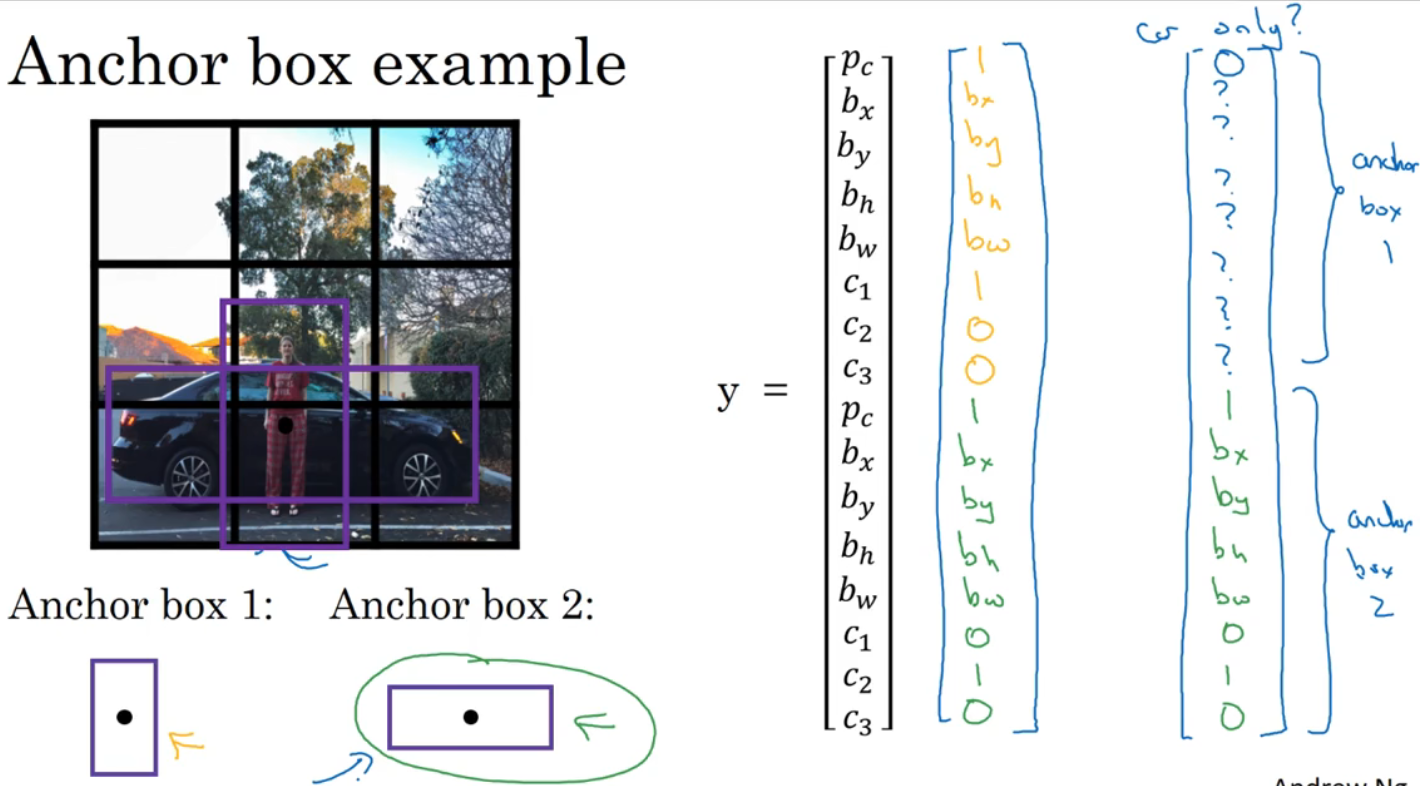
图像一网格可能有三个对象,或两个box形状一样,需引入打破僵局的手段。
YOLO后期有更好做法,即K-mean算法,可将两类对象形状聚类。
九、YOLO算法(Putting it together:YOLO algorithm)
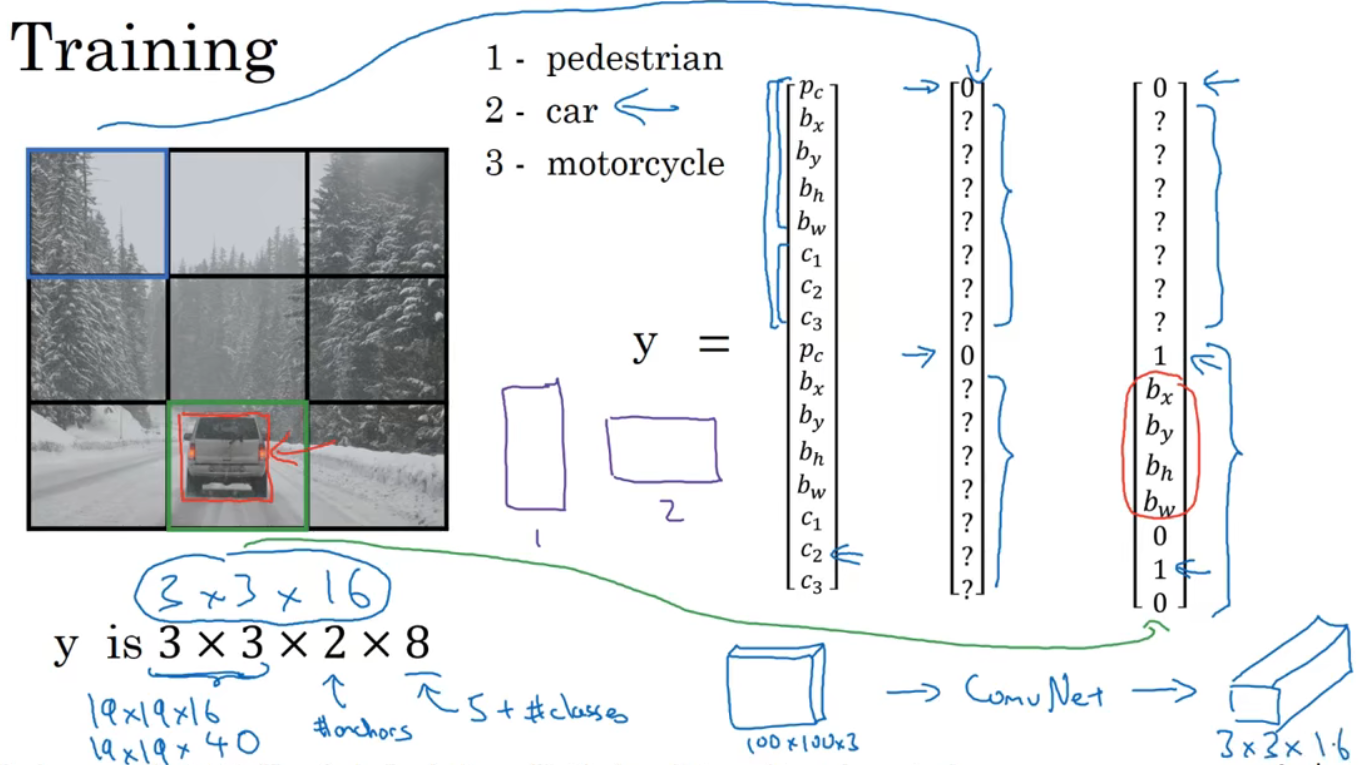
假设设计算法检测三种对象,需遍历9个格子,然后构成对应的目标向量y。
如图第8个格子有对象,红框,有两个anchor box,检测和其中一个交并比更高。
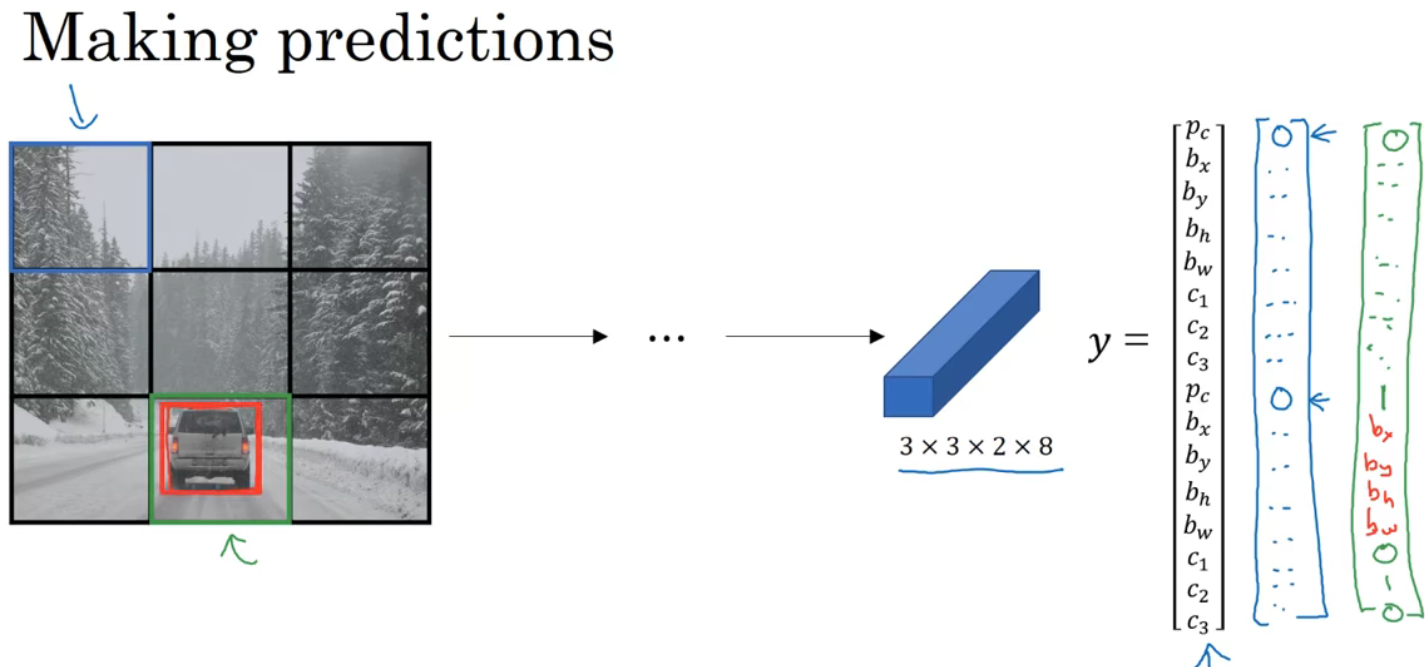

如图,首先抛弃交并比低的一个,若检测三个对象,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框。
十、(选)候选区域(Region proposals)

滑动窗口在显然没有任何对象的区域浪费时间。
本节引用了R-CNN的算法,意思是带区域的CNN,此算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,不对每个滑动窗口运行检测算法,只选一些窗口运行卷积网络分类器。
分割算法检测到色块,然后做分类。

R-CNN太缓慢;
Fast R-CNN得到候选区域的聚类步骤仍然非常缓慢;
Faster R-CNN使用卷积神经网络,而非传统的分割算法来获得候选区域色块。