TransGait: ���ڶ�ģ̬�IJ�̬ʶ���뼯��Transformer
paper��Ŀ:TransGait: Multimodal-based gait recognition with set transformer
paper��������ѧ������Applied Intelligent 2022�Ĺ���
paper��ַ:����
Abstract
��Ϊһ�ֿ��Դ�Զ��ʶ�����������,��̬��Ԥ�����˾����������ᰲȫ�ȷ������Ź㷺��Ӧ�á�Ȼ��,��̬ʶ����Ȼ��һ�������ս�Ե�����,�ڵ��͵IJ�̬ʶ���д����������⡣����,���еIJ�̬ʶ�������˵��·���Я�����³���Ժ������ڶ�,���еIJ�̬ʶ���ʱ�佨ģ�������ܳ�ֵ��������е�ʱ���ϵ,��Ҫ��̬���б��ֲ���Ҫ��˳��Լ�����ڱ�����,���������һ���µĻ��ڼ�Ӱ�����������Ķ�ģ̬��̬ʶ�������˷���Щ���⡣���������Ƶ��������������˵��·���Я������кܸߵĿ��б��Ժ�³���ԡ�����,���������һ������ʱ��ۺϲ����ļ���transformerģ��,�Ի�ü��ϼ��Ŀռ�-ʱ������������ʱ�佨ģ��������֡���е�Ӱ��,�����������ڲ�ͬ�����»�õIJ�ͬ��Ƶ��֡,���粻ͬ�Ĺۿ��Ƕȡ���CASIA-B��GREW�������������ݼ��ϵ�ʵ�����,������ķ����ṩ�����Ƚ������ܡ���CASIA-B�ϴ��Ų�ͬ�·�������һ�����ս�Ե�������,������ķ����ﵽ��85.8%��rank-1ȷ��,�����������߳��ܶ�(>4%)��
1 Introduction
��̬ʶ����һ�ֻ����˵�����ģʽ������ʶ������������ʶ����ʹ�õ�������������ʶ����Ϣ,��ָ�ơ���Ĥ���������,��̬��Ϣ���ڻ��,����α��,�����ʺ��ڳ����������ʶ����������������,��һֱ������ʶ��ͼ�����Ӿ������һ����Ծ���о�����,Ŀ�����ڹ�����ȫ�ͷ�������о��й㷺��Ӧ��ǰ�������еIJ�̬ʶ������Ǵ��˵���������ȡ��̬�������ر���������Ⱦ�������ķ�չ,���ڼ�Ӱ���еķ����ѱ��㷺�о���ʹ�á���Ӱ���еļ���ɱ���,��������Ч������һ���˵IJ�̬��Ȼ��,ʶ���ܸ����ⲿ���ص�Ӱ��ܴ�,���·���Я������[1, 2]������,�����һ�����Ƚ��ķ���MT3D[3],��CASIA-B��̬���ݼ���,�ڲ�ͬ���ӽ���,�������������µ�ȷ�ʴﵽ��96.7%[4]��Ȼ��,�ڻ��·��������,ȷ���½���81.5%��
Ϊ�˼��ٷ�װ��Я�������Բ�̬ʶ���Ӱ��,���������һ�ֽ�ϼ�Ӱ��������ͼ�Ķ�ģʽ��̬ʶ������Ӱ��������ͼ�Ӳ�ͬ�Ƕ��������ˡ���Ӱ���������������ڲ�̬�����е���۱仯,�����ḻ��������Ϣ�����,��Ӱ�IJ�̬�������к�ǿ�Ŀ��б��ԡ�Ȼ��,��Ӱ�������ܵ������·�����Ʒ�ĸ���,���Ӱ�첽̬ʶ���ȷ�ԡ����֮��,�������������������ڲ��ؽ��ڲ�̬�����еı仯�����,�����������˵��·���Я����ĸ�����Ϣ,���·��ı仯��Я�������³����[5]����ͼ1a��ʾ,���ڷ�װ��Ϣ�Ĵ���,ͬһ�����ڲ�ͬ��װ�����µļ�Ӱ�кܴ�IJ�ͬ,����ͬ��װ�����µ�������ͼ�����Ƶġ�Ȼ��,������ͼ��������Ϣ����,���������ֲ�ͬ�����ˡ���ͼ1b��ʾ,����ͬ������������,��ͬ���˵���̬��ͼ�dz�����,����Ӱȴ�����ԵIJ��졣��˵����Ӱ��������Ϣ�ǻ�����,���Խ������ȷ�������˵IJ�̬����Ӱ���зḻ�������Ϣ,���������ֲ�ͬ������,�Ӷ�������ı�ʶ�ȡ�������ͼ���·���Я����ı仯����³���ԡ����,�ڲ�̬ʶ����,������Ϣ��Ӱ�챻����,���������ڲ��졣��CASIA-B���ݼ���GREW�ϵ�ʵ�����,��Ӱ��������ͼ�Ľ�Ͽ�����߲�̬ʶ���ȷ��,����ģ̬�����DZ���ġ�
ʱ�佨ģ�Dz�̬ʶ��Ĺؼ�����֮һ,��Ϊ��̬���������˶��ġ������еķ�����,ͨ��ʹ��LSTM��3DCNN�Բ�̬����ʱ���ϵĽ�ģ��LSTM���ԶԲ�̬�����еij���ʱ���������н�ģ��Ȼ��,LSTM���ܽ��в���ѵ������һ����,3DCNNͨ����Ҫ�����IJ�����Fan����[6]ѡ�����ʱ��������Ϊ���ಽ̬��ģ�����б�ʶ�ȵ�������Ȼ��,ֻ�ж��ڵ�ʱ����Ϣ��������ȡ���ಽ̬���б������������������������˸����ʱ����Ϣ,��������������֡�Ͳ�ͬ��֡�ʿ��ܻ��������Ե��˻���������Ϊ��Щ���������˲���Ҫ��˳��Լ�������,�����ڲ�̬ʶ�����������˼���transformerģ��(STM),�Բ�ͬʱ��߶ȵ��˶�ģʽ���н�ģ������,STM�Բ�̬����Ԫ�ص�˳��û���κ�Լ��,�Ա��ܹ��ڲ�ͬ���ӽ��¶Բ�̬֮֡��Ļ������н�ģ�����,STM����Ӧ��ѧϰ��̬�����а����IJ�ͬ�˶�ģʽ,������̬���ڵĶ��ڡ����ںͳ���ʱ����Ϣ��transformer�е�ÿ����ͷע�����������������ڲ�ͬ���˶�ģʽ�ϡ����ǵ���Ҫ�����ܽ����¡�
-
���ǽ���Ӱ��������ͼ�������,�ھ�����˵��Ƚ��Ϳɱ��IJ�̬���������ǹ����˻��ڲ�λ�Ķ�ģ̬����,��Щ�����������Լ�Ӱ��������ͼ�ķָ����������϶��ɵġ���Щ��Ӧ���ض���λ�Ķ�ģ̬�������������߹����еIJ�λ���˶�������
-
���������STM,����һ�����ڲ�̬ʶ�������ʱ�佨ģģ�顣��Ӧ��һ����λ�Ķ�ģ̬�������б����뵽STM��,����ȡ����˶��������ڲ�̬ʶ���������STM�����ں��˶�ģ̬�Ӿ���Ϣ�����ڲ�����ϸ���������Ͳ�̬���е�ʱ������ԡ��������Ӿ�������ʹ�õ�transformerģ�Ͳ�ͬ,STM�������֡���е�³���Զ���������ԡ�
-
������ķ�����CASIA-B��GREW���ݼ��еı����������Ƚ��IJ�̬ʶ����
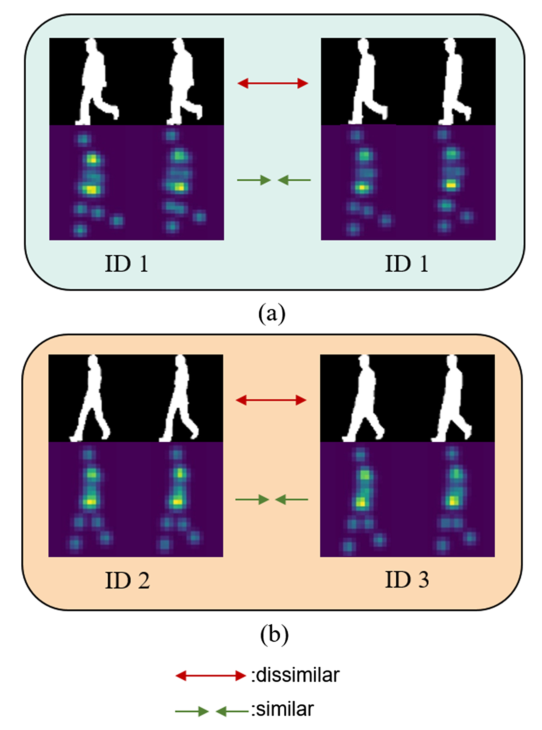
ͼ1 ��Ӱ(��)������(��)�����ӡ�(a)��ͬ��װ�����µ�ͬһ������:��Ӱ�Dz�ͬ��,��������ͼ�����Ƶġ�(b) ��ͬ������:��ͬ���˵�������ͼ�����Ƶ�,����Ӱ�Dz�ͬ�ġ�
2 Related works
2.1 Body representation in gait recognition
�������������,��̬ʶ����Է�Ϊ���ڼ�Ӱ�ķ���[3, 6-13]�ͻ������Ƶķ���[14-19]����Ӱһֱ����������õ������������Ӱ������Ч�����������ڲ�̬�ڼ����۱仯,������Ϊ��Ӱ��û�������벽̬ʶ���ص���Ϣ,����ɫ[2]��Ȼ��,�����������������˵����,���ԶԷ�װ��Я����ı仯�dz����С��������ƵIJ�̬ʶ��ͨ��������ά�Ǽ���Ϊ�����ʾ,��Ϊ��ά�Ǽܲ������ܵ��·���Я�����Ӱ�졣Ȼ��,��ά��̬���Ʒ���������������:i)������ά�Ǽܵķ���������������ؽڵľ�ȷ���,���ڵ��Ƚ�����;ii)��ά�Ǽ�ֻ������̬�ڼ�����ؽڵı仯,������ȫ��ӳ���˵IJ�̬��
������,�������ѧϰ�ķ�չ,��ά��̬�������˺ܴ�Ľ���������������Ϣ�����ಽ̬ʶ���зdz���Ҫ,��˶�ά�����DZ���ά���Ƹ����С��ɱ����͵ļ���������Feng����[20]���ô�RGBͼ������ȡ������ؽ���ͼ����ȡʱ��������Ȼ��,����ȫ���Լ�Ӱʱ,ֻʹ�����Ƶ�ʶ���ʲ����������⡣Li����[21]�������������ά�ؽڡ���ά�ؽںͼ�Ӱ�����ַ���ȡ�������Ƚ��Ľ��,����Ը��ӡ�Zhao����[22]�ֱ���ȡ�˼�Ӱ�����Ƶĵ�ģ̬��̬����,�����ǽ���Ӱ�����ƴ���������Ϊ��ģ̬�������ʾ����ȡ��ģ̬��̬���������������,���ǵ�Ŀ���ǽ����̬ʶ��Է�װ��Я�����³�������⡣���������һ��ʹ�ü�Ӱ-���������ʾ�Ķ�ģʽ��̬ʶ������Ӱ-���������ʾ�����������˵IJ�̬�仯�����Ϊȫ�档�������˵ķ�װ��Я����ı仯Ҳ���Ƚ����ڱ�����,����ѡ��2D������ͼ���������˹ؽڵı仯�����ڶ�ά��̬��ͼ������ؽڵĸ���ͼ,������ά�Ǽܶ���̬���������Ƚ���
2.2 Temporal representation in gait recognition
��̬ʶ���е�ʱ���ʾ�ɷ�Ϊ����ģ��ķ����ͻ������еķ���������ģ��ķ���ʹ��ͳ�ƺ�������̬��Ϣ�ۺϵ�һ��ͼ����,�ɷ�Ϊ���������:ʱ��ģ��;���ģ�塣ʱ��ģ�������뵽����֮ǰ�ۺ��˲�̬��Ϣ,�粽̬����ͼ��(GEI)[23]�Ͳ�̬��ͼ��(GENI)[24]������ģ���ھ�����������ͳػ�������ۺ��˲�̬��Ϣ,�������ϳػ�[9]�Ͳ�̬��������ͼ(GCEM)[25]���������еķ���ѧϰ�˲�̬�����е�ʱ���ϵ,�����ǽ�����ܡ��������еķ������Է�Ϊ��������𡣻���LSTM�ķ���[7, 25, 26],����3DCNN�ķ���[3, 27]�ͻ��������ķ���[6]��Zhang����[7]�������Ϊ��������,ÿ������ʹ��LSTMʱ��ע��ģ����ȡ��̬�Ŀռ�-ʱ��������Lin����[3]�����һ����ʱ��߶ȵ�3DCNN(MT3D)ģ��,��ģ�Ľ���3D�ػ������ۺ�ÿ���ֲ�ʱ��Ƭ�ε�ʱ����Ϣ��Fan����[6]�����һ��������ģ��(MCM),����һ����ģ����������һ��ʱ��ػ�ģ����ɡ���ģ������������ע�������ƺ�ͳ�ƺ������ۺϾֲ����ڵ�֡,��������ɾֲ���ģ�塣Ȼ��,��Щ��ģ�屻�ۺ�����,ͨ��ʱ��ػ�ģ���ò�̬���������ַ���֤�������Բ�̬ʶ������Ч�ġ�Ȼ��,�÷���ֻ����������ģʽ��û�п��������˶�ģʽ������,��ʼ�˶���δ������˶�֮��Ĺ�ϵ�Բ�̬ʶ��������ġ����,����ʹ�ü���transformerģ����ģ�����뼯���и�Ԫ��֮��������,transformer�еĶ�ͷע�����е�ÿ��ͷ����ѧϰ��̬�����еIJ�ͬ�˶�ģʽ,Ȼ����Щ�˶�ģʽ�����ۺ��������в�̬ʶ��
2.3 Transformer
Transformer�ڻ������е�����,�ر�������Ȼ���Դ���(NLP)�����б��ֳ��˳�ɫ������[28, 29]���������Ϊ�˽��RNN���ܲ���ѵ�����������Ƶ�[30]����transformer��һ����ע����ģ���һ��ǰ����������ɡ���ע����ģ��ѧϰ��ע�����������κ��������֮��Ĺ�ϵ,�ṩ�˸��õIJ����ԡ���ͷע�������ɶ����ע������ɵġ�ÿ��ͷ��ȡ��ͬģʽ����������,�������ڲ����ḻ��������Ϣ��transformer�ѱ��������������Ӿ�������,�綯��ʶ��[31, 32],��֡�ϳ�[33]��������,transformerҲ������ͼ��ռ�������ȡ[34, 35]��Dosovitskiy����[34]�״�����transformer����CNN����ͼ��ռ佨ģ��Liu����[35]�����һ�ֻ�����λ���ڷ����ķֲ�transformer�ṹ,�ýṹ���������ڸ��ֳ߶��Ͻ�ģ,����㸴�Ӷ���ͼ���С�����Թ�ϵ��Yao����[36]�ڲ�̬ʶ����ʹ�ø�transformer�����˹ؽڵĿռ��ϵ���н�ģ���ڱ�����,���ǽ�transformer���ڲ�̬ʶ���ʱ�佨ģ����Ϊһ�����粻��Ļ���ע������������ģ��,STM�������ѧϰ�;ۼ���̬�����еIJ�ͬ�˶�ģʽ��
3 Proposed method
ͼ2����������IJ�̬ʶ��ģ�͵�����ṹ������,������IJ�̬�����л�ü�Ӱ��������ͼ��Ȼ��,���DZ�������Ӧ��������ȡģ��,��ʾΪ E s E_{s} Es?�� E p E_{p} Ep?,����ȡ֡��������Ȼ��,��Ӱ����������ͼ����������,�õ���Ӱ-���ƶ�ģ̬��ܼ�������������ģ̬�Ŀ�ܼ���������ͨ��ˮƽ�ػ�(HP)ģ�鱻ˮƽ�ָ�ɲ��ּ�����������ÿ������,����ʹ��STM����ȡ��̬�����в�ͬʱ��߶ȵ��˶�ģʽ,��ͨ��ʱ��ۺϻ�ÿռ�-ʱ���ϸ�������������,��ȡ�ļ��ϼ������˶�����������ʶ�����ಽ̬��
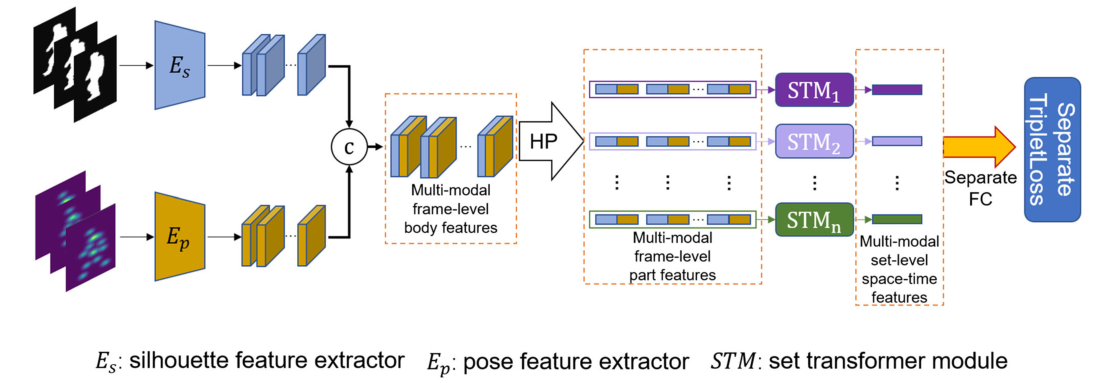
ͼ2 TransGait�������ܡ� E s E_{s} Es?�� E p E_{p} Ep?�ֱ������Ӱ������ȡ��������������ȡ��,c��ʾ���Ӳ�����HP����Horizontal Pooling,STM����set transformerģ�顣
3.1 Pipeline
�����ǽ����ݼ��������ߵ� RGB ͼ�����б�ʾΪ
{
I
i
�O
i
��
=
1
,
��
,
t
}
\left\{I_{i} \mid \underline{i}=1, \ldots, t\right\}
{Ii?�Oi?=1,��,t},����
t
t
t�������е�֡��������������Ԥѵ����̬��������(CPM)[37]�ֱ����ڴ�RGBͼ����������ȡ��Ӧ���������к�2D��̬��ͼ����,��Ϊ
{
S
i
��
�O
i
��
=
1
,
��
,
t
}
\left\{\underline{S_{i}} \mid \underline{i}=1, \ldots, t\right\}
{Si??�Oi?=1,��,t}��
{
P
i
�O
i
=
1
,
��
,
t
}
\left\{P_{i} \mid i=1, \ldots, t\right\}
{Pi?�Oi=1,��,t}��Ȼ��,����ͨ��
E
s
E_{s}
Es?��
E
p
E_{p}
Ep?��ȡ������ 2D ������ͼ���еĿռ�������
s
i
=
E
s
(
S
i
)
p
i
=
E
p
(
P
i
)
\begin{aligned} &s_{i}=E_{s}\left(S_{i}\right)\\ &p_{i}=E_{p}\left(P_{i}\right) \end{aligned}
?si?=Es?(Si?)pi?=Ep?(Pi?)?
����������ͼ
s
i
s_{i}
si?����̬����ͼ
p
i
p_{i}
pi?ƴ�ӵõ�����-��̬��ģ̬����ͼ
m
i
m_{i}
mi?,����:
m
i
=
[
s
i
,
p
i
]
m_{i}=\left[s_{i}, p_{i}\right]
mi?=[si?,pi?]
����
[
?
]
\left[\cdot\right]
[?]��ʾ���Ӳ������Զ�ģ̬������Ϊ�����ʾ����,�ֱ�������������������������˵��·���Я������и�ǿ��³���Ժ�ǿ���б�����
�����������ʶ���Ӿֲ�����������ȱ�ʾ,�����˵�ϸ�����б�����[38-40]������Щ����������,����ʹ��ˮƽ�ػ�(HP)ģ������ȡ����������б��Բ�����������ͼ 3 ��ʾ,HP ģ�齫��ģ̬����ͼ
m
i
m_{i}
mi?ˮƽ���Ϊ
n
n
n������(������ʵ����ѡ��
n
=
16
n=16
n=16)��Ȼ��,HP ģ��ͨ��ȫ��ƽ�������ػ���
m
i
m_{i}
mi?��ÿ�����ֽ����²���,����������������
m
p
j
,
i
m p_{j, i}
mpj,i?��
m
p
j
,
i
=
Avgpool
?
2
?
d
(
m
j
,
i
)
+
Maxpool
?
2
?
d
(
m
j
,
i
)
m p_{j, i}=\operatorname{Avgpool} 2 \mathrm{~d}\left(m_{j, i}\right)+\operatorname{Maxpool} 2 \mathrm{~d}\left(m_{j, i}\right)
mpj,i?=Avgpool2?d(mj,i?)+Maxpool2?d(mj,i?)
����
j
��
1
,
2
,
��
,
n
j \in 1,2, \ldots, n
j��1,2,��,n.���ǽ���ģ̬��������ת��Ϊ
n
\mathrm{n}
n����λ����������,�õ���ģ̬��λ��ʾ����
M
P
=
M P=
MP=
(
m
p
j
,
i
)
n
��
t
\left(m p_{j, i}\right)_{n \times t}
(mpj,i?)n��t?����ģ̬���ֱ�ʾ����Ķ�Ӧ��������Ϊ
M
P
j
,
?
=
M P_{j, \cdot}=
MPj,??=
{
m
p
j
,
i
�O
i
=
1
,
��
,
t
}
\left\{m p_{j, i} \mid i=1, \ldots, t\right\}
{mpj,i?�Oi=1,��,t}��Ȼ��,����MP��
j
j
j����,STM��ȡ���ϼ�ʱ������
v
j
v_{j}
vj?����ע��,STM ����Ҫ�ϸ��˳������,��ʹ�������Ҳ���Ի����ͬ�������
v j = S T M j ( M P j ) v_{j}=\mathrm{STM}_{j}\left(M P_{j}\right) vj?=STMj?(MPj?)
���,����ʹ�ü��������� FC �㽫�� STM ����ȡ����������ӳ�䵽�����ռ��Խ��в�̬ʶ��
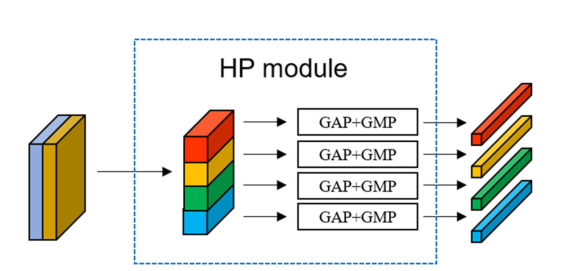
ͼ3 HP�Ľṹ(��n = 4Ϊ��)
3.2 Multi-head attention
��Ϊtransformer��һ����ɲ���,self-attention ������ʽ��ģ��������������ʵ��֮��Ľ�������ע�������ڽ���Ԫ������(��ѯ������ֵ)ʱ�����,�������ŵĵ��ִ��Ϊ
?Attention?
(
Q
,
K
,
V
)
=
softmax
?
(
Q
K
T
d
q
)
V
\text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{q}}}\right) V
?Attention?(Q,K,V)=softmax(dq??QKT?)V
����
Q
=
X
W
Q
(
W
Q
��
R
n
��
a
q
)
,
K
=
X
W
K
(
W
K
��
\mathbf{Q}=\mathbf{X} \mathbf{W}^{Q}\left(\mathbf{W}^{Q} \in \mathbb{R}^{n \times a_{q}}\right), \mathbf{K}=\mathbf{X} \mathbf{W}^{K}\left(\mathbf{W}^{K} \in\right.
Q=XWQ(WQ��Rn��aq?),K=XWK(WK��
R
n
��
d
k
)
,
V
=
X
W
V
(
W
V
��
R
n
��
d
W
)
\left.\mathbb{R}^{n \times d_{k}}\right), \mathbf{V}=\mathbf{X} \mathbf{W}^{V}\left(\mathbf{W}^{V} \in \mathbb{R}^{n \times d_{\mathbb{W}}}\right)
Rn��dk?),V=XWV(WV��Rn��dW?),
X
\mathbf{X}
X��ʾ��������Ƕ�롣
��ͷע�������������ע������,����ÿ����ע����ͷ������Ԫ��֮��Ѱ�Ҳ�ͬ�Ĺ�ϵ����ͷע����ģ�鹫ʽ����:
?MultiHead?
(
Q
,
K
,
V
)
=
?Concat?
(
head
?
1
,
��
,
?head?
h
)
W
0
\text { MultiHead }(Q, K, V)=\text { Concat }\left(\operatorname{head}_{1}, \ldots, \text { head }_{h}\right) W^{0}
?MultiHead?(Q,K,V)=?Concat?(head1?,��,?head?h?)W0
����
h
e
a
d
i
=
{head}_{i}=
headi?= Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)
(QWiQ?,KWiK?,VWiV?)
3.3 Set transformer module (STM)
�ڱ�����,��������� STM,����һ������ע������ģ��,����չ�˱�transformer���� [28] ��ѧϰ��̬������Ԫ��֮��Ľ�������ע��,����ʹ���ʺϲ�̬ʶ�������ʱ��ػ�(TP)�����������ۺ�,����������transformerʹ�õ� [cls] ��ǡ���ԭʼtransformer��ͬ����,λ��Ƕ��û�����ӵ������С����� Gaitset [9],��̬������ÿ��λ�õ�������������ͼ���ж��ص����,��˱����������ǵ�λ����Ϣ��
��ͼ 4 ��ʾ,STM ��������ģ�����:��ͷע������ (MAB)��ǰ��ģ���ʱ��ػ�ģ�顣 MAB���ö�ͷע����������ʱ��߶���Ѱ�Ҳ�̬���еIJ�ͬ�˶�ģʽ,��ʽ����:
MAB
?
(
X
)
=
?MultiHead?
(
X
W
Q
T
,
X
W
K
T
,
X
W
V
T
)
\operatorname{MAB}(X)=\text { MultiHead }\left(X W_{Q_{T}}, X W_{K_{T}}, X W_{V_{T}}\right)
MAB(X)=?MultiHead?(XWQT??,XWKT??,XWVT??)
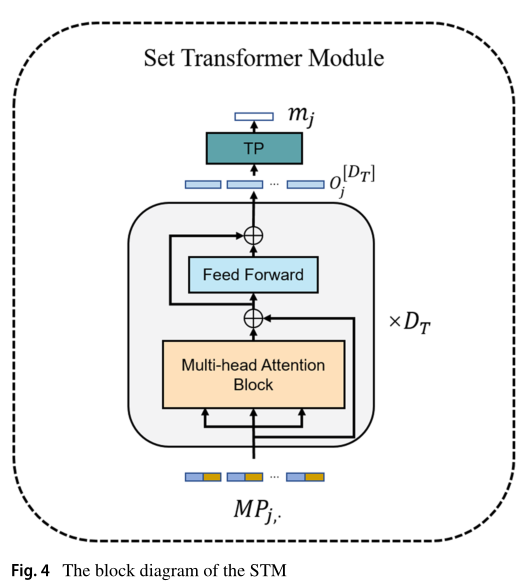
ͼ 4 STM�Ŀ�ͼ
ǰ��ģ�����һ�� MLP �� ReLU ������� temporal pooling ģ����ȡ����������б������˶���������,����
max
?
(
?
)
\max (\cdot)
max(?)���� temporal pooling ��ʵ������������transformer��ʽ����:
O
j
,
[
0
]
=
M
P
j
,
O
^
j
,
?
[
i
]
=
M
A
B
j
(
O
j
,
[
i
?
1
]
)
+
O
j
,
[
i
?
1
]
O
j
,
?
[
i
]
=
O
^
j
,
?
[
i
]
+
ReLU
?
(
f
j
��
(
O
^
j
,
?
[
i
]
)
)
v
j
=
TP
?
(
O
j
,
?
[
D
T
]
)
=
max
?
(
O
j
,
?
[
D
T
]
)
\begin{aligned} &O_{j,}^{[0]}=M P_{j}, \\ &\hat{O}_{j, \cdot}^{[i]}=M A B_{j}\left(O_{j,}^{[i-1]}\right)+O_{j,}^{[i-1]} \\ &O_{j, \cdot}^{[i]}=\hat{O}_{j, \cdot}^{[i]}+\operatorname{ReLU}\left(f_{j}^{\theta}\left(\hat{O}_{j, \cdot}^{[i]}\right)\right) \\ &v_{j}=\operatorname{TP}\left(O_{j, \cdot}^{\left[D_{T}\right]}\right)=\max \left(O_{j, \cdot}^{\left[D_{T}\right]}\right) \end{aligned}
?Oj,[0]?=MPj?,O^j,?[i]?=MABj?(Oj,[i?1]?)+Oj,[i?1]?Oj,?[i]?=O^j,?[i]?+ReLU(fj��?(O^j,?[i]?))vj?=TP(Oj,?[DT?]?)=max(Oj,?[DT?]?)?
����
f
j
��
f_{j}^{\theta}
fj��?��ʾ��Ӧ����
j
j
j��ǰ��ģ��,
��
\theta
���Dz�����
D
T
D_{T}
DT?�Ǽ���Transformer �еIJ�����
3.4 Implementation details
���糬������ E S E_{S} ES?�� E p E_{p} Ep?�ṹ��ͬ��������ͬ,����������ģ����ɡ�ÿ������ģ��������� 3 �� 3 3 \times 3 3��3�����㡢һ�����ػ��� [41] ��һ�� Leaky ReLU ��� HPģ���part number n n n����Ϊ16��STM�еIJ�������Ϊ2,heads����������Ϊ8������set transformer������,STM�����ڲ�������ȶѵ����������ȡ�������ʱ�����������ڵͲ�۲��������С��������ó����� D T D_{T} DT?�������о��ڵ� 4.4 �������ۡ�
��ʧ�Ͳ����������õ�������������(BA+)��Ԫ����ʧ[42]��ѵ�����硣��ͬ����֮���Ӧ���������������ڼ�����ʧ��������С����Ϊ ( p , k ) (\mathrm{p}, \mathrm{k}) (p,k),���� p \mathrm{p} p��ʾ����, k \mathrm{k} k��ʾ������ÿ���˵���������
���ԡ��ڲ��Խ�,gallery��probe֮��ľ��뱻����Ϊ��Ӧ����������ƽ��ŷ����¾��롣
�����

