摘要:差分私有(DP)学习在构建文本的大型深度学习模型方面取得了有限的成功,而将差分私有随机梯度下降(DP- sgd)应用于NLP任务的直接尝试导致了较大的性能下降和高计算开销。我们表明,这种性能下降可以通过(1)使用大型预训练语言模型来缓解;(2)适合DP优化的非标准超参数;(3)与预训练程序相一致的微调目标。为了解决在large Transformers上运行DP-SGD的计算挑战,我们提出了一种内存节省技术,该技术允许在DP-SGD中运行裁剪,而无需实例化模型中任何线性层的每个示例梯度。这种技术能够以几乎与非私有训练相同的内存成本。与DP优化在学习高维模型时失败的传统智慧相反(由于噪声随维缩放),经验结果表明,使用预先训练的语言模型的私人学习往往不会遭受维度依赖的性能下降。
1 introduction
当DP学习应用于大型语言模型时,通常很难产生有用的模型,导致模型要么具有没有意义的隐私保证,要么性能远低于非私有基线。核心问题是:注入的噪声必须随着参数的数量缩放,导致大型语言模型的噪声水平较大。
我们解决了构建语句分类和语言生成任务的性能DP语言模型的问题,只需使用数万到数十万个示例。为了实现这一目标,我们重新检查基线DP优化算法的性能,以微调大型语言模型,并研究在给定固定隐私预算的情况下,超参数、训练目标和预训练模型的选择如何影响性能。与主流看法相反,我们的实证结果表明,具有数亿个参数的大型预训练模型可以有效地和高效地微调,以产生在适度隐私泄漏下的高性能模型。
1)我们表明,在适当的超参数和下游任务目标下,使用DP-SGD/DP-Adam进行微调的预训练语言模型在隐私级别ε∈{3,8}的一组NLP任务中产生了强大的性能。
(2)运行DP-SGD可能是内存密集型的,因为要裁剪每个示例的梯度。我们提出了ghost clipping,一种节省内存的技术,使微调large Transformers在DP内存高效。
(3)我们发现梯度更新的维度不能解释私有微调性能。虽然私有(凸)优化存在维数依赖的下界(Bassily等人,2014),我们发现更大的预训练模型导致更好的私有微调结果。此外,降低更新维度的参数高效适应方法并不一定优于微调所有模型参数的基线方法。
我们的实证研究表明,在适度的隐私预算下,直接微调预训练的DP优化模型可以在性能良好的DP语言模型中获得结果。这使得可以为一系列可能涉及隐私的常见任务构建实用的私有NLP模型。
2 problem statement
DP学习通常依赖于DP优化器,它在执行更新之前将梯度私有化。DP优化在训练高维深度学习模型时表现不佳的原因因为较大的模型每次更新会经历更重的噪声。
通过对公共预训练模型超参数的微调,迁移到另一任务中,并且利用RDP追踪隐私损失。
语句分类。我们的目标是学习一个能将句子分类的模型。对于这些任务,每个示例/记录由输入句子和一个要预测的标签组成。我们对BERT和RoBERTa 模型进行微调。
语言生成。我们的目标是学习一个模型,它可以在一定的环境下生成自然语言句子。
对于表到文本生成任务,如E2E和DART,训练数据中的每个示例/记录由一对表条目和相应的文本描述组成。
对于对话生成任务,如Persona-Chat ,每个示例/记录由元数据、对话历史和要预测的响应组成。针对这些问题,我们微调了GPT-2 和不同大小的变体,因为这个模型家族被认为可以很好地用于文本生成。
3?EFFECTIVE?DIFFERENTIALLY?PRIVATE?FINE-TUNING
超参数的影响和微调目标的选择是决定性能的重要因素
3.1?HYPERPARAMETER?TUNING
DP优化对超参数的选择很敏感。因此,我们提出了设置最重要超参数的简单而有效的指南。
3.1.1 BATCH?SIZE, LEARNING?RATE?& TRAINING?EPOCHS
我们的实验表明,批量大小(batch size=5,循环5次之后权重进行更新)是正确设置的最重要的超参数之一,而最优批量大小与学习速率和训练轮次的相关性使其选择变得复杂。
固定的训练轮次
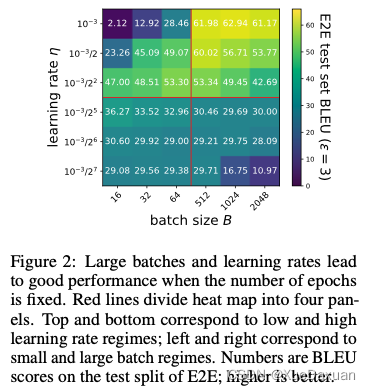
在这个固定的训练时间设置中,学习率和批大小共同影响性能,因为使用更大的批意味着执行更少的梯度更新。为了从经验上研究这种联合影响,我们在E2E数据集上微调GPT-2,以便在不同批处理大小和学习速率的情况下使用DP- Adam ε = 3生成表到文本。从图2可以看出,在大批量和大学习率的情况下,每个成形模型都能获得最佳的BLEU值~62。使用较小的学习速率和较小的批处理大小会产生相当糟糕的结果。
在非私有环境中,预训练的语言模型通常用小批量和小学习率对Adam进行微调(图2左下角)。这意味着n??vely使用非私有学习中经常使用的超参数对预训练的语言模型进行私下微调,会大大降低性能。
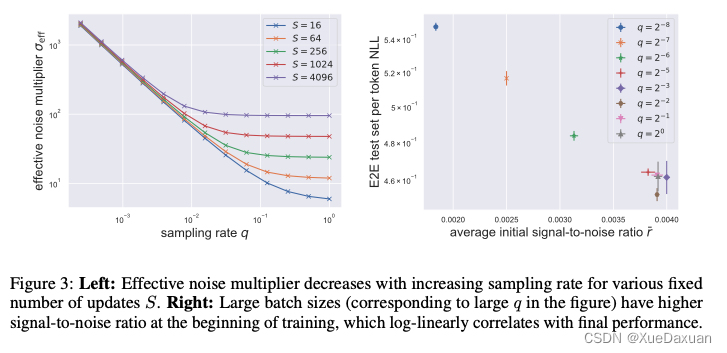
固定的更新步数S
?![]()
![]()
![]()
3.1.2 CLIPPING?NORM?
DP优化对裁剪范数的选择非常敏感。由于噪声的尺度取决于这个剪切范数,选取比实际梯度范数大得多的阈值C意味着应用了比必要更多的噪声。在整个训练过程中,一个小的剪切规范强制几乎所有的梯度都被剪切,从而导致最佳表现的模型。
3.2 IMPROVING THE TASK ALIGNMENT HELPS PRIVATE LEARNING
?在语言生成任务上的微调模型工作得很好,因为预训练目标和下游任务是一致的:两者都涉及到对符号序列的预测。这种结合简化了任务,有利于私人学习。虽然预先训练的模型在语言生成方面是自然对齐的,但在分类任务方面却远非如此。(用同一目标的预训练模型)
?4 GHOST?CLIPPING: CLIPPING WITHOUT PER-EXAMPLE GRADIENTS
DP-SGD由于对每个示例的梯度进行了裁剪,因此有很高的内存开销。这个步骤在优化过程中为每个示例实例化一个巨大的梯度向量,可能非常昂贵。提出了一个裁剪过程,每次只实例化模型中单个层参数的每个示例梯度,而不是一次性实例化整个模型。

