? ? ? ? 上一篇文章实现了使用tkinter显示动态二维码。本篇为了模拟摄像头读取动态二维码信息,使用pyautogui库,对电脑屏幕进行录屏(连续截图),然后利用OpenCV按帧读取二维码,最后重组被拆分的文件。
一、使用pyautogui库,对电脑屏幕进行录屏
? ? ? ? pyautogui库可以实现电脑屏幕的截图,经过测试,自己电脑的性能大概可以实现0.1S的截图,由于上一篇动态二维码的帧率速度0.2S每帧,由香农定理可知,截图的采样频率应两倍于0.2S每帧(快于0.1S每帧),所以pyautogui录屏性能应该是满足要求的。具体理论可以参考以下文章:
采样定理为2倍,但是为何工程上要求2.56倍采样频率进行采样?![]() https://blog.csdn.net/seekyong/article/details/104383577????????第一步,将原来拆分的29张二维码转换成GIF,方便后面测试录屏读取。
https://blog.csdn.net/seekyong/article/details/104383577????????第一步,将原来拆分的29张二维码转换成GIF,方便后面测试录屏读取。
? ? ? ? 第二步,一边打开图片播放器播放GIF图片,另一边同时运行save_qrs(_len)函数对电脑屏幕录像(连续截图),并把每帧截图存入固定文件夹。
????????编写的save_qrs(_len)函数通过输入参数_len,实现循环截图_len次,并把截取的图片保存到read_cache文件夹下面,保存图片前需要先把原来的文件夹内文件清空。主要代码如下:
import pyautogui
import os
def save_qrs(_len):
# 删除原来read_cache文件夹内的文件
for _pic_file in os.listdir("read_cache"):
os.remove("read_cache/" + _pic_file)
# 是否存在read_cache这个文件夹
if not os.path.exists("read_cache"):
os.makedirs("read_cache")
# 从0到_len截图_len次
for i in range(0,_len):
_screenshot = pyautogui.screenshot('read_cache/read_qrs_00'+str(i)+'.png')
if __name__ == '__main__':
save_qrs(100)? ? ? ? 测试时,使函数输入_len为100,循环截图100次,程序运行结果如下,截取了电脑屏幕100次,并将截取的100帧图片保存在read_cache文件夹下:
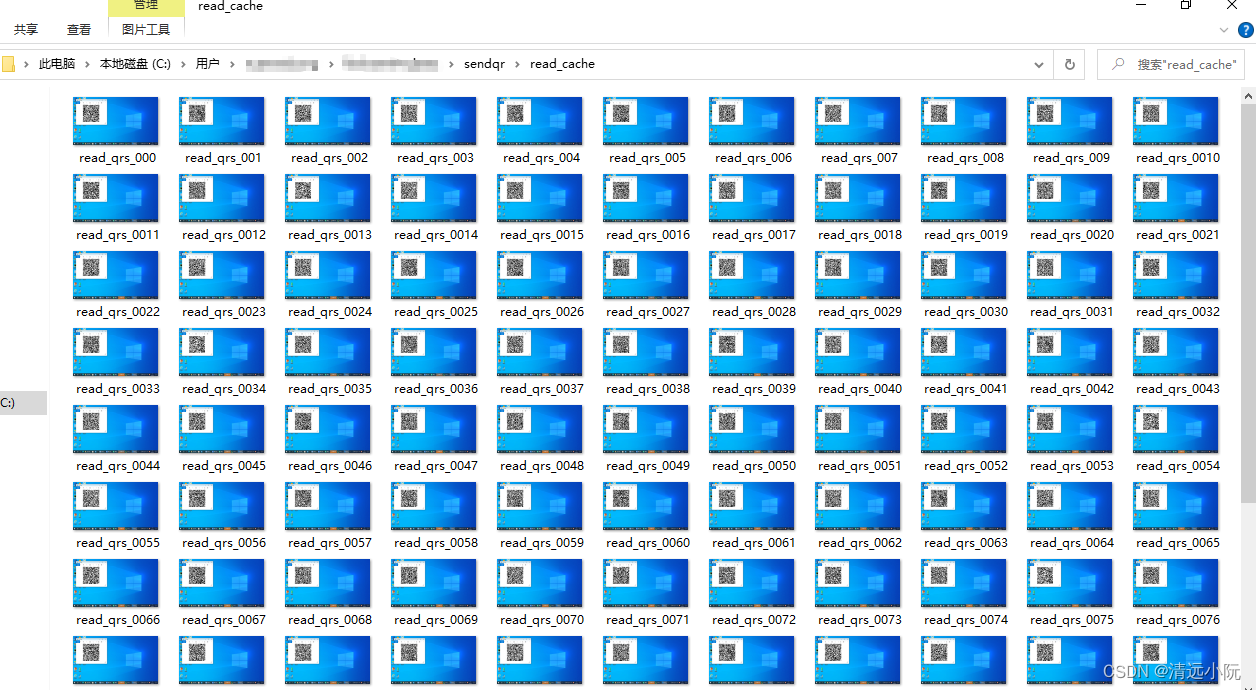
?二、使用OpenCV库对100帧截图进行识别,并与原29帧二维码图片内含信息进行比对
????????这里更新优化了第二篇文章中的verify_qr()函数,从read_cache文件中按顺序一帧一帧读取、识别当中的二维码信息,并用print(data[0].data.decode('utf-8'))输出识别结果。代码如下:
import cv2
from pyzbar import pyzbar
# 识别拆分后二维码还原并验证
def verify_qr():
#_qr_list用于存放每帧识别出来的二维码信息
_qr_list = []
for i in range(0, len(os.listdir("read_cache"))):
# 读取二维码图片
qrcode = cv2.imread("read_cache/read_qrs_00"+str(i)+".png")
# 解析二维码中的数据
data = pyzbar.decode(qrcode)
# 将每帧识别出来的二维码存放与列表中
_qr_list.append(data[0].data.decode('utf-8'))
print(data[0].data.decode('utf-8'))
# 对_qr_list列表按原顺序进行去重
_temp_list = list(set(_qr_list))
return _temp_list????????把原29帧二维码信息和当前识别的100帧图片信息一同拷贝到excel中进行比对,发现出现丢帧现象,证明pyautogui库截图的采样频率不足。
????????好在经过时间较长的100帧截图,原29帧二维码信息都采集到了。
????????Excel的比对情况如下,由于数据量太多只截取了前50帧。

三、把获取的100帧二维码信息去重,并保持原来顺序,重组成原来的文件
? ? ? ?通过上图的Excel对比,发现OpenCV并不是重[0/28]第一张二维码开始识别,而是从[10/28]第11张开始识别,所以我们获取到的列表是乱序且不连续的帧。
? ? ? ? 因此,虽然截取了100帧的二维码图片信息,我们仍需以下四个步骤才能重新组合出原来被拆分的文件。
? ? ? ? 1)去掉重复帧
? ? ? ? Python有方便且高效的列表去重方法。就是先把列表转换为不包含重复元素的set对象,然后再重新转换为list对象即可。
????????但这样去重的list并不是按原来元素顺序排列的,是一个乱序的list,主要代码如下。
# 对_qr_list列表按原顺序进行去重
_temp_list = list(set(_qr_list))
return _temp_list????????如要了解Python的列去重并保持原来顺序,可以参加以下文章:
python实现列表去重并保持原来顺序![]() https://blog.csdn.net/Dxy1239310216/article/details/123131721
https://blog.csdn.net/Dxy1239310216/article/details/123131721
? ? ? ? 2)读取去重列表中帧的序号,并按序号重新排列
????????在第二篇文章拆分文件并生成二维码信息时,程序特意在每帧二维码信息的前缀增加了[x/len]iVBORw.......格式的帧序号,x代表当前帧原来的顺序,len代表总数据长度,如下图:

?????????由于采样频率不足,且帧开始位置不确定,导致去重后的帧是乱序的。
????????因此需要先提取[x/len]iVBORw.......中的x,并根据x重新排序。
????????这里使用Python的.split()方法提取[x/len]iVBORw.......中的x,主要代码如下:
# 从[1/28]分离出1,用于重组排序
_str1 = _str.split(']')
_str2 = _str1[0].split('/')
_str3 = _str2[0].split('[')? ? ? ? 提取x后,使用Python列表的.sort(key=lambda x:x)方法,根据lambda公式结果进行排序,主要代码如下:
# 列表排序函数
def comp(_str):
# 从[1/28]分离出1,用于重组排序
_str1 = _str.split(']')
_str2 = _str1[0].split('/')
_str3 = _str2[0].split('[')
# 返回整型序号用于list.sort(key=)排序
return int(_str3[1])
if __name__ == '__main__':
_list = verify_qr()
# 根据lambda公式对列表进行排序
_list.sort(key=lambda x: comp(x))? ? ? ? ?3)把二维码信息重新组合,并用base64进行解码
????????经过.sort()排序后,二维码信息已重新按序号排列好,现通过遍历列表把二维码信息串联起来。
? ? ? ? 由于原二维码信息经过base64编码,因此需把串联后的二维码信息使用base64.b64decode()进行base64解码,即可还原最初的字节。主要代码如下:
if __name__ == '__main__':
# 使用OpenCV库截图,使函数输入_len为100,循环截图100次
# save_qrs(100)
_list = verify_qr()
# 根据lambda公式对列表进行排序
_list.sort(key=lambda x: comp(x))
_regroup_str = ""
# 遍历_list列表串联二维码信息
for _list_item in _list:
_regroup_str = _regroup_str+_list_item.split(']')[1]
print("重组的二维码信息【解码前】",_regroup_str)
# 使用base64格式对_uini_str进行解码
_regroup_str_b64decode = base64.b64decode(_regroup_str)
print("重组的二维码信息【解码后】",_regroup_str_b64decode)????????输出结果如下:

??????????4)把解码字节以二进制方式写入文件
? ? ? ? 有了解码后完整的字节数据,现只需使用Python的二进制模式把信息写入文件并保存即可,这里把文件另存为_regroup_pic001.png,主要代码如下:
if __name__ == '__main__':
# 使用OpenCV库截图,使函数输入_len为100,循环截图100次
# save_qrs(100)
_list = verify_qr()
# 根据lambda公式对列表进行排序
_list.sort(key=lambda x: comp(x))
_regroup_str = ""
# 遍历_list列表串联二维码信息
for _list_item in _list:
_regroup_str = _regroup_str+_list_item.split(']')[1]
print("重组的二维码信息【解码前】",_regroup_str)
# 使用base64格式对_uini_str进行解码
_regroup_str_b64decode = base64.b64decode(_regroup_str)
print("重组的二维码信息【解码后】",_regroup_str_b64decode)
# 使用二进制方式把重组的信息写入文件,并另存为_regroup_pic001.png
with open('_regroup_pic001.png', 'wb') as f:
f.write(_regroup_str_b64decode)
f.close()? ? ? ? 运行程序,文件夹中出现了_regroup_pic001.png文件,打开该png图片文件,得到了原来拆分的图片,如下图:
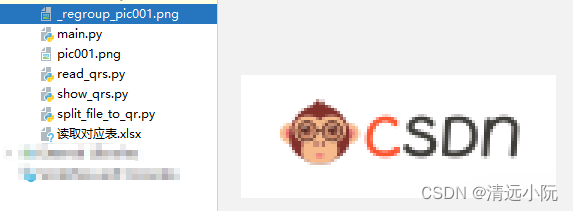
?四、小结和完整代码
? ? ? ? 到此,使用动态二维码传输文件的理论验证工作已经完成了,在不考虑性能的情况下,文件确实可以通过动态二维码进行传输。
????????后续将对程序的关键环节进行优化,一是提高二维码拆分效率、二是要提高采样频率、三是要提高传输性能、四是要优化人机交互。
????????完整代码如下:
import pyautogui
import os
import base64
import cv2
from pyzbar import pyzbar
# 使用OpenCV库,截图_len次
def save_qrs(_len):
# 删除原来read_cache文件夹内的文件
for _pic_file in os.listdir("read_cache"):
os.remove("read_cache/" + _pic_file)
# 是否存在read_cache这个文件夹
if not os.path.exists("read_cache"):
os.makedirs("read_cache")
# 从0到_len截图_len次
for i in range(0, _len):
_screenshot = pyautogui.screenshot('read_cache/read_qrs_00' + str(i) + '.png')
# 识别拆分后二维码还原并验证
def verify_qr():
# _qr_list用于存放每帧识别出来的二维码信息
_qr_list = []
for i in range(0, len(os.listdir("read_cache"))):
# 读取二维码图片
qrcode = cv2.imread("read_cache/read_qrs_00" + str(i) + ".png")
# 解析二维码中的数据
data = pyzbar.decode(qrcode)
# 将每帧识别出来的二维码存放与列表中
_qr_list.append(data[0].data.decode('utf-8'))
# print(data[0].data.decode('utf-8'))
# 对_qr_list列表按原顺序进行去重
_temp_list = list(set(_qr_list))
return _temp_list
# 列表排序函数
def comp(_str):
# 从[1/28]分离出1,用于重组排序
_str1 = _str.split(']')
_str2 = _str1[0].split('/')
_str3 = _str2[0].split('[')
# 返回整型序号用于list.sort(key=)排序
return int(_str3[1])
if __name__ == '__main__':
# 使用OpenCV库截图,使函数输入_len为100,循环截图100次
# save_qrs(100)
_list = verify_qr()
# 根据lambda公式对列表进行排序
_list.sort(key=lambda x: comp(x))
_regroup_str = ""
# 遍历_list列表串联二维码信息
for _list_item in _list:
_regroup_str = _regroup_str + _list_item.split(']')[1]
print("重组的二维码信息【解码前】", _regroup_str)
# 使用base64格式对_uini_str进行解码
_regroup_str_b64decode = base64.b64decode(_regroup_str)
print("重组的二维码信息【解码后】", _regroup_str_b64decode)
# 使用二进制方式把重组的信息写入文件,并另存为_regroup_pic001.png
with open('_regroup_pic001.png', 'wb') as f:
f.write(_regroup_str_b64decode)
f.close()