昨天有个朋友问我:"你了解图神经网络么?",想了半天,不知从何说起.这半年,读了一些相关论文,TransR,TransE,GNN,GCN,GIN,还有一些综述性的.好像大概能说明白,它是怎么做的,但又不能完全说明白它是干啥的,进而扩展到自然语言模型,知识图谱,你说它们是干啥的?在网上一搜,出来的往往是具体实现方法(how),而具体干啥讲得很抽象(what).
试试说说我的理解,也不一定对:从根本上看,它们都是知识表示,文本向量化.通俗地讲就是把文本编码成一串数,文本可能是一个字("生"),一个词("苹果"),一个短语("你说呢")或者一个句子("我是一个句子")… 让文字可以量化,比较,计算.
比如:提到自然语言模型,可能首先想到的是 BERT,GTP,它可以用来做阅读理解,完型填空,判断对错,续写文章等等.模型将一段文字转换成一串数,再传入下游任务(比如:阅读理解),参与决策具体问题.而 BERT 类模型解决的问题是某个字(比如"生")在不同上下文环境下到底是什么意思?然后把它在这里的意思转换成一串数.
再如:知识图谱,一度困惑它是干啥的?把文献或者网站上的大段文字通过命名识体识别,知识抽取等技术切成小的单元,获取它们之间的关系,放在三元组的结构里,存在图数据库中.可以通过这些小文本之间的关系从一个词"联想"到另一个词,做一些推荐的工具,然后呢?怎么利用它参与决策?
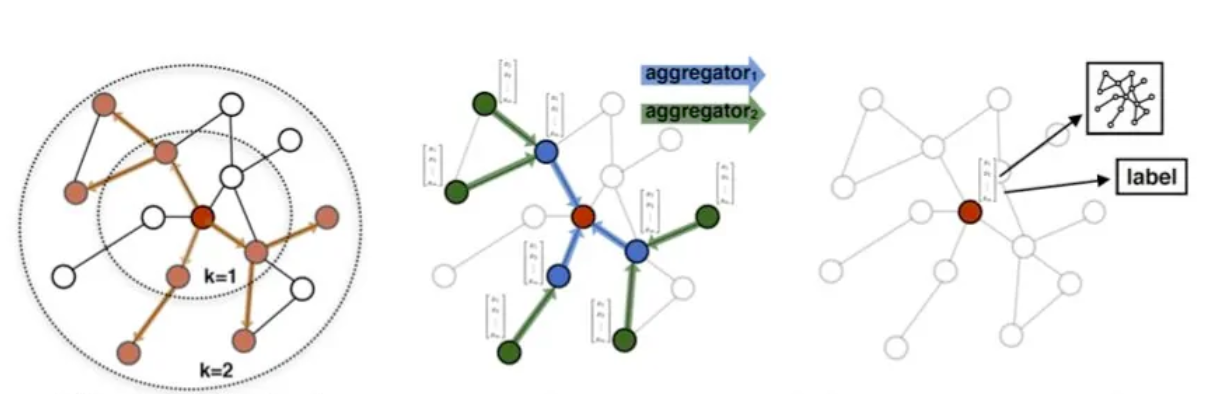
这就引出了图神经网络GNN,如同BERT通过对海量数据中上下文的学习来计算每个词的含义,GNN利用图中实体(简单理解实体就是词)之间的关系,也是通过海量数据,计算实体的含义,并且用向量表示出来.同样也是送入下游任务,参与进一步决策.
图神经网络的算法原理很简单,假设我是一个实体(比如:词),利用我的邻居来算我(红色),我的邻居(蓝色)又根据它的邻居计算(这其中也包括我),经过数次反复迭代,直到表示我们的向量逐渐趋于稳定(不再因为迭代而变化),此时就认为找到了合适的编码.比较推荐之前写的论文阅读_GCN,把邻接矩阵,度矩阵,拉普拉斯矩阵这些基本概念介绍了一下.
进而又演生出结合上下文(比如BERT)和知识图(比如GNN)的模型,如ERNIE-THU.
归根结底,它们都是知识的表示,用一串数代表某种概念.不限于自然语言处理,图神经网络还可以描述蛋白质分子结构,社群中的人际关系等等.而GIN,GCN,GNN这些方法则是具体实现的技术.
这串数即向量,形如: [8,66,993,32,5…],每一个维度(其中的每个数)可能描述某种更加抽象的概念(比如:大小,形状,情绪…),又或者几个数共同表示一个概念,这里"苹果"和"桃"的数值差异很小,因为它们的含义相近,"爱"和"恨"距离也很近,因为它们同为情绪,而"爱"和"积木"则距离很远;"生"在与不同上下文的组合中可能被转换成完全不同的向量…
这些数并没有什么实质的意义,同一个词送入BERT编码成这样的向量,送入GPT编码成那样的向量,GNN编码又完全不同… 但是,如果是好的编码器,"苹果"和"桃"的距离就会很近.和世界上所有的概念一样,这里没有绝对的正确,但有相对的"差不多".