1. ���ѧϰ��ʵ�ò���
1.1 ѵ�������������Լ�
1.1.1 ����
(1)ѵ����:����ѵ��ģ��;
(2)��֤��:ͨ����֤��ѡ����õ�ģ��,ȷ������ģ��;
(3)���Լ�:��������Ч����
1.1.2 ���ֱ���
| ���ݹ�ģ | ѵ���� | ��֤�� | ���Լ� |
|---|---|---|---|
| ������(10-10000) | 70% | - | 30% |
| 60% | 20% | 20% | |
| 100�� | 98% | 1% | 1% |
| >100�� | 99.5% | 2.5% | 2.5% |
ע:ȷ����֤���Ͳ��Լ�����ͬһ�ֲ�
1.2 ƫ��ͷ���
1.2.1 ����
����: ��Ԥ��ֵ������һ��ָ��;
ƫ��: ��Ԥ��ֵ����ʵֵ��һ��ָ�ꡣ
1.2.2 ʾ��
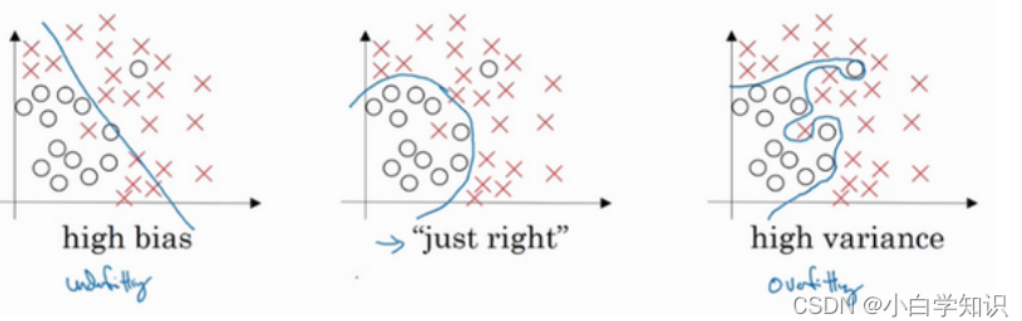
1.2.3 ��ƫ���߷���Ĵ������

1.4 ����
1.4.1 ��������
���ѧϰ���ܴ��ڹ�������⡪���߷���,�������������,һ��������,��һ���������������,���Ƿdz��ɿ��ķ���,���������ʱʱ�̿����㹻���ѵ�����ݻ���ȡ�������ݵijɱ��ܸ�,������ͨ�������ڱ������ϻ�������������
1.4.2 L 2 L2 L2 ����
J
(
w
,
b
)
=
1
2
��
i
=
1
m
L
(
y
^
i
,
y
i
)
+
��
2
m
�O
�O
w
�O
�O
2
2
J(w, b) = {1\over2} \sum_{i=1}^m L(\hat{y}^{i}, y^{i}) + {\lambda \over{2m}} ||w||^2_2
J(w,b)=21?i=1��m?L(y^?i,yi)+2m��?�O�Ow�O�O22?
����:
��
\lambda
�� :������,ͨ��ʹ����֤���������������
�O
�O
w
�O
�O
2
2
||w||^2_2
�O�Ow�O�O22? :ŷ����÷���(2����)��ƽ��,����:
�O
�O
w
�O
�O
2
2
=
��
n
j
=
1
w
j
2
=
w
T
w
||w||^2_2= \underset{j=1}{\overset{n}{\sum}} w^2_j=w^Tw
�O�Ow�O�O22?=j=1��n??wj2?=wTw
1.5 Ϊʲô�����Լ��ٹ����
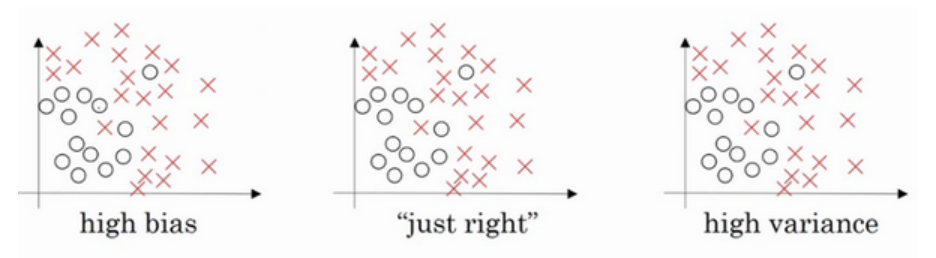
��ͼ�Ǹ�ƫ��,��ͼ�Ǹ߷���,�м���Just Right��
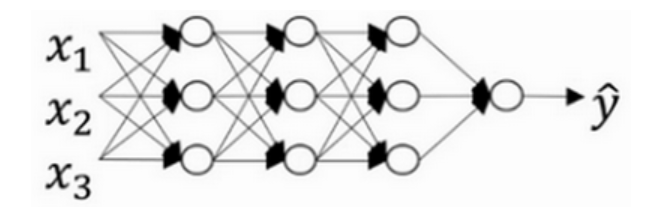
����������������Ӵ�������������硣��֪������ͼ������,���Ҳ����,���������������һ������ϵ������硣
ֱ������������������ �� \lambda�� ���õ��㹻��,Ȩ�ؾ��� w ww ������Ϊ�ӽ���0��ֵ,ֱ��������ǰѶ����ص�Ԫ��Ȩ����Ϊ0,���ǻ�������������Щ���ص�Ԫ������Ӱ�졣������������,����������˵����������һ����С������,С����ͬһ�����ع鵥Ԫ,�������ȴ�ܴ�,����ʹ�������ӹ�����ϵ�״̬���ӽ���ͼ�ĸ�ƫ��״̬��
���� �� \lambda �� �����һ���м�ֵ,���ǻ���һ���ӽ���Just Right�����м�״̬��
ֱ���������
��
\lambda
�� ���ӵ��㹻��,
w
w
w ��ӽ���0,ʵ�����Dz��ᷢ�����������,���dz������������ټ����������ص�Ԫ��Ӱ��,�������������ø���,���������Խ��Խ�ӽ����ع�,����ֱ������Ϊ�������ص�Ԫ����ȫ������,��ʵ��Ȼ,ʵ�����Ǹ���������������ص�Ԫ��Ȼ����,�������ǵ�Ӱ���ø�С�ˡ��������ø�����,ò���������������������, ����Ҳ�ȷ�����ֱ�������Ƿ�����,�����ڱ����ִ������ʱ,��ʵ�ʿ���һЩ������ٵĽ����
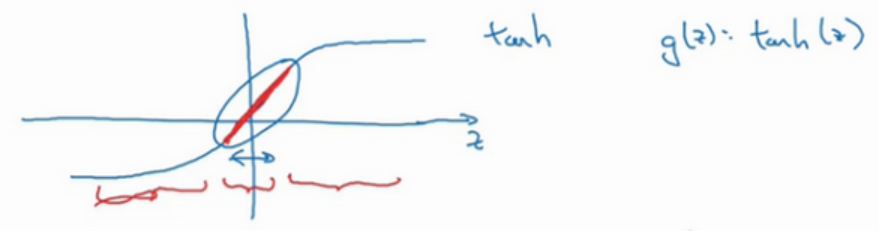
�ܽ�һ��,�����������úܴ�,����
w
w
w ��С,
z
z
z Ҳ����Ա�С,��ʱ����
b
b
b ��Ӱ��,
z
z
z ����Ա�С,ʵ����,
z
z
z ��ȡֵ��Χ��С,��������,Ҳ�������ߺ���
t
a
n
h
tanh
tanh����Գ�����,�������������������Ժ�������ֵ,������Ժ����dz���,������һ�������ӵĸ߶ȷ����Ժ���,���ᷢ������ϡ�
1.6 Dropout(���ʧ��)����
1.6.1 Dropout������
����ģ�����
1.6.2 DropoutΪʲô���Է�ֹ�����?
��Ϊ��ʹ��ģ�����ʧ��һЩ�ڵ�,��ģ�ͱ�ø��Ӽ� ������˼��һ��,���˼����Խ��,˼����Խ��,������Խȷ������ģ�����,����ϣ��ģ�ͽ����Ҫ��ôȷ������,����ģ�ͽڵ�,������˼���ĸ���,��������Ľ���Ͳ���ôȷ��
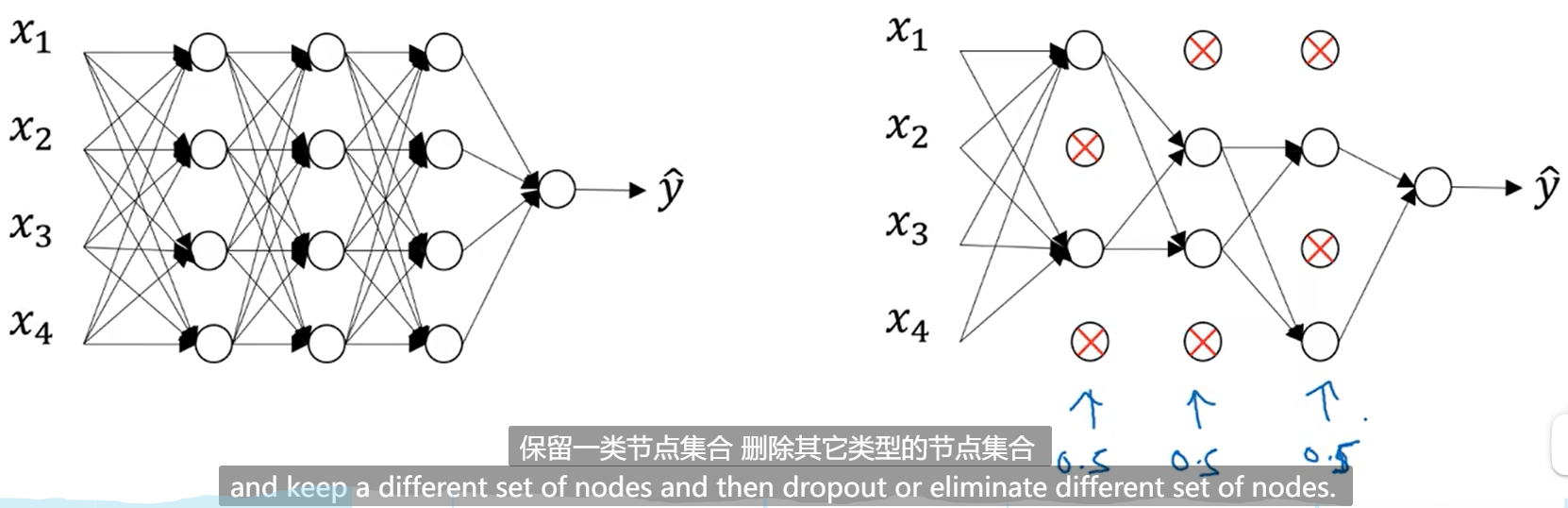
Step1: ��ÿ���ڵ�����һ�����ʧ��ĸ���p;
Step2: ģ������ʱ,�������һ��ʧ�����q;
Step3: ��� q < p, �ͽ��Ľڵ�ʧ��; ��֮,����ԭ����
1.9 ��һ������
����: ��������ѵ����
1.10 �ݶ���ʧ���ݶȱ�ը
�ݶ���ʧ: ����ʱ,������÷dz�С;
�ݶȱ�ը: ����ʱ,��ʦ��÷dz���
1.11 �������Ȩ�س�ʼ��
����: �����ڽ���ݶ���ʧ���ݶȱ�ը��
��ʼ��:
һ����˵,Ȩ�س�ʼ��������õļ�����й�,���±�:
| ����� | Ȩ�س�ʼ�� |
|---|---|
| Relu | W [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ? n p . s q r t ( 2 n [ l ? 1 ] ) W^{[l]}=np.random.randn(shape)*np.sqrt({2\over{n^{[l-1]}}}) W[l]=np.random.randn(shape)?np.sqrt(n[l?1]2?) |
| Tanh | W [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ? n p . s q r t ( 1 n [ l ? 1 ] ) W^{[l]}=np.random.randn(shape)*np.sqrt({1\over{n^{[l-1]}}}) W[l]=np.random.randn(shape)?np.sqrt(n[l?1]1?) |
����:
(1)shape��ʾ�������ݵ�shape;
(2)
n
[
l
?
1
]
n^{[l-1]}
n[l?1] ��ʾ�������ݵ�ά�ȡ�
����ͼ:
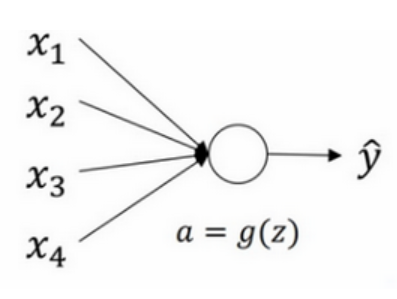
(1)shape = (1, 4);
(2)
n
[
l
?
1
]
n^{[l-1]}
n[l?1] =
n
[
1
?
1
]
n^{[1-1]}
n[1?1] =
n
[
0
]
n^{[0]}
n[0] = 4