��ǰ�������ķ���,�м��DZ���+����+��������+ʵ�����,��������еIJ���רҵ���ʽ���(ˮƽ�߷ֿ�,��������,���ַ�����ܲ�̫ȷ)
ժҪ:
????????֪ʶ����(KD)��Ŀ�����о���ǿ���ѧϰ����ģ�͵�������������KDĿ���ⷽ����������ģ��ģ�������ڵ��������,������ģ�·���logit,��Ϊ������ȡ��λ��Ϣ����Ч�ʵ���,���ҸĽ���С������ͨ����֪ʶ���������±���,�ڶ�λ������,���������һ���µĶ�λ��ȡ����,������Ч�ؽ���λ֪ʶ�ӽ�ʦ���ݸ�ѧ��������,���ǻ������Ե��������м�ֵ�Ķ�λ����ĸ���,��������ѡ�����ȡ�ض����������Ͷ�λ֪ʶ���״ν�������������������,����֤����logitģ����������ģ��,��������ȡĿ������ʱ,��λ֪ʶ��ȡ������֪ʶ����Ҫ������Ч�����ǵ���������Ч,���Ժ�����Ӧ���ڲ�ͬ�ij�������̽������ʵ�����,��COCO����,���ǵ�LD�����ڲ����������ٶȵ������,ͨ�����߶�1��ѵ���ƻ���GFocal-ResNet-50��AP������40.1��ߵ�42.1��
1.����
????????��λ��Ŀ�����е�һ���������⡣�߽�лع�������Ϊֹ�����е�Ŀ���ⶨλ����,����Dirac delta�ֲ���ʾֱ�������ж��ꡣȻ��,������ı�Ե���ܿɿ���λʱ,��λģ����Ȼ��һ�����������⡣����,��ͼ1��ʾ,�������±�Ե�͡����˰塱���ұ�Ե��λ����ȷ����������̽������˵,��������Ϊ���ء�������һ�����һ�ַ�����֪ʶ��ȡ(KD),��Ϊһ��ģ��ѹ������,���ѱ��㷺��֤,����ͨ��������ͽ�ʦ���粶��Ĺ���֪ʶ�����С��ѧ����������ܡ�

ͼ1????????�������±�Ե�͡����˰塱���ұ�Ե����ȷ
????????����Ŀ�����е�֪ʶ����,��ǰ�Ĺ���ָ��,ԭʼ��logitģ����༼��Ч�ʵ���,��Ϊ��ֻ��������֪ʶ(������),�������˾ֲ�֪ʶ��ȡ����Ҫ�ԡ����,���е�KDĿ���ⷽ������������ǿʦ����֮�����������һ����,�����ø�������ģ������ͼ2չʾ����������Ŀ���������KD�ܵ���Ȼ��,��������֪ʶ�Ͷ�λ֪ʶ��������ͼ���ǻ�ϵ�,�����ж���ÿ��λ��ת�ƻ��֪ʶ�Ƿ�����������,�Լ���Щ�����������ض�����֪ʶ��ת�ơ�
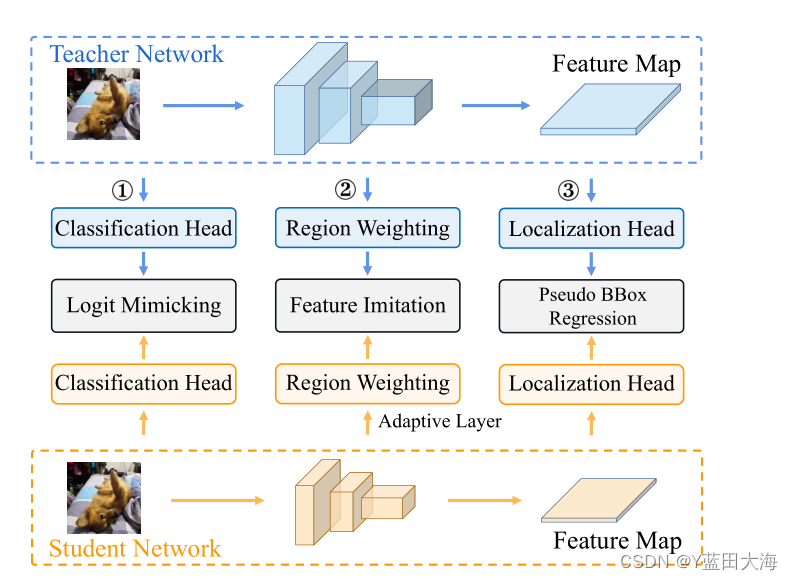
?????????ͼ2??? ����Ŀ���������KD�ܵ����� Logitģ��:����KD��[20];�� ����ģ��:������еķ������ڸ�����ȡ������ȡ�м�����,ͨ����Ҫ����Ӧ��������ѧ������ͼ�Ĵ�С;�� αBBox�ع�:����ʦԤ��ı߽����Ϊ����Ļع�Ŀ�ꡣ
??????? ������������,�ڱ�����,���������һ���µķֶ���֮����ȡ����,�����Ǽ���������ͼ����ȡ���֪ʶ,�ò��Էֱ�����Ͷ�λ֪ʶ����������֪ʶ,����ʹ��ԭʼ����KD�����ڶ�λ֪ʶ,�������������˶�λ�ϵ�֪ʶ���ݹ���,��ͨ�����߽���л������ʷֲ�,�����һ�ּ���Ч�Ķ�λ��ȡ(LD)������������ǰ����ʦ�������Ϊ����Ļع�Ŀ��(��ͼ2�е�αBBox�ع�)�Ĺ����кܴ�ͬ�������ڸ��ʷֲ���ʾ,���ǵ�LD������Ч�ؽ���ʦѧ���ķḻ��λ֪ʶ���ݸ�ѧ��������,������ķ�����ȡ���ԵĻ�����,���ǽ�һ���������м�ֵ�ľֲ�����(VLR),������Ч���ж���Щ���������ڷ����ֲ�ѧϰ��ͨ��һϵ��ʵ��,�����״�֤����ԭʼlogitģ�������������ģ��Ͷ�λ֪ʶ��ȡ������֪ʶ����Ҫ������Ч��������Ϊ,���ڸ��Ե���������ֱ���ȡ����Ͷ�λ֪ʶ������ѵ�����õ�Ŀ��������һ����ϣ���ķ�����
????????���ǵķ�����,���Ժ����ذ�װ���κ��ܼ�����������,�����������,���������κ�������������MS COCO�Ͻ��еĴ���ʵ�����,��û�������������������,���ǿ��Խ�����ResNet-50-FPN���ɵ�ǿ����GFocal��AP������40.1��ߵ�42.1,AP 75��43.1��ߵ�45.6�����ǵ����ģ��ʹ��ResNeXt-101-32x4d-DCN���ɿ���ʵ��50.5 AP�ĵ���Ȳ���,�ⳬ������ͬ���ɡ������Ͳ��������µ��������м������
2.��ع���
????????�ڱ�����,���Ǽ�Ҫ�ع�����ع���,�����߽�лع顢��λ�������ƺ�֪ʶ��ȡ��
2.1. ��Χ�лع�
????????��Χ�лع���Ŀ��������õĶ�λ������R-CNNϵ�в��ö�Ԫ�ع����ϸ�������,��[2,33,41�C43,50]����һ�λع顣��[45,60,67,68]��,����˻���IoU����ʧ��������߰�Χ�еĶ�λ���������,��Χ�б�ʾ���Ѵ�Dirac delta�ֲ���չ����˹�ֲ�,����һ����չ�����ʷֲ�����Χ�и��ʷֲ���ȫ��������˰�Χ�еIJ�ȷ����,������֤Ϊ����Ϊֹ���Ƚ��İ�Χ�б�ʾ����
2.2. ������������
????????����˼��,��λ��������(LQE)Ԥ��һ������,�÷������������Ԥ��ı߽��Ķ�λ������LQEͨ��������ѵ���ڼ���Ϸ�������,����ǿ����Ͷ�λ֮���һ���ԡ���������Ӧ���ں��������е����Ͼ���,����ִ��NMSʱͬʱ���Ƿ��������LQE�����ڵ��о������ݵ�YOLOv,����Ԥ��Ķ������Ŷ����ڳͷ����������Ȼ��,����˺�/����IoU�ͺ�/���Ķȷֱ����ڽ�ģĿ�����ʵ���ָ�ļ�ⲻȷ���ԡ��ӱ߽�б�ʾ�ĽǶ�����,������NMS��˹YOLOv3Ԥ��߽��ÿ����Ե�ķ��LQE��һ�ֳ����Ľ�ģ��λģ���ķ�����
2.3. ֪ʶ����
????????֪ʶ����ּ��ѧϰ�������ʦ���������Ľ��ո�Ч��ѧ��ģ�͡�FitNets����ģ�½�ʦģ�����ز��е��м���ʾ��[5]�״ν�֪ʶ��ȡӦ���ڶ�����,������ʾѧϰ��KD�����ڶ�������⡣Ȼ��,������������������ģ�������Ľ���,��ʵ�ָ����R-CNN��������ģ���˽���ê��λ�õ�ϸ�������������,Dai����������ͨ��ʵ��ѡ��ģ��,��ģ��ʦ����֮��������IJ����е�������������ڶ�������ͱ��������Ͻ�������ģ��ʱ,ʧ�������˲�ͬ����ʧȨ�ء���������������ģ��ķ�����ͬ,���ǵĹ��������˾ֲ���ȡ,����������м�ֵ�ľֲ�����ֱݷ���Ͷ�λ֪ʶ,�������ȡЧ�ʡ�
3.�������
????????�ڱ�����,���ǽ�������������������������һ���µķֶ���֮����ȡ����,�ò��Բ�����������ͼ����ȡ���֪ʶ,���Ǹ��ݸ��Ե���ѡ����ֱ���ȡ����Ͷ�λ֪ʶ��Ϊ�˴�������֪ʶ,����ֻ���ڷ���ͷ�ϲ��÷���KD,�����ڶ�λ֪ʶ,���������һ�ּ���Ч�Ķ�λ��ȡ(LD)�������ּ������ǻ��ڵ���ͷ������,���������������Ȼ��,Ϊ�˽�һ���������Ч��,�����������м�ֵ�ľֲ�����(VLR),�������ж��������͵�֪ʶ�����ڲ�ͬ�����ת�ơ��ڽ�������������,�������ȼ�Ҫ�ع˰�Χ�еĸ��ʷֲ���ʾ��Ȼ����ɵ�������ķ�����
3.1. Ԥ������
????????���ڸ����ı߽��B,��ͳ��ʾ��������ʽ,��{x��y��w��h}(���ĵ����ꡢ���Ⱥ߶�)��{t��B��l��r}(�Ӳ����㵽�������ײ��������Ҳ��Ե�ľ���)����������ʽʵ������ѭDiracdelta�ֲ�,�÷ֲ�����ע������ֵλ��,������ģ�߽���ģ����,��ͼ1��ʾ��������ǰ����Ʒ��Ҳ�õ��������֤����
????????�����ǵķ�����,����ʹ��������İ�Χ�и��ʷֲ���ʾ,����ȫ��������˰�Χ�еĶ�λ��ȷ���ԡ���e�� B�DZ߽��ıߡ����ֵͨ�����Ա�ʾΪ:
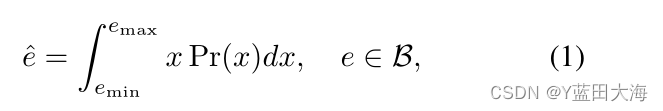
?????????����x�Ƿ�Χ��[e min,e max]�ڵĻع�����,Pr(x)����Ӧ�ĸ��ʡ���ͳ��Dirac delta��ʾ��Eqn��������(1) ,����,��x=e gtʱ,Pr(x)=1,����Pr(x)=0��ͨ���������ع鷶Χ[e min,e max]����Ϊ������ɢ����e=[e 1,e 2,������,e n]T�� R n����n��������,����e 1=e min��e n=e max,�����߽�е�ÿ����Ե����ͨ��ʹ��SoftMax������ʾΪ���ʷֲ���
3.2. �����
????????�ڱ�С����,��������˾ֲ�����(LD),����һ�����Ŀ��������Ч�ʵ��·��������ǵ�LD�ǴӰ�Χ�еĸ��ʷֲ���ʾ�ĽǶȷ�չ������,��Χ������������һ���Ŀ����,��Я���ḻ�Ķ�λ��Ϣ��ͼ1��ģ���������ı�Ե���ֱ�ͨ���ֲ���ƽ̹�Ⱥ��������ӳ��
????????LD�Ĺ���ԭ����ͼ3��ʾ�����������ܼ���������,��ѭ[29],�������Ƚ��߽�б�ʾ����Ԫ��ʾת��Ϊ���ʷֲ�������ѡ��B={t,B,l,r}��Ϊ��Χ�еĻ�����ʽ����{x,y,w,h}��ʽ��ͬ,{t,b,l,r}��ʽ��ÿ������������������һ�µ�,��������ǽ�ÿ����Ե�ĸ��ʷֲ���������ͬ�����䷶Χ�ڡ�����[66],������ʽ֮��û�����ܲ��졣���,������{x,y,w,h}��ʽʱ,���ǽ����Ƚ���ת��Ϊ{t,b,l,r}��ʽ��
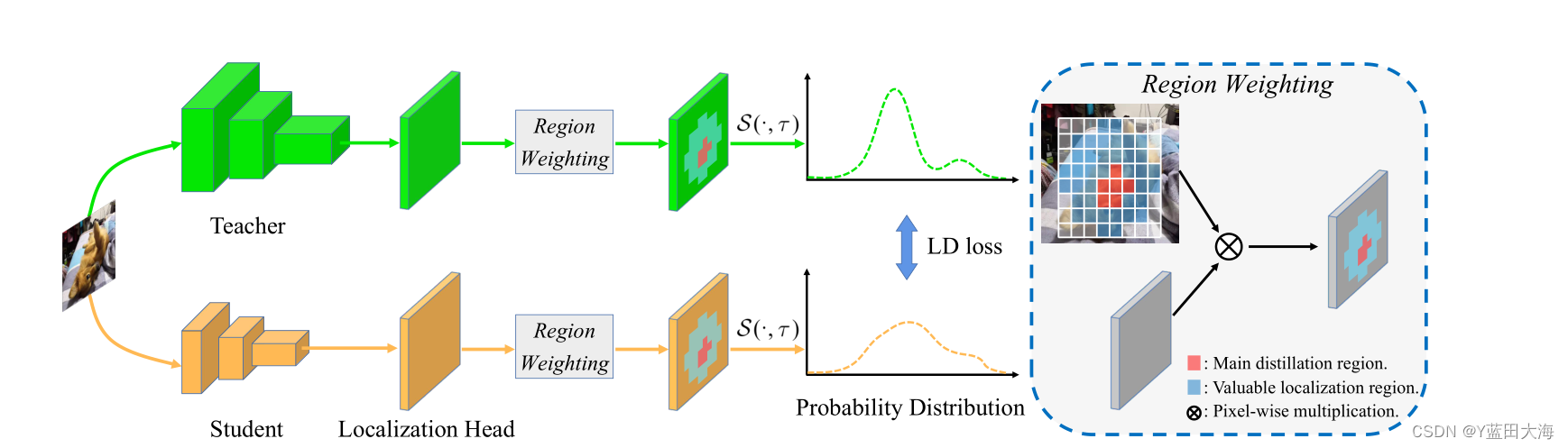
?????????ͼ3?? ��Եe�ľֲ�����(LD)ͼʾ�� B={t,B,l,r}���˴�����ʾ��λ��֧��S(��,��)�Ǿ����¶ȦӵĹ���SoftMax���������ڸ����ļ����,�������Ƚ��߽���ʾת��Ϊ���ʷֲ���Ȼ��,����ͨ����������������м�ֵ�ľֲ�������������Ȩ��ȷ����ȡλ�á����,���Ǽ����˽�ʦ��ѧ��Ԥ����������ʷֲ�֮���LD��ʧ��
????????��zΪ��λͷԤ��ı�e���п���λ�õ�n����,�ֱ��ɽ�ʦ��ѧ����z T��z S��ʾ����[29,39]��ͬ,����ʹ�ù���SoftMax����S(��,��)=SoftMax(��/��)��z T��z Sת��Ϊ���ʷֲ�p T��p S��ע��,����=1ʱ��Ч��ԭʼSoftMax���������ӡ� 0,��������Dirac delta�ֲ������ӡ� ��, �����˻�Ϊ���ȷֲ������ݾ���,��>1������Ϊ�����ֲ�,ʹ���ʷֲ�Я��������Ϣ��
????????������������p T,p S֮�������Եľֲ�������� R nͨ�����·�ʽ���:
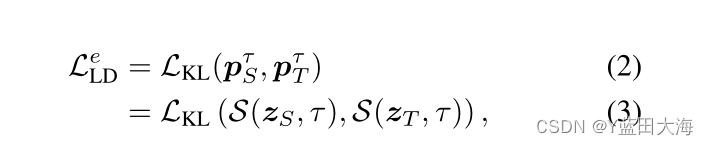
?????????����,L KL��ʾKL��ɢ��ʧ��Ȼ��,�߽��B�����������ߵ�Ld���Թ�ʽ��Ϊ:
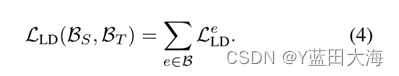
?????????����:���ǵ�LD���״γ��Բ���logitģ������ȡ����Ŀ����Ķ�λ֪ʶ����Ȼ���ӵĸ��ʷֲ���ʾ��һ���Ŀ�����������Ѿ���֤�������õ�,��û�����о����ڶ�λ֪ʶ��ȡ�е����ܡ����ǽ����ӵĸ��ʷֲ���ʾ��KL��ɢ��ʧ����,��֤�����ּ�logitģ�⼼�������Ŀ������������Ч�ʷ���������á���Ҳʹ�����ǵ�LD����ǰ����ع����кܴ�ͬ,�෴,��Щ����ǿ��������ģ�µ���Ҫ�ԡ������ǵ�ʵ�鲿��,���ǽ����������LD���ŵ���и������ֵ������
3.3. �м�ֵ�Ķ�λ����
????????�������о����ͨ����С��L2��ʧ����ʹѧ�����������ģ�½�ʦ�����������Ȼ��,һ��������Ӧ����:�����Ƿ�Ӧ�ò������ӵ�ʹ������ģ����������ȡ���֪ʶ?�������ǵĹ۲�,���Ƿġ���ǰ�Ĺ����Ѿ�ָ��,����Ͷ�λ��֪ʶ�ֲ�ģʽ�Dz�ͬ�ġ����,�ڱ�С����,�����������м�ֵ�ľֲ�������(VLR),�Խ�һ���������Ч��,������Ϊ�⽫��һ�ֺ���ϣ���ķ�����ѵ�����õ�ѧ���������
?????������˵,���������Ϊ������,������������м�ֵ�ľֲ��������������ɱ�ǩ����ֱ��ȷ��,�����ͷ����λ�á��㷨1���Ի���м�ֵ�Ķ�λ��������,���ڵ�l��FPN����,���Ǽ���������ê��B a l�͵�����ֵ��B gt֮���DIoU����X l��Ȼ��,���ǽ�DIoU����������Ϊ��vl=�æ�pos,���Ц�pos�DZ�ǩ�������IoU��ֵ��VLR���Զ���ΪV l={��vl? X��? ��pos}�����ǵķ���ֻ��һ����������,������VLR�ķ�Χ������=0ʱ,Ԥ��ê�����GT��֮��ľ�������0������λ��? x i l j? ��pos����ȷ��ΪVLR�����á� 1,VLR��������Ϊ�ա���������ʹ��DIoU,��Ϊ���Կ����������ĵ�λ�ø����˸��ߵ����ȼ���???

?�㷨1�м�ֵ�Ķ�λ����
????????���ǩ��������,���ǵķ��������Է������༶FPN��ÿ��λ�á�����,��������ȼ���ֻ������һЩλ�á����,����ʵ���Ͽ��Խ�VLR��Ϊ�����������������졣ע��,������ê�����,��FCO,���ǿ�����������ͼ��ʹ��Ԥ��ê,���Ҳ��ı���ع���ʽ,�Ա㶨λѧϰ����Ϊ��ê���͡���Ȼ����ͨ����ÿ��λ�����ö��ê�Ļ���ê�ļ����,����չ��ê��������DIoU����,Ȼ����������ԡ�
3.4. �����������
????????ѵ��ѧ��������ʧ���Ա�ʾΪ:
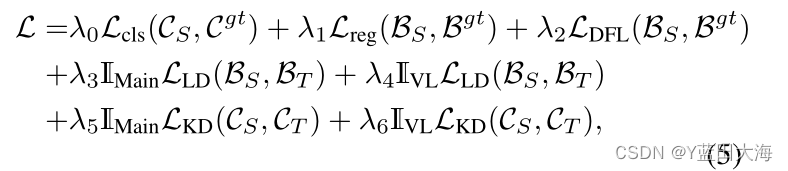
?
????????����ǰ�������κλ��ڻع�ļ�����ķ���Ͱ�Χ�лع��֧��ȫ��ͬ,��L cls�Ƿ�����ʧ,L reg�ǰ�Χ�лع���ʧ,L DFL�Ƿֲ�������ʧ��I Main��I VL�ֱ���������������м�ֵ��λ�������������,L KD��KD��ʧ,C S��C T�ֱ��ʾѧ���ͽ�ʦ�ķ���ͷ�������,C gt�ǻ�����ֵ���ǩ������������ʧ����������������ͬ��Ȩ�����Ӽ�Ȩ,����,LD��ʧ��ѭbbox�ع�,KD��ʧ��ѭ���ࡣ����,ֵ��һ�����,����LD��ľ����㹻����������,��˿��Խ���DFL��������,���ǿ������û�����������͵�������ʧ,�Ա��Ե�������������ʽ����ѧ����
4.ʵ��
????????�ڱ�����,���ǽ�����ȫ�����ʴ�о��ͷ���,��֤���������LD�������ھ�����ս�ԵĴ��ģMS COCO���ϵ���Խ�ԡ�
4.1. ʵ��װ��
????????train2017(118Kͼ��)����ѵ��,val2017(5Kͼ��)������֤�����ǻ�ͨ���ύ��COCO���������MS COCO test dev 2019(20Kͼ��)�����������ʵ������mmDetection����½��еġ���������˵��,����ʹ�ô���FPN��ResNet��Ϊ���ɺ;�������,ʹ��FCOS������êͷ���з���Ͷ�λ������ʵ���ѵ���ƻ�����Ϊ���߶�1��ģʽ(12������)����������ѵ���Ͳ��Գ�����,������ȫ��ѭGFocalЭ��,�������ڷ����QFL��ʧ������bbox�ع��GIoU��ʧ�ȡ�����ʹ�ñ�COCO������������IJ���,��ƽ������(AP)��ͨ��������ͬ�ķ�������ѵ�����л���ģ������,�Ա������ǵ�LD���й�ƽ�Ƚϡ��й�PASCAL VOC�ĸ���ʵ��ϸ�ں���ʵ����,����IJ�����ϡ�
4.2. ��ʴ�о��ͷ���

(a) LD�е��¶Ȧ�:���д�ӵĹ���Softmax���������˿ɹ۵����档����Ĭ�����æ�=10����ʦ��
ResNet-101,ѧ����ResNet-50
(b) LD��αBBox�ع�[5]:���ǵ�LD���Ը���Ч�ش��ݶ�λ֪ʶ����ʦ��ResNet-101,ѧ����ResNet-50
(c) ����VLR�е�����:���м�ֵ�Ķ�λ�����ϴ���LD�������л���Ӱ�졣Ĭ�������,���ǽ�������Ϊ0.25����ʦ��ResNet-101,ѧ����ResNet-50��
��1????????��ʴ��������COCO val2017��չʾ��LD��VLR������ʵ�顣?
????????LD�е��¶Ȧӡ����ǵ�LD������һ��������,���¶Ȧӡ���1a�����˲�ͬ�¶��µ�LD���,���н�ʦģ��ΪResNet-101,AP 44.7,ѧ��ģ��ΪResNet-50���˴��������������������1a�еĵ�һ�����,��ͬ�¶�ʼ�ջᵼ�¸��õĽ�����ڱ�����,���Ǽؽ�LD�е��¶�����Ϊ��=10,������������ʵ�����ǹ̶��ġ�
????????LD��αBBox�ع顣��ʦ�н�ع�(TBR)��ʧ���ڶ�λͷ����ǿѧ���ij�������,��ͼ2�е�αbbox�ع�,���ʾΪ:
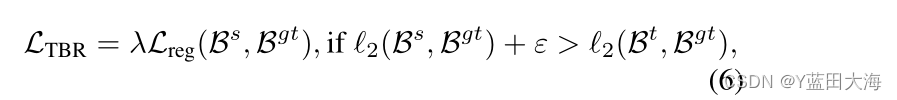
????????����B s��B t�ֱ��ʾѧ���ͽ�ʦ��Ԥ���,B gt��ʾ������ֵ��,����Ԥ�����ԣ��,L reg��ʾGIoU��ʧ���˴������������������ӱ�1b�п��Կ���,���ڵ�ʽn��ʹ���ʵ�����ֵ��=0.1ʱ,TBR���ȷʵ�������������(+0.4 AP��+0.7 AP 75)��(6). ����,��ʹ�ô�bbox��ʾ��,��������������κζ�λ��ȷ������Ϣ,���´��Ž�����෴,���ǵ�LDֱ�Ӳ���41.1 AP��44.9 AP 75,��Ϊ�������˰����ḻ��λ֪ʶ��bbox�ĸ��ʷֲ���?
????????VLR�еĸ��֦á��������VLR���п���VLR��Χ�IJ����á����1c��ʾ,������0��0.5֮��ʱ,AP���ȶ��ġ�AP�ڴ˷�Χ�ڵı仯ԼΪ0.1�����Ŧõ�����,VLR������Ϊ�ա�����Ҳ����41.1,������������������LD�������ȷ���ʵ������ñ���,��VLR�ϴ���LD�������л���Ӱ�졣������ʵ����,Ϊ�˼����,���ǽ�������Ϊ0.25��
?????????������������ʽ������KD��LD������ѡ���������,��һЩ��Ȥ�Ĺ۲����������ڱ�2�б�������ص���ʴ�о����,���С�Main����ʾlogitģ����������������,����ǩ�������λ��,��VLR����ʾ�м�ֵ�Ķ�λ�������Կ���,ִ�С���KD��������LD��������϶����Էֱ�ѧ���ı������+0.1��+1.0��+1.3 AP��������������������з���Ͷ�λ���м�ֵ֪ʶ,����KD��LD������١�Ȼ��,���ǽ�����ʩ���ڸ���ķ�Χ��,��VLR�����ǿ��Կ���,��VLR LD��(��2�ĵ�5��)�����ڡ���LD��(��3��)�Ļ����Ͻ�һ����AP���+0.7��Ȼ��,���ǹ۲쵽,��һ���漰��VLR KD����������ĸ���(��2�ĵ�2�к͵�5��),����û�и���(��2���������)�����ٴα���,��λ֪ʶ��ȡ������֪ʶ��ȡ�����ǵķֶ���֮��ȡ����(����Main��)����Ҫ������ЧKD��+��MainLD��+��VLRLD��,��VLR����ɲ��֡�
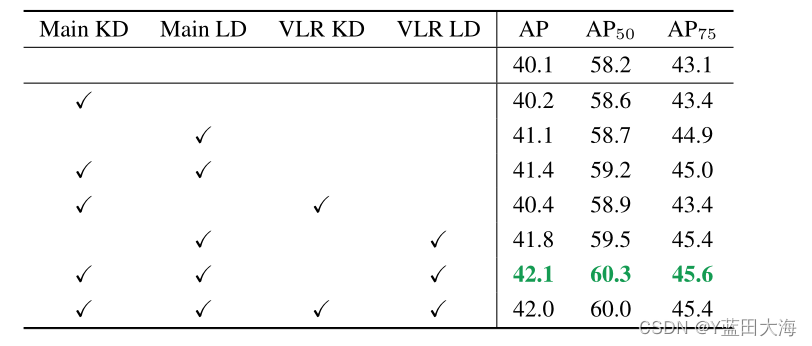
?????????��2????????KD�����ǵ�LD�ķ�����������ʽ����������ʦ��ResNet-101,ѧ����ResNet-50����Main����ʾ��������,����ǩ�������λ�á���VLR����ʾ�м�ֵ�Ķ�λ�������MS COCO val2017����ʵ��ó�
????????Logitģ���빦��ģ�¡����ǽ����������LD�뼸�����Ƚ�������ģ�ⷽ�������˱Ƚϡ����Dz��÷����������ķ�ʽ,������������ִ��KD��LD,��VLR��ִ��LD�������ִ������ͨ���䱸FPN,��֮ǰ�Ĺ���֮��,��������ʵ�������ǵķ���,������������ģ��ʩ���ڶ༶FPN��,�Խ��й�ƽ�Ƚϡ�����,��FitNets����ȡ����������ͼ����ʧ�ܡ���ʾGT��������ģ�����ʧȨ�ش���GT���ڵ���ʧȨ�ء���ϸ���ȡ���ȡ����ê��λ�õ������������GIģ�¡�����ѧ���ͽ�ʦ���б�Ԥ��ѡ�����������ڲ�GT�С���ָ������FPN����ʹ��������ģ��������ͬ��GT�С�����Ҫ������ָ����ģ����Ҫ���������ڵ�������
????????�ӱ�3��,���ǿ��Կ���,����������ͼ�е�����ﵽ+0.6 AP���档ͨ��ΪGT�����λ�����ø������ʧ����(ʧ��),���������ڶ�����λ��ʹ����ͬ��ʧ������ϸ���Ⱦ۽���GTbox������λ��,����41.1 AP,����ʹ�������������ģ�����൱��GIģ��[8]�����б���������ģ��,���41.5 AP������ѧ���ͽ�ʦ֮���Ԥ����ܴ�,ģ��������ܳ������κεط���

?????????��3????????Logitģ���빦��ģ�¡������ǵġ���ָ����ʹ�÷����������ķ�ʽ,�������������Ͻ���KD��LD,��VLR�Ͻ���LD����ʦ��ResNet-101,ѧ����ResNet50�������MS COCOval2017����ʵ��ó�
?????? ������Щ����ģ�ⷽ�����������ĸĽ�,������û����ȷ����֪ʶ�ֲ�ģʽ���෴,���ǵķ�������ͨ����������������ʽ����֪ʶ,ֱ������42.1 AP��ֵ��ע�����,���ǵķ�������logit�����������ϲ�����,�����logitģ�²�����������ģ��ֻҪ��ȡ�ʵ����������,�������ǵ�LD������,���ǵķ�������������ģ�ⷽ����������3��ʾ,ͨ����Щ����ģ�ⷽ��,���ǵ����ܿ��Խ�һ����ߡ��ر���GIģ��,���ǽ�ǿGFocal���������+2.3 AP��+3.1 AP 75��
????????���ǽ�һ��������ʵ��,�Լ���������ͺи��ʷֲ���ƽ�����,��ͼ4��ʾ�����Կ���,ϸ��������ģ��[54]��GIģ��[8]��Ԥ����������������������,��Ϊ����֪ʶ�Ͷ�λ֪ʶ�����������ͼ�ϡ����ǵġ���LD���͡���LD+VLR LD�������൱�����ķ���÷ֵ�ƽ������ϸ���Ⱥ�GIģ��[8]��ƽ������,���и��ʷֲ���ƽ�����ϵ͡������,��ʹ��LD�����������ÿ����������ٽ�ʦ��ѧ��֮��ĺи��ʷֲ�����,�����Dz��ܼ��ٷ���ͷ����������Ǻ����ġ�������ǽ�����KDǿ�Ӹ���������,�õ�����KD+��LD+VLR LD��,�������ƽ�����ͺи��ʷֲ�ƽ�������Լ�С��
????????���ǻ����ӻ���ѧ���ͽ�ʦ��P5��P6 FPNˮƽ��ÿ��λ�õĶ�λͷ������L1�����ܺ͡���ͼ5��,�롰û���������,���ǿ��Կ���GIģ��[8]ȷʵ�����˽�ʦ��ѧ��֮��Ķ�λ���졣��ע��,�����ر�ѡ����һ�������ڿ��ӻ�����,AP��������GIģ�⡣���ǵķ������Ը������ؼ����������,�����ⶨλģ����
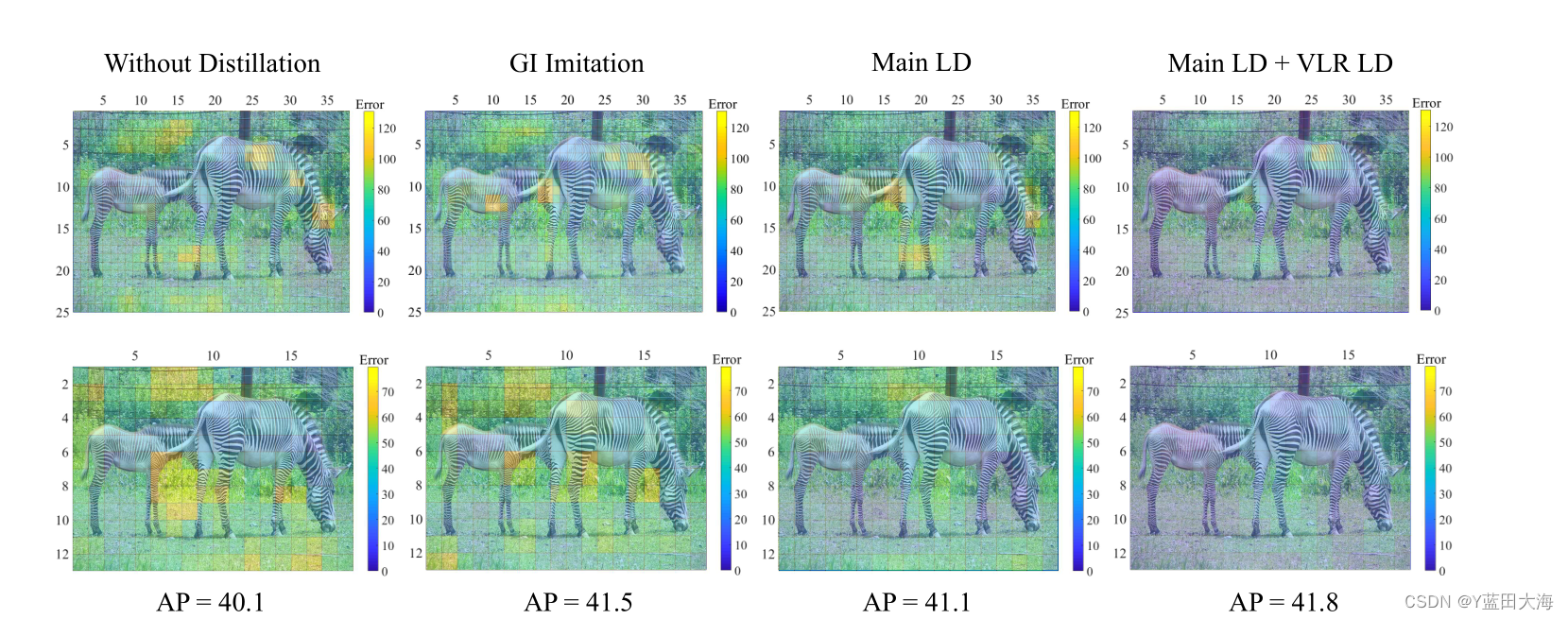
????????ͼ5????????���Ƚ��Ĺ���ģ������ǵ�LD֮����Ӿ��Ƚϡ�����չʾ��ÿ��λ�õ�L1����ܺ�
��P5(��һ��)��P6(�ڶ���)FPN����,��ʦ��ѧ��֮��ı��ػ�ͷ��¼����ʦ��ResNet-101,ѧ����ResNet-50�����ǿ��Կ���,��GIģ��[8]���,���ǵķ���(��LD+VLR LD)����
�������˼�������λ�õ�����ɫԽ��Խ�á��Բ�ɫ�ۿ�Ч����ѡ�?
????????����̽������LD��������,�����÷����������ķ�ʽ,����KD+��LD+VLR LD,������̽����������֤������ѡ����mmDetection�ṩ��44.7AP��ResNet-101��Ϊ���ǵ���ʦ,����ȡһϵ��������ѧ�������4��ʾ,���ǵ�LD�����ȶ��ؽ�ѧ��ResNet-18��ResNet-34��ResNet-50���+1.7��+2.1��+2.0 AP��AP 75�е�+2.2��+2.4��+2.4������Щ���,���ǿ��Եó�����,���ǵ�LD�����ȶ����������ѧ���Ķ�λ���ȡ�

????????��4????????����̽����LD�Ķ����������ʦ��ResNet-101�������MS COCOval2017����ʵ��ó�???
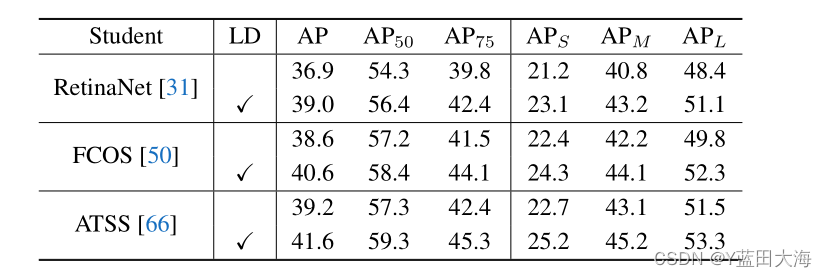
????????��չ�������ܼ�����̽���������ǵ�LD�������ؼ��ɵ������ܼ�����������,�����ǻ���ê��Ļ�����ê��ġ����ǽ�LD�ͷ����������ķ�ʽӦ���ڼ���������еļ����,��������Ĥ��(����ê��)��FCOS[50](��ê��)��ATSS[66](ê��)�����ݱ�5�еĽ��,LD��������Щ�ܼ�̽���������Ľ���2 AP��
?
?????��5.LD�ڸ��ֳ����ܼ�����̽�����ϵĶ����������ʦ��ResNet-101,ѧ����ResNet-50��
�����MS COCOval2017����ʵ��ó�???
4.3. �����Ƚ������ıȽ�
????????ͨ��ʹ�����ǵ�LD��һ����ǿGFocalV2,���ǽ����ǵ�LD�����Ƚ����ܼ�����̽���������˱Ƚϡ�����COCO val2017,����֮ǰ�Ĵ��������ʹ�õ��߶�1��ѵ���ƻ�(12����)��ResNet-50-FPN���ɽ�����֤,���ǻ������˸������µĽ��,�Խ��й�ƽ�Ƚϡ�����COCO���Կ���2019,��֮ǰ�Ĺ���֮��,��������1333��[480:960]��߶�2��ѵ���ƻ�(24����)��LDģ�͡�ѵ���ھ���8��GPU�Ļ����ڵ��Ͻ���,ÿ��GPUʹ��2������,��ʼѧϰ��Ϊ0.01,�Խ��й�ƽ�Ƚϡ�������������,���õ��߶Ȳ���([1333��800]�ֱ���)�����ڲ�ͬ��ѧ��ResNet-50��ResNet-101��ResNeXt-101-32x4d-DCN[56,72],���ǻ��ֱ�ѡ��ͬ������ResNet-101��ResNet-101-DCN��Res2Net101-DCN��Ϊ���ǵ���ʦ��
????????���6��ʾ,��ʹ��ResNet-50-FPN����ʱ,���ǵ�LD��SOTA GFocalV2��AP���������+1.6,��AP 75���������+1.8����ʹ�þ��ж�߶�2��ѵ����ResNet-101-FPN��ResNeXt-101-32x4d-DCNʱ,���ǻ������ߵ�AP����,�ֱ�Ϊ47.1��50.5,����ͬ�����ɡ������Ͳ��������������������е��ܼ���������������Ҫ����,���ǵ�LDû�������κζ���������������㳬ͷ�ͳ�ͷ���Ա�֤��GFocalV2��ȫ��ͬ�������ٶȡ�
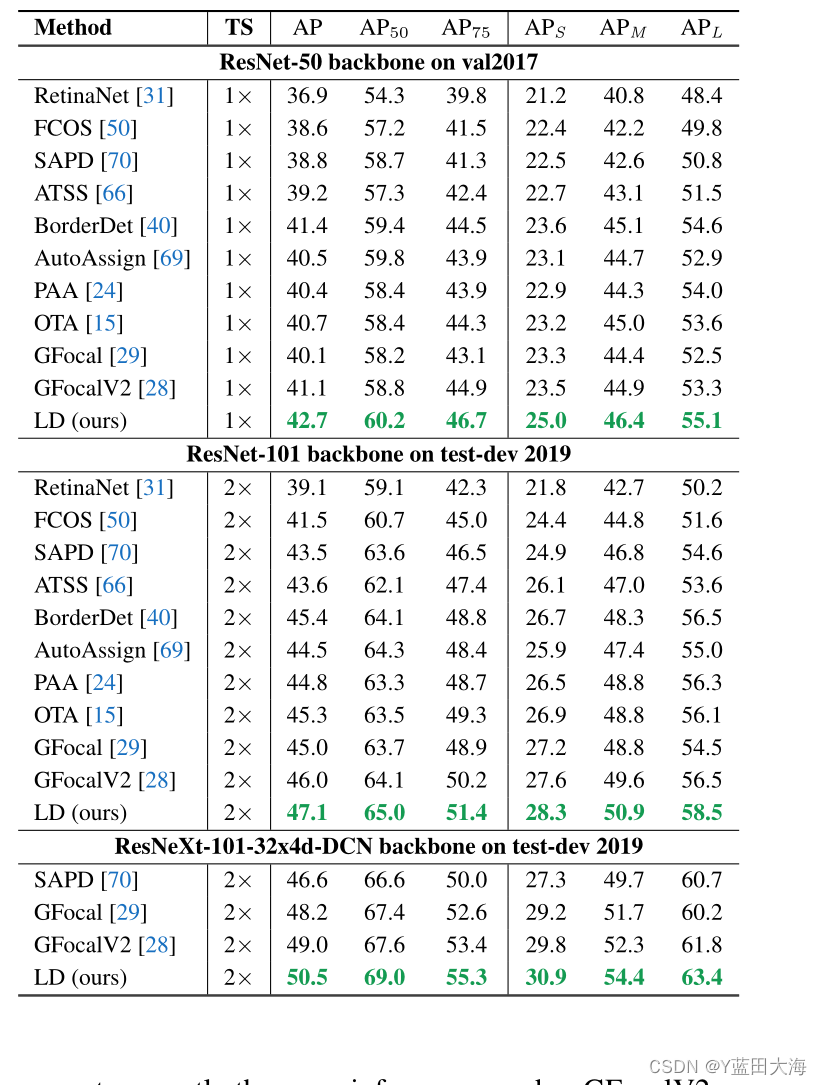
????????��6????????�Ƚ�COCOVAL2017��test-dev2019�����·�����TS:ѵ��ʱ�������1��':���߶�ѵ��12����2��':��߶�ѵ��24���Ρ�?
5.����
????????�ڱ�����,���������һ�������ܼ�Ŀ�������λ��ȡ����,�������һ���м�ֵ�Ķ�λ����,�Ե�������ȡ����ķ�ʽ��ȡѧ����������������:1)logitģ����������ģ��;�Լ�2)����ת�Ʒ���ķ�����������ʽ����ȡĿ������ʱ,��λ֪ʶ�dz���Ҫ������ϣ�����ǵķ����ܹ�ΪĿ����翪�����õ���ȡ�����ṩ�µ��о�ֱ��������,LD��ϡ���������(DETRϵ��)��������������Ӧ��,����ʵ���ָ������ٺ���ά������,ֵ�ý�һ���о���