?

说明:IEEE会议 2月6日 2020
题目:基于深度协同图像和特征对齐的无监督双向跨模态自适应医学图像分割
作者:陈程,学生 会员,IEEE,窦琪,会员,IEEE,陈浩,会员,IEEE,秦静,会员,IEEE,冯安恒,资深会员,IEEE
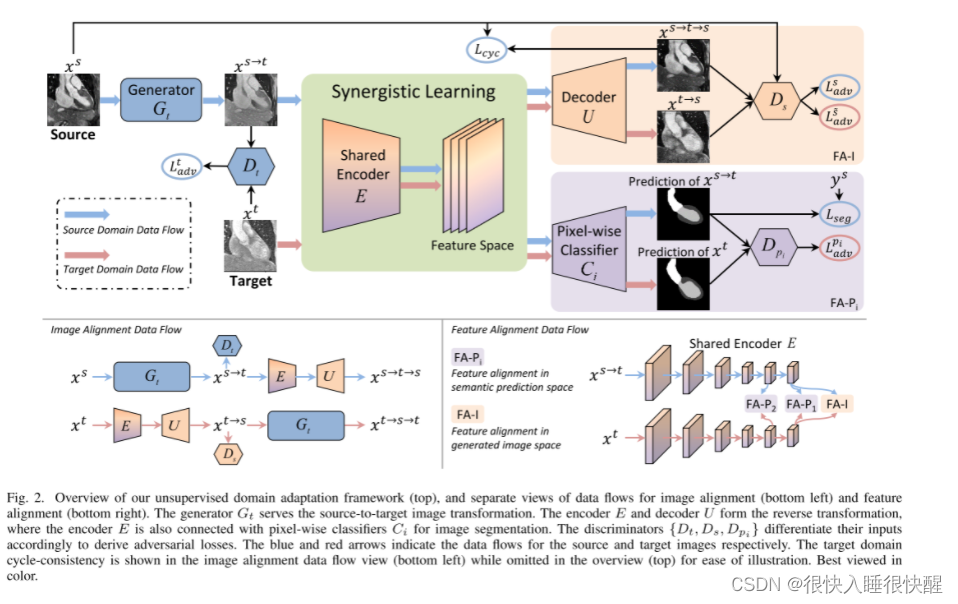
创新:SIFA 的一个关键特点是图像变换和分割任务的共享编码器。通过参数共享,本框架中的图像对齐和特征对齐能够协同工作,减少端到端训练过程中的域偏移(domain shift)。同时,另一个研究方向是特征对齐,目的是在对抗性学习的情况下提取深度神经网络的域不变特征。
摘要:
无监督域自适应技术在医学图像计算中越来越受到关注,其目的是解决深度神经网络在处理具有异构特征的未知数据时性能下降的问题。 在这项工作中,我们提出了一个新的无监督域自适应框架,称为协同图像和特征对齐(SIFA),以有效地使分割网络适应于未标记的目标域。 我们提出的SIFA从图像和特征两个角度对域进行协同比对。 特别地,我们同时对图像的外观进行了跨域变换,并通过多个方面的对抗学习和深度监督机制增强了提取特征的域不变性。 特征编码器在两个自适应视角之间共享,以通过端到端的学习来利用它们的共同利益。 我们用心脏亚结构分割和腹部多器官分割对MRI和CT图像之间的双向交叉适应性进行了广泛的评价。 在两个不同任务上的实验结果表明,本文提出的SIFA方法能够有效地提高无标记目标图像的分割性能,并且在很大程度上优于目前最先进的域自适应方法。
数据集:多模态全心分割(MMWHS)挑战赛2017数据集 ISBI 2019 Chaos Challenge[48]20卷的T2-SPIR MRI训练数据(已下载),以及来自[49]30卷的公开CT数据
评价指标:the Dice similarity coef?cient (Dice) and the average symmetric surface distance (ASD)
DICE ASD
消融实验:
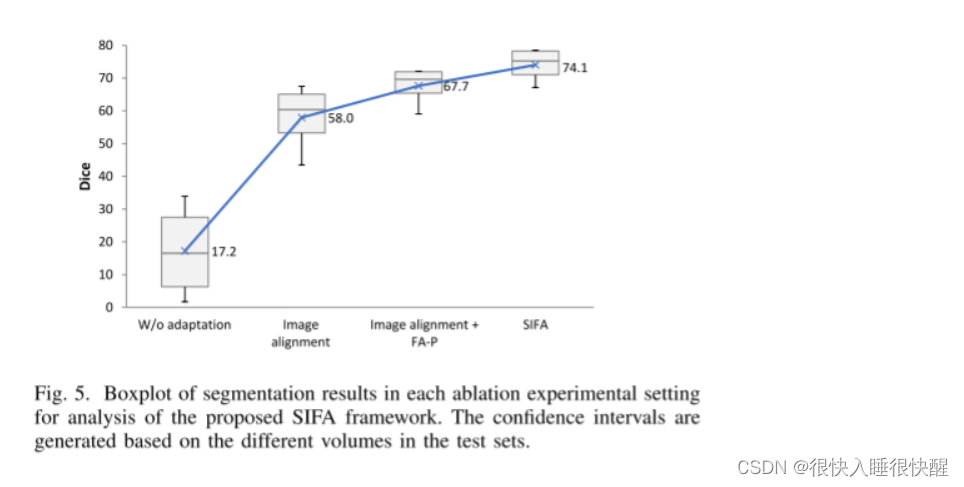
(1)首先,在MRI与CT自适应的心脏数据集上进行了消融实验,证明了在两个紧凑空间中图像对齐和特征对齐可以共同提高区域自适应性能。
基线网络只使用图像对齐,它是通过在训练网络时去除特征对齐对抗性损失来构建的。 与“W/O自适应”下界相比平均DICE提高到58.0%表明,通过图像变换,可以成功地使源图像更接近目标域。
将语义预测空间中的深度监督特征对齐FA-P1和FA-P2加入到基线网络中,使平均DICE提高到67.7%。 进一步在生成的图像空间中添加特征对齐,即FA-I,对应于我们提出的SIFA模型,获得了74.1%的平均骰子。
分割精度的不断提高表明,图像和特征对齐可以联合进行以获得更好的域自适应,而不同紧凑空间中的特征对齐可以注入积分效应以促进域不变性。
(2)然后,我们通过与我们以前的会议论文[20](即SIFA)的比较,进一步评估了本文中引入的深度监督机制。
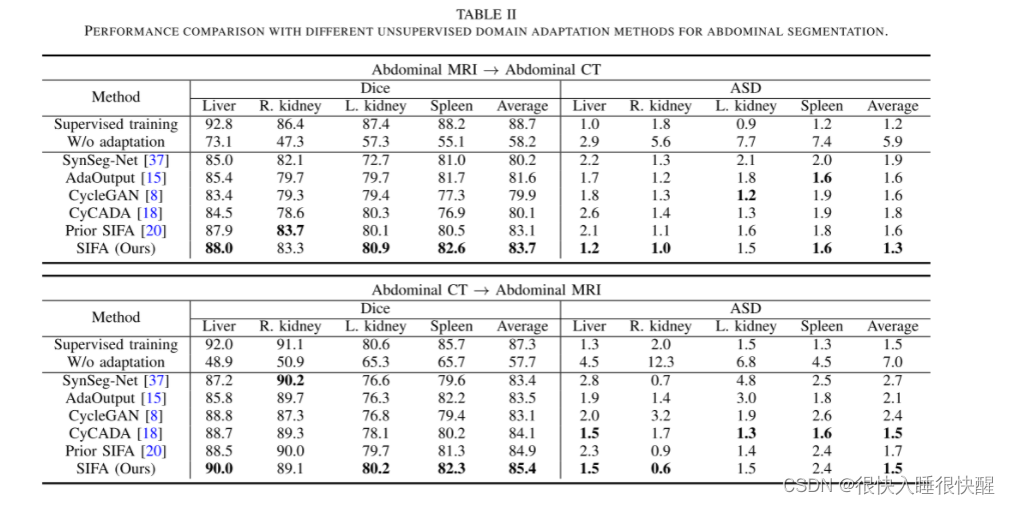
与传统的SIFA相比,我们提出的方法在更高的平均DICE和更低的ASD值的情况下持续地改善了域适应性能,尤其是对于体积较小或边界不规则的结构,如腹部数据集中的心脏、紫胶和肌结构以及脾脏。 这表明语义预测空间中的辅助对抗学习FA-P2有助于更有效地对低层特征进行对齐,从而获得更好的领域适应性能。
网络框架:
对抗损失
使用一个生成器
G
t
G_t
Gt?将源域图像转换成与目标域相似的图像,即
G
t
G_t
Gt?(
x
s
x^{s}
xs)=
x
s
→
t
x^{s\rightarrow t}
xs→t并使用一个判别器
D
t
D_t
Dt?来判断生成的图像是真正来自目标域还是生成的。这个 GAN 的损失函数为:
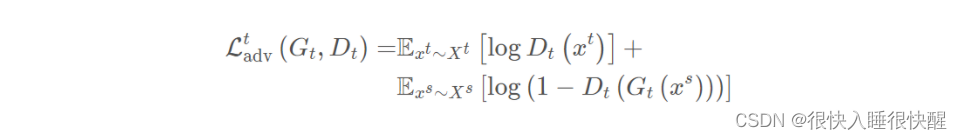
为了让转换得到的图像
x
s
→
t
x^{s\rightarrow t}
xs→t保留源域的特征,通常使用一个相反的生成器,以用来促进图像的循环一致性。图中的E(特征编码器)和U(解码器)组合起来相当于相反的生成器即
G
s
G_s
Gs?。它的作用就是将转换得到的目标域图像又转换为源域图像,并通过源域的判别器
G
s
G_s
Gs?进行判别,得到对抗损失为
L
a
d
v
s
L_{adv}^{s}
Ladvs?
循环一致性损失
通过源域-目标域-源域或目标域-源域-目标域的转换,得到循环一致性损失函数:
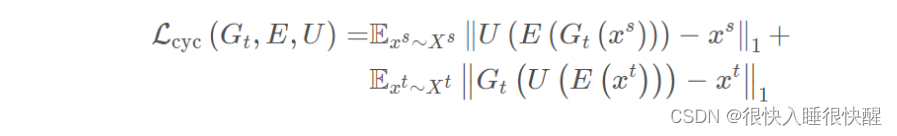
?分割损失
图中E和C(像素级分类器)组合成目标域的分割网络,输入为
x
s
→
t
x^{s\rightarrow t}
xs→t,y,
x
t
x_t
xt?,输出为
x
s
→
t
x^{s\rightarrow t}
xs→t与
x
t
x_t
xt?的分割标签,分割损失函数:
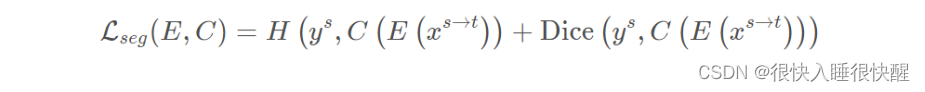
第一项为交叉熵,第二项为Dice损失。
语义预测空间的特征对齐
使用判别器
D
p
D_p
Dp?对分割网络生成的分割标签进行判别,如果两者的特征没有对齐,则通过反向传播对E进行优化,从而减少了生成的目标域图像
x
s
→
t
x^{s\rightarrow t}
xs→t和真正的目标域图像
x
t
x_t
xt?的特征分部之间的差异。该对抗损失为:
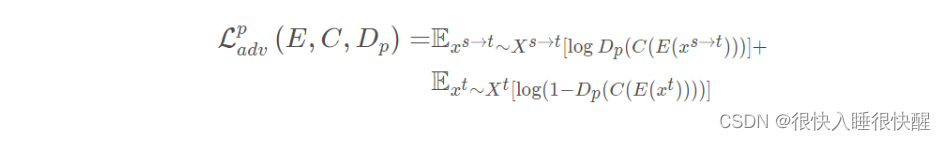
语义预测空间的深度监督对抗学习
因低级特征可能和高级特征的对齐情况并不一样,所以使用额外的和编码器低层的输出相关的像素级分类器来产生额外的辅助预测,然后通过一个判别器来对这些额外的预测进行判别,这样就可以增强低级特征的对齐。如此一来,对于
L
s
e
g
L_{seg}
Lseg?和
L
a
d
v
L_{adv}
Ladv?的表达式,就需要调整。它们分别被拓展为
L
s
e
g
i
L_{seg}^{i}
Lsegi?(E,
C
i
C_i
Ci?)和
L
a
d
v
P
i
L_{adv}^{Pi}
LadvPi?(E,
C
i
C_i
Ci?,
D
p
i
D_{pi}
Dpi?),其中i=1,2,
C
1
C_1
C1?,
C
2
C_2
C2?表示连接到编码器不同层的两个分类器,
D
p
1
D_{p1}
Dp1?和
D
p
2
D_{p2}
Dp2?表示对两个分类器的输出进行判别的判别器。
生成图像空间的特征对齐
对于
G
s
G_s
Gs?,为判别器
D
s
D_s
Ds?增加一个辅助任务,即判别生成的源域图像来自生成的目标域图像
x
s
→
t
x^{s\rightarrow t}
xs→t还是本来就是目标域的图像
x
t
x_t
xt?。该辅助任务的对抗损失为:
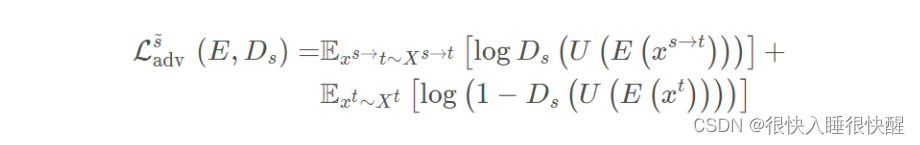
用于协同学习的共享编码器
在协同学习框架的一个关键在于图像和特征对齐之间共享编码器E,编码器会通过损失
L
a
d
v
s
L_{adv}^{s}
Ladvs?和
L
c
y
c
L_{cyc}
Lcyc?以及判别器
D
p
i
D_{pi}
Dpi?,
D
s
D_s
Ds?的反向传播来进行优化。
在进行训练过程中各个模块的训练顺序为
G
t
G_t
Gt?->
D
t
D_t
Dt?->E->
C
i
C_i
Ci?->U->
D
s
D_s
Ds?->
D
p
i
D_{pi}
Dpi?。网络框架总损失函数如下:
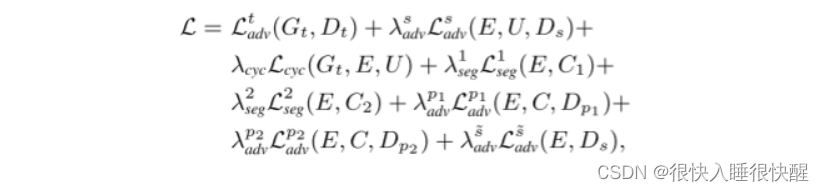
其中{
λ
a
d
v
s
\lambda _{adv}^{s}
λadvs?,
λ
c
y
c
\lambda _{cyc}
λcyc?,
λ
s
e
g
1
\lambda _{seg}^{1}
λseg1?,
λ
s
e
g
2
\lambda _{seg}^{2}
λseg2?,
λ
a
d
v
p
1
\lambda _{adv}^{p1}
λadvp1?,
λ
a
d
v
p
2
\lambda _{adv}^{p2}
λadvp2?,
λ
a
d
v
s
~
\lambda _{adv}^{\widetilde{s}}
λadvs
?}是被用来平衡各项的参数,在实验是分别设为{0.1,10,1.0,0.1,0.1,0.01,0.1}。
性能比较:
心脏图像分割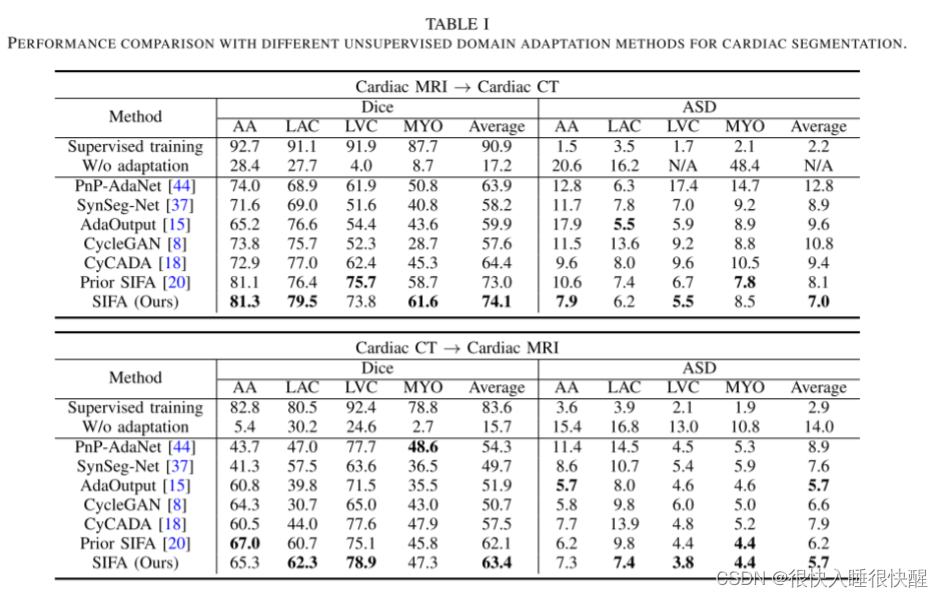
腹部图像分割