1. ժҪ
??���ڶԱ�ѧϰ(CL)�����Ҽලѧϰģ���ԳɶԵķ�ʽѧϰ�Ӿ���������ȻĿǰ���е�CLģ���Ѿ�ȡ���˺ܴ�Ľ�չ,���ڱ�����,���Ƿ�����һ��һֱ�����ӵ�����:��������ͼ��ѵ��CLģ��ʱ,������ͼ���в��Ե����ܱ���ǰ��������Ե�����Ҫ��;��ʹ��ǰ������ѵ��CLģ��ʱ,������ͼ���в��Ե����ܱ���ǰ��������Ե����ܲ��һ�۲�������,ͼ���еı������ܻ����ģ��ѧϰ��������Ϣ,��Ӱ����δ��ȫ������Ϊ�˽���������,���ǽ�����һ���ṹ���ģ��(SCM),��������ģΪһ�������������������һ�ֻ��ں��ŵ�����������,������Ԫ�������Ľ����ԶԱ�ѧϰ(ICLMSR),��������Ĺ�Ӧ���������������Ԥ��ICL-MSR�������ϵ��κ����е�CL������,�Լ������ѧϰ�ı������š���������֤����ICL-MSR���и�С����Χ��������,�����ڶ�������ݼ��ϵ�ʵ�����,ICL-MSR�ܹ���߲�ͬ���Ƚ���CL���������ܡ�
2. ����
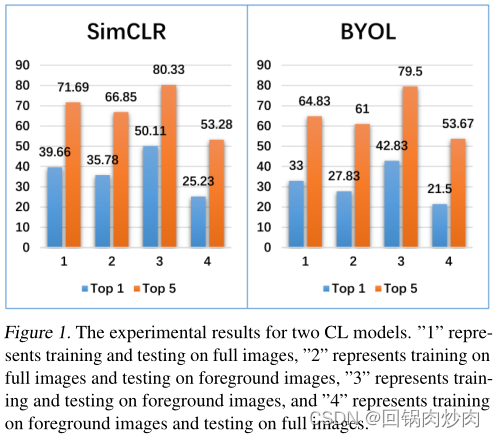
COCO���ݼ�������ʵ������
- ������ͼ����ѵ���Ͳ���CLģ��;
- �ֱ�������ͼ���ǰ��ͼ����ѵ���Ͳ���CLģ��;
- ��ǰ��ͼ����ѵ��������CLģ��;
- �ֱ���ǰ��ͼ�������ͼ����ѵ���Ͳ���CLģ�͡�
��������Ľ���
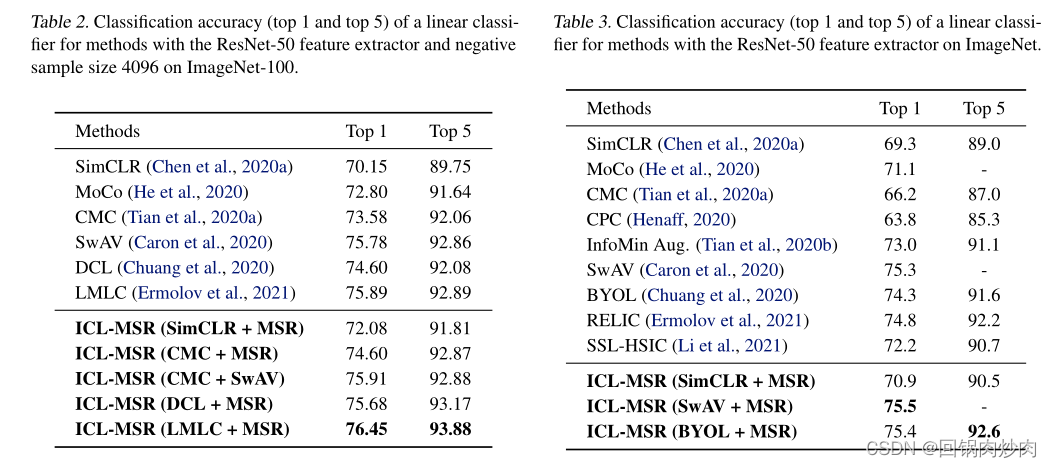
??�Ա�1��2���Է���,������ͼ���ϲ��Ե�����������ǰ��ͼ���ϲ��Ե����ܡ�����,�Ա�1��4���Է���,������ͼ��ѵ����ģ��������ͼ���ϲ���ʱ������ǰ��ͼ��ѵ����ģ�͡��ɴ˵ó�����һ�������������Ϣ����Ӱ��CLģ�͵�ѧϰ���̡�
??�Ա�3��4���Է���,ʹ��ǰ��ͼ��ѵ��ģ��ʱ,��ǰ��ͼ���ϵIJ�������Զ����������ͼ���ϲ��Ե����ܡ�����,�������б�������,ֻʹ��ǰ��ͼ��ѵ���Ͳ��Ի������õĽ�����ɴ˵ó����۶��������������Ϣ�ή�ͻ��ڴ˵�CLģ�͵����ܡ�
�����Ľ���
??һ����������ͼ��ѵ����������ȡ��������ȡ�뱳����ص������������ڲ��Խ�,��������ͼ��ͬʱ����ǰ�����ֺͱ�������,����ǰ������,�������ֶԷ���Ҳ��һ���Ĵٽ����á���һ����,CLŬ����Ӧ������������,������⡢����ָ�ȡ�ֻ����ǰ����ص�������Ϣ���ܱ�֤ѧϰ���������Ը��������³���ԡ�
��Ҫ����
- ������һ�����:�ڲ�ͬ��������,������Ϣ�ȿ������Ҳ������ֹѧϰ����������ʾ���ܵ���ߡ�
- Ϊ�˲�������Ϣ����������ê��֮��������ϵ,���ǽ�����һ���ṹ���ģ��(SCM)�����ǿ��Լ��ƶ�,������һ����Ч�Ļ�����,���������ͻ��ڴ˵�ê֮�����������ԡ�
- ���������һ���µķ���,��Ϊ�����ԶԱ�ѧϰ��Ԫ��������(ICL-MSR),ͨ��ʵʩ���ŵ����ƻ���SCM��
- �����ṩ����Χ�����۱�֤�;�������,��֤��ICLMSR���Ը��Ʋ�ͬ���Ƚ���CL���������ܡ�
3. ����
3.1 �ṹ���ģ��
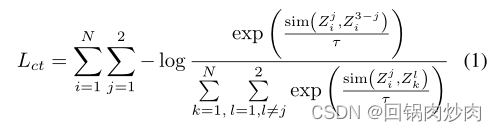
??��С��ʽ1���Խ��Ƶȼ���Ԥ��
X
i
3
?
j
X^{3-j}_i
Xi3?j?����ǩ
X
i
j
X^j_i
Xij?��Ȼ��,CL���漰��SCM������ʽ��Ϊͼ2��
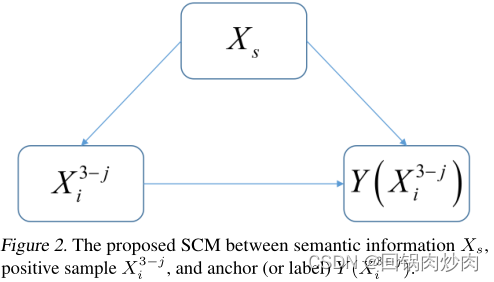
SCM�еĽڵ��ʾ��������ݱ���,������߱�ʾ(����)�����ϵ,����: X i 3 ? j �� Y ( X i 3 ? j ) X^{3-j}_i \rightarrow Y(X^{3-j}_i) Xi3?j?��Y(Xi3?j?)���� X i 3 ? j X^{3-j}_i Xi3?j?��ԭ��, Y ( X i 3 ? j ) Y(X^{3-j}_i) Y(Xi3?j?)�ǽ����
ͼ������
- X i 3 ? j �� Y ( X i 3 ? j ) X^{3-j}_i \rightarrow Y(X^{3-j}_i) Xi3?j?��Y(Xi3?j?): Y ( X i 3 ? j ) Y(X^{3-j}_i) Y(Xi3?j?)��ʾ X i 3 ? j X^{3-j}_i Xi3?j?��Ӧ�ı�ǩ���������ǩ�ȼ���ê��,����� Y ( X i 3 ? j ) = X i j Y(X^{3-j}_i)=X^{j}_i Y(Xi3?j?)=Xij?�������Ӽ��� X i 3 ? j X^{3-j}_i Xi3?j?Ӧ���� X i j X^{j}_i Xij?���ơ�
- X i 3 ? j �� X s �� Y ( X i 3 ? j ) X^{3-j}_i \leftarrow X_s \rightarrow Y(X^{3-j}_i) Xi3?j?��Xs?��Y(Xi3?j?): X s X_s Xs?��ʾ������Ϣ,������Ϊ��������ȡ�� f f f�ľ����ˡ����,���� X i 3 ? j �� X s X^{3-j}_i \leftarrow X_s Xi3?j?��Xs?�� X s �� Y ( X i 3 ? j ) X_s \rightarrow Y(X^{3-j}_i) Xs?��Y(Xi3?j?)���� X i 3 ? j X^{3-j}_i Xi3?j?�� Y ( X i 3 ? j ) Y(X^{3-j}_i) Y(Xi3?j?)��DZ�ڿռ��е�������ʾ���� f f f��ȡ��,ÿ��������ʾͨ����Ӧһ��������Ϣ��
- Ϊ��Ѱ�� X i 3 ? j X^{3-j}_i Xi3?j?�� Y ( X i 3 ? j ) Y(X^{3-j}_i) Y(Xi3?j?)֮�������������ϵ,������Ҫ�������Ԥ�� P ( Y ( X i 3 ? j ) �O d o ( X i 3 ? j ) ) P(Y(X^{3-j}_i)|do(X^{3-j}_i)) P(Y(Xi3?j?)�Odo(Xi3?j?))����� P ( Y ( X i 3 ? j ) �O X i 3 ? j ) P(Y(X^{3-j}_i)|X^{3-j}_i) P(Y(Xi3?j?)�OXi3?j?)���������ϵ��
3.2 ͨ�����ŵ������������Ԥ
������ȡ���ܹ���ȡ�뱳���������������ԭ��
- ����������̫��ֻ��һ��
??��Ŀ��ʽ1��ʾ,�������һ��ê��,ֻ��һ��������,���� 2 N ? 2 2N-2 2N?2��������������,�ڸ�������һЩ����(�ٸ�����)��������������ͬ��ǰ�����������е�ê�������������ͬ��ԭʼͼ�����ɵ�,ʹ������������֮���ǰ���ͱ������ơ�����С��Ŀ��ʽ1ʱ,���������̫��,��������֮�乲����ǰ���ͱ������ܻ�һ������������ê�㡣������ê������ͬ������Ϣ�ļٸ��������й۲졣���,���ٸ�������ê����Զ,��Ҫ�ǽ���ǰ�����ƶȡ�Ҳ����˵,����һ���̶��Ͽ��ܴ�ʹ ����ק�� �����������ӵı��������,���������õõ�����ǿ�����ʹ�������ĶԱ�ѧϰģ���ܹ���ȡ�뱳����ص�����������
���ŵ���
??���ŵ����������ǿ��Թ۲�ͷֲ�������������SCM��,������������
X
s
X_s
Xs?��,���ǿ��Խ���ֲ�Ϊ��ͬ����������,����:
X
s
=
{
Z
s
i
}
i
=
1
i
=
n
X_s=\{Z^i_s\}^{i=n}_{i=1}
Xs?={Zsi?}i=1i=n?,����
Z
s
i
Z^i_s
Zsi?��ʾ���������ķֲ㡣��ʽ��,SCM�ĺ��ŵ���������ʾ:
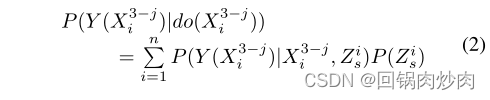
����
P
(
Y
(
X
i
3
?
j
)
�O
d
o
(
X
i
3
?
j
)
)
P(Y(X^{3-j}_i)|do(X^{3-j}_i))
P(Y(Xi3?j?)�Odo(Xi3?j?))��ʾ
X
i
3
?
j
X^{3-j}_i
Xi3?j?��
Y
(
X
i
3
?
j
)
Y(X^{3-j}_i)
Y(Xi3?j?)֮�����ʵ�����ϵ��
4. ����
4.1 Ԫ��������
??Ϊ�˲�ʧһ����,���ǽ�������ȡ�� f f f����� Z i j Z^j_i Zij?��ά����ʾΪ w �� h �� c w��h��c w��h��c,���� w w wΪ����, h h hΪ�߶�, c c cΪ����ͨ�������������˵,���Ǽ� Z i j Z^j_i Zij?Ϊ Z i j = [ Z i , 1 j , . . . , Z i , c j ] Z^j_i=[Z^j_{i,1},...,Z^j_{i,c}] Zij?=[Zi,1j?,...,Zi,cj?],���� Z i , r j �� R w �� h Z^j_{i,r} \in R^{w��h} Zi,rj?��Rw��h��ʾ Z i j , r �� { 1 , . . . , c } Z^j_i,r\in \{1,...,c\} Zij?,r��{1,...,c}��
ע��:�����κ�Ԥ��ѵ���Ļ���CNN��������ȡ��,ÿ��ͨ����Ӧһ��������Ϣ���Ӿ����Ȼ��,�õ���ͨ������һ���Ӿ������Ǻ����ѵġ����,���ʹ����Ϊÿ��������ϢѰ��һ��Ȩ�����������ǵ��뷨��,ÿ��������Ϣ��Ӧ��ͨ����һ���Ӽ������,������ͨ���Ӽ���ȨֵӦ�úܴ�,���Ӽ�֮���ͨ����ȨֵӦ�ú�С��
??����һ��Ȩ����
a
t
=
[
a
1
,
t
,
.
.
.
,
a
c
,
t
]
T
a_t=[a_{1,t},...,a_{c,t}]^T
at?=[a1,t?,...,ac,t?]T,���DZ�ʾ
Z
s
t
Z^t_s
Zst?�ĺ���ʵ��Ϊ
Z
s
t
=
a
t
Z^t_s=a_t
Zst?=at?,��
P
(
Z
s
t
)
=
1
/
n
P(Z^t_s)=1/n
P(Zst?)=1/n��Ȼ��,���DZ�ʾ
P
(
Y
(
X
i
3
?
j
)
�O
X
i
3
?
j
,
Z
s
t
)
P(Y(X^{3-j}_i)|X^{3-j}_i,Z^t_s)
P(Y(Xi3?j?)�OXi3?j?,Zst?)�ĺ���ʵ��Ϊ:
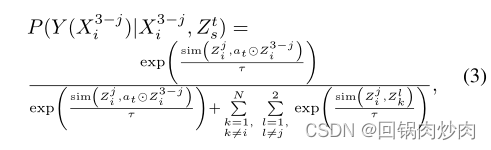
����
a
t
��
Z
i
3
?
j
=
[
a
1
,
t
?
Z
i
,
1
3
?
j
,
.
.
.
,
a
c
,
t
?
Z
i
,
c
3
?
j
]
a_t\odot Z^{3-j}_i=[a_{1,t}��Z^{3-j}_{i,1},...,a_{c,t}��Z^{3-j}_{i,c}]
at?��Zi3?j?=[a1,t??Zi,13?j?,...,ac,t??Zi,c3?j?]�����,������ŵ������Ϊ:
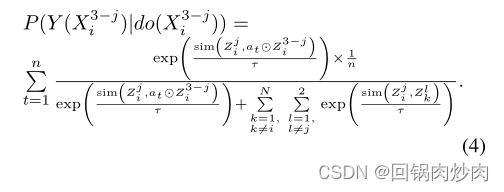
??�����Ԫ�������������Կ�����һ����ѧϰ��ģ��
f
m
s
r
f_{msr}
fmsr?,��ģ������������ص�Ȩֵ����
A
s
A_s
As?,��ͨ������������ʵ��,����
A
s
=
[
a
1
,
.
.
.
,
a
n
]
A_s=[a_1,...,a_n]
As?=[a1?,...,an?]������˵,����һ����������
X
X
X,�������ȵõ�������������
{
X
1
,
X
2
}
\{X^1, X^2\}
{X1,X2}��
X
X
X���뵽һ�����������ǿģ�顣Ȼ��
X
X
X����
f
m
s
r
f_{msr}
fmsr?ģ��,�õ�Ȩ�ؾ���
A
s
A_s
As?,������������
{
X
1
,
X
2
}
\{X^1, X^2\}
{X1,X2}ֻ��һ��Ȩ�ؾ���
A
s
A_s
As?��
4.2 ģ��Ŀ��
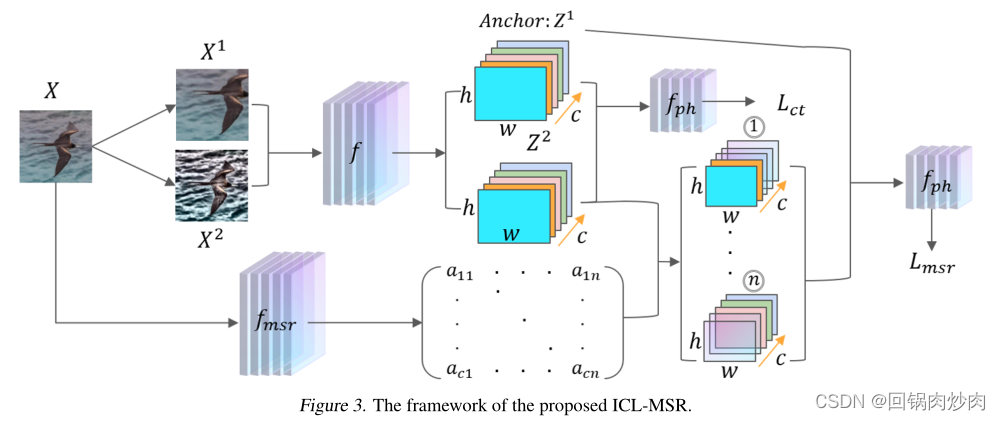
??ICL-MSR��������ȡ��
f
f
f��Ԫ����������
f
m
s
r
f_{msr}
fmsr?��ͶӰͷ
f
p
h
f_{ph}
fph?����ģ����ɡ�Ԫ������������������ȡ��һ��ѵ��,ÿ��ʱ���������Ρ���һ��ʹ��������ǿѵ�����ݼ�
X
t
r
a
u
g
X^{aug}_{tr}
Xtraug?���������Ȩ����
A
s
A_s
As?ѧϰ
f
f
f��
f
p
h
f_{ph}
fph?���ڵڶ���,ͨ������
f
m
s
r
f_{msr}
fmsr?����ڶԱ���ʧ���ݶ�������
f
m
s
r
f_{msr}
fmsr?��
��ÿ��epoch�ĵ�һ��,ͨ����С��Ŀ��
L
t
o
L_{to}
Lto?������
f
f
f��
f
p
h
f_{ph}
fph?�IJ���,���Ա�ʾΪ:
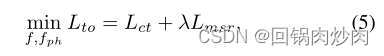
����
L
c
t
L_{ct}
Lct?ΪĿ��1,
��
\lambda
��������,
L
m
s
r
L_{msr}
Lmsr?Ϊ:
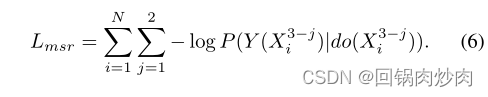
��ÿ���εĵڶ���,Ϊ��ѧϰ
f
m
s
r
f_{msr}
fmsr?�IJ���,���������һ������Ԫѧϰ��ѵ�����ơ�Ҳ����˵,
f
m
s
r
f_{msr}
fmsr?ͨ��ѡ��Ȩ�ؾ���������,���ʹ��Ȩ�ؾ���ѵ��
f
f
f��
f
p
h
f_{ph}
fph?,�����Ա�ѧϰ�����ܽ�����ͬ��ѵ�����������������˵,����������ѧϰ��
��
��
������
f
f
f��
f
p
h
f_{ph}
fph?һ��,��������:
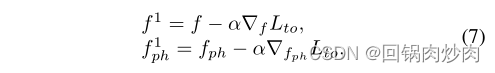
���������¿��Կ�����ѧϰ��һ���õ�
f
f
f��һ���õ�
f
p
h
f_{ph}
fph?��������һ��,
f
1
f^1
f1��
f
p
h
1
f^1_{ph}
fph1?���Կ�����
f
m
s
r
f_{msr}
fmsr?�ĺ���,��Ϊ
?
f
L
t
o
?_fL_{to}
?f?Lto?��
?
f
p
h
L
t
o
?_{f_{ph}}L_{to}
?fph??Lto?��
f
m
s
r
f_{msr}
fmsr?�йء�Ȼ��,����ͨ����С����������������
f
m
s
r
f_{msr}
fmsr?:
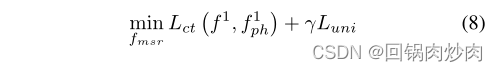
����
��
��
���dz�����,
L
c
t
(
f
1
,
f
p
h
1
)
L_{ct}(f^1, f^1_{ph})
Lct?(f1,fph1?)��ʾ��ʧ
L
c
t
L_{ct}
Lct?�ǻ��ڲ���
f
1
f^1
f1��
f
p
h
1
f^1_{ph}
fph1?�����,��
L
u
n
i
L_{uni}
Luni?�Ǿ�����ʧ,ּ��Լ��
A
s
A_s
As?��Ԫ�صķֲ�,�Խ��ƾ��ȷֲ�,�Ӷ��������Ӿ�������Ծ����ܲ�һ�¡����ڸ�˹�ƺ�,
L
u
n
i
L_{uni}
Luni?���Ա�ʾΪ:
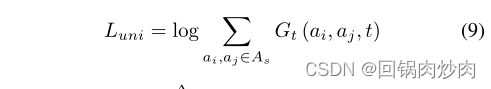
ʽ��
G
t
(
a
i
,
a
j
,
t
)
?
e
x
p
(
2
t
?
a
i
T
a
j
?
2
t
)
G_t(a_i,a_j,t)\triangleq exp(2t��a_i^Ta_j?2t)
Gt?(ai?,aj?,t)?exp(2t?aiT?aj??2t),
t
t
tΪ�̶���������
??��������С��Ŀ��8Ϊʲô����ʹ f m s r f_{msr} fmsr?ѧϰ������Ϣ����Ҫע�����,ֻ������֮�乲����������Ϣ������ʾ X i 3 ? j X^{3?j}_i Xi3?j?�� Y ( X i 3 ? j ) Y(X^{3?j}_i) Y(Xi3?j?)����,�Ӷ���С���Ա���ʧ��ͨ��SCM���Կ���,������������Ϣ�����˱�����Ϣ��ǰ����Ϣ��Ŀ��8�����˼������С���Ա���ʧ,�Ա� f m s r f_{msr} fmsr?ѧϰ������������Ϣ����һ��Ҳ���Կ������� L c t L_{ct} Lct?�Ļ�������һ�δٽ� L c t L_{ct} Lct?��ѧϰ,������ѧϰѧϰ����Ҳ�����dz���ΪԪ������������ԭ��
5. ����������
??�����������������۴����������ѧϰ���������ܡ����,��������˻���ͨ����С����ͳ��������ʧ��ѵ��softmax�������ķ��������ICL-MSR��������(GEB)������ L S M ( f ; T ) = i n f W L C E ( W ? f ; T ) L_{SM}(f;T) = inf_WL_{CE}(W��f;T) LSM?(f;T)=infW?LCE?(W?f;T),���� W W WΪ���Է�����, T T TΪ��ǩ����������Ƕ�� f ( X ) f(X) f(X),��������� L S M T ( f ) = E X [ L S M ( f ; T ) ] L^T_{SM}(f) = E_X[L_{SM}(f;T)] LSMT?(f)=EX?[LSM?(f;T)]��Ȼ�������о������ַ������ L S M T ( f ) L^T_{SM}(f) LSMT?(f)��Ա�ѧϰĿ�� L c t L_{ct} Lct?֮��IJ�ࡣ
����5.1
��
f
?
��
a
r
g
m
i
n
f
L
c
l
+
��
L
m
s
r
f^*\in argmin_fL_{cl}+\lambda L_{msr}
f?��argminf?Lcl?+��Lmsr?��������
1
?
��
1?��
1?���ĸ���
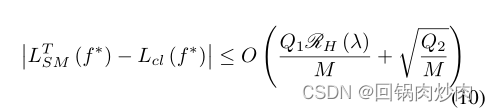
����MΪѵ����������,NΪС�����Ĵ�С,
Q
1
=
1
+
1
/
N
,
Q
2
=
l
o
g
(
1
/
��
)
?
l
o
g
2
(
M
)
Q_1=\sqrt {1 + 1/N},Q_2 = log (1/��)��log^2 (M)
Q1?=1+1/N?,Q2?=log(1/��)?log2(M),
R
H
(
��
)
R_H (��)
RH?(��)ΪRademacher���Ӷȡ�ͬʱ,
R
H
(
��
)
R_H (��)
RH?(��)��
��
��
���ʵ����ݼ���ϵ��
��ʽ10��ʾ,���ǿ��Եõ���������ѵ��������СM�����Ӷ���С��ע��,����۲����봫ͳ�ļලѧϰ������һ�µġ�����,���ǿ��Կ�������� Q 2 / N \sqrt{Q_2/N} Q2?/N?�е�С������СN���ڴ�������СN�ǿ��Ժ��Ե�,�����������,��Դ�ijߴ�N����Ч�ؼ��ٵ�һ����� Q 1 R H ( �� ) Q_1R_H (��) Q1?RH?(��),�Ӷ��ս����硣���,������������������ʱ,Rademacher���Ӷ� R H R_H RH?Ҳ�ή��,�Ӷ���һ����С������,����˶Ա�ѧϰ�㷨�ķ����ԡ�
6. ʵ����