文章目录
ELMo
ELMo 是 Embedding from Language Model 的缩写,它通过无监督的方式对语言模型进行预训练来学习单词表示
这篇论文的想法其实非常简单,但是效果却很好。它的思路是用深度的双向 Language Model 在大量未标注数据上训练语言模型,如下图所示

在实际任务中,对于输入的句子,我们使用上面的语言模型来处理它,得到输出向量,因此这可以看作是一种特征提取。但是 ELMo 与普通的 Word2Vec 或 GloVe 不同,ELMo 得到的 Embedding 是有上下文信息的
GPT(Generative Pre-training Transformer)
GPT 得到的语言模型参数不是固定的,它会根据特定的任务进行调整(通常是微调),这样的到的句子表示能更好的适配特定任务。它的思想也很简单,使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,然后根据具体任务对 Transformer 的参数进行微调。GPT 与 ELMo 有两个主要的区别:
-
模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 transformer decoder
-
针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型
ELMo、GPT 的问题
ELMo 和 GPT 最大的问题就是传统的语言模型是单向的 ―― 我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子 The animal didn’t cross the street because it was too tired。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。传统的语言模型,都只能利用单方向的信息。比如前向的 RNN,在编码 it 的时候它看到了 animal 和 street,但是它还没有看到 tired,因此它不能确定 it 到底指代什么。如果是后向的 RNN,在编码的时候它看到了 tired,但是它还根本没看到 animal,因此它也不能知道指代的是 animal。Transformer 的 Self-Attention 理论上是可以同时关注到这两个词的,但是根据前面的介绍,为了使用 Transformer 学习语言模型,必须用 Mask 来让它看不到未来的信息,所以它也不能解决这个问题的
注意:即使 ELMo 训练了双向的两个 RNN,但是一个 RNN 只能看一个方向,因此也是无法 “同时” 利用前后两个方向的信息的。也许有的读者会问,我的 RNN 有很多层,比如第一层的正向 RNN 在编码 it 的时候编码了 animal 和 street 的语义,反向 RNN 编码了 tired 的语义,然后第二层的 RNN 就能同时看到这两个语义,然后判断出 it 指代 animal。理论上是有这种可能,但是实际上很难。举个反例,理论上一个三层(一个隐层)的全连接网络能够拟合任何函数,那我们还需要更多层的全连接网络或者 CNN、RNN 干什么呢?如果数据量不是及其庞大,或者如果不对网络结构做任何约束,那么它有很多种拟合的方法,其中大部分是过拟合的。但是通过对网络结构的约束,比如 CNN 的局部特效,RNN 的时序特效,多层网络的层次结构,对它进行了很多约束,从而使得它能够更好的收敛到最佳的参数。我们研究不同的网络结构(包括 Resnet、Dropout、BatchNorm 等等)都是为了对网络增加额外的(先验的)约束
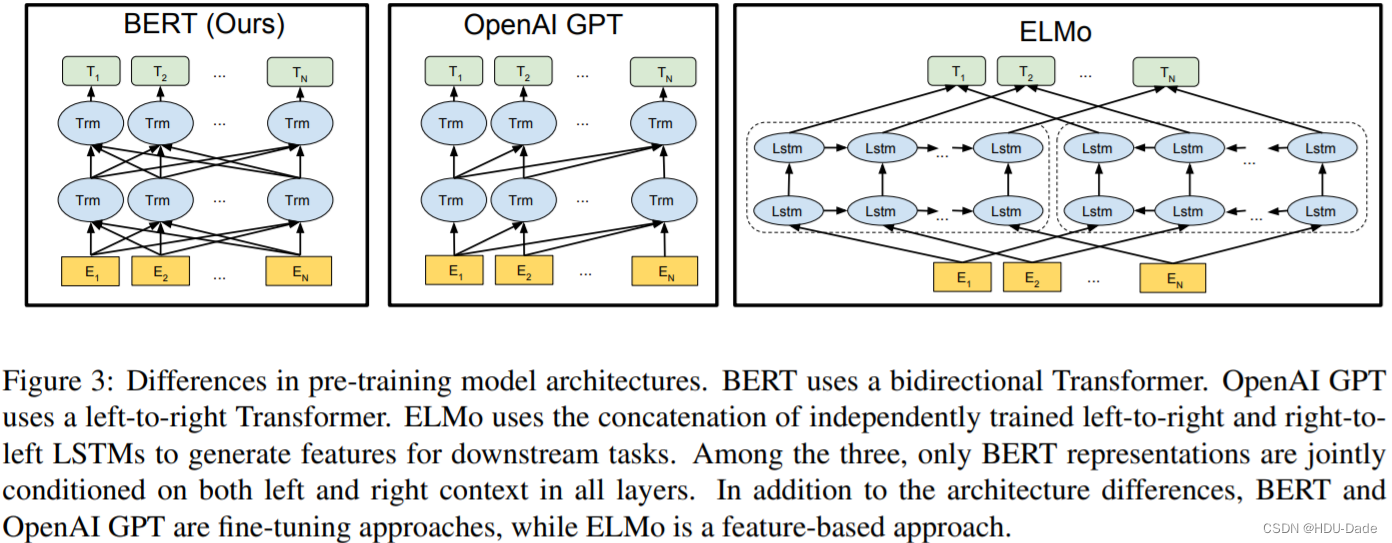
BERT
BERT 全称为 Bidirectional Encoder Representation from Transformer,是 Google 以无监督的方式利用大量无标注文本「炼成」的语言模型,其架构为 Transformer 中的 Encoder(BERT=Encoder of Transformer)
以往为了解决不同的 NLP 任务,我们会为该任务设计一个最合适的神经网络架构并做训练,以下是一些简单的例子
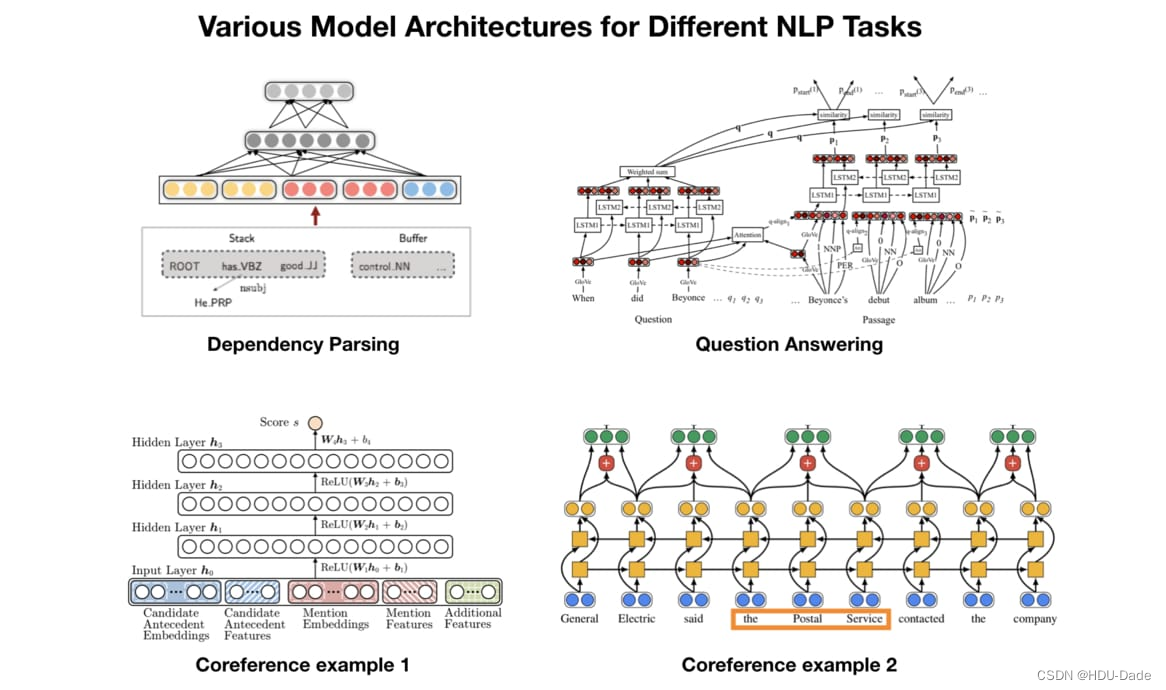
不同的 NLP 任务通常需要不同的模型,而设计这些模型并测试其 performance 是非常耗成本的(人力,时间,计算资源)。如果有一个能直接处理各式 NLP 任务的通用架构该有多好?
随着时代演进,不少人很自然地有了这样子的想法,而 BERT 就是其中一个将此概念付诸实践的例子
Google 在预训练 BERT 时让它同时进行两个任务:
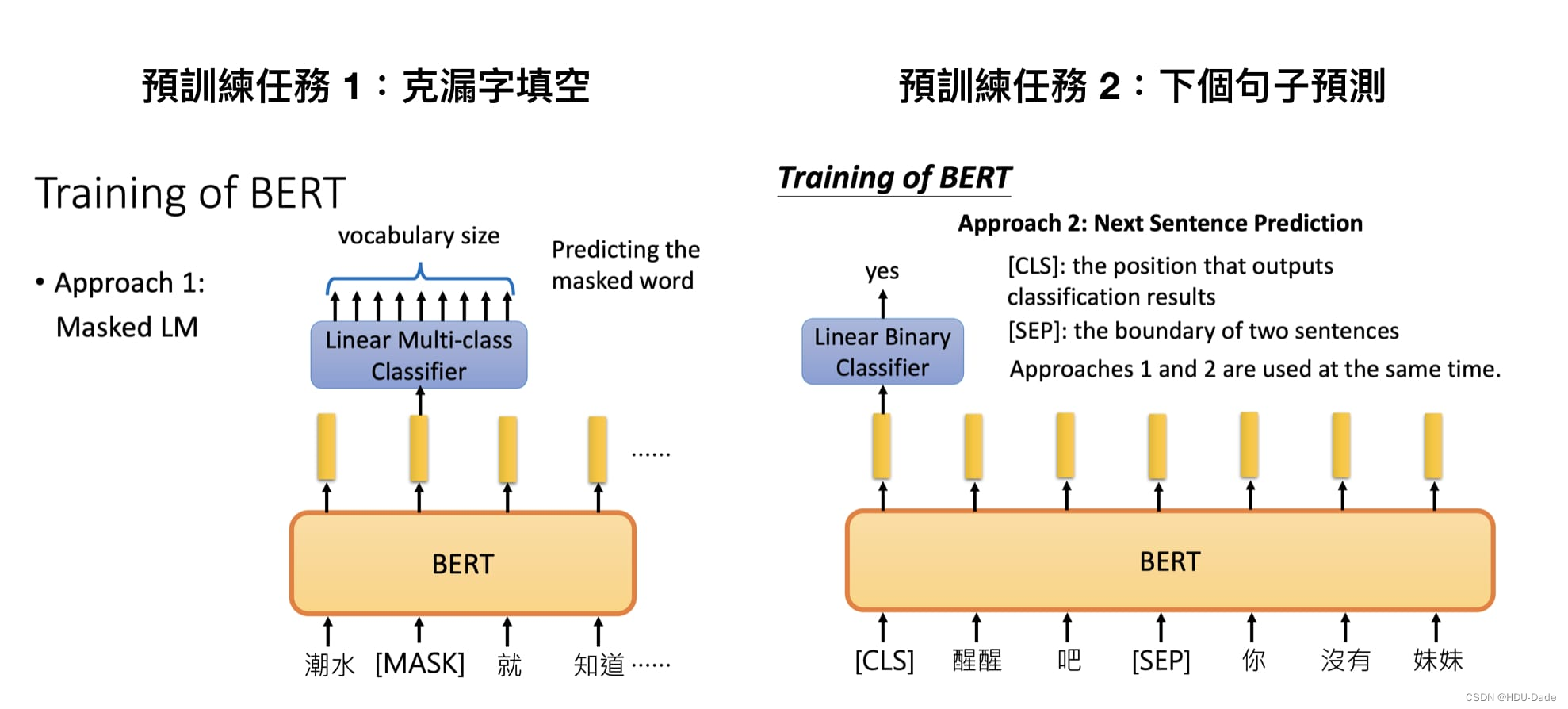
-
漏字填空(完型填空), Masked Language Model(MLM)
-
判断第 2 个句子在原始本文中是否跟第 1 个句子相接(Next Sentence Prediction)
对正常人来说,要完成这两个任务非常简单。只要稍微看一下前后文context就知道完形填空任务中 [MASK] 里应该填退了;而醒醒吧后面接你没有妹妹也十分合理
BERT 语言模型任务一:Masked Language Model
在 BERT 中,Masked LM(Masked Language Model)构建了语言模型,简单来说,就是随机遮盖或替换一句话里面的任意字或词,然后让模型通过上下文预测那一个被遮盖或替换的部分,之后做 Loss 的时候也只计算被遮盖部分的 Loss,这其实是一个很容易理解的任务,实际操作如下:
-
随机把一句话中 15% 的 token(字或词)替换成以下内容:
- 这些 token 有 80% 的几率被替换成 [MASK],例如 my dog is hairy→my dog is [MASK]
-
有 10% 的几率被替换成任意一个其它的 token,例如 my dog is hairy→my dog is apple
-
有 10% 的几率原封不动,例如 my dog is hairy→my dog is hairy
-
之后让模型预测和还原被遮盖掉或替换掉的部分,计算损失的时候,只计算在第 1 步里被随机遮盖或替换的部分,其余部分不做损失,其余部分无论输出什么东西,都无所谓
这样做的好处是,BERT 并不知道 [MASK] 替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的 apple 可能是被替换的词。这样强迫模型在编码当前时刻词的时候不能太依赖当前的词,而要考虑它的上下文,甚至根据上下文进行 “纠错”。比如上面的例子中,模型在编码 apple 时,根据上下文 my dog is,应该把 apple 编码成 hairy 的语义而不是 apple 的语义
BERT 语言模型任务二:Next Sentence Prediction
我们首先拿到属于上下文的一对句子,也就是两个句子,之后我们要在这两个句子中加一些特殊的 token:
[CLS]上一句话[SEP]下一句话[SEP]
也就是在句子开头加一个 [CLS],在两句话之间和句末加 [SEP],具体地如下图所示
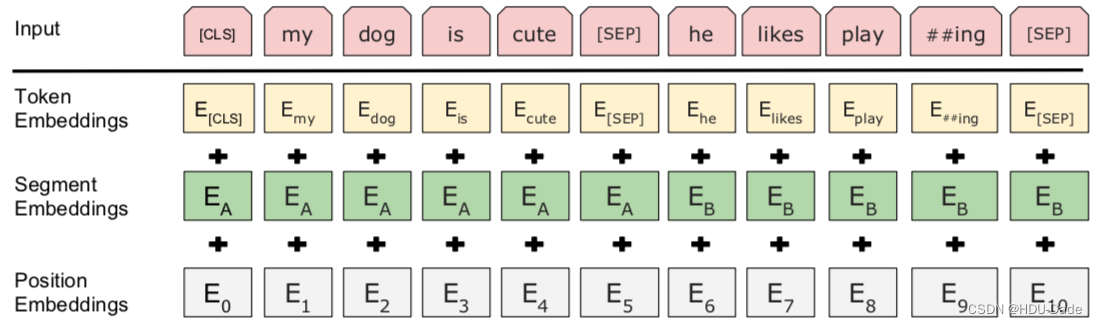
可以看到,上图中的两句话明显是连续的。如果现在有这么一句话
[CLS]我的狗很可爱[SEP]企鹅不擅长飞行[SEP],
可见这两句话就不是连续的。在实际训练中,我们会让这两种情况出现的数量为 1:1
-
Token Embedding 就是正常的词向量,即 PyTorch 中的 nn.Embedding()
-
Segment Embedding 的作用是用 embedding 的信息让模型分开上下句,我们给上句的 token 全 0,下句的 token 全 1,让模型得以判断上下句的起止位置,例如
[CLS]我的狗很可爱[SEP]企鹅不擅长飞行[SEP] 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 -
Position Embedding 和 Transformer 中的不一样,不是三角函数,而是学习出来的
Multi-Task Learning
BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加,例如
Input:
[CLS] calculus is a branch of math [SEP] panda is native to [MASK] central china [SEP]
Targets: false, south
----------------------------------
Input:
[CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton and leibniz [SEP]
Targets: true, branch, was
Fine-Tuning
BERT 的 Fine-Tuning 共分为 4 中类型
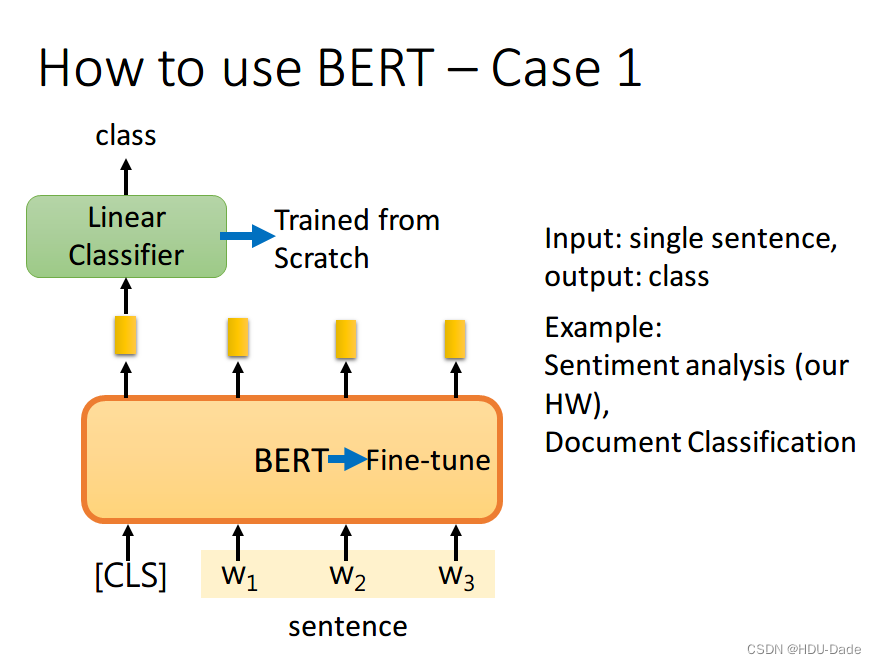
如果现在的任务是 classification,首先在输入句子的开头加一个代表分类的符号 [CLS],然后将该位置的 output,丢给 Linear Classifier,让其 predict 一个 class 即可。整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调就可以了
为什么要用第一个位置,即 [CLS] 位置的 output。因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以 [CLS] 的 output 里面肯定含有整句话的完整信息,这是毋庸置疑的。但是 Self-Attention 向量中,自己和自己的值其实是占大头的,现在假设使用的 output 做分类,那么这个 output 中实际上会更加看重 ,而 又是一个有实际意义的字或词,这样难免会影响到最终的结果。但是 [CLS] 是没有任何实际意义的,只是一个占位符而已,所以就算 [CLS] 的 output 中自己的值占大头也无所谓。当然你也可以将所有词的 output 进行 concat,作为最终的 output
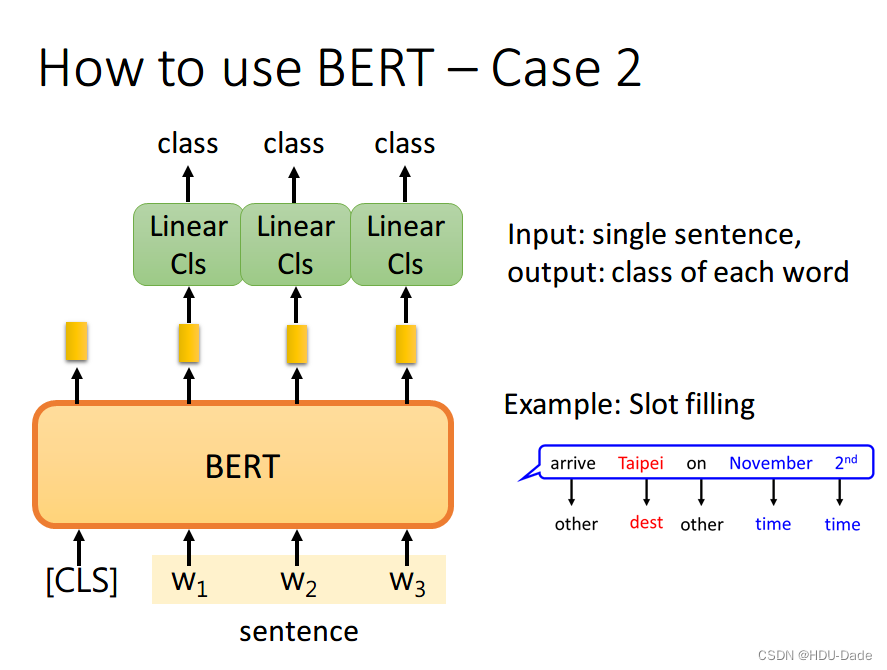
如果现在的任务是 Slot Filling,将句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别
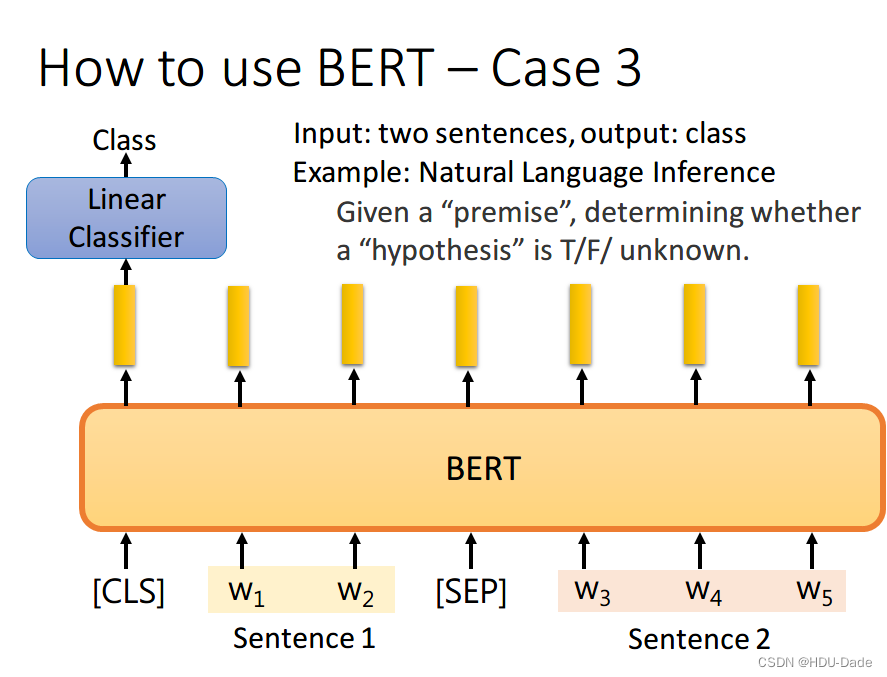
如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和 Case 1 差不多,对 [CLS] 的 output 进行预测即可
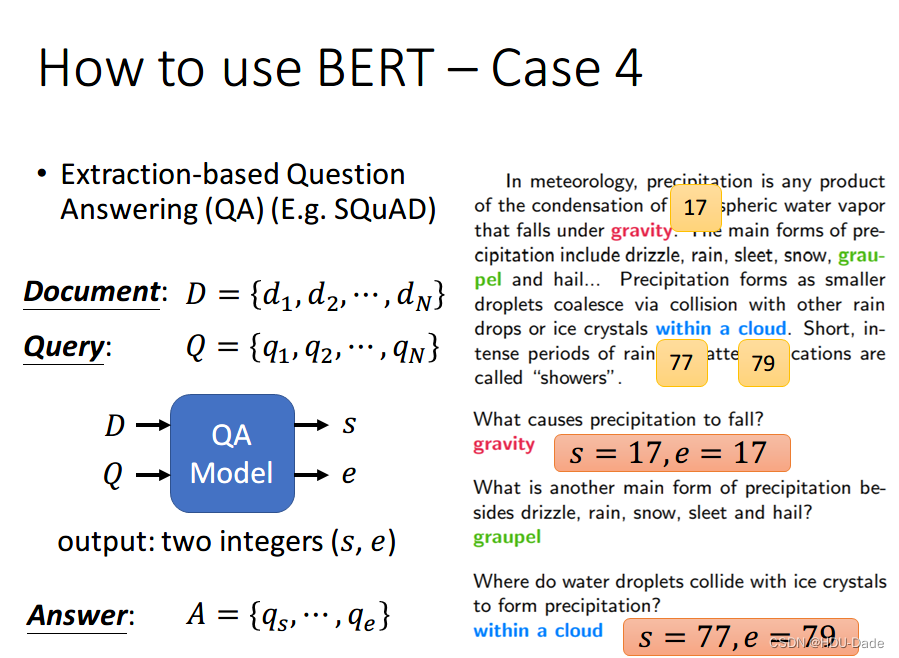
首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。此时我们还要训练两个 vector,即上图中橙色和黄色的向量。首先将橙色和所有的黄色向量进行 dot product,然后通过 softmax,看哪一个输出的值最大,例如上图中 对应的输出概率最大,那我们就认为 s=2
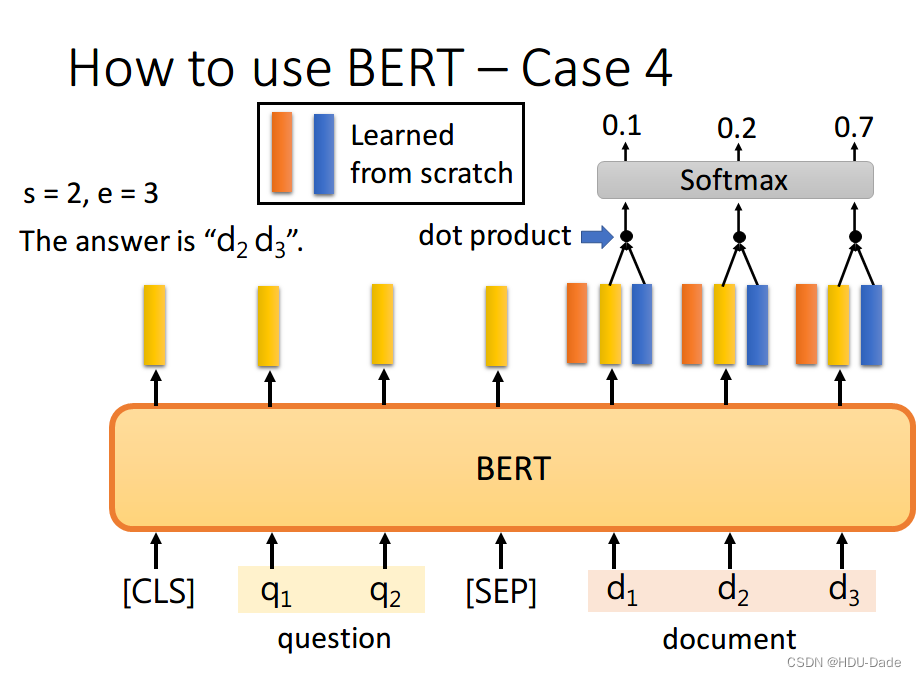
同样地,我们用蓝色的向量和所有黄色向量进行 dot product,最终预测得 的概率最大,因此 e=3。最终,答案就是 s=2,e=3
你可能会觉得这里面有个问题,假设最终的输出 s>e 怎么办,那不就矛盾了吗?其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案