������������ʦ����ľͷ��ʦ��Ƶ��ѧϰ�ʼ�
Ȩ��˥��
һ��ģ�͵IJ���Խ����ôģ�͵�������Խ��(ģ���ܶ�������ϵij̶�),Ϊ�˷�ֹģ�������ʱ������Ҫ����ģ�͵�����,����ͨ�����Ʋ���ֵ�ķ�Χ��������Сģ��������Ŀ�ġ�
m
i
n
??
l
(
w
,
b
)
s
u
b
j
e
c
t
??
t
o
�O
�O
w
�O
�O
2
��
��
min\; \mathscr{l}(w,b) \quad subject\; to \quad ||w||^2 \leq \theta
minl(w,b)subjectto�O�Ow�O�O2����
��
\theta
��ԽС������ԽС
����һ��Լ������Ϊ
�O
�O
w
�O
�O
2
��
��
||w||^2\leq \theta
�O�Ow�O�O2������������ֵ����,ʹ���������ճ��ӷ����,��ô����:
m
i
n
??
l
(
w
,
b
)
+
��
2
(
�O
�O
w
�O
�O
2
?
��
)
min\;\mathscr{l}(w,b)+\cfrac{\lambda}{2}\big(||w||^2-\theta\big)
minl(w,b)+2��?(�O�Ow�O�O2?��)
������
��
\lambda
����
��
\theta
��֪��һ�Ϳ��Խ����һ��,���Կ��Եȼ�Ϊ:
m
i
n
??
l
(
w
,
b
)
+
��
2
�O
�O
w
�O
�O
2
min\;\mathscr{l}(w,b)+\cfrac{\lambda}{2}||w||^2
minl(w,b)+2��?�O�Ow�O�O2
��֤��
��
��
��
w
?
��
0
\lambda\rightarrow\infty\quad w^*\rightarrow 0
������w?��0ʹ��
��
\lambda
������
��
\theta
��
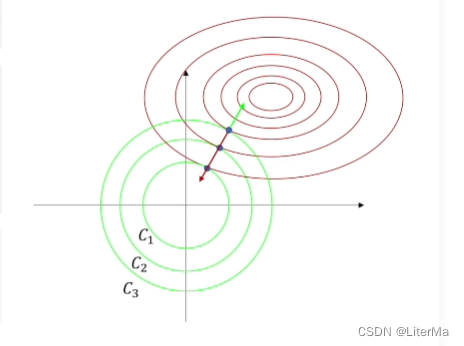
����ͼ��
C
C
C����
��
\theta
��������������Ϊ
w
w
w�Ĵ�С,�ɼ�
C
C
CԽ��
w
w
wԽС�����˿���ģ�����������á�
��ô�ݶȵļ���Ͳ������¾ͱ�Ϊ��:
�ݶ�:
?
?
w
(
l
(
w
,
b
)
+
��
2
�O
�O
w
�O
�O
2
)
??
=
??
l
(
w
,
b
)
?
w
+
��
w
\cfrac{\partial}{\partial w}\big ( \mathscr l(w,b)+\cfrac{\lambda}{2}||w||^2 \big )\;=\; \cfrac{\mathscr l (w,b)}{\partial w}+\lambda w
?w??(l(w,b)+2��?�O�Ow�O�O2)=?wl(w,b)?+��w
��ȡ��������������¹�ʾ:
w
t
+
1
=
(
1
?
��
��
)
w
t
?
��
?
l
(
w
t
,
b
t
)
?
w
t
w_{t+1}=(1-\eta\lambda)w_t-\eta\cfrac{\partial \mathscr l(w_t,b_t)}{\partial w_t}
wt+1?=(1?����)wt??��?wt??l(wt?,bt?)?
��
��
��
<
1
\lambda\eta<1
����<1ʱ����Ȩ��˥�ˡ�
������
�������������Ԫ��
x
i
x_i
xi?�������Ŷ�:
{
0
,
p
r
o
b
a
b
i
l
i
t
y
??
p
x
i
1
?
p
,
o
t
h
e
r
i
s
e
\left\{\begin{matrix}0,\quad probability \;p \\\cfrac{x_i}{1-p},\quad otherise\end{matrix}\right.
?
?
??0,probabilityp1?pxi??,otherise?
�������Ŷ�����ÿ��
x
i
x_i
xi?��������Ϊ
x
i
x_i
xi?
E
(
x
i
��
)
=
0
?
p
+
(
1
?
p
)
?
x
i
1
?
p
=
x
i
E(x_i^{'})=0\cdot p+(1-p)\cdot \cfrac{x_i}{1-p}=x_i
E(xi��?)=0?p+(1?p)?1?pxi??=xi?
��������һЩ���ز������������Ϊ0,�Ӷ�������ģ���Ӷ�,�䶪������Ϊ����ģ���Ӷȵij�������
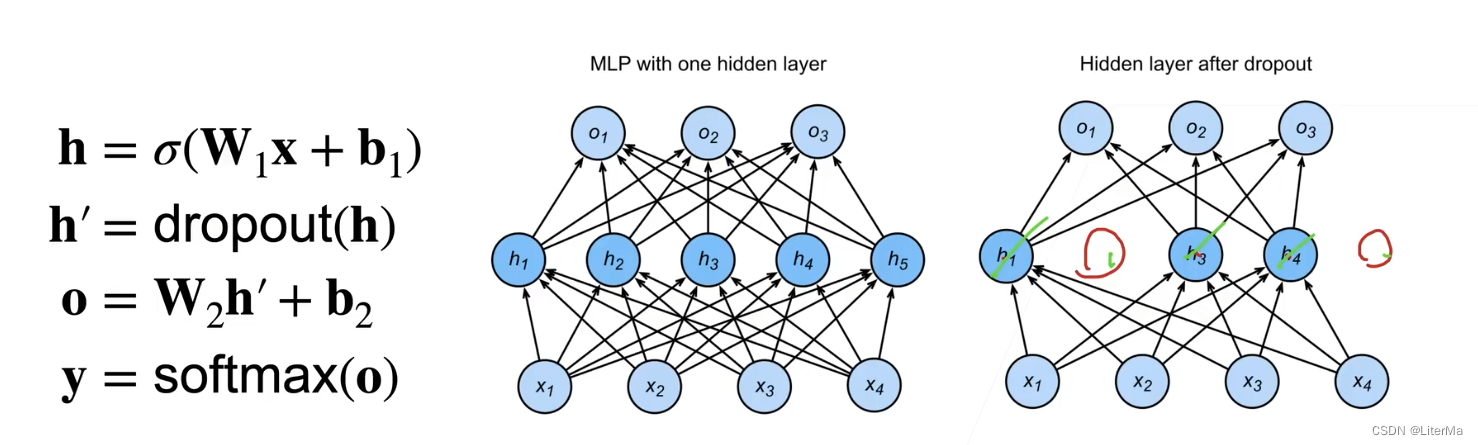
dropoutֻ��ѵ��ʱ����,���ڵ�������,������ʱ����ʹ�á�