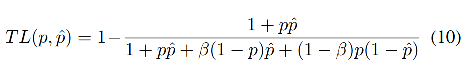����Ŀ¼
- һ���ָ������
- ����2D ���ݼ�����
- ��������ָ��
- �ġ�Loss ����
һ���ָ������
ͼ��ָ��ǻ����Ӿ������һ����Ҫ��������,��ͼ��������Զ���ʻ����Ƶ��صȷ��涼�к���Ҫ�����á�ͼ��ָ���Ա�����һ����������,��Ҫ��ÿ�����ؽ��з���,���Ծͱ�ͼ�����������Ӹ��ӡ��˴���Ҫ���� DL-based ������
mmsegmentation �ָ�����ṹͨ��ģʽ:
-
encoder:����ͼ���resize���ض���С������ backbone���õ�����ͼ
-
��ѡ:decode_head[0]:����ͼ��FCN���������ͼ�����Ȩ�ص� loss(Ȩ��0.4)
-
��ѡ:decode_head[1]:����ͼ���ض�����ͷ(psp/ocr��)���������ͼ�����Ȩ�ص� loss(Ȩ��1.0)
�ָ���Ҫ���ٵ����⼰��Ӧ�����н������:
- �ٶȺ��ڴ�����,��Ҫ���ͷֱ���,ȱʧ�˴���ϸ����Ϣ:�༶�����ںϡ����;����������Ұ
- �ϲ�����ʽ���µ���Ϣ��ʧ:Deconvolution Network ,encoder-decoder ����,ͨ���Ż� decoder ��������߶�ϸ�������Ķ�λ����
- ����ֻ�ܿ��Ǿֲ���Ϣ,��ʧ��ȫ����Ϣ:attention
- Ŀ���С���ϴ�:��߶��ںϡ��������ʾ������ں�����
�����:
[1] Image Segmentation Using Deep Learning: A Survey
[2] A survey of loss functions for semantic segmentation
1.1 Fully Convolutional Networks [2015]
1.1.1 FCN
����:Fully convolutional networks for semantic segmentation
����ָ���Կ���һ������ģ��,Ψһ���ӵĵط�������Ҫ��ͼ���е�ÿ�����ؽ��з��ࡣ
����ģ��һ�㶼�ǽ�����ͬ��С������ͼ��,�����ռ����ꡣ��ʹ�õ�ȫ���Ӳ���Ա�����һ�����ܹ�����ȫ��Ԫ�صľ����㡣
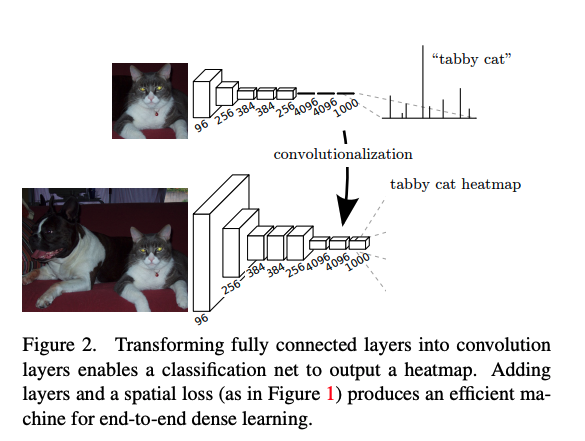
����,�Ƿ���ʹ��ȫ�������������ȫ����������?
���ǿ��Ե�,ʹ��ȫ�������绹�����˱���ʹ�á���ͬ��С�����롱������,���������ת����ͼ 2 ��ʾ��
FCN �����ǵ�һ���������ѧϰ�ķָ��,ֻ����������,�������������С��ͼȻ��������ָ���ͼ��
��δӷ������� dense FCN:
backbone:VGG-16(�� VGG-19 ��Ч������)�� GoogLeNet(ʹ������ loss ��)
ʹ�� backbone �ķ�ʽ:ȥ�����һ������,ʹ�� 1x1 ������ͨ������ɷָ�������(PASCAL ��ʹ�� 21,����һ��Ϊ����),Ȼ��ʹ�� deconvolution ���ϲ�����
������λ�ý��н��:
��ͼ 3 ��ʾ,���߲��ý��㼶�������н�ϵķ�ʽ����ϸ���ָ������ڿռ��ϵ����Ԥ�⡣
���:
- FCN-32s:ֱ�ӽ� pool5 �����,�ϲ�����ԭͼ��С,��Ԥ��,��ͼ 4 ���Կ���,Ԥ��Ľ���dz��ֲ�(mIoU 59.4)
- FCN-16s:�� pool5 �ϲ��� 2 ��,�� pool 4 �����������,Ȼ���ϲ�����ԭͼ��С,������ 32s �ľ�ϸһЩ(mIoU 62.4)
- FCN-8s:�� pool5(�ϲ���2��)�� pool4 ��Ӻ������,���ϲ��� 2 ��,Ȼ��� pool3 ���,�õ� FCN-8s ����(mIoU 62.7)
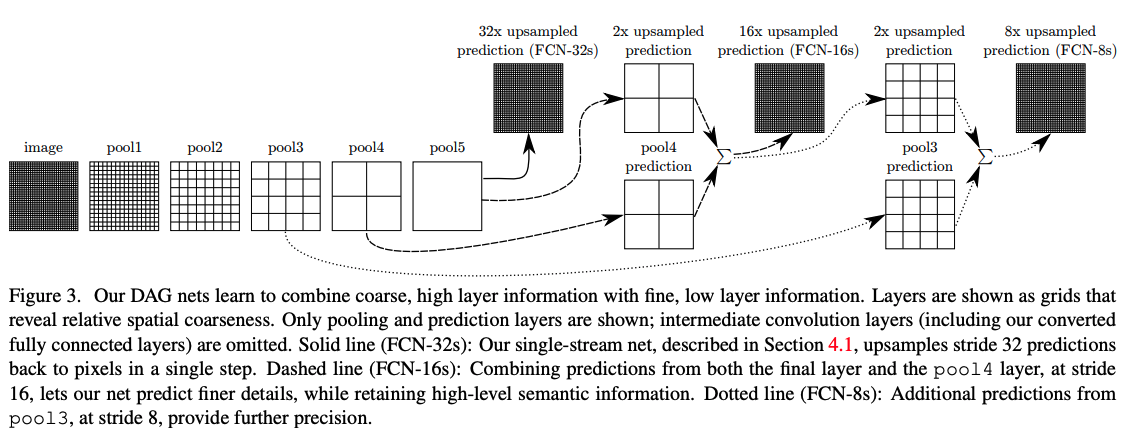
��ͼ 4 Ҳ�ܿ���,��dz������������������н��֮��,�ܹ������罫ȫ�ֺ;ֲ����������н��,��ȫ�ֵ�������ָ���ֲ�������Ԥ�⡣
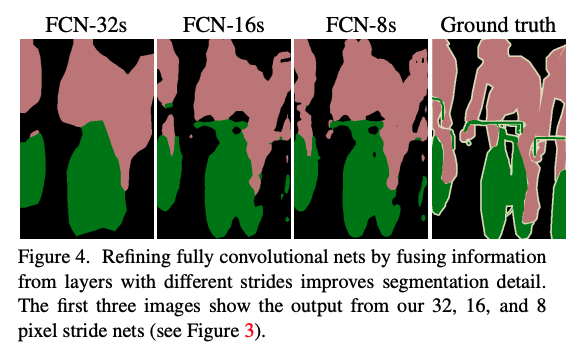
����:�÷�����ͼ��ָ��һ����Ҫ��ת�۵�,֤�������ѧϰ������Զ˵��˵�ʵ�ֶԲ�ͬ��Сͼ�������ָ
ȱ��:FCN ģ���ٶȽ���,��֧��ʵʱ������ָ�;û�п���ȫ����������Ϣ;���������չ�� 3D ͼ��
1.1.2 ParseNet
����:Parsenet: Looking wider to see better
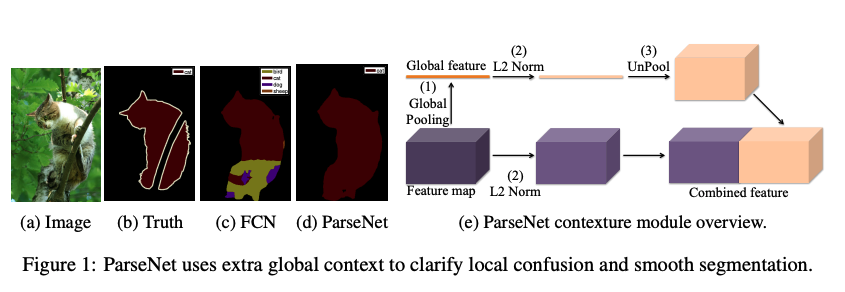
FCN Ϊʹ�þ���������ʵ�ֶ˵��˵�����ָ��ṩ�˺ܺõ�˼����ʽ,��ȴ�����˺���Ҫ��ȫ����������Ϣ,���� FCN ������ȫ����������ϢҲ������,���� ParseNet ʹ��ƽ����������ǿ����,������������Ϊ����ָ�����˺ܺõ�������
ParseNet ����:
ʹ��ȫ����������Ϣ��������ֲ���ʶ������,������ļ������dz�С,�ͱ� FCN ����һ�¡�
�� ����ȫ�������ķ�ʽ:parsenet ʹ�����ںϵķ�ʽ
- ���ںϷ�ʽ:
��ͼ 1e ��ʾ,unpool(Ҳ�����ظ�������)ȫ����������ԭ������ͬ��С,Ȼ�� concat ����,һ��ȥѧϰ��������
- ���ںϷ�ʽ:
ȫ��������ԭ�������ֱ�ѧϰ����,Ȼ������Ԥ��ķ������������,��Ϊ���յķ�������
������Խ���������ѵ������,�������ںϷ�ʽ�Ľ�����,������ij�����������µľֲ����������жϳ���ȷ�ķ�����,����,�����ѵ������������ɵ���ʧ�Dz�����ġ�
�� ΪʲôҪ��һ��
��ͼ 3 ��ʾ,��Ҫ�����������ʱ,������ߵ� scale �� norm ���ܴ�Ļ�,����һ�������̵�С��һ��,���ʹ�ù�һ��,���ܽϺõı��������,��ѵ�����ȶ���


1.2 Encoder-Decoder Based Models
���кܶ�ͼ��ָ��ǻ��ھ��� encoder-decoder �ṹ��,���Է�Ϊ��������:ͨ�÷ָҽѧͼ��ָ�
1.2.1 ͨ�÷ָ�
1.2.1.1 Deconvolutional semantic segmentation
����:Deconvolutional semantic segmentation
FCN �����㲻��ĵط�:
-
FCN ����ֻ�ܴ��������߶�,��Ϊ�����Ұ�ǹ̶���,���Աȸø���Ұ��ܶ����С�ܶ��Ŀ��,�ͻ����һЩ��ʶ��(�������ѻ���������)��Ҳ����˵�� label ��Ԥ��������ھֲ���Ϣ,���һ��,�ͻ����:
��Ŀ��:�����������������ص�������,����ͼ 1a ��ʾ
СĿ��:�������Ϊ��������,����ͼ 1b ��ʾ -
����������� label map ��,Ŀ���ϸ�ڽṹ����ʧ��ƽ������,�һָ���С���ֶ�Ҳ�ܼ�FCN ��,label map ����Ϊ 16x16 ��С,Ȼ��ʹ��˫���Բ�ֵ����ԭ�����ɷָ���ͼ��

���,���ĵ���������� deconvolutional ����ָ�����: -
encoder ʹ�� VGG-16 �еľ�����
-
decoder ʹ�÷������������ɷָ�ͼ,������������ deconvolution�� unpooling �� ReLU ��ɵġ�
Deconvolutional semantic segmentation �Ŀ�ܽṹ:
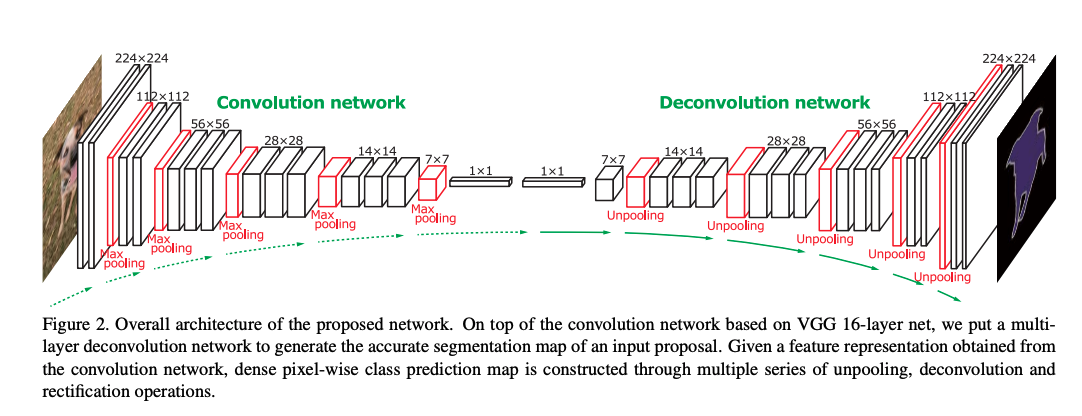
��ͼ 2 ��ʾ,�����Ҫ�����������:convolution �� deconvolution
- convolution:������ȡ�ͱ���,����ʹ�� VGG-16 ��ʵ��,�Ƴ��˺���ķ����,
- deconvolution:map ����,���յ�����Ǻ�����ͼ��ͬ�ȴ�С�ĸ��� map,��ʾ��ÿ���������ڶ�Ӧ���ĸ��ʡ�
�� Deconvolution Network for Segmentation
-
Unpooling
���������е� pooling �ܹ����Ӹ���Ұ,���ͼ�����,��Ҳ�ᶪʧλ����Ϣ,������ָ��е�λ����Ϣ���Ǻ���Ҫ�ġ�Ϊ�˽��������,����ʹ���� pooling �ķ�����,���ҽ�����ͼ��ԭ�� pooling ֮ǰ�Ĵ�С,��ͼ 3 ��ʾ���� pooling �Ĺ�����,���¼���ֵ����Դδ֪,unpooling ��ʱ����ٰ� pooling ����ŵ���Ӧ��λ����ȥ��
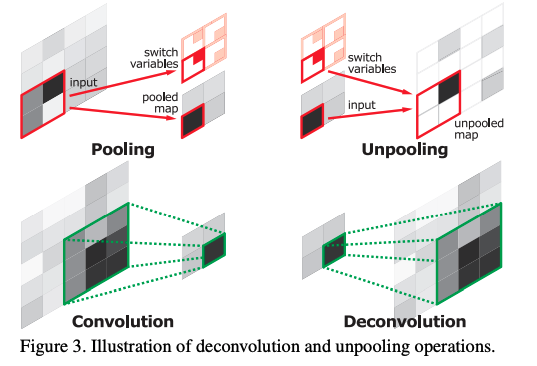
-
Deconvolution
unpooling ������һ��������ϡ�� map,deconvolution �����ܹ�����ϡ�� map ���ܻ���
deconvolution �� convolution �ķ������,�ܹ�������������չ�ɶ�����,��ͼ 3 ��ʾ,���� deconvolution �������һ�������ҳ��ܵ�����ͼ��
deconvolution �IJ㼶�ṹ�ܹ�����ͬ�߶ȵ�����,�Ͳ㲶Ŀ��Ĵ�������,�߲㲶���ϸ������
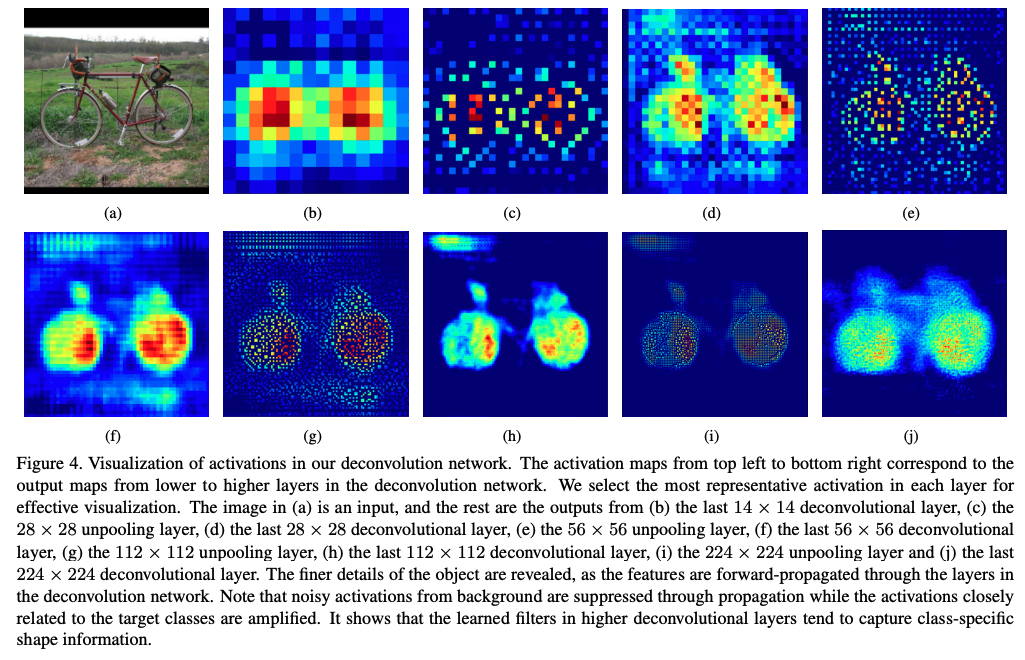
�� Deconvolution �������:
��ͼ 4 ���ӻ�����������,���Կ���,deconvolution �ܹ��Ӵֵ�ϸ��ȡĿ�������,unpooling ��ͨ������ǿ��Ӧ��λ������ example-specific �ṹ,�ܹ���Ч���ؽ�Ŀ���ϸ����Ϣ��deconvolution ���ܹ��� class-specific ��״,���� deconvolution ��,��Ŀ��������صļ����������Ŵ�,��������������������ơ������ߵĽ���ܸ�������ȷ�� maps �����ɡ�
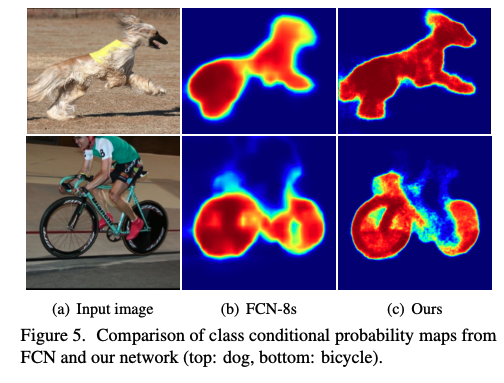
ͼ 5 Ҳչʾ�˲�ͬ��������Ч��,�� FCN-8s ���,���ĵ�����ṹԤ���Ϊ��
1.2.1.2 SegNet
����:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
����ָ������ؼ��ķ�������,Ҳ�����˺ܶ���ܹ�ʵ�ֶ˵��˵�Ԥ��,ֱ�ӵõ�ÿ�����ص�Ԥ�����,�������Ƚϴֲڡ���������Ҫ���� max-pooling �� �²������¶�ʧ��һЩ��Ϣ��
����Ϊ�˽�����ȫ����Ϣ�ĵͷֱ�������ͼ���õ�ӳ�䵽�����С�ķֱ���,����ӳ����Ҫ�ܺõı����߽��λ����Ϣ��
���Ա��Ĺ����� SegNet,��ʵ�ָ�Ч�Ҿ�ϸ������ָ
�ؼ���:
- SegNet �ڽ�������ʹ��ȥ�ػ�������ͼ�����ϲ���,���ڷָ��б��ָ�Ƶϸ�ڵ������ԡ�
- ��������ʹ��ȫ���Ӳ�(�� FCN һ�����о���),�����ӵ�н��ٲ��������������硣
�ṹ:
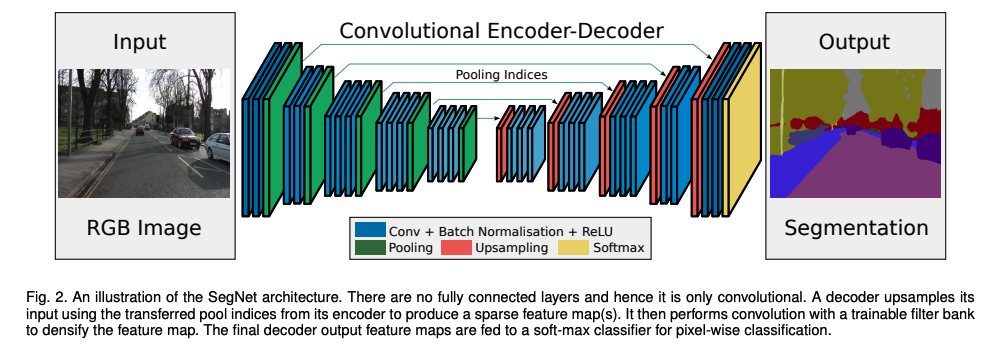
-
Encoder:VGG-16 ����(ȥ�����һ������),�� 13 �������,
�����ṹΪ Conv+BN+ReLU,�²���ʹ�����ػ���ʵ��(2x2,s=2),��һ��ᶪʧλ����Ϣ,�����ӵ����(boundary detail)�dz�����������ָ�Ľ��
����ָ��б߽�dz���Ҫ,����,encoder �о����ܶ�ı����߽���Ϣ�dz���Ҫ�����ǵ��ڴ��Ч������,��һЩ��������������ֵ��Ӧ��λ��������λ����Ϣ,���Ա���Ҳʹ�������ַ����� -
Decoder:ÿ�� encoder �����Ӧһ�� decoder,���� decoder Ҳ���� 13 ��,ͨ��ʹ�� memorized max-pooling �ķ�ʽ,���ϲ���������Ľṹ��ͼ 3 ��ʾ,
-
�����:���һ�� decoder ����������� multi-class soft-max ������,Ϊÿ�����������ɶ�Ӧ�����Ԥ��
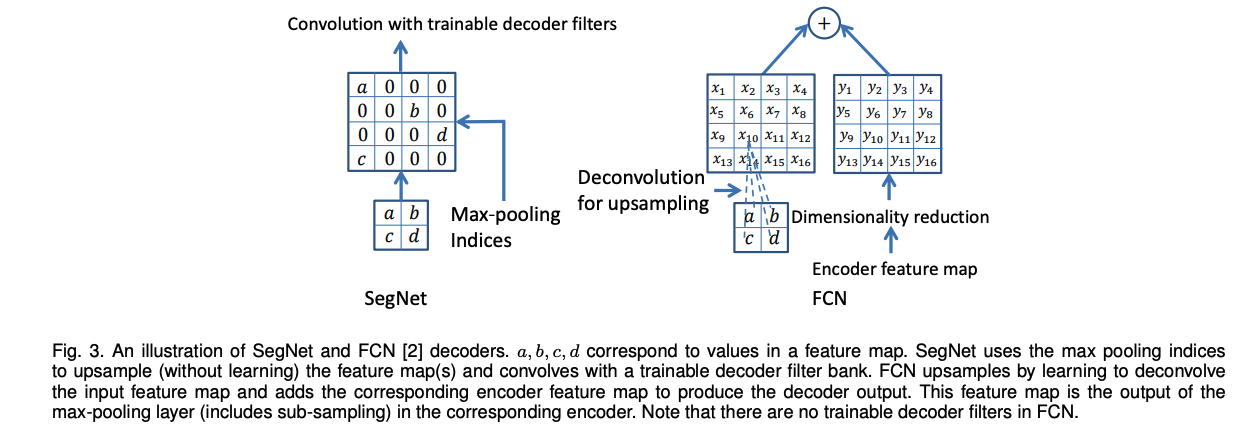
1.2.1.3 HRNet
Original HRNet ����:Deep High-Resolution Representation Learning for Human Pose Estimation
HRNetV2 ����:High-Resolution Representations for Labeling Pixels and Regions
HRNet ͨ�����ɸߵ��͵ķֱ���������������ķ�ʽ,ʵ�ֶԸ߷ֱ��������ı���,���Ҳ�ͬ�ֱ��ʵ�����Ҳ��������Ϣ�����������кܶ�ָ�ķ�ʽʹ�� HRNet ��Ϊ backbone,��Ϊģ����������������Ϣ�Ŀ���������
���ѧϰ���и߲�����Ҳ�еͲ�����,�кܶ��о���֤����,�ͷֱ��ʵĸ������ʺ��ڷ�������,�߷ֱ��ʵĵͼ��������ܼ�Ԥ������Ҫ����,����̬���ơ�Ŀ���⡢����ָ�ȡ�
�ʼ����� Original HRNet ����ʹ���� high-resolution ����������,��ͼ��ʾ,���Ķ� Original HRNet ����һЩ��,����ʹ���� high-to-low resolution ����������,Ҳ�� HRNetV2��
Original HRNet:
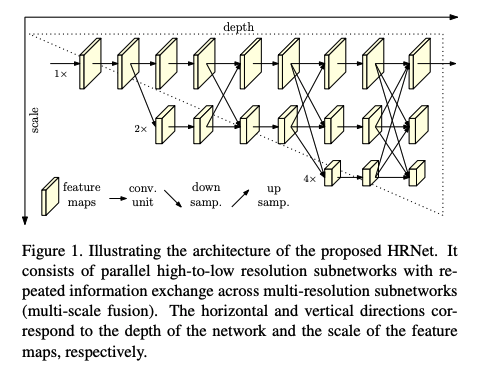
HRNetV2:
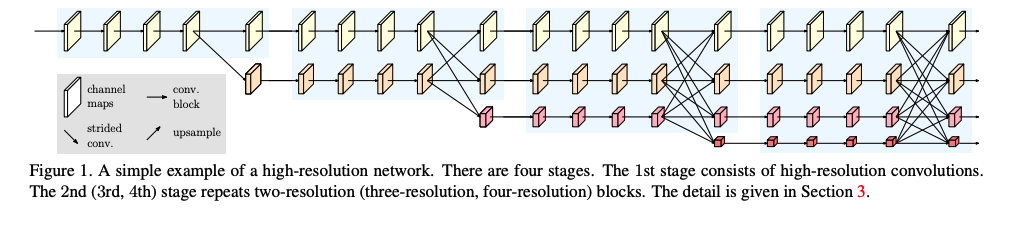
����չʾһ�� HRNetV2 ����ķֱ���:
- [2, 18, 128, 256]
- [2, 36, 64, 128]
- [2, 72, 32, 64]
- [2, 144, 16, 32]
�ָ����ʹ�������ֱ�������:�ϲ�������ͬ��С,Ҳ������������ͼ��С,Ȼ�� concat,���õ����´�С,������ decode_head ��ʹ��:
- [2, 270, 128, 256]
HRNetV2 �ṹ:
����ͼ 1 ��ʾ,�ܹ��� 4 stages,ÿ��stage�ṹ����,���� multi-resolution block,���Ǹ߷ֱ��������͵ͷֱ��������Ľ�ϡ�
��һ�� stage ������:ԭͼ�������� 3x3 �ľ�������������ȡ���ͼ(1/4ԭͼ��С)
multi-resolution block ��Ҫ��������ģ��:
- ��ֱ��������������ģ��:multi-resolution group convolution(ͼ2a)
- ��ֱ�����������ģ��:multi-resolution convolution(ͼ2b)
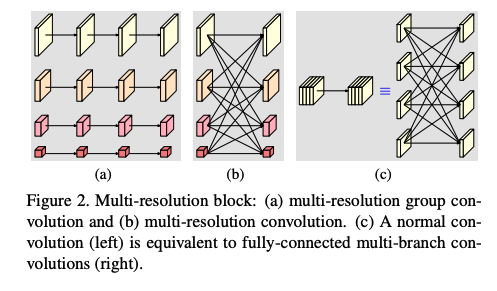
HRNet �ĶԱ�:
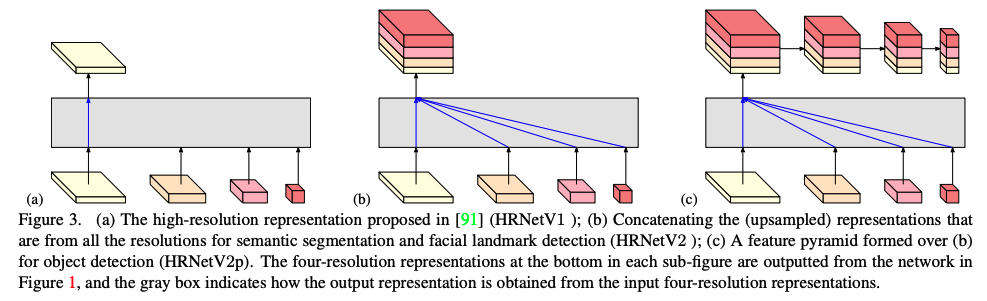
- HRNetV1:��ͼ 3a ��ʾ,ֻʹ���˷ֱ������ķ�֧�����,Ҳ���ǻᶪʧ�������Ӹ߷ֱ��ʷ�֧��ȡ���������������ͷֱ��ʵ�������
- HRNetV2:��ͼ 3b ��ʾ,���ͷֱ��ʵ�����ϲ���,����߷ֱ��ʵ���� concat,һ����������map���沿�ؼ���ʶ��
- HRNetV2p:��ͼ 3c ��ʾ,�� HRNetV2 ��������,ʹ��ƽ���ػ������²���,�õ���߶�����,����Ŀ���⡣
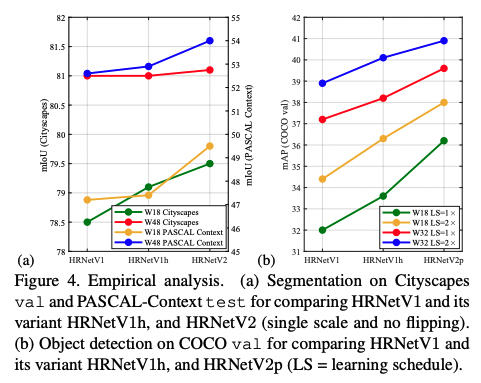
��ͼҲͨ����������,��֤�� HRNetV2 �� HRNetv2p ȷʵ���� HRNetV1��
1.2.2 ҽѧͼ��ָ�
1.2.2.1 U-Net [2015]
����:U-net: Convolutional vnetworks for biomedical image segmentation
ѵ�����ѧϰ������Ҫ����������,����ָ���ѵ�����:�߷ֱ��������͵ͷֱ��������Ľ��,Ҳ���Կ����ǵͲ�λ����Ϣ�߲�������Ϣ�Ľ��,ȱһ����,���������������ʹ����һ����ֵ���о�������
- �߷ֱ��������ܹ���֤λ����Ϣ
- �ͷֱ��������ܹ���֤������Ϣ
������ FCN �Ļ�����,������һЩ�ĺ��Ż�,�ܹ���֤��ʹ���������ݵĻ����ϲ�����ȷ�ķָ�����
FCN ����Ҫ����:
- �ڳ���ľ������,�������ϲ�����,������ͼ����,�����������ʱ��ʹ����ǰһ��ĸ߷ֱ�������,�����˸����ʵ�λ����Ϣ��
U-Net ����Ҫ�Ľ�����:
- ���ϲ�������,Ҳ�����˺ܶ��ͨ��,���ø������������Ϣ���ݵ��߷ֱ��ʲ�
- ʹ����һЩ������ǿ����,�������ܹ�ѧϰ��³��������
- ʹ���˼�Ȩ loss
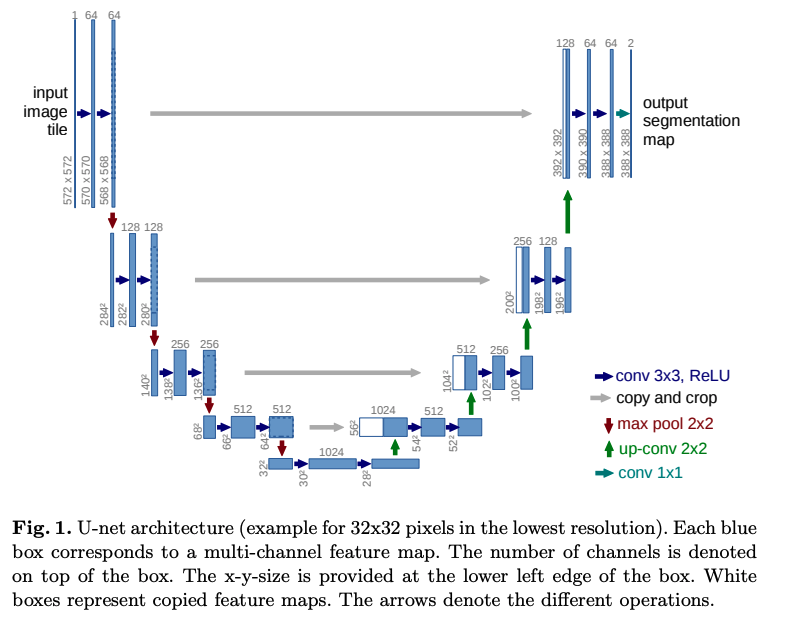
U-Net ��ܽṹ:
��ͼ 1 ��ʾ,U-Net �� FCN �ṹ����,Ҳ��Ϊ encoder �� decoder ģ��,����ṹ��ֻ�о����ͳػ���,��������·��:
- ������������Ϣ������·��(encoder)
- ʵ�־�ȷ��λ�ĶԳ���չ·��(decoder)
�ص�:
- U-Net �����²���ʹ������ͬ���ݵľ�������,��ʹ���� skip ����,ʹ���²����������ֱ�Ӵ��ݵ��ϲ�����,��֤�� U-Net ����ȷ�����ض�λ��
- U-Net ѵ��Ч��Ҳ���� FCN ,U-Net ֻ��Ҫһ��ѵ��,�� FCN-8s ��Ҫ 3 ��ѵ��
1.2.2.2 V-Net [2016]
����:V-net: Fully convolutional neural networks for volumetric medical image segmentation
1.3 Multi-Scale and Pyramid Network Based Models
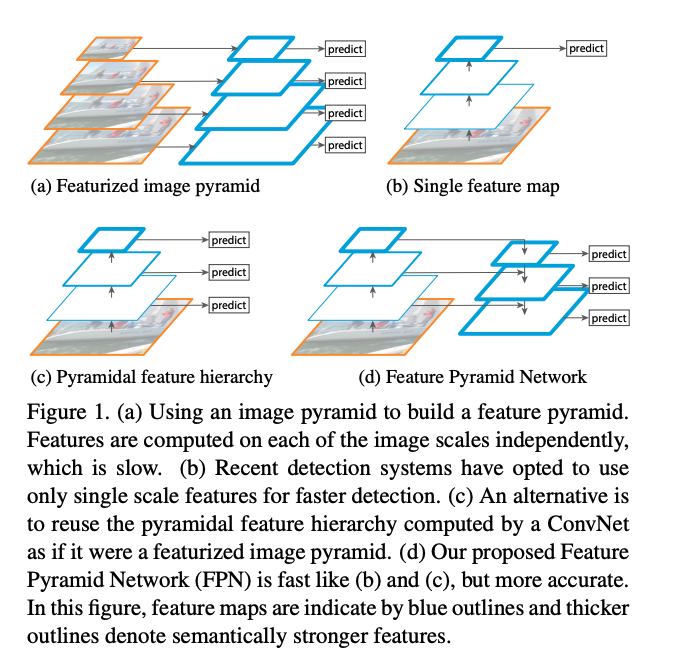
1.3.1 FPN [2017]
����:Feature Pyramid Networks for Object Detection
FPN ����������ʱ���DZ�����Ŀ�����,Ŀ���������е�Ŀ���С��һ,�߶����Ҳ�Ƚϴ�,�����ڼ��������ڴ��ԭ��,�����������ںܳ�һ��ʱ�䲢û�б��㷺ʹ�á����Ա��ĵ����߾������ FPN ģ��,����Ƕ���κ�����ṹ(�� Faster R-CNN ��),���Ҽ��㿪����С��
�ṹ:
- ͼ 1a �ǻ�����ͼ��������ṹ,��ԭͼ�� resize,Ȼ��ֱ���ȡ����,�ֱ���Ԥ��
- ͼ 1b �ǵ����߶ȵĽ�����,ֻʹ�����һ�����������Ԥ��
- ͼ 1c ��ʹ�ö��������ֱ���Ԥ��
- ͼ 1d(FPN �Ľṹ)�ǻ�Բ�ͬ�߶ȵ����������ں�,�ٷֱ���Ԥ��,��һ���������ͨ���ϲ�������ǰһ������������ں�,�����������ں����������������Ҳ��������Ϊdz���ں����������������
FPN ���ص�:���ں�
Ҳ������ÿ����ϲ��ںϺ�,�ֱ���н��Ԥ��,Ȼ���ٰѽ�������ں�
����ϸ��:
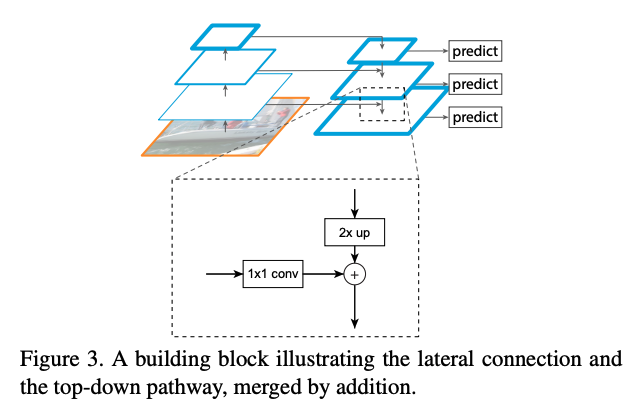
֮��Ҳ�����ڷָ�����FPN ����ֻ���Ӻ��ټ������������,�ں϶�߶Ƚ�����������֮��,ʹ��������� MLP �����ɷָ� mask��
1.3.2 PSPNet [2017]
����:Pyramid Scene Parsing Network
Pyramid Scene Parsing Network(PSPNet),Ҳ��һ����߶�����,�ܸ��õ�ѧϰȫ����������Ϣ��
Scene Parsing �ǻ�������ָ��,Ҳ�Ǽ�����Ӿ��Ļ���,��Ҫ��ÿ�����ط�����������ѵ����ڳ��������Ķ����ԡ�
��ͼ 2 �ĵ�һ��չʾ��һ����ʶ��:����ʶ��Ϊ�˳�
������ʶ����������ڴ��ͳ���Ŀ�����һ����������,�����߿���,���ģ���ܿ��Ǹ�Ŀ��(��)����������Ϣ,��ᷢ�ִ�һ���ͺ�����ý�,Ҳ���ή����ʶ��
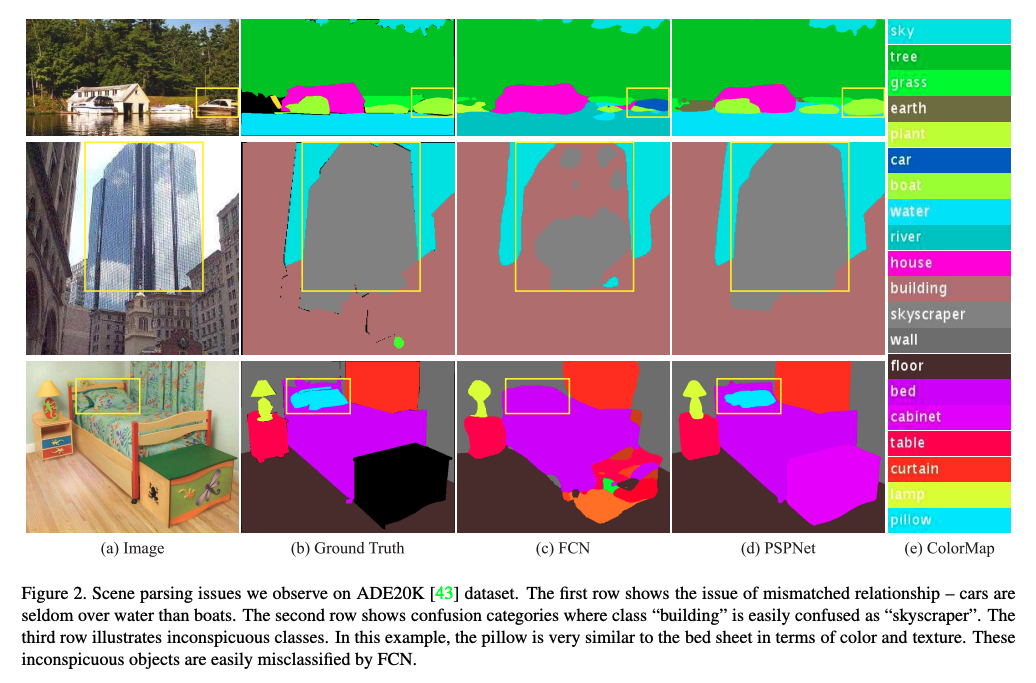
��Ҫ����:
�����pyramid pooling module (PPM) ģ��,�ۺϲ�ͬ�������������Ϣ,�Ӷ����ȡȫ����Ϣ��������
���е�������緽����,ijһ�������ĸ���Ұֱ�Ӿ���������������Ի�ö�����������Ϣ,������������Ұ����Ϊ��������������������Ϣ��
���:
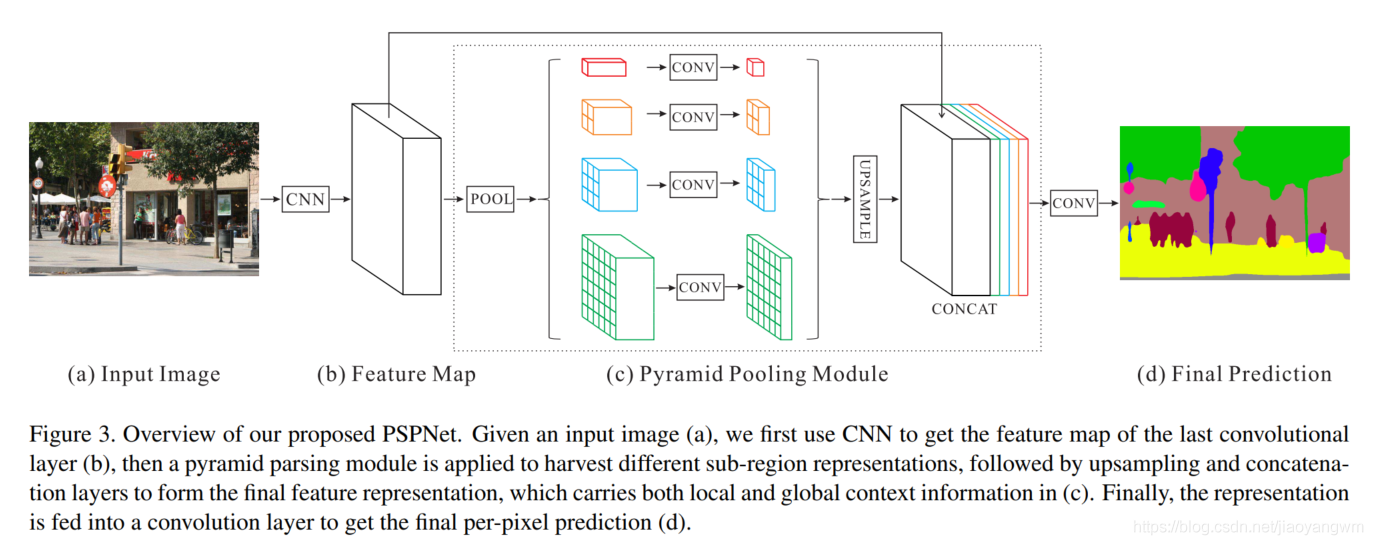
Step1: ʹ��global averag pooling�õ���ͬ�߶ȵ�����,PPMģ���ں���4����ͬ�߶ȵ�����:
- ��ɫ����ֲڳ߶�,ʹ��һ��global average pooling ʵ��
- �����Ķ��ǽ�����ͼ�з�Ϊ��ͬ�����Ŀ�,��ÿ������ʹ��global average pooling (�����ĸ��߶ȷֱ��� 1x1, 2x2, 3x3, 6x6)
Step2: global average pooling ֮��,ÿ�㶼��һ��1x1�ľ���������ͨ��ά�ȡ�
Step3: �ϲ�������ԭͼ��ͬ�ijߴ�,Ȼ��ͽ���PPMͷ֮ǰ��feature map ����concat ��Ԥ������
1.4 R-CNN Based Models(for Instance Segmentation)
Mask-RCNN ����ʵ�� object instance segmentation,�� COCO ���ݼ���ȡ���˺ܺõijɼ���
���кܶ���� Mask-RCNN ��ʵ���ָ�ṹ���� R-FCN��DeepMask��PolarMask��CenterMask �ȡ�
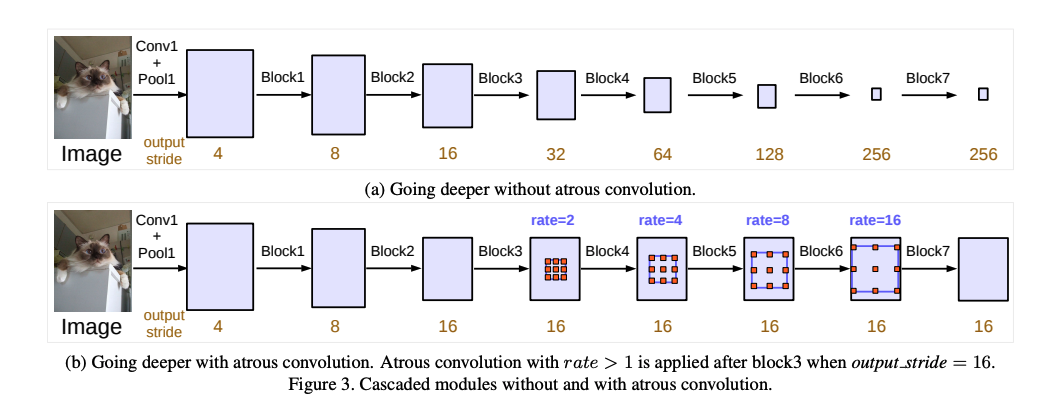
1.5 Dilated Convolutional Models and DeepLab Family
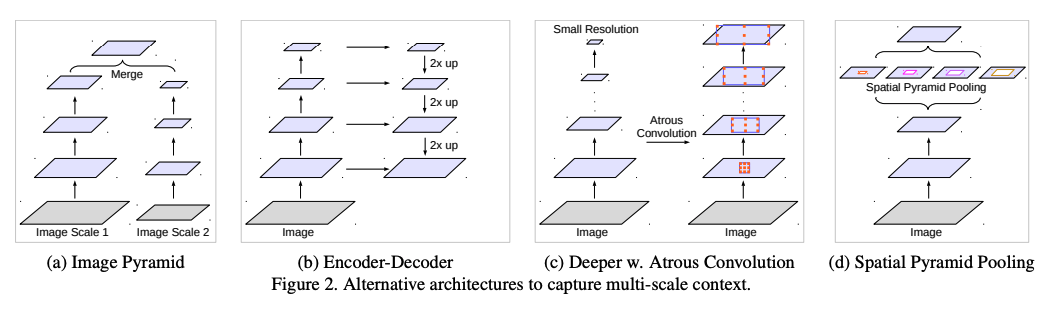
���;���(Dilated,Ҳ�� atrous ����)Ϊ��������������һ���µIJ������������ʡ����;����ܹ��ڲ������������������,��߸���Ұ,�����кܶ�ʵʱ�ķָ����綼��ʹ�����;������� DeepLab ����[78]��multi-scale context aggregation[79]��dense upsampling convolution and hybrid dilatedconvolution(DUC-HDC)[78]��densely connnected atrous spatial pyramid pooling(ASPP)[81] �� efficient neural network(ENet)[82]��
1.5.1 Deeplab v1
����:Semantic image segmentation with deep convolutional nets and fully connected crfs
������Ϊ����ָ����Ҫ����:
- �������²���
- �ռ�λ�Ʋ�����
���ĵķ���:
- ���������;������������Ұ
- ������ fully-connected CRF ����λ����ȷ�ķָ�߽�
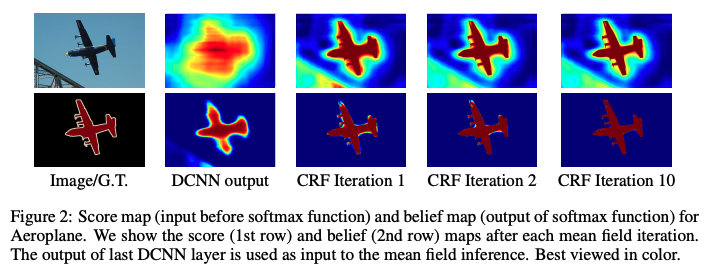
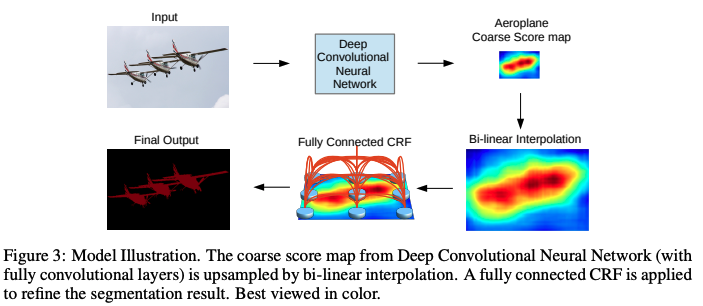
1.5.2 Deeplab v2
������Ϊ����ָ����Ҫ����:
- Ϊ�˷ֱ����½����ظ�ʹ�óػ����²���,��ʧ��λ�õ�ϸ����Ϣ
- Ŀ��߶ȵĶ�����
- �ռ�λ�ƵIJ�����(���Ա��������� fully-connected CRF,Ϊ���������λ��ϸ�ڵ�����)
Deeplab v2 �������ؼ���:
- ʹ�����;�������������������ͼ�ķֱ���
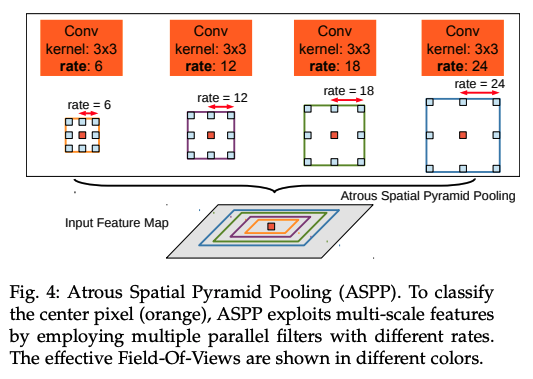
- ����� ASPP,�ܹ�ʹ�ò�ͬ�����߶ȵ��˲�������ȡ�����������,����ͬ�߶��µ�ͼ����������Ϣ
- ͨ�������� CNN ����ͼ(CRF)ģ��,������Ŀ��߽�Ķ�λ����
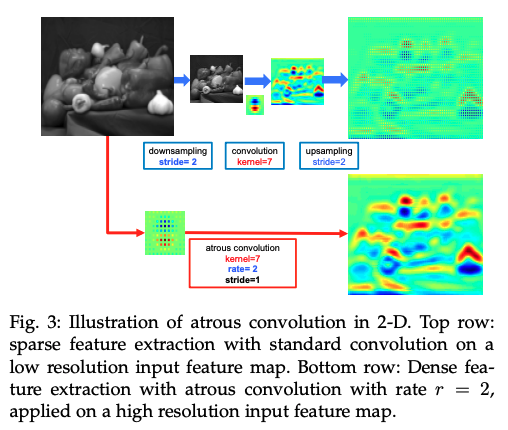
ASPP ��ܽṹ: 4 �鲢����ʹ�ò�ͬ�����ʵľ���
1.5.3 Deeplab v3
����:Rethinking atrous convolution for semantic image segmentation
�Ľ�:
- �Ľ��� ASPP(���;����������� BN;������ȫ��ƽ���ػ�������ȫ����Ϣ)
- ȥ���� V2 �� CRF
������Ϊ����ָ����Ҫ����(Deeplab ϵ��������������һ��):
- ���ͷֱ����Լ��ټ�����,һ��ʹ�óػ��Ͳ���������ʵ��,�������ᶪʧ�϶�Ŀռ�ϸ����Ϣ,����ʹ�����;������б�Ҫ
- Ŀ���С���ϴ�,һ��Ľ������Ϊ��������:��߶��ںϡ�encoder-decoder �ṹ��ʹ�ö���Ľṹ�����������������ռ�������ػ�(�����ͬ�ijػ���,����ͬ�߶ȵ�����)
DeeplabV3 �Ľ������:���;���(����������)+ SPP
- ����˼����Ͳ��������;���
- �����ľ���ģ�鱻Ƕ���� ASPP
����ָ�ĸ�������������Ҫ�����ĵͷֱ�������ͼ����ȡ��,�Ա���ʹ�úͲ�ʹ�����;��������:
- ��ʹ�����;���:��ʧ��ϸ����Ϣ
- ʹ�����;���:�ֱ��ʱ���
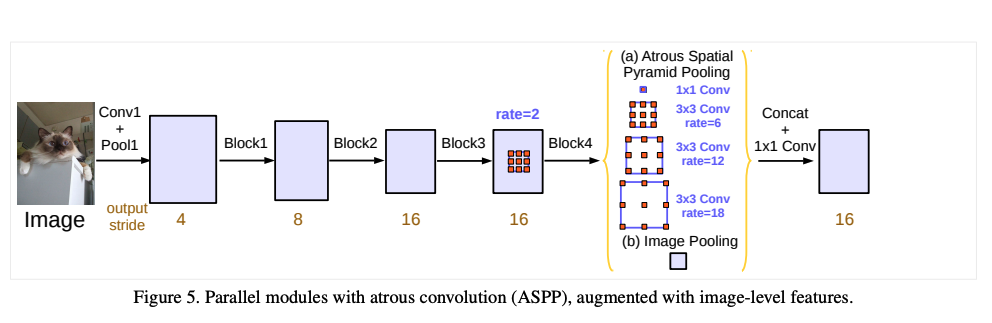
�� ASPP ����:
- �� ASPP �������� batch normalization,������ѵ��,����Ч��
- ������һ�����е�ȫ��ƽ���ػ�,����ȫ����Ϣ
ʹ��ȫ��ƽ���ػ���ԭ��:
ASPP ��ʹ�ò�ͬ��������������ͬ�߶ȵ���Ϣ,���ǵ������ʱ���ʱ��,��Ч��Ԫ�ؾ�Խ��,Ҳ���Ǽ��Խ��,���кܶ�Ȩ���䵽����ͼ��,��������,��������������3x3�ľ�����Ч��������һ��1x1�ľ�����
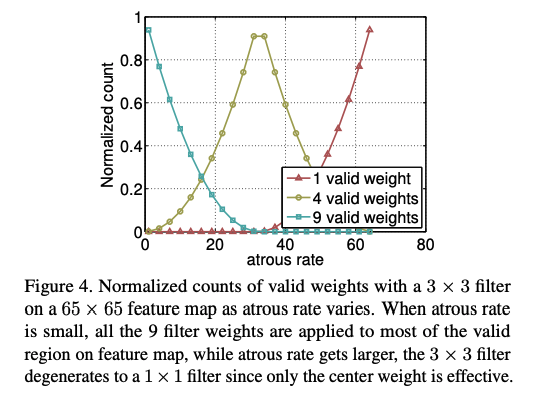
�����ʽ:
�����һ������ͼʹ��ȫ��ƽ���ػ�,���� ��image-level�� ���������� 1x1 ������+BN ��,���ϲ�������Ҫ�Ĵ�С
�ĺ�� ASPP ����ͼ 5 ��ʾ,����������:
- ԭʼ ASPP(1 �� 1x1 ����,3 ����ͬ�����ʵ� 3x3 ����)
- �¼ӵ�ȫ��ƽ���ػ�
1.5.4 Deeplabv3+
����:Encoder-decoder with atrous separable convolution for semantic image segmentation
����ָ��е��������ò���:
- �ռ�������ػ�:����߶���������Ϣ,��߸���Ұ
- Encoder-decoder ���:ͨ���ָ��ռ���Ϣ,����ͻ��ı߽���Ϣ
Deeplabv3+:������������Խ������
Deeplabv3+ �� Deeplabv3 ����ϵ:
- Deeplabv3+ �� Deeplabv3 ��Ϊ encoder
- ������ decoder �ṹ,��ϸ���ָ�Ľ��
�Ľ��Ķ���:
- Deeplabv3 ��Ȼͨ��ʹ�øĽ��� ASPP �����˷ָ��Ч��,Ҳ���������һ������ͼ��,�����˷ḻ��������Ϣ,��Ŀ���ϸ�ڱ߽���Ϣ�����кܶ�Ķ�ʧ(backbone �е��²����� stride �����ȵ���,����Ч�ʺͼ�����������ԭ��)
- encoder-decoder ������� encoder �������˺ܶ�����,���Լ���ܿ�,���ľ������� encoder ��������ȡ����,�ٽ� decoder �и�����Ϣ�Ļָ���
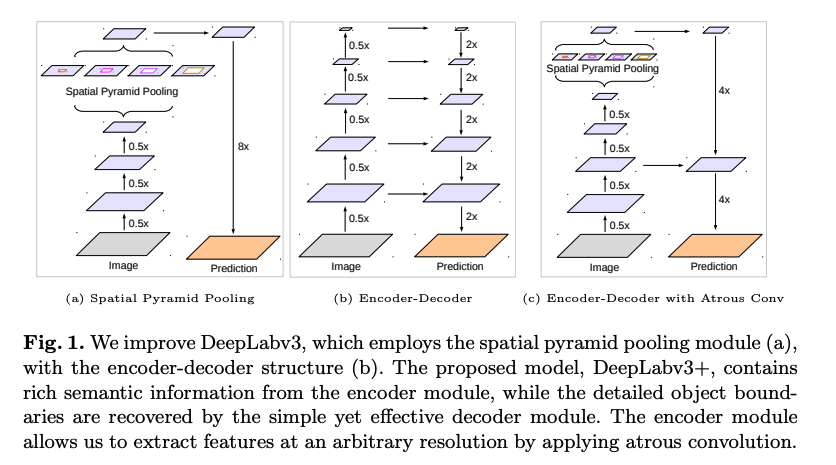
��ܽṹ:
- Encoder:ʹ�� ASPP �����ж�߶���������ȡ,��concat,���� 1x1 �����õ� 16x �²���������ͼ,�������ͼ�����˶�߶ȸ�������Ϣ
- Decoder:ʹ�ø߳߶�������Ϣ(�ϲ�����4x),�͵Ͳ�����concat����,�����������ϲ���,�õ����ս���Ľ��
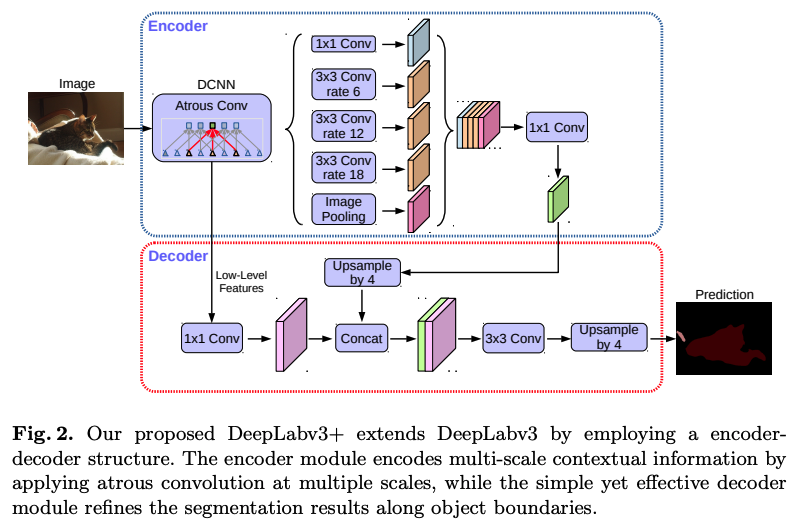
1.6 Attention-based Models
1.6.1 Non-Local [2018]
����:Non-Local Neural Networks
������������ȡ local ����������ṹ,Ϊ�˲��������������ϵ,��������� non-local �ķ��������Ժ����еĽṹ���,���ڷ��ࡢĿ���⡢�ָ��̬���Ƶȡ�
non-local �ĺ���˼���Ǽ�������ͼ�е�ÿ��������������ع�ϵ,Ҳ���ǿռ��ϵ�ע������
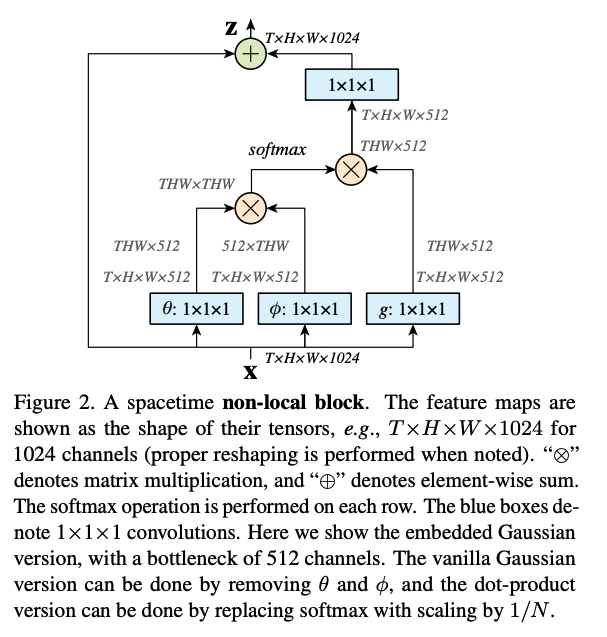
1.6.2 PSANet
����:PSANet: Point-wise Spatial Attention Network for Scene Parsing
��������Ϣ�ۺϵ�����������Ұ�IJ���,�� ParseNet��ASPP��PPM �ȶ����õ���
PSANet ��,��������� point-wise spatial attention,������Ӧ�ľۺϳ�������������Ϣ��
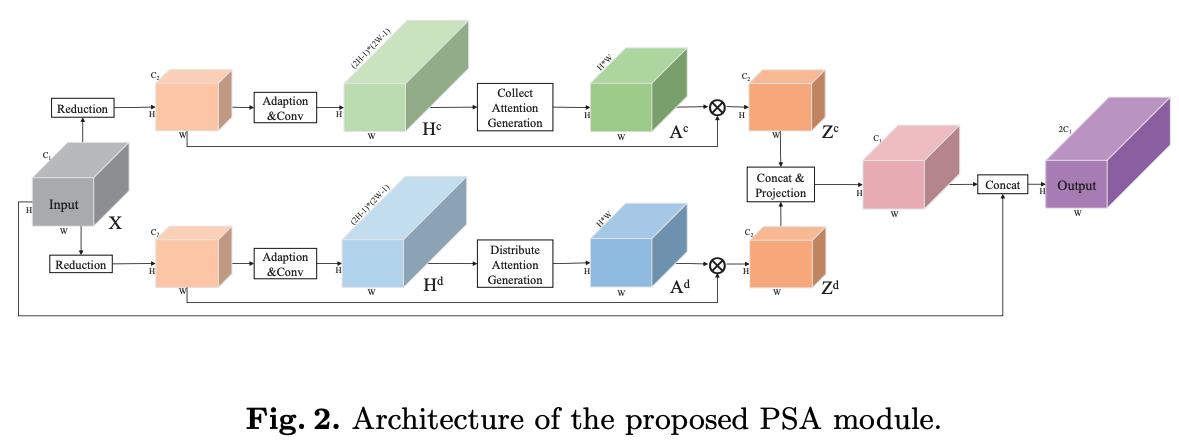
1.6.3 OCNet
����:Ocnet: Object context network for scene parsing

1.6.4 DANet [2019]
����:Dual attention network for scene segmentation
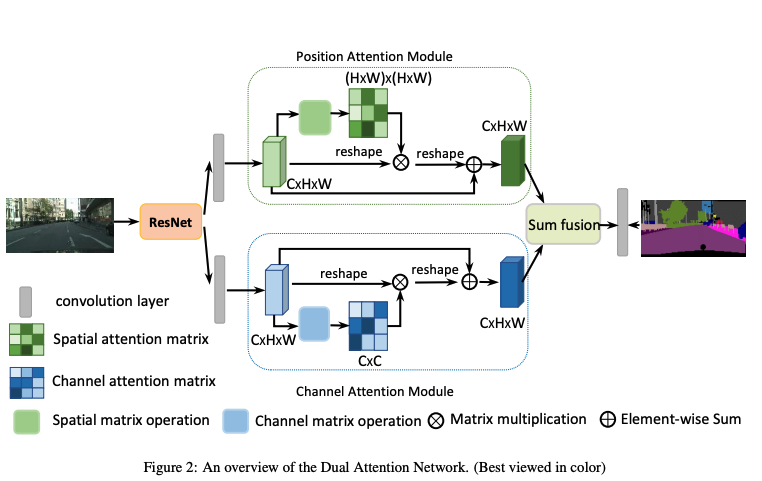
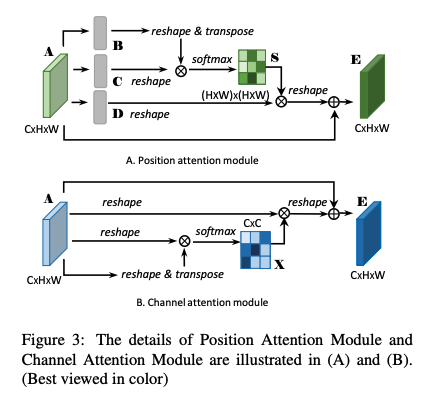
Ϊ��ͬʱ���ռ��ͨ���������,DANet ʹ�ò��еķ���,��ͨ���Ϳռ�ͬʱʹ���� non-local ģ�顣����ģ����ͼ 3 ��ʾ��
- position attention:Ҳ�ǿռ� attention,���Եõ�ÿ�����غ��������صĹ�ϵ,��ϵԽ��,Ȩ��Խ��
- channel attention:Ҳ����� attention,���Եõ�ÿ��ͨ����Ȩ��,ͨ��Խ��Ҫ,Ȩ��Խ��
1.6.5 OCRNet
����:Object-Context Representations for Semantic Segmentation
����:
����ָ�������,ÿ�����ص�����Ǹ���������Ŀ������,������������˺�Ŀ�걾�������صķ���,����ÿ�����ط������
����(�� cityscapes Ϊ��):�������յļ�Ȩ���Կ��������غ����֮��ļ�Ȩ
- ����,�õ���ͨ�ij�ʼ�ָ���(19��)
- Ȼ��,����ÿ������ͼ(512)�ͳ�ʼ�ָ���(19)�������,�õ� 512x19 �ľ���
- ֮��,�ø� 512x19 �ľ���,������ͼ(512)��Ȩ,�õ���Ȩ�������ͼ
- ���,�Լ�Ȩ�������ͼ����������ȡ,�õ���Ȩ������շָ���(19��)
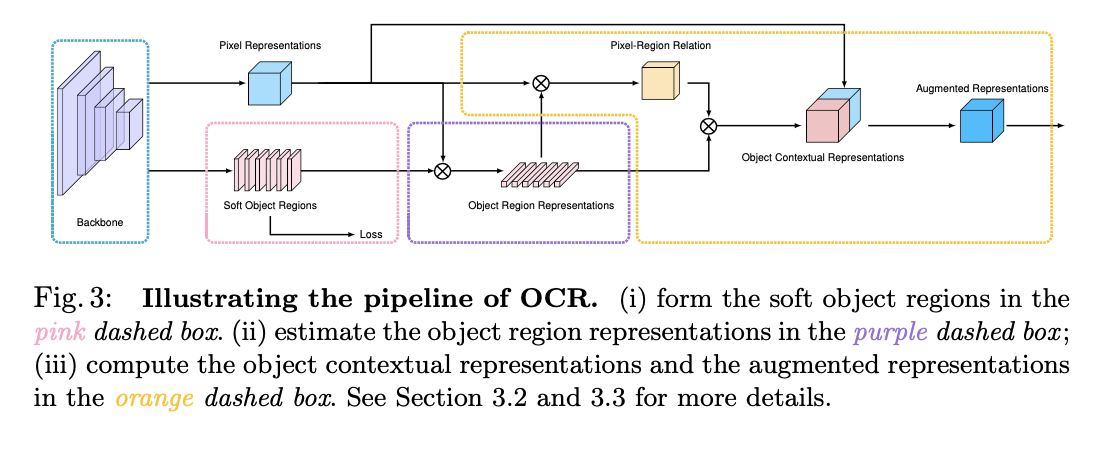
����ָ��о���һ����Ҫ��֧���dz�ȡij��λ���ܱߵ�������������Ϣ:
- �� ASPP �� PPM �����˶�߶ȵ�������������Ϣ��OCRNet �� ASPP �IJ�ͬ���Լ���ͼ 2��ASPP ֻ�ܳ�ȡ��߶ȵ���������Ϣ,�� OCR ���Խ�������ͬһ�������������ֿ�,��������ø�Զ��
- DANet��CFNet��OCNet,��������ij��λ�ú���������λ�õ���Ϣ,���ҶԸ�λ���ܱߵ�λ�õ������ĸ����˸��ߵ�Ȩ�ء�

����Ա��� DANet �� OCR ������ͼ�Ա�,���Կ��� OCR �ĵ�������ͼ��۽���ij���ض����,DANet ������ͼ��������Ϣ����ȷ��


1.7 Transformer-based Segmentation
1.7.1 SETR
����: Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers
SETR �����ڷָ������ϳ�Խ CNN �� Transformer ����ṹ,������������Ϊ,��Ȼ FCN �����������綼ȡ���˽Ϻõijɼ�,�������϶��� encoder-decoder �Ľṹ,����,������������Ҫ���ָ�������һ�� sequence-to-sequence �Ľṹ,���Ծ������һ���� Transformer �Ľṹ(�� CNN �ͷֱ��ʽ���)��
�Դ� ViT ֤���� Transformer ��ͼ����������ϵĵ�Ч����,�����˺ܶ���ص��о������ָ�������Կ�����������صķ�������,��ͼ������к�ǿ�Ĺ�ϵ,���� SETR ʹ�� ViT ��Ϊ backbone,Ȼ��ʹ�� CNN ����������ͼ�ָ���
��ܽṹ:
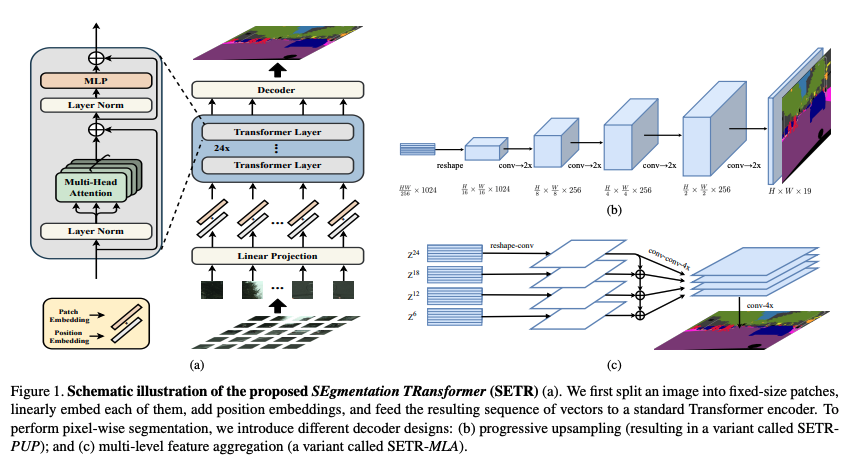
- ��ͼ����һϵ�е� image patches
- Ȼ��ʹ������ӳ��õ� embedding,������ position embedding
- ʹ�� Transformer ��ܽ���������ȡ
- ʹ�� conv ���зֱ��ʻָ�
Decoder������:���ɺ�ԭͼ��Сһ�µ�2ά�ָ���
����,������Ҫ�� encoder ������ Z �� H W 256 \frac{HW}{256} 256HW? reshape �� H 16 �� W 16 �� C \frac{H}{16} \times \frac{W}{16} \times {C} 16H?��16W?��C��
����һ:Naive upsampling (Naive)
�� ��transformer�õ������� Z L e Z^{L_e} ZLe? ӳ�䵽�ָ������(��cityscape����19)
1x1 conv + sync batch norm (with relu) + 1x1 conv
�� ʹ��˫���Բ�ֵ�����ϲ���,Ȼ�����loss
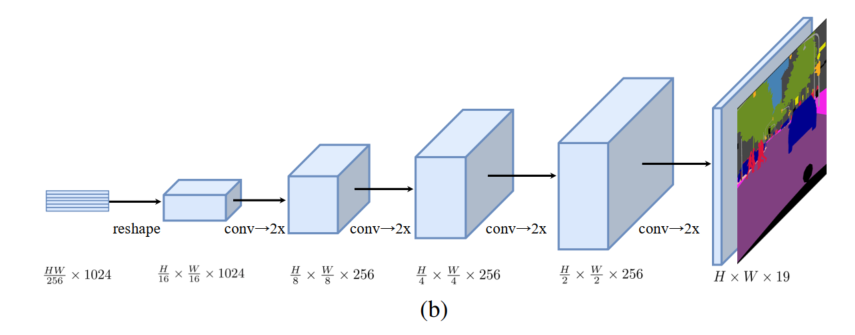
������:Progressive UPsampling (PUP)�� �����
ʹ�ý����ϲ���,ʹ�þ������ϲ�������任��ʵ��,Ϊ�˱���ֱ���ϲ�������������,����ϲ�������ÿ��ֻ�ϲ���2��,Ҳ����˵���Ҫ�Ѵ�СΪ
H
16
��
W
16
\frac{H}{16} \times \frac{W}{16}
16H?��16W? ��
Z
L
e
Z^{L_e}
ZLe? �ϲ�����ԭͼ��С,��Ҫ����4�β�����
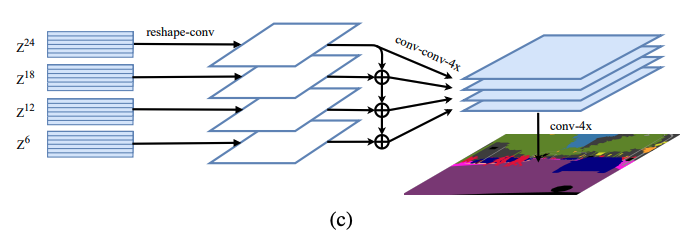
������:Multi-Level feature Aggregation(MLA)
1.7.2 PVT
����: Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
�� ViT ��һЩ����:
- ViT ֻ�������һ�߶ȵĵͷֱ�������
- ��ͼ���ϼ������ܴ�
���� PVT �����һ�ֽ������� Transformer,�ܹ��������ܼ�Ԥ�⡣PVT �� ViT ����Ҫ��ͬ����:
- ViT ���ڸ߷ֱ��ʵļ��������ڴ�����,ֻʹ���˵ͷֱ�������
- PVT ʹ���˶��ܼ�Ԥ�����Ҫ�ĸ߷ֱ�������,����ʹ���� shrinking pyramid �����ͼ�����
- PVT ͬʱ�� CNN �� Transformer ������,�����ܹ�������ͬ����� backbone
��ܽṹ:
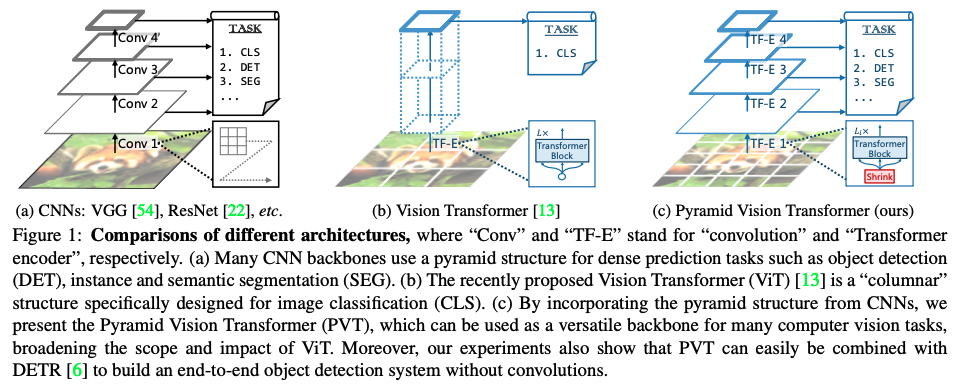
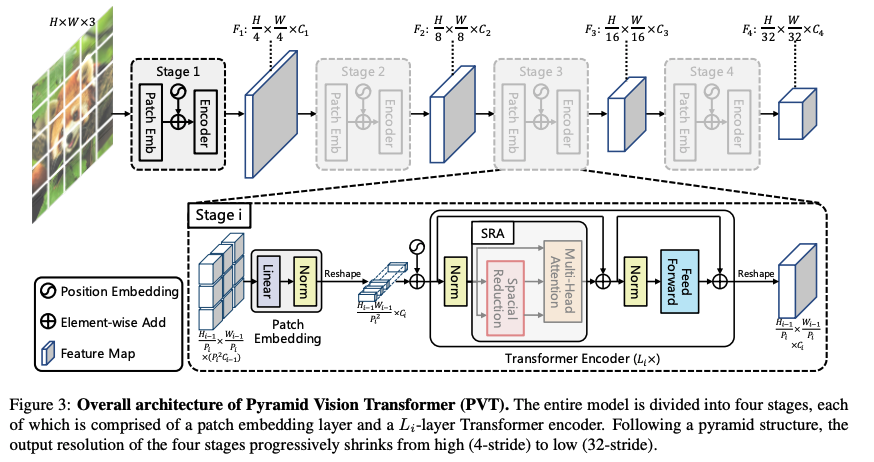
�����ܽṹ��ͼ 3 ��ʾ:
- �� 4 �� stages,�ֱ����ɲ�ͬ�߶ȵ�����ͼ(4x,8x,16x,32x �²�����С������ͼ)
- ���� stage �Ľṹ������ͬ��,���� 1 �� patch embedding �� L i L_i Li? �� Transformer encoder
1.7.3 SegFormer
����:SegFormer:Simple and Efficient Design for Semantic Segmentation with Transformers
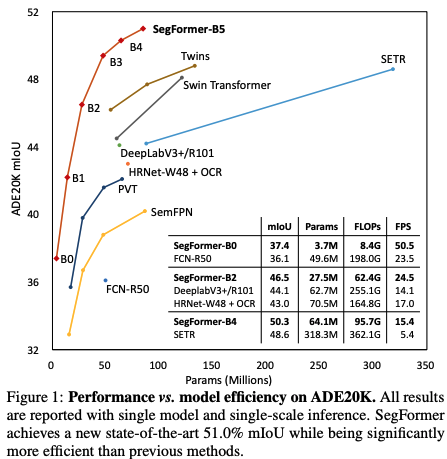
PVT��Swin �� Twins �ȷ���,��Ҫ������� encoder,������ decoder ����������,������������� SegFormer,ͬʱ������Ч����Ч�ʡ�³����,ʹ���� encoder-decoder ��ģʽ��
��ܽṹ:
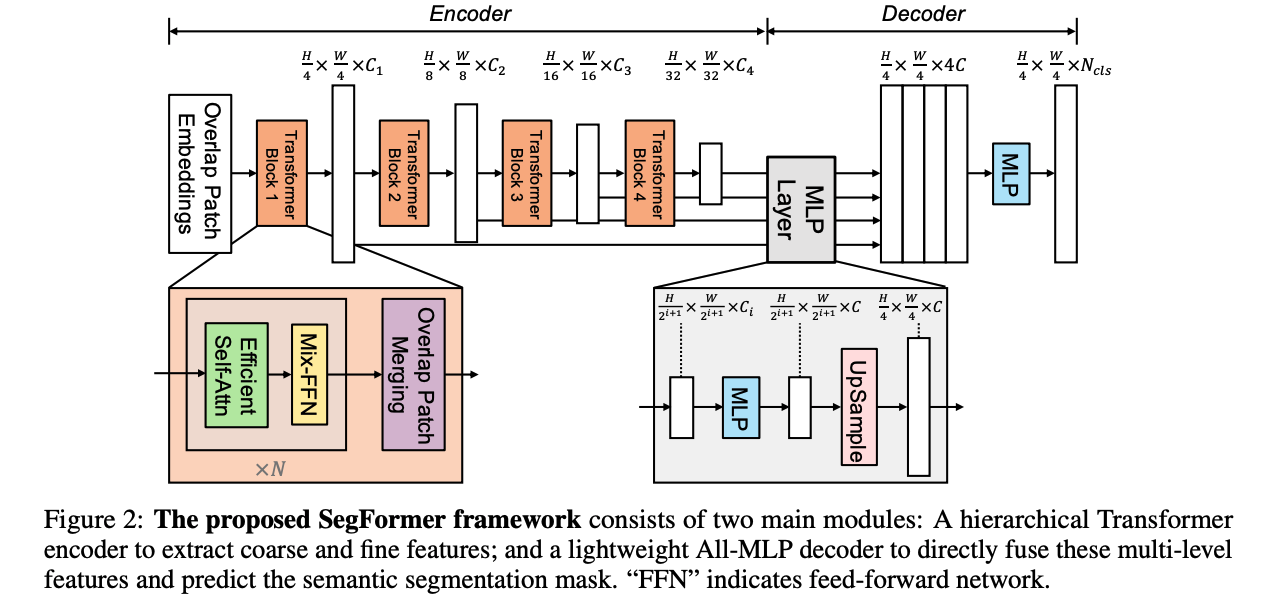
- ����ͼ���СΪ H �� W �� 3 H\times W \times 3 H��W��3
- ����,��ͼ���Ϊ��СΪ 4 �� 4 4\times 4 4��4 ��С�� patches,patch ԽСԽ�������ܼ�Ԥ������
- ����,�� patches ����㼶 transformer encoder ��,�õ���߶�����,����ԭͼ���С�� { 1 / 4 , 1 / 8 , 1 / 16 , 1 / 32 } \{1/4, 1/8, 1/16, 1/32\} {1/4,1/8,1/16,1/32}��
- ֮��,����Щ��߶��������� ALL-MLP decoder ��,Ԥ��ָ� mask H 4 �� W 4 �� N c l s \frac{H}{4} \times \frac{W}{4} \times N_{cls} 4H?��4W?��Ncls?
SegFomer �� SETR ������:
- SegFormer ֻʹ���� ImageNet-1k Ԥѵ��,SETR �е� ViT �� ImageNet-22k ��Ԥѵ��
- SegFormer �� encoder �Ƕ�㼶�Ľṹ,�ܹ�ͬʱ����ͬ�ֱ��ʵ�����,SETR �� ViT encoder ֻ�����ɵ����ֱ��ʵ�����ͼ
- SegFormer û��ʹ��λ�ñ���,SETR ʹ���˹̶���С��λ�ñ���,�ή��ȷ��
- MLP �� decoder �� SETR �ĸ�С������,SETR ��Ҫ��� 3x3 �ľ����ѵ���ʵ�� decoder��
Hierarchical Transformer Encoder
���������һϵ�е� Mix Transformer encoders (MiT),MiT-B0 �� MiT-B5,�ṹ��ͬ,��С��ͬ,MiT-B0 ������������,����������������,MiT-B5 ������������,����ȡ����õ�Ч����
MiT �����Դ�� ViT,��Ϊ��Ӧ�ָ�����һЩ�Ż���
�� Hierarchical Feature Representation:
��������ͼ�� H �� W �� 3 H\times W \times 3 H��W��3,����ʹ�� patch merging �ķ������õ��㼶����ͼ F i F_i Fi?,��ֱ���Ϊ H 2 i + 1 �� W 2 i + 1 �� C i \frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C_{i} 2i+1H?��2i+1W?��Ci?,���� i = { 1 , 2 , 3 , 4 } i=\{1, 2, 3, 4\} i={1,2,3,4},�� C i + 1 > C i C_{i+1}>C_{i} Ci+1?>Ci?
�� Overlapped Patch Merging:
ViT ��,�� N �� N �� 3 N\times N \times 3 N��N��3 �� patch,merge ���� 1 �� 1 �� C 1 \times 1 \times C 1��1��C ������,����,���߿��������� H 4 �� W 4 �� C 1 \frac{H}{4} \times \frac{W}{4} \times C_{1} 4H?��4W?��C1? �任�� H 8 �� W 8 �� C 2 \frac{H}{8} \times \frac{W}{8} \times C_{2} 8H?��8W?��C2?�����Ҳ��ص��� patch ��ʧȥ�ֲ�������,��������ʹ�����ص��� patch merging ������
���ߵ� patch size K=7,���� patch �� stride Ϊ S=4,padding size P=1,���ڴ���ʵ�����ص��� patch merging,�õ������ص� patch merging ��ͬ��С�Ľ����
�� Efficient Self-Attention
encoder �м��������ľ��� self-attention ��,��������ʹ�������� [8] ������ķ���,ʹ����һ�� reduction ratio R R R ���������еij���:
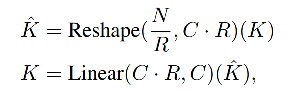
�� Mix-FFN
ViT ʹ�� position encoding(PE) ������ֲ�λ����Ϣ,���� PE �ķֱ��ʴ�С�ǹ̶���,���Ե����Բ�ͬ��ѵ��ͼ���С��ͼ��ʱ,��Ҫ��ֵ,�����ᵼ��ȷ���½���
������Ϊ PE ������ָ����Dz���Ҫ��,������һ�� Mix-FFN,������������λ��й¶��Ӱ��,ֱ���� FFN ��ʹ�� 3x3 �ľ���,��ʽ����:
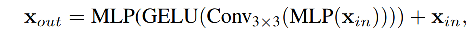
Mix-FFN �� FNN ��ʹ���� 3x3 �ľ����� MLP,����Ҳ֤���� 3x3 �ľ����ܹ�����λ����Ϣ��
Lightweight ALL-MLP Decoder
SegFormer ʹ�� MLP ������һ�� Decoder,�ܹ�ʹ�� MLP ��ʵ�� decoder ��һ����Ҫԭ����,Transformer �б� CNN �ߵĸ���Ұ��
Decoder ����:
- step 1:����㼶�������� MLP ��,���淶ͨ��ά��
- step 2:������ͼ�ϲ���Ϊԭͼ��С�� 1/4 ��С,concat ����
- step 3:ʹ��һ�� MLP ������ͨ���ۺ�
- step 4:���Ԥ�� segmentation mask H 4 �� W 4 �� N c l s \frac{H}{4} \times \frac{W}{4} \times N_{cls} 4H?��4W?��Ncls?
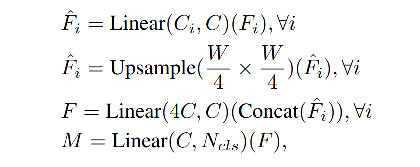
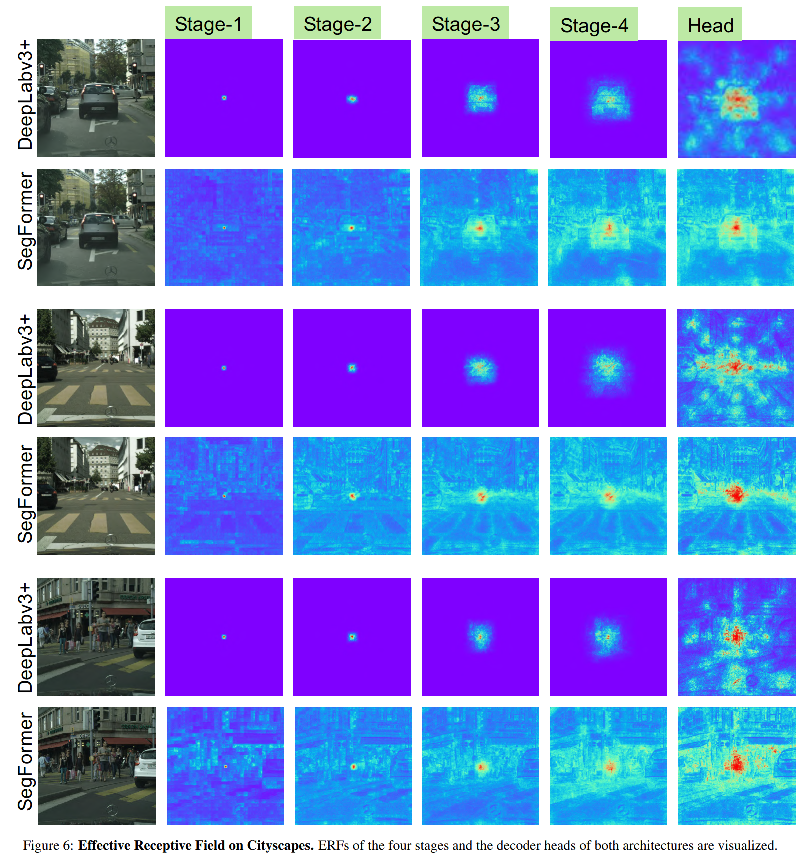
Effective Receptive Field Analysis:
����ָ�������,���ִ�ĸ���Ұ�dz���Ҫ,��������ʹ�� Effective Receptive Field Analysis(ERF)��Ϊ���������ӻ�������Ϊʲô MLP decoder �� Transformer �������Ч��
��ͼ 3 ��ʾ,���߷ֱ���ӻ���SegFormer �� Deeplabv3+ �� 4�� stage �� decoder head �� ERF��
- Deeplabv3+ �� ERF ��ÿ�� stage ��С
- SegFormer �� encoder �ڽϵ� stage ���������ھ����ľֲ�ע��,ͬʱҲ�ܹ��� stage 4 ����Ǿֲ���ע��,�ܹ���Ч����������
- MLP head �� ERF (����)��ͬ�� stage 4 �ĺ��,������� non-local ��attention��,���и�ǿ�ľֲ�attention��
����,MLP ��ʽ�� decoder ���� Transformer �����з��ӱ� CNN �и��õ����õ�ԭ�����ڸ���Ұ��

������ѵ�� cityscapes Ϊ��,��չʾ���е�Ҫ�㡣
��������:
python tools/train.py local_configs/segformer/B1/segformer.b1.1024x1024.city.160k.py
�� Encoder ��Ҫ����
- 1������ [1,3,1024,1024],���� OverlapPatchEmbed,ʹ�ú˴�СΪ 7,����Ϊ 4 �ľ���,���� [1, 64, 256, 256] �� patches
- 2������ transformer block 1(attention+mlp),����ͼ��С���� [1, 64, 256, 256]
- 3���� block 1 ���������ͼ,���� OverlapPatchEmbed,ʹ�ú˴�СΪ 3,����Ϊ 2 �ľ���,���� [1, 128, 128, 128] �� patches
- 4������ transformer block 2 (attention+mlp),����ͼ��С���� [1, 128, 128, 128]
- 5���� block 2 ���������ͼ,���� OverlapPatchEmbed,ʹ�ú˴�СΪ 3,����Ϊ 2 �ľ���,���� [1, 320, 64, 64] �� patches
- 6������ transformer block 3 (attention+mlp),����ͼ��С���� [1, 320, 64, 64]
- 7���� block 3 ���������ͼ,���� OverlapPatchEmbed,ʹ�ú˴�СΪ 3,����Ϊ 2 �ľ���,���� [1, 512, 32, 32] �� patches
- 8������ transformer block 4 (attention+mlp),����ͼ��С���� [1, 512, 32, 32]
�ĸ� stage ������� concat ��Ϊһ�� list,Ҳ�������ֲ�ͬ�ֱ��ʴ�С�Ķ�㼶����ͼ��
transformer block 1 ����:
ModuleList(
(0): Block(
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=64, out_features=64, bias=True)
(kv): Linear(in_features=64, out_features=128, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=64, out_features=64, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(drop_path): Identity()
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=64, out_features=256, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
(act): GELU()
(fc2): Linear(in_features=256, out_features=64, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=64, out_features=64, bias=True)
(kv): Linear(in_features=64, out_features=128, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=64, out_features=64, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath()
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=64, out_features=256, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
(act): GELU()
(fc2): Linear(in_features=256, out_features=64, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
�� SegFormer Head
- 1������Ϊ����� 4 �ֲ�ͬ�ֱ��ʵ����
- 2������4�� MLP �� �ϲ���(ÿ�� stage �������ֱ�һ�� MLP,����������,�ϲ������������ͼ�Ĵ�С)
- 3��4 ������concat,�õ� [1, 1024, 256, 256] ά����,Ȼ�� Conv+BN+ReLU,�õ� [1, 256, 256, 256]
- 4������ӳ��Ϊ [1, 19, 256, 256],��ΪԤ�� segmentation mask
# MLP 1 (for the feature from stage 4)
MLP(
(proj): Linear(in_features=512, out_features=256, bias=True)
)
resize
# MLP 2
MLP(
(proj): Linear(in_features=320, out_features=256, bias=True)
)
resize
# MLP 3
MLP(
(proj): Linear(in_features=128, out_features=256, bias=True)
)
resize
# MLP 4
MLP(
(proj): Linear(in_features=64, out_features=256, bias=True)
)
resize
# �����ں�
ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
1.7.4 HRFormer
NeurIPS 2021
����:HRFormer:High-Resolution Transformer for Dense Prediction
HRFormer ��һ������ܼ�Ԥ����������ķ���,��ͬ�� ViT ϵ��ֻʹ�õͷֱ��������ķ�����
ViT ϵ�еķ����ڷ��������ϵ�������Ŀ����,�佫ͼ���з�ΪС��,�ֱ���ȡС���е�����,��������ǵ����ֱ��ʵ�,ȱʧ�˴�����߶�Ŀ���������
HRFormer �ܹ���ȡ��߶ȿռ���Ϣ,Ϊ�ܼ�Ԥ���ṩ��ֱ����������
HRFormer block:
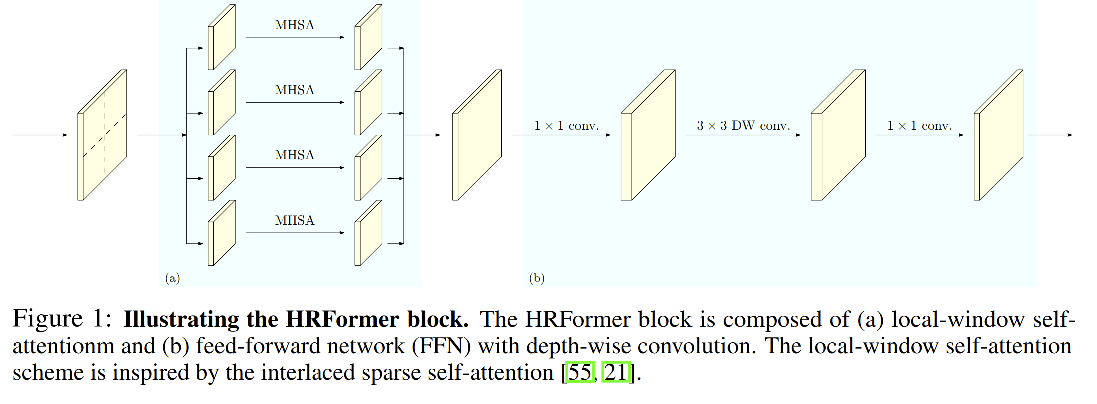
��μ��ټ�����:
- ��ÿ���ֱ�������ͼ�ڲ�,���߶�ʹ���� local-window self-attention �����ټ�����,���߽�����ͼ���ص��Ļ���ΪС�� windows,Ȼ����ÿ�� window �ڲ��ֱ�ʹ�� self-attention
- ����,Ϊ�˽��в�ͬ window �����Ϣ����,������ local-window self-attention �����ǰ������ FFN �������� 3x3 �Ŀɷ������,��������߸���Ұ
HRFormer ��ܽṹ:
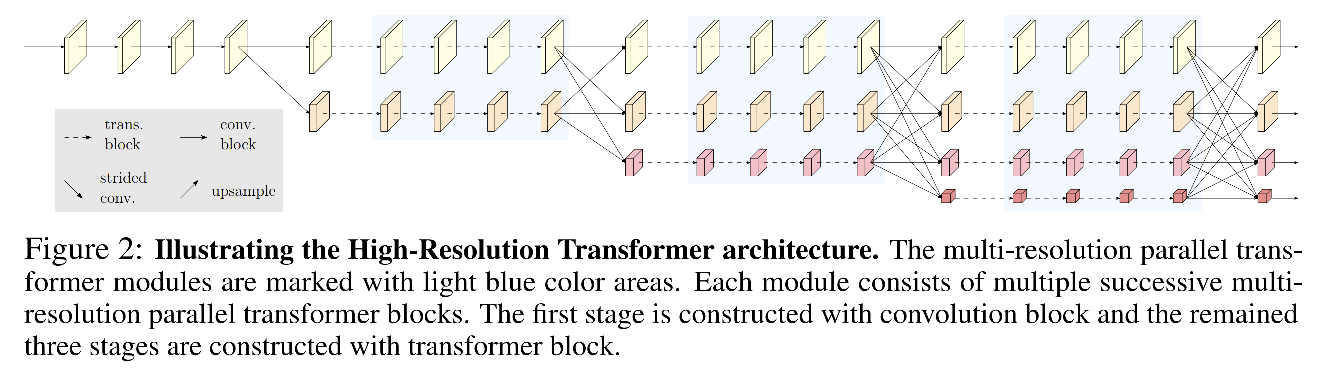
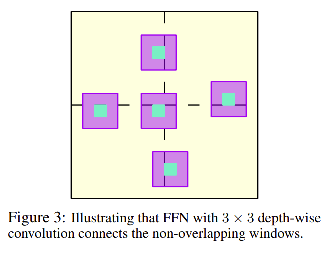
- Local-window self-attention:������ͼ�гɲ��ص��Ŀ�,��ÿ����(window)�ڽ��ж�ͷ��ע��������(MHSA)
- �� FFN �е� MLP ֮������ 3x3 �Ŀɷ������,���� windows ֮�����Ϣ����
HRFormer ����������� 4 �ֲ�ͬ�ֱ��ʵ�����ͼ,���ڲ�ͬ������,���������˲�ͬ�� head ��Ʒ���:
- ��������:�� 4 ������ͼ���� bottleneck,���ͨ���仯Ϊ 128��256��512��1024,Ȼ��ʹ�þ��������Ǿۺ�����,���һ�����ά������ͼ,���ʹ��avgpooling��
- ��̬��������:����ʹ�����ά�ȵ�����ͼ
- ����ָ�����:�����е�����ͼ�ϲ�������ͬ�Ĵ�С,Ȼ��concat����
1.7.5 PoolFormer
����:PoolFormer: MetaFormer is Actually What You Need for Vision
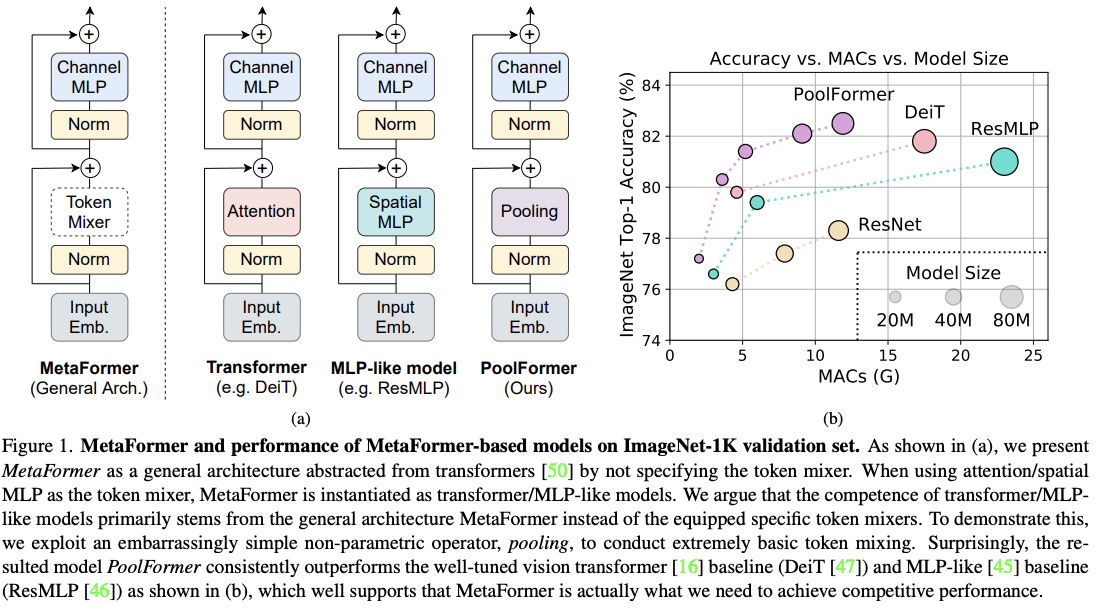
Transformer ����ڼ�����Ӿ�������չʾ�˺ܺõ�Ч��,��һ����϶���Ϊ���ֳɹ���Դ�ڻ��� self-attention �Ľṹ������������֤��,ֻʹ�� MLP Ҳ�ܴﵽ�ܺõ�Ч��,���������� Transformer ��Ч����Դ�� transformer �Ľṹ,���ǽ� token �����ںϽ�����ģ�顣
����,����ʹ�ü� spatial pooling ģ���滻�� attention ģ��,��ʵ�� token ֮�����Ϣ����,��Ϊ PoolFormer,Ҳ�ܴﵽ�ܺõ�Ч����
�� ImageNet-1K �ϴﵽ�� 82.1% �� top-1 acc��
����ʹ�� PoolFormer ֤�������ǵIJ���,��������� ��MetaFormer�� �ĸ���,Ҳ����һ�ִ� Transformer �г�������Ľṹ,û������� token mixer ��ʽ��
��ܽṹ:
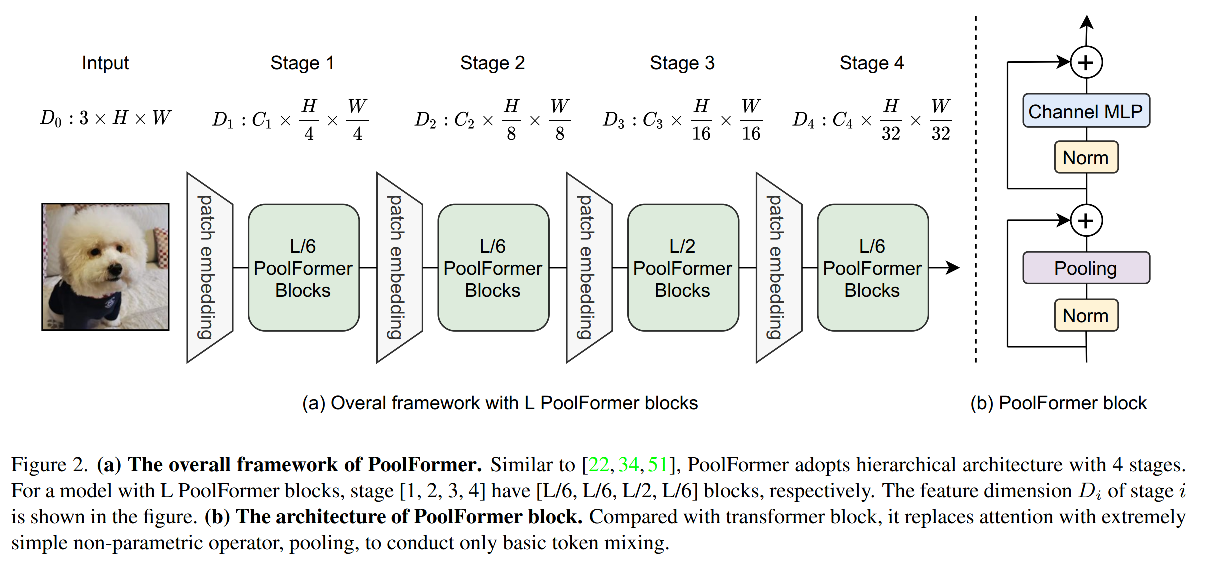
1��MetaFormer
MetaFormer ��ʵ�� Transformer ��һ������,�������ֺ� Transformer ����һ��,token mixer ��ʽ�Dz�����ָ���ġ�
�� ����,����
I
I
I ���� embedding:
X
=
I
n
p
u
t
_
E
m
d
(
I
)
X=Input\_Emd(I)
X=Input_Emd(I)
�� Ȼ��,�� embedding token ���� MetaFormer blocks,�� block ���������в� sub-blocks
- ��һ�� sub-block:token mixer,���� tokens ֮�������Ϣ����
Y = T o k e n _ M i x e r ( N o r m ( X ) ) + X Y=Token\_Mixer(Norm(X))+X Y=Token_Mixer(Norm(X))+X
- �ڶ��� sub-block:���� MLP & �����
Z = �� ( N o r m ( Y ) W 1 ) W 2 + Y Z=\sigma(Norm(Y)W_1)W_2+Y Z=��(Norm(Y)W1?)W2?+Y
2��PoolFormer
����Ϊ��֤������,ʹ���˷dz��� pooling ������ʵ�� token mixer,û���κο�ѧϰ������
����������ʽΪ T �� R C �� H �� W T\in R^{C\times H \times W} T��RC��H��W,channel ά����ǰ,�� pooling ��������, k k k Ϊ pooling ��С:
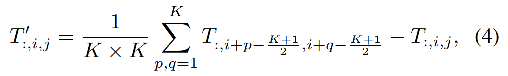
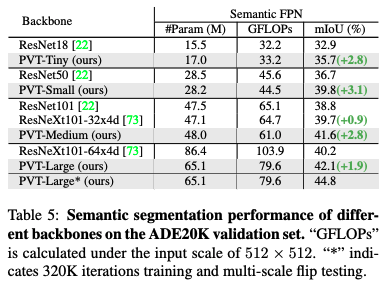
����ʹ�� PoolFormer ��Ϊ Semantic FPN ����������,ʹ�� mmsegmentation ѵ���Ľ�����¡���Խ�˻��� CNN �����硣
����2D ���ݼ�����
2.1 PASCAL Visual Object Classes (VOC)
����֧�� 5 ������:���ࡢ�ָ��⡢����ʶ�����塣
���ڷָ�����,��֧�� 21 �����,ѵ������֤�� 1464 �� 1449 ��ͼ:
vehicles, household, animals, aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, TV/monitor, bird, cat, cow, dog, horse, sheep, and person
2.2 PASCAL Context
�� VOC 2010 �����������伯,���� 400 �����,��������(objects��stuff��hybrids),����ֻʹ�� 59 ���������
2.3 Microsoft Common Objects in Context (MS COCO)
������ 91 �����,328k ͼ��,2.5 million �� label ��ʵ����
��������� 80 �����,82k ѵ��,40.5 ��֤��
2.4 Cityscapes
�־����ݼ�,���� 5k ��ϸ��ע����,20k �ֲڱ�ע���ݡ���ע�� 30 �����
- 5000�ž�ϸ��ע:2975��ѵ��ͼ,500��ѵ��ͼ,1525�Ų���ͼ
- 20000�Ŵֲڱ�ע(ʹ�ö���θ��ǵ�������)
- ͼ���С:1024x2048
- 50����ͬ���еĽ־�,train/val/test�ij��ж���ͬ
�����:
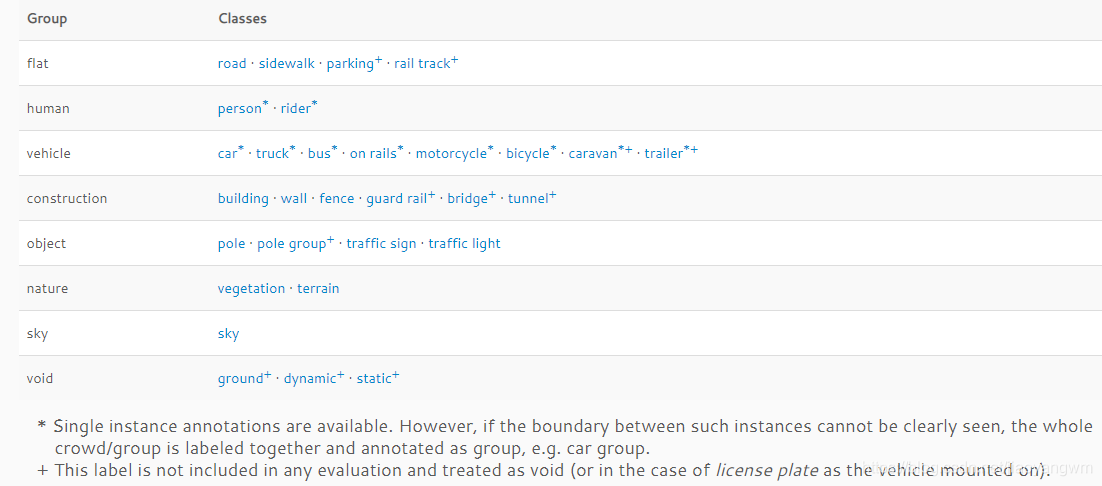
- *:����Ե���ʵ�����б�ע��,���ͬһ���Ķ�����彻��ֲ�,Ҳ��ʵ���߽粻����,��Щ�������һ����һʵ����group,�� car/bicycle group.
- +: ��ʾ��labelĿǰ��û�а������κε���������,treated as void;����ȥ����Щlabel,һ������˵CityScapes����19�ࡣ

2.5 ADE20K/MIT Scene Parsing
���� 20k ѵ��,2k ��֤����,�� 150 �����
2.6 Mapillary
Mapillary Vistas ���ݼ����� 66 � 25,000 �Ÿ߷ֱ��ʽ־�����������,������ 37 ��������ʵ�����ֵı�ǩ������������ cityscapes ��5��֮��,������ͬ���������ڡ�ʱ�䡣�ɼ���ʽ�����ֻ�������������ԡ��˶�����ȡ�
- ��������:25k
- ѵ������:18k
- ��֤����:2k
- ��������:5k
����:https://www.mapillary.com/
��������ָ��
3.1 Pixel accuracy
���� K+1 �����(K ��Ŀ��,1 ���),PA ��������:
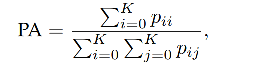
����, p i j p_{ij} pij? �ǵ� i �����Ԥ��Ϊ�� j ����������
3.2 Mean Pixel Accuracy(MPA)
�� PA ����չ,��ÿ�����ֱ����,Ȼ����ƽ��
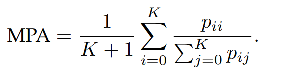
3.3 IoU
������ָ��е�һ������Ҫ�ĺ���ָ��,��ʾ����Ԥ��� map �� gt map ֮��Ľ�����:
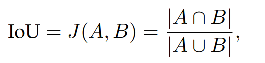
I o U = T P T P + F P + F N IoU = \frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP?
����ָ���,IoU����mask�����۵�:
GT:

Prediction:

Intersection:

Union:

mIoU:��������IoU�ľ�ֵ
mIoU �ļ���:
- ����һ:�����������
- �����:����mIoU
��������:
| ��ʵ��� | Ԥ���� | Ԥ���� |
|---|---|---|
| ��ʵ��� | ���� | ���� |
| ���� | TP | FN |
| ���� | FP | TN |
��������ĶԽ����ϵ�ֵ��ʾԤ����ȷ��ֵ,IoU��ֻ��������IoU,����ҳ��������йصĻ�������Ԫ����,����ͨ�����߷����õ�,

������N�����,������������һ��NxN�ľ���,�ԽDZ�ʾTP,�ῴ��ʵ,����Ԥ�⡣
����һ��3���Ԥ������Ļ�������������ʾ:
| ��ʵ | Ԥ�� | Ԥ�� | Ԥ�� |
|---|---|---|---|
| ��ʵ | 0 | 1 | 2 |
| 0 | 3 | 0 | 0 |
| 1 | 0 | 2 | 1 |
| 2 | 0 | 1 | 2 |
- �Խ����ϵ�Ԫ�ر�ʾԤ�������ȷ��������Ŀ
- ÿһ�б�ʾ�������ʵ�����ظ���
- ÿһ�б�ʾԤ��Ϊ���������ظ���
| ��ʵ | Ԥ�� | Ԥ�� | Ԥ�� |
|---|---|---|---|
| ��ʵ | 0 | 1 | 2 |
| 0 | a | b | c |
| 1 | d | e | f |
| 2 | g | h | i |
��ȷ��:
p
r
e
c
i
s
i
o
n
0
=
a
/
(
a
+
d
+
g
)
precision_0 = a/(a+d+g)
precision0?=a/(a+d+g)
p
r
e
c
i
s
i
o
n
1
=
e
/
(
b
+
e
+
h
)
precision_1 = e/(b+e+h)
precision1?=e/(b+e+h)
p
r
e
c
i
s
i
o
n
2
=
i
/
(
c
+
f
+
i
)
precision_2 = i/(c+f+i)
precision2?=i/(c+f+i)
p
r
e
c
i
s
i
o
n
0
=
3
/
(
3
+
0
+
0
)
=
1
precision_0 = 3/(3+0+0)=1
precision0?=3/(3+0+0)=1
p
r
e
c
i
s
i
o
n
1
=
2
/
(
2
+
1
+
0
)
=
2
/
3
precision_1 = 2/(2+1+0)=2/3
precision1?=2/(2+1+0)=2/3
p
r
e
c
i
s
i
o
n
2
=
2
/
(
2
+
1
+
0
)
=
2
/
3
precision_2 = 2/(2+1+0)=2/3
precision2?=2/(2+1+0)=2/3
�ٻ���:
r
e
c
a
l
l
0
=
a
/
(
a
+
b
+
c
)
recall_0 = a/(a+b+c)
recall0?=a/(a+b+c)
r
e
c
a
l
l
1
=
e
/
(
d
+
e
+
f
)
recall_1 = e/(d+e+f)
recall1?=e/(d+e+f)
r
e
c
a
l
l
2
=
i
/
(
g
+
h
+
i
)
recall_2 = i/(g+h+i)
recall2?=i/(g+h+i)
r
e
c
a
l
l
0
=
3
/
(
3
+
0
+
0
)
recall_0 = 3/(3+0+0)
recall0?=3/(3+0+0)
r
e
c
a
l
l
1
=
2
/
(
2
+
1
+
0
)
=
2
/
3
recall_1 = 2/(2+1+0)=2/3
recall1?=2/(2+1+0)=2/3
r
e
c
a
l
l
2
=
2
/
(
2
+
1
+
0
)
=
2
/
3
recall_2 = 2/(2+1+0)=2/3
recall2?=2/(2+1+0)=2/3
CPA:Class Pixel Accuracy(ÿ������ؾ���)������������ȷ������ռ�����صı���
P
i
=
�Խ���ֵ
/
��Ӧ�е���������
P_i = �Խ���ֵ/��Ӧ�е���������
Pi?=�Խ���ֵ/��Ӧ�е���������
p
0
=
3
/
(
3
+
0
+
0
)
=
1
p_0 = 3/(3+0+0) = 1
p0?=3/(3+0+0)=1
p
1
=
2
/
(
0
+
2
+
1
)
=
0.67
p_1 = 2/(0+2+1) = 0.67
p1?=2/(0+2+1)=0.67
p
2
=
2
/
(
0
+
1
+
2
)
=
0.67
p_2 = 2/(0+1+2) = 0.67
p2?=2/(0+1+2)=0.67
MPA:Mean Pixel Accuracy��ÿ����ȷ�������ر�����ƽ��
M
P
A
=
s
u
m
(
p
i
)
/
�����
=
(
1
+
0.67
+
0.67
)
/
3
=
0.78
MPA = sum(p_i)/����� = (1+0.67+0.67)/3=0.78
MPA=sum(pi?)/�����=(1+0.67+0.67)/3=0.78
IoU:
-
���߷�:
I o U 0 = 3 / ( 3 + 0 + 0 + 0 + 0 ) = 1 IoU_0 = 3/(3+0+0+0+0) = 1 IoU0?=3/(3+0+0+0+0)=1
I o U 1 = 2 / ( 0 + 2 + 1 + 1 + 1 ) = 0.5 IoU_1 = 2/(0+2+1+1+1) = 0.5 IoU1?=2/(0+2+1+1+1)=0.5
I o U 2 = 2 / ( 0 + 1 + 2 + 2 + 1 ) = 0.5 IoU_2 = 2/(0+1+2+2+1) = 0.5 IoU2?=2/(0+1+2+2+1)=0.5 -
���뷽��: S A �� B = S A + S B ? S A �� B S_{A\cup B} = S_A+S_B-S_{A\cap B} SA��B?=SA?+SB??SA��B?
I o U 0 = 3 / [ ( 3 + 0 + 0 ) + ( 3 + 0 + 0 ) ? 3 ] = 1 IoU_0 = 3/[(3+0+0)+(3+0+0) - 3] = 1 IoU0?=3/[(3+0+0)+(3+0+0)?3]=1
I o U 1 = 2 / [ ( 0 + 2 + 1 ) + ( 1 + 2 + 1 ) ? 2 ] = 0.5 IoU_1 = 2/[(0+2+1)+(1+2+1) - 2]= 0.5 IoU1?=2/[(0+2+1)+(1+2+1)?2]=0.5
I o U 2 = 2 / [ ( 0 + 1 + 2 ) + ( 0 + 2 + 1 ) ? 2 ] = 0.5 IoU_2 = 2/[(0+1+2)+(0+2+1) - 2] = 0.5 IoU2?=2/[(0+1+2)+(0+2+1)?2]=0.5
mIoU:
m I o U = s u m ( I o U i ) / c l a s s mIoU = sum(IoU_i)/class mIoU=sum(IoUi?)/class
import numpy as np
class IOUMetric:
"""
Class to calculate mean-iou using fast_hist method
"""
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
# �ҳ���ǩ����Ҫ��������,ȥ���˱���
mask = (label_true >= 0) & (label_true < self.num_classes)
# np.bincount�����˴�0��n**2-1��n**2������ÿ�������ֵĴ���,����ֵ��״(n, n)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
# ����:Ԥ��ֵ����ʵֵ
# ����ָ��������Ϊÿ�����ص����һ��label
def evaluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
#miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iu)
#��������ָ��
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.nanmean(np.diag(self.hist) / self.hist.sum(axis=1))
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, iou, miou, fwavacc
3.4 Mean-IoU
��������� IoU ��ƽ��
3.5 Precision/Recall/F1 score
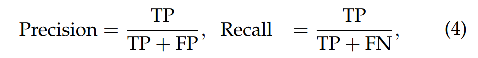
3.6 Dice coefficient
������ IoU:
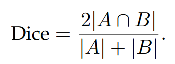
��Ϊ��ֵ map ʱ,���� F1 score
�ġ�Loss ����
��������:https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions
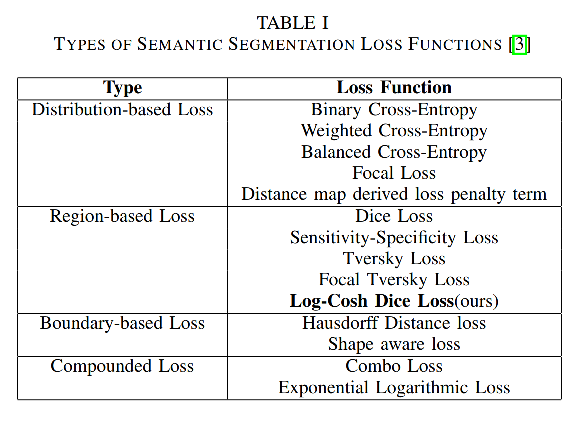
�ָ�� loss �������Ա������Ϊ 4 ������:
- Distribution-based
- Region-based
- Boundary-based
- Compounded
4.1 Cross-Entropy loss
Cross-entropy �Ǻ����������ʷֲ��ľ������,һ�㱻���������Ŀ�꺯��,�ָ���Ϊһ�����ؼ�����������,Ҳͬ������ʹ�øú�����ΪĿ�꺯����
1��Binary Cross-entropy
��Ϣ��:��������һ���¼�����������Ϣ��С,һ���¼������ĸ���Խ��,��ȷ����ԽС,��Ϣ��ԽС����ʽ����,�ӹ�ʽ�п��Կ���,��Ϣ���Ǹ��ʵĸ�����:
h
(
x
)
=
?
l
o
g
2
p
(
x
)
h(x) = -log_2p(x)
h(x)=?log2?p(x)
��:��������һ��ϵͳ�Ļ��ҳ̶�,����ϵͳ����Ϣ�����ܺ�,����Ϣ��������,��Ϣ���ܺ�Խ��,����ϵͳ��ȷ���Ծ�Խ��
E n t r o p y = ? �� p l o g ( p ) Entropy = -\sum p log(p) Entropy=?��plog(p)
������:��������ʵ���������������Ľӽ��̶ȵ���,������ԽС,�������ʷֲ���Խ�ӽ���
L
=
��
c
=
1
M
y
c
l
o
g
(
p
c
)
L = \sum_{c=1}^My_clog(p_c)
L=c=1��M?yc?log(pc?)
����,M��ʾ�����,
y
c
y_c
yc?��label,��one-hot����,
p
c
p_c
pc?��Ԥ�����,��M=2ʱ,���Ƕ�Ԫ��������ʧ
pytorch�еĽ�����:
Pytorch��CrossEntropyLoss()��������Ҫ�ǽ�softmax-log-NLLLoss�ϲ���һ��õ��Ľ����
- Softmax�����ֵ����0~1֮��,����ln֮��ֵ���Ǹ����0��
- Ȼ��Softmax֮��Ľ��ȡlog,���˷��ijɼӷ����ټ�����,ͬʱ���Ϻ����ĵ����� ��
- NLLLoss�Ľ�����ǰ�����������Label��Ӧ���Ǹ�ֵ�ó���,ȥ������,�����ֵ��
������loss�����õ����������ָ����,������һ�����Ե�ȱ��,����ֻ�÷ָ�ǰ���ͱ���ʱ,ǰ������ԶԶС�ڱ������ص�����,��ʧ������y=0�ijɷ־ͻ�ռ������,ʹ��ģ������ƫ��,����Ч�����á�
����ָ� cross entropy loss���㷽ʽ:
���� model_output=[2, 19, 128, 256] # 19 ����������
��ǩ target=[2, 512,1024]
1����model_output��ά���ϲ����� [512, 1024]
2��softmax����:�����������������������Ԥ��ͼ��,�������dim=1(19)�ϼ�����ʡ����ά�Ȳ���,dim=1ά���ϵ�ֵ���������ÿ�����ĸ���ֵ��
x_softmax = F.softmax(x,dim=1)
3��log����:
log_softmax_output = torch.log(x_softmax)
4��nll_loss ����(negative log likelihood loss):�������Ŀ�ľ��ǰѱ�ǩͼ���Ԫ��ֵ,��Ϊ����ֵ,��temp3��ѡ����Ӧ��ֵ,����ƽ����
output = nn.NLLLoss(log_softmax_output, target)
�����һ������ֵ��Ӧ��3,����Ԥ�����е�3��ͨ��ȥ�Ҹõ��Ԥ��ֵ,����õ�Ԥ����Ϊ-0.62,��Ϊ��lossǰ�Ҹ���,�����ս����Ϊ0.62����������������,������ֵ��ʱ������ʧ�����
- ��һ������ʵ���=3ʱ,�������Ӧ��������������ͼ�ϵĵ�Ϊ0.9,����-log�Ľ���dz��ӽ�0,��ʱloss��dz�С
- ��һ������ʵ���=3ʱ,�������Ӧ��������������ͼ�ϵĵ�Ϊ0.2,����-log�Ľ����Ƚϴ�,��ʱloss��dz���
��ֵ Cross-entropy ��ʽ����:
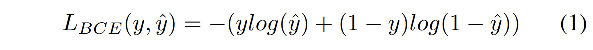
����,
y
^
\hat{y}
y^? ��Ԥ��Ľ��,
y
y
y ����ʵ���
2��Weighted Binary Cross-entropy
Weighted Binary Cross-entropy(WCE) �Ƕ�ֵ cross-entropy �����ı���,��������ͨ����Ȩϵ�����õ�Ȩ�صļ�ǿ�������ڷֲ�����б������,����ͼ��ʾ��
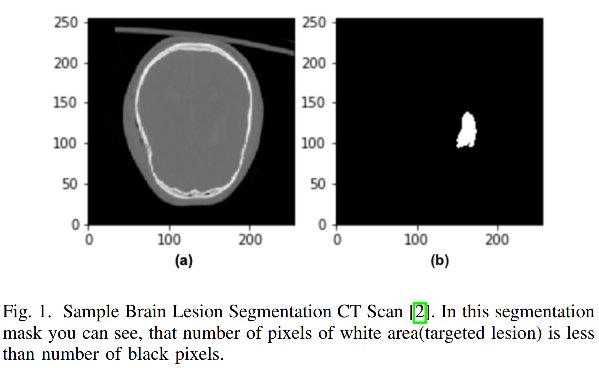
Weighted Binary Cross-entropy ��ʽ����:
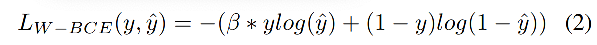
����:
- �� \beta �� ���Ա����������ٸ��ͼ�������
- �����Ҫ���ͼٸ�����������,�������� �� > 1 \beta>1 ��>1
- �����Ҫ���ͼ�������������,�������� �� < 1 \beta<1 ��<1
2��Balanced Cross-entropy
Balanced cross entropy (BCE) ������ WCE,Ψһ�IJ�ͬ����������,
BCE �Ĺ�ʽ����:
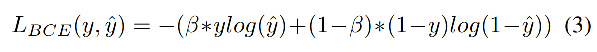
����:
��
=
1
?
y
H
?
W
\beta = 1-\frac{y}{H*W}
��=1?H?Wy?,���ԭ����loss,���������������������¿��Ի�ø��õ�Ч����
4.2 Focal loss
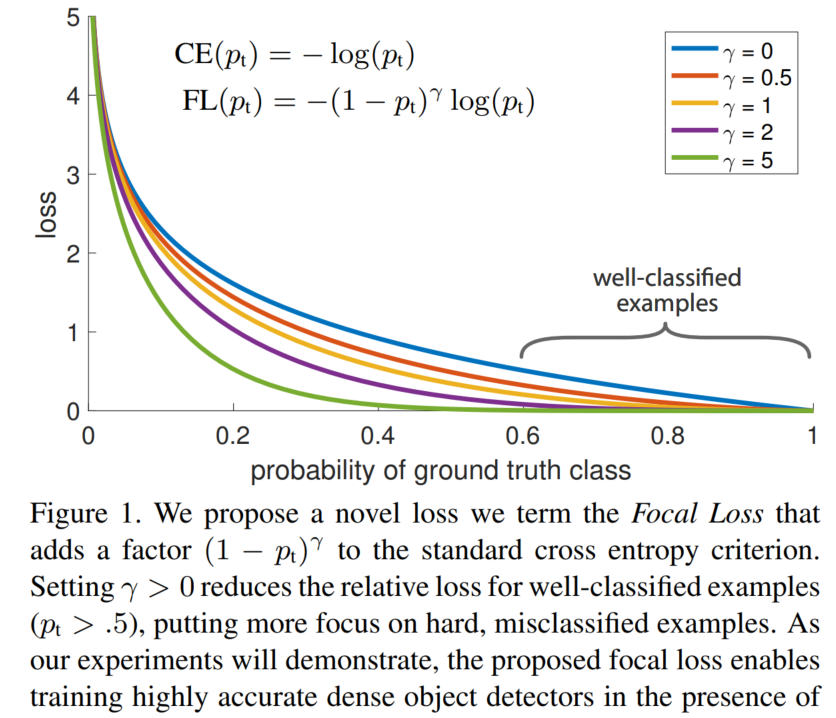
Focal loss ���Ա����� Binary Cross-entropy loss �ı���,�ص�����:
- FL ����������Ȩ�ر�С,��ģ����ע������
- ����Ȳ�ƽ��ij������ֺá�
Focal loss ��ʵ��Դ�� Cross-entropy loss ��,Ŀ���ǽ������������ƽ������:
- ������loss����,������loss��С
- ������loss����,������loss��С
һ�����ʱ��ͨ��ʹ�ý�������ʧ:
C r o s s E n t r o p y ( p , y ) = { ? l o g ( p ) , y = 1 ? l o g ( 1 ? p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -log(p), & y=1 \\ -log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={?log(p),?log(1?p),?y=1y=0?
Ϊ�˽����������������ƽ�������,���Ǿ����ڶ�Ԫ��������ʧǰ���һ������ �� \alpha �������������ֵ�Ƶ�ζ�,��ô�ͽ���������Ȩ��,������������,����������������Ȩ�ء���˿���ͨ���趨 �� \alpha ����ֵ�����������������ܵ�loss�Ĺ���Ȩ�ء� �� \alpha ��ȡ�Ƚ�С��ֵ����������(�����������)��Ȩ�ء���:
C r o s s E n t r o p y ( p , y ) = { ? �� l o g ( p ) , y = 1 ? ( 1 ? �� ) l o g ( 1 ? p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -\alpha log(p), & y=1 \\ -(1-\alpha) log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={?��log(p),?(1?��)log(1?p),?y=1y=0?
��Ȼƽ������������������,��ʵ����,Ŀ�����д����ĺ�ѡĿ�궼������������Щ��������ʧ�ܵ�,����������������ƽ��,�������������������̫��,�����������ܵ���ʧ��
���,��ƪ������Ϊ������(��,���Ŷȸߵ�����)��ģ�͵�����Ч���dz�С,ģ��Ӧ����Ҫ��ע����Щ�ѷ����� ��һ�����뷨����ֻҪ���ǽ������Ŷ���������ʧ����һЩ, Ҳ��������Ĺ�ʽ:
F
o
c
a
l
_
L
o
s
s
=
{
?
(
1
?
p
)
��
l
o
g
(
p
)
,
y
=
1
?
p
��
l
o
g
(
1
?
p
)
,
y
=
0
Focal \_Loss = \begin{cases} -(1-p)^ \gamma log(p), & y=1 \\ -p^\gamma log(1-p), & y=0 \end{cases}
Focal_Loss={?(1?p)��log(p),?p��log(1?p),?y=1y=0?
�� �� = 0 \gamma=0 ��=0 ʱ,��Ϊ��������ʧ����,��������ʱ,�������ӵ�Ӱ��Ҳ������,ʵ�鷢��Ϊ2ʱЧ�����š�
����ȡ �� = 2 \gamma=2 ��=2,���ij��Ŀ�����ŵ÷�p=0.9,��������ѧ�ķdz���,��ô���������Ȩ��Ϊ ( 1 ? 0.9 ) 2 = 0.001 (1-0.9)^2=0.001 (1?0.9)2=0.001,��ʧ��������1000����
Ϊ��ͬʱƽ��������������,Focal loss������˼�Ȩ�Ľ�����loss,�������߽�Ϻ�õ������յ�Focal loss:
F o c a l l o s s = { ? �� ( 1 ? p ) �� l o g ( p ) , y = 1 ? ( 1 ? �� ) p �� l o g ( 1 ? p ) , y = 0 Focal loss = \begin{cases} -\alpha (1-p)^\gamma log(p), & y=1 \\ -(1-\alpha) p^\gamma log(1-p), & y=0 \end{cases} Focalloss={?��(1?p)��log(p),?(1?��)p��log(1?p),?y=1y=0?
ȡ �� = 0.25 \alpha=0.25 ��=0.25 ������,��������Ҫ�ȸ�����ռ��С,������Ϊ�������֡�
��������alpha�Ļ�,alpha=0.75ʱ�����ŵġ����ǽ�gamma���ǽ�����,��Ϊ�Ѿ������˼�������Ȩ��,gammaԽ��,ԽС��alpha���Խ�á����ȡ����alpha=0.25,gamma=2.0
https://zhuanlan.zhihu.com/p/49981234
class FocalLoss(nn.Module):
def __init__(self, gamma=0, alpha=None, size_average=True):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
if isinstance(alpha,(float,int,long)): self.alpha = torch.Tensor([alpha,1-alpha])
if isinstance(alpha,list): self.alpha = torch.Tensor(alpha)
self.size_average = size_average
def forward(self, input, target):
if input.dim()>2:
input = input.view(input.size(0),input.size(1),-1) # N,C,H,W => N,C,H*W
input = input.transpose(1,2) # N,C,H*W => N,H*W,C
input = input.contiguous().view(-1,input.size(2)) # N,H*W,C => N*H*W,C
target = target.view(-1,1)
logpt = F.log_softmax(input)
logpt = logpt.gather(1,target)
logpt = logpt.view(-1)
pt = Variable(logpt.data.exp())
if self.alpha is not None:
if self.alpha.type()!=input.data.type():
self.alpha = self.alpha.type_as(input.data)
at = self.alpha.gather(0,target.data.view(-1))
logpt = logpt * Variable(at)
loss = -1 * (1-pt)**self.gamma * logpt
if self.size_average: return loss.mean()
else: return loss.sum()
4.3 Dice Loss
Dice Loss:
D
i
c
e
_
L
o
s
s
=
1
?
D
i
c
e
_
C
o
e
f
f
i
c
i
e
n
t
Dice\_Loss = 1-Dice\_Coefficient
Dice_Loss=1?Dice_Coefficient
Dice ϵ��:
���� Lee Raymond Dice����,��һ�ּ������ƶȶ�������,ͨ�����ڼ����������������ƶ�(ֵ��ΧΪ [0, 1]),��ʽ����,������2����Ϊ��ĸ��������TP:
D i c e C o e f f i c i e n t = 2 �O X �� Y �O �O X �O + �O Y �O DiceCoefficient = \frac{2|X \cap Y|}{|X|+|Y|} DiceCoefficient=�OX�O+�OY�O2�OX��Y�O?
����, �O X �O |X| �OX�O�� �O Y �O |Y| �OY�O�ֱ��ʾ���ϵ�Ԫ�ظ���,�ָ�������,���߷ֱ��ʾGT��Ԥ�⡣
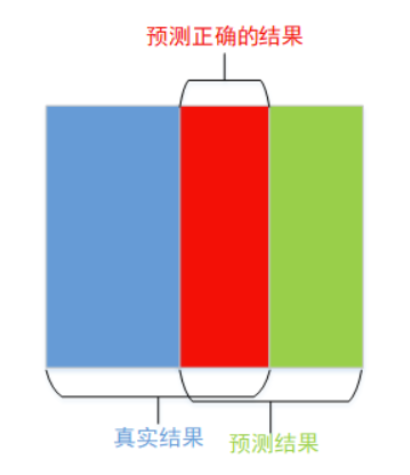
���� Dice Loss ��ʽ����:
D i c e L o s s = 1 ? 2 �O X �� Y �O �O X �O + �O Y �O DiceLoss = 1-\frac{2|X \cap Y|}{|X|+|Y|} DiceLoss=1?�OX�O+�OY�O2�OX��Y�O?
��IoU���ȵ�Dice:
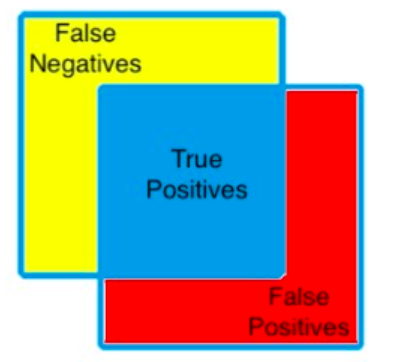
- ��ɫ����:Ԥ��Ϊnegative,����GT����positive��False Negative����;
- ��ɫ����:Ԥ��Ϊpositive,����GT����Negative��False positive����;
IoU����ʽ:
I o U = T P T P + F P + F N IoU = \frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP?
��˵����,�ص���Խ��,IoUԽ�ӽ�1,Ԥ��Ч��Խ�á�
Dice ϵ��:
D i c e _ C o e f f i c i e n t = 2 �O X �� Y �O �O X �O + �O Y �O Dice\_Coefficient = \frac{2|X \cap Y|}{|X|+|Y|} Dice_Coefficient=�OX�O+�OY�O2�OX��Y�O?
- �O X �� Y �O |X \cap Y| �OX��Y�O �� T P TP TP
- X X X �� G T GT GT �� T P + F N TP+FN TP+FN
- Y Y Y �� P r e d Pred Pred�� T P + F P TP+FP TP+FP
����:
D
i
c
e
_
C
o
e
f
f
i
c
i
e
n
t
=
2
��
T
P
T
P
+
F
N
+
T
P
+
F
P
Dice\_Coefficient = \frac{2 \times TP}{TP+FN+TP+FP}
Dice_Coefficient=TP+FN+TP+FP2��TP?
�������ǿ��Եõ�Dice��IoU֮��Ĺ�ϵ��,�����֮���DiceĬ�ϱ�ʾDice Coefficient:
I o U = D i c e 2 ? D i c e IoU=\frac{Dice}{2-Dice} IoU=2?DiceDice?
�������ͼ������ͼ,����ֻ��ע0~1�������ͺ���,���Է���:
- IoU��DiceͬʱΪ0,ͬʱΪ1;��ܺ�����,����ȫԤ����ȷ��ȫ��Ԥ�����
- ��������ͬ��Ԥ�������,���Է���Dice���������ۻ��IoU��һЩ,������������Dice�����ݻ���Ӻÿ�һЩ��
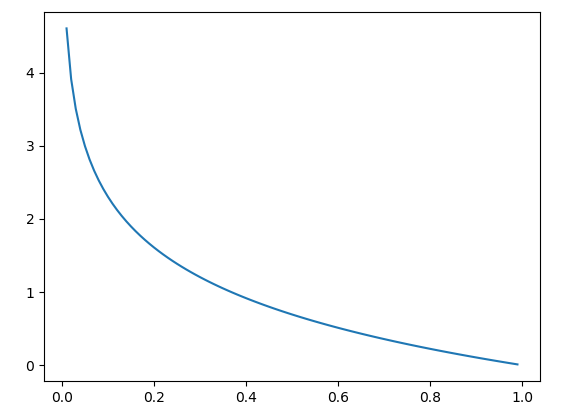
��Ҫע�����Dice Loss������������:
-
ѵ��������߷dz�����,���ѿ���������������Ϣ�����ܿ��Լ������֤���ϵ�������ܿ������⡣
-
Dice Loss�Ƚ��������������Ȳ��������,һ��������,ʹ�� Dice Loss ��Է�����ɲ�����Ӱ��,����ʹѵ����ò��ȶ���
������һ�������,����ʹ�ý�������ʧ������
Dice coefficient ͨ����������������ͼ������ƶ�,Dice loss ��ʽ����:
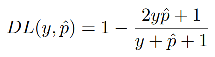
����,��ĸ���ӷֱ�� 1,��Ϊ�˱�֤��Ե����Ŀ�����,�統
y
=
p
^
=
0
y=\hat{p}=0
y=p^?=0 ʱ��
4.4 Tversky Loss
Tversky index(TI) Ҳ���Ա����� Dice coefficient ��һ����չ:
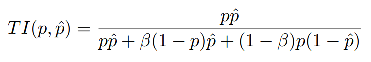
�� �� = 1 / 2 \beta=1/2 ��=1/2 ʱ,���� Dice coefficient��
Tversky loss ��ʽ����: