文章目录
【图像分类】2021-DeiT
论文题目:Training data efficient image transformers & distillation through attention
论文链接:https://arxiv.org/abs/2012.12877
论文代码:https://github.com/facebookresearch/deit
论文翻译:https://blog.csdn.net/gaocui883/article/details/124236798
1. 简介
1.1 简介
存在的问题
训练ViT不容易:
ViT需要大量的GPU资源:ViT-L “~8卡85天”
ViT的预训练数据集JFT-300M没有公开
超参数设置不好很容易Train不出效果
只用ImageNet训练准确率没有很好:
ViT-B: top1 acc 77.91
对于VIT训练数据巨大,超参数难设置导致训练效果不好的问题,提出了DeiT。
DeiT的模型和VIT的模型几乎是相同的,可以理解为本质上是在训一个VIT。
针对ViT难训练的问题,DeiT提出参数设置、数据增强、知识蒸馏来更有效地训练ViT。DeiT提出的训练方法成为后续ViT模型的训练标注。
Data-efficient image Transformers (DeiT) 的优势
- DeiT只需要8块GPUs训练2-3天 (53 hours train,20 hours finetune)。
- 数据集只使用 ImageNet。
- 不包含任何卷积 (Convolution)。
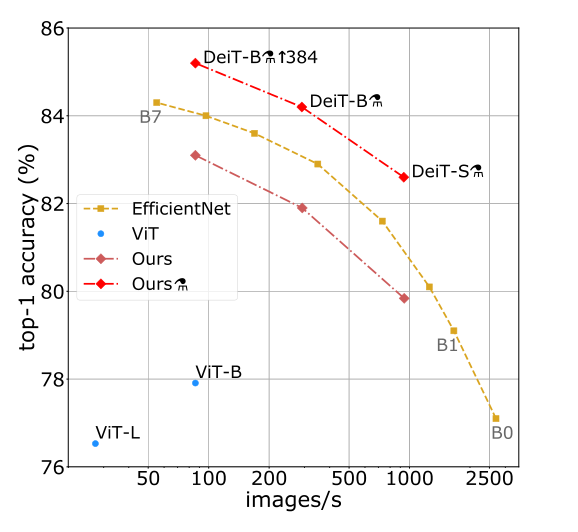
为什么DeiT能在大幅减少 1. 训练所需的数据集 和 2. 训练时长 的情况下依旧能够取得很不错的性能呢?
我们可以把这个原因归结为DeiT的训练策略。上图是用ImageNet训练并在ImageNet测试的性能结果。ViT在小数据集上的性能不如使用CNN网络EfficientNet,但是跟ViT结构相同,仅仅是使用更好的训练策略的DeiT比ViT的性能已经有了很大的提升,在此基础上,再加上蒸馏 (distillation) 操作,性能超过了EfficientNet。
1.2 什么是知识蒸馏
1) 什么是知识蒸馏?
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方式,由于其简单,有效,并且已经在工业界被广泛应用。这一技术的理论来自于2015年Hinton发表的一篇神作:论文:Distilling the Knowledge in a Nerual Network,
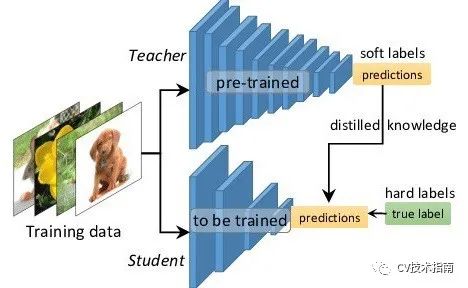
Knowledge Distillation,简称KD,顾名思义,就是将已经训练好的模型包含的知识(”Knowledge”),蒸馏(“Distill”)提取到另一个模型里面。知识蒸馏是指将笨拙的模型(教师)的学习行为转移到较小的模型(学生),其中,教师产生的输出被用作训练学生的“软目标”。通过应用此方法,作者发现他们在MNIST数据集上取得了令人惊讶的结果,并表明通过将模型集成中的知识提取到单个模型中可以获得显着的改进。
2) 主要流程
模型蒸馏的主要流程是先使用训练集训练出来一个完整复杂的teacher模型,然后设计一个小规模的student模型,再固定teacher模型的权重参数,然后使用训练集和teacher模型的输出同时对student模型进行训练,此时就需要设计一系列loss,让student模型在蒸馏学习的过程中逐渐向teacher模型的表现特性靠拢,使得student模型的预测精度逐渐逼近teacher模型。 所以从流程上来说,模型蒸馏中比较重要的就是loss函数的构成,比如可以将损失函数拆分成两个部分,一个部分为teacher模型输出与student模型输出之间的蒸馏损失(如KL散度),另一部分则是student模型输出与原始数据标签之间的交叉熵损失
3) 知识蒸馏用于图像分类
Hinton和他的两位合著者在论文中首先介绍了他们对图像分类任务的知识蒸馏:在神经网络中提炼知识。
如本文所述,知识蒸馏的最简单形式是在具有软目标分布的传递集上训练蒸馏模型。到目前为止,我们应该知道有两个目标用于训练学生模型。一个是正确的标签(硬目标),另一个是从教师网络生成的软标签(软目标)。
因此,目标函数是两个不同目标函数的加权平均值。 第一个目标函数是学生预测和软目标之间的交叉熵损失,第二个目标函数是学生输出和正确标签之间的交叉熵损失。 作者还提到,最好的结果通常是通过在第二目标函数上使用较低的权重来获得的。
2. 网络
2.1 整体架构
首先其整体示意图如下所示,DeiT并没有提出比较新颖的模型结构,对比ViT模型结构就是引入了一个distillation token作为蒸馏输出与teacher模型的输出计算蒸馏损失,而teacher模型可以选择Transformer模型也可以选择CNN模型(具体的蒸馏效果,作者做了一些对比实验)
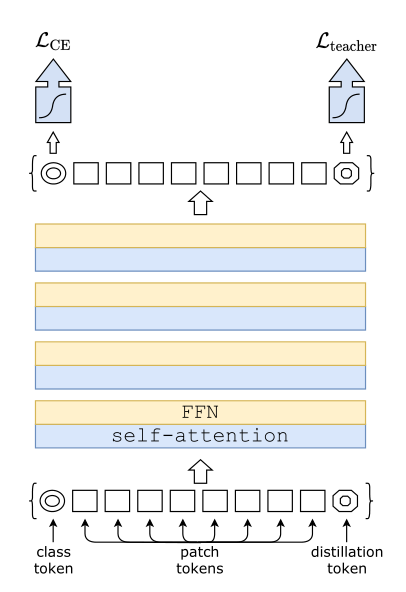
假设我们有一个性能很好的分类器 (它可以是CNN,也可以是Transformer,后面会有实验验证哪个效果更好) 作为teacher model。我们可以通过图3和4对比下DeiT与原版ViT的结构差异:通过引入了一个distillation token,然后在self-attention layers中跟class token,patch token不断交互。它跟左下角的class token很像,唯一的区别在于,class token的目标是跟真实的label一致,而distillation token是要跟teacher model预测的label一致。
2.2 知识蒸馏 损失(knowledge distillation)
1) 软蒸馏(soft distillation)
下图为soft distillation的原理图(为什么叫soft? 因为教师模型输出的是概率值):
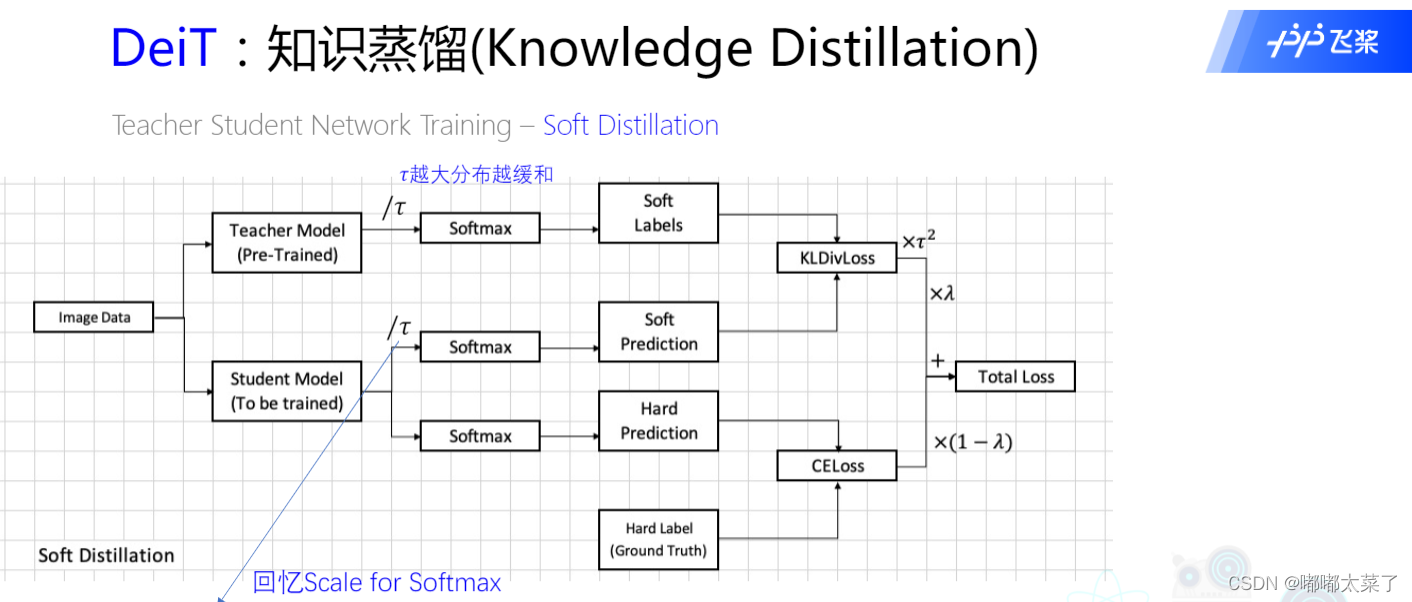
损失函数如下
L
global?
=
(
1
?
λ
)
L
C
E
(
ψ
(
Z
s
)
,
y
)
+
λ
τ
2
K
L
(
ψ
(
Z
s
/
τ
)
,
ψ
(
Z
t
/
τ
)
)
\mathcal{L}_{\text {global }}=(1-\lambda) \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{\mathrm{s}}\right), y\right)+\lambda \tau^{2} \mathrm{KL}\left(\psi\left(Z_{\mathrm{s}} / \tau\right), \psi\left(Z_{\mathrm{t}} / \tau\right)\right)
Lglobal??=(1?λ)LCE?(ψ(Zs?),y)+λτ2KL(ψ(Zs?/τ),ψ(Zt?/τ))
其中
- λ \lambda λ控制散度损失和交叉熵损失比率
- y表示ground truth,
- ψ ( Z s ) \psi\left(Z_{\mathrm{s}}\right) ψ(Zs?)表示学生模型的预测结果,
- ψ ( Z t / τ ) \psi\left(Z_{\mathrm{t}} / \tau\right) ψ(Zt?/τ)表示教师模型的预测结果,
- ψ ( Z s / τ ) \psi\left(Z_{\mathrm{s}} / \tau\right) ψ(Zs?/τ)distillation输出的概率),
- τ \tau τ 为温度
- ψ \psi ψ为softmax 函数
- KL 散度来做学生和老师模型的损失:
学生和教师模型的预测损失函数为KLDivLoss。
KL散度是什么东西呢:
K
L
(
A
∥
B
)
=
∑
i
A
(
i
)
log
?
A
(
i
)
B
(
i
)
\mathrm{KL}(\mathrm{A} \| \mathrm{B})=\sum_{\mathrm{i}} \mathrm{A}(\mathrm{i}) \log \frac{\mathrm{A}(\mathrm{i})}{\mathrm{B}(\mathrm{i})}
KL(A∥B)=i∑?A(i)logB(i)A(i)?
可以度量两个随机变量的距离,KL 散度就是两个概率分布A,B差别的非对称性的度量。
A表示真实分布,B表示理论分布或者模型。目标就是要让模型分布尽可能与真实分布相同,所以 B是老师,A是学生。
值越小,表示越接近,因此可以直接用来作为损失函数,KL散度也成为相对熵损失。
# pytorch 调用的两个方式
# 1.使用torch.nn.KLDivLoss()
# 这个class的forward如下
class KLDivLoss(_Loss):
"""
...
"""
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.kl_div(input, target, reduction=self.reduction, log_target=self.log_target)
# 这个类也是调用的F.kl_div这个函数
# 所以第二种使用方式就是
# 2.torch.nn.functional.kl_div()
# 这个函数最主要的三个参数:
# * input : 模型预测值,传入之前需要先算一下log()
# * target: 真实值
# * reduction: 四种取值'none' 就是各点单独计算loss ,'batchmean' 按batchsize划分计算loss的均值
# 'sum' 就是loss的总和, 'mean' 就是loss的均值
import torch.nn.functional as F
kl = F.kl_div(x.softmax(dim=-1).log(), y.softmax(dim=-1), reduction='sum')
温度 τ \tau τ的作用
softmax 对i 类别进行作用 :
q
i
=
exp
?
(
Z
i
/
τ
)
∑
j
(
Z
j
/
τ
)
\mathrm{q}_{\mathrm{i}}=\frac{\exp \left(\mathrm{Z}_{\mathrm{i}} / \tau\right)}{\sum_{\mathrm{j}}\left(\mathrm{Z}_{\mathrm{j}} / \tau\right)}
qi?=∑j?(Zj?/τ)exp(Zi?/τ)?
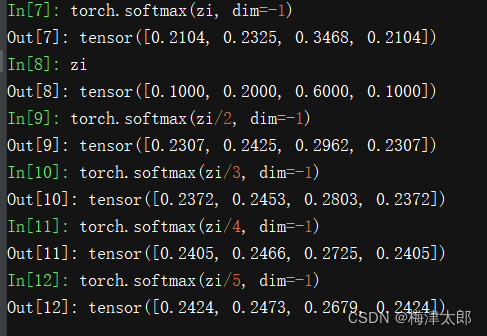
对 z i z_i zi?使用1-5 温度,来查看softmax 后变化的效果:
import matplotlib.pyplot as plt
x0 = [0.2104, 0.2325, 0.3468, 0.2104]
x1 = [0.2307, 0.2425, 0.2962, 0.2307]
x2 = [0.2372, 0.2453, 0.2803, 0.2372]
x3 = [0.2405, 0.2466, 0.2725, 0.2405]
x4 = [0.2424, 0.2473, 0.2679, 0.2424]
plt.plot(range(4), x0, marker='o', label = "t=1")
plt.plot(range(4), x1, marker='o', label = "t=2")
plt.plot(range(4), x2, marker='o', label = "t=3")
plt.plot(range(4), x3, marker='o', label = "t=4")
plt.plot(range(4), x4, marker='o', label = "t=5")
plt.legend()
plt.show()
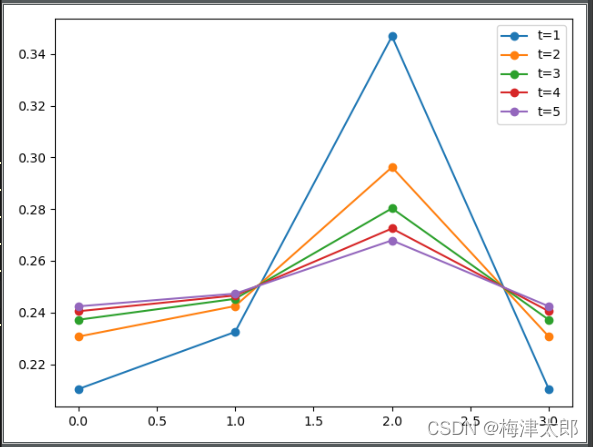
从图中可以看出,温度越大,变化越平缓。
也就是将原来容易区分的类别的距离拉近了,从而提高了分类难度。
放到公式中:
L
global?
=
(
1
?
λ
)
L
C
E
(
ψ
(
Z
s
)
,
y
)
+
λ
τ
2
K
L
(
ψ
(
Z
s
/
τ
)
,
ψ
(
Z
t
/
τ
)
)
\mathcal{L}_{\text {global }}=(1-\lambda) \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{\mathrm{s}}\right), y\right)+\lambda \tau^{2} \mathrm{KL}\left(\psi\left(Z_{\mathrm{s}} / \tau\right), \psi\left(Z_{\mathrm{t}} / \tau\right)\right)
Lglobal??=(1?λ)LCE?(ψ(Zs?),y)+λτ2KL(ψ(Zs?/τ),ψ(Zt?/τ))
就是降低老师模型的平缓度,同时降低学生的平欢度,两者都是为了提高学生网络的学习难度的。
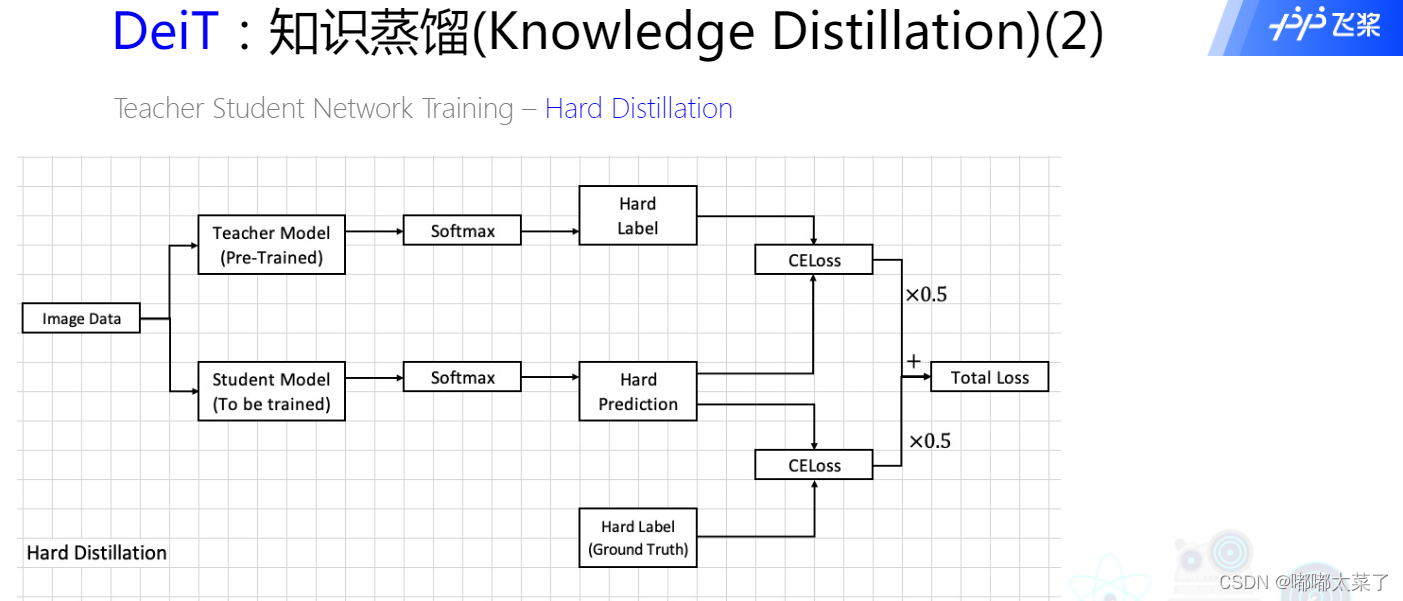
2) 硬蒸馏(Hard-label distillation)
下图为hard distillation的原理图(为什么叫hard? 因为教师模型输出的是预测结果,argmax的输出):
上边的是soft label 进行蒸馏,也就是通过学习学生网络最后的 l o g i t logit logit分布来进行的。而另一种就是hard label distillation,也就是学习不再是老师网络的 l o g i t logit logit,而是对 l o g i t logit logit进行 s o f t m a x softmax softmax,并且进行 a r g m a x ( . ) argmax(.) argmax(.)的结果,也就是老师预测的类别 y ′ y^\prime y′
损失函数如下,
L
global?
hardDistill?
=
1
2
L
C
E
(
ψ
(
Z
s
)
,
y
)
+
1
2
L
C
E
(
ψ
(
Z
s
)
,
y
t
)
y
t
=
argmax
?
c
Z
t
(
c
)
\mathcal{L}_{\text {global }}^{\text {hardDistill }}=\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{s}\right), y\right)+\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{s}\right), y_{\mathrm{t}}\right) \\ y_{\mathrm{t}}=\operatorname{argmax}_{c} Z_{\mathrm{t}}(c)
Lglobal?hardDistill??=21?LCE?(ψ(Zs?),y)+21?LCE?(ψ(Zs?),yt?)yt?=argmaxc?Zt?(c)
- y表示ground truth
- ψ ( Z s ) \psi\left(Z_{s}\right) ψ(Zs?)表示学生模型的预测结果
- y t y_{\mathrm{t}} yt?表示教师模型的预测结果(argmax的输出),
学生和教师模型的预测损失函数为CELoss。
简而言之,蒸馏的含义就是:学生网络的输出
Z
s
Z_s
Zs?与真实标签取CE Loss接着如果是硬蒸馏,就再与教师网络的标签取 CE Loss 。如果是软蒸馏,就再与教师网络的softmax输出结果取 KL Loss 。
值得注意的是,硬标签也可以通过标签平滑技术 (Label smoothing) 转换成软标签,其中真值对应的标签被认为具有 1 ? ε 1?ε 1?ε的概率,剩余的 ε ε ε由剩余的类别共享。 ε ε ε是一个超参数,这里取0.1。
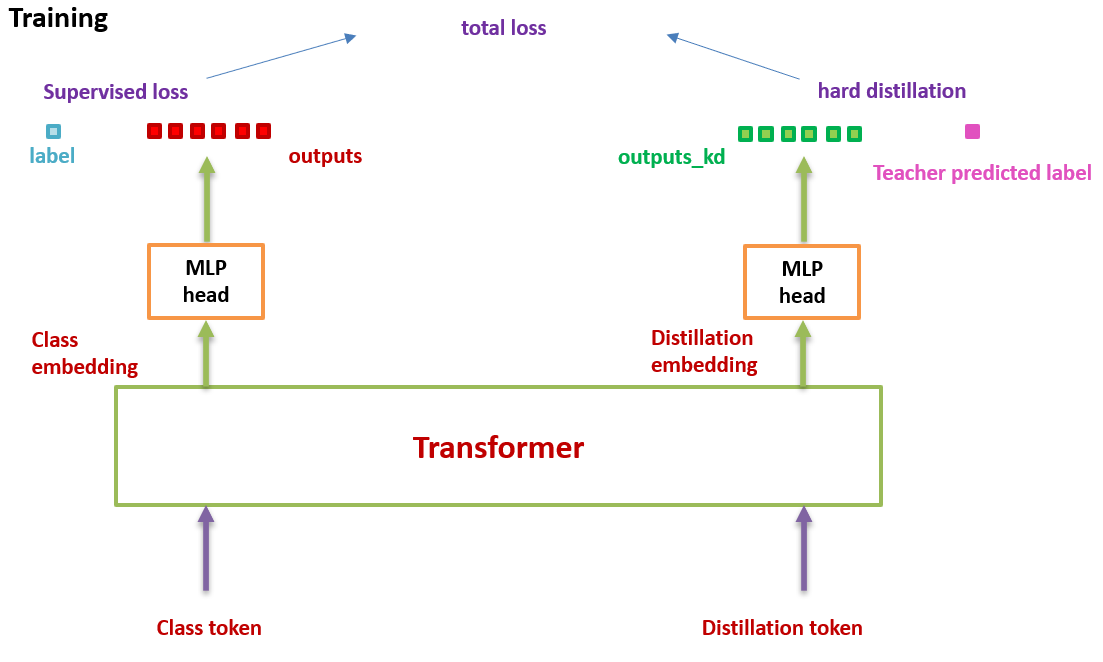
3) Distillation token
它和ViT中的class token一起加入Transformer中,和class token一样通过self-attention与其它的embedding交互作用,并且在最后一层之后由网络输出。
问:distillation token对应的这个输出的目标函数是什么?
答:就是蒸馏损失 (下图hard distillation loss 或者 soft distillation loss)。
distillation token 允许我们的模型从教师网络的输出中学习,就像在常规的蒸馏中一样,同时也作为一种对class token的补充。
作者发现一个有趣的现象,class token和distillation token是朝着不同的方向收敛的,对各个layer的这两个token计算余弦相似度,平均值只有0.06,不过随着网络会越来越大,在最后一层是0.93,也就是相似但不相同。 这是预料之中的,因为他们的目标是生产相似但不相同的目标。
作者做了个实验来验证这个确实distillation token有给模型add something。就是简单地增加一个class token来代替distillation token,然后发现,即使对这两个class token进行独立的随机初始化,它们最终会收敛到同一个向量 (余弦相似度为0.999),且性能没有明显提升。
在测试时,我们有class token的输出向量,有distillation token的输出向量,它们经过linear层都可以转化成预测结果,那么最终的预测结果怎么定呢?可以简单地把二者的softmax结果相加来得到预测结果。
2.3 总结
DeiT对比ViT而言,就是在patch tokens后又添加了一个distillation token,这个token最终的输出 负责与teacher模型的输出计算蒸馏损失,作者使用了两种蒸馏方式:硬蒸馏和软蒸馏(详见蒸馏损失说明)
对于不同的蒸馏策略得到的效果也不同,具体的对比实验如下图所示,实验表明:
1、对于Transformer来讲,硬蒸馏的性能明显优于软蒸馏
2、拿着训练好的模型,只使用distillation token进行测试,性能是要强于只使用class token进行测试的。当然两者都使用的效果最好,意味着这两个tokens提供了对分类有用的补充信息
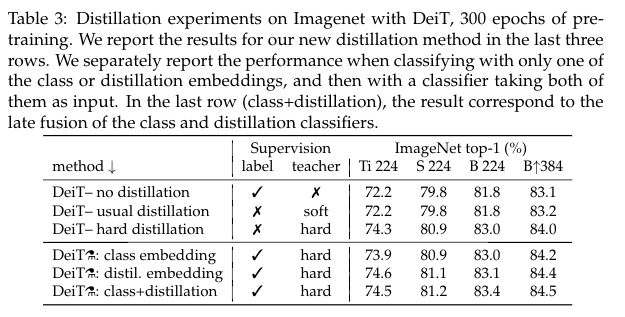
- 使用CNN作为teacher模型比transformer作为teacher的性能更优
3. 代码
代码使用 https://github.com/lucidrains/vit-pytorch
import torch
import torch.nn.functional as F
from torch import nn
from vit_pytorch.vit import ViT
from vit_pytorch.t2t import T2TViT
from vit_pytorch.efficient import ViT as EfficientViT
from einops import rearrange, repeat
# helpers
def exists(val):
return val is not None
# classes
class DistillMixin:
def forward(self, img, distill_token = None):
distilling = exists(distill_token)
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim = 1)
x += self.pos_embedding[:, :(n + 1)]
if distilling:
distill_tokens = repeat(distill_token, '() n d -> b n d', b = b)
x = torch.cat((x, distill_tokens), dim = 1)
x = self._attend(x)
if distilling:
x, distill_tokens = x[:, :-1], x[:, -1]
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
out = self.mlp_head(x)
if distilling:
return out, distill_tokens
return out
class DistillableViT(DistillMixin, ViT):
def __init__(self, *args, **kwargs):
super(DistillableViT, self).__init__(*args, **kwargs)
self.args = args
self.kwargs = kwargs
self.dim = kwargs['dim']
self.num_classes = kwargs['num_classes']
def to_vit(self):
v = ViT(*self.args, **self.kwargs)
v.load_state_dict(self.state_dict())
return v
def _attend(self, x):
x = self.dropout(x)
x = self.transformer(x)
return x
class DistillableT2TViT(DistillMixin, T2TViT):
def __init__(self, *args, **kwargs):
super(DistillableT2TViT, self).__init__(*args, **kwargs)
self.args = args
self.kwargs = kwargs
self.dim = kwargs['dim']
self.num_classes = kwargs['num_classes']
def to_vit(self):
v = T2TViT(*self.args, **self.kwargs)
v.load_state_dict(self.state_dict())
return v
def _attend(self, x):
x = self.dropout(x)
x = self.transformer(x)
return x
class DistillableEfficientViT(DistillMixin, EfficientViT):
def __init__(self, *args, **kwargs):
super(DistillableEfficientViT, self).__init__(*args, **kwargs)
self.args = args
self.kwargs = kwargs
self.dim = kwargs['dim']
self.num_classes = kwargs['num_classes']
def to_vit(self):
v = EfficientViT(*self.args, **self.kwargs)
v.load_state_dict(self.state_dict())
return v
def _attend(self, x):
return self.transformer(x)
# knowledge distillation wrapper
class DistillWrapper(nn.Module):
def __init__(
self,
*,
teacher,
student,
temperature = 1.,
alpha = 0.5,
hard = False
):
super().__init__()
assert (isinstance(student, (DistillableViT, DistillableT2TViT, DistillableEfficientViT))) , 'student must be a vision transformer'
self.teacher = teacher
self.student = student
dim = student.dim
num_classes = student.num_classes
self.temperature = temperature
self.alpha = alpha
self.hard = hard
self.distillation_token = nn.Parameter(torch.randn(1, 1, dim))
self.distill_mlp = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img, labels, temperature = None, alpha = None, **kwargs):
b, *_ = img.shape
alpha = alpha if exists(alpha) else self.alpha
T = temperature if exists(temperature) else self.temperature
with torch.no_grad():
teacher_logits = self.teacher(img)
student_logits, distill_tokens = self.student(img, distill_token = self.distillation_token, **kwargs)
distill_logits = self.distill_mlp(distill_tokens)
loss = F.cross_entropy(student_logits, labels)
if not self.hard:
distill_loss = F.kl_div(
F.log_softmax(distill_logits / T, dim = -1),
F.softmax(teacher_logits / T, dim = -1).detach(),
reduction = 'batchmean')
distill_loss *= T ** 2
else:
teacher_labels = teacher_logits.argmax(dim = -1)
distill_loss = F.cross_entropy(distill_logits, teacher_labels)
return loss * (1 - alpha) + distill_loss *
使用
import torch
from torchvision.models import resnet50
from vit_pytorch.distill import DistillableViT, DistillWrapper
teacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)
参考资料
Transformer学习(四)―DeiT - 知乎 (zhihu.com)
Vision Transformer 超详细解读 (原理分析+代码解读) (三) - 知乎 (zhihu.com)