
БОЦЊЗжЯэТлЮФЁКPeripheral Vision TransformerЁЛ,POSTECH&MSRA&жаПЦДѓЬсГіPerViT,ШУЩёОЭјТчвВФмЙизЂЭМЦЌжаЕФжиЕуаХЯЂ!
ЯъЯИаХЯЂШчЯТ:

ТлЮФЕижЗ:https://arxiv.org/abs/2206.06801
ЯюФПЕижЗ:http://cvlab.postech.ac.kr/research/PerViT/ (ЩаЮДПЊдД)
01
еЊвЊ
ШЫРрЪгОѕгЕгавЛжжЬиЪтРраЭЕФЪгОѕДІРэЯЕЭГ,ГЦЮЊЭтЮЇЪгОѕ(peripheral vision)ЁЃИљОнЕНФ§ЪгжааФЕФОрРыНЋећИіЪгвАЛЎЗжЮЊЖрИіТжРЊЧјгђ,ЭтЮЇЪгОѕЮЊШЫРрЬсЙЉСЫИажЊВЛЭЌЧјгђЕФИїжжЪгОѕЬиеїЕФФмСІЁЃ
дкетЯюЙЄзїжа,зїепВЩгУСЫвЛжжЪмЩњЮябЇЦєЗЂЕФЗНЗЈ,ВЂЬНЫїдкЩюЖШЩёОЭјТчжаЖдЭтЮЇЪгОѕНјааНЈФЃвдНјааЪгОѕЪЖБ№ЁЃзїепЬсГіНЋЭтЮЇЮЛжУБрТыКЯВЂЕНЖрЭЗздзЂвтСІВужа,вдШУЭјТчбЇЯАдкИјЖЈбЕСЗЪ§ОнЕФЧщПіЯТНЋЪгвАЛЎЗжЮЊВЛЭЌЕФЭтЮЇЧјгђЁЃ
зїепдкДѓЙцФЃ ImageNet Ъ§ОнМЏЩЯЦРЙРСЫБОЮФЬсГіЕФЭјТчPerViT,ВЂЯЕЭГЕибаОПСЫЛњЦїИажЊФЃаЭЕФФкВПЙЄзїдРэ,БэУїИУЭјТчбЇЯАИажЊЪгОѕЪ§ОнЕФЗНЪНРрЫЦгкШЫРрЪгОѕЕФЗНЪНЁЃдкИїжжФЃаЭДѓаЁЕФЭМЯёЗжРрШЮЮёжаЕФзюаТадФмжЄУїСЫЫљЬсГіЗНЗЈЕФгааЇадЁЃ
02
Motivation
дкЙ§ШЅЕФЪЎФъжа,ОэЛ§вЛжБЪЧЪгОѕЪЖБ№ЩёОЭјТчжаЕФжївЊЬиеїзЊЛЛ,вђЮЊЫќдкЭМЯёПеМфХфжУНЈФЃЗНУцОпгагХЪЦЁЃОЁЙмдкбЇЯАЪгОѕФЃЪНЗНУцКмгааЇ,ЕЋОэЛ§КЫЕФОжВПКЭОВжЙЬиадЯожЦСЫСщЛюДІРэжаБэЪОФмСІЕФзюДѓГЬЖШ,Р§Шч,ОпгаШЋОжИаЪмвАЕФЖЏЬЌБфЛЛЁЃ
здзЂвтСІзюГѕЪЧЮЊздШЛгябдДІРэ (NLP) ЩшМЦЕФ,ЫќВћУїСЫетИіЗНЯђ;ХфБИздЪЪгІЪфШыДІРэКЭВЖЛёдЖГЬНЛЛЅЕФФмСІ,ЫќвбГЩЮЊМЦЫуЛњЪгОѕЕФЬцДњЬиеїБфЛЛ,БЛЙуЗКгУзїКЫаФЙЙНЈПщЁЃ
ШЛЖј,ЖРСЂЕФздзЂвтФЃаЭ,Р§Шч ViT,ашвЊИќЖрЕФбЕСЗЪ§ОнВХФмгыЦфОэЛ§ЖдгІЮяЕФОКељадФм,вђЮЊЫќУЧДэЙ§СЫОэЛ§ЕФФГаЉРэЯыЪєад,Р§Шч,ОжВПадЁЃОэЛ§КЭздзЂвтСІЕФетаЉЙЬгагХШБЕуЙФРјСЫзюНќЖдСНепНсКЯЕФбаОП,вдБуЯэЪмСНШЋЦфУР,ЕЋФФвЛжжзюЪЪКЯгааЇЕФЪгОѕДІРэ,ЕЋдкЮФЯзжаЩагаељвщЁЃ

гыЛњЦїЪгОѕжаеМжїЕМЕиЮЛЕФЪгОѕЬиеїзЊЛЛВЛЭЌ,ШЫРрЪгОѕгЕгавЛжжЬиЪтРраЭЕФЪгОѕДІРэЯЕЭГ,ГЦЮЊЭтЮЇЪгОѕ(peripheral vision)ЁЃЫќИљОнЕНФ§ЪгжааФЕФОрРыНЋећИіЪгОѕЛЎЗжЮЊЖрИіТжРЊЧјгђ,ЦфжаУПИіЧјгђБъЪЖВЛЭЌЕФЪгОѕЗНУцЁЃШчЩЯЭМЫљЪО,ШЫРрдкзЂЪгжааФИННќ(МДжааФКЭзМжааФЧјгђ)НјааСЫИпЗжБцТЪДІРэ,вдЪЖБ№ИпЖШЯъЯИЕФЪгОѕдЊЫи,Р§ШчМИКЮаЮзДКЭЕЭМЖЯИНкЁЃ
ЖдгкОрРызЂЪгИќдЖЕФЧјгђ,МДжаВПКЭдЖБпдЕЧјгђ,ЗжБцТЪЛсНЕЕЭвдЪЖБ№ГщЯѓЕФЪгОѕЬиеї,Р§ШчдЫЖЏКЭИпМЖЩЯЯТЮФЁЃетжжЯЕЭГЛЏЕФВпТдЪЙШЫРрФмЙЛгааЇЕиИажЊвЛаЁВПЗж(1%)ЪгвАФкЕФживЊЯИНк,ЭЌЪБзюДѓЯоЖШЕиМѕЩйЖдЦфгрВПЗж(99%)БГОАдгВЈЕФВЛБивЊДІРэ,ДгЖјДйНјШЫФдЕФИпаЇЪгОѕДІРэЁЃ
ИљОнзюНќЖдЪгОѕTransformerФкВПЙЄзїдРэЕФбаОП,ЫќУЧЕФааЮЊЪЕМЪЩЯгыЭтЮЇЪгОѕЕФЙІФмУмЧаЯрЙиЁЃбЇЯАдчЦкВуЕФзЂвтСІЭМвдОжВПВЖЛёжааФЧјгђЕФЯИСЃЖШМИКЮЯИНк,ЖјКѓУцВуЕФзЂвтСІЭМдђжДааШЋОжзЂвтСІвдДгећИіЪгвАжаЪЖБ№ДжСЃЖШгявхКЭЩЯЯТЮФ,ИВИЧЭтЮЇЧјгђЁЃ
етаЉЗЂЯжБэУї,ФЃЗТЩњЮяЩшМЦПЩФмгажњгкЖдгааЇЕФЛњЦїЪгОѕНјааНЈФЃ,ВЂЧвЛЙжЇГжзюНќЪЕЯжОэЛ§КЭздзЂвтЕФЛьКЯЗНЗЈ,ЖјВЛНіНіЪЧЖРСЂЕФЪгОѕДІРэЁЃСНжжВЛЭЌИажЊВпТдЕФгХЪЦ:ЯИСЃЖШ/ОжВПКЭДжСЃЖШ/ШЋОжЁЃ
дкетЯюЙЄзїжа,зїепВЩгУСЫвЛжжЪмЩњЮябЇЦєЗЂЕФЗНЗЈ,ВЂЬсГіНЋЭтЮЇЙщФЩЦЋжУзЂШыЩюЖШЩёОЭјТчвдНјааЭМЯёЪЖБ№ЁЃзїепЬсГіНЋЭтЮЇзЂвтСІЛњжЦНсКЯЕНЖрЭЗздзЂвтСІжа,вдШУЭјТчбЇЯАдкИјЖЈбЕСЗЪ§ОнЕФЧщПіЯТНЋЪгвАЛЎЗжЮЊВЛЭЌЕФЭтЮЇЧјгђ,ЦфжаУПИіЧјгђВЖЛёВЛЭЌЕФЪгОѕЬиеїЁЃзїепЭЈЙ§ЪЕбщБэУї,ЫљЬсГіЕФЭјТчЖдгааЇЕФЪгОѕЭтЮЇНјааСЫНЈФЃ,вдЪЕЯжПЩППЕФЪгОѕЪЖБ№ЁЃ
БОЮФЕФжївЊЙБЯзПЩвдзмНсШчЯТ:
етЯюЙЄзїЬНЫїЭЈЙ§НЋЭтЮЇЙщФЩЦЋжУзЂШыздзЂвтСІВуРДЫѕаЁШЫРрКЭЛњЦїЪгОѕжЎМфЕФВюОр,ВЂЬсГіСЫвЛжжГЦЮЊЖрЭЗЭтЮЇзЂвт (MPA) ЕФаТаЮЪНЕФЬиеїзЊЛЛЁЃ
дк MPA ЕФЛљДЁЩЯ,зїепв§Шы PerViT(PerViT),ВЂЭЈЙ§ЖЈадКЭЖЈСПЗжЮі PerViT ЕФбЇЯАзЂвтСІЯЕЭГЕибаОП PerViT ЕФФкВПЙЄзїдРэ,етНвЪОСЫЭјТчбЇЯАИажЊЪгОѕдЊЫиЕФЗНЪНРрЫЦгкШЫРрЪгОѕУЛгаЕФЗНЪНШЮКЮЬиЪтМрЖНЁЃ
ВЛЭЌФЃаЭДѓаЁЕФЭМЯёЗжРрШЮЮёЕФзюаТадФмбщжЄСЫЫљЬсГіЗНЗЈЕФгааЇадЁЃ
03
ЗНЗЈ
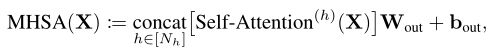
ЦфжаЪЧвЛзщЪфШыtoken,КЭЪЧзЊЛЛВЮЪ§ЁЃздзЂвтСІЕФИіЪфГіжМдкДгЪфШыБэЪОжаЬсШЁвЛзщВЛЭЌЕФЬиеїЁЃаЮЪНЩЯ,head h ЕФ self-attention ЖЈвхЮЊ:
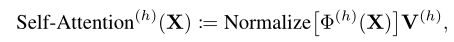
Цфжа Normalize[ЁЄ] БэЪОж№ааЙщвЛЛЏ,ЪЧвЛИіЛљгкФкШнаХЯЂЬсЙЉПеМфзЂвтСІвдОлКЯжЕЕФКЏЪ§:
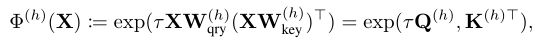
ЪЙгУЕФЯпадЭЖгАЗжБ№гУгкВщбЏЁЂМќКЭжЕЁЃ
3.1 Peripheral Vision Transformer
Лљгк MHSA ЕФЙЋЪН,зїепНЋЖрЭЗЭтЮЇзЂвт (MPA) ЖЈвхЮЊ:
 Цфжа
ЪЧ Hadamard Л§,ЫќЛьКЯСЫИјЖЈЕФзЂвтСІЖдвдЬсЙЉЛьКЯзЂвтСІ
ЁЃЖдгкЛљгкФкШнЕФзЂвтСІ
,зїепдкВщбЏКЭМќжЎМфЪЙгУжИЪ§(ЫѕЗХ)ЕуЛ§:
ЁЃЖдгкЛљгкЮЛжУЕФзЂвтСІ
,зїепЩшМЦСЫвЛИіжМдкФЃЗТШЫРрЪгОѕЯЕЭГ(Р§ШчЭтЮЇЪгОѕ)ЕФЩёОЭјТчЁЃ
Цфжа
ЪЧ Hadamard Л§,ЫќЛьКЯСЫИјЖЈЕФзЂвтСІЖдвдЬсЙЉЛьКЯзЂвтСІ
ЁЃЖдгкЛљгкФкШнЕФзЂвтСІ
,зїепдкВщбЏКЭМќжЎМфЪЙгУжИЪ§(ЫѕЗХ)ЕуЛ§:
ЁЃЖдгкЛљгкЮЛжУЕФзЂвтСІ
,зїепЩшМЦСЫвЛИіжМдкФЃЗТШЫРрЪгОѕЯЕЭГ(Р§ШчЭтЮЇЪгОѕ)ЕФЩёОЭјТчЁЃ
Modelling peripheral vision: a Roadmap
ШЫРрЪгвАПЩвдИљОнгызЂЪгжааФЕФХЗЪНОрРыЗжЮЊМИИіЧјгђ,УПИіЧјгђаЮГЩШчЭМ1ЫљЪОЕФЛЗаЮЧјгђ,ЦфжаУПИіЧјгђВЖЛёВЛЭЌЕФЪгОѕЗНУц;РыФ§ЪгдННќ,ДІРэЕФЬиеїдНИДдг,РыФ§ЪгдНдЖ,ИажЊЕФЪгОѕЬиеїОЭдНМђЕЅЁЃдкЖўЮЌзЂвтСІЭМЕФЩЯЯТЮФжа,зїепНЋВщбЏЮЛжУ,МДИааЫШЄЕФЬиеїЫљдкЕФЮЛжУНјааБфЛЛ,зїЮЊзЂЪгжааФ,ОжВПВщбЏжмЮЇЕФЧјгђЮЊжааФ/зМжааФЧјгђ,ЦфгрЮЊжа/дЖЭтЮЇЧјгђЁЃ
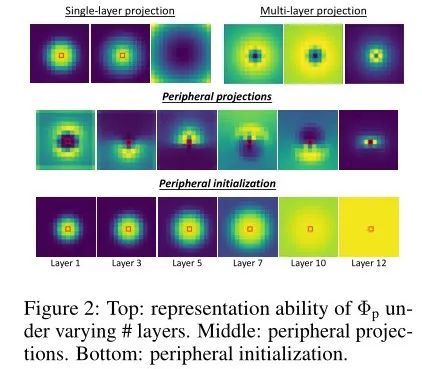
вВаэНЋЪгвАЛЎЗжЮЊЖрИізгЧјгђЕФзюМђЕЅЗНЗЈЪЧЖдХЗЪНОрРыжДааЕЅИіЯпадЭЖгА,МД,Цфжа,ЮЊСЫжБНгФЃЗТЭтЮЇЪгОѕ,зїепЪЙгУХЗЪНОрРызїЮЊЯрЖдЮЛжУЪфШы R,ВЂвджжВЛЭЌЗНЪНШЈКтОрРы,вдБуЭјТчбЇЯАЖрИіГпЖШЕФгГЩф:,ЦфжаЪЧвЛзщПчВуКЭЭЗЙВЯэЕФПЩбЇЯАВЮЪ§,ВЂЧвЪЧВщбЏКЭМќЮЛжУжЎМфЕФХЗЪНОрРы,ЁЃ
Ждгк Ів,зїепбЁдё sigmoid РДЮЊЛљгкФкШнЕФзЂвтСІЬсЙЉЙщвЛЛЏШЈжиЁЃетжжЕЅВуЙЋЪНЕФвЛИіжївЊШБЕуЪЧжЛФмЬсЙЉШчЩЯЭМзѓЩЯНЧЫљЪОЕФРрЫЦИпЫЙЕФзЂвтСІЭМ,вђДЫЮоЗЈБэЪОВЛЭЌЕФЭтЮЇЧјгђЁЃЖдгкБэЪОВЛЭЌ(ЛЗаЮ)ЭтЮЇЧјгђЕФБрТыКЏЪ§,ОрРыБиаыгЩ MLP ДІРэ:
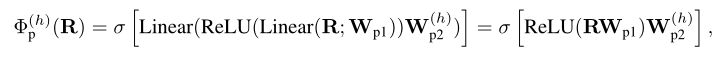
ЦфжаКЭ ЪЧЯпадЭЖгАВЮЪ§,ReLU ИГгшКЏЪ§ЗЧЯпадЁЃЕквЛИіЭЖгАдкЭЗжЎМфЙВЯэвдНЛЛЛаХЯЂ,вђДЫУПИіЬиеїЖМФмЙЛЬсЙЉЖдЦфЫћЭЗзЂвтСІгааЇЛђЛЅВЙЕФзЂвтСІЁЃИјЖЈЙЬЖЈВщбЏЕуКЭЙиМќЕужЎМфЕФЯрЭЌЯрЖдОрРы,МД,ЩЯЪНЬсЙЉСЫЯрЭЌЕФзЂвтСІЗжЪ§:,ШчЩЯЭМЕФгвЩЯНЧЫљЪОЁЃ
ШЛЖј,дкЪЕМЪГЁОАжаВЂВЛзмЪЧашвЊДЫЪєад,вђЮЊа§зЊЖдГЦЪєадМИКѕВЛЪЪгУгкДѓЖрЪ§ЯжЪЕЪРНчЕФЖдЯѓЁЃЮЊСЫДђЦЦЩЯЪНжаЕФЖдГЦЪєад,ВЂГфЗжБЃСєЭтЮЇЩшМЦ,зїепв§Шы ЭтЮЇЭЖгА(peripheral projection) ,ЦфжаБфЛЛВЮЪ§БЛИГгшаЁЕФПеМфЗжБцТЪ,ЪЙЕУКЭ,вђДЫЫќУЧЬсЙЉЯрЫЦЕЋВЛЭЌЕФзЂвтСІЗжЪ§,ЁЃИјЖЈ,ЭЈЙ§ВЮПММќжмЮЇЕФЯрСкЯрЖдОрРы:
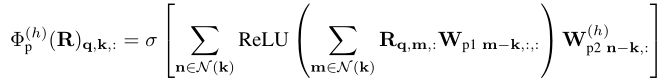
ЦфжаЪЧвЛИіЬсЙЉЪфШыЮЛжУжмЮЇЕФвЛзщСкгђЕФКЏЪ§ЁЃдкУПИіЭтЮЇЭЖгАжЎКѓ,зїепЬэМгвЛИіЪЕР§ЙщвЛЛЏВувдНјааЮШЖЈгХЛЏ:
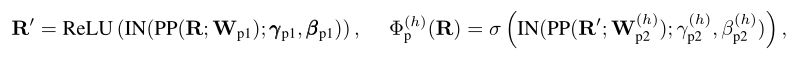
ЦфжаЪЧЪЕР§ЗЖЪ§ЕФШЈжи/ЦЋжУЁЃЩЯЭМЕФжаМфааУшЛцСЫОпгаЭтЮЇЭЖгАЕФЕФбЇЯАзЂвтСІ,гыУЛга N ЕФЕЅВуКЭЖрВуЖдгІЮяЯрБШ,ЫќЬсЙЉСЫИќЖрбљЛЏЕФЭтЮЇзЂвтСІЭМЁЃ
Peripheral initialization
зюНќЕФбаОПЙлВьЕН,ЪмЙ§бЕСЗЕФЪгОѕTransformerЕФдчЦкВубЇЯАОжВПЙизЂ,ЖјКѓЦкВудђжДааШЋОжЙизЂЁЃЮЊСЫДйНјБОЮФЭјТчЕФбЕСЗ,зїепдкбЕСЗНзЖЮЕФПЊЪМзЂШыетИіЪєад,ЮЊДЫФПЕФЭЈЙ§ГѕЪМЛЏ ЕФВЮЪ§,ЪЙППНќВщбЏЕФзЂвтСІЗжЪ§ДѓгкдчЦкВужаНЯдЖЕФВщбЏ,ЭЌЪБОљдШЕиЗжВМдкКѓЦкВужа,ШчЩЯЭМЕФЕзааЫљЪОЁЃзїепНЋДЫЗНЗЈГЦЮЊ ЭтЮЇГѕЪМЛЏ( peripheral initialization) ,вђЮЊЫќРрЫЦгкЭтЮЇЪгОѕЕФЬиеї,ЭтЮЇЪгОѕвВПЩвддкОжВПЛђШЋОжЗЖЮЇФкВйзївдИажЊВЛЭЌЕФЪгОѕЁЃИјЖЈСНИіШЮвтбЁдёЕФОрРы,Тњзу ,зїепЯЃЭћ,МДдчЦкВуЕФОжВПзЂвтСІЁЃ
ЖдгкКѓЦкВуЕФШЋОжзЂвтСІ,зїепЯЃЭћЁЃзїепЪзЯШНЋКЭЕФВЮЪ§ГѕЪМЛЏЮЊЬиЖЈжЕЁЃОпЬхРДЫЕ,ЖдгкЫљгаВуКЭ head :
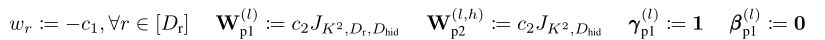
ЦфжаЪЧе§ЪЕЪ§,жИЕФЪЧДѓаЁЮЊ N ЁС M ЕФШЋвЛОиеѓЁЃЩЯЪіГѕЪМЛЏдкЕкЖўДЮЭтЮЇЭЖгАКѓЬсЙЉОжВПзЂвтСІ,МДИјЖЈ,ЁЃ
НгЯТРД,ЛљгкБОЮФЕФЗЂЯж,МДЕкЖўЪЕР§ЗЖЪ§жаЕФЦЋВюКЭШЈжиЗжБ№ПижЦОжВПзЂвтСІЕФДѓаЁКЭЧПЖШ,ЭЈЙ§НЋЫќУЧЕФГѕЪМжЕЩшжУЮЊРДФЃФтЭтЮЇГѕЪМЛЏ,ЦфжаЪЧзЂвтСІДѓаЁКЭЧПЖШЕФГѕЪМжЕМЏЁЃ
3.2 Overall Architecture
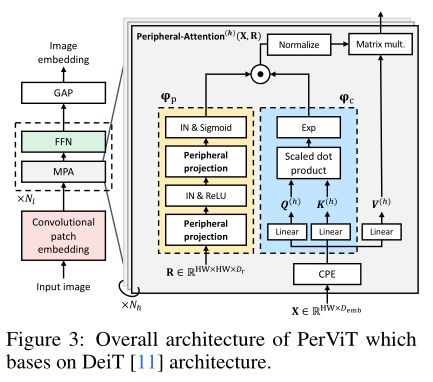
ЛљгкЬсГіЕФЭтЮЇЭЖгАКЭГѕЪМЛЏ,зїепПЊЗЂСЫГЦЮЊЭтЮЇЪгОѕTransformerЕФЭМЯёЗжРрФЃаЭ,ШчЩЯЭМЫљЪОЁЃдЪМЕФ patchify stemгЩгкЦфДжСЃЖШЕФдчЦкЪгОѕДІРэЖјБэЯжГіВЛКЯБъзМЕФПЩгХЛЏад,вђДЫаэЖрзюНќЕФ ViT ФЃаЭВЩгУЖрЗжБцТЪН№зжЫўЩшМЦРДЛКНтИУЮЪЬтЁЃ
ЫфШЛН№зжЫўФЃаЭдкбЇЯАПЩППЕФЭМЯёЧЖШыЗНУцвбОЯдЪОГіЫќУЧЕФЙІаЇ,ЕЋзїепМсГжЪЙгУ PerViT ЕФдЪМЕЅЗжБцТЪдВжљаЮЩшМЦ,вђЮЊЖрЗжБцТЪЕФЬиеїЪЙБОЮФЕФбаОПФбвдНтЪЭЁЃЮЊСЫНјааЯИСЃЖШЕФдчЦкДІРэ,ЭЌЪББЃГжПчВуЕФЕЅЗжБцТЪЬиеї,зїепВЩгУОэЛ§patchЧЖШыВу,ЭЈЕРГпДчОпгаЖрНзЖЮВМОжЁЃОэЛ§ЧЖШыВугЩЫФИі 3ЁС3 КЭвЛИі 1ЁС1 ОэЛ§зщГЩ,Цфжа 3ЁС3 ОэЛ§КѓУцЪЧBatchNormКЭReLUЁЃ
Peripheral Vision Transformer
ИјЖЈвЛеХЭМЯё,ОэЛ§patchЧЖШыЬсЙЉСЫtokenЧЖШыЁЃЧЖШыБЛРЁЫЭЕНИіПщ,УПИіПщгЩвЛИі MPA ВуКЭвЛИіДјгаВаВюТЗОЖЕФЧАРЁЭјТчзщГЩ: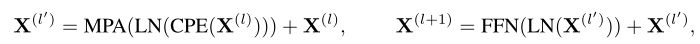
Цфжа LN ЪЧВуЙщвЛЛЏ,FFN ЪЧгЩСНИіДјга GELU МЄЛюЕФЯпадБфЛЛзщГЩЕФ MLPЁЃ зїепдкЕквЛВуЙщвЛЛЏжЎЧАВЩгУОэЛ§ЮЛжУБрТы (CPE),МД 3 ЁС 3 Щю ЖШОэЛ§ЁЃ ЪфГі БЛШЋОжЦН ОљГиЛЏвдаЮГЩЭМЯёЧЖШыЁЃ
04
ЪЕбщ
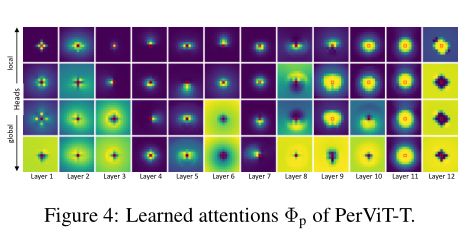
ЩЯЭМеЙЪОСЫбЇЯАЕНЕФзЂвтСІЭМ,ПЩвдЙлВьЕНзЂвтСІБЛбЇЯАЕНДІгкВЛЭЌаЮзДЕФЭтЮЇЧјгђжаЁЃ
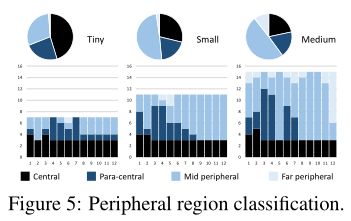
ЩЯЭМЕФБ§ЭМУшЪіСЫ TinyЁЂSmall КЭ Medium ФЃаЭЕФЭтЮЇЧјгђЕФБШР§,ЦфжаЬѕаЮЭМвдЗжВуЗНЪНЯдЪОЫќУЧЁЃ
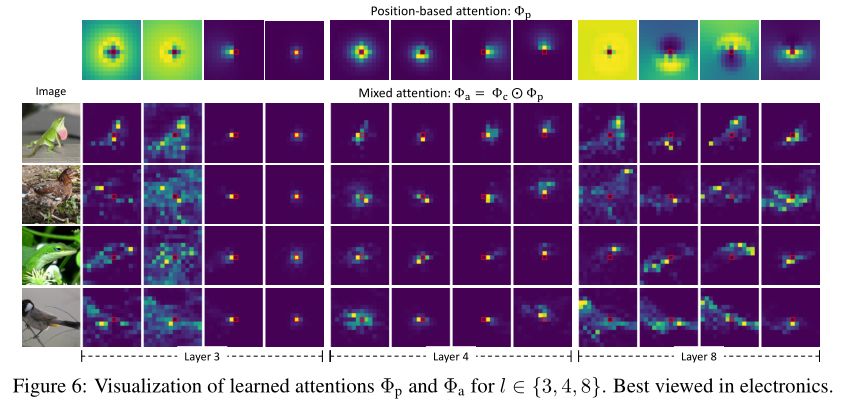
ЮЊСЫбаОПЛљгкЮЛжУЕФзЂвтСІШчКЮЖдЛьКЯзЂвтСІ зіГіЙБ,зїепЪеМЏбљБОЭМЯёВЂНЋЦфдкЩЯЭМжаЕФЕк 3ЁЂ4 КЭ 8 ВуЕФзЂвтСІЭМПЩЪгЛЏЁЃ
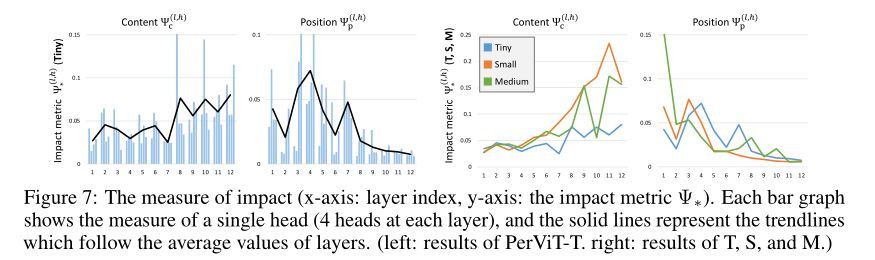
ШчЩЯЭМЫљЪО,зїепЙлВьЕНвЛИіУїЯдЕФЧїЪЦ,МДЛљгкЮЛжУЕФзЂвтСІЕФгАЯьдкдчЦкДІРэжаЯдзХИќИп,АыЖЏЬЌЕизЊЛЛЬиеї,ЖјКѓУцЕФВуашвЊНЯЩйЕФЮЛжУаХЯЂ,НЋЪгЮЊНЯаЁЕФЮЛжУЦЋВюЁЃетжжЧїЪЦЫцзХИќДѓЕФФЃаЭБфЕУИќМгУїЯд,ШчЩЯЭМгвВрЫљЪО;гы Tiny ФЃаЭЯрБШ,Small КЭ Medium ФЃаЭИќЖрЕиРћгУЖЏЬЌзЊЛЛ,гШЦфЪЧдкКѓУцЕФВужаЁЃ
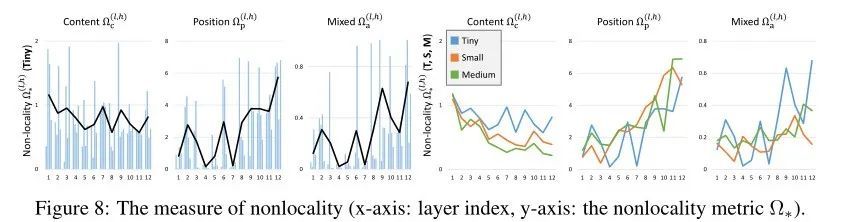
ШчЩЯЭМЫљЪО,зїепЙлВьЕНжЎМфЯрЫЦЕФОжВПадЧїЪЦ,етБэУїЮЛжУаХЯЂдкаЮГЩгУгкЬиеїзЊЛЛЕФПеМфзЂвтСІ () ЗНУцБШФкШнаХЯЂИќеМжїЕМЕиЮЛЁЃ
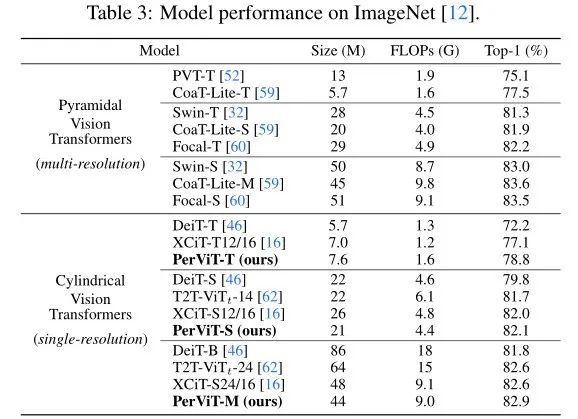
ЩЯБэеЙЪОСЫБОЮФЗНЗЈКЭSOTAЗНЗЈЕФЖдБШНсЙћЁЃ
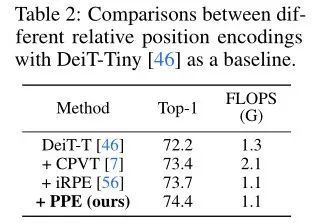
ЩЯБэеЙЪОСЫВЛЭЌЯрЖдЮЛжУБрТыЕФНсЙћЖдБШЁЃ
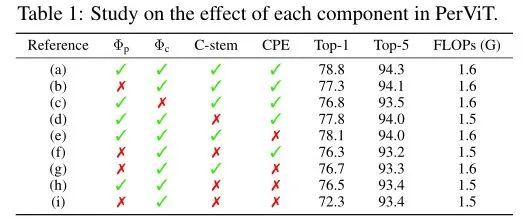
ЩЯБэеЙЪОСЫБОЮФЗНЗЈЕФВЛЭЌФЃПщЕФЯћШкНсЙћЁЃ
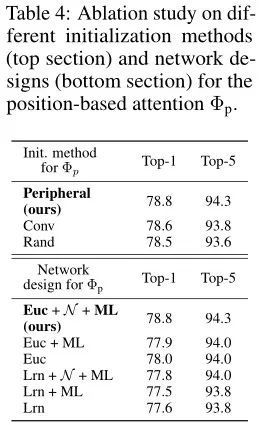
ЩЯБэеЙЪОСЫВЛЭЌЕФГѕЪМЛЏЗНЗЈКЭЭјТчЩшМЦЖдЪЕбщНсЙћЕФгАЯьЁЃ
05
змНс
зїепЯЕЭГЕибаОПСЫЫљЬсГіЭјТчЕФФкВПЙЄзїдРэ,ВЂЙлВьЕНЭјТчЭЈЙ§бЇЯАОіЖЈЬиеїзЊЛЛжаЕФОжВПадКЭЖЏЬЌадЫЎЦН,ЭЈЙ§ЭјТчБОЩэИјЖЈбЕСЗЪ§Он,ДгЖјЯэЪмОэЛ§КЭздзЂвтСІЕФКУДІЁЃдкВЛЭЌФЃаЭДѓаЁКЭЩюШыЕФЯћШкбаОПжа,ImageNet ЩЯЯжгаММЪѕЕФГжајИФНјжЄЪЕСЫЫљЬсГіЗНЗЈЕФгааЇадЁЃ
ВЮПМзЪСЯ
[1]https://arxiv.org/abs/2206.06801Ј зїепМђНщ баОПСьгђ:FightingCVЙЋжкКХдЫгЊеп,баОПЗНЯђЮЊЖрФЃЬЌФкШнРэНт,зЈзЂгкНтОіЪгОѕФЃЬЌКЭгябдФЃЬЌЯрНсКЯЕФШЮЮё,ДйНјVision-LanguageФЃаЭЕФЪЕЕигІгУЁЃ жЊКѕ/ЙЋжкКХ:FightingCV
вбНЈСЂЩюЖШбЇЯАЙЋжкКХЁЊЁЊFightingCV,ЛЖгДѓМвЙизЂ!!!
ICCVЁЂCVPRЁЂNeurIPSЁЂICMLТлЮФНтЮіЛузм:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
УцЯђаЁАзЕФAttentionЁЂжиВЮЪ§ЁЂMLPЁЂОэЛ§КЫаФДњТыбЇЯА:https://github.com/xmu-xiaoma666/External-Attention-pytorch