前言
计算机视觉可以应用在很多不同的行业、不同的场景当中,而自动驾驶领域是这众多的行业、场景里面之一。
当一个大问题到了非常具体的行业、到了一个具体的场景中时,那么对应产生的任务也需要具体落地,这些具体任务就形成了行业中的落地应用。
下面,我们通过几个具体的案例,来看看目标检测如何在自动驾驶领域中进行具体应用。
一、在高速行驶的过程中,目标在远处时就需要提前被感知,这样才能留给系统足够的时间进行反应。
这该如何做到?
在车辆驾驶的过程中,一旦提高车速,摄像头需要对远方的目标有及时的感知能力。
而远处的目标通常会以小目标的形式出现,在目标检测中检测出小目标具备一定的困难。但是如果只有目标具有某个大小尺寸时才能检测到,那么接下来给予系统反应的时间就会变得非常少,因为可能一眨眼的瞬间就会相撞,此时危险性极高。
在《Object detection with location-aware deformable convolution and backward attention filtering》中,作者使用了后向注意力过滤后的模型来对应这个问题。
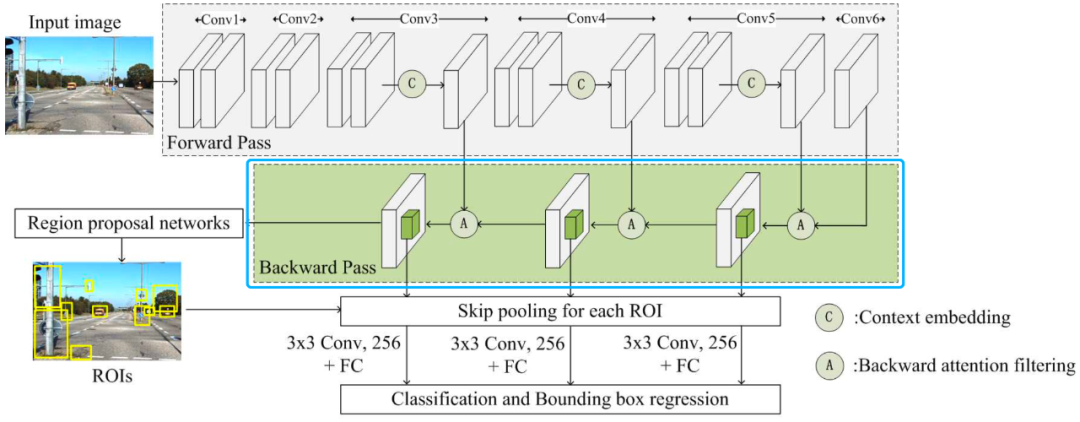
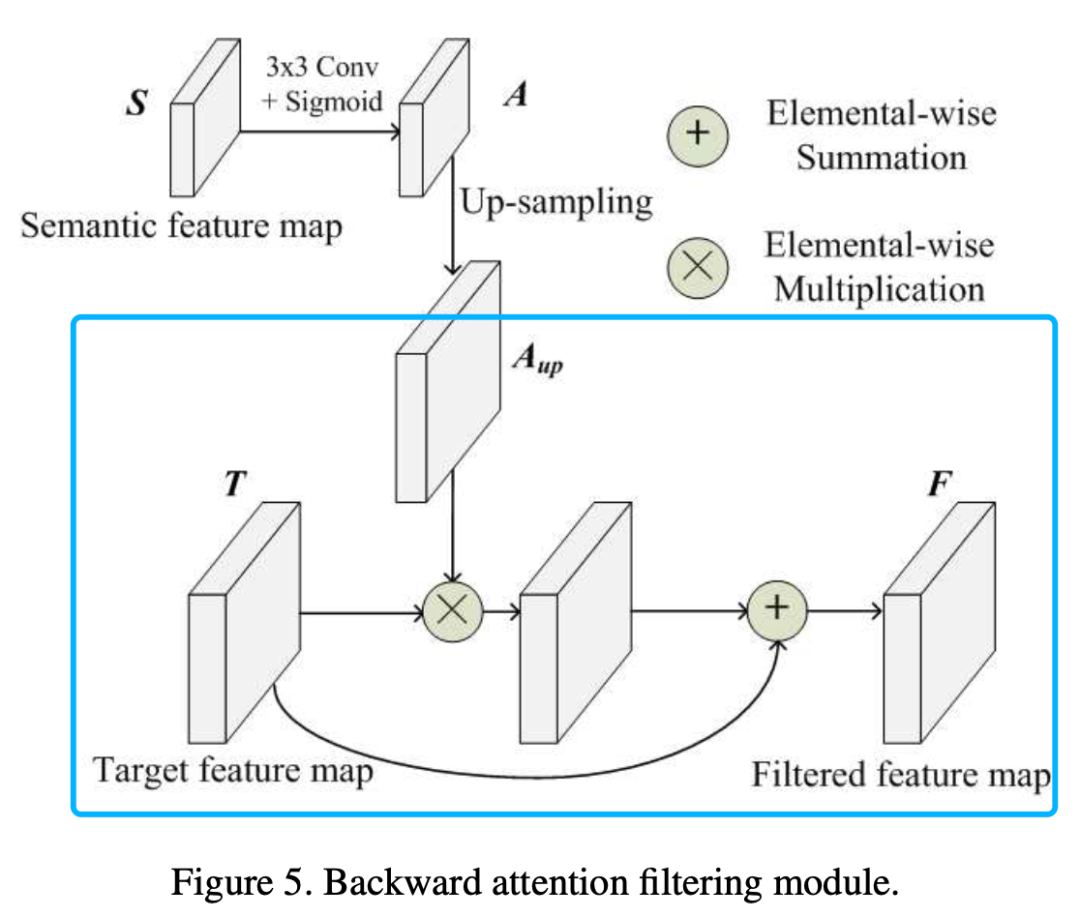
如上图所示,作者在对feature map进行上采样的过程中,对之前的浅层feature进行了融合,这个融合并非element wide的相加,也不是concat的channel拼接。
作者设计了一个滤波器,使得上采样的feature map和浅层feature map可以形成过滤掉“背景”的效果,如此一来,小尺寸的目标在更纯净,更少噪声的feature map就能被网络更好地识别出来。
二、在交通道路上,两辆车在行驶,它们之间的距离有时候相近,有时候甚远。
那么,该如何根据时间序列上的信息更好地检测到对方的存在呢?
在较为空旷的交通道路上,车速一般都会比较快。两辆高速行驶的车,它们之间的相对距离变化会比较大,摄像头中采集到的目标就会在单位时间内快速变大或快速变小。
如果能够提前预判和推理到对方车辆的存在,那么车辆在行驶过程中就有更多时间进行决策。
例如,对方在自己左侧车道中远离(当前自己的车速更快),那么在自己下一次超车时,就需要额外小心,左侧车道的车会不会忽然加速,出现追尾的事故。
在《Video Object Detection With Two-Path Convolutional LSTM Pyramid》中,作者采取了一种“双路径的卷积长短时记忆金字塔”网络来应对这个问题。
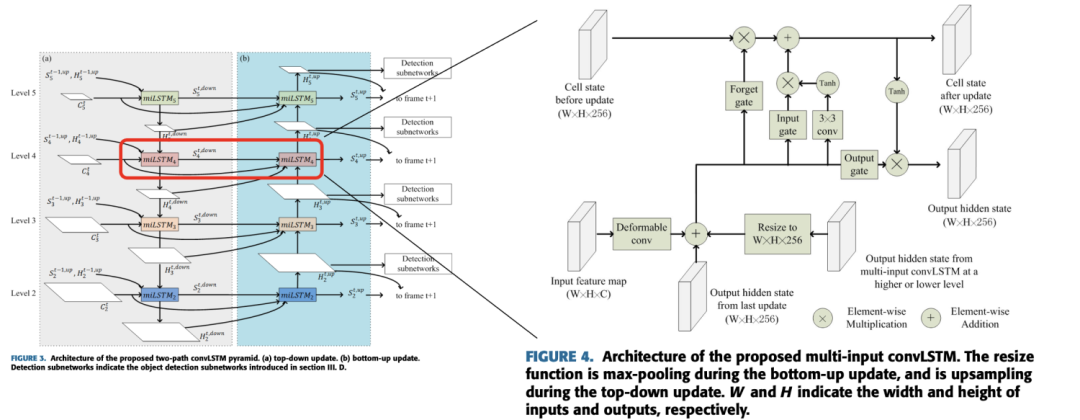
通过双路径的金字塔结构,不同尺寸的feature可以在不同尺寸的感知区域中进行信息交换和信息流动;
而LSTM本身可以把时间信息从上一个时刻t-1带到下一个时刻t,这又使得上一个时刻中不同尺度感知的记忆可以带到当前时刻中不同尺度的记忆中。
由此,使得在时间流中,目标在快速尺度变换时,也能通过这种信息交换机制进行相关性的传递,更好地检查到目标。

(上图很直观地对使用这种方式带来的改进进行的可视化)
三、多个目标重叠在一起时,如果能有效地检测到他们的存在,那么他们忽然分离时,系统也不会因此感到“意外”。
这是如何做到的?
在人群中,如果有一辆自行车被遮挡在人群中,仅仅露出了局部。自行车的移动速度比人群快。
此时,这个“整体目标”在以某个速度进行行进的过程就会忽然让自行车离群。
如果能提前感知到自行车的存在,那么这有利于系统有足够的时间反应和预判,减少感到“意外”。
在《Object detection with location-aware deformable convolution and backward attention filtering》中,作者提出了基于位置感知的可变卷积来对应这个问题。
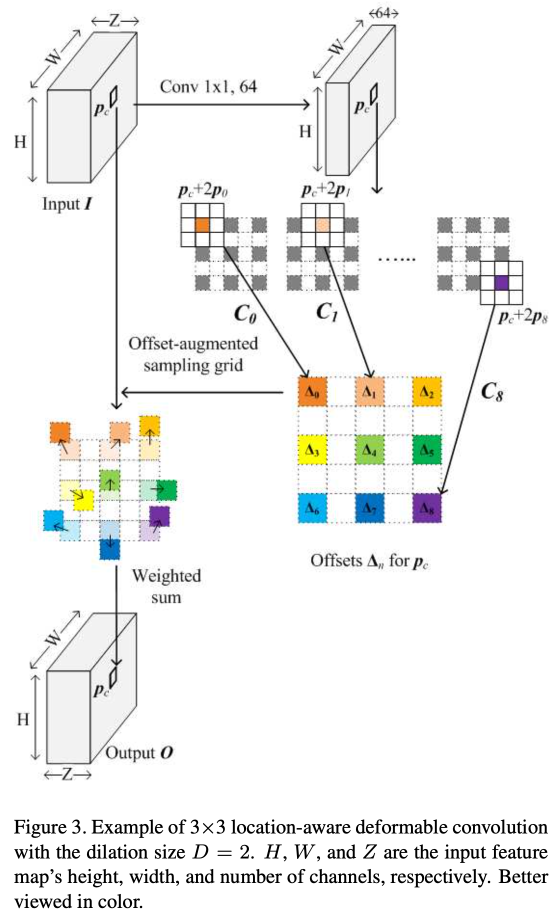
与一般的可变卷积不同,基于位置感知的可变卷积的学习偏移量的卷积层使用的卷积核,可以和位置感知的可变形卷积核有不同的受视野:
1.可变形卷积网络中,如果计划使用的可变形卷积核是膨胀率为1的3*3卷积核,那么学习偏移量的卷积核也必须是使用标准的3*3卷积核;
2.位置感知的可变形卷积网络中,虽然计划使用的可变卷积核是膨胀率为2的3*3卷积核,但是学习偏移量的卷积核依然可以随意选择自己的受视野,
同时,基于位置感知的可变卷积在学习每个采样点的偏移量时,卷积运算的中心点以采样点为基础:
1.可变形卷积网络中,学习偏移量的卷积操作是以当前input feature map的输入样本点为中心的。
例如,假设当前坐标为(0,0),那么它的9个偏移量都是以(0,0)作为中心点进行卷积操作的。
2.位置感知的可变形卷积网络中,学习偏移量的卷积操作是以可变性卷积核的采样点为中心的。
例如,假设当前坐标为(0,0),根据膨胀率为2的情况下,那么它的9个偏移量都是以对应(0,0)(-2,-2)(-2,0)(-2,2)(0,-2)(0,2)(-2,2)(0,2)(2,2)的9个采样点作为中心点进行卷积操作的。
基于位置感知的可变卷积,它的灵活性使得它能更好地捕捉到目标的“特征”,即便目标被局部遮挡时,也能有很好的检测效果。

如上图所示,作者的模型可以检测到行人背后的自行车,这个连人肉眼都难以辨别的目标也被可靠地检测出来,以保证尽可能全面的交通参与者都被检测到,确保安全。
小结
计算机视觉在各行各业的不同场景中有着不同的应用,落到自动驾驶这个具体的领域中,也会使得任务被具体化。
针对一些特定的自动驾驶过程中关注的问题,研究方向也会变得细节化。
就如上文提及的,对小目标检测的需求,对两个目标运动时的参照物关系,以及对重叠目标检测的诉求,都是自动驾驶领域比较关注的应用。
作者:四叶山桐