目录
?活动地址:CSDN21天学习挑战赛
学习:深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天_K同学啊的博客-CSDN博客
(文章内部分相关概念解释来源于 百度)
一、前期准备
1.1 环境配置
? ? ? ? 详情请见博主的另一篇文章
深度学习21天――准备(环境配置)_清园暖歌的博客-CSDN博客
1.2 CPU和GPU
1.2.1 CPU
????????CPU(Central Processing Unit-中央处理器),是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
 ?
?
1.2.2 GPU
????????GPU(Graphics Processing Unit-图形处理器),是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器。
 ?
?
1.2.3 CPU和GPU的区别
(1)缓存
????????CPU有大量的缓存结构,目前主流的CPU芯片上都有四级缓存,这些缓存结构消耗了大量的晶体管,在运行的时候需要大量的电力。
????????GPU的缓存就很简单,目前主流的GPU芯片最多有两层缓存,而且GPU可以利用晶体管上的空间和能耗做成ALU单元,因此GPU比CPU的效率要高一些。
(2)响应方式
????????CPU要求的是实时响应,对单任务的速度要求很高,所以就要用很多层缓存的办法来保证单任务的速度。
????????GPU是把所有的任务都排好,然后再批处理,对缓存的要求相对很低。
(3)浮点运算方式
????????CPU除了负责浮点整形运算外,还有很多其他的指令集的负载,比如像多媒体解码,硬件解码等,因此CPU是多才多艺的。CPU注重的是单线程的性能,要保证指令流不中断,需要消耗更多的晶体管和能耗用在控制部分,于是CPU分配在浮点计算的功耗就会变少。
????????GPU基本上只做浮点运算的,设计结构简单,也就可以做的更快。GPU注重的是吞吐量,单指令能驱动更多的计算,相比较GPU消耗在控制部分的能耗就比较少,因此可以把电省下来的资源给浮点计算使用。
(4)应用方向
????????CPU所擅长的像操作系统这一类应用,需要快速响应实时信息,需要针对延迟优化,所以晶体管数量和能耗都需要用在分支预测、乱序执行、低延迟缓存等控制部分。
????????GPU适合对于具有极高的可预测性和大量相似的运算以及高延迟、高吞吐的架构运算。
? ? ?
????????所以,我们在做深度学习时,有条件尽量使用gpu,更有效率、节能
第一步:设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
1.3 MNIST 手写数字数据集
MNIST是一个公开的数据集,获取网址为MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges(下载后需解压)
mnist 是一个包含 60,000 个 28x28 的 10 位灰度图像的数据集,以及一个包含 10,000 个图像的测试集。更多信息可以在 MNIST 主页上找到
第二步:导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()train_images:uint8 具有形状的灰度图像数据的 NumPy 数组(60000, 28, 28),包含训练数据。像素值范围从 0 到 255。
train_labels:uint8 NumPy 数字标签数组(0-9 范围内的整数)与形状(60000,)对于训练数据。
test_images:uint8 NumPy 灰度图像数据数组,形状为 (10000, 28, 28),包含测试数据。像素值范围从 0 到 255。
test_labels:uint8 NumPy 数字标签数组(0-9 范围内的整数)与形状(10000,)为测试数据。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
assert x_train.shape == (60000, 28, 28)
assert x_test.shape == (10000, 28, 28)
assert y_train.shape == (60000,)
assert y_test.shape == (10000,)1.4 归一化
归一化是为了消除量纲,因为数据都是 0-255 的像素值,所以这里除以 255
第三步:归一化
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
"""
二、其他代码理解
2.1 可视化图片
第四步:可视化
plt.figure(figsize=(20,10)) # 生成指定宽和高的画布(20,10)
for i in range(20):
plt.subplot(5,10,i+1) # 生成5行10列位置,这个是第i+1个
plt.xticks([]) # 横坐标刻度为空
plt.yticks([]) # 纵坐标刻度为空
plt.grid(False) # False:设置背景网格线不显示
plt.imshow(train_images[i], cmap=plt.cm.binary) # 显示第i个图片,binary为黑白色(二值)
plt.xlabel(train_labels[i]) # 显示第i个标签
plt.show()
(1)figure语法说明
figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)
num:图像编号或名称,数字为编号 ,字符串为名称
figsize:指定figure的宽和高,单位为英寸;
dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80 1英寸等于2.5cm,A4纸是 21*30cm的纸张
facecolor:背景颜色
edgecolor:边框颜色
frameon:是否显示边框
参考plt.figure()参数使用详解及运行演示_超级-马里奥的博客-CSDN博客_plot.figure
2.2 调整图片格式
第五步:调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
"""
reshape的第四个参数可能是 排序:顺序或逆序,不确定
2.3 构建CNN网络
2.3.1 卷积神经网络(CNN)
以下概念摘自学习笔记:深度学习(3)――卷积神经网络(CNN)理论篇_新四石路打卤面的博客-CSDN博客_图解卷积神经网络
????????CNN是一种带有卷积结构的前馈神经网络,卷积结构可以减少深层网络占用的内存量,其中三个关键操作――局部感受野、权值共享、池化层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
????????卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此而得名1。
????????CNN主要应用于图像识别(计算机视觉,CV),应用有:图像分类和检索、目标定位检测、目标分割、人脸识别、骨骼识别和追踪,具体可见MNIST手写数据识别、猫狗大战、ImageNet LSVRC等,还可应用于自然语言处理和语音识别。
????????总的来说,CNN是为了解决两个难题:① 图像需要处理的数据量太大,导致成本很高,效率很低;② 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。
2.3.2 主要结构
CNN主要包括以下结构:
(1)输入层(Input layer):输入数据;
(2)卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
(3)激活层:非线性映射(ReLU)
(4)池化层(Pooling layer,POOL):进行下采样降维;
(5)光栅化(Rasterization):展开像素,与全连接层全连接,某些情况下这一层可以省去;
(6)全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
(7)激活层:非线性映射(ReLU)
(8)输出层(Output layer):输出结果。
????????其中,卷积层、激活层和池化层可叠加重复使用,这是CNN的核心结构。
????????在经过数次卷积和池化之后,最后会先将多维的数据进行“扁平化”,也就是把(height,width,channel)的数据压缩成长度为height × width × channel的一维数组,然后再与FC层连接,这之后就跟普通的神经网络无异了。
? ? ? ? 具体每个层的内容就直接到我上面转的那个博主的文章看吧
第六步:构建CNN网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),#卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层2,2*2采样
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取
layers.Dense(10) #输出层,输出预期结果
])
# 打印网络结构
model.summary()
?下图来自深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天_K同学啊的博客-CSDN博客

(1)layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)):
其他参数参考:TensorFlow 之 keras.layers.Conv2D( ) 主要参数讲解_分发吧的博客-CSDN博客_layers.conv2d
? ? ? ? 32:32个核
? ? ? ? (3,3):卷积核大小为3×3
? ? ? ? activation='relu':激活函数
? ? ? ? input_shape:根据名称判断该参数应该是单个数据的shape值
? ? ? ? 此外步长未指定,应该是默认的 1
relu激活函数
公式: f ( x ) = m a x ( 0 , x )
图像:
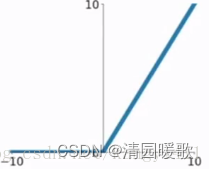
1. 为什么要用ReLU激活函数
由于sigmoid函数在输入远离中心点时导数会很小,会出现梯度消失的现象。使用ReLU激活函数时则不会出现梯度消失的现象。
但是当输入为负数时ReLU函数会死掉,拐点不可导。所以需要做特殊处理。
转自文章:“智能”(5)――ReLU激活函数&卷积神经网络_Nevey-Chen的博客-CSDN博客_activation='relu
sigmoid函数:f(x)= 1/(1+e^(-z))
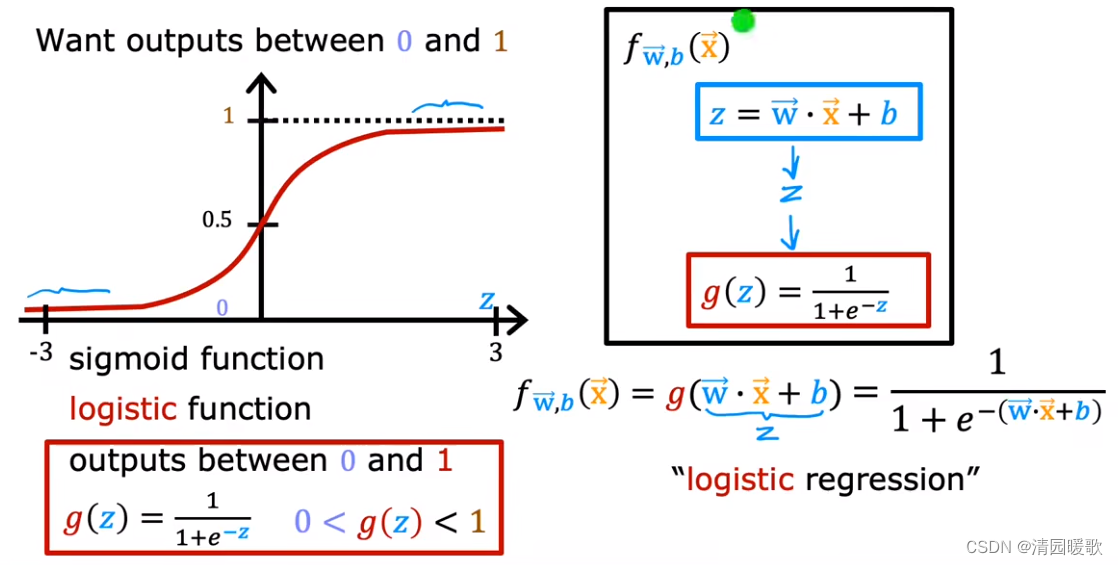
(2)layers.MaxPooling2D((2, 2))?
? ? ? ? 设置池化层的尺寸为 2×2
其他参数参考:CNN中的最大池化(MaxPool2D)的参数和含义,_园游会的魔法糖的博客-CSDN博客_maxpooling2d
(3)models.Sequential
????????Sequential()方法是一个容器,描述了神经网络的网络结构,在Sequential()的输入参数中描述从输入层到输出层的网络结构
tensorflow中tf.keras.models.Sequential()用法_yunfeather的博客-CSDN博客_models.sequential()
(4)layers.dense
tf.layers.dense用于添加一个全连接层。
函数如下:
tf.layers.dense(
? ? inputs,?? ??? ??? ??? ??? ?#层的输入
? ? units,?? ??? ??? ??? ??? ?#该层的输出维度
? ? activation=None,?? ??? ?#激活函数
? ? use_bias=True,?? ??? ??? ?
? ? kernel_initializer=None, ??? ?# 卷积核的初始化器
? ? bias_initializer=tf.zeros_initializer(), ?# 偏置项的初始化器
? ? kernel_regularizer=None, ? ?# 卷积核的正则化
? ? bias_regularizer=None, ? ??? ?# 偏置项的正则化
? ? activity_regularizer=None,?
? ? kernel_constraint=None,
? ? bias_constraint=None,
? ? trainable=True,
? ? name=None, ?# 层的名字
? ? reuse=None ?# 是否重复使用参数
)部分参数解释:
inputs:输入该层的数据。
units:该层的输出维度。
activation:激活函数。
use_bias:是否使用偏置项。
trainable=True:表明该层的参数是否参与训练。
tf.layers.dense的使用方法_Bubbliiiing的博客-CSDN博客_layers.dense
2.3.3 编译模型
第七步:编译模型
"""
这里设置优化器、损失函数以及metrics
这三者具体介绍可参考博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
https://blog.csdn.net/qq_38251616/category_10258234.html
tensorflow中model.compile()用法_yunfeather的博客-CSDN博客_model.compile
adam算法介绍和总结_Only_whitecat的博客-CSDN博客_adam 算法
简而言之,adam算法可以在传统梯度下降算法的基础上,能够自适应的改变学习率
2.3.4 训练模型
plt.imshow(test_images[1])
第八步:训练模型
"""
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
关于model.fit()函数的具体介绍可参考博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
https://blog.csdn.net/qq_38251616/category_10258234.html
2.3.5 预测
第九步:预测
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果
与测试集的一张图片比较
plt.imshow(test_images[1])