目录
1.论文下载地址
https://arxiv.org/abs/1505.04597
2.FCN语义分割
https://mydreamambitious.blog.csdn.net/article/details/125966298
3.U-Net正文
(1)U-Net概述
人们对于深度神经网络的认识是,需要通过大量的带标签的数据集进行训练才能得到较好的结果,然而在UNet这篇文章当中,提出了一种“全卷积网络”;这个网络分为两部分:第一部分为收缩路径(contracting path);第二部分为相称的扩张路径(expanding path)用来精确定位的。并且也提出了使用数据增强的策略,这给数据集较少的情况下扩充了数据集的大小。并且这个网络支持端到端的训练,在最新型的GPU上,512x512图像的分割时间不到一秒,比之前的方法都要好。最终的结果是赢得了2015年ISBI的细胞跟踪挑战(ISBI cell tracking challenge)。
(2)提出原由
我们在图像的分类领域中,图像的最终输出是单个的类标签,因为最终的输出表示预测的结果;然而生物医学图像领域不同(因为处理的图像更加的细),我们希望每个像素的输出是多个类标签的,而且也存在一个问题就是不可能训练成千上万的图片,所以有研究者在训练的网络中通过提供周围的局部区域作为输入,来预测每个像素的类标签。可是这样做很明显是有缺点的,因为网络训练是像素周围局部区域,所以训练的数据量比训练图片的数据量要大得多。
缺点:
? ? ? ?a.首先是非常的慢,因为每一个patch都要通过网络来运行,并且有很多重复的patches。
? ? ? ?b.定位准确率(localization accuracy)和上下文(the use of context)不能同时兼顾。大的patches需要更多的最大池化层,从而降低了局部的准确性,但是小的patches只能看到很小的context。
因此这篇文章提出了一种更好的网络结构“全卷积网络”,对其进行了修改和扩展,从而能够在处理很少的训练图像上产生更加精确分割。以下就是提出的网络结构,呈现的是一个'U型结构,虽然有大量的特征通道,但是这能够将上下文信息(context information)传播到更高分辨率层。
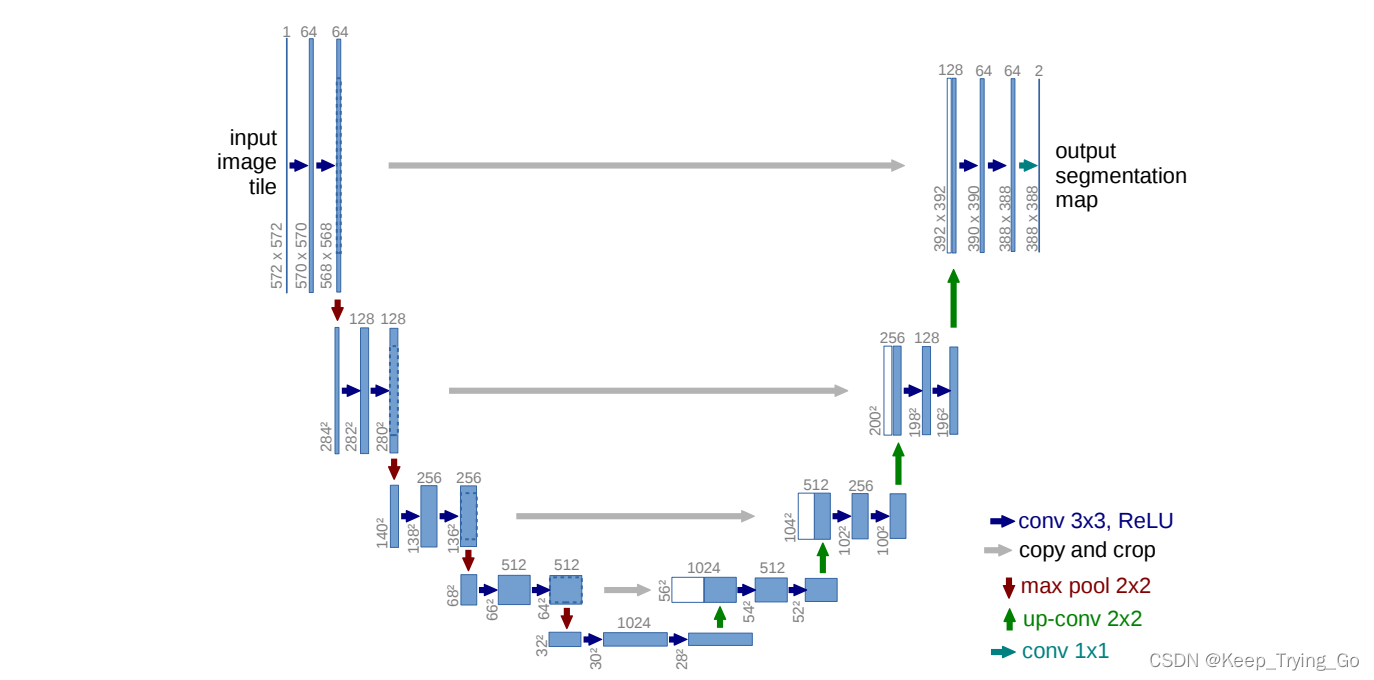
结构说明:
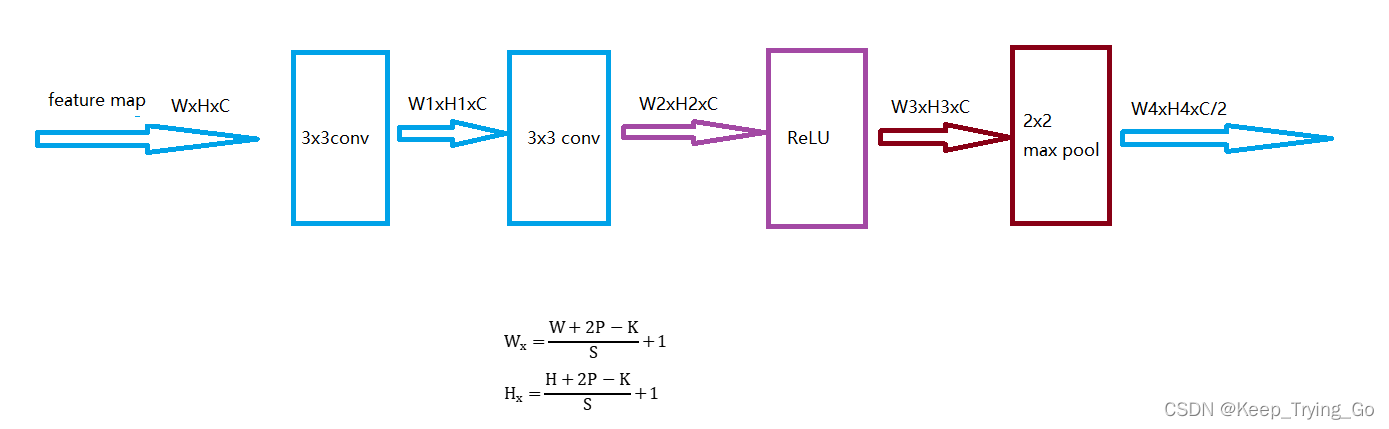
? ?左侧为收缩路径:在收缩路径中使用的典型的卷积网络结构,重复使用3x3卷积操作(padding=0),接着跟一个非线性激活函数ReLU和一个步长为2的最大池化并且通道数x2,进行下采样操作(downSampling)。
?
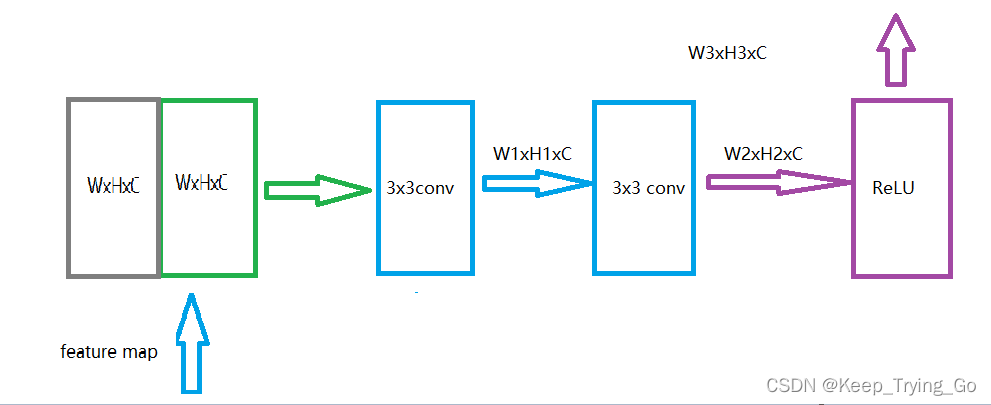
右侧为扩大路径:使用2x2卷积将特征图通道数减半,并且与来自收缩路径相应的特征图进行拼接,接着是两个3x3的卷积操作和一个非线性激活函数ReLU。在最后一层使用1x1卷积来映射每个64组件特征向量到所需的类数。该网络总共23个卷积层。
?
?优点:
? ? ? ? ?a.提高了输出的分辨率;
? ? ? ? ?b.使用局部的信息,将收缩路径(contracting path)中的高分辨率特征作为上层的输出;
? ? ? ? ?c.连续的卷积层能根据这些信息学习综合,从而更加精确的输出;
? ? ? ? ?d.端到端的训练方式;
? ? ? ? ?e.在一秒只能即可对图像进行分割。
(3)overlap-tile策略
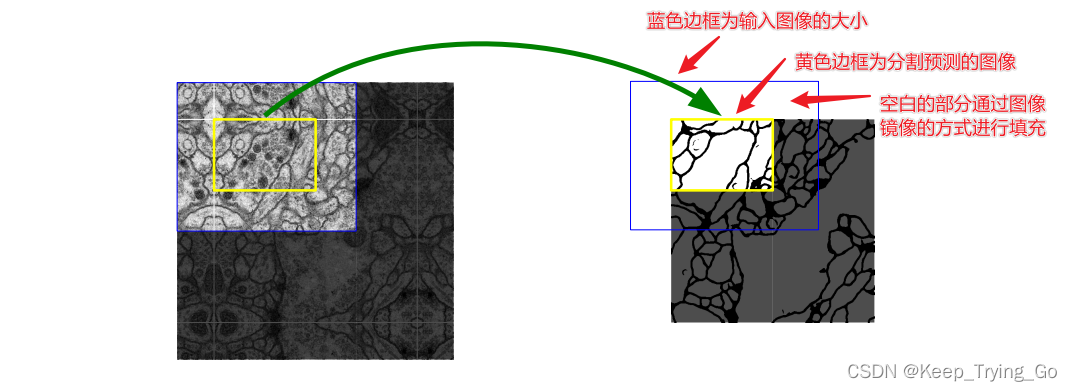
通过overlap-tile方式对任意大的图像进行无缝分割;使用这种方式的主要原因是:如果将一整张超大分辨率的图像直接输入到网络中,会导致GPU显存“爆炸”,所以采用这种裁剪的方式(但是又不同于普通的裁剪)。
(4)数据增强
由于在这篇文章中提到,所用的训练数据集非常少,所以需要对数据集进行扩充。通过对可用的训练图片使用弹性变形进行数据增强,使得网络去学习变形中的不变性;为什么要提及不变性呢?主要是因为形变是组织中最常见的变异,所以以此来模拟真实的变形。
数据增强的方式:
? ? ? ? ? a.平移不变性;
? ? ? ? ? b.旋转不变性;
? ? ? ? ? c.变形;
? ? ? ? ? d.灰度值变化。
使用随机位移矢量在粗糙的3x3的网格上产生平滑的形变。位移是从具有 10 个像素标准偏差的高斯分布中采样的。然后使用双三次插值计算每个像素位移。 收缩路径末端使用 Drop-out 层执行进一步的隐式数据增强。
数据增强:https://mydreamambitious.blog.csdn.net/article/details/121589832
(5)加权损失

?
在细胞的分割任务中相同类别接触目标的分离,在接触的细胞之间像素赋予的权重更大,而背景赋予更小的权重。
使用形态学的方式计算分离边界,权重映射计算方式:
? ? ? ? ??
?其中w c : Ω → R?:Ω→R为平衡类频率的权重映射,d 1 : Ω → R d_1:?:Ω→R为到最近的cell边界的距离,d 2 :?Ω→R为到第二个最近cell边界的距离。在实验中,我们设置了w 0 = 10 , σ ≈ 5。?
注:在深度网络中带有很多的卷积层和不同的网络路径,所以一个好的权重初始化非常的重要。
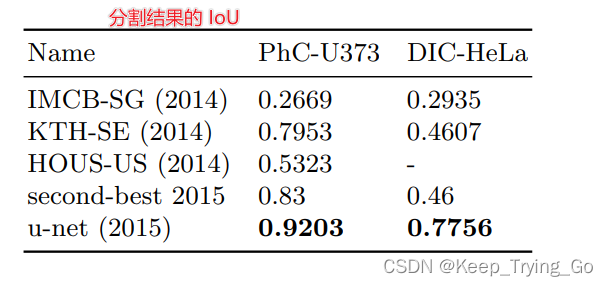
(6)实验结果
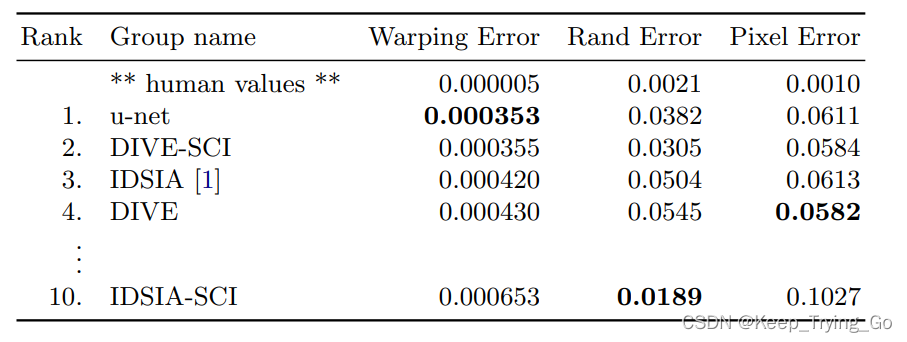
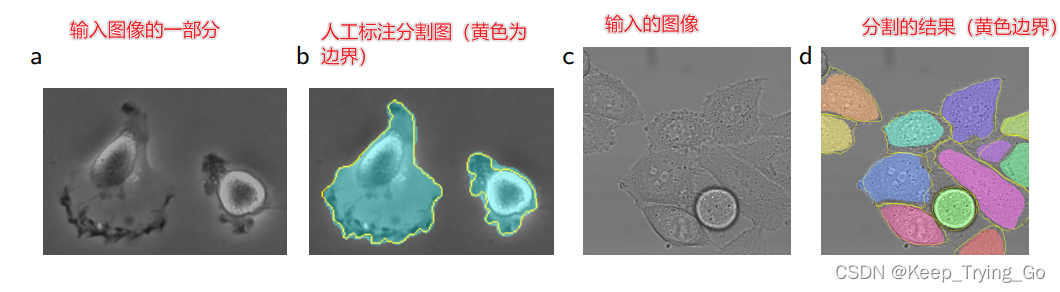 ?
?
?
?