前言
本文记录在云服务器autodl上选择安装cuda、cudnn开始,部署相同视角、相同时间、相同地点拍摄的红外和可见光图像数据集OTCBVS在Github目前开源的图像融合PIAFusion、目标检测Yolo-v4、目标跟踪DeepSort算法上实现单数据集贯通。
本文只做到以下几点:
1、列举常见红外-可见光图像数据集及其特征。
2、仅提供在云服务器上部署实现的流程经验。
本文不提供以下几点:
1、不对算法做任何优化,也不讨论最后的图像结果。如果需要,可以自行加入创新点去发挥。
2、不讨论任何指标。
3、对开源的其他图像融合、目标检测、目标跟踪算法不做调研。
本文较为基础,只是因为调研了CSDN上罕有分享整个过程打通的技术实现,哔哩哔哩上也仅提供实现后的结果,不少up主为了一键三连不公开源码。笔者在公开的源码上提供整个技术实现参考。
一、任务概述
无人机上常采用多相机拍摄的方式获取目标特征,这是因为红外相机和可见光相机拍摄得到的图片有各自的特征显示优势。红外相机通过目标物和背景之间的温差使得目标物可以被显著标记,同时也具备一定的纹理特征,可以比较好地观测到白天阴影中的目标和夜间目标;而可见光相机拍摄得到的图片由于突出的边缘信息,具备更多的纹理特征,但对于阴影、黑夜中的人物不具备很好的信息表达性。多模态图像融合通过提取红外的显著特征和可见光的纹理特征,根据灵活的特征融合规则将红外特征和可见光特征融合,最后使用图像重建将融合特征重建为图片。无人机通过目标识别和定位对信息量更为丰富的融合图片处理分析,得到目标物的位置和类别。随后根据需要,标记感兴趣目标物进行目标跟踪(目标跟踪是在相邻两帧图片中对目标物的进行定位和识别,可对目标接下来的运动进行预测,属于中级计算机视觉任务)。目标跟踪得到的感兴趣目标的位置,将其反馈到无人机视觉伺服模块,调整无人机机身姿态、速度,可定向追踪目标物。
无人机通过红外相机和可见光相机拍摄,无法做到两台相机是从同一视觉拍摄的,这一块涉及图像配准。由于尚没找到可利用的公开数据集,暂时不考虑图像配准的任务。视觉伺服模块属于控制类模块,不属于我们要解决的范畴,因此也不考虑在内。
二、常见红外-可见光图像数据集
2.1 OTCBVS
包含16个子类的红外和可见光图片数据集(本次使用OTCBVS的第2个子类中的一部分),第2个子类的信息:总大小为1.83 GB,图像尺寸为320 x 240 像素(可见和热成像),4228对热图像和可见图像。
链接:http://vcipl-okstate.org/pbvs/bench/
2.2 TNO image fusion dataset
包含军队夜间场景相关的多光谱如近红外、远红外、可见光的图像,图像尺寸为768 × 576像素。
链接:https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029
2.3 INO image fusion dataset
包含多天气、夜间条件下的彩色、红外图像,图像尺寸为328×254像素。
链接:http://www.ino.ca/en/video-analytics-dataset/
2.4 Eden Project Multi-Sensor Dataset
图像尺寸为560×468像素
链接:http://www.cis.rit.edu/pelz/scanpaths/data/bristol-eden.htm
三、图像融合
3.1 开源图像融合算法PIAFusion
PIAFusion是2022年发表在融合领域顶刊《Information Fusion》上的图像融合算法
链接:https://github.com/Linfeng-Tang/PIAFusion
文章:《PIAFusion: A progressive infrared and visible image fusion network based on illumination aware》
3.2 安装环境及相关包版本
考虑到云服务器在配置上的便捷性,我们采用市面上实惠的云服务器autodl配置图像融合。后期可以考虑对配置好的环境进行镜像迁移,便于实现在NVIDIA不同算力显卡上的测试。
cuda和cuDNN版本如下:
cuDNN7.4
cuda10.0
其他库的安装版本
tensorflow-gpu==1.14.0
opencv-python==3.4.2.17
scipy==1.2.0
numpy==1.19.2
pandas==1.1.5
openpyxl==3.0.10
protobuf==3.19.0
cuda和cuDNN与其他库选择版本的依据可参考下面几张图

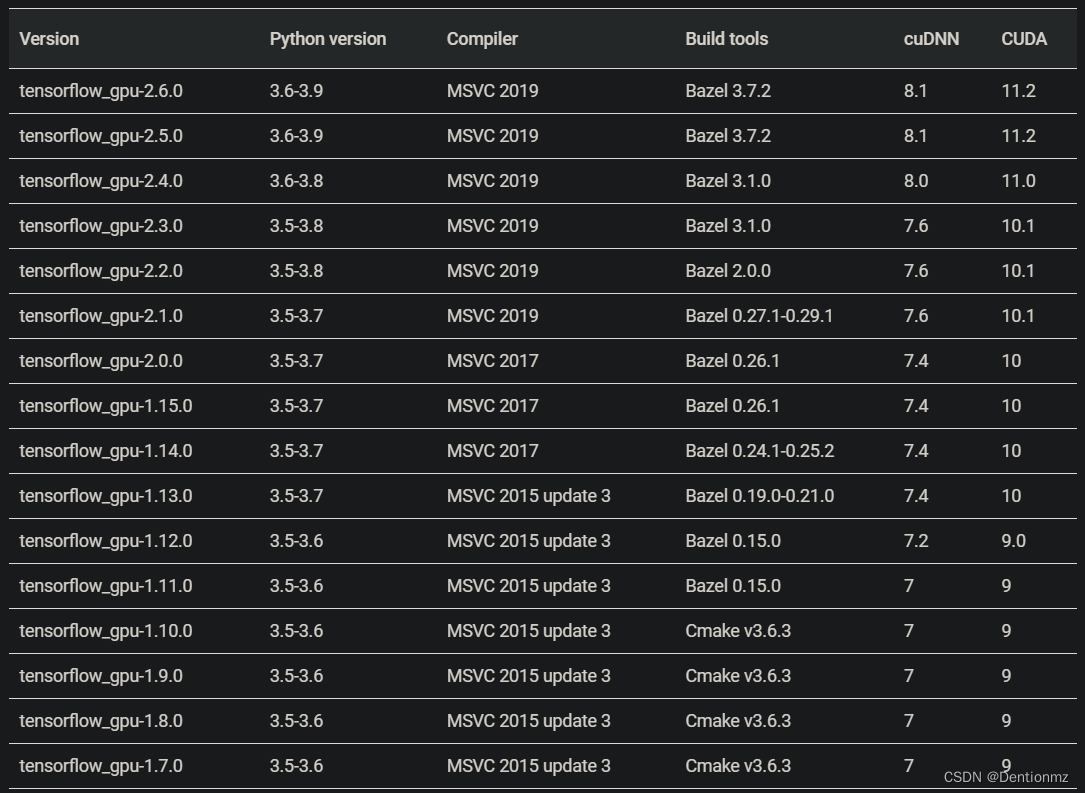

然而autodl官网并不直接提供上述cuda和cuDNN版本镜像,因此需要我们自行安装。我们首先选择RTX2080卡,选择TensorFlow1.15.5,Python3.8,cuda11.4的镜像。
3.2.1 检查(安装)NVIDIA驱动
nvidia-smi
得到如下
Sun Jul 31 15:04:41 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.44 Driver Version: 495.44 CUDA Version: 11.5 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:1A:00.0 Off | N/A |
| 54% 47C P8 5W / 250W | 0MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
我们只需重点关注驱动版本为495.44,支持CUDA最高版本到11.5,如果输出信息,表明已经安装了NVIDIA驱动,如果需要在自己笔记本上安装驱动,另外找驱动安装教程。
3.2.2 检查(安装)cuda和cuDNN版本
检查cuda使用
nvcc -V
输出
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
验证cuda版本为10.0
检查cuDNN使用
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A2
输出
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 4
#define CUDNN_PATCHLEVEL 1
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"
验证cuDNN版本为7.4.1
这是我安装后的结果,如果需要安装,参考下面几个步骤
3.2.2.1 官网下载cuda
链接:https://developer.nvidia.com/cuda-toolkit-archive
下载.run格式的安装包后:
chmod 777 cuda_10.0.130_410.48_linux.run # 修改权限使其可运行
./cuda_10.0.130_410.48_linux.run --override # 运行安装包
添加到环境变量中
echo "export PATH=/usr/local/cuda-10.0/bin:${PATH} \n" >> ~/.bashrc
echo "export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:${LD_LIBRARY_PATH} \n" >> ~/.bashrc
使用以下让环境变量生效
source ~/.bashrc
3.2.2.2 确认cuda是否安装成功
重启后,使用
nvcc -V
如果顺利输出cuda版本号,表明已经安装成功。
如果需要额外测试cuda功能,可以
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
make
./deviceQuery
输出
......
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.5, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
3.2.2.3 官网下载cuDNN
链接:https://developer.nvidia.com/cudnn
mv cuda/include/* /usr/local/cuda/include/
chmod +x cuda/lib64/* && mv cuda/lib64/* /usr/local/cuda/lib64/
使用以下使其生效
ldconfig
3.2.2.4 验证GPU是否可以利用
import tensorflow as tf
print(tf.test.is_gpu_available())
输出
......
2022-07-31 15:26:53.092539: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/device:GPU:0 with 10322 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 2080 Ti, pci bus id: 0000:1a:00.0, compute capability: 7.5)
True
表明GPU可被调用
3.2.3 安装环境
建议使用我上方提供的版本去更新源码提供的requirements.txt
pip install -r requirements.txt
3.3 下载数据集并批量化修改图片名
数据集选择OTCBVS的第二个子数据集,我列举了该数据集第一张红外-可见图片组,可以直观地看出红外图片和可见光图片之间的差别。


图像融合PIAFusion源码对图片名称有要求,可以使用下面去批量修改文件名。
import os
dirpath_top = os.path.dirname(os.path.abspath(__file__))
filelist_name = "OCTBVS0312"
filelist_se1 = "ir"
filelist_se2 = "vi"
otcbvs_path1 =os.path.join(dirpath_top, filelist_name, filelist_se1)
otcbvs_path2 =os.path.join(dirpath_top, filelist_name, filelist_se2)
#print(otcbvs_path1)
otcbvsir = os.listdir(otcbvs_path1)
otcbvsvi = os.listdir(otcbvs_path2)
#print(otcbvsir)
i=0
for item in otcbvsir:
if item.endswith('.bmp'):
src = os.path.join(os.path.abspath(otcbvs_path1), item) #原本的名称
dst = os.path.join(os.path.abspath(otcbvs_path1), str(i).zfill(4) + '.bmp') #这里我把格式统一改成了 .jpg
try:
os.rename(src, dst) #意思是将 src 替换为 dst
i+=1
print('rename from %s to %s' % (src, dst))
except:
continue
print('ending...')
i=0
for item in otcbvsvi:
if item.endswith('.bmp'):
src = os.path.join(os.path.abspath(otcbvs_path2), item)
dst = os.path.join(os.path.abspath(otcbvs_path2), str(i).zfill(4) + '.bmp')
try:
os.rename(src, dst)
i+=1
print('rename from %s to %s' % (src, dst))
except:
continue
print('ending...')
3.4 运行PIAFusion
为方便,可以将OTCBVS名称修改为TNO,放在测试数据中,运行
python main.py --is_train=False model_type=PIAFusion --DataSet=TNO
也可以在相关文件里面添加argparse项。懒人用上面那个方法就行了!
就可以将600对红外-可见光图片融合,下图是融合后的图片

3.5 融合后图片做成视频
import numpy as np
import cv2
import os
size = (320,240)
print("每张图片的大小为({},{})".format(size[0],size[1]))
dirpath_top = os.path.dirname(os.path.abspath(__file__))
src_path = os.path.join(dirpath_top,"OTCBVS")
sav_path = os.path.join(dirpath_top,"OTCBVS.mp4")
all_files = os.listdir(src_path)
index = len(all_files)
print("图片总数为:" + str(index) + "张")
fourcc = cv2.VideoWriter_fourcc(*'mp4v')#MP4格式
videowrite = cv2.VideoWriter(sav_path,fourcc,20,size)#2是每秒的帧数,size是图片尺寸
img_array=[]
tmp_name_list = []
for i in range(0,index):
tmp_i=str(i).zfill(4)
tmp_name_list.append(os.path.join(src_path,r'{0}.bmp'.format(tmp_i)))
#for filename in [src_path + r'{0}.bmp'.format(i) for i in tmp_name]:
for filename in tmp_name_list:
img = cv2.imread(filename)
if img is None:
print(filename + " is error!")
continue
img_array.append(img)
for i in range(0,index):
img_array[i] = cv2.resize(img_array[i],(320,240))
videowrite.write(img_array[i])
print('第{}张图片合成成功'.format(i))
print('------done!!!-------')
视频效果
OTCBVS-fusedresults
四、目标检测和目标跟踪
4.1 开源目标检测和跟踪算法Yolo-v4&DeepSort
Yolo-v4
链接:https://github.com/AlexeyAB/darknet
DeepSort
链接:https://github.com/ZQPei/deep_sort_pytorch
我们使用封装好的Yolo-v4和DeepSort
https://github.com/TsMask/deep-sort-yolov4
4.2 使用图像融合后得到的视频作为目标检测和跟踪的输入
运行
python detect_video_tracker.py --video OTCBVS.mp4 --min_score 0.3 --model_yolo model_data/yolov4.h5 --model_feature model_data/mars-small128.pb
视频效果
OTCBVS-D+TVideo
五、总结
本教程粗糙地提供了在云服务器autodl上的图像融合、目标检测、目标跟踪的技术实现,后续笔者应该会根据组内要求对算法优化并部署到开发板上做轻量级实现。欢迎同道中人一起交流!