文章目录
一、CNN的架构理解
CNN并不适用于所有的问题,就像针对某种问题设计的独特的神经网络架构,CNN相比Fully Connected神经网络是有很大的model bias的,CNN适合处理图像相关的问题,或者更确切的说,grid-like的数据。
?
假设有一个图片分类的任务,我们要交给神经网络去做,最朴素的想法是将一张图片拉直成一个很长的向量,然后输入进一个Fully Connected网络,然后用数个FC层进行叠加最后经过softmax输出结果向量,与真实的target进行cross entropy损失求解,训练整个网络。
?
使用FC网络处理图片并不是不可以假设一个50503的一个图片,转换成向量就是7500维,再经过一个有64个神经元的FC层,参数量有7500*64个,而且这只是整个网络中的一层,巨大的参数量会放缓神经网络的训练,而且其中大量的参数对于最终结果的贡献度并不高。
?
于是我们有了针对图像任务进行网络改造的需求。
?
首先,人类对图像的识别往往是基于某些局部特征,而不是对整个图像进行综合的扫描识别。比如,判断图像中是否有一只猪,我们通常关注的重点是猪鼻子和猪的其他区别于其他类别的特征。于是在FC网络的基础上我们去除掉大量的参数(即神经元连接)。
?
使用receptive field(感受野)覆盖图片的一小块儿,使用和感受野大小相同的kernel size(卷积核大小),对覆盖范围进行乘积并求解,给定一个stride(步长),从左向右从上到下进行感受野和卷积核的移动,并进行相应的计算。至于卷积核大小和感受野的设计是比较自由的,根据具体的任务,感受野可以覆盖不同的channel,感受野的大小可以不相同。
?
另外,继续沿用上面识别一张图片中猪的例子,猪鼻子可能出现在图片的左上角,也可能出现在图片的右下角,而不同位置的卷积核识别的是同一个要素,他们应该有相同的参数,这就是parameter sharing(参数共享)。
?
通常对于固定区域的感受野,我们不止连接到一个神经元上,通常会是64,128等数量,也就是说我们有若干组参数去针对某一个感受野,一组参数就叫一个filter。原始的图像通常是RGB图像,也就是channel为3,在经过一个filter数量为64的卷积层之后,会输出一张抽象的图像(feature map),图像的channel数量就是上一层的filter数量,即64。
?
二、CNN中的其他trick
CNN的各种操作演示参考以下链接:CNN操作演示
1、下采样sub-sampling
将图像进行适当的缩小并不会影响人类的识别,下采样的目的是为了减小图像的尺寸,缩小模型的规模。
通常下采样通过pooling(池化)进行实现,池化的方式有max-pooling,mean-pooling等。
并不是所有CNN都要进行下采样,比如Alpha-go使用的CNN并未进行下采样。
?
2、padding
在进行感受野和卷积核移动的时候,有可能超过图像的边界,此时需要padding,即给图像的边界进行扩展,在图像外层再加上若干层的边界,经常使用的padding方式是zero-padding。
如果不进行padding,那么塞不满卷积核部分的图像就会被抛弃,对应tensorflow中padding='valid'的方式。
?
3、data augmentation
由于将原始图像进行扩大,或者翻转之后,机器并不能像人类一样准确的还原识别,所以在使用CNN进行图像相关任务之前,通常会对原始的数据集进行augmentation,加入一些翻转和扩大之后的图像。
?
4、filter和kernel的区别
这两者是比较相似的概念,因为他们守备的都是同一片区域,但是kernel是针对一个channel而言的,也就是说同一个感受野,有多个kernel,而filter包含了所有的channel。描述kernel的大小的时候我们用的是二维的尺寸,比如33,而描述filter的时候,我们使用三维的尺寸,比如,33*3。
?
5、dilation (空洞卷积或扩展卷积)
对原始的卷积核进行了改造,使得感受野扩大,dilation的操作如下图所示

?
6、转置卷积Transposed convolution(上采样)
和卷积的操作相反,是将卷积后的feature map进行尺寸的还原
?
7、分组卷积
该操作对应pytorch中卷积层的group参数,group=K(k>1)意味着将输出图像的channel分成K组,每组使用out_channels/in_channels个filter进行守备。
?
8、卷积之后的图像尺寸计算
新图像尺寸 = (图像尺寸 + padding尺寸 - 卷积核尺寸) / 步长 + 1
?
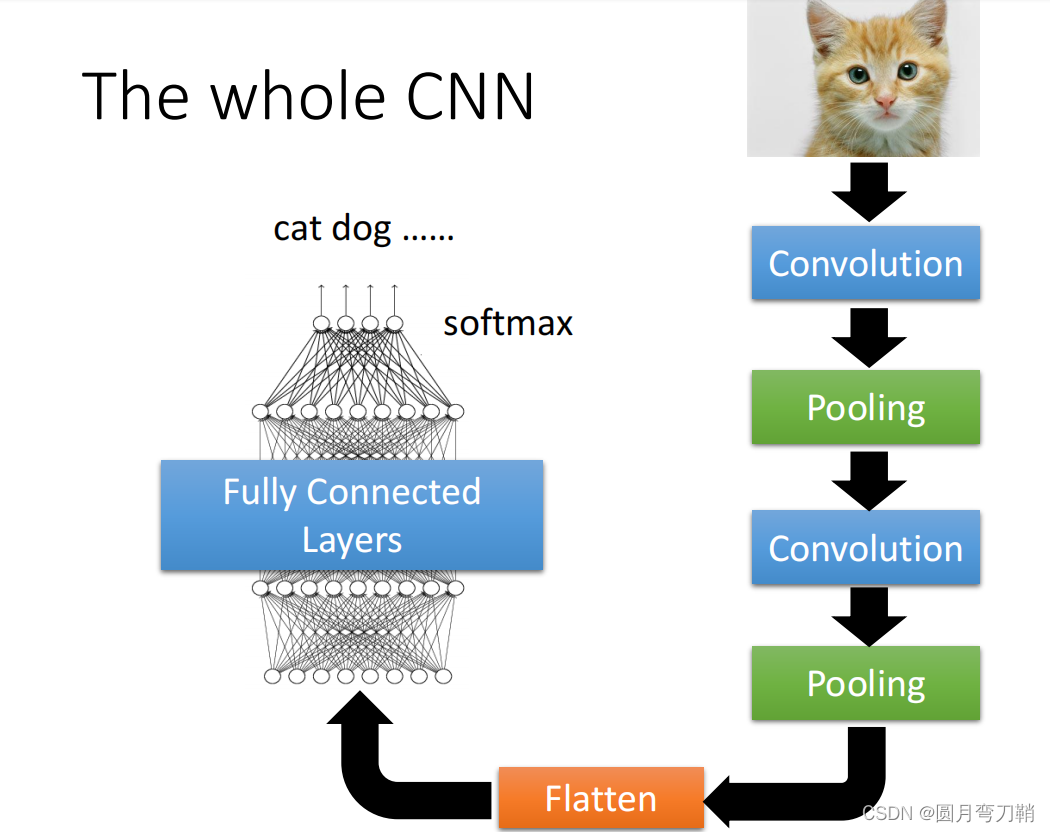
三、常用的CNN整体网络结构
整个CNN通常由若干个卷积层进行处理之后,将feature map拉直,再经过若干个FC层,如下图所示