MobileNet
��ͳ����������,�ڴ���������������������ƶ��豸�Լ�Ƕ��ʽ�豸�����С�
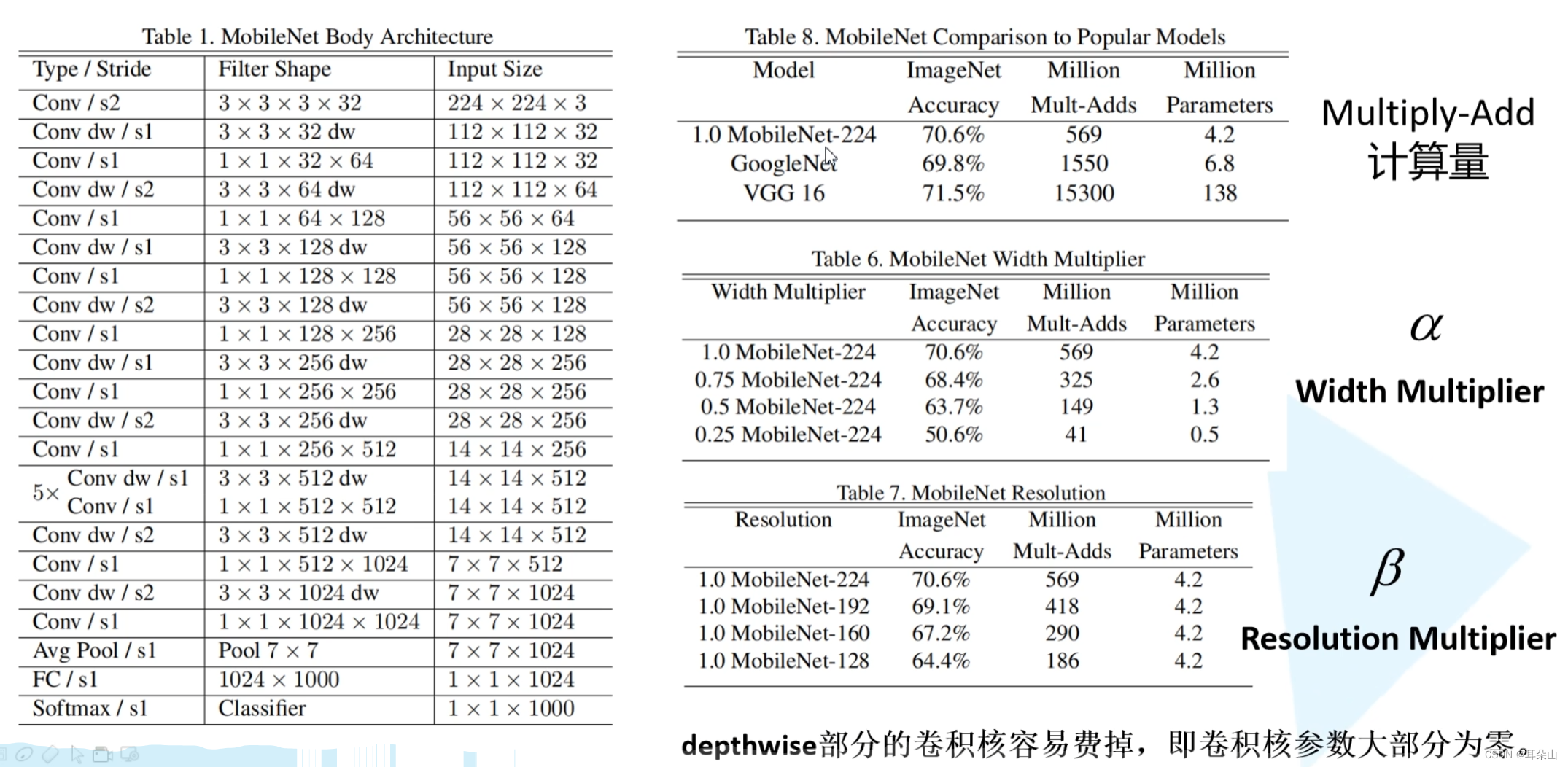
MobileNet��������google�Ŷ���2017�������,רע���ƶ��˻���Ƕ��ʽ�豸�е�������CNN���硣��ȴ�ͳ����������,��ȷ��С�����͵�ǰ���´�����ģ�Ͳ�������������(���VGG16ȷ�ʼ�����0.9%,��ģ�Ͳ���ֻ��VGG��1/32)
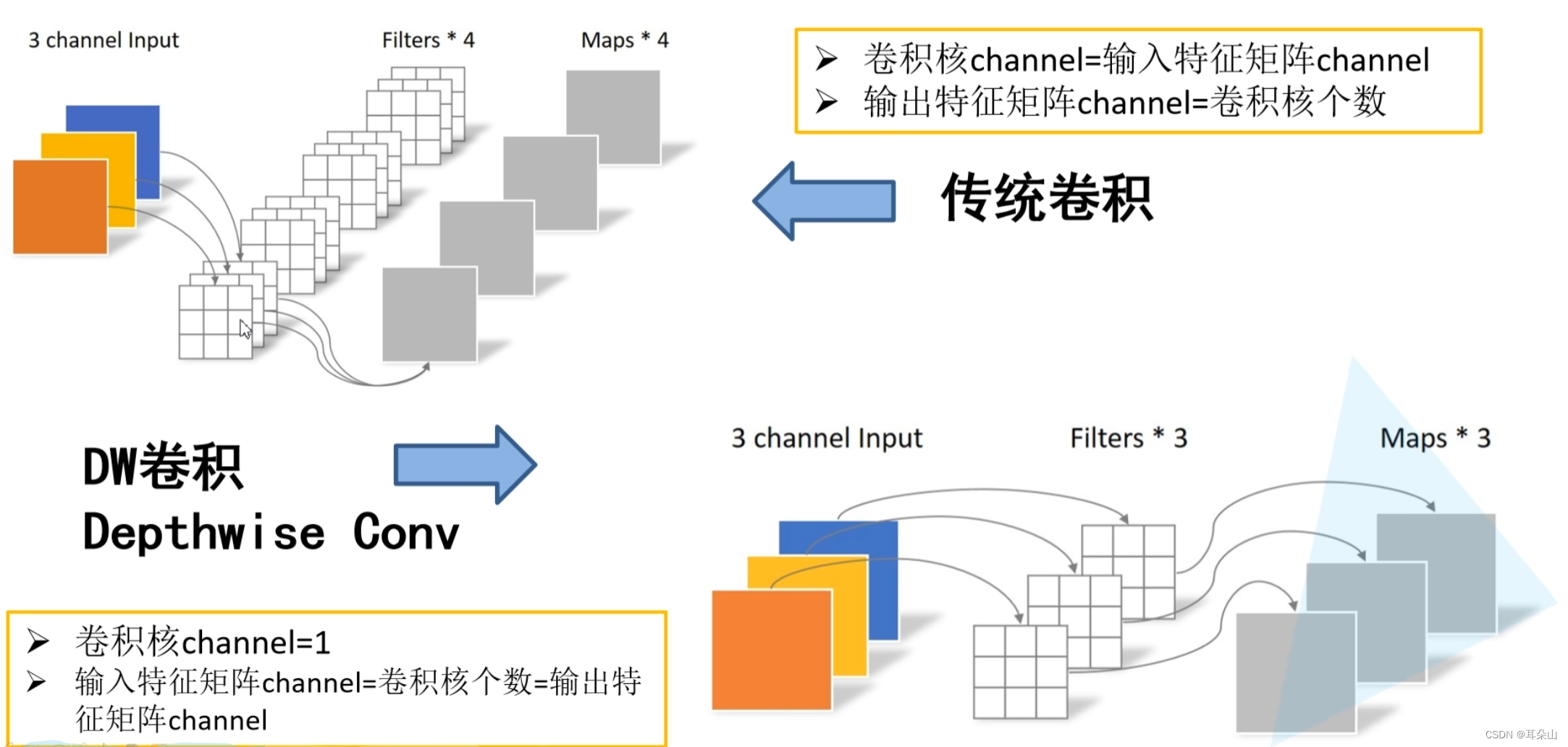
�����Ǵ�ͳ������Depthwise Convolution�ıȽ�:
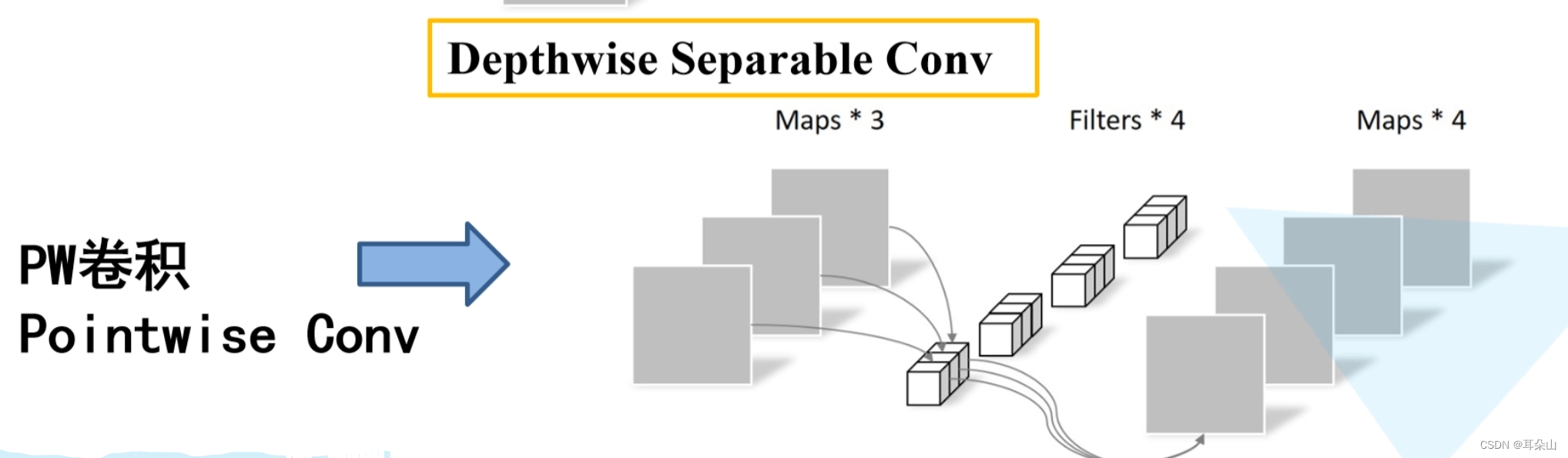
pw����(����1*1����,���ڵ������):
?
���������:

MobileNet V1?
���������:
? ? ? ? Depthwise Convolution(�������������Ͳ�������)
????????���ӳ�����������?
????????���Ц�Ϊ�����˵ĸ���,��Ϊ����ͼ��ķֱ��ʡ�
MobileNet V2
MobileNet v2��������google�Ŷ���2018�������,���MobileNet V1��.
��,ȷ�ʸ���,ģ��С��
���������:
????????Inverted Residuals (���в�ṹ)
????????Linear Bottlenecks
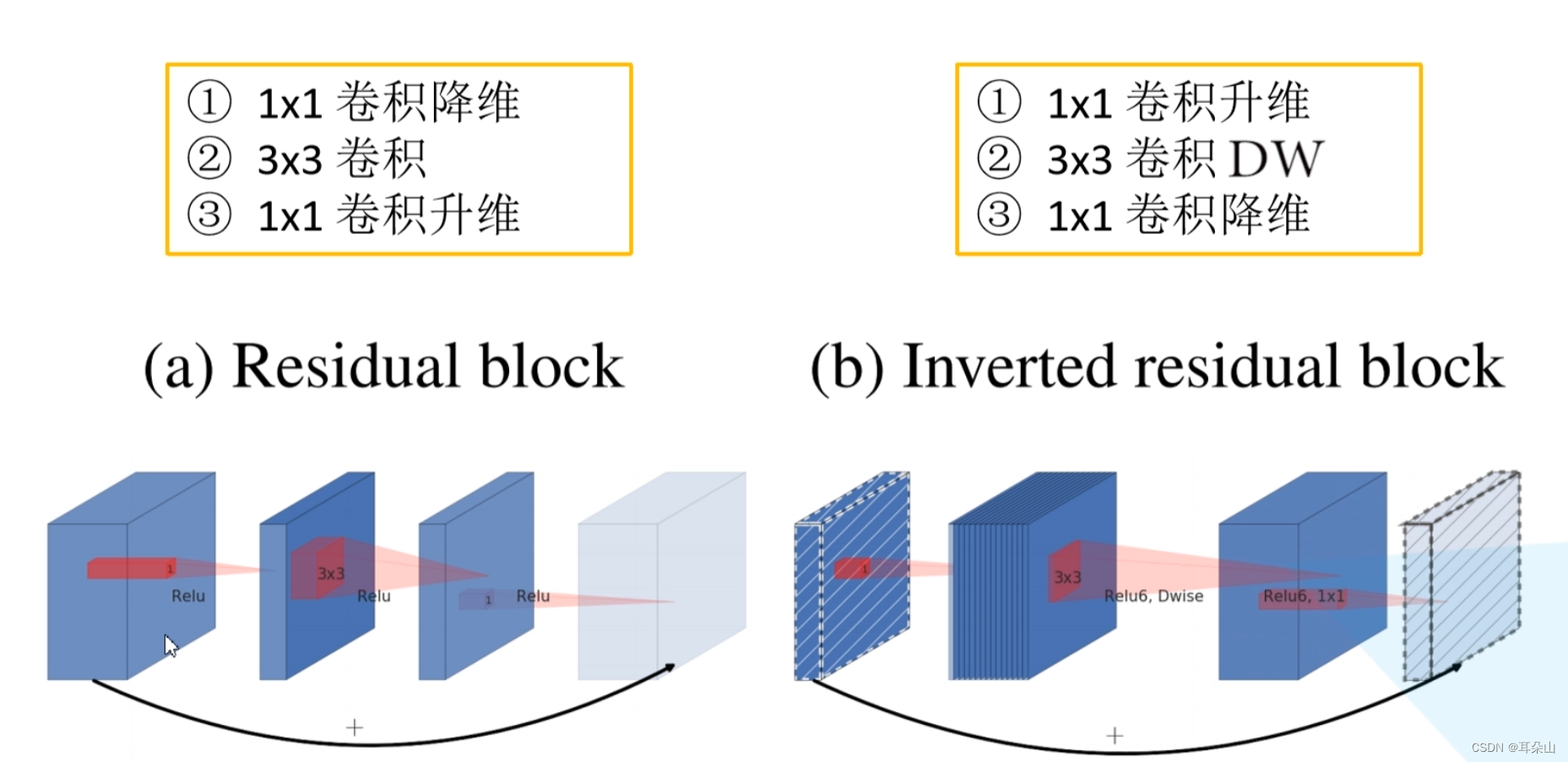
��ResNet���γɵ���ͷ�� �м�С��bottleneck�ṹ�෴,��һ�ֵ��в�ṹ��
������ReLU6����,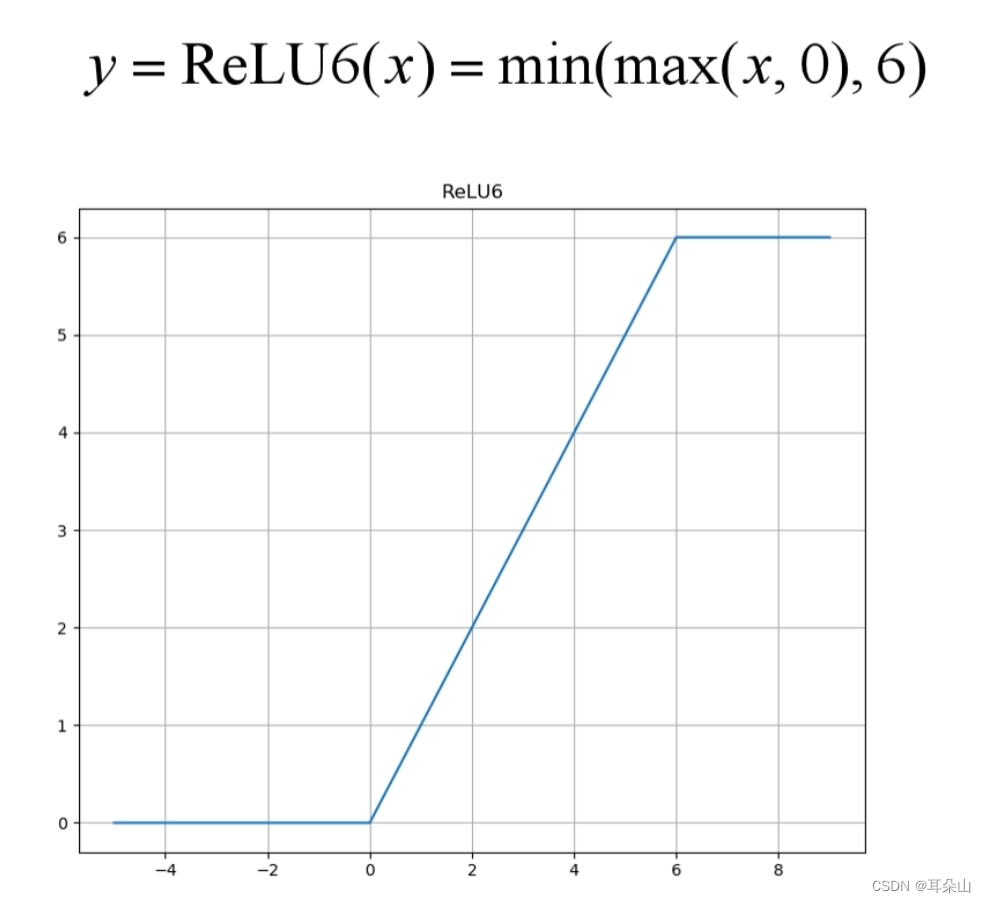
?�ڵ��в�ṹ�����һ��1*1��������,ʹ�������Եļ����,������ReLU�������

?���������е�block�ж���shortcut�ݾ���֧,��sride=1�����������������������������shape��ͬʱ����shortcut���ӡ�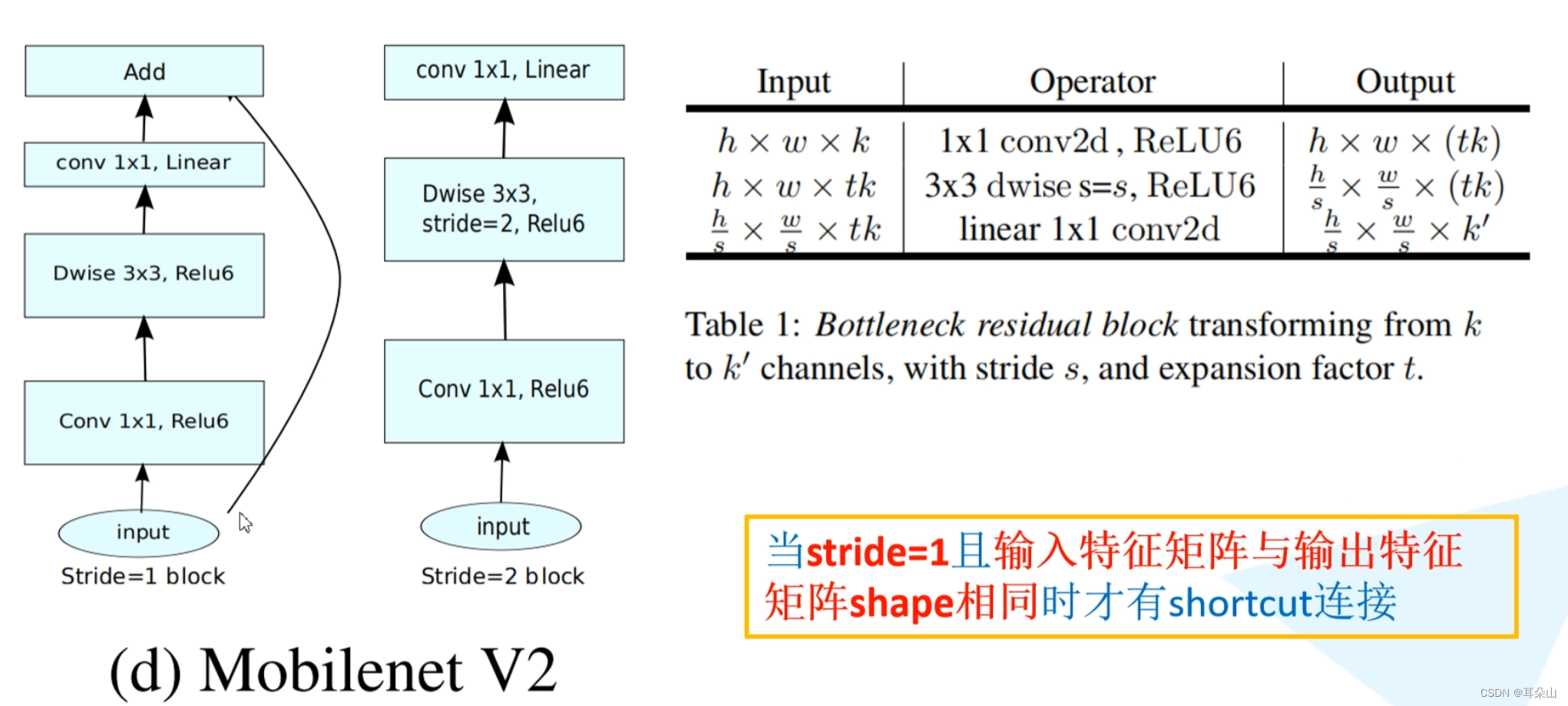
?
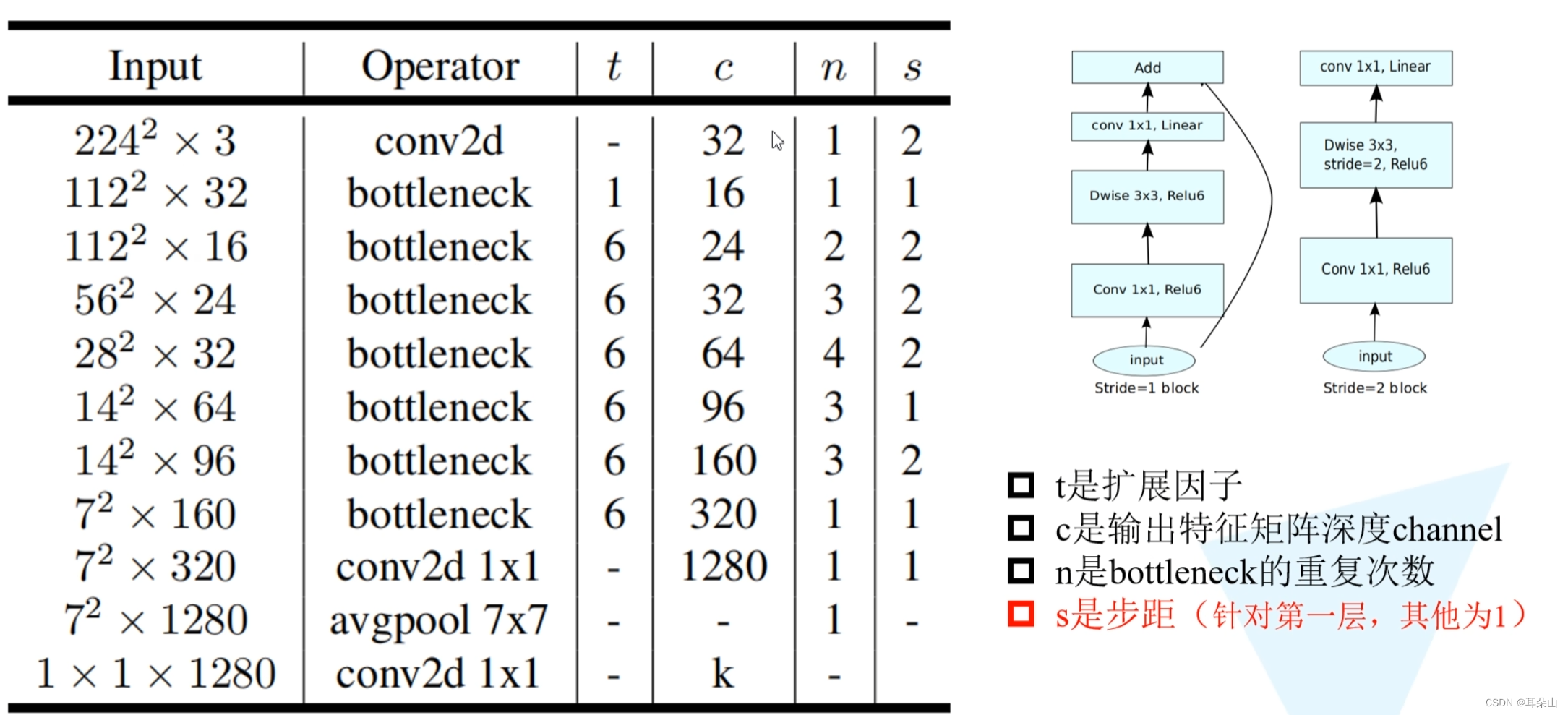
����ṹ:
��������������bottleneck�ǵ��в�ṹ��?
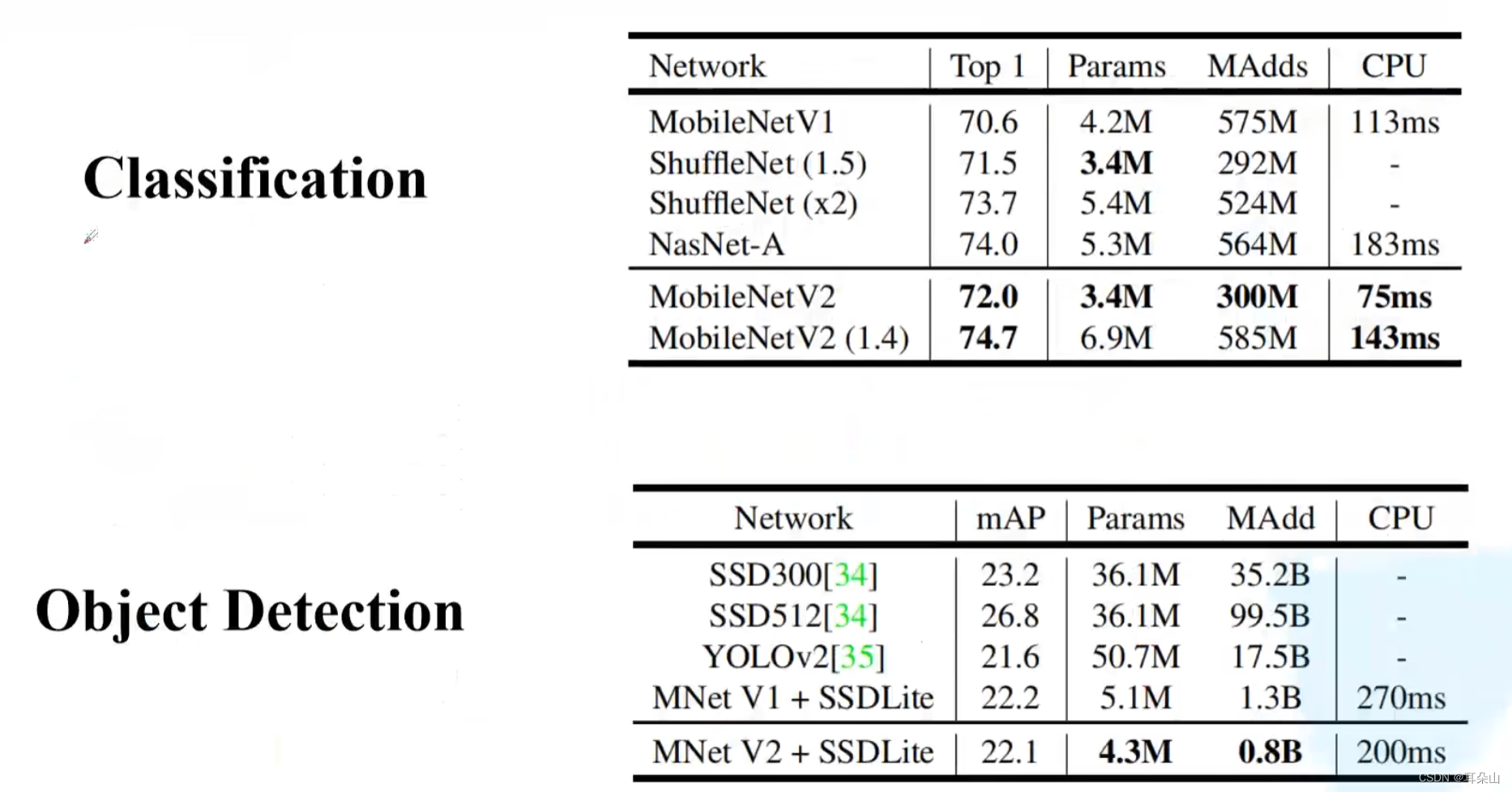
������MobileNet V2�ڷ����Ŀ������������MobileNet V1��Ч�ʶԱ�,���Կ�����CPU���бȽ����Ե�Ч������,����ʵ�������ƶ�����ʵʱ�������Ĺ��ܡ�
MobileNet V3
MoblieNet V3��Ҫ������:
????????����Block(bneck)
????????ʹ��NAS(Neural Architecture Search)��������
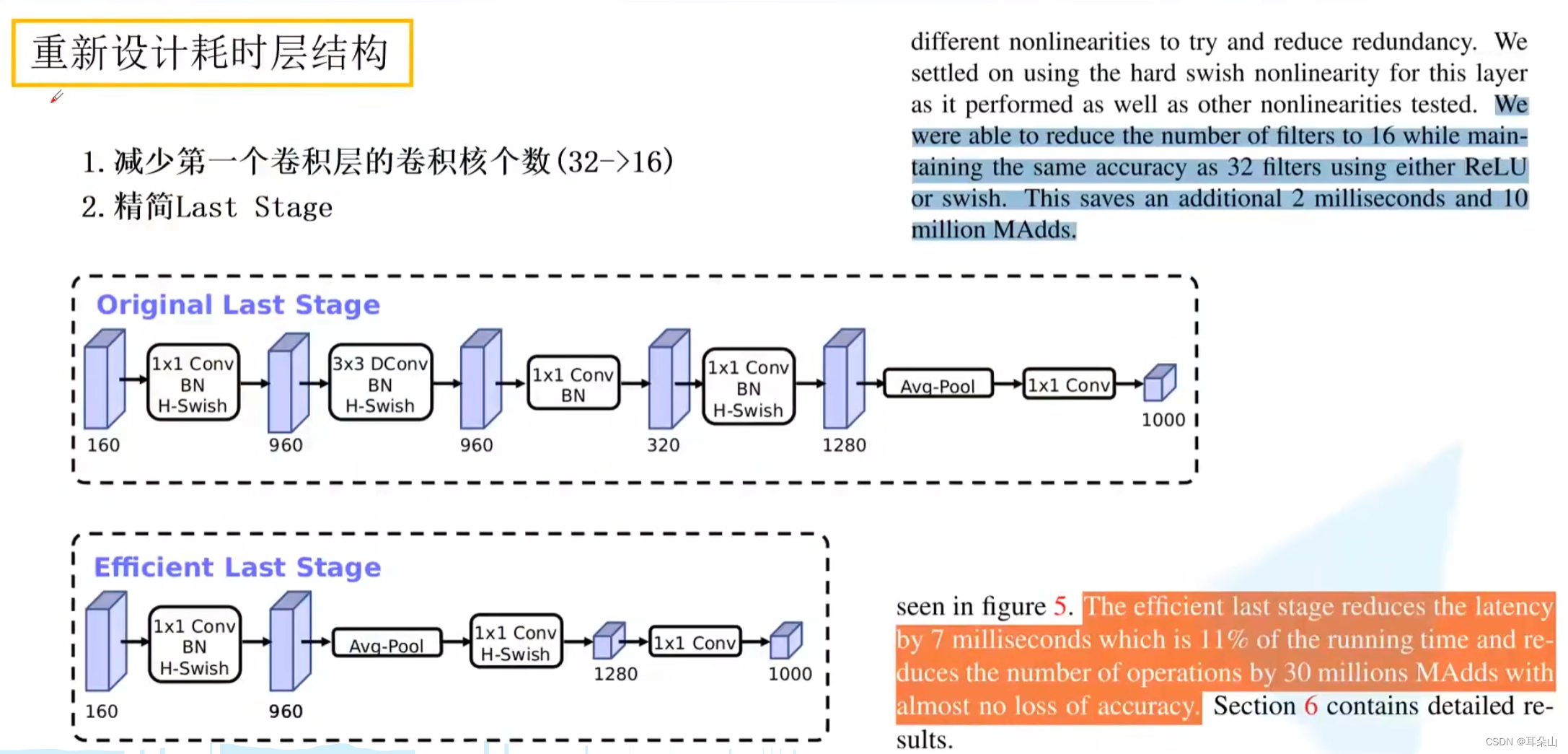
????????������ƺ�ʱ��ṹ
����Block
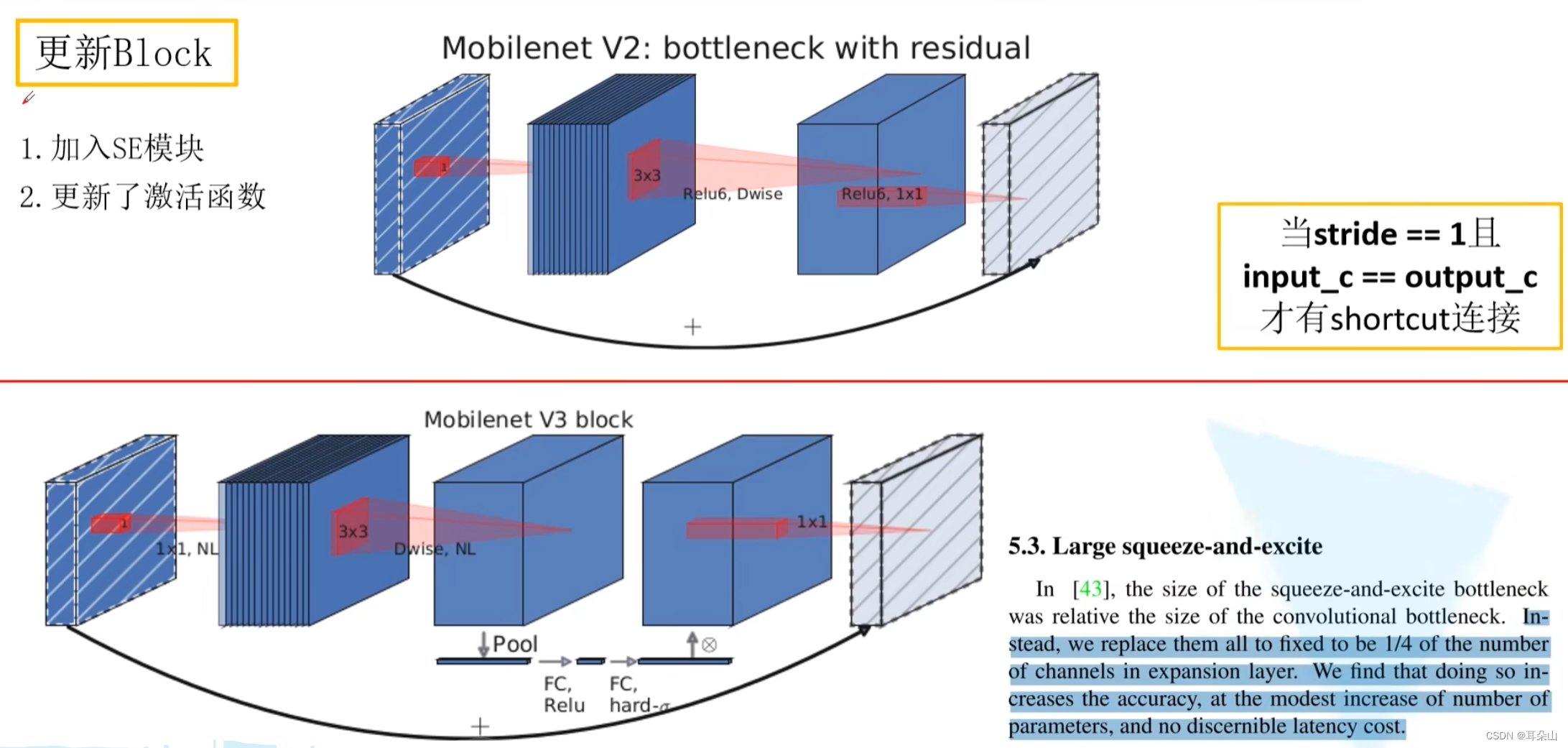
?������ƺ�ʱ��ṹ
?������Ƽ����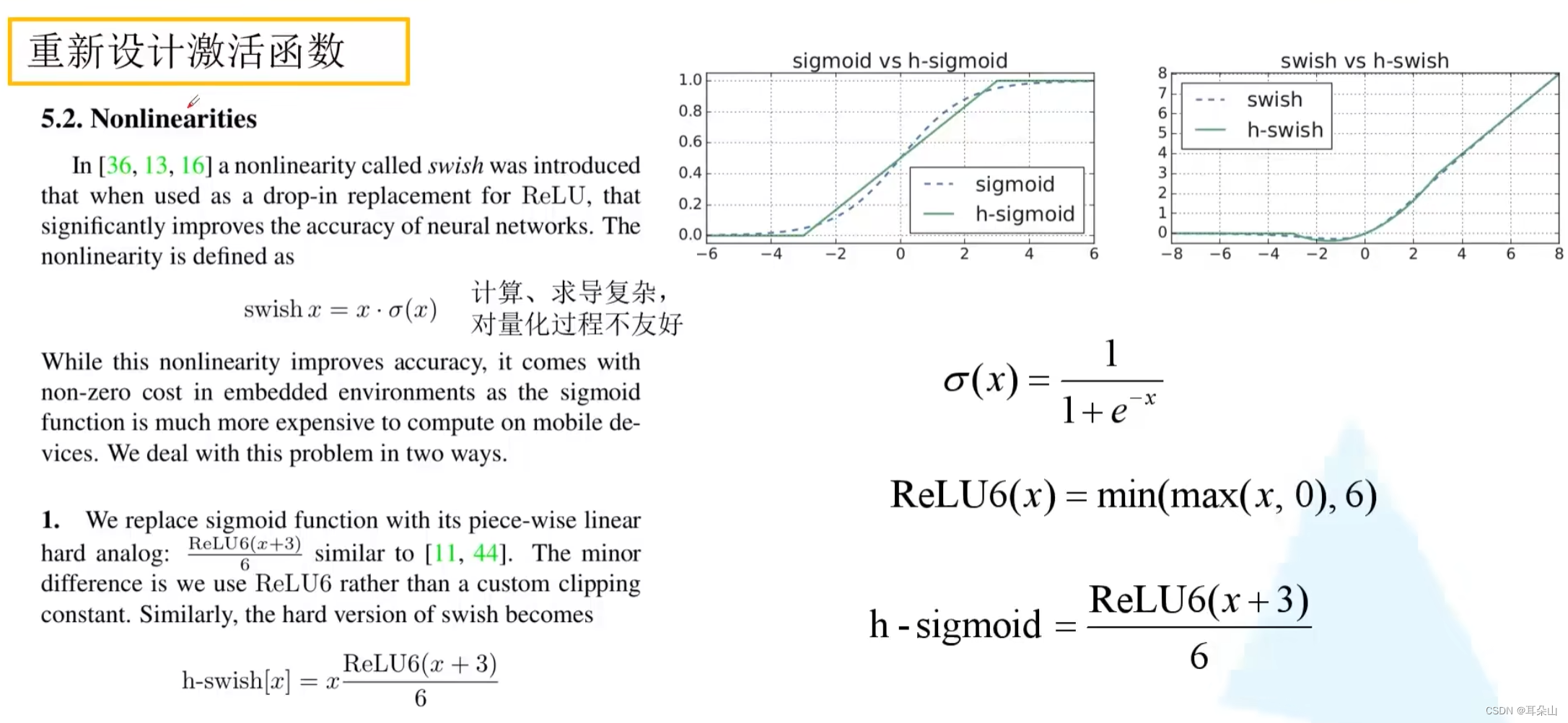
?
SENet
�����Զ���ʻ��ҵ��˾ Momenta �� ImageNet 2017 ��ս���ж��,����ܹ�Ϊ SENet,Squeeze-and-Excitation Networks,��������Ϊ Momenta ���з�����ʦ���ܡ�
�����Ƿ���Դ���������������ȥ��������,���翼������ͨ��֮��Ĺ�ϵ?SENet���ǿ�����ͨ������Ĺ�ϵ��������˵,����ͨ��ѧϰ�ķ�ʽ����ȡÿ������ͨ������Ҫ�̶�,Ȼ�����������Ҫ�̶�ȥ�������õ����������ƶԵ�ǰ�����ô������������
SEģ������ͼ��ʾ: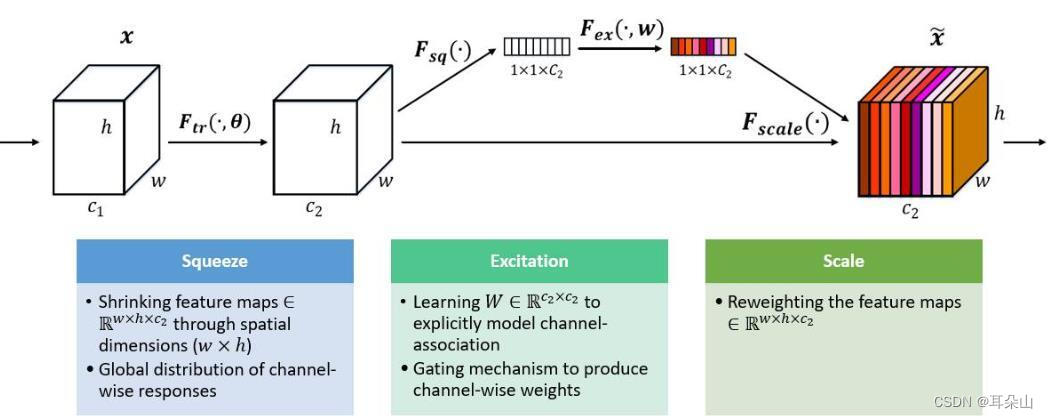
?
������ Squeeze ����,˳�ſռ�ά������������ѹ��,��ÿ����ά������ͨ�����һ��ʵ��,���ʵ��ij�̶ֳ��Ͼ���ȫ�ֵĸ���Ұ,������������ͨ������Ӧ��ȫ�ֲַ�
Ȼ���� Excitation ����,������ѭ���������ŵĻ��ơ�ͨ������ w ��Ϊÿ������ͨ������Ȩ��,���в��� w ��ѧϰ������ʽ�ؽ�ģ����ͨ���������ԡ�(����������ȫ���Ӳ�)
����� Reweight �IJ���,�� Excitation �������Ȩ�ؿ����ǽ�������ѡ����ÿ������ͨ������Ҫ��,Ȼ��ͨ���˷���ͨ����Ȩ����ǰ��������,�����ͨ���϶�ԭʼ�������ر궨��
������ BasicBlock �Ĵ���:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# shortcut�����ά�Ⱥ������һ��ʱ,��1*1�ľ�����ƥ��ά��
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels))
# �� excitation ������ȫ����
self.fc1 = nn.Conv2d(out_channels, out_channels//16, kernel_size=1)
self.fc2 = nn.Conv2d(out_channels//16, out_channels, kernel_size=1)
#��������ṹ
def forward(self, x):
#feature map�������ξ����õ�ѹ��
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# Squeeze ����:global average pooling
w = F.avg_pool2d(out, out.size(2))
# Excitation ����: fc(ѹ����16��֮һ)--Relu--fc(����֮ǰά��)--Sigmoid(��֤���Ϊ 0 �� 1 ֮��)
w = F.relu(self.fc1(w))
w = F.sigmoid(self.fc2(w))
# �ر궨����: ���������feature map�� w ���
out = out * w
# ����dz������ͼ
out += self.shortcut(x)
#R elu����
out = F.relu(out)
return outSE����ṹ:
#����SENet����
class SENet(nn.Module):
def __init__(self):
super(SENet, self).__init__()
#���շ����������
self.num_classes = 10
#�������Ϊ64
self.in_channels = 64
#��ʹ��64*3*3�ľ�����
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
#�����������,BasicBlock
#2,2,2,2Ϊÿ����������Ҫ��block����
self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1)
self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2)
self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2)
self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2)
#ȫ����
self.linear = nn.Linear(512, self.num_classes)
#ʵ��ÿһ�����
#blocksΪ��layer�еIJв����
#����ÿһ��layer�м����в��,resnet18��2,2,2,2
def _make_layer(self, block, out_channels, blocks, stride):
strides = [stride] + [1]*(blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
#��������ṹ
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return outHybridSN �߹�����
S. K. Roy, G. Krishna, S. R. Dubey, B. B. Chaudhuri HybridSN: Exploring 3-D�C2-D CNN Feature Hierarchy for Hyperspectral Image Classification,?IEEE GRSL?2020
��ƪ���Ĺ�����һ�� ������� ����߹���ͼ���������,������ 3D����,Ȼ��ʹ�� 2D����,������Լ�,�����Ǵ���Ľ�����
1. ���� HybridSN ��
ģ�͵�����ṹΪ����ͼ��ʾ:
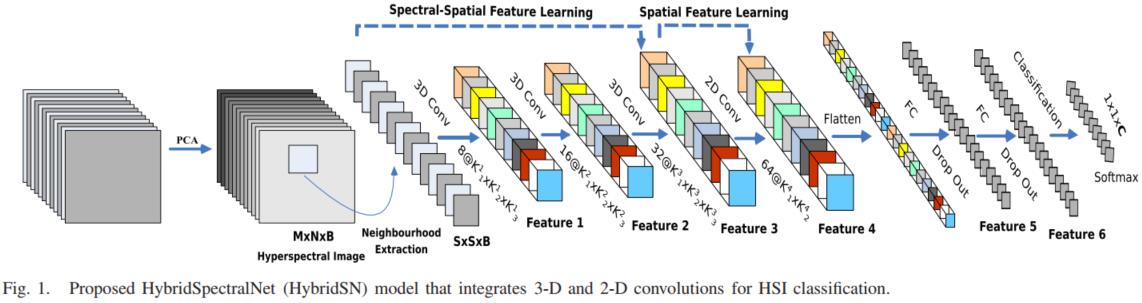
����������:
- conv1:(1, 30, 25, 25), 8�� 7x3x3 �ľ����� ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16�� 5x3x3 �ľ����� ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32�� 3x3x3 �ľ����� ==>(32, 18, 19, 19)
������Ҫ���ж�ά����,��˰�ǰ��� 32*18 reshape һ��,�õ� (576, 19, 19)
��ά����:(576, 19, 19) 64�� 3x3 �ľ�����,�õ� (64, 17, 17)
��������һ�� flatten ����,��Ϊ 18496 ά������,
����������Ϊ256,128�ڵ��ȫ���Ӳ�,��ʹ�ñ���Ϊ0.4�� Dropout,
������Ϊ 16 ���ڵ�,�����յķ����������
������ HybridSN ��Ĵ���:
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
# conv1:(1, 30, 25, 25), 8�� 7x3x3 �ľ����� ==>(8, 24, 23, 23)
self.conv1 = nn.Sequential(
nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True)
)
# conv2:(8, 24, 23, 23), 16�� 5x3x3 �ľ����� ==>(16, 20, 21, 21)
self.conv2 = nn.Sequential(
nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True)
)
# conv3:(16, 20, 21, 21),32�� 3x3x3 �ľ����� ==>(32, 18, 19, 19)
self.conv3 = nn.Sequential(
nn.Conv3d(in_channels=16, out_channels=32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True)
)
# ������Ҫ���ж�ά����,��˰�ǰ��� 32*18 reshape һ��,�õ� (576, 19, 19)
# ��ά����:(576, 19, 19) 64�� 3x3 �ľ�����,�õ� (64, 17, 17)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=576, out_channels=64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
# ��������һ�� flatten ����,��Ϊ 18496 ά������,����18496 = 64*17*17
# ����������Ϊ256,128�ڵ��ȫ���Ӳ�,��ʹ�ñ���Ϊ0.4�� Dropout,
# ������Ϊ 16 ���ڵ�,�����յķ����������
self.fc1 = nn.Linear(in_features=18496, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=class_num)
self.drop = nn.Dropout(p=0.4)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = out.reshape(out.shape[0], -1, 19, 19)
out = self.conv4(out)
out = out.reshape(out.shape[0],-1)
out = F.relu(self.drop(self.fc1(out)))
out = F.relu(self.drop(self.fc2(out)))
out = self.fc3(out)
return out
# �������,��������ṹ�Ƿ�ͨ
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
2. �������ݼ�
���ȶԸ߹�������ʵʩPCA��ά;Ȼ�� keras ���㴦�������ݸ�ʽ;Ȼ�������ȡ 10% ������Ϊѵ����,ʣ�����Ϊ���Լ���
���ȶ����������:
# �Ը߹������� X Ӧ�� PCA �任
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
# �Ե���������Χ��ȡ patch ʱ,��Ե���ؾ���ȡ��,���,���ⲿ�����ؽ��� padding ����
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
# ��ÿ��������Χ��ȡ patch ,Ȼ���ɷ��� keras �����ĸ�ʽ
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# �� X �� padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test�����ȡ���������ݼ�:
# �������
class_num = 16
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
# ���ڲ��������ı���
test_ratio = 0.90
# ÿ��������Χ��ȡ patch �ijߴ�
patch_size = 25
# ʹ�� PCA ��ά,�õ����ɷֵ�����
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# �ı� Xtrain, Ytrain ����״,�Է��� keras ��Ҫ��
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# Ϊ����Ӧ pytorch �ṹ,����Ҫ�� transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# ���������������ݺͶ�Ӧ�ı�ǩ
return self.x_data[index], self.y_data[index]
def __len__(self):
# �����ļ����ݵ���Ŀ
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# ���������������ݺͶ�Ӧ�ı�ǩ
return self.x_data[index], self.y_data[index]
def __len__(self):
# �����ļ����ݵ���Ŀ
return self.len
# ���� trainloader �� testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)3.?��ʼѵ��
# ʹ��GPUѵ��,�����ڲ˵� "����ִ�й���" -> "��������ʱ����" ���������
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ����ŵ�GPU��
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# ��ʼѵ��
total_loss = 0
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# �Ż����ݶȹ���
optimizer.zero_grad()
# ���� +������ + �Ż�
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')����:
[Epoch: 1] [loss avg: 20.0778] [current loss: 2.0543]
[Epoch: 2] [loss avg: 16.4718] [current loss: 1.4499]
[Epoch: 3] [loss avg: 14.0356] [current loss: 0.9051]
[Epoch: 4] [loss avg: 12.1260] [current loss: 0.7068]
[Epoch: 5] [loss avg: 10.5903] [current loss: 0.4818]
[Epoch: 6] [loss avg: 9.3619] [current loss: 0.2623]
[Epoch: 7] [loss avg: 8.3675] [current loss: 0.1905]
[Epoch: 8] [loss avg: 7.5316] [current loss: 0.1921]
[Epoch: 9] [loss avg: 6.8536] [current loss: 0.0949]
[Epoch: 10] [loss avg: 6.2873] [current loss: 0.1509]
[Epoch: 11] [loss avg: 5.7947] [current loss: 0.1316]
[Epoch: 12] [loss avg: 5.3677] [current loss: 0.1210]
[Epoch: 13] [loss avg: 4.9912] [current loss: 0.0300]
[Epoch: 14] [loss avg: 4.6676] [current loss: 0.0594]
[Epoch: 15] [loss avg: 4.3908] [current loss: 0.1179]
[Epoch: 16] [loss avg: 4.1447] [current loss: 0.1044]
[Epoch: 17] [loss avg: 3.9206] [current loss: 0.0430]
[Epoch: 18] [loss avg: 3.7333] [current loss: 0.0263]
[Epoch: 19] [loss avg: 3.5731] [current loss: 0.1190]
[Epoch: 20] [loss avg: 3.4192] [current loss: 0.0483]
[Epoch: 21] [loss avg: 3.2751] [current loss: 0.0676]
[Epoch: 22] [loss avg: 3.1402] [current loss: 0.0514]
[Epoch: 23] [loss avg: 3.0141] [current loss: 0.0487]
[Epoch: 24] [loss avg: 2.8986] [current loss: 0.0501]
[Epoch: 25] [loss avg: 2.7922] [current loss: 0.0062]
[Epoch: 26] [loss avg: 2.6939] [current loss: 0.0276]
[Epoch: 27] [loss avg: 2.6039] [current loss: 0.0897]
[Epoch: 28] [loss avg: 2.5162] [current loss: 0.0429]
[Epoch: 29] [loss avg: 2.4366] [current loss: 0.0146]
[Epoch: 30] [loss avg: 2.3645] [current loss: 0.0153]
[Epoch: 31] [loss avg: 2.2966] [current loss: 0.0369]
[Epoch: 32] [loss avg: 2.2290] [current loss: 0.0122]
[Epoch: 33] [loss avg: 2.1718] [current loss: 0.0184]
[Epoch: 34] [loss avg: 2.1135] [current loss: 0.0162]
[Epoch: 35] [loss avg: 2.0582] [current loss: 0.0083]
[Epoch: 36] [loss avg: 2.0039] [current loss: 0.0149]
[Epoch: 37] [loss avg: 1.9525] [current loss: 0.0016]
[Epoch: 38] [loss avg: 1.9031] [current loss: 0.0155]
[Epoch: 39] [loss avg: 1.8560] [current loss: 0.0134]
[Epoch: 40] [loss avg: 1.8132] [current loss: 0.0051]
[Epoch: 41] [loss avg: 1.7739] [current loss: 0.0175]
[Epoch: 42] [loss avg: 1.7356] [current loss: 0.0083]
[Epoch: 43] [loss avg: 1.7029] [current loss: 0.0728]
[Epoch: 44] [loss avg: 1.6686] [current loss: 0.0515]
[Epoch: 45] [loss avg: 1.6422] [current loss: 0.3931]
[Epoch: 46] [loss avg: 1.6102] [current loss: 0.0074]
[Epoch: 47] [loss avg: 1.5781] [current loss: 0.0016]
[Epoch: 48] [loss avg: 1.5478] [current loss: 0.0232]
[Epoch: 49] [loss avg: 1.5180] [current loss: 0.0012]
[Epoch: 50] [loss avg: 1.4897] [current loss: 0.0173]
[Epoch: 51] [loss avg: 1.4636] [current loss: 0.0026]
[Epoch: 52] [loss avg: 1.4385] [current loss: 0.0601]
[Epoch: 53] [loss avg: 1.4140] [current loss: 0.0268]
[Epoch: 54] [loss avg: 1.3893] [current loss: 0.0192]
[Epoch: 55] [loss avg: 1.3659] [current loss: 0.0227]
[Epoch: 56] [loss avg: 1.3441] [current loss: 0.0163]
[Epoch: 57] [loss avg: 1.3233] [current loss: 0.0030]
[Epoch: 58] [loss avg: 1.3035] [current loss: 0.0128]
[Epoch: 59] [loss avg: 1.2844] [current loss: 0.0071]
[Epoch: 60] [loss avg: 1.2674] [current loss: 0.0045]
[Epoch: 61] [loss avg: 1.2490] [current loss: 0.0041]
[Epoch: 62] [loss avg: 1.2321] [current loss: 0.0788]
[Epoch: 63] [loss avg: 1.2144] [current loss: 0.0036]
[Epoch: 64] [loss avg: 1.1973] [current loss: 0.0017]
[Epoch: 65] [loss avg: 1.1810] [current loss: 0.0041]
[Epoch: 66] [loss avg: 1.1641] [current loss: 0.0057]
[Epoch: 67] [loss avg: 1.1478] [current loss: 0.0070]
[Epoch: 68] [loss avg: 1.1319] [current loss: 0.0168]
[Epoch: 69] [loss avg: 1.1172] [current loss: 0.0005]
[Epoch: 70] [loss avg: 1.1019] [current loss: 0.0044]
[Epoch: 71] [loss avg: 1.0876] [current loss: 0.0305]
[Epoch: 72] [loss avg: 1.0731] [current loss: 0.0088]
[Epoch: 73] [loss avg: 1.0591] [current loss: 0.0228]
[Epoch: 74] [loss avg: 1.0455] [current loss: 0.0045]
[Epoch: 75] [loss avg: 1.0323] [current loss: 0.0002]
[Epoch: 76] [loss avg: 1.0201] [current loss: 0.0168]
[Epoch: 77] [loss avg: 1.0076] [current loss: 0.0089]
[Epoch: 78] [loss avg: 0.9964] [current loss: 0.0316]
[Epoch: 79] [loss avg: 0.9858] [current loss: 0.0476]
[Epoch: 80] [loss avg: 0.9752] [current loss: 0.0033]
[Epoch: 81] [loss avg: 0.9658] [current loss: 0.0073]
[Epoch: 82] [loss avg: 0.9552] [current loss: 0.0047]
[Epoch: 83] [loss avg: 0.9456] [current loss: 0.0092]
[Epoch: 84] [loss avg: 0.9355] [current loss: 0.0004]
[Epoch: 85] [loss avg: 0.9255] [current loss: 0.0015]
[Epoch: 86] [loss avg: 0.9163] [current loss: 0.0214]
[Epoch: 87] [loss avg: 0.9080] [current loss: 0.0763]
[Epoch: 88] [loss avg: 0.8981] [current loss: 0.0092]
[Epoch: 89] [loss avg: 0.8907] [current loss: 0.1359]
[Epoch: 90] [loss avg: 0.8824] [current loss: 0.0028]
[Epoch: 91] [loss avg: 0.8759] [current loss: 0.0130]
[Epoch: 92] [loss avg: 0.8682] [current loss: 0.0057]
[Epoch: 93] [loss avg: 0.8600] [current loss: 0.0359]
[Epoch: 94] [loss avg: 0.8516] [current loss: 0.0235]
[Epoch: 95] [loss avg: 0.8456] [current loss: 0.0230]
[Epoch: 96] [loss avg: 0.8386] [current loss: 0.0044]
[Epoch: 97] [loss avg: 0.8312] [current loss: 0.0062]
[Epoch: 98] [loss avg: 0.8257] [current loss: 0.1492]
[Epoch: 99] [loss avg: 0.8187] [current loss: 0.0099]
[Epoch: 100] [loss avg: 0.8121] [current loss: 0.0025]
Finished Training4. ģ�Ͳ���
count = 0
# ģ�Ͳ���
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# ���ɷ��౨��
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
��һ�β��Խ��:
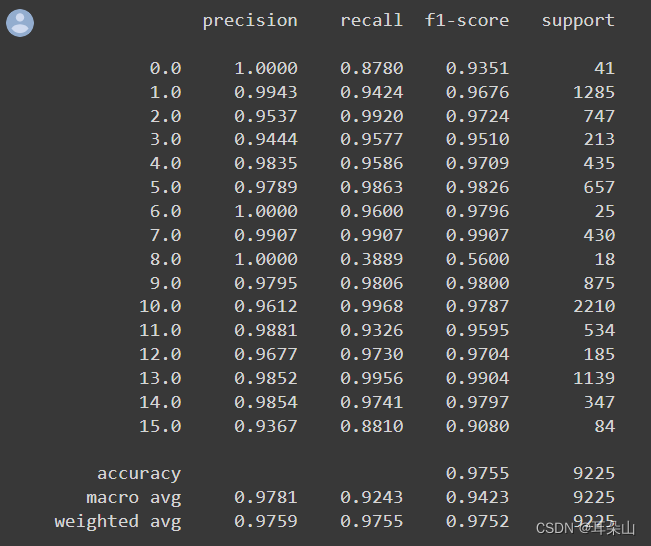
�ڶ��β��Խ��:
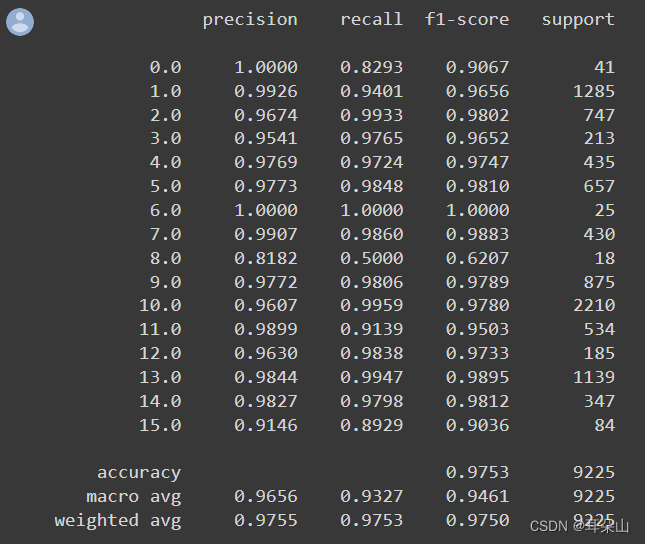
�����β��Խ��:
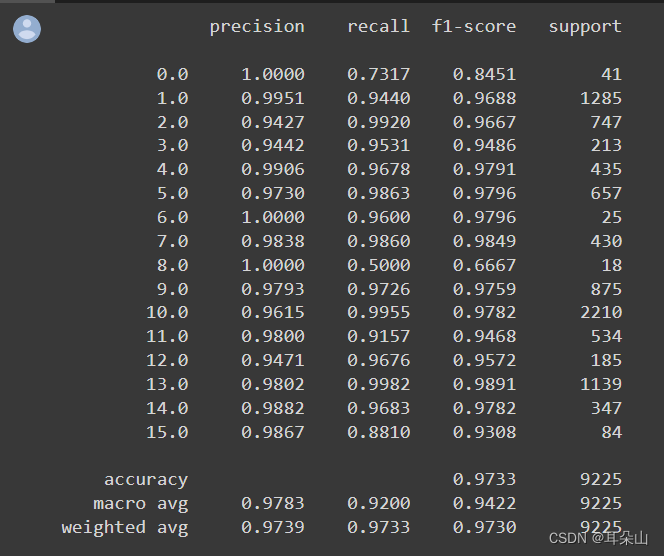
������˼��
3D������2D����������
?????????2D������3D��������Ҫ����Ϊ�˲��������Ŀռ�ά�ȡ�3D������������������3D�ռ��еĶ����ϵ��
ÿ�η���Ľ������һ��,Ϊʲô?
????????�����в�����dropoutÿ�ζ�����������Ԫ���Խ����������ͬ��
��ν�һ�������߹���ͼ��ķ�������?
????????����ħ������������֮��ġ�?