b站刘二视频,地址:
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
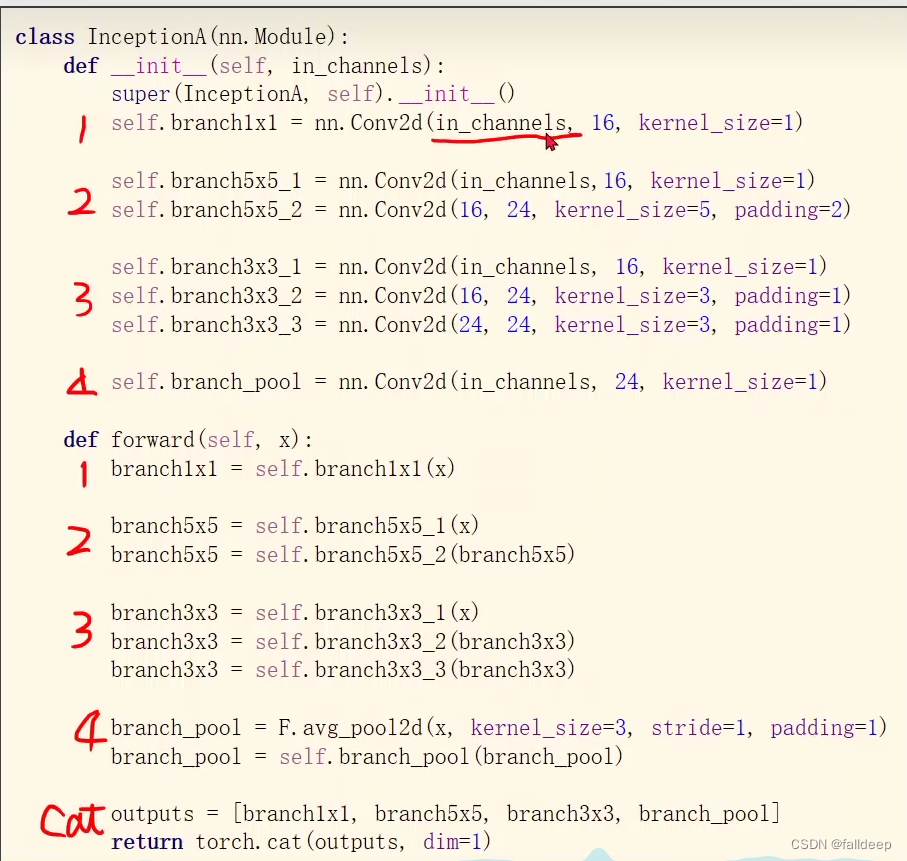
concatenate将张量合并 (试一试不同的路线)
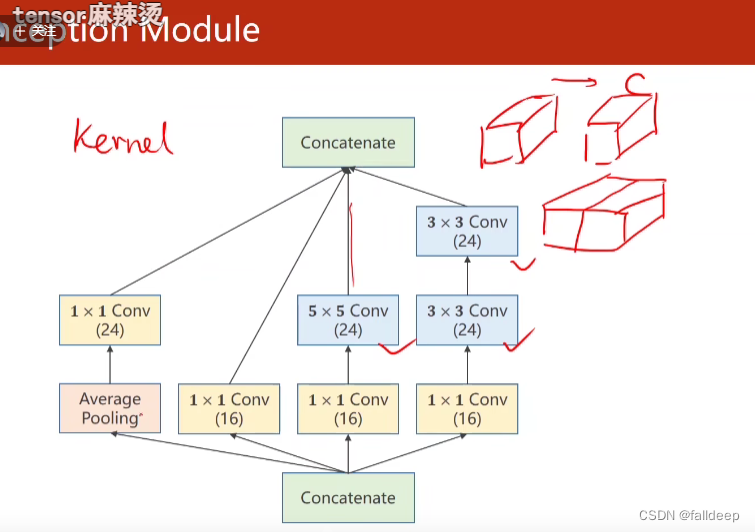
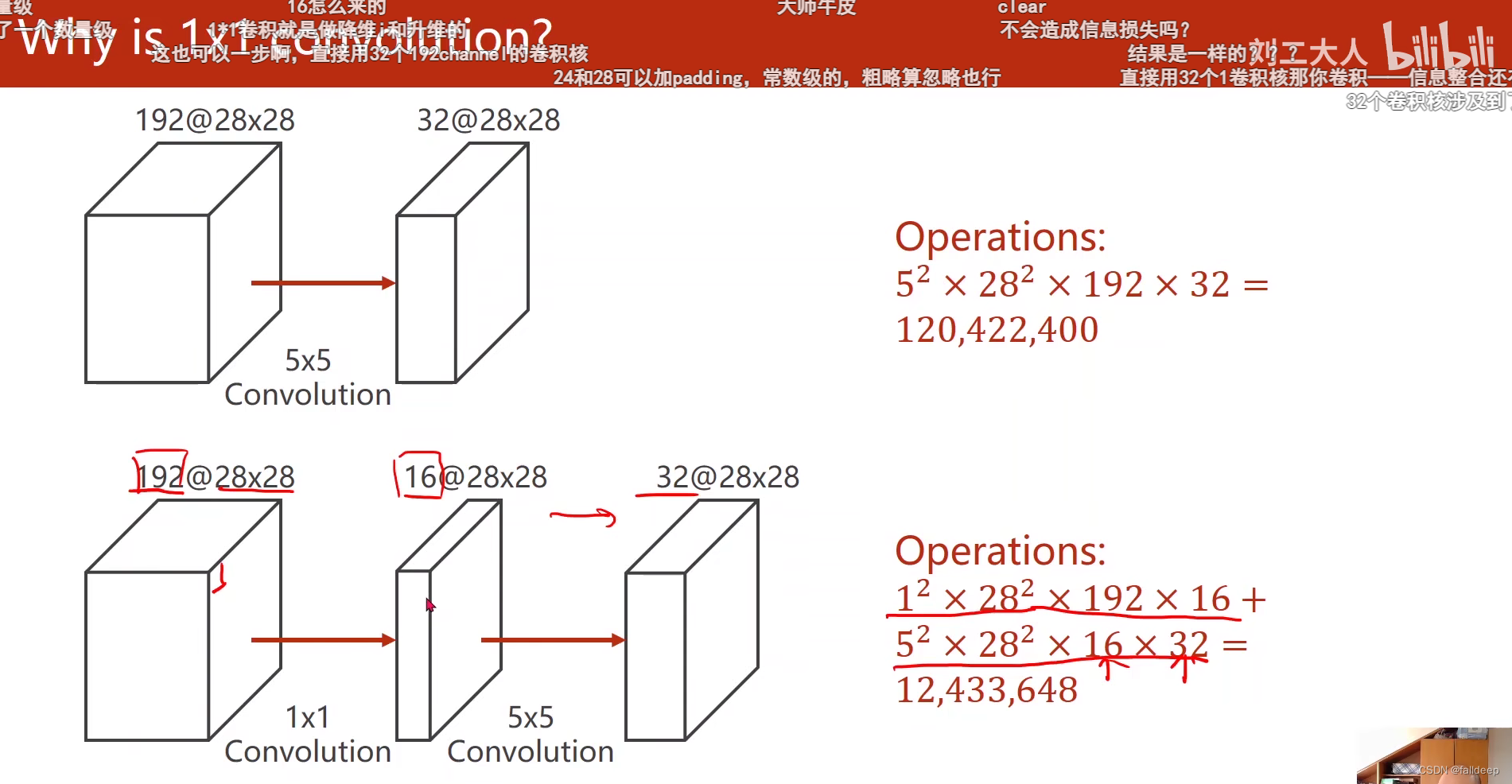
?1*1卷积核的作用,减少运算次数?
?
代码实现Inception模块?
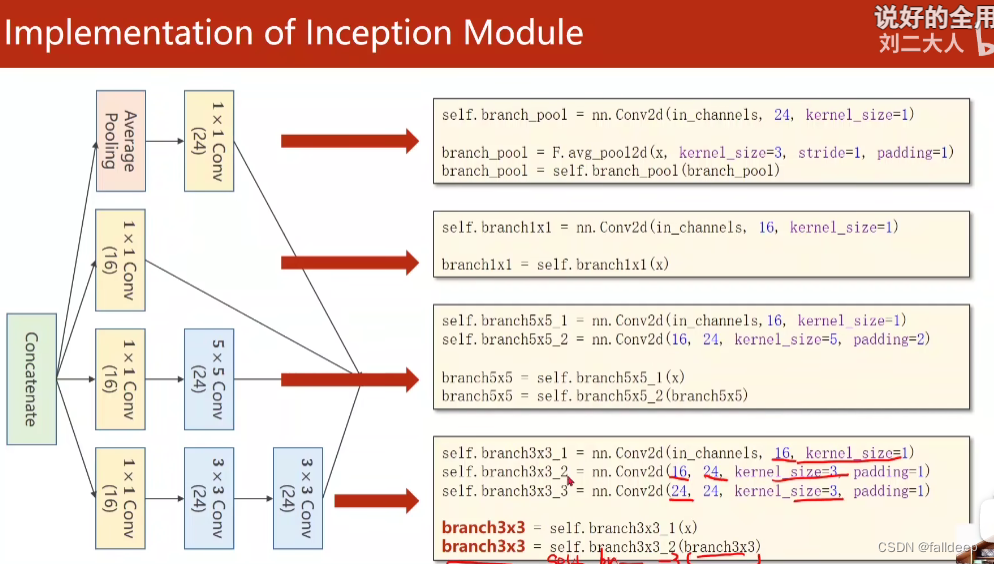
?
梯度消失
56层3 * 3 的网络效果反而跑不过20层的,因为在反向传播中,是每一层网络的导数值乘起来,因为每个导数的值都小于1,当有值特别小的时候,总结果就会趋近于0,导致最开始那几层网络得不到训练。
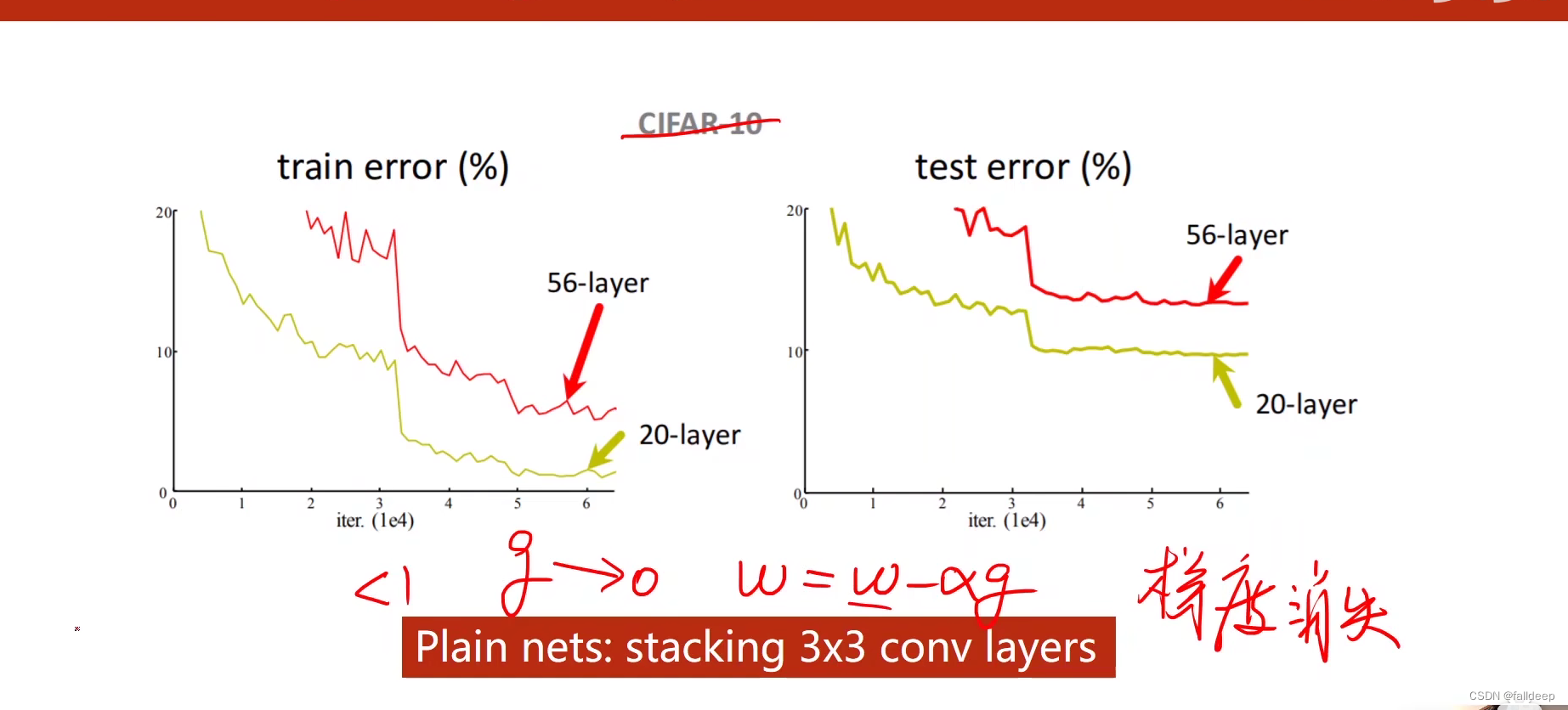 解决方法1
解决方法1
?逐层训练,然后训练完一层后上锁
?
解决方法2 Residual net
加了一个x后,导数永远大于1
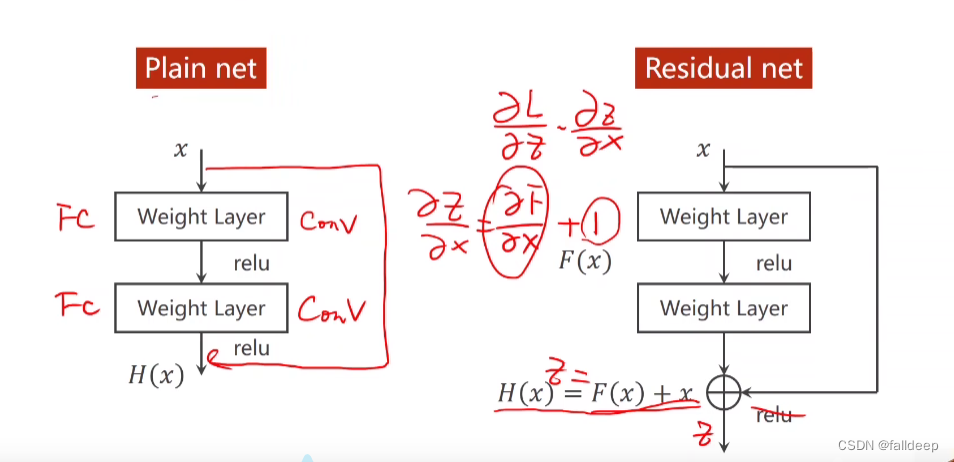 Residual block的实现?
Residual block的实现?
import torch
import torch.nn.functional as F
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1) #padding是为了使得输出像素等于输入像素
self.conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y) #加上x深度学习学习路线?

作业代码
1.使用inception的代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
#step1 prepare data
BATCH_SIZE = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_set = datasets.MNIST(root='mnist', download=False, transform=transform, train=True)
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_set = datasets.MNIST(root='mnist', download=False, transform=transform, train=False)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=False)
#step2 construct network
class inception(nn.Module):
def __init__(self, in_channels):
super(inception, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) #在通道维度合并
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = inception(10)
self.incep2 = inception(20)
self.mp = nn.MaxPool2d(kernel_size=2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
net = Net()
#step3 损失函数和优化函数
criterion = nn.CrossEntropyLoss()
optimizor = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
def train():
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, lables = data
y_pred = net(inputs)
loss = criterion(y_pred, lables)
running_loss += loss.item()
optimizor.zero_grad()
loss.backward()
optimizor.step()
if i % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 300))
loss_lst.append(running_loss / 300)
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for i, data in enumerate(test_loader, 0):
inputs, lables = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += lables.size(0)
correct += (predicted == lables).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
acc_lst.append(100 * correct / total)
#step4 训练过程
if __name__ == '__main__':
acc_lst = []
loss_lst = []
for epoch in range(10):
train()
test()
num_lst = [i for i in range(len(loss_lst))]
plt.plot(num_lst, loss_lst)
plt.xlabel("i")
plt.ylabel("loss")
plt.show()
num_lst = [i for i in range(len(acc_lst))]
plt.plot(num_lst, acc_lst)
plt.xlabel("epoch")
plt.ylabel("accurate_rate")
plt.show()
2.使用ResidualBlock的代码
import torch
from torchvision import transforms
from torchvision import datasets
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
#step1
BATCH_SIZE = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_set = datasets.MNIST(root='mnist', download=False, transform=transform, train=True)
train_loader = DataLoader(train_set, shuffle=True, batch_size=BATCH_SIZE)
test_set = datasets.MNIST(root='mnist', download=False, transform=transform, train=False)
test_loader = DataLoader(test_set, shuffle=False, batch_size=BATCH_SIZE)
#step2
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv1(y)
return F.relu(y + x)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.pool = nn.MaxPool2d(2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.pool(self.conv1(x)))
x = self.rblock1(x)
x = F.relu(self.pool(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
net = Net()
#step3
criterion = nn.CrossEntropyLoss()
optimizor = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
#step4
def train():
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, lables = data
y_pred = net(inputs)
loss = criterion(y_pred, lables)
optimizor.zero_grad()
loss.backward()
optimizor.step()
running_loss += loss.item()
if i % 300 == 299:
print("[%d, %5d]loss: %.3f" %(epoch + 1, i + 1, running_loss / 300))
loss_lst.append(running_loss / 300)
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for i, data in enumerate(test_loader, 0):
inputs, lables = data
outputs = net(inputs)
_, predicted = torch.max(outputs, dim=1)
correct += (predicted == lables).sum().item()
total += lables.size(0)
print('accuracy on test set: %d %%' %(100 * correct / total))
acc_lst.append(100 * correct / total)
if __name__ == '__main__':
acc_lst = []
loss_lst = []
for epoch in range(10):
train()
test()
num_lst = [i for i in range(len(loss_lst))]
plt.plot(num_lst, loss_lst)
plt.xlabel("i")
plt.ylabel("loss")
plt.show()
num_lst = [i for i in range(len(acc_lst))]
plt.plot(num_lst, acc_lst)
plt.xlabel("epoch")
plt.ylabel("accurate_rate")
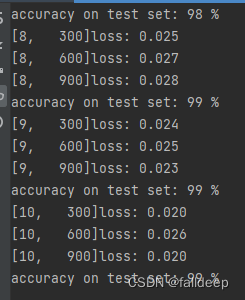
plt.show()3.训练结果
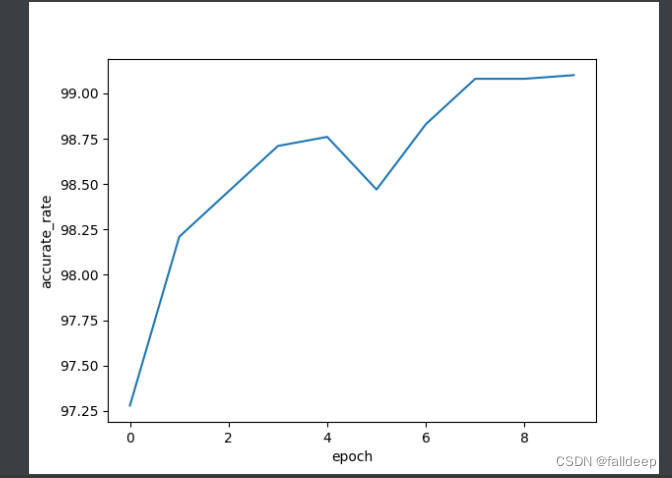 ?
?