����ͼ��ʵ�����ǩ����ѧϰ
����ѧϰ
����ѧϰ(Active Learning)�Ĵ���˼·����:ͨ������ѧϰ�ķ�����ȡ����Щ�Ƚ� ���ѡ� �������������,���˹��ٴ�ȷ�Ϻ����,Ȼ���˹���ע�õ��������ٴ�ʹ���мලѧϰģ�ͻ��߰�ලѧϰģ�ͽ���ѵ��,������ģ�͵�Ч��,���˹������������ѧϰ��ģ���С�
��ʾ�����ǩѧϰ
��ͳ�ļලѧϰ��,һ��ͼ��������һ��instance(ʾ��)����,����������һ����ǩ���ܶ�ͼ����ǩ��ע�ķ�����ͨ����ͼ���������ָ��������,Ȼ���ÿ�������������б�ע������ʾ�����ǩѧϰ����ʡȥ�˼��/�ָ�ֹ�����
��ʾ������ͼѧϰ
����ͼ��ʾ������ѧϰ��Ҫ��עͬһ��ͼ�ڰ�֮����ڲ���ϵ�����֮��,����ͼ��ʾ������ѧϰӦ�ÿ��ǿ���ͼ�İ�֮������ϵ������������ͼ���칹��,��ѡ�İ���ǩ������ͼ֮����ܲ�һ�¡�����ÿ����ͼ��ʾ���Բ�ͬ�ӽǵĶ���,��˴ӵ�����ͼ�����İ���ǩ�Բ��ɿ������,����ͼ���ݵĸ��Ժ�����Ϣ��Ӧ�ÿ��ǵ�����ͼ���ݵ�����ѧϰ��
M3AL
M3AL����ѧѧϰ�˿�����ͼ�İ��Ĺ�����Ϣ��������Ϣ;Ȼ������ÿ��δ��ǰ��ڶ����ͼ�е�ʵ���ֲ�,�Բ����Ķ����ԡ�Ȼ��ѵ����ʼ�İ�Ԥ����;Ȼ��ͨ����ϰ��Ĺ�����Ϣ��������Ϣ���䲻ͬ��ʵ���ֲ����������岻ȷ����; ���ʹ����ϵIJ�ȷ������ѡ����Ϣ��ḻ�İ���ǩ�Խ��в�ѯ;�û�õIJ�ѯ��Ӧ���±�ǩ��ؾ���Ͱ�Ԥ������
����ϵͳ
| ���� | ���� |
|---|---|
| D l v = { ( X 1 v , Y 1 ) , ( X 2 v , Y 2 ) , ? ? , ( X l v , Y l ) } \mathcal{D}_l^v=\{(\mathcal{X_1^v},\mathbf{Y}_1),(\mathcal{X_2^v},\mathbf{Y}_2),\cdots,(\mathcal{X_l^v},\mathbf{Y}_l)\} Dlv?={(X1v?,Y1?),(X2v?,Y2?),?,(Xlv?,Yl?)} | �� v v v����ͼ�е� l l l���б�ǵİ� |
| m i v m_i^v miv? | �� v v v����ͼ�е� i i i�����е�ʵ������ |
| x v \mathbf{x}^v xv | �� v v v����ͼ��ʵ���������ռ� |
| S \mathbf{S} S | ��ͬ��ͼ��Ĺ�����Ϣ |
| P \mathbf{P} P | ��ͬ��ͼ���������Ϣ |
| U ( S ^ , i , c ) U(\widehat{\mathbf{S}},i,c) U(S ,i,c) | �ڶ����ͼ�°���ǩ�� < i , c > <i,c> <i,c>�Ĺ�����Ϣ |
| U ( P ^ v , i , c ) U(\widehat{\mathbf{P}}^v,i,c) U(P v,i,c) | �� v v v��ͼ�°���ǩ�� < i , c > <i,c> <i,c>��������Ϣ |
����һ��ͼ
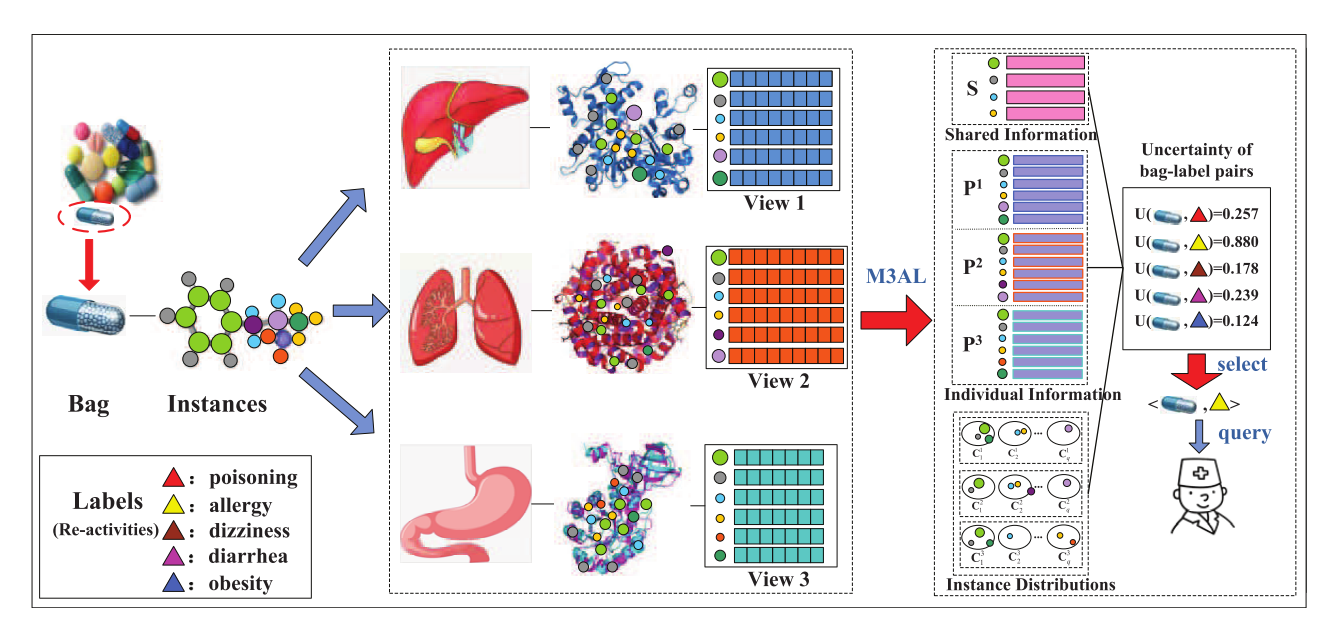
һ��ҩ�ﱻ����һ����,һ��ҩ���ɶ��ֻ��������,��Щ�����ﱻ��������ʵ����ҩ���ڲ�ͬ�����еı�ʾ��������ͬ����ͼ�� S \mathbf{S} S��ʾ��ͬ��ͼ֮��Ĺ�����Ϣ, P \mathbf{P} P��ʾ��ͬ��ͼ������Ϣ�����ǵ���Щ���ٵ� S \mathbf{S} S�� P \mathbf{P} P,����֤��ҩ�ﷴӦ�Բ���Ӧ��ע��ͬ���ٹ��е���Щ,��Ӧ��ע�����������еĶԡ���Щ��-��ǩ�Կ������Ƚ�������ҽѧר�ҽ��ж�����顣
��ȡ����ͼ���ĸ��Ժ���:
��
(
{
P
v
=
1
v
}
,
S
)
=
min
?
1
V
��
v
=
1
V
�O
�O
X
v
?
(
S
+
P
v
)
X
v
�O
�O
F
2
+
��
1
��
1
(
S
)
(
{
P
v
}
v
=
1
V
)
+
��
2
��
2
(
S
)
\Theta(\{\mathbf{P}^v_{v=1}\},\mathbf{S})=\min \frac{1}{V}\sum\limits_{v=1}^V||\mathbf{X}^v-(\mathbf{S}+\mathbf{P}^v)\mathbf{X}^v ||_F^2+\lambda_1\Phi_1(\mathbf{S})(\{\mathbf{P}^v\}^V_{v=1})+\lambda_2\Phi_2(\mathbf{S})
��({Pv=1v?},S)=minV1?v=1��V?�O�OXv?(S+Pv)Xv�O�OF2?+��1?��1?(S)({Pv}v=1V?)+��2?��2?(S)
����ʹ�ñ�Ķ�ʾ�����µĴ��������� X i v \mathcal{X}_i^v Xiv?ת��Ϊ��������ʾ X i v \mathbf{X}_i^v Xiv?,��һ��ʱ����ͼ��ȡ���Ĺ�����Ϣ����������Ϣ,�ڶ������ڼ�ǿ��ͬ��ͼ�±������֮��IJ��� { P v } v = 1 V \{\mathbf{P}^v\}^V_{v=1} {Pv}v=1V?,�������������ͼ�Ĺ��Ա������ S \mathbf{S} S.
���Ķ����Լ���:
D
B
v
(
i
)
=
1
C
��
c
=
1
C
��
c
v
(
i
)
l
o
g
(
��
c
v
(
i
)
)
+
(
1
?
��
c
v
(
i
)
)
l
o
g
(
1
?
��
c
v
(
i
)
)
l
o
g
(
0.5
)
DB^v(i)=\frac{1}{C}\sum\limits_{c=1}^C\frac{\beta_c^v(i)log(\beta_c^v(i))+(1-\beta_c^v(i))log(1-\beta_c^v(i))}{log(0.5)}
DBv(i)=C1?c=1��C?log(0.5)��cv?(i)log(��cv?(i))+(1?��cv?(i))log(1?��cv?(i))?
D
B
(
i
)
=
1
V
��
v
=
1
V
D
B
v
(
i
)
DB(i)=\frac{1}{V}\sum\limits_{v=1}^{V}DB^v(i)
DB(i)=V1?v=1��V?DBv(i)
�����������ʵ�����в���ͬ�ķֲ����ǩ,��ð��Ķ����Խϸ�,�����ܱ�ѡ�����ڲ�ѯ����ѯ���в�ͬʵ���ֲ��İ����Դ��ģ�͵IJ�ȷ���ԡ�
���
