论文题目:Is Space-Time Attention All You Need for Video Understanding?
论文链接:https://arxiv.org/pdf/2102.05095.pdf
github 地址:https://github.com/lucidrains/TimeSformer-pytorch
引言
自从Transformer爆火以来,Facebook AI提出了一种称为 TimeSformer(Time-Space transformer) 的视频理解新架构,这个结构完全基于 Transformer。
TimeSformer 在多个有挑战的行为识别数据集上达到了 SOTA 的结果,论文中使用的数据集包括 Kinetics-400,Kinetics-600、Something-Something-v2 、Diving-48 和 HowTo100M 数据集。相比于现代的 3D 卷积神经网络,TimeSformer训练要快3倍,推理的时间为它的十分之一。
此外,TimeSformer 还具有可扩展性,它可以在更长的视频片段上训练更大的模型,当前的 3D CNN 最多只能够处理几秒钟的片段,使用 TimeSformer ,甚至可以在数分钟的片段上进行训练。
TimeSformer简介
如果直接将VIT用于视频理解,那要怎么做呢,容易想到的方法是抽取多帧图片,每一帧的图像都分成一个一个的小patch,然后直接送入transformer。从原理上来说这样是可行的,但是就如同3D卷积神经网络一样,计算量是非常庞大的,特别是对于视频时间相对长一些的数据来说,需要提取的帧数也要随之增加。本文中作者实验了五种不同的方式,最终发现了所谓的divided space-time attention,就是空间和时间上分离的注意力这种方式,不仅减少了计算量,效果上还表现SOTA。下图是作者实验的几种结构:
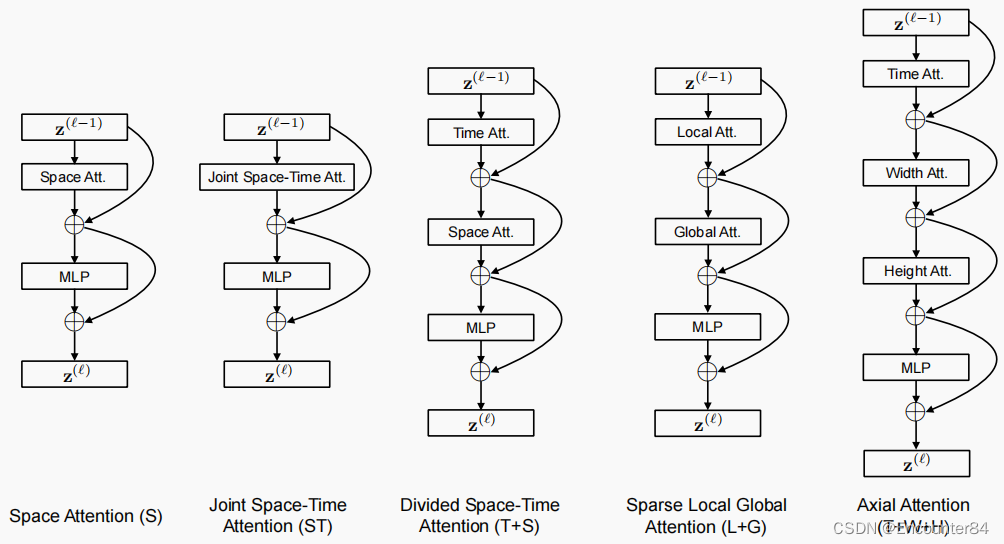

我们知道transformer的核心是self-attention,是K,Q,V之间的矩阵乘法,我们要关注的就是哪些图像patch放到一起来计算attention。五种不同的计算attention的方式如上图所示。假设我们对视频提取3帧,每一帧分成16小块。第t帧中蓝颜色的块为query块,其余颜色块为与其进行attention的patch块。
通过对输入图像进行分块,论文中一共研究了五种不同的注意力机制:
1.空间注意力机制(S):只取同一帧内的图像块进行自注意力机制,第t时刻其余图像块参与query块的计算,即只考虑每一帧自身,不考虑时序性,即第t帧与t+1和t-1帧没有联系;
2.时空共同注意力机制(ST):取所有帧中的所有图像块进行注意力机制,在上图中,三帧中所有图像块(除去query块)均参与query 块进行计算,计算量大了很多。
3.分开的时空注意力机制(T+S):在时间 attention 中,每个图像块仅和其余帧在对应位置提取出的图像块进行 attention。在空间 attention 中,这个图像块仅和同一帧的提取出的图像块进行 attention。也就是计算两种attention,其一为Space Attention,第t时刻其余图像块参与query块的计算;其二为Time attention,第t时刻的query和其余时刻对应位置的图像块(绿颜色)计算。这也是作者实验中表现SOTA的方式,且时间复杂度低,耗时短。如果假设一段视频里面有m帧图像,每个图像有
n
2
n^2
n2个patch,由于Transformer的时间复杂度为O(
n
2
n^2
n2),时空共同注意力机制的复杂度为O(
(
n
2
m
)
2
(n^2m)^2
(n2m)2),即
n
4
m
2
n^4m^2
n4m2。而分开的时空注意力机制复杂度为
n
2
m
2
n^2m^2
n2m2+
n
4
m
n^4m
n4m,低于时空共同注意力机制。
4.稀疏局部全局注意力机制(L+G):先利用所有帧中,相邻的 H/2 和 W/2 的图像块计算局部的注意力,然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似。
5.轴向的注意力机制(T+W+H):先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上进行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制。这种方式的时间复杂度就更低了,从图中也可以看出。
实验
自注意力机制的分析
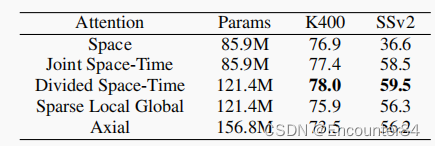
由上图可以看出,Space和Joint Space-Time的参数量是一样的,因为他们使用的都是同一个模型,只是参与计算的patch数量不一样(?感觉也不对啊。。存疑),在 K400 和 SSv2 数据集上研究了所提的五个自注意力策略,其中Divided Space-Time效果最好。
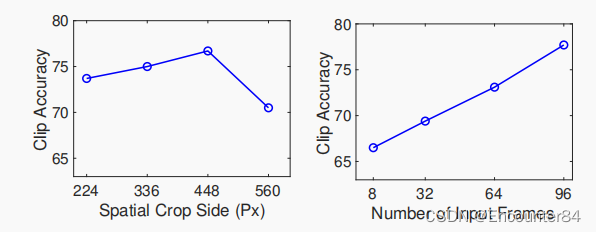
图像大小和视频长度的影响
当每一个图像块的大小不变时,图像越大,图像块的个数越多。同时,帧数越多,输入注意力机制的数据也越多。由图可知,随着输入信息更加丰富,带来的效果提升是非常明显的。
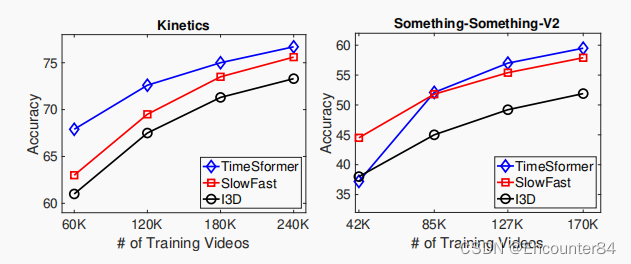
预训练和数据集规模的重要性
为了研究数据集的规模的影响,使用了两个数据集,实验中,分四组,分别使用25%,50%,75%和100%的数据。结果是 TimeSformer 当数据比较少的时候表现不太好,数据多的时候表现好。
 实验结果
实验结果
作者在实验中尝试了模型的两种升级版:
原版:TimeSformer
升级版1:TimeSformer-HR:空间清晰度比较高
升级版2:TimeSformer-L:时间范围比较广
K400上的结果:
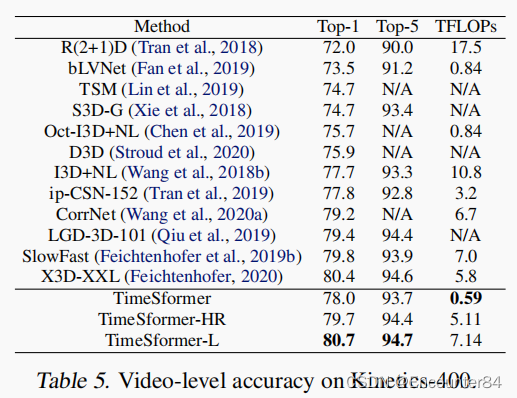
K600上的结果:
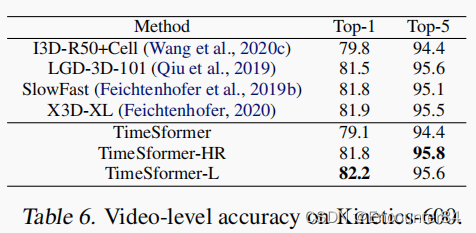
SSV2和Diving48上的结果:
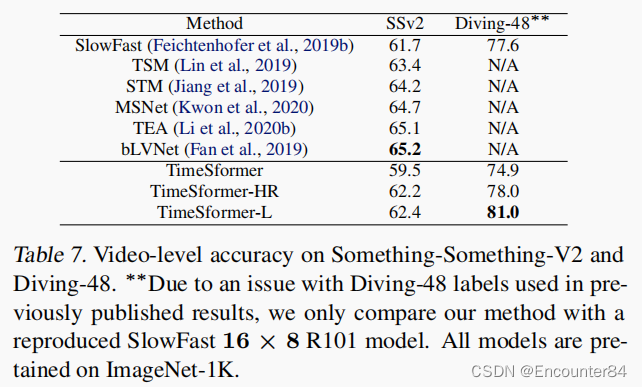
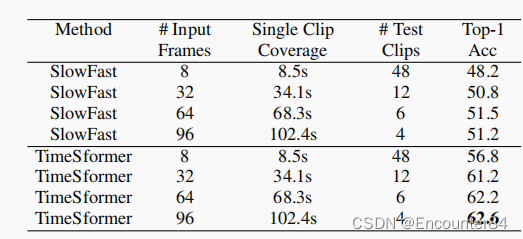
视频中长期建模的优势:
从图中可以看出,由于Divided space-time attention特点,随着视频长度的增加,TimeSformer计算量并不会显著增加,而且模型同样能对中长时间的时空特点进行建模,进一步体现出了优势。
代码
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from timesformer_pytorch.rotary import apply_rot_emb, AxialRotaryEmbedding, RotaryEmbedding
# helpers
def exists(val):
return val is not None
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x, *args, **kwargs):
x = self.norm(x)
return self.fn(x, *args, **kwargs)
# time token shift
def shift(t, amt):
if amt is 0:
return t
return F.pad(t, (0, 0, 0, 0, amt, -amt))
class PreTokenShift(nn.Module):
def __init__(self, frames, fn):
super().__init__()
self.frames = frames
self.fn = fn
def forward(self, x, *args, **kwargs):
f, dim = self.frames, x.shape[-1]
cls_x, x = x[:, :1], x[:, 1:]
x = rearrange(x, 'b (f n) d -> b f n d', f = f)
# shift along time frame before and after
dim_chunk = (dim // 3)
chunks = x.split(dim_chunk, dim = -1)
chunks_to_shift, rest = chunks[:3], chunks[3:]
shifted_chunks = tuple(map(lambda args: shift(*args), zip(chunks_to_shift, (-1, 0, 1))))
x = torch.cat((*shifted_chunks, *rest), dim = -1)
x = rearrange(x, 'b f n d -> b (f n) d')
x = torch.cat((cls_x, x), dim = 1)
return self.fn(x, *args, **kwargs)
# feedforward
class GEGLU(nn.Module):
def forward(self, x):
x, gates = x.chunk(2, dim = -1)
return x * F.gelu(gates)
class FeedForward(nn.Module):
def __init__(self, dim, mult = 4, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, dim * mult * 2),
GEGLU(),
nn.Dropout(dropout),
nn.Linear(dim * mult, dim)
)
def forward(self, x):
return self.net(x)
# attention
def attn(q, k, v, mask = None):
sim = einsum('b i d, b j d -> b i j', q, k)
if exists(mask):
max_neg_value = -torch.finfo(sim.dtype).max
sim.masked_fill_(~mask, max_neg_value)
attn = sim.softmax(dim = -1)
out = einsum('b i j, b j d -> b i d', attn, v)
return out
class Attention(nn.Module):
def __init__(
self,
dim,
dim_head = 64,
heads = 8,
dropout = 0.
):
super().__init__()
self.heads = heads
self.scale = dim_head ** -0.5
inner_dim = dim_head * heads
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x, einops_from, einops_to, mask = None, cls_mask = None, rot_emb = None, **einops_dims):
h = self.heads
q, k, v = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h = h), (q, k, v))
q = q * self.scale
# splice out classification token at index 1
(cls_q, q_), (cls_k, k_), (cls_v, v_) = map(lambda t: (t[:, :1], t[:, 1:]), (q, k, v))
# let classification token attend to key / values of all patches across time and space
cls_out = attn(cls_q, k, v, mask = cls_mask)
# rearrange across time or space
q_, k_, v_ = map(lambda t: rearrange(t, f'{einops_from} -> {einops_to}', **einops_dims), (q_, k_, v_))
# add rotary embeddings, if applicable
if exists(rot_emb):
q_, k_ = apply_rot_emb(q_, k_, rot_emb)
# expand cls token keys and values across time or space and concat
r = q_.shape[0] // cls_k.shape[0]
cls_k, cls_v = map(lambda t: repeat(t, 'b () d -> (b r) () d', r = r), (cls_k, cls_v))
k_ = torch.cat((cls_k, k_), dim = 1)
v_ = torch.cat((cls_v, v_), dim = 1)
# attention
out = attn(q_, k_, v_, mask = mask)
# merge back time or space
out = rearrange(out, f'{einops_to} -> {einops_from}', **einops_dims)
# concat back the cls token
out = torch.cat((cls_out, out), dim = 1)
# merge back the heads
out = rearrange(out, '(b h) n d -> b n (h d)', h = h)
# combine heads out
return self.to_out(out)
# main classes
class TimeSformer(nn.Module):
def __init__(
self,
*,
dim,
num_frames,
num_classes,
image_size = 224,
patch_size = 16,
channels = 3,
depth = 12,
heads = 8,
dim_head = 64,
attn_dropout = 0.,
ff_dropout = 0.,
rotary_emb = True,
shift_tokens = False
):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
num_positions = num_frames * num_patches
patch_dim = channels * patch_size ** 2
self.heads = heads
self.patch_size = patch_size
self.to_patch_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, dim))
self.use_rotary_emb = rotary_emb
if rotary_emb:
self.frame_rot_emb = RotaryEmbedding(dim_head)
self.image_rot_emb = AxialRotaryEmbedding(dim_head)
else:
self.pos_emb = nn.Embedding(num_positions + 1, dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
ff = FeedForward(dim, dropout = ff_dropout)
time_attn = Attention(dim, dim_head = dim_head, heads = heads, dropout = attn_dropout)
spatial_attn = Attention(dim, dim_head = dim_head, heads = heads, dropout = attn_dropout)
if shift_tokens:
time_attn, spatial_attn, ff = map(lambda t: PreTokenShift(num_frames, t), (time_attn, spatial_attn, ff))
time_attn, spatial_attn, ff = map(lambda t: PreNorm(dim, t), (time_attn, spatial_attn, ff))
self.layers.append(nn.ModuleList([time_attn, spatial_attn, ff]))
self.to_out = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, video, mask = None):
b, f, _, h, w, *_, device, p = *video.shape, video.device, self.patch_size
assert h % p == 0 and w % p == 0, f'height {h} and width {w} of video must be divisible by the patch size {p}'
# calculate num patches in height and width dimension, and number of total patches (n)
hp, wp = (h // p), (w // p)
n = hp * wp
# video to patch embeddings
video = rearrange(video, 'b f c (h p1) (w p2) -> b (f h w) (p1 p2 c)', p1 = p, p2 = p)
tokens = self.to_patch_embedding(video)
# add cls token
cls_token = repeat(self.cls_token, 'n d -> b n d', b = b)
x = torch.cat((cls_token, tokens), dim = 1)
# positional embedding
frame_pos_emb = None
image_pos_emb = None
if not self.use_rotary_emb:
x += self.pos_emb(torch.arange(x.shape[1], device = device))
else:
frame_pos_emb = self.frame_rot_emb(f, device = device)
image_pos_emb = self.image_rot_emb(hp, wp, device = device)
# calculate masking for uneven number of frames
frame_mask = None
cls_attn_mask = None
if exists(mask):
mask_with_cls = F.pad(mask, (1, 0), value = True)
frame_mask = repeat(mask_with_cls, 'b f -> (b h n) () f', n = n, h = self.heads)
cls_attn_mask = repeat(mask, 'b f -> (b h) () (f n)', n = n, h = self.heads)
cls_attn_mask = F.pad(cls_attn_mask, (1, 0), value = True)
# time and space attention
for (time_attn, spatial_attn, ff) in self.layers:
x = time_attn(x, 'b (f n) d', '(b n) f d', n = n, mask = frame_mask, cls_mask = cls_attn_mask, rot_emb = frame_pos_emb) + x
x = spatial_attn(x, 'b (f n) d', '(b f) n d', f = f, cls_mask = cls_attn_mask, rot_emb = image_pos_emb) + x
x = ff(x) + x
cls_token = x[:, 0]
return self.to_out(cls_token)
参考网址:
1.https://zhuanlan.zhihu.com/p/360349869
2.https://www.bilibili.com/video/BV11Y411P7ep?spm_id_from=333.999.0.0&vd_source=5e1245e8eb129616520e394d9dec0623
3.https://blog.csdn.net/m0_37169880/article/details/114941518?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165923576316781818755705%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=165923576316781818755705&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-1-114941518-null-null.142v35pc_rank_34&utm_term=Timesformer&spm=1018.2226.3001.4187