一、前言
PPLiteSeg是百度飞浆研发的一种兼具高精度和低延时的实时语义分割算法,目前已经开源。
实时语义分割领域更讲究运行流程性和分割准确度之间的平衡。
PP-LiteSeg 是一个同时兼顾精度与速度的 SOTA(业界最佳)语义分割模型。它基于 Cityscapes 数据集,在 1080ti 上精度为 mIoU 72.0 时,速度高达273.6 FPS(mIoU 77.5 时,FPS 为102.6),超越现有 CVPR SOTA 模型 STDC,真正实现了精度和速度的 SOTA 均衡。
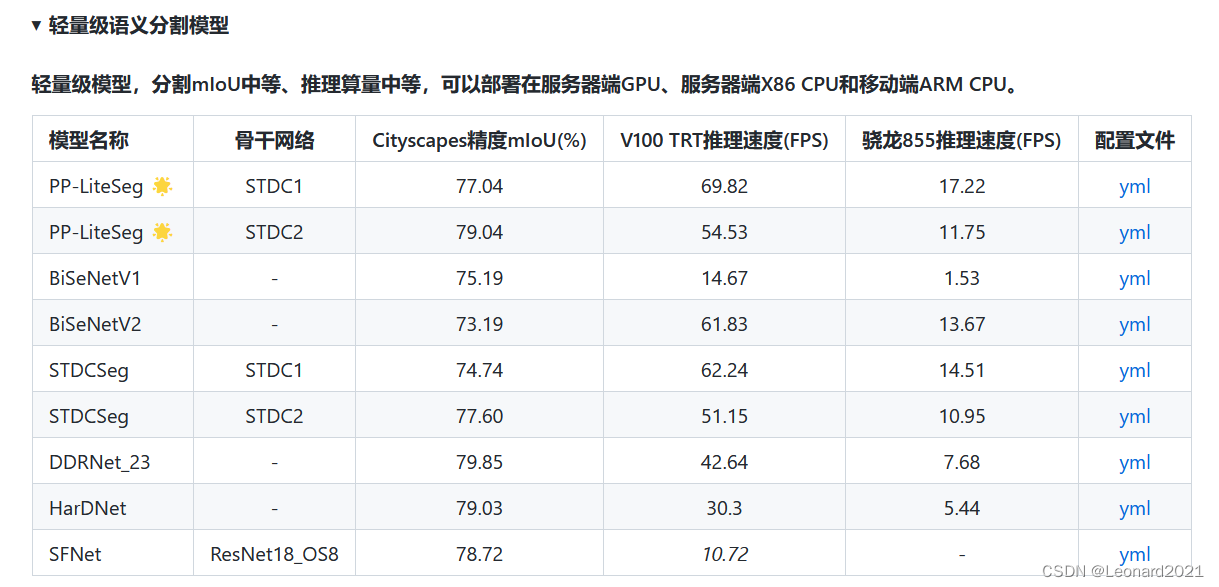
?更值得令人惊喜的是,PP-LiteSeg 不仅在开源数据集评测效果优秀,在产业数据集也表现出了惊人的实力!例如在质检、遥感场景,PP-LiteSeg 的精度与高精度、大体积的 OCRNet 持平,而速度却快了近7倍!!!
本人使用PP-LiteSeg 的目的是尝试将语义分割和目标检测相结合,来实现自动驾驶的视觉部分。
由于PP-LiteSeg 在实时语义分割领域的实时检测流程性和分割准确率都是SOTA,故选择其进行训练与部署。
二、训练
1.环境的搭建
根据你电脑的显卡类型、安装的显卡驱动来安装? paddlepaddle-gpu? ,比如我的电脑显卡是英伟达的 RTX 2060,CUDA是11.1,CUDNN是8.1,选择对应的版本进行命令行下载。
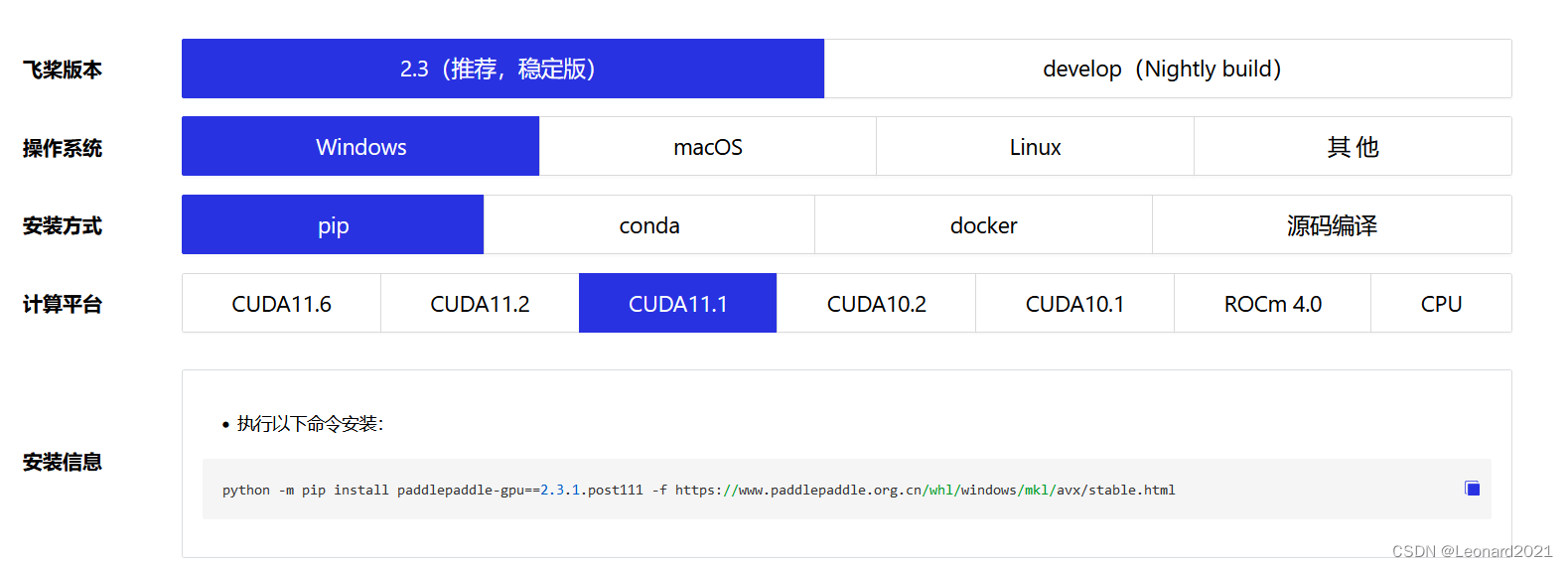
使用如下命令验证PaddlePaddle是否安装成功,并且查看版本。
# 在Python解释器中顺利执行如下命令
>>> import paddle
>>> paddle.utils.run_check()
# 如果命令行出现以下提示,说明PaddlePaddle安装成功
# PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
# 查看PaddlePaddle版本
>>> print(paddle.__version__)
?安装完成后,安装 PaddleSeg
pip install paddleseg2.数据集
首先,我使用的数据集是Kaggle上获取的CARLA自动驾驶汽车模拟器的数据集,后续会尝试使用真实环境下的数据集进行训练与分割。
Semantic Segmentation for Self Driving Cars | Kaggle
它的原始数据集分成了A、B、C、D、E五个部分,每个部分含有1000张image和1000张对应的mask。
数据集处理的官方教程:
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/docs/data/marker/marker_cn.md
可能需要用到的代码, change_channel.py? :
# 将三通道变成单通道。
import os
import os.path as osp
import sys
import numpy as np
from PIL import Image
input = 'data/dataA_B/annotations'
# os.walk()方法用于通过在目录树中游走输出在目录中的文件名
for fpath, dirs, fs in os.walk(input):
print(fpath)
for f in fs:
try:
path = osp.join(fpath, f)
# _output_dir = fpath.replace(input, '')
# _output_dir = _output_dir.lstrip(os.path.sep)
image = Image.open(path)
image,_,_ = image.split()
image.save(path)
except:
continue
print("已变为单通道!")可能用到的命令行:
# 变成伪彩色图
python gray2pseudo_color.py /CARLA_data/annotations /CARLA_data/annotations# 数据划分
python split_dataset_list.py CARLA_data images annotations --split 0.9 0.1 0 --format png png我将原始数据集整理到一起,并且进行了重命名和数据集划分,方便操作。免费提供给大家:
链接:https://pan.baidu.com/s/1dzQw8XD-URdBiEq8XArDdw
提取码:8888
整体架构:
CARLA_data-
-annotations
---000000.png
---000001.png
---**********
-images
---000000.png
---000001.png
---**********
-test.txt
-train.txt
-val.txt3.训练实战
百度飞浆官方教程:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/docs/whole_process_cn.md
PaddleSeg动态图API使用教程 - 飞桨AI Studio
我使用的是API的简易版本,具体如下:
建立一个?? train.py? 文件
from paddleseg.models import PPLiteSeg
from paddleseg.models.backbones import STDC1
import paddleseg.transforms as T
from paddleseg.datasets import Dataset
from paddleseg.models.losses import CrossEntropyLoss
import paddle
from paddleseg.core import train
backbone = STDC1()
#构建模型
model = PPLiteSeg(num_classes=13,
backbone= backbone,
arm_out_chs = [32, 64, 128],
seg_head_inter_chs = [32, 64, 64],
pretrained=None)
# 构建训练用的transforms
transforms = [
T.ResizeStepScaling(min_scale_factor=0.5,max_scale_factor=2.5,scale_step_size=0.25),
T.RandomPaddingCrop(crop_size=[960,720]),
T.RandomHorizontalFlip(),
T.RandomDistort(brightness_range=0.5,contrast_range=0.5,saturation_prob=0.5),
T.Normalize()
]
# 构建训练集
train_dataset = Dataset(
transforms = transforms,
dataset_root = 'CARLA_data',
num_classes= 13,
train_path = 'CARLA_data/train.txt',
mode='train'
)
# 构建验证用的transforms
transforms = [
T.Normalize()
]
# 构建验证集
val_dataset = Dataset(
transforms = transforms,
dataset_root = 'CARLA_data',
num_classes= 13,
val_path = 'CARLA_data/val.txt',
mode='val'
)
# 设置学习率
base_lr = 0.01
lr = paddle.optimizer.lr.PolynomialDecay(base_lr, power=0.9, decay_steps=1000, end_lr=0)
optimizer = paddle.optimizer.Momentum(lr, parameters=model.parameters(), momentum=0.9, weight_decay=4.0e-5)
#构建损失函数
losses = {}
losses['types'] = [CrossEntropyLoss()] * 3
losses['coef'] = [1]* 3
#设置训练函数
train(
model=model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=optimizer,
save_dir='output',
iters=10000,
batch_size=4,
save_interval=200,
log_iters=10,
num_workers=0,
losses=losses,
use_vdl=True)训练完成后会在根目录下的output文件夹中生成训练好的模型以及训练过程的日志。
?对图像文件或者文件夹内的图像文件进行识别与保存:建立? predict.py? 文件
from paddleseg.models import PPLiteSeg
from paddleseg.models.backbones import STDC1
import paddleseg.transforms as T
import os
from paddleseg.core import predict
backbone = STDC1()
model = PPLiteSeg(num_classes=13,
backbone= backbone,
arm_out_chs = [32, 64, 128],
seg_head_inter_chs = [32, 64, 64],
pretrained=None)
transforms = T.Compose([
T.Resize(target_size=(512, 512)),
T.RandomHorizontalFlip(),
T.Normalize()
])
def get_image_list(image_path):
"""Get image list"""
valid_suffix = [
'.JPEG', '.jpeg', '.JPG', '.jpg', '.BMP', '.bmp', '.PNG', '.png'
]
image_list = []
image_dir = None
if os.path.isfile(image_path):
if os.path.splitext(image_path)[-1] in valid_suffix:
image_list.append(image_path)
elif os.path.isdir(image_path):
image_dir = image_path
for root, dirs, files in os.walk(image_path):
for f in files:
if os.path.splitext(f)[-1] in valid_suffix:
image_list.append(os.path.join(root, f))
else:
raise FileNotFoundError(
'`--image_path` is not found. it should be an image file or a directory including images'
)
if len(image_list) == 0:
raise RuntimeError('There are not image file in `--image_path`')
return image_list, image_dir
if __name__ == '__main__':
image_path = 'CARLA_data/image/000658.png' # 也可以输入一个包含图像的目录
image_list, image_dir = get_image_list(image_path)
predict(
model,
model_path='output/best_model/model.pdparams',
transforms=transforms,
image_list=image_list,
image_dir=image_dir,
save_dir='output/results'
)识别结果将保存到根目录下output文件夹内的 result文件夹内,这种预测方式只能针对图像,无法做到实时检测,非常地不人性化。
原始图像:


?
三、爆改? predict.py? 制作成实时检测的可低延时调用的API
1.思路
原始的paddleseg.core.py下的predict函数输入端要求是文件的地址,即要求:string格式的输入,故直接改成 0 来调用摄像头来获取图像是完全不可行的,且输出端只有保存到指定地址的代码,没有实时识别与显示的代码,中间还夹杂了很多用于记录训练过程的代码和写入文件的代码。我的整体思路是将输入端改成:由调用端的程序获取摄像头图像后输入到predict函数中,predict函数再进行实时预测并且显示到屏幕上,删去其他用于记录的代码,提高运行流畅性。
2.代码
根目录下新建 visualize_myself.py :
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import cv2
import numpy as np
from PIL import Image as PILImage
def visualize(image, result, color_map, save_dir=None, weight=0.6):
"""
Convert predict result to color image, and save added image.
Args:
image (str): The path of origin image.
result (np.ndarray): The predict result of image.
color_map (list): The color used to save the prediction results.
save_dir (str): The directory for saving visual image. Default: None.
weight (float): The image weight of visual image, and the result weight is (1 - weight). Default: 0.6
Returns:
vis_result (np.ndarray): If `save_dir` is None, return the visualized result.
"""
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
color_map = np.array(color_map).astype("uint8")
# Use OpenCV LUT for color mapping
c1 = cv2.LUT(result, color_map[:, 0])
c2 = cv2.LUT(result, color_map[:, 1])
c3 = cv2.LUT(result, color_map[:, 2])
pseudo_img = np.dstack((c3, c2, c1))
#im = cv2.imread(image)
im = image.copy()
vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
if save_dir is not None:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
image_name = os.path.split(image)[-1]
out_path = os.path.join(save_dir, image_name)
cv2.imwrite(out_path, vis_result)
else:
return vis_result
def get_pseudo_color_map(pred, color_map=None):
"""
Get the pseudo color image.
Args:
pred (numpy.ndarray): the origin predicted image.
color_map (list, optional): the palette color map. Default: None,
use paddleseg's default color map.
Returns:
(numpy.ndarray): the pseduo image.
"""
pred_mask = PILImage.fromarray(pred.astype(np.uint8), mode='P')
if color_map is None:
color_map = get_color_map_list(256)
pred_mask.putpalette(color_map)
return pred_mask
def get_color_map_list(num_classes, custom_color=None):
"""
Returns the color map for visualizing the segmentation mask,
which can support arbitrary number of classes.
Args:
num_classes (int): Number of classes.
custom_color (list, optional): Save images with a custom color map. Default: None, use paddleseg's default color map.
Returns:
(list). The color map.
"""
num_classes += 1
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = color_map[3:]
if custom_color:
color_map[:len(custom_color)] = custom_color
return color_map
def paste_images(image_list):
"""
Paste all image to a image.
Args:
image_list (List or Tuple): The images to be pasted and their size are the same.
Returns:
result_img (PIL.Image): The pasted image.
"""
assert isinstance(image_list,
(list, tuple)), "image_list should be a list or tuple"
assert len(
image_list) > 1, "The length of image_list should be greater than 1"
pil_img_list = []
for img in image_list:
if isinstance(img, str):
assert os.path.exists(img), "The image is not existed: {}".format(
img)
img = PILImage.open(img)
img = np.array(img)
elif isinstance(img, np.ndarray):
img = PILImage.fromarray(img)
pil_img_list.append(img)
sample_img = pil_img_list[0]
size = sample_img.size
for img in pil_img_list:
assert size == img.size, "The image size in image_list should be the same"
width, height = sample_img.size
result_img = PILImage.new(sample_img.mode,
(width * len(pil_img_list), height))
for i, img in enumerate(pil_img_list):
result_img.paste(img, box=(width * i, 0))
return result_img
根目录下新建? predict_with_api.py? :
import cv2
import numpy as np
import paddle
from paddleseg.core import infer
from paddleseg.utils import visualize
import visualize_myself
def preprocess(im_path, transforms):
data = {}
data['img'] = im_path
data = transforms(data)
data['img'] = data['img'][np.newaxis, ...]
data['img'] = paddle.to_tensor(data['img'])
return data
def predict(model,
model_path,
transforms,
image_list,
aug_pred=False,
scales=1.0,
flip_horizontal=True,
flip_vertical=False,
is_slide=False,
stride=None,
crop_size=None,
custom_color=None
):
# 加载模型权重
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
# 设置模型为评估模式
model.eval()
# 读取图像
im = image_list.copy()
color_map = visualize.get_color_map_list(256, custom_color=custom_color)
with paddle.no_grad():
data = preprocess(im, transforms)
# 是否开启多尺度翻转预测
if aug_pred:
pred, _ = infer.aug_inference(
model,
data['img'],
trans_info=data['trans_info'],
scales=scales,
flip_horizontal=flip_horizontal,
flip_vertical=flip_vertical,
is_slide=is_slide,
stride=stride,
crop_size=crop_size)
else:
pred, _ = infer.inference(
model,
data['img'],
trans_info=data['trans_info'],
is_slide=is_slide,
stride=stride,
crop_size=crop_size)
# 将返回数据去除多余的通道,并转为uint8类型,方便保存为图片
#pred_org =pred.clone()
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')
# 保存结果
added_image = visualize_myself.visualize(image= im,result= pred,color_map=color_map, weight=0.6)
cv2.imshow('image_predict', added_image)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
#return pred_org根目录下新建 detect_with_API.py,调用制作好的API来尝试使用摄像头图像实时预测分割:
import cv2
from predict_with_api import predict
from paddleseg.models import PPLiteSeg
from paddleseg.models.backbones import STDC1
import paddleseg.transforms as T
backbone = STDC1()
model = PPLiteSeg(num_classes=13,
backbone= backbone,
arm_out_chs = [32, 64, 128],
seg_head_inter_chs = [32, 64, 64],
pretrained=None)
transforms = T.Compose([
T.Resize(target_size=(512, 512)),
T.RandomHorizontalFlip(),
T.Normalize()
])
model_path = 'output/best_model/model.pdparams'
cap=cv2.VideoCapture(0)# 0
if __name__ == '__main__':
while True:
rec,img = cap.read()
predict(model=model,model_path=model_path, transforms=transforms,image_list=img)
#print("pred_org:", type(list), list)
if cv2.waitKey(1)==ord('q'):
break
配置完成后,运行 detect_with_API.py即可实现调用摄像头输入到训练好的模型框架中进行预测分割并输出到屏幕上。
由于我使用的是仿真数据集,使用摄像头识别的话没有对应的识别环境,故这里我就简单展示实时识别的状态,识别效果不作评价。
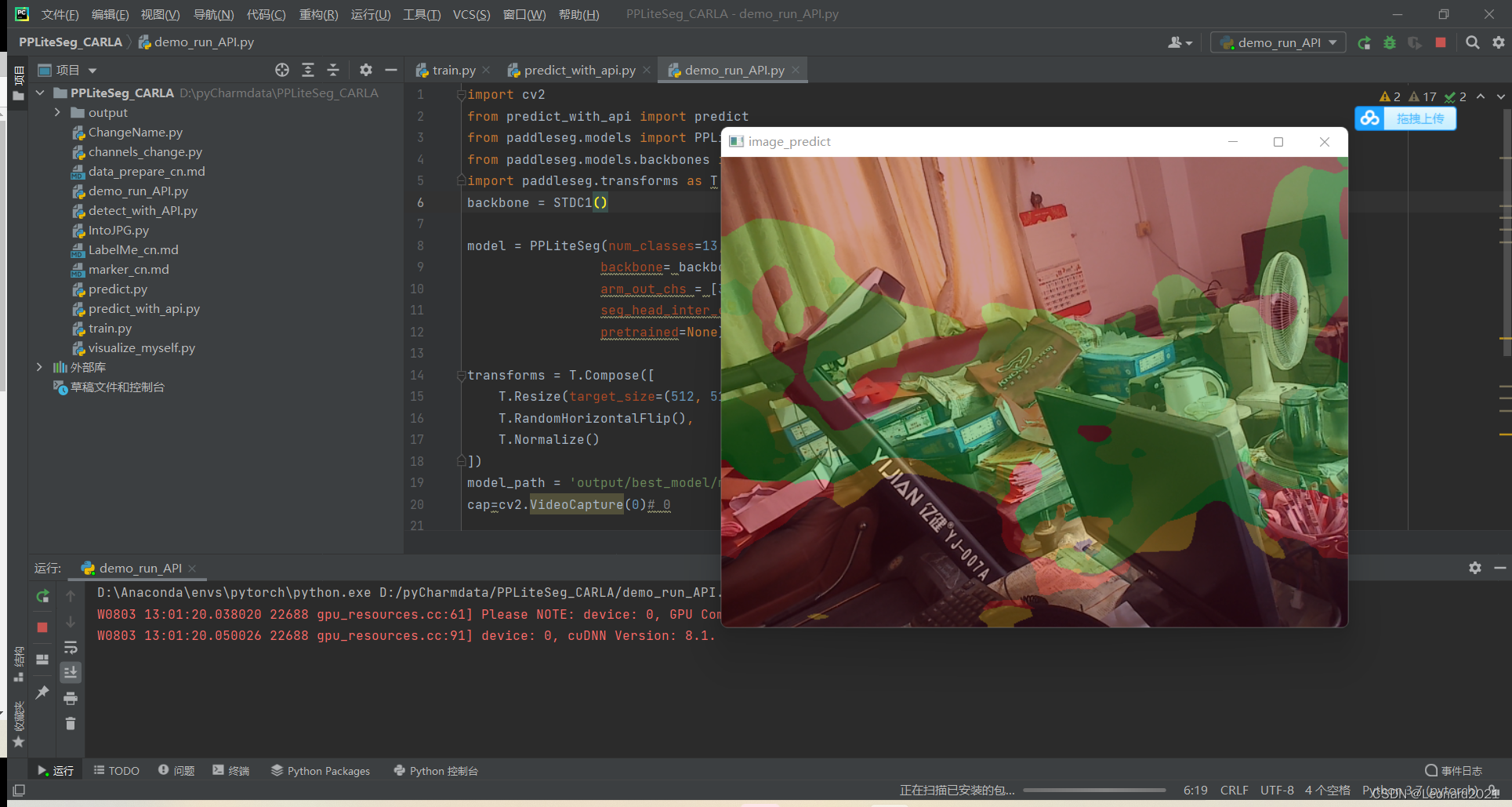
?我的整体项目框架:
PPLiteSeg_CARLA.zip-深度学习文档类资源-CSDN下载
后续在对真实环境下的道路数据集进行收集与训练后,通过摄像头获取实时图像并输出对应的mask预测结果,比如:对车道线和道路的语义分割,再通过霍夫线变换找到车道线的位置和角度来控制无人车的转向,实现沿道路自动驾驶。后续可能会加更,敬请期待。
再与目标检测相结合,实现对道路上的目标进行识别,返回目标的二维坐标、目标种类、置信度,目标可以通过自己收集数据进行训练,比如:车、红绿灯、人、动物、绿植等,通过返回的信息设置相应的逻辑,比如:红灯停、绿灯行、遇行人停等。
爆改YOLOV7的detect.py制作成API接口供其他python程序调用(超低延时)_Leonard2021的博客-CSDN博客
这样以后整体上就完成了无人驾驶的视觉识别部分。
后续再加上ROS的激光雷达实现避障和SLAM,就形成了一个简易自制版的无人驾驶系统。
我的初步想法是 上位机使用Jeston Nano,下位机使用Arduino,以python为主要编程语言,pyserial库来实现上位机与下位机之间的通讯。
python与arduino通讯(windows和linux)_Leonard2021的博客-CSDN博客_python与arduino通信