етРяаДФПТМБъЬт
Part1 ТлЮФдФЖСгыЪгЦЕбЇЯА:
ДЋЭГОэЛ§ЩёОЭјТч,ФкДцашЧѓДѓЁЂдЫЫуСПДѓ ЕМжТЮоЗЈдквЦЖЏЩшБИвдМАЧЖШыЪНЩшБИЩЯдЫаа,ЬсГіСЫMobilenetЭјТчЁЃ
?
1 MobilenetЯЕСа
1.1 Mobilenet V1
ЭјТчжаЕФССЕу:
- ЬсГіСЫЩюЖШПЩЗжРыОэЛ§(Depthwise Convolution),ЫќНЋБъзМОэЛ§ЗжНтГЩЩюЖШОэЛ§вдМАвЛИі1x1ЕФОэЛ§МДж№ЕуОэЛ§,ДѓЗљЖШМѕЩйСЫдЫЫуСПКЭВЮЪ§СПЁЃ
- діМгГЌВЮЪ§ІСЁЂІТ,етСНИіГЌВЮЪ§ЪЧШЫЮЊЩшЖЈЕФ,ВЂЗЧбЇЯАЕУЕНЕФЁЃ
ЯТУцПДвЛЯТЦеЭЈОэЛ§КЭЩюЖШПЩЗжОэЛ§ЕФЖдБШ:
????ДЋЭГ(ЦеЭЈ)ОэЛ§:- ОэЛ§КЫ c h a n n e l = ЪфШыЬиеїОиеѓ c h a n n e l ОэЛ§КЫchannel = ЪфШыЬиеїОиеѓchannel ОэЛ§КЫchannel=ЪфШыЬиеїОиеѓchannel
-
ЪфГіЬиеїОиеѓ
c
h
a
n
n
e
l
=
ОэЛ§КЫИіЪ§
ЪфГіЬиеїОиеѓchannel = ОэЛ§КЫИіЪ§
ЪфГіЬиеїОиеѓchannel=ОэЛ§КЫИіЪ§
DWОэЛ§: - ОэЛ§КЫ c h a n n e l = 1 ОэЛ§КЫchannel=1 ОэЛ§КЫchannel=1
-
ЪфШыЬиеїОиеѓ
c
h
a
n
n
e
l
=
ОэЛ§КЫИіЪ§
=
ЪфГіЬиеїОиеѓ
c
h
a
n
n
e
l
ЪфШыЬиеїОиеѓchannel=ОэЛ§КЫИіЪ§=ЪфГіЬиеїОиеѓchannel
ЪфШыЬиеїОиеѓchannel=ОэЛ§КЫИіЪ§=ЪфГіЬиеїОиеѓchannel
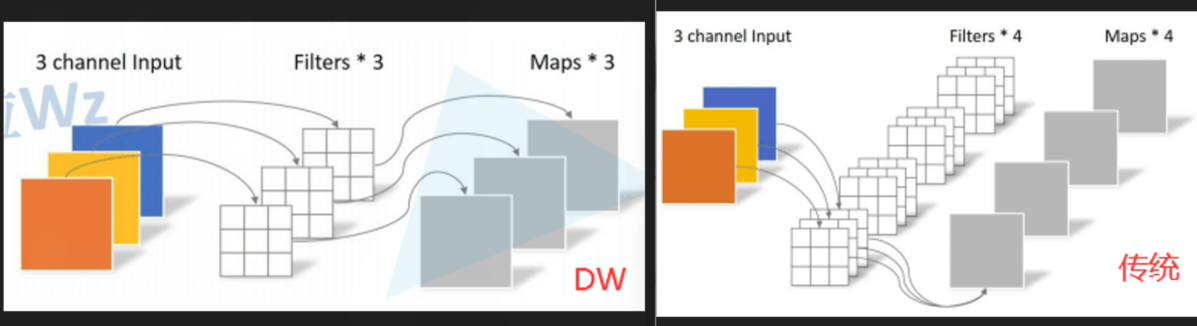
вЛАуЪЧ DW+PW вЛЦ№ЪЙгУ,РэТлЩЯ ЦеЭЈОэЛ§ЕФ МЦЫуСПЪЧ DW+PW ЕФ8ЕН9БЖ ~
зЂвт:PW ЕФ filter ДѓаЁЮЊ 1 ЁС 1 ЁС C i n 1\times 1\times C_{in} 1ЁС1ЁСCin?
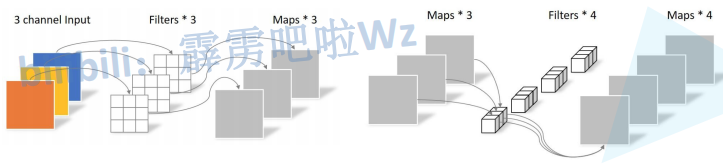
DW + PW
depthwiseВПЗжЕФОэЛ§КЫШнвзЗбЕє,МДОэЛ§КЫВЮЪ§ДѓВПЗжЮЊСуЁЃ?
1.2 Mobilenet V2
MobileNet v2ЭјТчЪЧгЩgoogleЭХЖгдк2018ФъЬсГіЕФ,ЯрБШMobileNet V1Эј Тч,зМШЗТЪИќИп,ФЃаЭИќаЁЁЃ
ЭјТчжаЕФССЕу:
- Inverted Residuals(ЕЙВаВюНсЙЙ)
- Linear Bottlenecks
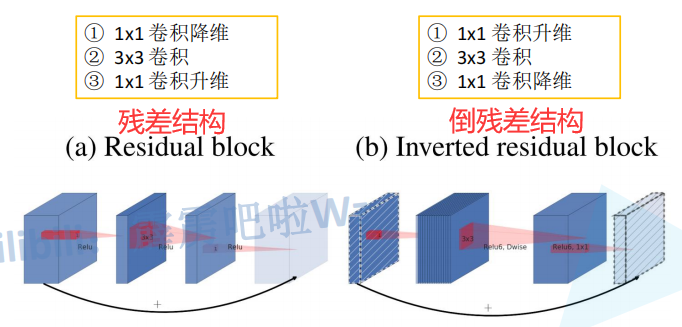
Residual blockЪЙгУReLuМЄЛюКЏЪ§,Inverted Residuals blockЪЙгУReLu6МЄЛюКЏЪ§ЁЃ
y = R e L U 6 ( x ) = m i n ( m a x ( x , 0 ) , 6 ) y = ReLU6(x) = min(max(x, 0), 6) y=ReLU6(x)=min(max(x,0),6)

зЂвт:
ЕБ stride=1 Чв ЪфШыЬиеїОиеѓshape = ЪфГіЬиеїОиеѓshapeЪБ ВХгаshortcutСЌНгЁЃ
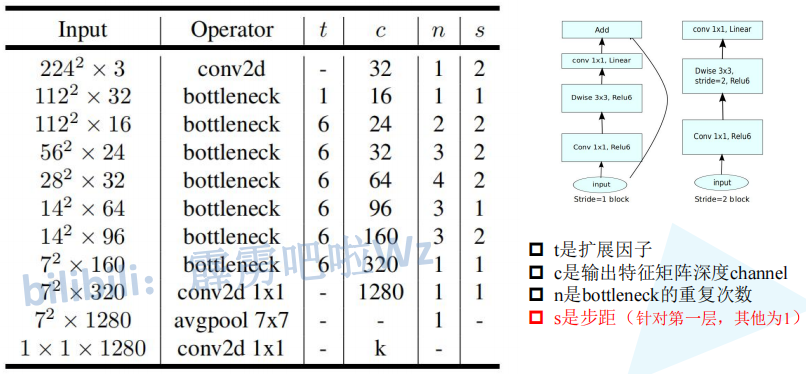
Mobilenet V2
ВЂЧвдкЕЙВаВюНсЙЙзюКѓвЛИі1ЁС1ЕФОэЛ§Ву,ЪЙгУСЫЯпадЕФМЄЛюКЏЪ§,вђЮЊReLu6МЄЛюКЏЪ§ЖдгкЕЭЮЌЬиеїаХЯЂдьГЩДѓСПЫ№ЪЇ,ЖјЖдИпЮЌЬиеїаХЯЂЫ№ЪЇКмаЁЁЃ
?
1.3 Mobilenet V3
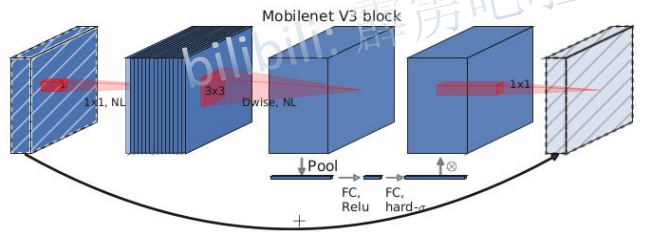
Mobilenet V3
?ЭјТчжаЕФССЕу:
- ИќаТСЫ block(bneck)
- МгШы SE ФЃПщ (зЂвтСІЛњжЦ):вЛИіГиЛЏСНИіШЋСЌНг,ЯъЧщЧыМћЯТЮФSELetВПЗж~
- ИќаТСЫМЄЛюКЏЪ§,ЪЙгУ h ? s w i s h [ x ] = x ? R e L U 6 ( x + 3 ) 6 h-swish[x]=x ЁЄ\frac{ReLU6(x+3)}{6} h?swish[x]=x?6ReLU6(x+3)?
- ЪЙгУ NAS ЫбЫїВЮЪ§
- жиаТЩшМЦКФЪБВуНсЙЙ
- МѕЩйЕквЛИіОэЛ§ВуЕФОэЛ§КЫИіЪ§(32->16)
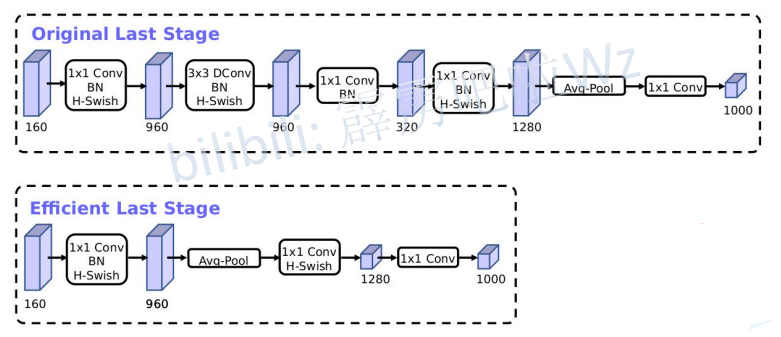
- ОЋМђLast Stage
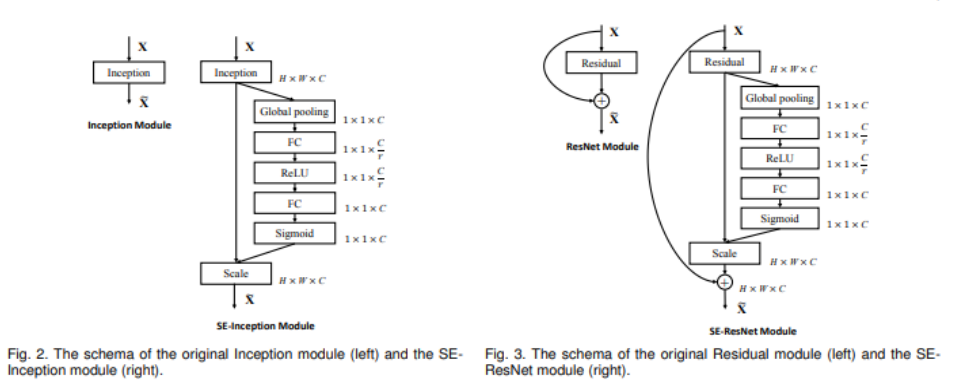
2 SENet
2.1 ЪВУДЪЧзЂвтСІЛњжЦ?
змЕФРДЫЕ,зЂвтСІЛњжЦФмЙЛСщЛюЕФВЖзНШЋОжаХЯЂКЭОжВПаХЯЂжЎМфЕФСЊЯЕЁЃЫќЕФФПЕФОЭЪЧШУФЃаЭЛёЕУашвЊжиЕуЙизЂЕФФПБъЧјгђ,ВЂЖдИУВПЗжЭЖШыИќДѓЕФШЈжи,ЭЛГіЯджјгагУЬиеї,вжжЦКЭКіТдЮоЙиЬиеїЁЃ
?
2.2 злЪі
ЪЧЪєгк ЭЈЕРгђ (ИФБфЕФЪЧchannel) ЕФзЂвтСІЛњжЦ~
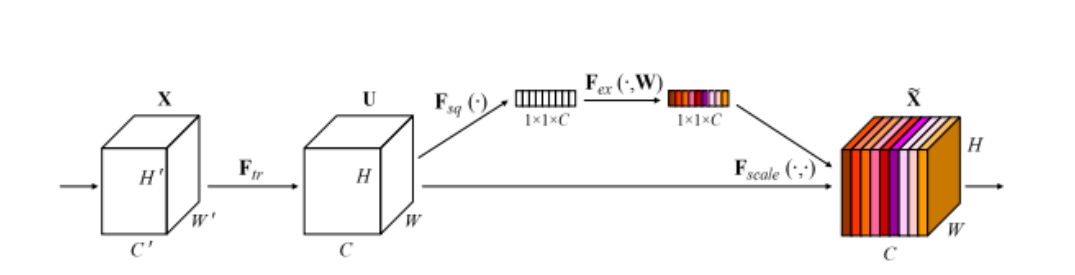
вЛИіФПЕФ: ЕУЕНвЛИіШЈжиОиеѓ(КЫаФ),ЖдЬиеїНјаажиЙЙ
СНИіживЊВйзї: Squeeze КЭ Excitation
ЫФВНзп: TransformationЁЂSqueeze ЁЂExcitationЁЂScale
(ЫќЪЧвЛИіПЩвдгУРДКтСПЭЈЕРживЊадЕФЪ§жЕ,ЩЯЭМжагУВЛЭЌбеЩЋеЙЪО)
?
2.3 Й§ГЬ
2.3.1 ЕквЛВН TransformationгГЩф
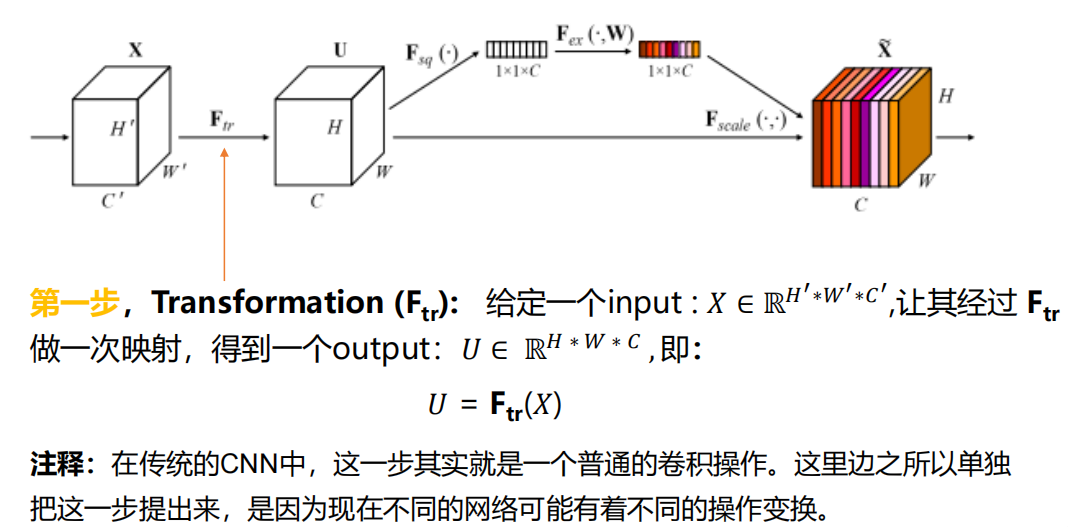
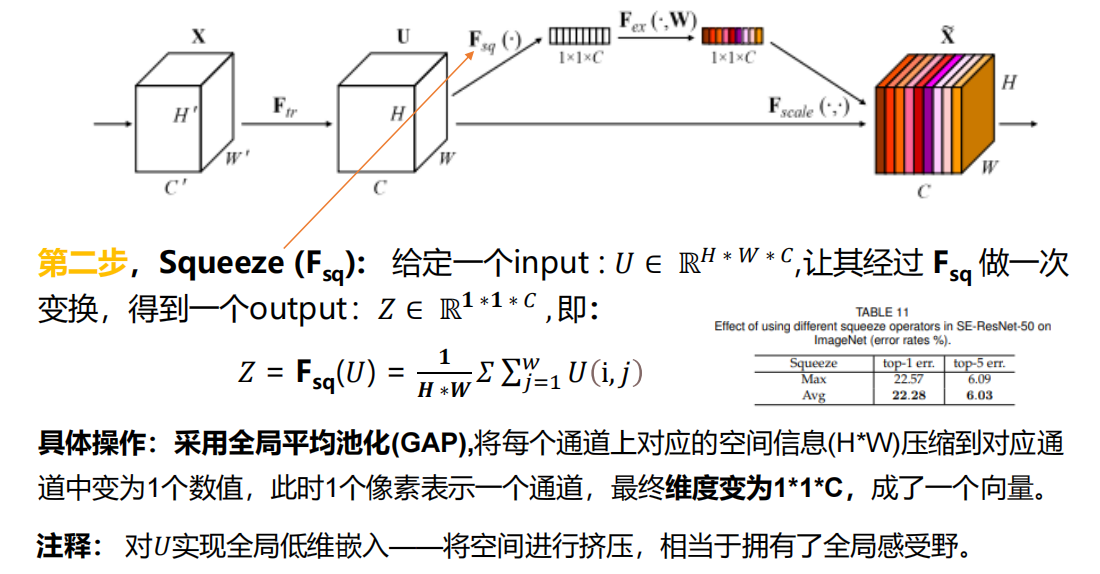
2.3.2 ЕкЖўВН Squeeze бЙЫѕ
ШЋОжЦНОљГиЛЏ:ЮЌЖШгЩ
H
ЁС
W
ЁС
C
H\times W\times C
HЁСWЁСC ЁЊЁЊ>
1
ЁС
1
ЁС
C
1\times 1\times C
1ЁС1ЁСC
2.3.3 ЕкШ§ВН Excitation
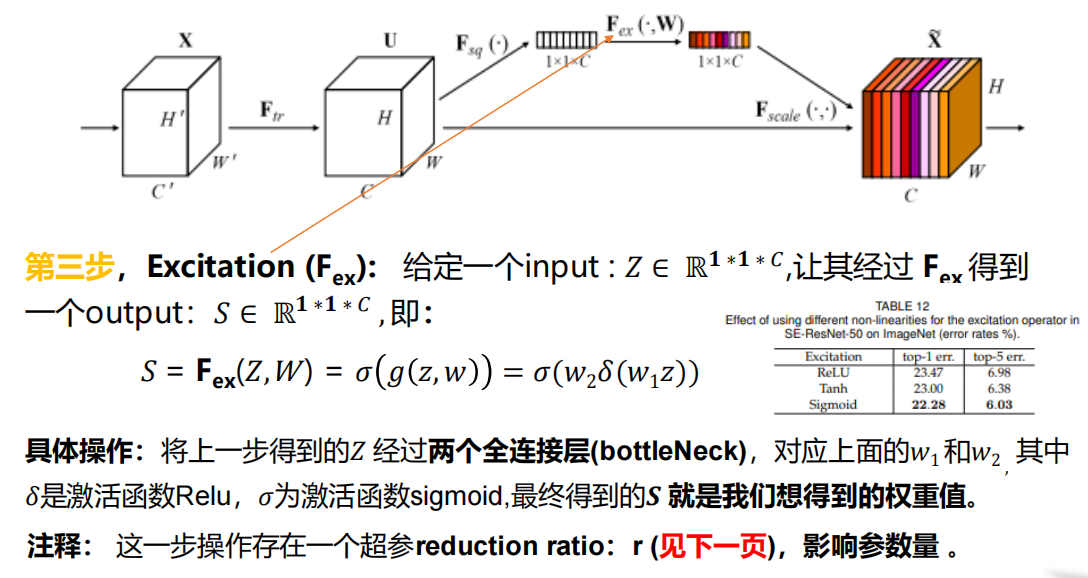
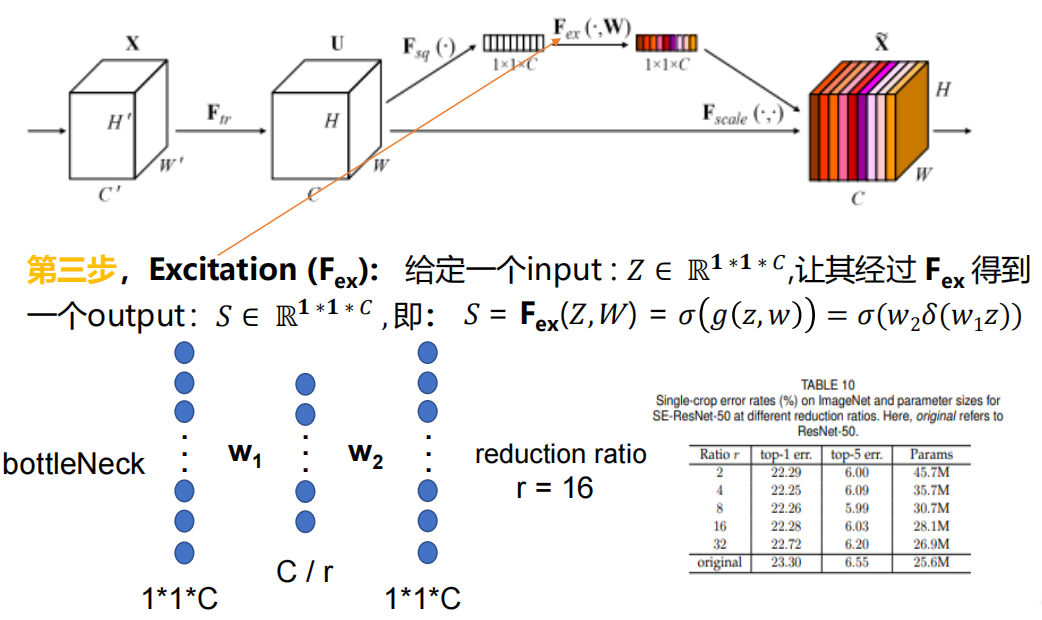
w1:ЕквЛИіШЋСЌНгВу
w2:ЕкЖўИіШЋСЌНгВу
ЮЊСЫНкЪЁВЮЪ§,ЪЙгУrШЅЫЅМѕвЛЯТЩёОдЊЕФИіЪ§,ОЪЕбщЗЂЯжЗЂЯж r=16 ЬиБ№КУ
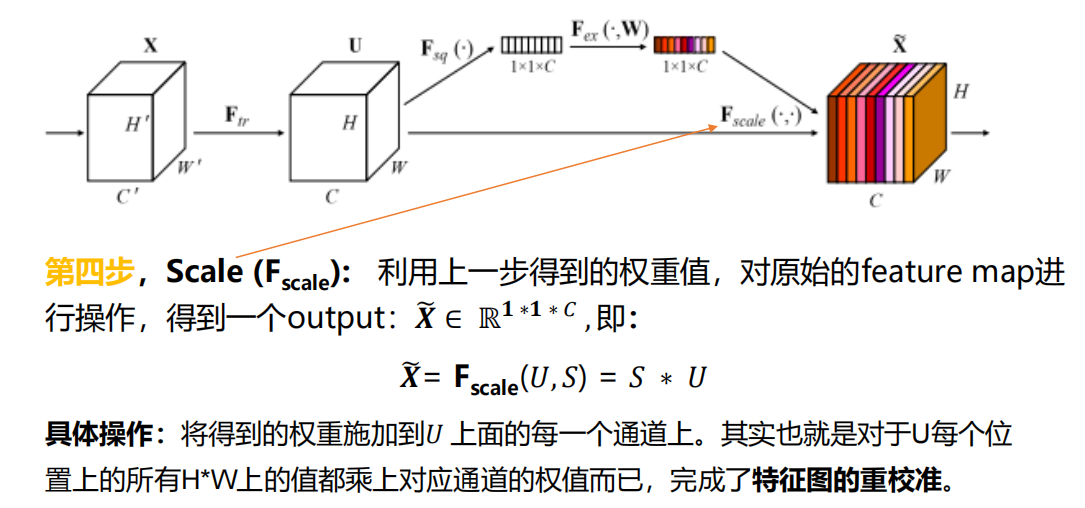
2.3.4 ЕкЫФВН Scale
X
~
\widetilde{X}
X
ОЭЪЧзюжеЕУЕНЕФФФЖљживЊФФЖљВЛживЊЕФЬиеїЭМСЫ~
?
2.4 гІгУ
БОФЃПщЕФЛљБОддђЪЧВЛИФБфдРДCNNНсЙЙ,зіЕНМДВхМДгУ
2.5 ДњТы
ЭъећДњТыМћБЪМЧБО:colabДњТы-ResNet18-SENet

# ЖЈвхBasicBlock
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# shortcutЕФЪфГіЮЌЖШКЭЪфГіВЛвЛжТЪБ,гУ1*1ЕФОэЛ§РДЦЅХфЮЌЖШ
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels))
# дк excitation ЕФСНИіШЋСЌНг
self.fc1 = nn.Conv2d(out_channels, out_channels//16, kernel_size=1)
self.fc2 = nn.Conv2d(out_channels//16, out_channels, kernel_size=1)
#ЖЈвхЭјТчНсЙЙ---ЭјТчНсЙЙВЮПМСЫResNet18
def forward(self, x):
#feature mapНјааСНДЮОэЛ§ЕУЕНбЙЫѕ
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# Squeeze Вйзї:global average pooling
w = F.avg_pool2d(out, out.size(2))
# Excitation Вйзї: fc(бЙЫѕЕН16ЗжжЎвЛ)--Relu--fc(МЄЕНжЎЧАЮЌЖШ)--Sigmoid(БЃжЄЪфГіЮЊ 0 жС 1 жЎМф)
w = F.relu(self.fc1(w))
w = F.sigmoid(self.fc2(w))
# жиБъЖЈВйзї: НЋОэЛ§КѓЕФfeature mapгы w ЯрГЫ
out = out * w
# МгЩЯЧГВуЬиеїЭМ
out += self.shortcut(x)
#R eluМЄЛю
out = F.relu(out)
return out
# ЖЈвхЭјТчНсЙЙ
class SENet(nn.Module):
def __init__(self):
super(SENet, self).__init__()
#зюжеЗжРрЕФжжРрЪ§
self.num_classes = 10
#ЪфШыЩюЖШЮЊ64
self.in_channels = 64
#ЯШЪЙгУ64*3*3ЕФОэЛ§КЫ(1)in_channel:ЭМЦЌRGBШ§ЭЈЕР(2)out_channel:filterзщЪ§(3)filterДѓаЁkernel_size:3x3
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
#ОэЛ§ВуЕФЩшжУ,BasicBlock
#2,2,2,2ЮЊУПИіОэЛ§ВуашвЊЕФblockПщЪ§
self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1)
self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2)
self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2)
self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2)
#ШЋСЌНг---зюжеЗжРрЪ§ЮЊ10
self.linear = nn.Linear(512, self.num_classes)
#ЪЕЯжУПвЛВуОэЛ§
#blocksЮЊДѓlayerжаЕФВаВюПщЪ§
#ЖЈвхУПвЛИіlayerгаМИИіВаВюПщ,resnet18ЪЧ2,2,2,2
def _make_layer(self, block, out_channels, blocks, stride):
strides = [stride] + [1]*(blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
#ЖЈвхЭјТчНсЙЙ
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
Accuracy of the network on the 10000 test images: 85.26 %
Part2 ДњТызївЕ
дФЖСТлЮФЁЖHybridSN: Exploring 3-DЈC2-DCNN Feature Hierarchy for Hyperspectral Image ClassificationЁЗ,ЭЈЙ§HybridSNЛьКЯЭјТчЪЕЯжИпЙтЦзЭМЯёЗжРр,ЦНЬЈЪЙгУGoogle ColabЦНЬЈЁЃ
3 ИпЙтЦзЭМЯёЗжРр HybridSNЛьКЯЭјТч
3.1 ЯрЙижЊЪЖ
3.1.1 ИпЙтЦзЭМЯё
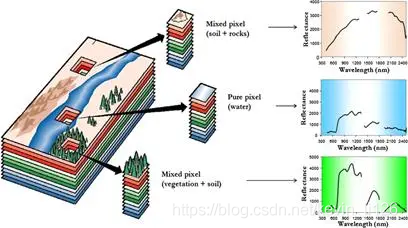
- МДАќКЌЙтЦзаХЯЂЬиБ№ГЄЕФЭМЯё(АќКЌКьЭтЯпЁЂзЯЭтЯпЕШВЛПЩМћЙтЙтЦз),БШШч:ЦеЭЈееЦЌжЛгаШ§ИіЭЈЕР,МДRGB ЁЊЁЊ КьЁЂТЬЁЂРЖЁЃЪ§ОнРраЭЪЧвЛИі m ? n ? 3 m ? n ? 3 m?n?3ЕФОиеѓ,ЖјИпЙтЦзЭМЯёдђЪЧ M ? N ? B M ? N ? B M?N?B (BЪЧЙтЦзЕФВуЪ§:3ВуRGB + ЦфЫћЙтЦзВуЁ)ЁЃ
- ЙтЦзЭМЯёЪЧвЛИіСЂЬхЕФШ§ЮЌНсЙЙ,xЁЂyБэЪОЖўЮЌЦНУцЯёЫиаХЯЂзјБъжс,ЕкШ§ЮЌЪЧВЈГЄаХЯЂзјБъжсЁЃ
3.1.2 ИпЙтЦзЭМЯёГЩЯёдРэ
ПеМфжаЕФвЛЮЌаХЯЂЭЈЙ§ОЕЭЗКЭЯСЗьКѓ,ВЛЭЌВЈГЄЕФЙтАДееВЛЭЌГЬЖШЕФЭфЩЂДЋВЅ,вЛЮЌЭМЯёЩЯЕФУПИіЕу,дйЭЈЙ§ЙтеЄНјаабмЩфЗжЙт,аЮГЩвЛИіЦзДј,ееЩфЕНЬНВтЦїЩЯ,ЬНВтЦїЩЯЕФУПИіЯёЫиЮЛжУКЭЧПЖШБэеїЙтЦзКЭЧПЖШЁЃ
3.2 ОэЛ§ЭјТчДІРэИпЙтЦзЭМЯёЪБЕФММЪѕЮЪЬт
- 2-D-CNNЮоЗЈДІРэЪ§ОнЕФЕкШ§ЮЌЖШЁЊЁЊЙтЦзаХЯЂ(ЧАСНЮЌЖШЪЧЭМЯёБОЩэЕФxжсКЭyжс)ЁЃ
- ДЋЭГЕФ2D-ОэЛ§ДІРэВЛКУетжжШ§ЮЌЕФИпЙтЦзЭМЯё;
- ШєжЛЪЙгУ3D-ОэЛ§,ЫфШЛПЩвдЬсШЁЕкШ§ЮЌЁЊЁЊЙтЦзЮЌЖШЕФЬиеї,ФмЭЌЪБНјааПеМфКЭПеМфЬиеїБэЪО,ЕЋЪ§ОнМЦЫуСПЬиБ№Дѓ,ЧвЖдЬиеїЕФБэЯжФмСІБШНЯВю(вђЮЊаэЖрЙтЦзДјЩЯЕФЮЦРэЪЧЯрЫЦЕФ)
Ыљвд,зїепзіСЫвдЯТЙЄзї:
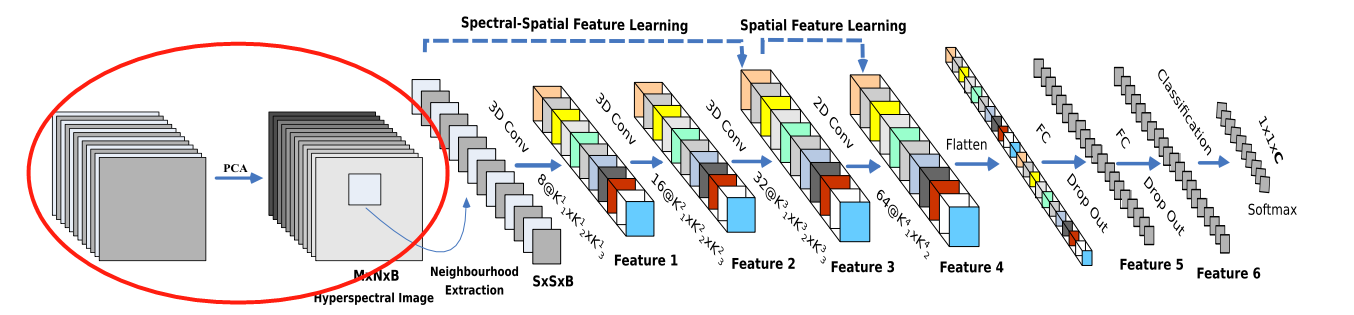
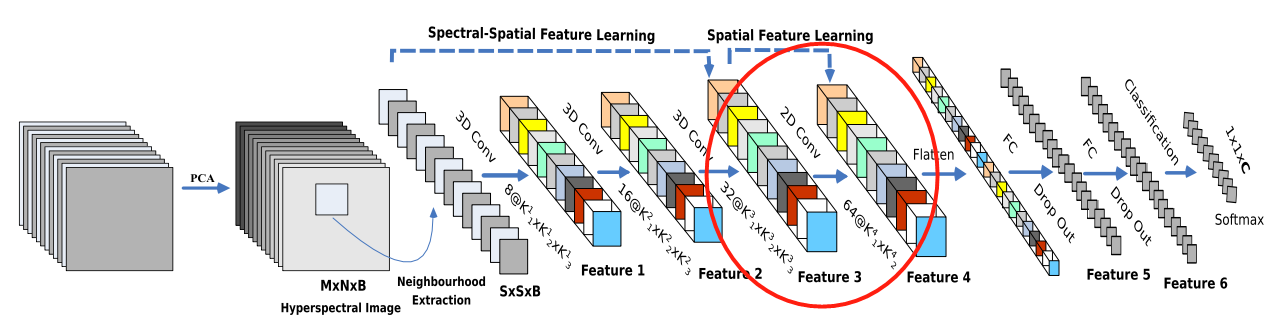
- ЬсГіHybirdSNФЃаЭ(ШЋГЦЪЧHybrid SpectralNetЁЊЁЊЛьКЯСЫ2DЁЂ3DОэЛ§ЕФЙтЦзЭјТч):
НЋПеМфЙтЦзКЭЙтЦзЕФЛЅВЙаХЯЂЗжБ№вд3D-CNNКЭ2D-CNNВузщКЯЕНСЫвЛЦ№,ДгЖјГфЗжРћгУСЫЙтЦзКЭПеМфЬиеїЭМ,РДПЫЗўвдЩЯШБЕуЁЃ - HybirdSNФЃаЭБШ3D-CNNФЃаЭЕФМЦЫуаЇТЪИќИпЁЃдкаЁЕФбЕСЗЪ§ОнЩЯвВЯдЪОГіСЫгХдНЕФадФмЁЃ
3.3 ЪЕЯжВНжш
3.3.1 PCAжїГЩЗжЗжЮі
- ЪзЯШ,ЖдгкЪфШыЕФИпЙтЦзЭМЯё,НјааСЫжїГЩЗжЗжЮі(PCA),МѕЩйСЫЕкШ§ЮЌЪ§ОнЕФвЛаЉЙтЦзВЈЖЮ,жЛБЃСєСЫЖдЪЖБ№ЮяЬхживЊЕФПеМфаХЯЂ;
- НЋЪ§ОнЕФЪфШыЙцЗЖЛЏЮЊ M ? N ? B M ? N ? B M?N?B;
3.3.2 НЋЪ§ОнЛЎЗжЮЊШ§ЮЌаЁПщ
- ЫцКѓНЋЪ§ОнЛЎЗжЮЊжиЕўЕФШ§ЮЌаЁПщ
S
?
S
?
B
S ? S ? B
S?S?B(ЁАКёЖШЁБВЛБф),аЁПщЕФlabelгЩжааФЯёЫиЕФlabelОіЖЈ.
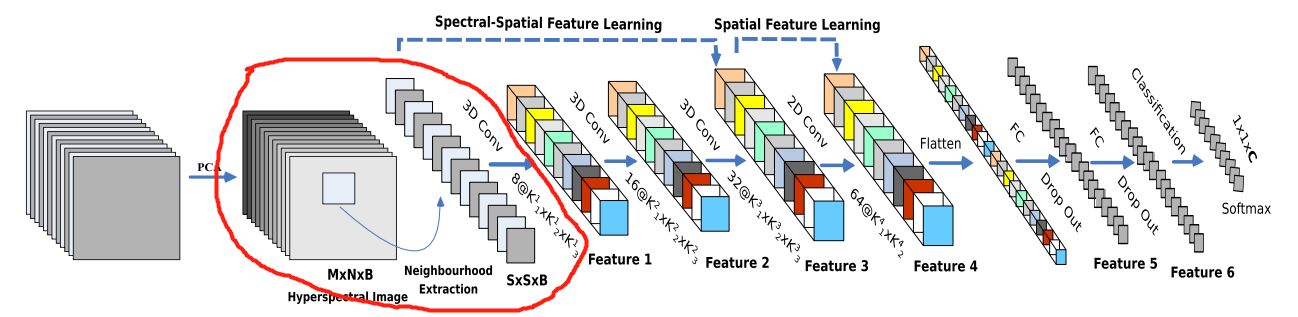
3.3.3 Ш§ЮЌОэЛ§ЬсШЁЙтЦзЮЌЖШЬиеї
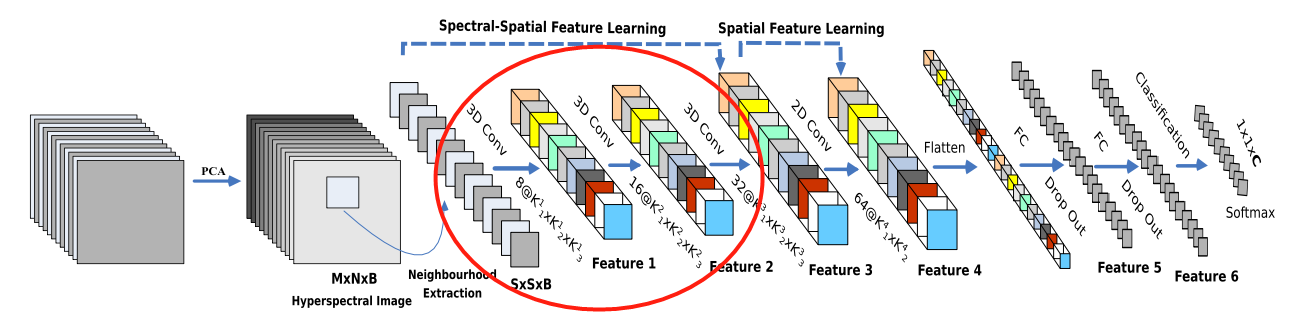
- жЎКѓ,ЪЙгУ3D-ОэЛ§ЛёШЁЙтЦзЮЌЖШКЭЭМЯёМфЕФЬиеї;
- Ш§ДЮШ§ЮЌОэЛ§жа,ОэЛ§КЫЕФГпДчвРДЮЮЊ:
- 8ЁС3ЁС3ЁС7ЁС1(8ЪЧЫћздМКЩшМЦЕФОэЛ§КЫЕФИіЪ§,3 ? 3 ? 7 ЪЧвЛИіШ§ЮЌОэЛ§КЫЕФДѓаЁ,1ЪЧвђЮЊвЛЙВжЛга1зщЭМ,ЫљвддйГЫИі1)
- 16ЁС3ЁС3ЁС5ЁС8
- 32ЁС3ЁС3ЁС3ЁС16ЁЃ
- дкШ§ЮЌОэЛ§жа,ЩњГЩЕк i ВуЕк j Иі feature map дкПеМфЮЛжУ(x, y, z)ЕФМЄЛюжЕ,МЧЮЊ v i , j x , y , z v_{i , j}^{x,y,z} vi,jx,y,z?,ЙЋЪН2ШчЯТЭМЫљЪО:
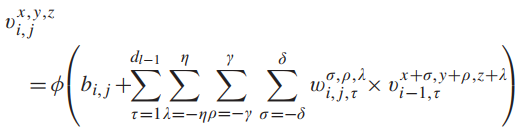
3.3.4 ЖўЮЌОэЛ§ОэЭМЯёЬиеї
- ЪЙгУ2D-ОэЛ§ЛёШЁЭМЯёБОЩэЕФЬиеї;
- ЖўЮЌОэЛ§жа,ОэЛ§КЫЕФГпДчЮЊ64ЁС3ЁС3ЁС576(576ЮЊЖўЮЌЪфШыЬиеїЭМЕФЪ§СП)
- дкЖўЮЌОэЛ§жа,Ек i ВуЕк j Иіfeature mapдкПеМфЮЛжУ (x, y) ДІЕФжЕ,МЧЮЊ
v
i
,
j
x
,
y
,
z
v_{i , j}^{x,y,z}
vi,jx,y,z?,ЦфЩњГЩЙЋЪН1ШчЯТ:
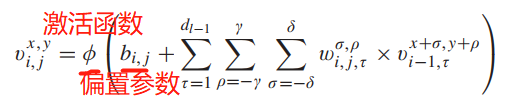
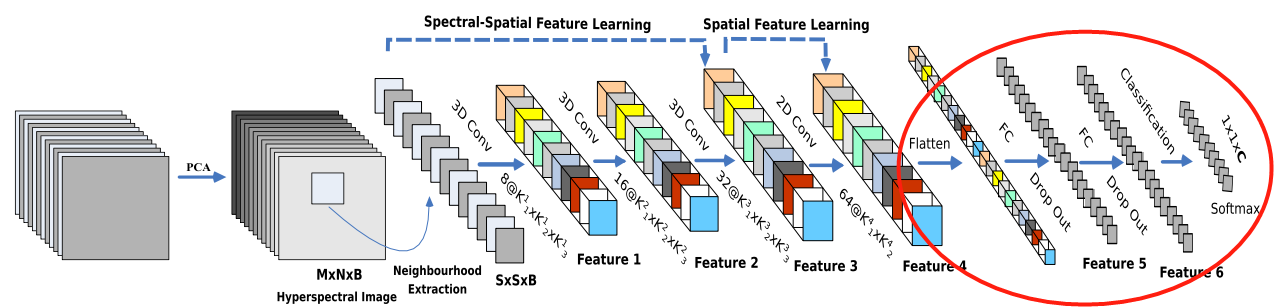
3.3.5 ШЋСЌНгЪфГі
- НгЯТРДЪЧвЛИі flatten Вйзї(ЮЊСЫЪфГіИјШЋСЌНгВу,ЫљвдБиаыЪЧвЛЬѕЖўЮЌЪ§Он),БфЮЊ 18496 ЮЌЕФЯђСП;
- НгЯТРДвРДЮЮЊ256,128НкЕуЕФШЋСЌНгВу,ЖМЪЙгУБШР§ЮЊ0.4ЕФ Dropout(ОЭЪЧШгЕє40%ЕФЪ§Он,ЗРжЙФЃаЭЙ§ФтКЯ);
- зюКѓЪфГіЮЊ 16 ИіНкЕу,ЪЧЗжРрЕФжжЪ§
4 дФЖСДњТы
Ш§ЮЌОэЛ§ВПЗж:
- conv1:(1, 30, 25, 25), 8Иі 7x3x3 ЕФОэЛ§КЫ ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16Иі 5x3x3 ЕФОэЛ§КЫ ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32Иі 3x3x3 ЕФОэЛ§КЫ ==>(32, 18, 19, 19)
НгЯТРДвЊНјааЖўЮЌОэЛ§,вђДЫАбЧАУцЕФ 32*18 reshape вЛЯТ,ЕУЕН (576, 19, 19)
ЖўЮЌОэЛ§:(576, 19, 19) 64Иі 3x3 ЕФОэЛ§КЫ,ЕУЕН (64, 17, 17)
НгЯТРДЪЧвЛИі flatten Вйзї,БфЮЊ 18496 ЮЌЕФЯђСП,
НгЯТРДвРДЮЮЊ256,128НкЕуЕФШЋСЌНгВу,ЖМЪЙгУБШР§ЮЊ0.4ЕФ Dropout,
зюКѓЪфГіЮЊ 16 ИіНкЕу,ЪЧзюжеЕФЗжРрРрБ№Ъ§ЁЃ
ДњТыСДНг ВЂВЙШЋЭјТч,ЭјТчНсЙЙШчЯТ:
class_num = 16
class HybridSN(nn.Module):
def __init__(self, class_num=16):
super(HybridSN, self).__init__()
# conv1:(1, 30, 25, 25), 8Иі 7x3x3 ЕФОэЛ§КЫ ==>(8, 24, 23, 23)
self.conv1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(7, 3, 3))
# conv2:(8, 24, 23, 23), 16Иі 5x3x3 ЕФОэЛ§КЫ ==>(16, 20, 21, 21)
self.conv2 = nn.Conv3d(8, 16, (5, 3, 3))
# conv3:(16, 20, 21, 21),32Иі 3x3x3 ЕФОэЛ§КЫ ==>(32, 18, 19, 19)
self.conv3 = nn.Conv3d(16, 32, (3, 3, 3))
# conv3_2d (576, 19, 19),64Иі 3x3 ЕФОэЛ§КЫ ==>(64, 17, 17)
self.conv3_2d = nn.Conv2d(576, 64, 3)
# ШЋСЌНгВу(256ИіНкЕу)
self.fc1 = nn.Linear(18496, 256)
# ШЋСЌНгВу(128ИіНкЕу)
self.fc2 = nn.Linear(256, 128)
# fc1,fc2ЪЙгУБШР§ЮЊ0.4ЕФDropout
self.dropout = nn.Dropout(0.4)
self.soft = nn.Softmax(dim=1)
# зюжеЪфГіВу(16ИіНкЕу)
self.fc3 = nn.Linear(128, class_num)
# МгШыBNЙщвЛЛЏЪ§Он
self.bn1 = nn.BatchNorm3d(8)
self.bn2 = nn.BatchNorm3d(16)
self.bn3 = nn.BatchNorm3d(32)
self.bn4 = nn.BatchNorm2d(64)
# ЖЈвхМЄЛюКЏЪ§
self.relu = nn.ReLU()
def forward(self, x):
# ЕквЛДЮ,УЛМгbn
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.relu(self.conv3(out))
# НгЯТРДвЊНјааЖўЮЌОэЛ§,вђДЫАбЧАУцЕФ 32*18 reshape вЛЯТ,ЕУЕН (576, 19, 19)
out = out.reshape(out.shape[0], -1, 19, 19)
out = self.relu(self.conv3_2d(out))
# flatten Вйзї,БфЮЊ 18496 ЮЌЕФЯђСП
out = out.view(out.size(0), -1)
out = self.dropout(self.fc1(out))
out = self.dropout(self.fc2(out))
out = self.relu(self.dropout(self.fc2(out)))
out = self.relu(self.fc3(out))
return out
# ЫцЛњЪфШы,ВтЪдЭјТчНсЙЙЪЧЗёЭЈ
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
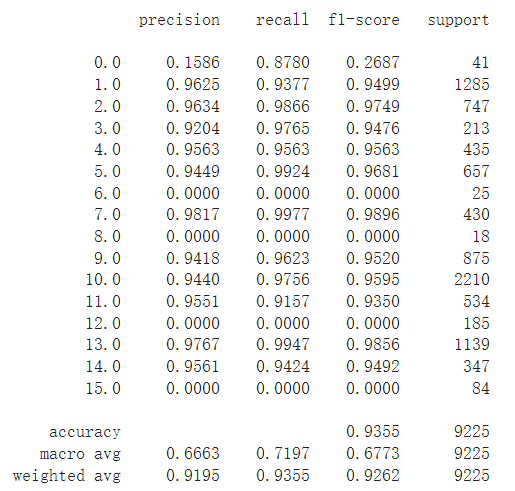
ЕквЛДЮбЕСЗ,зМШЗТЪКмЕЭ23%,УЛЪВУДЗжРраЇЙћ,ПЩФмФФРяаДДэСЫ
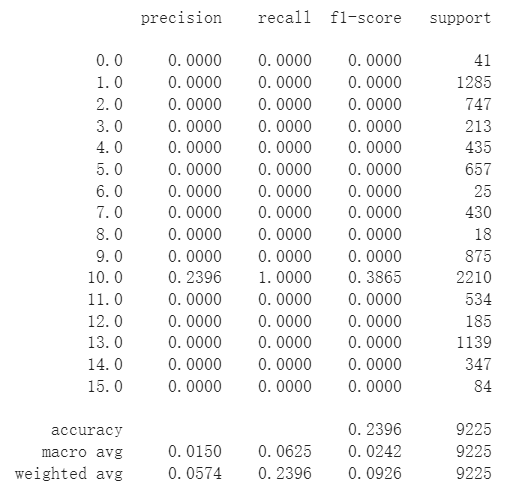
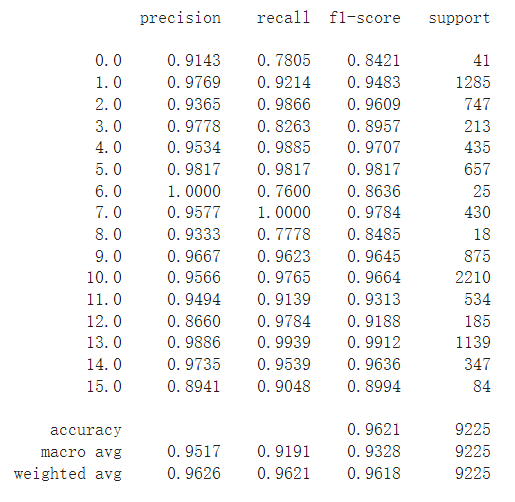
ШЅЕєsoftMaxКЏЪ§,зМШЗТЪЪЧ93%
ЕкЖўДЮбЕСЗ,АбsoftMaxКЏЪ§ИФГЩLogSoftmaxКЏЪ§,зМШЗТЪДяЕН96%

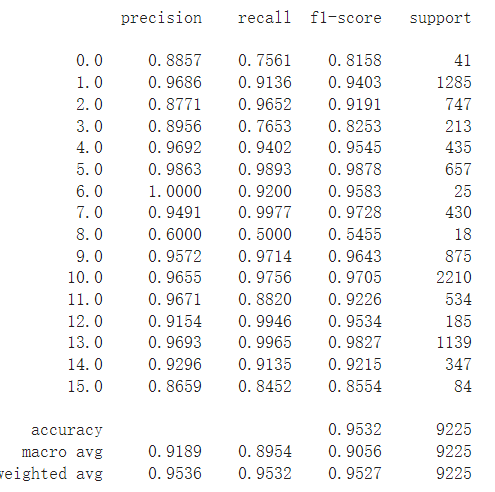
зюКѓ,МгЩЯBN,ИаОѕЗжРрЕФаЇЙћКмвЛАу,ЭМЯёаЇЙћВЛЬЋКУ
5 ЫМПМЬт
5.1 ЫМПМ3DОэЛ§КЭ2DОэЛ§ЕФЧјБ№

3DОэЛ§ЪЙгУЕФЪ§ОнКЭ2DОэЛ§зюДѓЕФВЛЭЌОЭдкгкЪ§ОнЕФЪБађадЁЃ3DОэЛ§КЭ2DОэЛ§ЯрБШ,ЖрСЫвЛИіЩюЖШЭЈЕР,етИіЩюЖШЭЈЕРПЩвдЛёШЁИќЖрЕФаХЯЂ,БШШчЪгЦЕЕФСЌајжЁКЭСЂЬхЭМЯёЕФЗжИюЕШЁЃ3DОэЛ§жаЕФЪ§ОнЭЈГЃЪЧЪгЦЕЕФЖрИіжЁЛђепЪЧвЛеХвНбЇЭМЯёЕФЖрИіЗжИюЭМЯёЖбЕўдквЛЦ№,етбљУПжЁЭМЯёжЎМфОЭгаЪБМфЛђепПеМфЩЯЕФСЊЯЕЁЃ
5.2 бЕСЗЭјТч,ШЛКѓЖрВтЪдМИДЮ,ЛсЗЂЯжУПДЮЗжРрЕФНсЙћЖМВЛвЛбљ,етЪЧЮЊЪВУД?
дкбЕСЗФЃЪНжа,ВЩгУСЫdropout,ЪЙЕУЭјТчдкбЕСЗЕФЪБКђ,ПЙдыЩљФмСІИќЧП,ЗРжЙЙ§ФтКЯЁЃЕЋЪЧдкВтЪдФЃаЭЕФЪБКђ,ЫцЛњЕФdrop,ОЭЛсЕМжТзюжеНсЙћЕФВЛвЛжТЁЃ
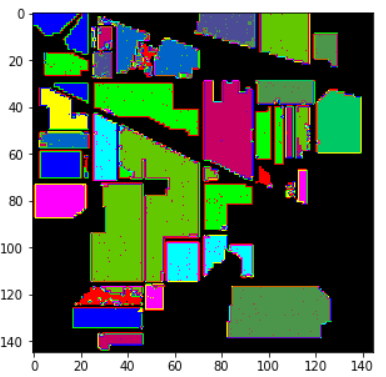
5.3 ШчКЮНјвЛВНЬсЩ§ИпЙтЦзЭМЯёЕФЗжРрадФм
1ЁЂдкЭјТчЕФзюКѓМгвЛИіLogSoftMaxКЏЪ§(етИіЗНЗЈЪЧДгЦфЫћВЉжїЕФВЉЮФРяПДЕНЕФ),ГЂЪдКѓЗЂЯжзМШЗТЪЕФШЗгаУїЯдЕФЬсИп~
2ЁЂПЩвдГЂЪдМгШызЂвтСІЛњжЦФЃПщЁЃБШШчМгШыЩЯУцЕФSENetФЃПщ,ШУФЃаЭЛёЕУашвЊжиЕуЙизЂЕФФПБъЧјгђ,ВЂЖдИУВПЗжЭЖШыИќДѓЕФШЈжи,ЭЛГіЯджјгагУЬиеї,ДгЖјЪЙЭјТчИќМггаВржиЕФбЇЯА,вдДЫЬсИпЭјТчЕФбЇЯАФмСІЁЃ