文章目录
基本信息
期刊:天津大学学报(自然科学与工程技术版)
IF = 1.152
出版时间:2020年8月
摘要
(1)中文手写体识别困境
中文字符数目繁多、相似性强、字体种类繁多、书写随意、缺乏统一规范等原因,一直是计算机视觉领域中一个具有挑战性的问题。
(2)本文方法
改进经典LeNet-5模型,提出LeNet-Ⅱ模型。
Step1: 利用改进的Inception模块和空洞卷积,设计了一种并行的双路卷积神经网络结构;双路的作用:两路分支可分别提取手写中文图像中不同尺度的特征,获得多个尺度的特征图像。
Step2: 通过对其进行特征融合,可以达到丰富特征图像多样性、提高识别准确率的目的。
Step3: 最后经过全连接层进行分类。
(2)结果
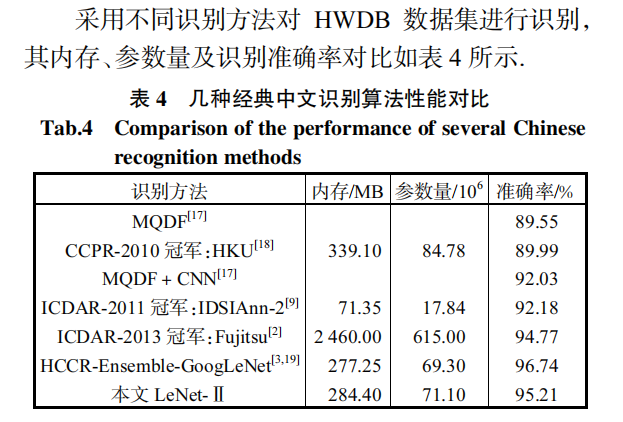
在中文数据集CASIA-HWDB1.1上准确率达到95.21%,高与经典LeNet-5和其他传统算法。
同时,在4幅找人手写的中文文本中的平均识别率也达到了97.30%。
0. 引言
手写中文识别分为:联机手写中文识别 和 脱机手写中文识别。与前者相比,后者没有可利用的笔画时序信息,识别难度更大,准确率更低。本文研究的后者。
1. 经典LeNet-5模型
LeNet-5 模型是一种常用的卷积神经网络,被广泛用于手写体数字识别领域。其模型结构:
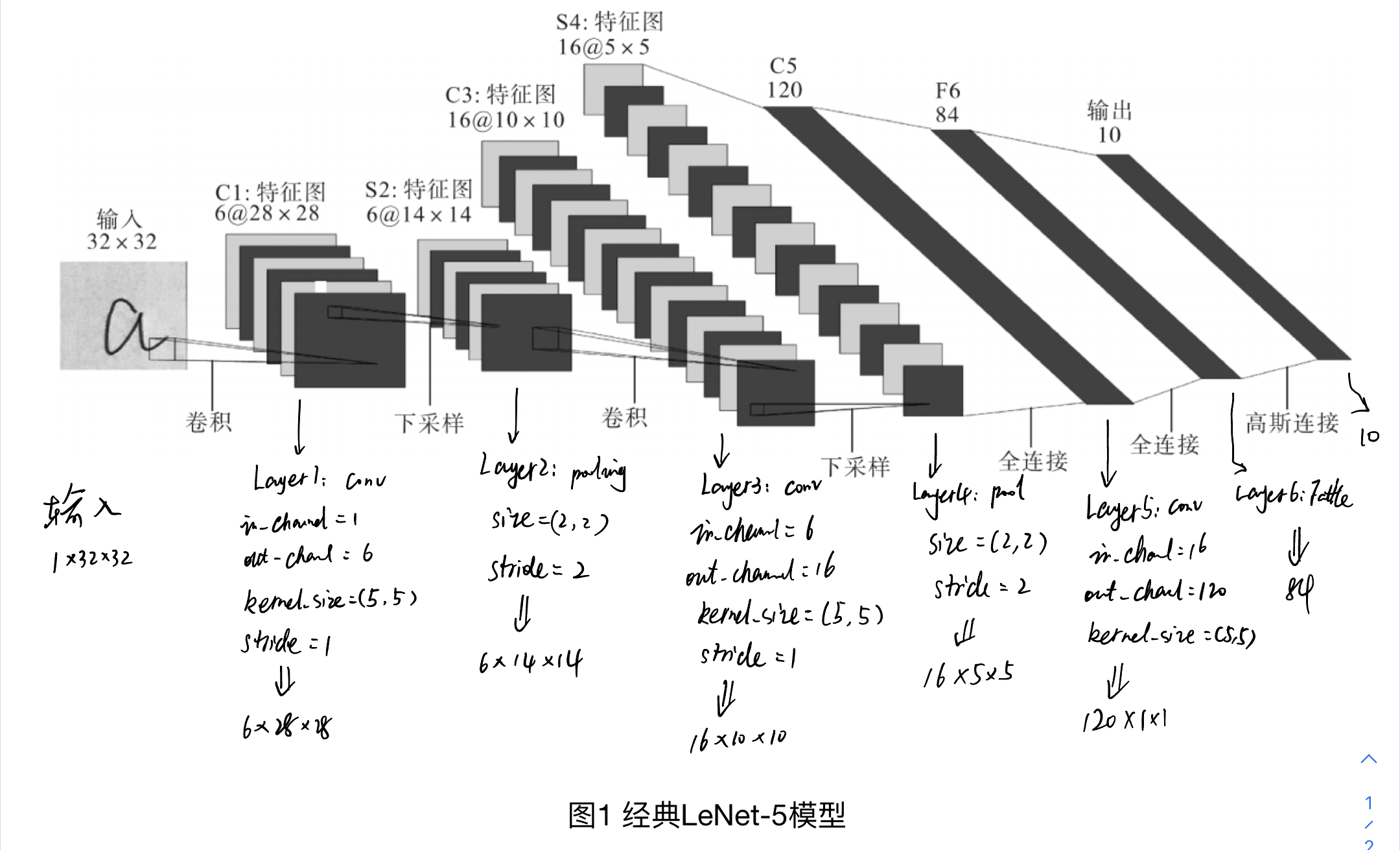
1.1 对LeNet-5模型的分析
传统LeNet-5模型适用于手写体数字识别,但对手写中文数字识别的准确率较低。
原因如下:
(1)常用中文字符高达3755个,分类种类过多;
(2)手写中文比数字复杂,特征更多;
(3)LeNet-5 模型输入默认为32*32,不满足要求;
(4)LeNet-5 模型仅有 3 层卷积层,卷积层和池化层采用的卷积核个数都较少,是一个简单的串行网络,不足以提取足够多的特征;
2. LeNet-Ⅱ 模型(即本文模型)
模型结构图:
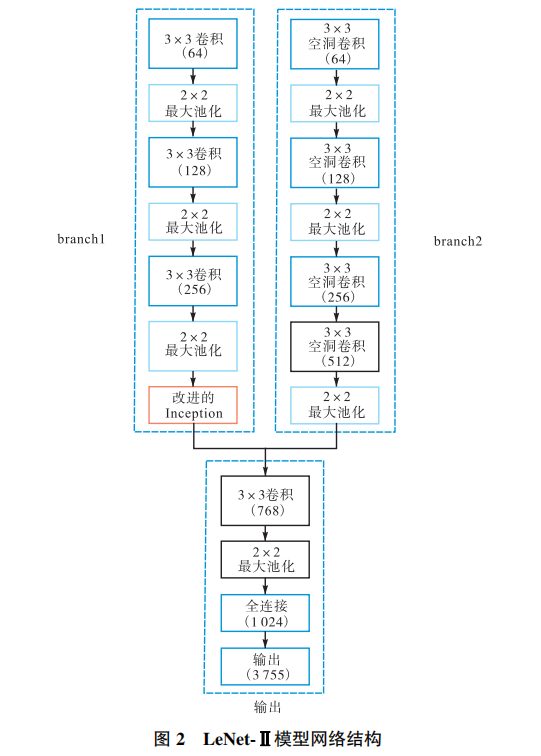
2.1 模型说明
(1)经典 LeNet-5 模型是一个简单的串行网络,提取汉字特征图像的多样性不足;为此,本文设计了一个并行的双路卷积神经网络,以获得不同尺度的特征图像,增强网络的适应力.
(2)Inception 模块有助于解决由于增加神经网络的层数和宽度所导致的过拟合、梯度弥散、计算复杂度增大等问题.本文重新设计的Inception模块,结构如下:
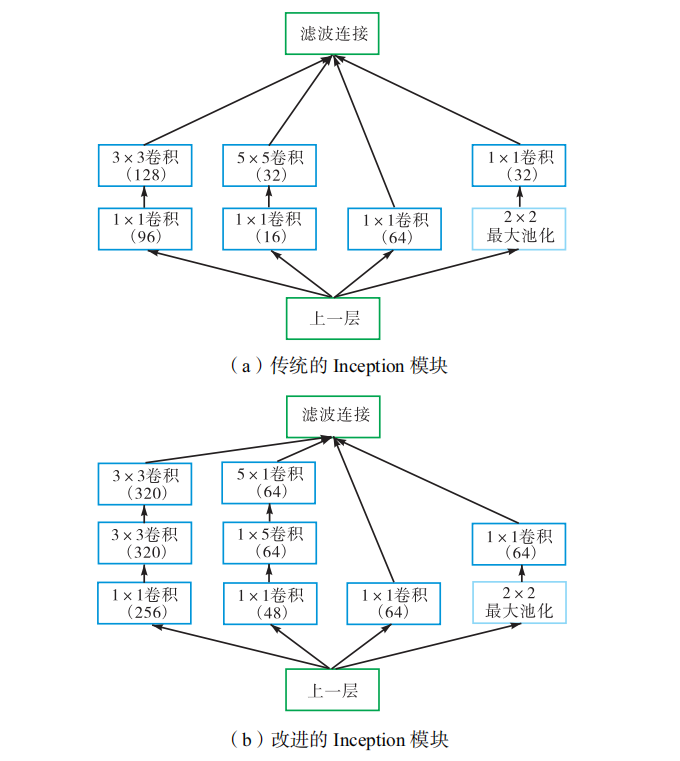
Inception模块的作用:
Inception 模块有助于解决由于增加神经网络的层数和宽度所导致的过拟合、梯度弥散、计算复杂度增大等问题。
其改进的地方如下:
1)重新分配了Inception模块的4个通道数,适当增加33卷积核的通道数,减少11卷积核的通道数,原来为4:1:2:1,修改为5:1:1:1。
其作用如下:
避免特征表示瓶颈,造成信息损失
2)在3*3卷积层后又添加了一个卷积层。
其作用:
增加3*3卷积层这一通道的表达能力
3)将55的二维卷积核分解层15和5*1两个一维卷积。
其作用:
降低计算成本,减轻过拟合,并利用非堆成的卷积结构来获得丰富的空间特征。
(3)经典LeNet-5模型是一个简单的串行模型,提取汉字特征图像的多样性不足。
故本文设计了一个“并行的双路卷积网络”,以获得不同尺度的特征图像,增强网络的适应能力。
其中,branch1主要由3*3卷积形成,branch2需要用更大的卷积核,以更好的学习汉字图像边缘的形状特征。
但是55或77的卷积核,会极大地增加参数个数和计算复杂度,所以选用空洞卷积来实现不增加参数个数和计算复杂度的情况下,提升模型感知范围。空洞卷积详见博文深入理解空洞卷积
3. 实验结果及分析
3.1 中文字符集
手写中文数据集选用中国科学院自动化研究所(CASIA)模式识别国家重点实验室公布的脱机手写样本数据库(HWDB)中的 CASIA-HWDB1.1 数据集。
其官网:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
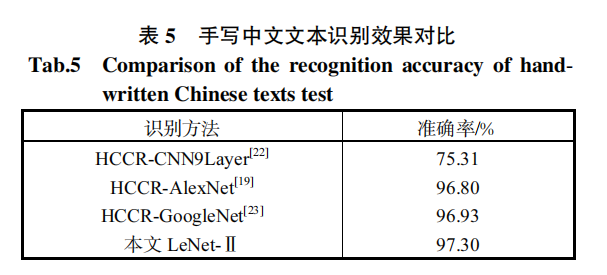
3.2 结果对比


3.3 自己手写数据集的结果
效果达到了97.30%。