目录
一、赛题介绍
赛题以竞品分析为背景,通过数据的聚类,为汽车提供聚类分类。对于指定的车型,可以通过聚类分析找到其竞品车型。通过这道赛题,鼓励学习者利用车型数据,进行车型画像的分析,为产品的定位,竞品分析提供数据决策。
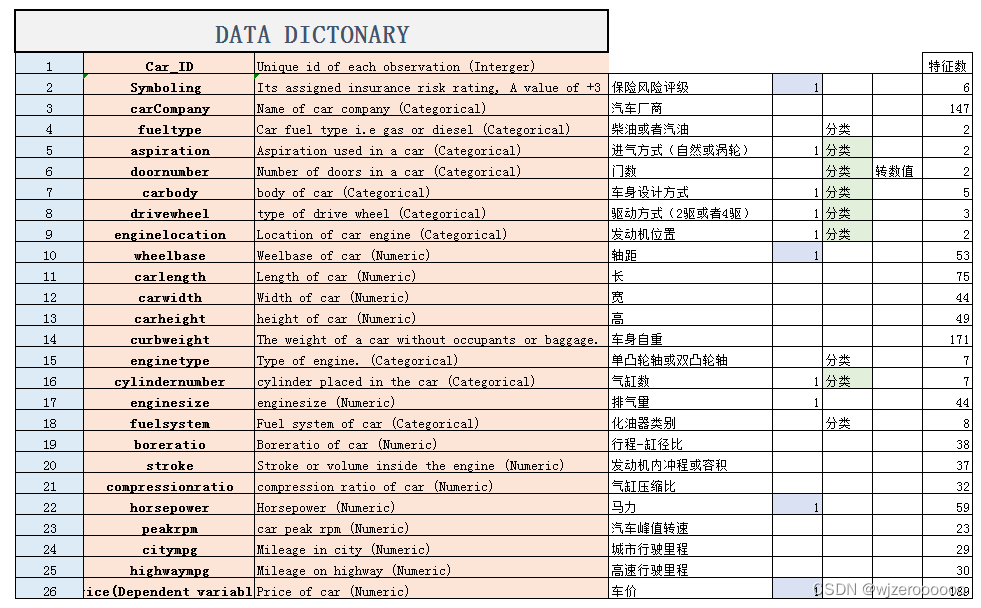
二、数据描述性统计
2.1. 查看缺失值、重复值
import pandas as pd
df=pd.read_csv("/car_price.csv")
print(df.isnull().any(axis=1).sum())
df[df.duplicated()==True]
# 无缺失值及重复值2.2. 查看数据统计信息
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns) # 数值变量
Ca_feature = list(df.select_dtypes(include=['object']).columns)
print(len(Nu_feature),Nu_feature)
print(len(Ca_feature),Ca_feature)
df.describe().T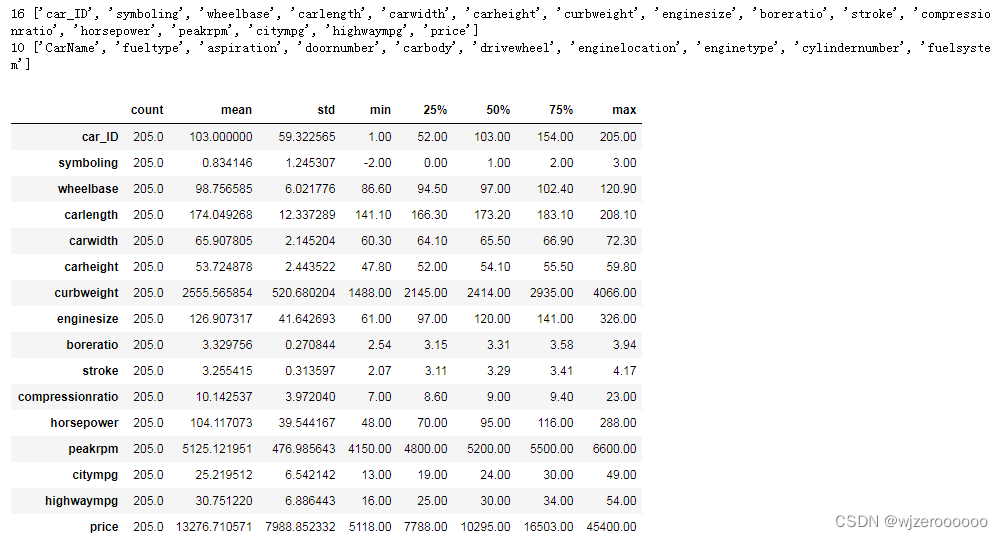
205个样本,16个数值变量, 10个分类变量
2.3. 查看数据分布
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(30,25))
i=1
for col in Nu_feature:
ax=plt.subplot(4,4,i)
ax=sns.distplot(df[col],color='red',hist=False)
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
i+=1
plt.show()
# 大部分的数据都服从正态分布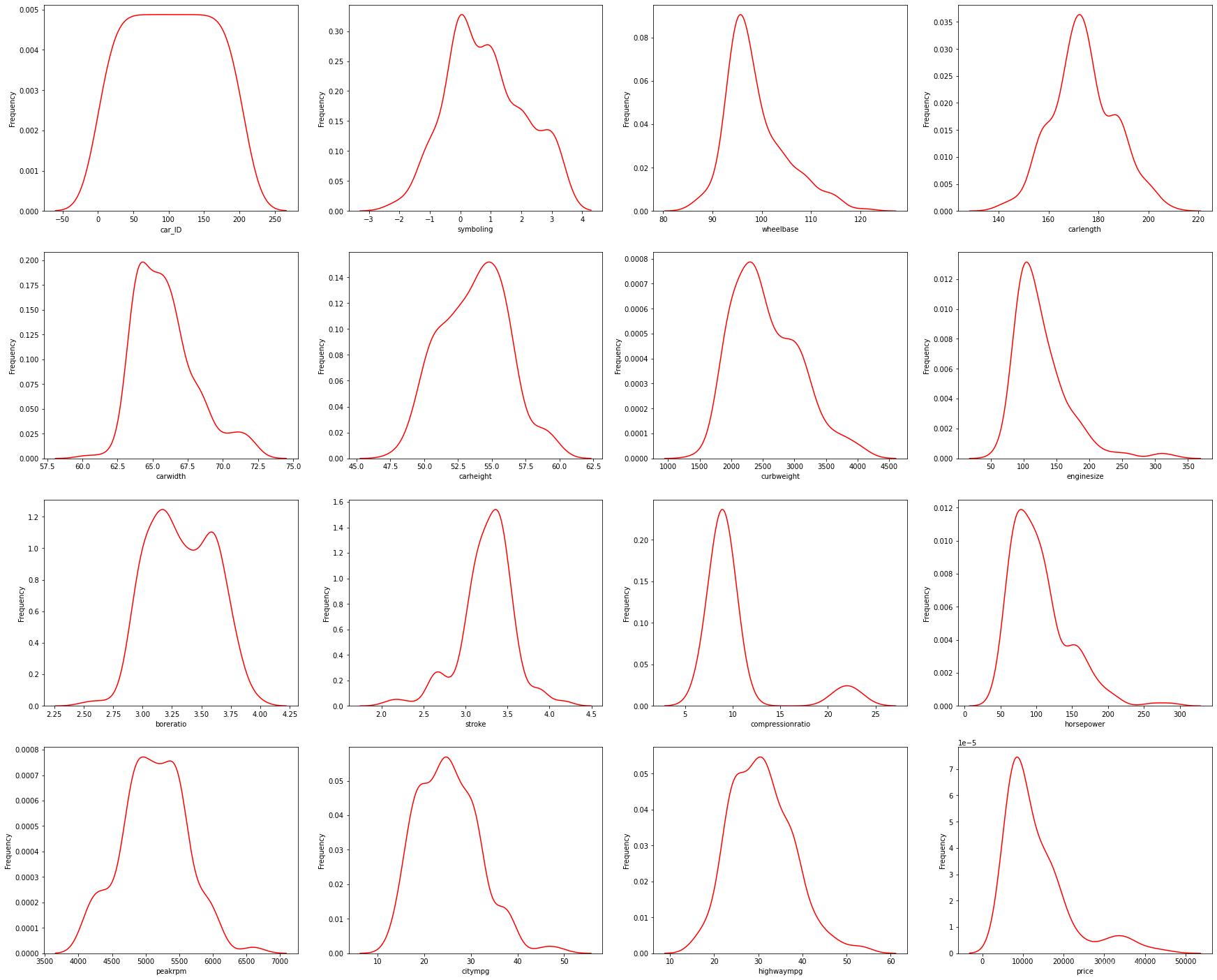
?2.4. 查看异常值
import matplotlib.pyplot as plt
plt.figure(figsize=(30,30))
j=1
for col in Nu_feature:
ax=plt.subplot(4,4,j)
ax=sns.boxplot(data=df[col])
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
j+=1
plt.show()
# 图中呈现的异常值是受样本数量的影响,对比原始数据,都非真正异常数据,比如豪车的价格及相关配置在图中可能就是异常值,但其实正常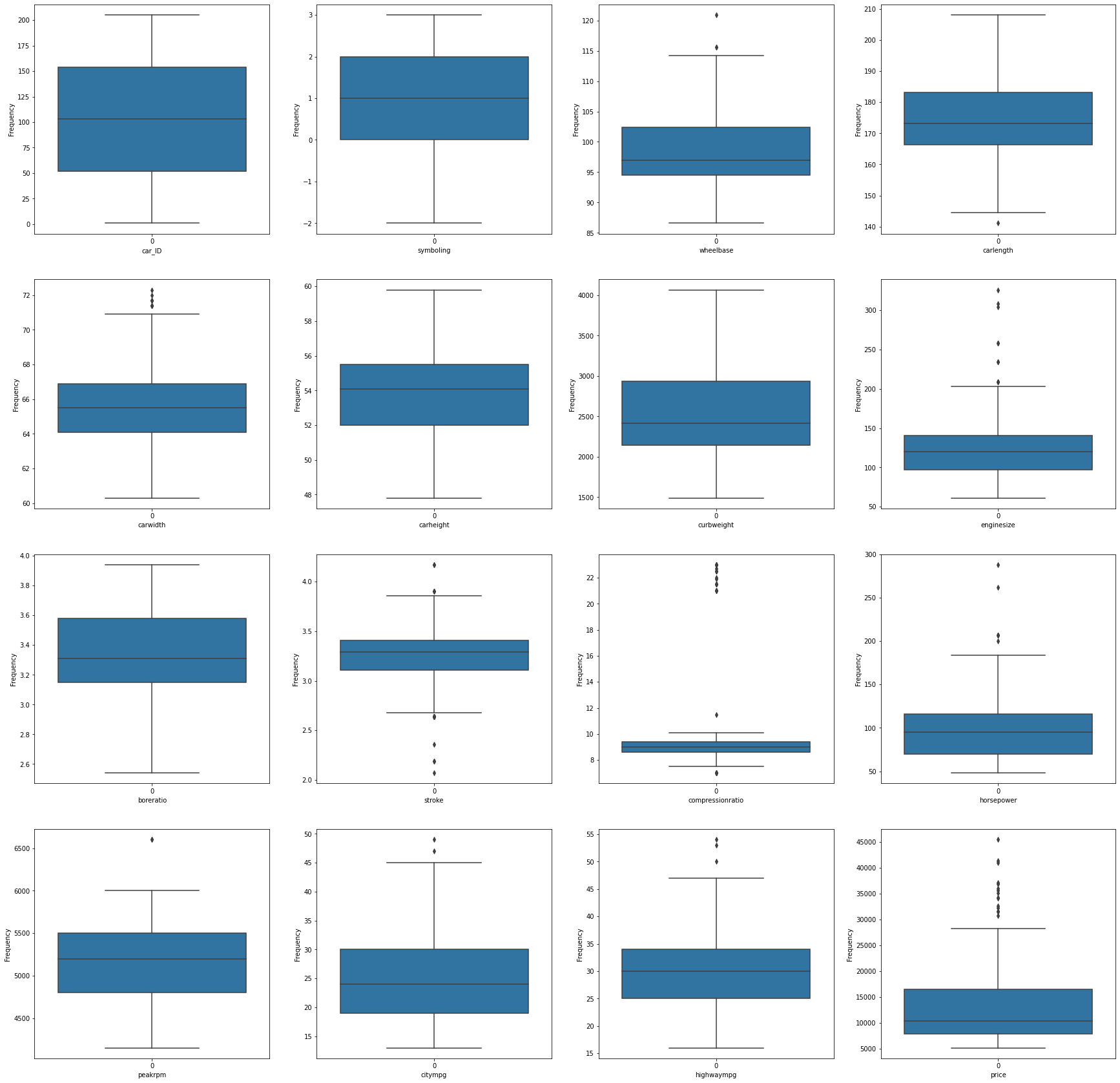
2.5. 数据相关性
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")
# 轴距与排量的相关性高于马力,所以选择马力
# 风险评级与车价有负相关关系,个人理解,以盗抢为例,四川是全国盗抢车最高的地区,高价格车辆的防盗措施肯定要由于低价格的,
# 然后高价格的车辆一般不会随意停放路边,有的甚至住在别墅,安保措施较好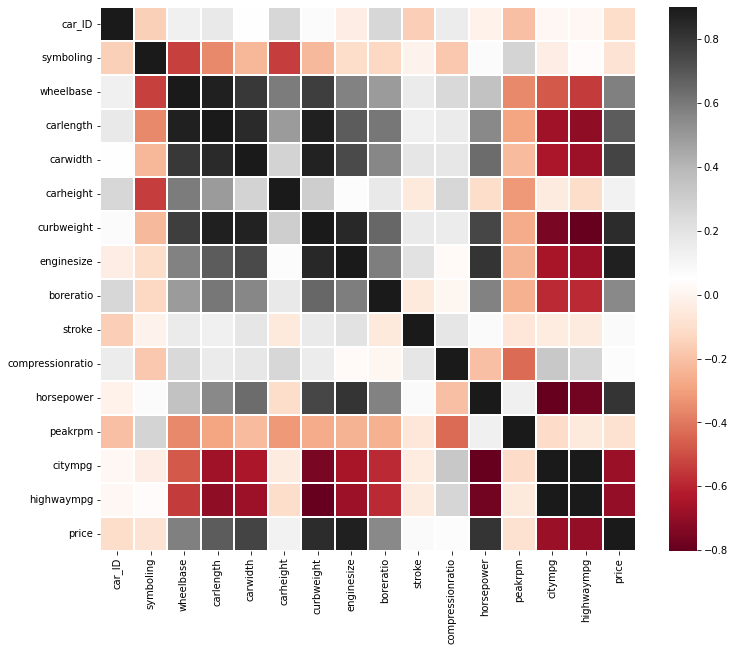
三、特征处理
df['doornumber'] = df['doornumber'].map({'two':2,'four':4})
# 将车门数转化为数字,用于后面的建模四、数据建模
4.1 变量选取及处理
import numpy as np
from sklearn.metrics import silhouette_score # 导入轮廓系数指标
from sklearn.cluster import KMeans # KMeans模块
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder,StandardScaler
df1=df[['symboling','wheelbase','horsepower','price','doornumber']]
cols=['carbody','drivewheel']
# 分类变量转化
model_ohe = OneHotEncoder(sparse=False)
ohe_matrix = model_ohe.fit_transform(df[cols])
# 数值标准化
model_scaler = MinMaxScaler()
data_scaled = model_scaler.fit_transform(df1)
# 合并所有维度
X = np.hstack((data_scaled, ohe_matrix))
X.shape
# 分类变量选取个人看法:选取区分度较大的变量,不要选用太多的分类变量(效果会变差,特征区分度也不明显),可以结合业务经验选取。4.2 确定聚类数(肘部法及平均轮廓系数)
sse = []
scores = []
silhouette_int = -1 # 初始化的平均轮廓系数阀值
for n_clusters in range(2, 8):
model_kmeans = KMeans(n_clusters=n_clusters) # 建立聚类模型对象
labels_tmp = model_kmeans.fit_predict(X) # 训练聚类模型
silhouette_tmp = silhouette_score(X, labels_tmp) # 得到每个K下的平均轮廓系数
if silhouette_tmp > silhouette_int: # 如果平均轮廓系数更高
best_k = n_clusters # 保存K将最好的K存储下来
silhouette_int = silhouette_tmp # 保存平均轮廓得分
best_kmeans = model_kmeans # 保存模型实例对象
cluster_labels_k = labels_tmp # 保存聚类标签
scores.append(silhouette_tmp)
sse.append(model_kmeans.inertia_) #整体簇内平方和
x = [i for i in range(2,8)]
plt.figure(figsize=(10, 5))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(1,2,1)
plt.title('KMeans聚类SSE系数')
plt.xlabel('聚类数')
plt.plot(x, sse, 'o-')
plt.subplot(1,2,2)
plt.title('KMeans聚类平均轮廓系数')
plt.xlabel('聚类数')
for i in range(2, 8):
plt.text(i, scores[i-2], (str(round(scores[i-2], 2))))
plt.plot(x, scores, 'o-')
# 拐点出现在5,轮廓系数0.53,效果还可以,初步决定分为5类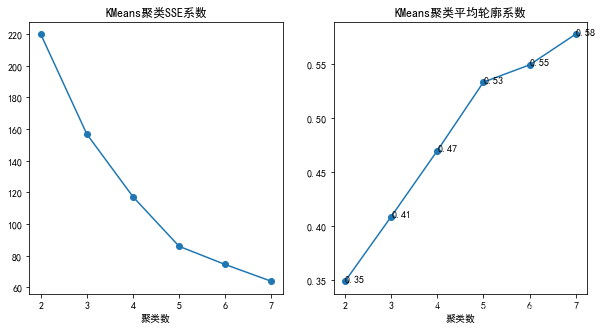
4.3? 模型训练
model_kmean = KMeans(n_clusters=5)
cluster_labels_ = model_kmean.fit_predict(X)
# 将类别结合原文件导出
cluster_labels = pd.DataFrame(cluster_labels_, columns=['clusters']) # 获得训练集下的标签信息
merge_data = pd.concat((df, cluster_labels), axis=1)
merge_data.to_csv('/merge_data.csv')导出文件五、特征可视化?
5.1? 雷达图
# 将相关特征合并
cols1=['carbody','drivewheel','clusters']
df2=pd.read_csv("/merge_data.csv",usecols=cols1)
merge_data1=pd.concat((df1, df2), axis=1)
merge_data1
clustering_count = pd.DataFrame(merge_data['car_ID'].groupby(merge_data['clusters']).count()).T.rename({'car_ID': 'counts'}) # 计算每个聚类类别的样本量
clustering_ratio = (clustering_count / len(merge_data)).round(2).rename({'counts': 'percentage'}) # 计算每个聚类类别的样本量占比
# 统计各类别下的特征信息
cluster_features = [] # 空列表,用于存储最终合并后的所有特征信息
for line in range(5): # 读取每个类索引
label_data = merge_data1[merge_data1['clusters'] == line] # 获得特定类的数据
part1_data = label_data.iloc[:, 0:5] # 获得数值型数据特征
part1_desc = part1_data.describe().round(3) # 得到数值型特征的描述性统计信息的均值
merge_data2 = part1_desc.iloc[1, 0:5] # 将clusters这一列去掉
part2_data = label_data.iloc[:, 5:-1] # 获得字符串型数据特征
part2_desc = part2_data.describe(include='all') # 获得分类变量特征的描述性统计信息,include='all'统计分类变量
merge_data3 = part2_desc.iloc[2, :] # 取分类变量的众数
merge_line = pd.concat((merge_data2, merge_data3), axis=0) # 将数值型和分类特征沿行合并
cluster_features.append(merge_line)
cluster_pd = pd.DataFrame(cluster_features).T
all_cluster_set = pd.concat((clustering_count, clustering_ratio, cluster_pd),axis=0) # 将每个聚类类别的所有信息合并
print(all_cluster_set)
num_sets = cluster_pd.iloc[:5, :].T.astype(np.float64) # 获取要绘图的数据
print(num_sets)
#每个类别下的特征就比较明显的展示出来了?
# 雷达图展示
model_scaler1=StandardScaler() # 相比MinMaxScaler归一化,可以更明确区分特征
num_sets_max_min = model_scaler1.fit_transform(num_sets) # 获得标准化后的数据
print(num_sets_max_min)
# part2 画布基本设置
fig = plt.figure(figsize=(8,8)) # 建立画布
ax = fig.add_subplot(111, polar=True) # 增加子网格,注意polar参数
labels = np.array(merge_data2.index) # 设置要展示的数据标签
cor_list = ['b', 'k', 'r', 'y', 'g', 'y', 'm', 'w','r','b'] # 定义不同类别的颜色
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False) # 计算各个区间的角度
angles = np.concatenate((angles, [angles[0]])) # 建立相同首尾字段以便于闭合
radar_labels = np.concatenate((labels, [labels[0]])) # 新版的matplotlib,标签要建立相同首尾字段以便于闭合
# part3 画雷达图
for i in range(len(num_sets)): # 循环每个类别
data_tmp = num_sets_max_min[i, :] # 获得对应类数据
data = np.concatenate((data_tmp, [data_tmp[0]])) # 建立相同首尾字段以便于闭合
ax.plot(angles, data, 'o-', c=cor_list[i], label=i) # 画线
ax.fill(angles, data,color=cor_list[i],alpha=0.25) # 填充背景
# part4 设置图像显示格式
ax.set_thetagrids(angles * 180 / np.pi, radar_labels, fontproperties="SimHei",fontsize=14) # 设置极坐标轴
ax.set_title("各类别特征对比", fontproperties="SimHei",fontsize=16) # 设置标题放置
ax.set_rlim(-2.5, 2) # 设置坐标轴尺度范围
plt.legend(loc=0) # 设置图例位置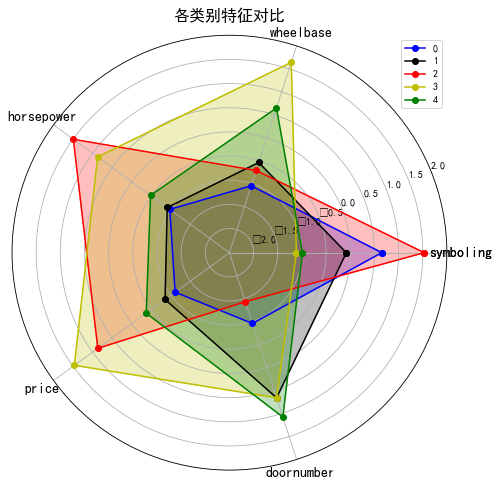
?上图看出:类别3的平均轴距最长、平均价格最高、风险评级最低,类别2的平均马力最高、风险评级最高,类别4以四门为主,类别0以两门为主。类别之间还是有一定的区分度,下面进一步将每个类别特征进行细分。
5.2? 饼图结合柱形图
# 读取分类好的数据
import pandas as pd
df=pd.read_csv("/merge_data.csv")
# 计算不同聚类类别的样本量和占比
label_count = df.groupby(['clusters'])['car_ID'].count() # 计算频数
label_count_rate = label_count/ df.shape[0] # 计算占比
kmeans_record_count = pd.concat((label_count,label_count_rate),axis=1)
kmeans_record_count.columns=['record_count','record_rate']
# 计算不同聚类类别数值型特征
kmeans_numeric_features = df.groupby(['clusters'])['price','wheelbase','horsepower'].mean()
# 计算不同聚类类别分类型特征
doornumber_list=[]
carbody_list = []
drivewheel_list = []
for each_label in range(5):
each_data = df[df['clusters']==each_label]
doornumber_list.append(each_data.groupby(['doornumber'])['car_ID'].count()/each_data.shape[0])
carbody_list.append(each_data.groupby(['carbody'])['car_ID'].count()/each_data.shape[0])
drivewheel_list.append(each_data.groupby(['drivewheel'])['car_ID'].count()/each_data.shape[0])
kmeans_doornumber = pd.DataFrame(doornumber_list)
kmeans_carbody = pd.DataFrame(carbody_list)
kmeans_drivewheel = pd.DataFrame(drivewheel_list)
kmeans_string_features = pd.concat((kmeans_doornumber,kmeans_carbody,kmeans_drivewheel),axis=1)
kmeans_string_features.index = range(5) # 行索引为类别
kmeans_string_features=kmeans_string_features.fillna(0).round(2) # 空值部分填充为0
# 合并所有类别的分析结果
features_all = pd.concat((kmeans_record_count,kmeans_numeric_features,kmeans_string_features),axis=1)
features_all.rename(columns={2:'two',4:'four'},inplace=True)
print(features_all)
import matplotlib.pyplot as plt
import numpy as np
# part 1 全局配置
fig = plt.figure(figsize=(18, 14))
titles = ['RECORD_RATE','AVG_price','AVG_wheelbase','AVG_horsepower','doornumber','carbody','drivewheel'] # 共用标题
line_index,col_index = 5,7 # 定义网格数
ax_ids = np.arange(1,36).reshape(line_index,col_index) # 生成子网格索引值
# part 2 画出5个类别的占比
pie_fracs = features_all['record_rate'].tolist()
for ind in range(len(pie_fracs)):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,0][ind]) # ax_ids[:,0][ind]取出对应值的索引
init_labels = ['','','','',''] # 初始化空label标签,5个类别,所以是5个空值
init_labels[ind] = 'cluster_{0}'.format(ind) # 设置标签
init_colors = ['lightgray', 'lightgray', 'lightgray','lightgray','lightgray']
init_colors[ind] = 'g' # 设置目标面积区别颜色
ax.pie(x=pie_fracs, autopct='%3.0f %%',labels=init_labels,colors=init_colors)
ax.set_aspect('equal') # 设置饼图为圆形
if ind == 0:
ax.set_title(titles[0])
# part 3 画出AVG_price均值
avg_orders_label = 'AVG_price'
avg_orders_fraces = features_all['price']
for ind, frace in enumerate(avg_orders_fraces):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,1][ind])
ax.bar(x=range(5),height=[0,0,avg_orders_fraces[ind],0,0])# 画出柱形图
ax.set_ylim((0, max(avg_orders_fraces)*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[1])
# 设置每个柱形图的数值标签和x轴label
ax.text(1,frace+0.3,s='{:.0f}'.format(frace),ha='center',va='top')
# part 4 画出AVG_wheelbase均值
avg_money_label = 'AVG_wheelbase'
avg_money_fraces = features_all['wheelbase']
for ind, frace in enumerate(avg_money_fraces):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,2][ind])
ax.bar(x=range(5),height=[0,0,avg_money_fraces[ind],0,0])# 画出柱形图
ax.set_ylim((0, max(avg_money_fraces)*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[2])
# 设置每个柱形图的数值标签和x轴label
ax.text(1,frace+4,s='{:.0f}'.format(frace),ha='center',va='top')
# part 5 画出AVG_horsepower均值
avg_money_label = 'AVG_horsepower'
avg_money_fraces = features_all['horsepower']
for ind, frace in enumerate(avg_money_fraces):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,3][ind])
ax.bar(x=range(5),height=[0,0,avg_money_fraces[ind],0,0])# 画出柱形图
ax.set_ylim((0, max(avg_money_fraces)*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[3])
# 设置每个柱形图的数值标签和x轴label
ax.text(1,frace+4,s='{:.0f}'.format(frace),ha='center',va='top')
# part 6 画出车门数
num_labels = ['two','four']
x_ticket = [i for i in range(len(num_labels))]
num_data = features_all[num_labels]
ylim_max = np.max(np.max(num_data)) # 获取Y轴最大值
for ind,each_data in enumerate(num_data.values):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,4][ind])
ax.bar(x=x_ticket,height=each_data) # 画出柱形图
ax.set_ylim((0, ylim_max*1.2)) # 将图形高度提升
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[4])
# 设置每个柱形图的数值标签和x轴label
num_values = ['{:.1%}'.format(i) for i in each_data]
for i in range(len(x_ticket)):
ax.text(x_ticket[i],each_data[i]+0.1,s=num_values[i],ha='center',va='top') # 图形添加数值
ax.text(x_ticket[i],-0.15,s=num_labels[i],ha='center',va='bottom') # 底部添加标签
# part 7 画出车类型
carbody_labels = ['convertible', 'hardtop', 'hatchback' , 'sedan', 'wagon']
x_ticket = [i for i in range(len(carbody_labels))]
carbody_data = features_all[carbody_labels]
ylim_max = np.max(np.max(carbody_data)) # 获取Y轴最大值
for ind,each_data in enumerate(carbody_data.values):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,5][ind])
ax.bar(x=x_ticket,height=each_data) # 画出柱形图
ax.set_ylim((0, ylim_max*1.2)) # 将图形高度提升
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[5])
# 设置每个柱形图的数值标签和x轴label
carbody_values = ['{:.1%}'.format(i) for i in each_data]
for i in range(len(x_ticket)):
ax.text(x_ticket[i],each_data[i]+0.1,s=carbody_values[i],ha='center',va='top',fontsize=8)
ax.text(x_ticket[i],-0.3,s=carbody_labels[i],ha='center',va='bottom',fontsize=8,rotation=-45)
# part 8 画出驱动方式
drivewheel_labels = ['4wd','fwd','rwd']
x_ticket = [i for i in range(len(drivewheel_labels))]
drivewheel_data = features_all[drivewheel_labels]
ylim_max = np.max(np.max(drivewheel_data)) # 获取Y轴最大值
for ind,each_data in enumerate(drivewheel_data.values):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,6][ind])
ax.bar(x=x_ticket,height=each_data) # 画出柱形图
ax.set_ylim((0, ylim_max*1.2)) # 将图形高度提升
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[6])
# 设置每个柱形图的数值标签和x轴label
drivewheel_values = ['{:.1%}'.format(i) for i in each_data]
for i in range(len(x_ticket)):
ax.text(x_ticket[i],each_data[i]+0.1,s=drivewheel_values[i],ha='center',va='top') # 图形添加数值
ax.text(x_ticket[i],-0.2,s=drivewheel_labels[i],ha='center',va='bottom') # 底部添加标签
plt.tight_layout(pad=0.8) #设置默认的间距
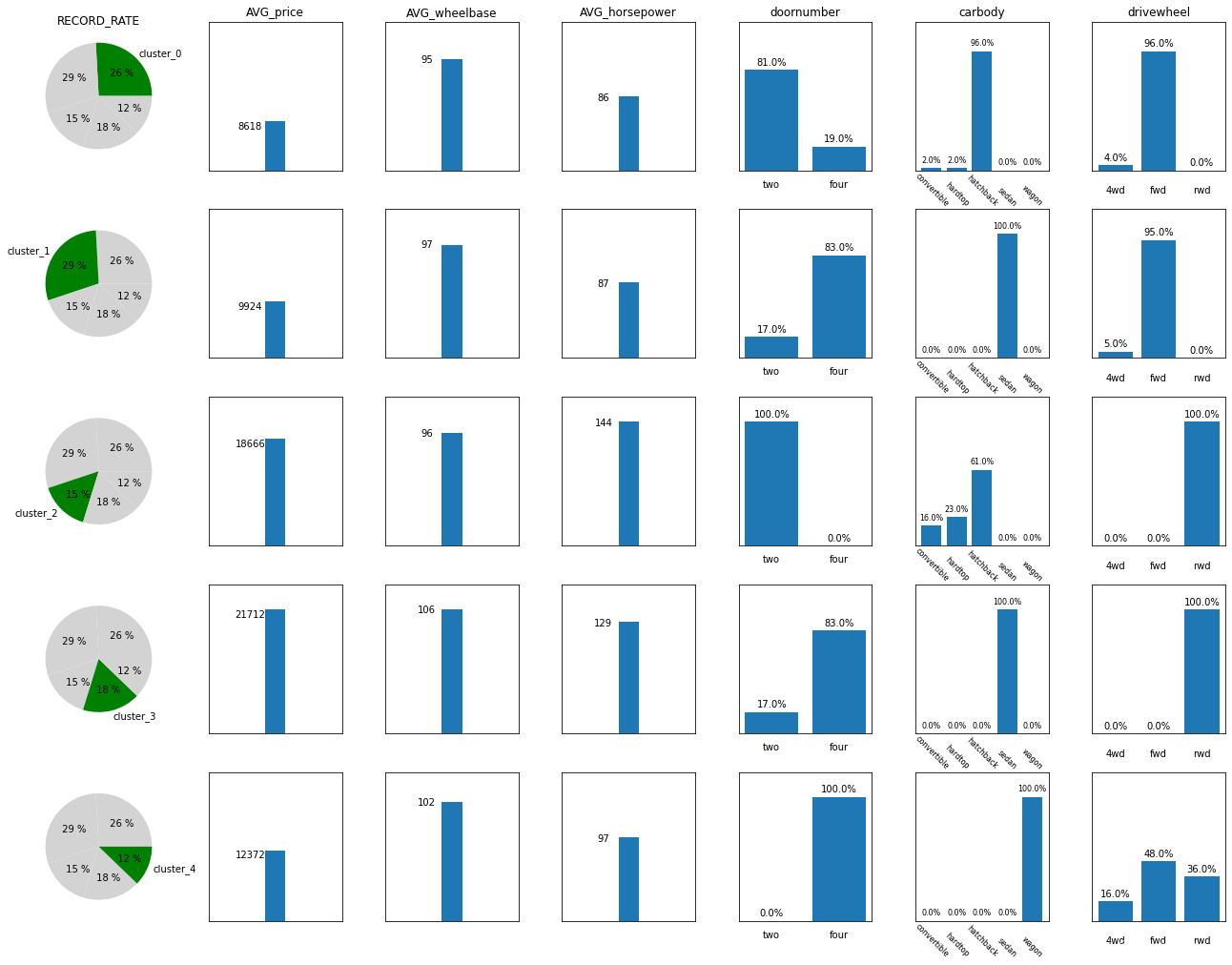
每个类别下的特征一目了然。
六、竞品分析思路
对于汽车竞品,首先要确定类型和价格,只有同价位、同类型的汽车才能算竞品,其次才是品牌、外观、配置、油耗等因素,如果要从竞品角度出发,可以将类别数设置多一些,将类别分得更加细一些,同时对竞品车辆价位进行分箱筛选,再将筛选出的车辆进行分类统计,看看属于哪个类别,这样得出的竞品才可能更具代表性,再通过可视化的方式将竞品的数据展示出来,更加方便解读。下面简单做一下尝试。
import pandas as pd
df=pd.read_csv("/merge_data.csv")
# 分箱,由于目标品牌vokswagen rabbit价格是7775,所以区间选择7500-8000
m_bins = [0,7500,8000,310000]
df['m_score'] = pd.cut(df['price'], m_bins, labels=[i+1 for i in range(len(m_bins)-1)])
# 筛选出vokswagen rabbit所在区间数据
df_car=df[df['m_score']==2]
# 分组聚合
df_car.groupby(by=['clusters','CarName']).size()
这样就得出每个类别下的竞品,再结合聚类特征就可以看出目标品牌的优劣。
总结
1. 聚类算法是一种无监督类算法,对凸簇数据区分比较好,适用于非大数据(数据量100万以下),但对非凸数据比较难以处理,非凸数据用DBSCAN算法更好一些。
2. 聚类特征的选择是一个难点,特征太多,聚类效果不好;特征太少,没有聚类的必要。这个可以从业务需求出发,选择相应的特征进行建模。
3. 可视化方面可以选择power bi、tableau等第三方工具,比用Python要方便很多。