���ַ:CSDN21��ѧϰ��ս��
����Ŀ¼
ǰ��
����:
python3.7
IDEA
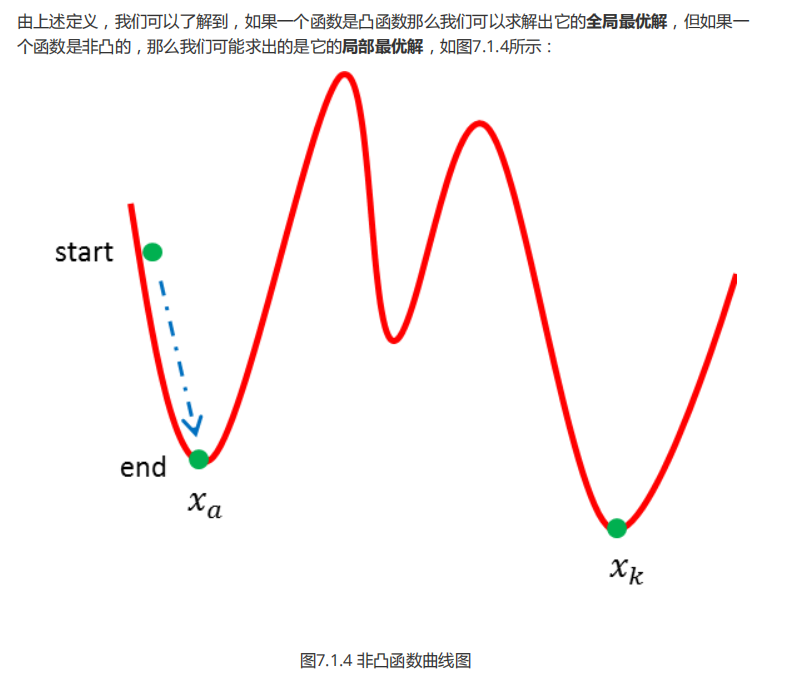
����ѧϰ����˼·:
- �Ƶ���ʽ���н�ģ
- �Ż�ģ��
- ����ϵ��
- ����ģ�ͽ���Ԥ��
�ع�
1. ����
һԪ���Իع�������������Իع�ģ��:
1920�������ٶ���ɲ���������,����,�������о��ٶ���ɲ������֮�䵽����ʲô���Ĺ�ϵ��
����ɢ��ͼ
# 1.�ռ�����
data_cars = pd.read_csv("../data/cars.csv",usecols = ["speed","dist"])
print(data_cars.head())
# 2.���ӻ�
speed = data_cars["speed"]
dist = data_cars["dist"]
plt.scatter(speed,dist) # ɢ��
plt.title("Scatter plot of vehicle speed and braking distance")
plt.show()
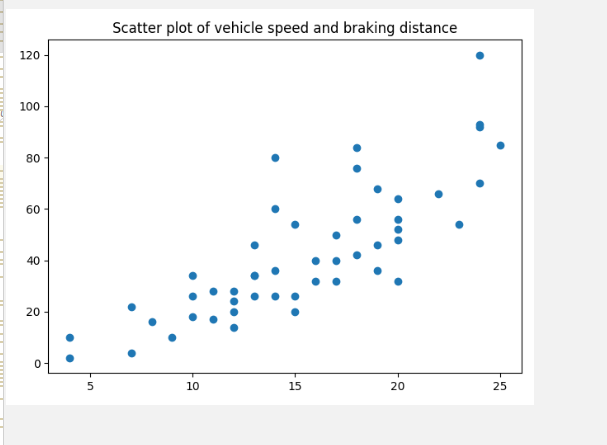
�������Թ�ϵ:
Ϊ��ʹԤ���Ϊ��

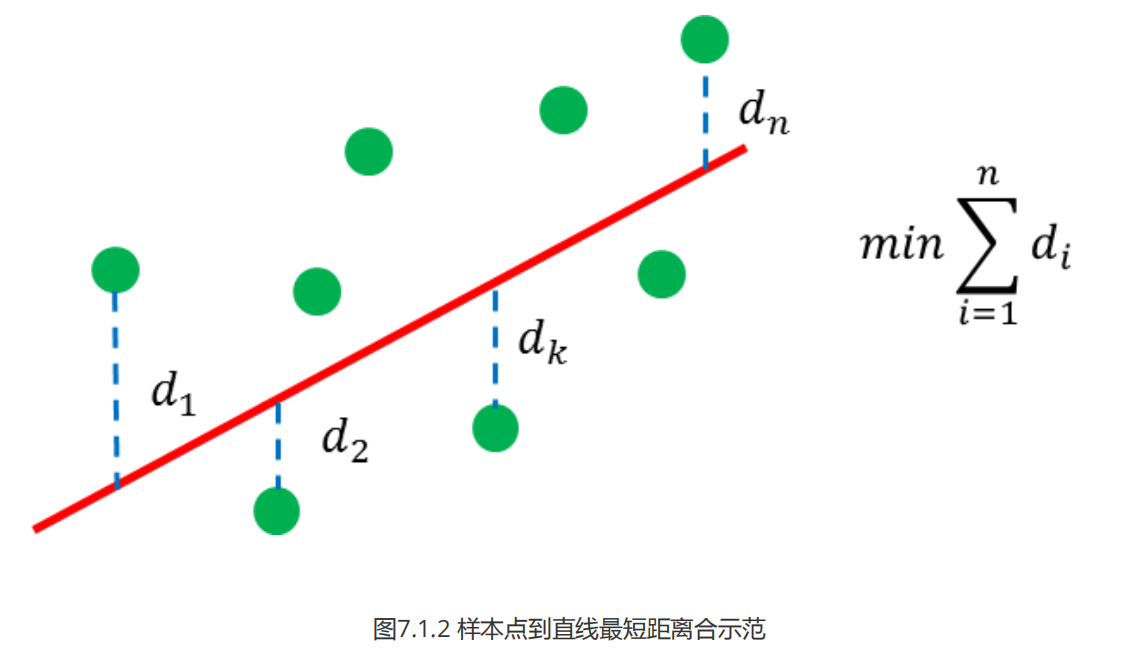
��ͼ��ֱ������,����ʹѰ��һ��ֱ��,ʹ�����������㵽ֱ�ߵľ���֮�����,��ͼ7.1.2��ʾ:
�����ڻ���ѧϰ�г�Ϊ��ʧ����:
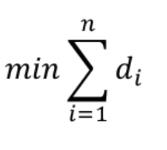
��ʧ����
���ǿ���ͨ��ֱ�ӷ��͵��������ַ�ʽ�Ը���ʧ���������Ż�,�����õ�ʹ��ʧ������С�Ļع�ϵ��������,���Ƿֱ��������ַ���������⡣
ֱ�ӷ�
ֱ�ӷ�,����ֱ�Ӹ����Ż���������Ž�,���������е��Ż����ⶼ������ֱ�ӷ��õ����Ž�,���Ҫ
ʹ��ֱ�ӷ�,��ʧ������Ҫ������������:
1. ��ʧ����Ϊ����; (�����ǰ�״����״)
2. ��ʧ����Ϊ������,��ͨ���ϸ�Ĺ�ʽ����õĽ⡣
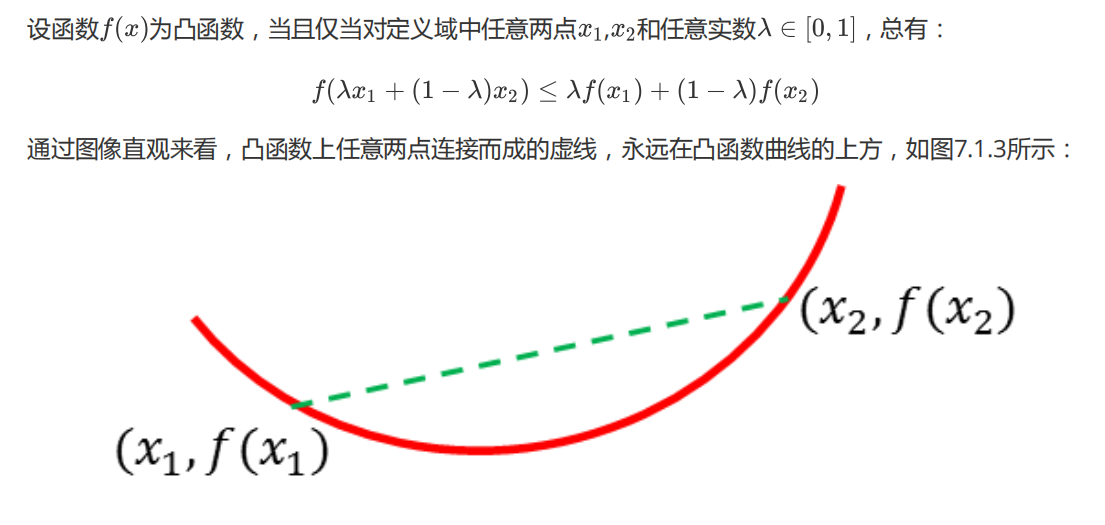
��������:
ͼ7.1.3 ��������ͼ

python����:
## 2.2 ��ʧ����
import sympy
#�趨�ع�ϵ��
alpha, beta = sympy.symbols("alpha beta")
#�趨��ʧ����
L = 0.5* np.sum((dist - beta*speed - alpha)**2)
#��ƫ��
print(sympy.diff(L, alpha))
#50.0*alpha + 770.0*beta - 2149.0
print(sympy.diff(L, beta))
#770.0*alpha + 13228.0*beta - 38482.0
f1 = sympy.diff(L, alpha)
f2 = sympy.diff(L, beta)
### ������Է�����
outcome = sympy.solve([f1, f2], [alpha, beta])
print(outcome)
#{alpha: -17.5790948905109, beta: 3.93240875912409} ���Ž�
{alpha: -17.5790948905109, beta: 3.93240875912409} ���Ž�
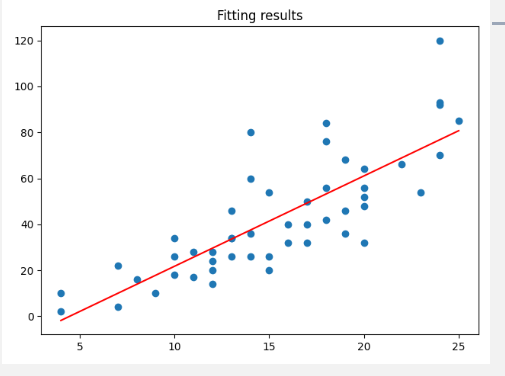
���ǽ�ֱ�� y = 3.932x+ -17.570 �����ڳ�����ɲ������ɢ��ͼ��,��ͼ7.1.5��ʾ��
### ��ͼ
alpha_num = outcome[alpha]
beta_num = outcome[beta]
dist_pre = beta_num*speed + alpha_num
plt.scatter(speed, dist)
plt.plot(speed, dist_pre, c = "r")
plt.title("Fitting results")
plt.show()
������
�ܶ�������Ƿ��ε� û��ʹ��ֱ�ӷ������Ż� �������ǿ���ʹ�õ�������⡣��������һ�ֲ����ñ����ľ�ֵ������ֵ�Ĺ���,���������þ�ֵ���������Ž�Ĺ��ơ�
����,����ʹ�õ������е�С�����ݶ��½����������:
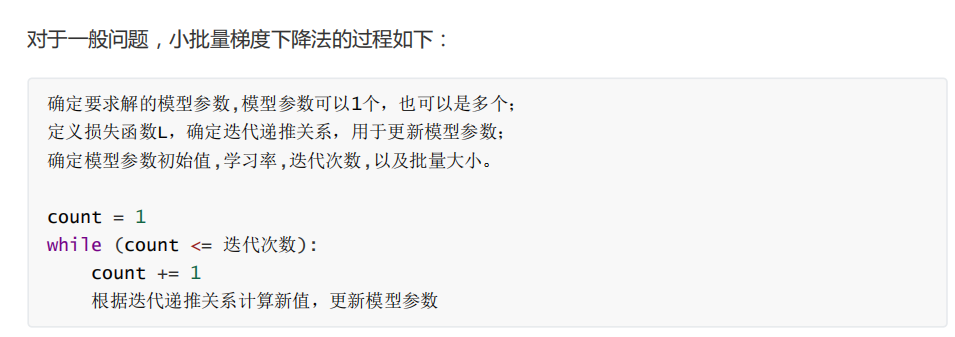
�������ǵ�����,С�����ݶ��½����Ĺ�������:
-
ȷ��Ҫ����ģ�Ͳ���Ϊ ��,�� ;
-
����С�����ݶ��½�������ʧ����:

-
����ݶ�,��������ƹ�ϵ:
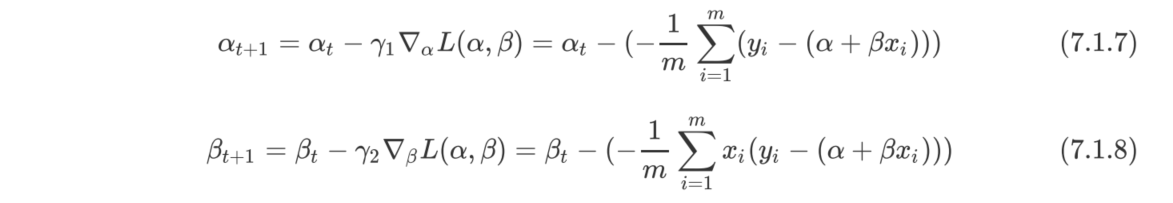
��[0, 10)�а��վ��ȷֲ��������alpha��beta�ij�ʼֵ,����ѧϰ�� �� ��Ϊ0.02,�����������
Ϊ20000��; -
����,��������������ģ�Ͳ�����
#������
import random
#������ƹ�ϵ,���µ�������
def update_var(old_alpha, old_beta, y, x, learning_rate):
len_x = len(x)
alpha_delta = np.sum(-(y - old_beta*x - old_alpha))/len_x
beta_delta = np.sum(-x*(y - old_beta*x - old_alpha))/len_x
new_alpha = old_alpha - learning_rate*alpha_delta
new_beta = old_beta - learning_rate*beta_delta
return (new_alpha, new_beta)
#����
def iterative_func(y, x, start_alpha, start_beta,
learning_rate, iterative_num,
sample_num):
alpha_list = []
beta_list = []
alpha = start_alpha
beta = start_beta
num_list = list(range(1, len(y)+1))
for i in range(iterative_num):
alpha_list.append(alpha)
beta_list.append(beta)
random.shuffle(num_list)
index = num_list[:sample_num]
alpha, beta = update_var(alpha, beta,
y[index], x[index], learning_rate)
# print("alpha: {}, beta:{}".format(alpha, beta))
return (alpha_list, beta_list)
#��[0, 10)֮�䰴�վ��ȷֲ��������alpha��beta�ij�ʼֵ
start_alpha = np.random.random()*10
start_beta = np.random.random()*10
#����ѧϰ��Ϊ0.01,��������Ϊ500��,ÿ�μ���8������
learning_rate = 0.002
iterative_num = 20000
sample_num = 16
alpha_list, beta_list = iterative_func(dist, speed, start_alpha, start_beta,
learning_rate, iterative_num,
sample_num)
���ᷢ��ֱ�ӷ��͵����� �����
�����Ʀ��ͦ±仯:
...�������...
#�
import csv
parameter_data = zip(alpha_list, beta_list)
with open("./outcome/gradient_descent_parameter.csv", 'w', newline = '') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["alpha","beta"])
csv_writer.writerows(parameter_data)
#��ͼ
plt.subplot(121)
plt.plot(alpha_list)
plt.title("alpha change process")
plt.subplot(122)
plt.plot(beta_list)
plt.title("beta change process")
plt.show()
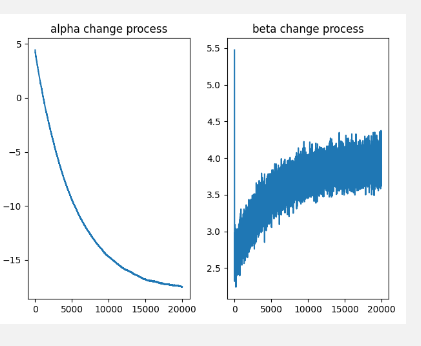
ѧϰ��:Ӱ��仯�ȶ�������,���ǿ���������ѧϰ�����ŵ������������ݼ�,��������������
������:
��������:
�������ݺû�

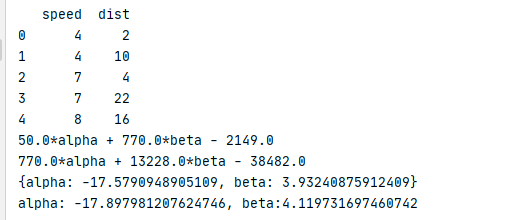
ֱ�ӷ���õĻع�ϵ������ֵ��������,�������� R^2:
#�ж�ϵ��R2
dist_pre = beta_num*speed + alpha_num
dist_mean = np.mean(dist)
R_2 = np.sum((dist_pre - dist_mean)**2)/np.sum((dist - dist_mean)**2)
print(R_2)
#0.651079380758251
#Ԥ��
new_speed = pd.Series([10, 20, 30])
new_dist_pre = beta_num*new_speed + alpha_num
print(new_dist_pre)
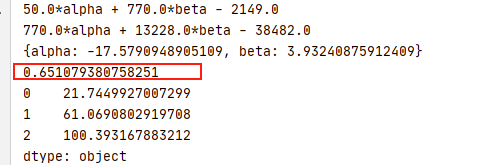
���R^2�õ�0.65107938
Ԥ��
�������ǵ�ģ�ͶԽ������Ԥ�⡣
������Ȼ����ֱ�ӷ���õĻع�ϵ������ֵ,���µ���������Ԥ�⡣
�����¼�¼��һ�������ij��ٷֱ�Ϊ10, 20, 30,����python,���ǿ��Եõ�ɲ�������Ԥ��ֵΪ21.745,61.069,100.393��
2. �ع�Ļ���˼��
��Ԫ���Իع�
�������������,���ǽ���һ���Ա���,��������ʵ������,����Ҫ�����IJ�ֻ��һ��,���Ƕ���Ա�
���������֮��Ĺ�ϵ,��������Ԥ������,���ǿ��Բ��ö�Ԫ���Իع�.

���ǵ�Ŀ�����û�����������ѧϰ��һ������ģ��,�Ӷ�����Ԥ��,���ǻ��������Զ���ѧϰ,����Ҫ
��ע�����,��Ҫ���˵�ָ����ȥ������
����,������Ҫ���������ѧϰ,������һϵ��"����"�û���Χ��������"����"���ϵ�ѧϰ,�����Լ�������,�ڶ�Ԫ���Իع��������,���ǵ�"����"����:
- ������ʧ����,����ģ�ͺû�
- �����㷨��С����ʧ����
��ʧ����

����:
��С���˷�

�ݶ��½���
�ݶ��½�����������һ��̩��չ��,ʹ һ�����ƽ�����,�Ӷ���С����ʧ�����ķ�����
���ݶ��½�����,����ÿ�ε���������ʧ��������Ʒ�����IJ�ͬ,�����ֿɽ����Ϊ:
- �����ݶ��½���(BGD),
- С�����ݶ��½���(MBGD)
- ����ݶ��½���(SGD)��
1.3 ����ֵԤ�ⰸ��
ijʯ����ҵ�Ĵ��ѻ����;�������װ������4��,�����˴�����ʷ���ݡ��Ӵ��ѻ����;���װ��
��,���ǵõ���325����������,�����Ϊ��Ʒ�е�����ֵ(RON)(y),�Ա�����310��(x1,x2,x3��x310),���Ƿֱ�Ϊ����ǰ
��ԭ���Ϻ������ֲ���������
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from mlxtend.evaluate import bias_variance_decomp
#��ȡԭʼ����
data_ron = pd.read_csv("../data/data_ron.csv")
print(data_ron.shape)
#(325, 311)
y = data_ron["RON"]
X = data_ron.iloc[:, 1: (len(data_ron) + 1)]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.2, random_state = 10)
#����ģ��
model = LinearRegression()
model.fit(X_train, y_train)
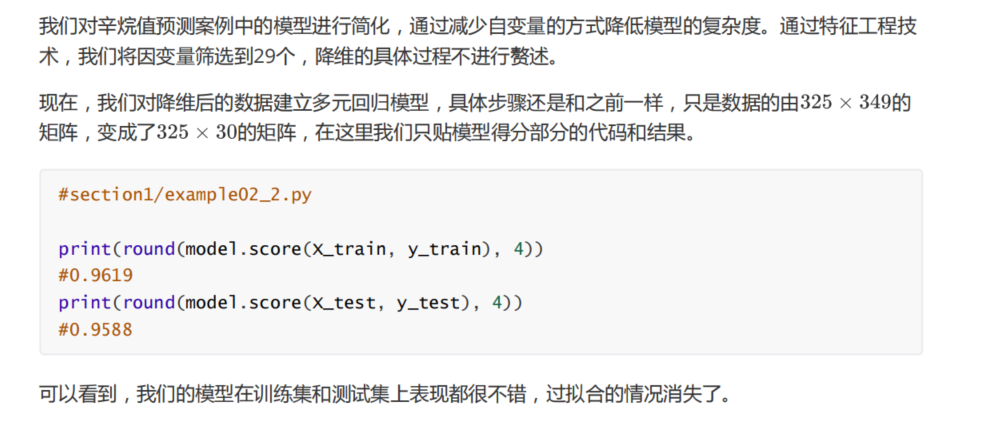
print(round(model.score(X_train, y_train), 4))
print(round(model.score(X_test, y_test), 4))
#����(����ݶ��½���֮ǰ��Ҫ����)
#stand_train = StandardScaler()
#stand_train.fit(X_train)
#X_train_standard = stand_train.transform(X_train)
#X_test_standard = stand_train.transform(X_test)
#model = SGDRegressor()
#model.fit(X_train_standard, y_train)
#print(round(model.score(X_train_standard, y_train), 4))
#print(round(model.score(X_test_standard, y_test), 4))
def mape(y_true, y_pre):
n = len(y_true)
mape = (sum(np.abs((y_true - y_pre)/y_true))/n)*100
return mape
y_hat = model.predict(X_test)
MSE = metrics.mean_squared_error(y_test, y_hat)
RMSE = metrics.mean_squared_error(y_test, y_hat)**0.5
MAE = metrics.mean_absolute_error(y_test, y_hat)
MAPE = mape(y_test, y_hat)
print("MSE:{:.4f}, RMSE:{:.4f}, MAE:{:.4f}, MAPE:{:.4f}".format(MSE, RMSE, MAE, MAPE))
#MSE:0.0370, RMSE:0.1924, MAE:0.1511, MAPE:0.1710
#������ת���ᱨ��
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
y_test = np.array(y_test)
mse, bias, var = bias_variance_decomp(model, X_train, y_train, X_test, y_test,loss='mse',
num_rounds=30, random_seed=1)
print("mse:{:.4f}, bias:{:.4f}, var:{:.4f}".format(mse, bias, var))
#mse:0.3947, bias:0.3443, var:0.0504
��Ҫʹ��sklearn��ģ��
���Կ���,������ѵ�����ϵ�ģ�͵÷־�Ȼ��1.0,���Dz���˵�����ǵ�ģ�������㹻����?����,
�����ٿ���ģ���ڲ��Լ��ϵĵ÷֡�

�ɽ����֪,ģ���ڲ��Լ��ϵĵ÷�Ϊ����,�Ѿ��㹻���ˡ�������ѵ�����ϱ��ֺ�,���ڲ��Լ��ϱ��ֲ������,���dz�Ϊ�����,������Եľ�����ѵ�����ϱ��ֲ�,���ڲ��Լ��ϱ��ֺ�,�������dz�֮ΪǷ���,
1.4 �������Ƿ���
����
����:�ó���ģ���ܹ��Բ��Լ�����ȷԤ��,��ô���Ǿ�˵�����нϺõķ���������
����ģ�͵�ͨ���Ժ�ǿ,�ڲ��Լ�����Ԥ��ȷ��
�������Ƿ���
�����
����:��������ʹ�ù���������,������ѵ�����÷ֺܸ�,���Լ��÷ֺܵ�,����dz����˹���ϵ������
Ƿ���
����:
�����ǵ�ģ���ڼ�ʱ,���ܻ����Ƿ��ϵ����,��˵�������ǵ�ѵ���������,ģ��û��ץסѵ
���������ݵ���Ϣ�����������İ�����,���ǵ�ģ�ͳ�����Ƿ���,��ô��ѵ������,���Եĵ÷�Ӧ
�ýϵ�,�����Լ��ϵ�ģ�͵÷�Ӧ�ýϸߡ�
��ܵķ���:
����Ƿ���ʱ,����Ӧ����������ģ�͵ĸ��Ӷ�,������Ƿ��ϵ�״����
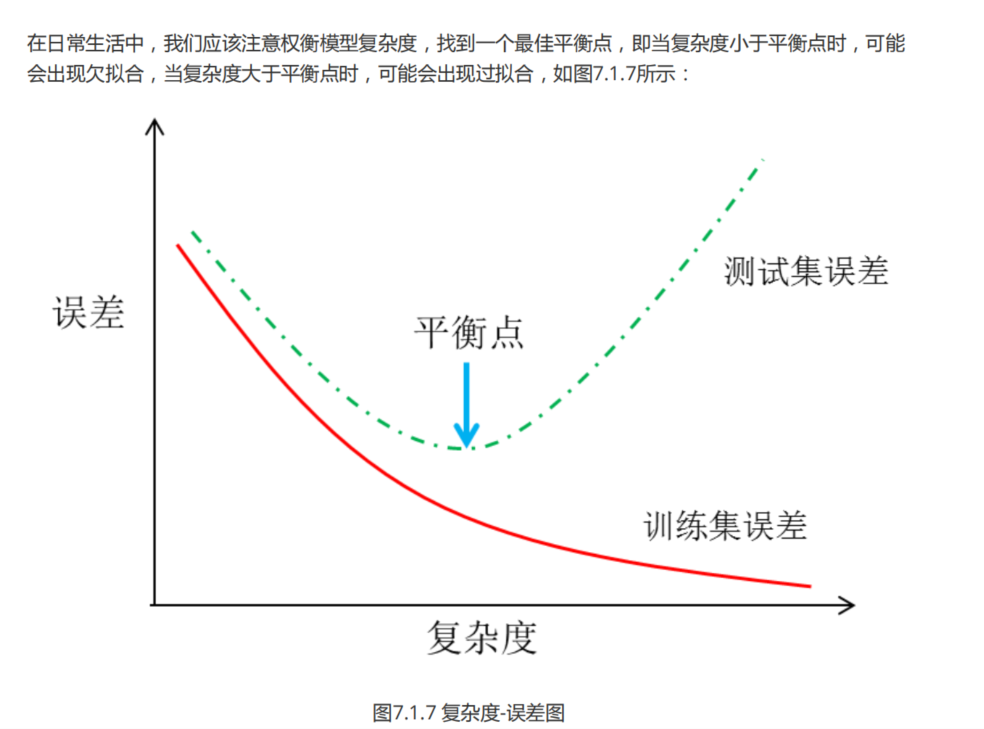
���Ӷ�С��ƽ���,Ƿ���;
���Ӷȴ���ƽ���,�����;
�ع�ģ��
1.5 ģ�͵�����
R^2

MSE��RMSE

MAE��MAPE

ƫ��-����Ȩ��(��ϸ�о�һ��)
���ۻع�ģ��
1.6 ������
�ڽ�ģʱ,��������ϣ���Լ���ģ���ܹ�������ѵ������ȡ�ýϸߵľ���,��ϣ��ģ���кõķ�����
��,��ʱ,���ǿ���ͨ������ʧ��������������ʵ����һĿ�ꡣ�������ʹ�ÿ��Լ�������ϵ�״��,
Ҳ����������ѡ��ģ�͵�������
��ع�

Lasso�ع�

ElasticNet�ع�

pythonʵ��
�ܽ�
����:
- ������ҳ�����ڽ��������Ӧ�ó��� Jupyter Notebook ___ ������дC++
����������:
- Mendeley Desktop
- Zotero
ģ��������:
- DVC
?������վ:
- �����������ѧϰ�� scikit-learn.org