优化策略(总)
?? 一个系统从开发出来到实际的应用需要层层的优化,对于一个机器学习或者深度学习系统,我们需要进行怎样的优化,这篇博客可以提供给你一些思路。资源来自于(吴恩达《深度学习》+《设计模式原理》+一些最新的深度学习领域论文文献)
| id | ideas |
|---|---|
| 1 | 搜集更多的数据 |
| 2 | 搜集更多样的数据(场景、姿势) |
| 3 | 用梯度下降算法训练的更久一点 |
| 4 | 用不同的优化算法(adam优化算法等) |
| 5 | 尝试规模更大或者更小的神经网络 |
| 6 | 尝试正则化或者dropout |
| 7 | 修改网络架构(激活函数、改变隐藏层的单元数目) |
| 8 | … |
??有的项目组可能花很长时间去优化其中的某一项或几项,但最后反而可能会降低模型的准确度。如何进行模型的优化以达到我们想要的想过是这篇博客主要讨论的问题。
1.正交化

??例如汽车的案例,汽车的有3个按钮,一个方向盘,一个油门,一个刹车。而不是一个按钮控制0.3x旋转角度-0.8乘以你的速度,或者其他的2x转角度+0.9x车速,理论上通过这种方式也可以达到调整车的状态的结果,但是比起单独控制旋转角度,单独控制油门和刹车要复杂的多。

??还有一个例子就是洗澡的淋浴按钮,大家应该体验过,只要关上水龙头就要重新调节的困境。但是如果把热水和冷水抽离出来,一个只控制热水,一个只控制冷水,那么这种装置会好用的多。
??这也就是涉及到面向对象的一个概念,高内聚,低耦合的原理。
2.单一数值评估指标
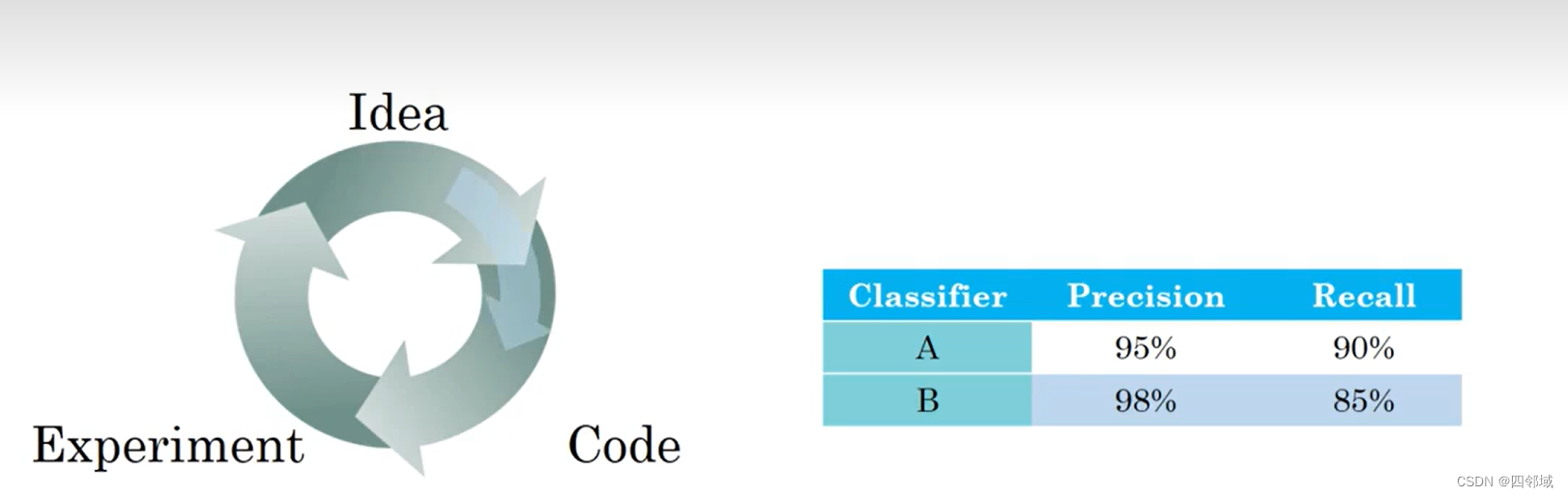
??在调整模型种,有一个可以评价的指标,可以很快的帮助你确定模型的调整比之前的手段好还是坏。所以我们应该为我们的问题设置一个单实数评估指标。
?? 例如,此时对于分类器P和R分别有一个有优势的,这时我们就会面临取舍的问题。
?? 对于Precision和Recall这两个指标有F1进行结合,大家可以简单的理解为取P和R的平均值。
? ?当然,单一指标的意义不只是指就一个指标,而是将一个重要指标结合起来抽象成一个可以得分的指标。这又体现着高内 聚的一个特点。所以结合我们的深度学习系统就可以优化为 ?系统+单一指标得分。

? ?总的来说,单一指标原则是可以提升我们效率的一种方法。
3.满足和优化指标
? ? 相信很多人看到单一评估指标就会发现它的缺点,有些时候我们的模型需要考虑的东西很多,不可能通过一个指标就完成评估。这时就需要满足和优化指标。
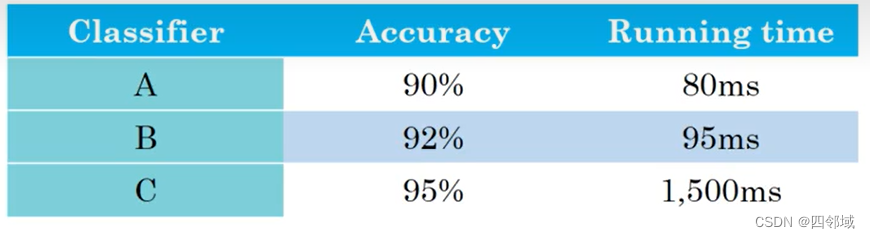
? ?满足指标:例如上面,我们有一个flag==100ms,当不满足时我们可以直接舍弃模型C。
对于满足指标的意义就是一个分数线,如果够不到分数线,那么其他再优的指标我们也不考虑。
? ?还有一层意思,实际的情况,只要响应时间低于100ms,用户可能对100ms和50ms的需求不是很高,对于分类器的相应速度虽然从95向80提高的比例高,但是此时,可能优先选择的还是B分类器,因为1%的正确率指标要不速度的提高更珍贵。
? ?如果我们此时有N个指标可以选择,有时候选择一个作为优化指标,然后剩下N-1个指标都是满足优化指标的,也就意味着只要达到一定的阈值,我们就不必再在乎超过阈值之后的得分了,但是必须要达到这个阈值。
4.训练_开发_测试集划分
训练集:单纯的训练时用的数据;
开发集:在系统没有发布前,对系统进行测试的测试集。(优化系统)
测试集:系统封装好后,用来测试系统性能的测试集。(验证系统)
? ?这是老生常谈的问题,一般的划分方法为训练测试标准是8:2或者7:3等,但是每个项目组面临的实际开发问题不同,数据量,数据类型,数据值大小不同,所以怎样根据自己的项目划分是一个非常重要的问题。
? ?

5.开发和测试集的大小

机器学习早期时这么分是比较合理的,但如果在数据集比较大的时候,例如数据集大小为1000000,那么1%=10000,对于测试集来说完全足够了。
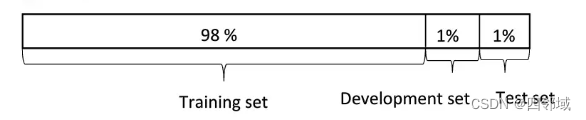
现在的趋势是,把大量大的数据集分到训练集上面,然后少量数据集分到开发集和测试集上。
6.什么时候改变开发集_测试集的大小
??在评估指标上做的更好。

??显然A系统的正确率更高,但是A系统可能会在显示图片时推送一些隐私图片。而B系统分类正确率低一些,但它不会犯这个错误,显然在我们看来B系统更合适一些,但是只通过得分我们会误以为A系统更好。
??你的评估指标无法正确衡量算法之间的优劣排序时。这时就发出信号,应该改变评估指标或者改变训练集和测试集了。
此时可以修改优化参数,对于一些是某一类的图片添加参数,使得x(i)出现时,把w(i)设置比较大,使得这个错误率项快速变大,把惩罚权重加大10倍。