对?学习属于?监督学习,所以对?学习是没有标签的。对?学习是通过构造正负样例来学习特征,如何构造正负样例对对?学习来说很重要。
对于?个输?样本x来说,存在与之相似的样本x+以及与之不相似的样本x-,对?学习要做的就是学习?个编码器f,这个编码器f能够拉近x与其正样本间的距离,推远x与其负样本之间的距离。即:
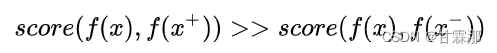
图像领域的自监督对比过程描述为三个基本步骤:
?通过分解为三个主要步骤来进一步剖析这种对比学习方法:数据增强、编码和损失最小化。
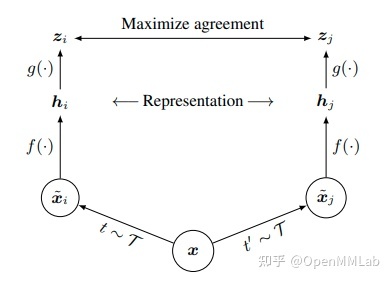
(1)对于数据集中的每个图像,我们可以执行两种增强组合(即裁剪 + 调整大小 + 重新着色、调整大小 + 重新着色、裁剪 + 重新着色等),我们希望模型知道这两个图像是“相似的”,因为它们本质上是同一图像的不同版本。
(2)将这两个图像输入到我们的深度学习模型(Big-CNN,例如 ResNet)中,为每个图像创建向量表示。目标是训练模型输出相似图像的相似表示。
(3)最后通过最小化对比损失函数来最大化两个向量表示的相似性。
? ? ? ? 值得注意的是,不同领域的数据增强的操作有所不同:图像领域中的扰动大致可分为两类:空间/几何扰动和外观/色彩扰动。空间/几何扰动的方式包括但不限于图片翻转(flip)、图片旋转(rotation)、图片挖剪(cutout)、图片剪切并放大(crop and resize)。外观扰动包括但不限于色彩失真、加高斯噪声等

?
? ? ? ??
本篇文章我们将分析?7 篇主流论文,带大家一起梳理对比学习的发展脉络:
1、MoCo v1
论文链接:https://arxiv.org/abs/1911.05722
其实 MoCo 并不是第一篇提出对比学习概念的文章,在 MoCo 之前也有一些算法是基于某种形式的对比损失函数,例如 NPID、CPC、CMC 等,但是 MoCo 这篇论文则将之前的对比学习总结成字典查找的框架,再基于此提出 MoCo。
作者提出了 Momentum Contrast 的概念,另外为无监督对比损失函数构建了足够大且具有高度一致性的字典,并通过队列 (queue) 的数据结构进行维护,下图即为 MoCo 论文思路的示意图,动量编码器以及通过队列存储特征向量,便是该文章两大最主要的特点了。
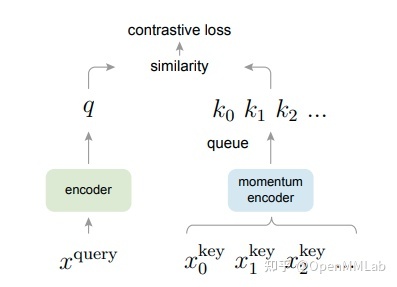
结合上图,在前向计算时,对每个 batch 数据施加两组不同的数据增强,从而得到两组数据,作为模型的输入,
其中一组为 x_query,通过 q_encoder 获得对应的特征向量 q;
另一组为 x_key ,通过 k_encoder (即上图的 momentum encoder) 获得对应的特征向量 k。
这两组 q,k 则作为正样本对进行损失函数的计算。而之前存在 queue 中的所有特征向量 k 和本次计算所得的 q 则作为负样本对进行损失函数计算,两者结合便是 MoCo 算法训练所需要的损失函数。在前向计算最后,需要将本次计算的 k 送入队列,若队列已满,则最旧的特征向量出列。
在反向计算时,q_encoder 通过梯度反向传播进行更新,但 k_encoder 则是根据 q_encoder 采用动量更新参数的模式进行更新,以此来保证模型一致性,这也就是动量编码器命名的由来,公式如下:
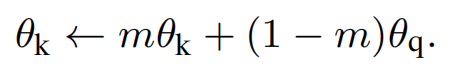
其中 q 和
?代表模型 q_encoder 和 k_encoder 的参数,m 为动量参数。
另外,MoCo 通过队列储存特征向量的方式,避免在训练过程中输入大 batch size,减少了硬件资源的需求和训练时间。而且由于队列的长度为 65536(算法默认设置),可以提供大量的负样本进行对比学习;且队列 First Input First Output 的原则,可以及时更新特征向量,删除过于老旧的特征向量,一定程度上保证队列的一致性和训练的稳定性。这也是一个非常巧妙的设计。
MoCo 在自监督领域中取得了 SOTA 的结果,视觉自监督领域也随之火爆了起来。
2、SimCLR
论文链接:https://arxiv.org/abs/2002.05709
在 MoCo 论文发布之后,很多研究者都投入到了对比学习的研究当中来,其中 Google 的 SimCLR 采用非常简单的 End-to-End 的训练框架取得了 SOTA 的结果。

SimCLR 提出四大结论:
- 对比学习中,强大的数据增强至关重要,相比于有监督学习,对比学习从中受益更多
- 在网络学习到的特征和损失函数计算之间,添加可学习的非线性层有助于特征的学习
- 归一化的 embeddings 和合适的 temperature 参数有助于特征表示的学习
- 越大的 batch size 和越久的训练时间有助于对比学习获得更好的结果,另外和监督学习一样,大网络可以取得更好的结果
和 MoCo 不同的是,SimCLR 没有使用动量更新也没有队列来储存特征向量,它通过大 batch size 来构建负样本,网络就是普通的 ResNet + MLP,通过梯度反向传播来更新,和普通的分类网络训练流程并无二致,正如标题所说,‘A Simple Framework’ 名副其实。
SimCLR 针对各种技巧做了非常详尽的实验,并进行总结,提出了一个简单而有效的框架,为后续对比学习的研究打下了夯实的基础,各种技巧也都被多篇论文所借鉴学习。
3、MoCo v2(验证了 SimCLR 中所提出的两个设计)
论文地址:https://arxiv.org/abs/2003.04297
这篇论文非常简单,只有短短两页,其实可以说是一篇技术报告。MoCo v2 验证了 SimCLR 中所提出的两个设计,相比 MoCo v1,其结果提升非常可观,甚至超过了 SimCLR 的结果,而且训练时间更快,所占资源更少。

如上图(左)所示,在 SimCLR 中所提出的更加强大的数据增强以及添加 MLP 非线性层可以非常有效地提升特征学习的质量。随着 SimCLR 和 MoCo v2 的发表,视觉自监督学习的结果总算是接近了有监督学习的水平。
4、BYOL(摒弃了负样本,而仅依靠正样本进行训练)
论文链接:https://arxiv.org/abs/2006.07733
主要贡献有以下三点:
- 提出 BYOL,摒弃负样本
- BYOL 所学习到的特征表达,在半监督和迁移学习的基准测试上也达到 SOTA
- 证明了 BYOL 对 batch size 的变化容忍度更高
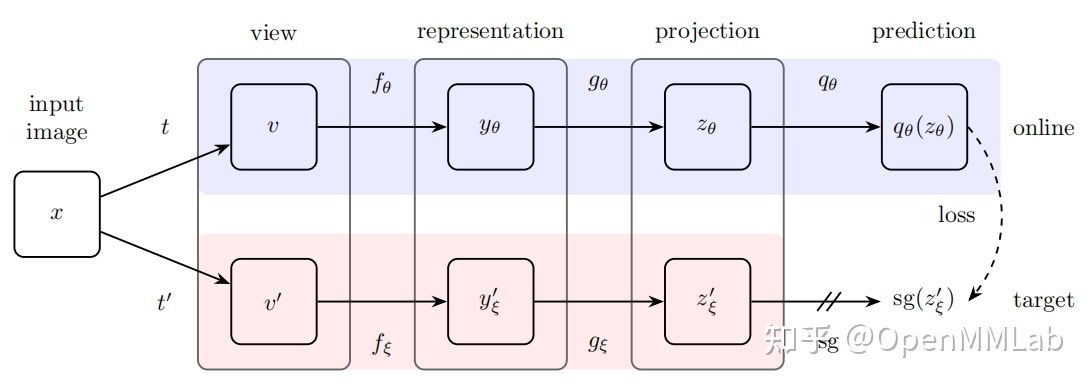
算法框架如上图,相比于之前的算法,BYOL 依然采用双网络,命名为 online 和 target,前向计算和之前算法差别不大,不过在 online 网络中,增加了 predictor,并不是完全对称。
另外在动量更新 target 网络时,动量参数也会随着训练的进行而更新。
损失函数则是简单的 MSE,只需要对正样本进行距离计算,而没有负样本之间的计算。
在之前对比学习中,负样本作为一个必须部分,且都需要给定足够多的负样本,对比学习才能达到更好的效果,以此来防止模型学到捷径解,从而避免模型坍缩;而在 BYOL 中则摒弃了负样本,通过非对称结构以及动量更新方式来避免模型坍缩,并且仍然达到了 SOTA 结果,这也是这篇论文当时引起剧烈讨论的因素之一。
5、SwAV(提出一种在线聚类损失 +?提出 multi-crop 数据增强策略)
论文链接:https://arxiv.org/abs/2006.09882
SwAV 为?Swapping?Assignments between multiple?Views (在多个视图之间交换分配)的缩写,这篇论文和上述的 BYOL 是同期工作,并且也取得了 SOTA 结果。主要贡献有:
- 提出一种在线聚类损失,不论大小 bacth size,不用大型队列和动量编码器,也可有效训练
- 提出 multi-crop 数据增强策略(本文的第二点贡献 multi-crop 的数据增强策略,对最终的结果影响很大,如果移除 multi-crop,则最终结果和 MoCo v2 类似,该数据增强方法也是一个即插即用性的方法,其他对比学习框架下的算法也具有提升学习效果的作用),增加输入图片的视角
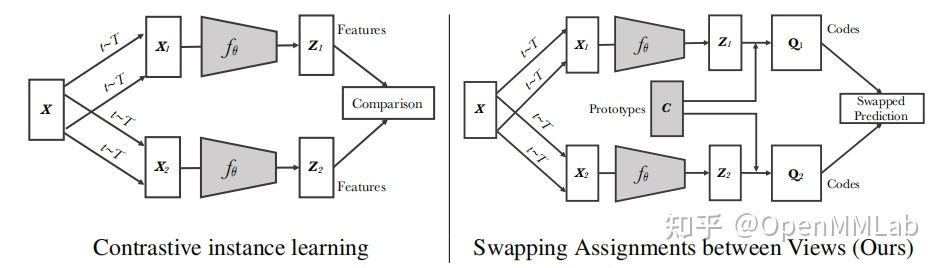
上图(左)为对比学习的抽象框架,而 SwAV 的算法框架和之前方法最大的不同点在于构建了一个名为 C 的聚类中心,将自监督学习和聚类方法相结合,利用上图(右)编码器 f 的输出 z1 和聚类中心向量 c 点乘的结果,可以得到相似度矩阵,以此来预测 Q2(Q1 和 Q2 则是通过 sinkhorn 算法得到),反之亦然,以此达到交换预测的效果。
采用聚类的方法,也有一些好处:一是通过和聚类中心进行对比,可以降低对负样本的需求;二是聚类中心有一定含义,而随机抽样反而可能会抽出正样本或者类别也不均衡。本文作者其实也是 Deep Cluster 的作者,这篇论文也是无监督领域非常经典的论文之一。

另外,本文的第二点贡献 multi-crop 的数据增强策略,对最终的结果影响很大,实验结果如上图,如果移除 multi-crop,则最终结果和 MoCo v2 类似,不过该数据增强方法也是一个即插即用性的方法,其他对比学习框架下的算法也具有提升学习效果的作用。
SwAV 提出了一种新的思路,结合聚类和对比学习进行训练,另外新的 multi-crop 数据增强策略也非常有效,值得后续算法学习应用。
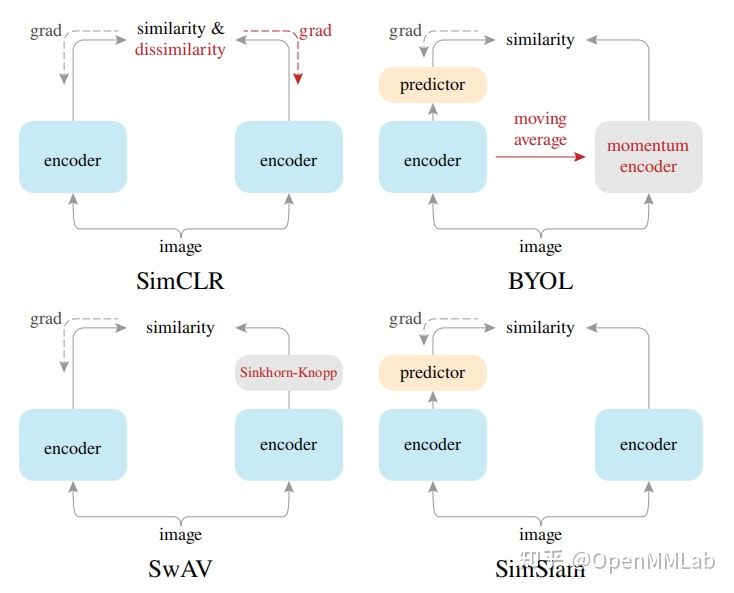
6、SimSiam(对上述多篇论文进行了总结,并且化繁为简)
论文链接:https://arxiv.org/abs/2011.10566
SimSiam 这篇论文则是对上述多篇论文进行了总结,并且化繁为简:
- 不使用负样本对
- 不使用大 batch size
- 不需要动量编码器
在不使用上述技巧的情况下,仍然能学到优秀的特征表达,算法的前向过程和之前算法类似,并且也是采用简单的 MSE 损失函数。
作者在对比实验后提出,stop-gradient 才是避免模型坍缩的关键,如果不使用 stop gradient,那么不论如何变换模型,都会得到捷径解,即模型输出常数,损失函数达到理论的最小值。作者提出假设, SimSiam 的实现是类 EM 算法,而 stop-gradient 的存在使得算法可以按照 EM 的思路进行迭代从而避免模型坍缩,在这我们不做详细赘述,可以阅读原论文的假设和推导。
作者在 SimSiam 这篇论文中,对前面的一些工作都做了总结,和之前的一些 SOTA 算法做了对比:
- 相比于 SimCLR,一定程度上可认为是 SimCLR 去掉了负样本
- 相比于 SwAV,一定程度上可认为是 SwAV 去掉了在线聚类
- 相比于 BYOL,一定程度上可认为是 BYOL 去掉了动量编码器
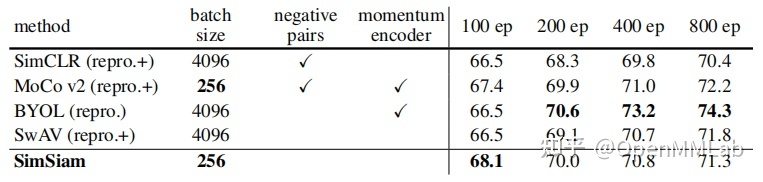
并且,对比之前几篇非常有影响力的工作在 ImageNet-1k 上的结果,SimSiam 对于特征的学习非常迅速,但是在长时训练下的提升不如 BYOL 等算法。
SimSiam 是一篇非常全面且细致的论文,针对对比学习中的所提出的各类方法,做了详尽的实验,应用了最少最有效的技巧,获得了 SOTA 的结果。
7、MoCo v3(进行了对比学习 + ViT 的实验,并提出改进点)
论文链接:https://arxiv.org/abs/2104.02057
随着 2021 年 ViT 网络的爆火,如何将对比学习的训练范式和 ViT 的网络主干结合也是大家经常在思考的问题。MoCo v3 在原先工作的基础上,改动了一些训练方式:
- 弃用了 queue 队列进行 key 的储存,并且采用大 batch (4096) 进行训练
- 增加了 prediction head,所以 q_encoder 和 k_encoder 不再完全对称
- 采用了对称损失函数
通过以上的改变,基于 ResNet50 的网络主干的结果也有一定提升,结果如下表所示:
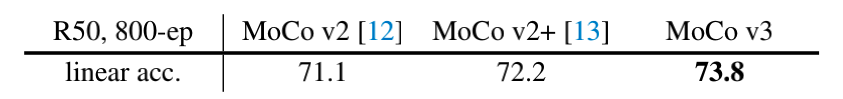
在完成基于 ResNet50 的实验之后,论文将重心移到了对比学习 + ViT 的实验上,实验中发现这种组合形式会导致训练过程不稳定,在大 batch 情况下尤为明显,这个现象会导致最终的训练结果不尽如人意,在 batch size 超过一定程度后,模型准确率反而会下降。
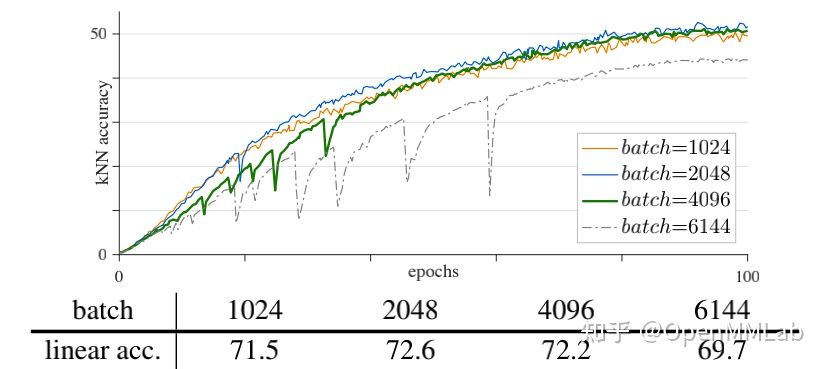
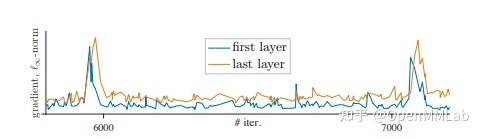
于是,作者团队对 batch size、learning rate、optimizer 都进行实验,但是准确率突然下降的问题并没有得到解决,最后在监督梯度时发现,梯度的突然增大、出现波峰,会导致准确率的突然下降,并且梯度变化的这个现象在第一层中会先于最后一层出现,如下图:
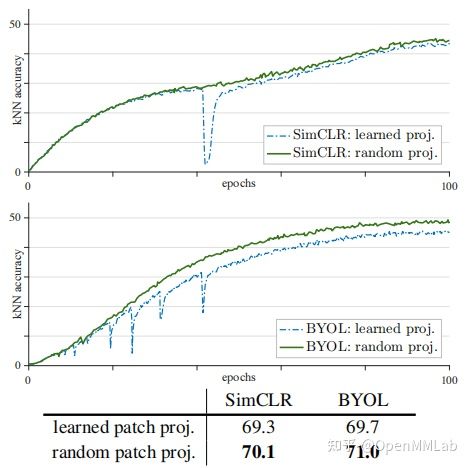
所以,MoCo v3 提出 trick,在训练过程中,可以冻结 ViT 中的 patch projection 层,即随机初始化后不进行参数学习,以此来缓解该问题,采用该 trick 后,可以看到训练曲线恢复正常(如下图左),并且该方法对于 ViT + SimCLR 和 ViT + BYOL 均可以缓解准确率突然下降的问题(如下图右)。但是作者认为该 trick 并没有完全解决问题,如果学习率过大的话,模型训练仍然会变得不稳定,且第一层并不是训练不稳定的关键因素,所有层都与之相关,不过在文章中并没有更加详细的解释。

MoCo v3 这篇论文实验思路清晰,且一定程度上解决了在结合 ViT 主干和对比学习框架过程中所遇到的问题,这还是非常值得我们去学习的。