�����ݿ�ѧ��Ŀ1��:������ĵ�һ�����ݿ�ѧ��Ŀ

����
���Ƕ���˵��һ�����дʡ��������ݿ�ѧ�������Ǵ�����˶��ԡ�����ʲô?�ҿ��Գ�Ϊ���ݷ���ʦ�����ݿ�ѧ����?����Ҫʲô����?�����Ǻ��˽⡣����:���뿪ʼһ�����ݿ�ѧ��Ŀ,����ȴ��֪��������ֽ��С�
���Ǵ�����˶���ͨ��һЩ���߿γ��˽�������������ǶԿγ��в��õ���ҵ����Ŀ�е��������ࡣ����,����ʼ����ȫ�»�δ֪�����ݼ�ʱ,���ǻ���ʧ����Ϊ���ڷ��������������κ����ݼ�������ʱ,������Ҫͨ�����ϵ���ϰ���Ҿ�����õķ�ʽ֮һ��������Ŀ�н���ѧϰ������ÿ���˶���Ҫ��ʼ�Լ��ĵ�һ����Ŀ�����,����дһ��ר��,�����һ��������ݿ�ѧ��Ŀ,����Ȥ�����ѿ���һ�������,Ԥ�Ʋ�������50ƪ���¡���ר����һ����ʵսΪ����ר����
��ô��������ȥ����һ�����ݿ�ѧ��Ŀ��?
Ҫ�����ݿ�ѧ��Ŀ��ȡ�óɹ�,���DZ����˽������̲���������Ż�,��ȷ������ɿ�,������Ŀ�ڱ�Ҫʱ���ڸ��١�ά�����ġ����,��ú����ķ�����ʹ��һ���淶ģ����������Ŀ�����������ܽ���һ���ȽϹ淶������,������ʾ��
- ��һ��:�ռ�����
- �ڶ���:ѡ��һ�����ʵ�IDE
- ������:�г������ݼ���Ҫ���еĻ
- ���IJ�:��Ŀ�ܽ�
- ���岽:�ڿ�Դƽ̨�Ϸ��������Ŀ
1.���ݻ�ȡ
ѵ������ѧϰ�㷨�Ĺ����е����һ�ν�С����һ�����������,Ȼ�����������´ο�����ʱ����ʶ����������ֻ��Ҫ�������ӾͿ���ʶ��һ�������塣�����ڻ�����˵�������,����Ҫ�ɰ���ǧ�����Ƶ���������Ϥһ��������Щʾ������������Ҫ�����ݼ���
Ҫѵ������ѧϰ�㷨,��Ҫ����㹻�����ݡ�����,��������,��������ռ�����Ҫ��չ���κ���Ŀ������?
����Դӹٷ���Դ�ռ�Ԥ�ȴ��ڵ����ݼ�,����Դ����ݿ��е�������,�����ֱ�Ӵ���ҳ��ץȡ����,�����ͨ��һЩ�罻ý�������ռ�����,�㻹�����������߱�����������ռ�����������������Դ,��������ռ�����ȡ����������ݿ�ѧ��Ŀ��������ǵ�һ�δ������ݿ�ѧ��Ŀ,��ѡ�������Ȥ�����ݼ������������˶�����Ӱ�������йء����κ������Ȥ�Ķ��������������Ƽ�������ƽʱ��ȡ���ݵ���վ:
- Kaggle ���ݼ�
- UCI ���ݼ�
- world data
- ������վ
- �Լ���ȡ����
������,��ѡ����һ�����ݼ�����ϰԤ��������Ҵ� Kaggle ��վ����ȡ�����ݼ�
�ҵ�github��Ҳ�ϴ��˸���Ŀ�����ݼ�: ���ݼ�
# ���Ȱ�װkaggle
! pip install -q kaggle
# ��kaggle��json�ļ�����
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle config set -n path -v /content
# �������ݼ�����ѹ��
! kaggle datasets download -d mirichoi0218/insurance
! unzip insurance.zip -d health-insurance
2.ѡ��һ��IDE
����������,����������
����������֮��,������һ������ʹ��ʲô�����������ݽ��д���,��ģ��ѡ��һ��������Ϥ�� IDE�������ʹ�� Python����,�����м���������IDE
-
Pycharm �C ����һ��ּ�ڱ�д Python ����� IDE�����ṩ�˸�����������,�������ܴ�����ɡ�������ʹ���������ͨ���ṩ��汾���ƹ��ܵļ���,֧�� Web �����Լ����ݿ�ѧ,ʹ��Ŀά���������
-
Jupyter Notebook �C ����һ����Դ Web Ӧ�ó���,������������������ʵʱ���롢���ӻ����ĵ����������ڼ�����ʹЭ��������
-
Google Colab �C �������û���д��ִ�� Python ���롣���dz��ʺϻ���ѧϰ�����ݿ�ѧ��Ŀ,��Ϊ������ṩ������Դ������������������������ͻ���ѧϰ�㷨,�����ص��Ļ�����ʩ��ɱ���
-
���� .py ��չ���ļ��ı��ļ� ,��������ѡ�������ò�������ʹ��,���������ϲ��ʹ�ü��±���д����,�����ʹ������ʹ�� .py ��չ�������ļ���Ȼ��,�����ʹ���Ϊ��python .py����������������ͬ������⽫ִ����ij���,���������ݿ�ѧ����,����ܲ������ѡ��,��Ϊ������ʱ�����������ӻ��������
������,��ѡ���� Google Colab ��Ϊ��������
��ȡҪʹ�õ����ݺ�,��һ����ͨ�����������������ö����ݵĵ�һӡ�˽ε���ҪĿ���Ƕ����ݽ��������Լ��,����ɴ��������ѷ�����Ѱ�Ҳ����ܻ����ܵ����顣����쳣ֵ��ȱʧֵ,������������Ƿ���ȷ,�������˵������������������?һ���õ������Ƕ���������һЩ��ͳ�Ʋ��Բ�������ӻ�,�Կ����˽����ݵ�ͳ�����Բ������ܵ��쳣ֵ��
3.�г������ݼ�Ҫ���еĻ
�г�Ҫ�����ݼ��Ͻ��еIJ���,�Ա��ڿ�ʼ֮ǰ��һ��������·�������������ݿ�ѧ��Ŀ��ִ�еij���������
���ݶ�ȡ����������������ת����̽�������ݷ�����ģ������ģ��������ģ�Ͳ����������Ҫ������Щ���衣
���ݶ�ȡ�����ݶ��뵽һ��dataframe�Ľṹ,ʹ��pandas
# ���������
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.cbook import boxplot_stats
import statsmodels.api as sm
from sklearn.model_selection import train_test_split,GridSearchCV, cross_val_score, cross_val_predict
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.tree import DecisionTreeRegressor
from sklearn import ensemble
import numpy as np
import pickle
# ��ȡ����,������һ�����������
health_ins_df = pd.read_csv("health-insurance/insurance.csv")
health_ins_df.head()
| index | age | sex | bmi | children | smoker | region | charges |
|---|---|---|---|---|---|---|---|
| 0 | 19 | female | 27.9 | 0 | yes | southwest | 16884.924 |
| 1 | 18 | male | 33.77 | 1 | no | southeast | 1725.5523 |
| 2 | 28 | male | 33.0 | 3 | no | southeast | 4449.462 |
| 3 | 33 | male | 22.705 | 0 | no | northwest | 21984.47061 |
| 4 | 32 | male | 28.88 | 0 | no | northwest | 3866.8552 |
������ϴ:ʶ����������ݼ���ȱʧֵ���쳣ֵ
# �鿴ȱʧֵ
health_ins_df.isnull().sum()
# ���Կ������ݼ���û��ȱʧֵ
age 0
sex 0
bmi 0
children 0
smoker 0
region 0
charges 0
dtype: int64
����ת���������漰�����е��������͡����������л�ɾ���ظ����ݵȵ�
̽�������ݷ������������ݼ�ִ�е������Ͷ��������,�Է����������ص�һЩ��ϵ
��������������ֵ�ͷ��������������������̽�������ݷ�����
̽�������ݷ���
������ֵ�ͱ����ķ���
#��ֵ�ͱ����Ŀ��ӻ�
# ֱ��ͼ����
fig,axes = plt.subplots(1,2,figsize=(12,6))
plt.style.use('ggplot')#ʹ��ggplot����,R���Ե�һ����ͼ��
sns.histplot( health_ins_df['age'] , color="skyblue",ax=axes[0])
sns.histplot( health_ins_df['bmi'] , color="olive",ax=axes[1])
plt.show()
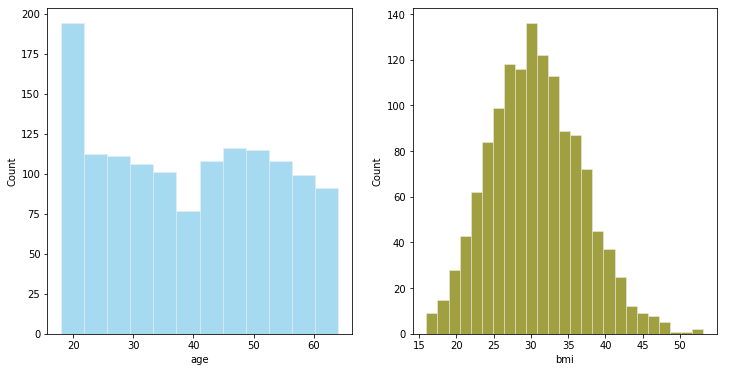
-
���ǿ��������������ת��Ϊ�����
-
BMI�ӽ���̬�ֲ�
# ����ͼ
fig,axes=plt.subplots(1,2,figsize=(10,5))
sns.boxplot(x = 'age', data = health_ins_df, ax=axes[0])
sns.boxplot(x = 'bmi', data = health_ins_df, ax=axes[1])
plt.show()

���Կ���BMI����һЩ��Ⱥֵ , ������������һ����Щ��
outlier_list = boxplot_stats(health_ins_df.bmi).pop(0)['fliers'].tolist()
print(outlier_list)
#���Ұ����쳣ֵ������
outlier_bmi_rows = health_ins_df[health_ins_df.bmi.isin(outlier_list)].shape[0]
print("bmi �а����쳣ֵ������:", outlier_bmi_rows)
#��Ⱥֵռ��
#Percentage of rows which are outliers
percent_bmi_outlier = (outlier_bmi_rows/health_ins_df.shape[0])*100
print("bmi��Ⱥֵ�쳣ֵ�İٷֱ� : ", percent_bmi_outlier)
[49.06, 48.07, 47.52, 47.41, 50.38, 47.6, 52.58, 47.74, 53.13]
bmi �а����쳣ֵ������: 9
bmi��Ⱥֵ�쳣ֵ�İٷֱ� : 0.672645739910314
��ֵ����������ת��
# ������ת��Ϊ��Ͱ��
print("Minimum value for age : ", health_ins_df['age'].min(),"\nMaximum value for age : ", health_ins_df['age'].max())
'''
18��40������佫��������
41��58������佫��������
58�����Ͻ���������
'''
health_ins_df.loc[(health_ins_df['age'] >=18) & (health_ins_df['age'] <= 40), 'age_group'] = '����'
health_ins_df.loc[(health_ins_df['age'] >= 41) & (health_ins_df['age'] <= 58), 'age_group'] = '����'
health_ins_df.loc[health_ins_df['age'] > 58, 'age_group'] = '����'
Minimum value for age : 18
Maximum value for age : 64
# ȥ��BMI�е��쳣ֵ
health_ins_df_clean = health_ins_df[~health_ins_df.bmi.isin(outlier_list)]
sns.boxplot(x = 'bmi', data = health_ins_df_clean)

���ڷ����ͱ����ķ���
fig,axes=plt.subplots(1,5,figsize=(20,8))
sns.countplot(x = 'sex', data = health_ins_df_clean, palette = 'magma',ax=axes[0])
sns.countplot(x = 'children', data = health_ins_df_clean, palette = 'magma',ax=axes[1])
sns.countplot(x = 'smoker', data = health_ins_df_clean, palette = 'magma',ax=axes[2])
sns.countplot(x = 'region', data = health_ins_df_clean, palette = 'magma',ax=axes[3])
sns.countplot(x = 'age_group', data = health_ins_df_clean, palette = 'magma',ax=axes[4])

��������ɺ�,��һ���ǽ�ģ��ѡ����ʵ��㷨��ȡ�������ݵ����͡�����,���������������,����Ӧ�ûع齨ģ,��������Ƿ����,����Ӧ�÷����㷨��ģ����Ϊһ�����ݿ�ѧ��,������������ģ�����������ʵ�ģ�͡�
ģ����
�ڸ���ҵ��/��������ѡ����ȷ��ģ��֮ǰ,���Բ��������ݼ������п��ܵ�ģ�͡��������,��Ҳ���Գ���һЩ bagging �� boosting ������������,�ҷֱ������Իع�ģ�͡��������ع顢Gradient Boosting Regression.
�����Իع�ģ��
������,��������ʹ�����Իع�ģ����Ϊ��ģ�͡�
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']#�Ա�����
y = health_ins_df_processed['charges']#�����
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)#����ѵ�����Ͳ��Լ�
lm.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(lm.score(X_train,y_train)))#ѵ����R2
lm.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(lm.score(X_test,y_test)))#���Լ�R2
R-Squared on train dataset=0.7494776882061486
R-Squaredon test dataset=0.7372938495110573
�ӽ������,ʹ�ü����Իع� R 2 R^2 R2Ϊ0.74,˵��ģ�ͽ���������74%����Ϣ,������������һЩ��complex��ģ��
�������ع�
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']
y = health_ins_df_processed['charges']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
dtr = DecisionTreeRegressor(max_depth=4,min_samples_split=5,max_leaf_nodes=10)#��ʼ������
dtr.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(dtr.score(X_train,y_train)))#ѵ����R2
dtr.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(dtr.score(X_test,y_test)))#���Լ�R2
R-Squared on train dataset=0.8594291626976573
R-Squaredon test dataset=0.8571718114547656
����IJ�����������趨,��һ����Զ�����е��������һ����Ч��,���εĴ������ϴ���github����https://github.com/JoJoYao996/data-science-projects
Gradient Boosting Regression
�ݶ������ع�ģ�͵���Ҫ��������
- learning_rate:ѧϰ��,Ĭ��Ϊ0.1
- n_estimators:Ĭ��Ϊ100
- max_depth:�����ع�������������ȡ����������������еĽڵ����������˲����Ի���������;���ֵȡ�����������������á�ֵ������ [1, inf) ��Χ�ڡ�
- min_samples_split:����ڲ��ڵ��������С������:
- min_samples_leaf:Ҷ�ڵ���С������,���������Ӱ��ģ�͵�ƽ��Ч��,�������ڻع��С�
��ʹ����gridsearch���ֱ����Щ��������,�����ǵ���֮��Ľ����
#���յ�ģ��
f_model = ensemble.GradientBoostingRegressor(learning_rate=0.015,n_estimators=250,max_depth=2,min_samples_leaf=5,
min_samples_split=2,subsample=1,loss = 'squared_error')
f_model.fit(X_train, y_train)
print("Accuracy score (training): {0:.3f}".format(f_model.score(X_train, y_train)))
f_model.fit(X_test, y_test)
print("Accuracy score (test): {0:.3f}".format(f_model.score(X_test, y_test)))
Accuracy score (training): 0.866
Accuracy score (test): 0.818
�鿴��������Ҫ��
#�鿴��������Ҫ��
feature_importance = f_model.feature_importances_
sorted_idx = np.argsort(feature_importance)#�õ���Ҫ�Ե���������
fig = plt.figure(figsize=(12, 6))
pos = np.arange(sorted_idx.shape[0]) + .5
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(health_ins_df_processed.columns)[sorted_idx])
plt.show()

���Կ�������Ҫ������������:smoker_no,children_5,bmi
����ģ��
# ����ģ��
filename = 'health_insurance_data_model.sav'
pickle.dump(f_model, open(filename, 'wb'))
# ����ģ��
filename = 'health_insurance_data_model.sav'
loaded_model = pickle.load(open(filename, 'rb'))
result = loaded_model.score(X_test, y_test)
print(result) #���Լ�����
0.8180114370687565
4.���ܽ�
�ܽ�һ���ĵ�,��Ҫ˵����Ŀ�Լ������Ŀ����ȡ�IJ��衣�����ܽ�����Ƶ�ҵ��������������ݿ�ѧ��������� ͬʱ�������ἰ�йظ���Ŀ������ϸ��,�Թ������ο���
������ʹ�ü� word �ĵ��� powerpoint ��ʾ�ĸ�����ժҪ����������5�����֡��ڵ�һ����,��Ҫ���ͱ��������⡣�ڵڶ�������,�ἰ������Ԥ����������ݼ���ʲô�Լ����ݵ���Դ��ʲô���ڵ� 3 �����ᵽ,��ִ�е���������������ת����̽�������ݷ�����ʲô?Ȼ��,��Ҫ�ἰ�����ԺͲ��Թ��IJ�ͬԤ��ģ�͵ĸ�����֤�����,�������ἰҵ����������ս���ͽ��������
�����Ŀ��ɺ��һ���һ����̵��ܽ�
5.�ڿ�Դƽ̨�Ϸ���
ѡ��һ������Ҫ������ĿժҪ�����Ŀ�Դƽ̨,����github��gitee��,�������������ݿ�ѧ�ҹ�ͨ����,���������Լ�����Ŀ��
ƪ������,��������������ҵ�github����鿴,��ӭ���star,fork��
github��ַ:��������
������ʲ���github�Ŀ���˽���һ�ȡԴ�롣