前言
由于做课题需要运用到3DCNN的知识,所以需要对3DCNN有关知识进行了解和梳理。这篇博客主要介绍了3DCNN的概念、3DCNN工作原理以及3DCNN与2DCNN的区别。这也是本人第一次编写博客,在内容上如有问题,欢迎指出。
文中图片除特殊标注外其他来自于论文:3D Convolutional Neural Networks for Human Action Recognition
1、3DCNN的概念及3DCNN与2DCNN的区别
2DCNN是输入为高度H*宽度W的二维矩阵,是在单通道的一帧图像上进行滑窗操作,这种方式没有考虑到时间维度的帧间运动信息。
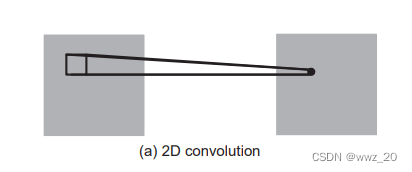
?而3DCNN有三个维度,分别为图像宽度W,图像高度H以及图像通道,过滤器深度<图像深度,卷积核可以在三个方向上移动,使用3D CNN能更好的捕获视频中的时间和空间的特征信息。
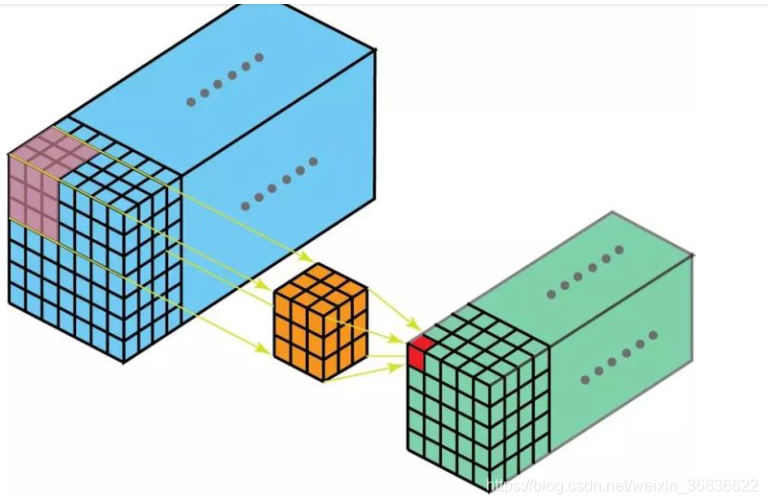
注:此图来自于CSDN博主「YOULANSHENGMENG」
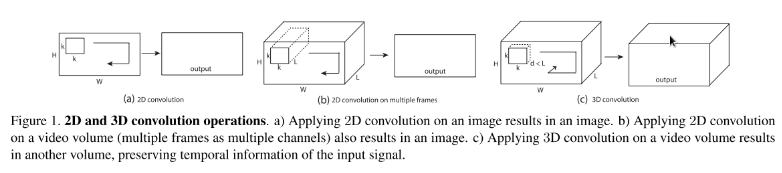
如下图所示,a)和b)分别为2D卷积用于单通道图像和多通道图像的情况(此处多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的图片,即一小段视频),对于一个滤波器,输出为一张二维的特征图,多通道的信息被完全压缩了。而c)中的3D卷积的输出仍然为3D的特征图。也就是说采用2D CNN对视频进行操作的方式,一般都是对视频的每一帧图像分别利用CNN来进行识别,这种方式的识别没有考虑到时间维度的帧间运动信息,而使用3D CNN能更好的捕获视频中的时间和空间的特征信息。
注:此处为CSDN博主「YOULANSHENGMENG」的原创文章
原文链接:https://blog.csdn.net/YOULANSHENGMENG/article/details/121328554
?2、3DCNN工作原理
3D卷积是通过堆叠多个连续的帧为一个立方体,在立方体中运用3D卷积核,在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息。下图则表达了该过程:
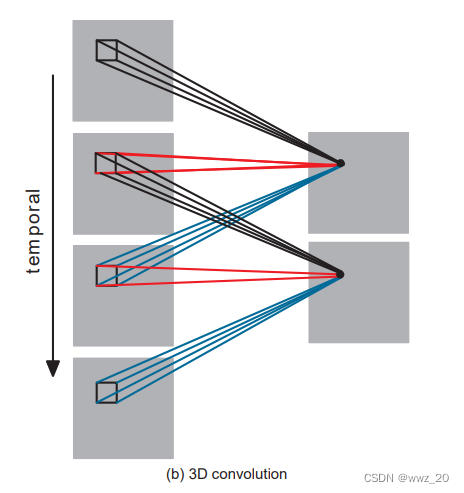
注:相同颜色的连线代表了相同的权值,可以采用多种卷积核,以提取多种特征 。
例如黑色连线同时卷积了相邻的两帧图像,并且运用的是相同的权值,得到的输出即可表达两帧之间的运动变化。