bp������,������Ϊ�ܶ��,���������ѧϰ��?
���ѧϰ����������ʲô����
���ѧϰ���������ϵ2017-01-10�����ʼѧϰ���ѧϰ,�����϶���zouxy09����������,д������,��ȫ��,Ҳ������Լ���˼·,����ɾ��,ϸ������è www.aifamao.com��
�塢DeepLearning�Ļ���˼�����������һ��ϵͳS,����n��(S1,��Sn),����������I,�����O,����ر�ʾΪ:I=>S1=>S2=>��..=>Sn=>O,������O��������I,������I�������ϵͳ�仯֮��û���κε���Ϣ��ʧ(�Ǻ�,��ţ˵,���Dz����ܵġ�
��Ϣ�����и�����Ϣ��㶪ʧ����˵��(��Ϣ��������ʽ),�账��a��Ϣ�õ�b,�ٶ�b�����õ�c,��ô����֤��:a��c�Ļ���Ϣ���ᳬ��a��b�Ļ���Ϣ���������Ϣ��������������Ϣ,�ִ����ᶪʧ��Ϣ��
��Ȼ��,�����������û�õ���Ϣ�Ƕ�ð�),�����˲���,����ζ������I����ÿһ��Si��û���κε���Ϣ��ʧ,�����κ�һ��Si,������ԭ����Ϣ(������I)������һ�ֱ�ʾ��
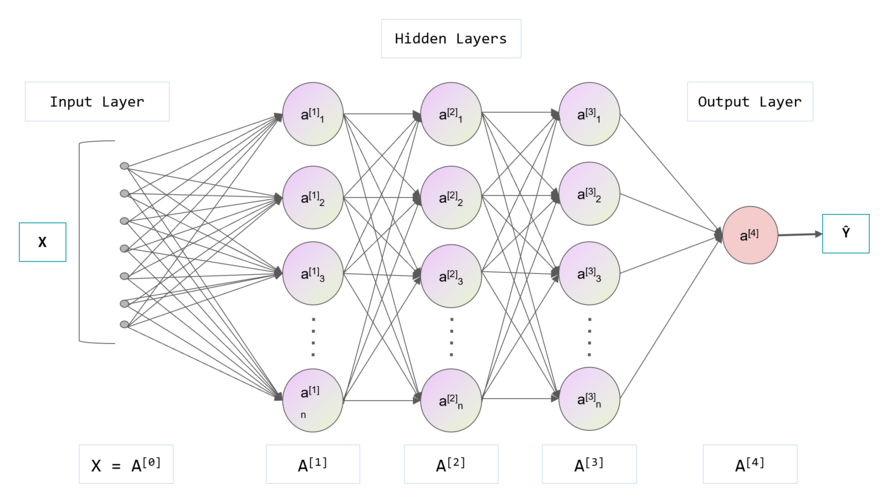
���ڻص����ǵ�����DeepLearning,������Ҫ�Զ���ѧϰ����,����������һ������I(��һ��ͼ������ı�),�������������һ��ϵͳS(��n��),����ͨ������ϵͳ�в���,ʹ�����������Ȼ������I,��ô���ǾͿ����Զ��ػ�ȡ�õ�����I��һϵ�в������,��S1,��,Sn��
�������ѧϰ��˵,��˼����ǶԶѵ������,Ҳ����˵��һ��������Ϊ��һ������롣ͨ�����ַ�ʽ,�Ϳ���ʵ�ֶ�������Ϣ���зּ������ˡ�
����,ǰ���Ǽ�������ϸ�ص�������,�������̫�ϸ�,���ǿ������ط����������,��������ֻҪʹ������������IJ���ܵ�С����,������ɻᵼ������һ�ͬ��DeepLearning������
��������DeepLearning�Ļ���˼�롣����dz��ѧϰ(ShallowLearning)�����ѧϰ(DeepLearning)dz��ѧϰ�ǻ���ѧϰ�ĵ�һ���˳���
20����80���ĩ��,�����˹�������ķ����㷨(Ҳ��BackPropagation�㷨����BP�㷨)�ķ���,������ѧϰ������ϣ��,�����˻���ͳ��ģ�͵Ļ���ѧϰ�ȳ�������ȳ�һֱ���������졣
���Ƿ���,����BP�㷨������һ���˹�������ģ�ʹӴ���ѵ��������ѧϰͳ�ƹ���,�Ӷ���δ֪�¼���Ԥ�⡣���ֻ���ͳ�ƵĻ���ѧϰ���������ȥ�����˹������ϵͳ,�ںܶ���Գ���Խ�ԡ�
���ʱ����˹�������,��Ҳ����������֪��(Multi-layerPerceptron),��ʵ������ֻ����һ������ڵ��dz��ģ�͡�
20����90���,���ָ�����dz�����ѧϰģ����̱����,����֧��������(SVM,SupportVectorMachines)��Boosting������ط���(��LR,LogisticRegression)�ȡ�
��Щģ�͵Ľṹ�����Ͽ��Կ��ɴ���һ������ڵ�(��SVM��Boosting),��û������ڵ�(��LR)����Щģ�������������۷�������Ӧ���ж�����˾�ijɹ���
���֮��,�������۷������Ѷȴ�,ѵ����������Ҫ�ܶྭ��ͼ���,���ʱ��dz���˹������練����Գ��š����ѧϰ�ǻ���ѧϰ�ĵڶ����˳���
2006��,���ô�����ѧ���ڡ�����ѧϰ�����̩��GeoffreyHinton������ѧ��RuslanSalakhutdinov�ڡ���ѧ���Ϸ�����һƪ����,���������ѧϰ��ѧ�����ҵ����˳���
��ƪ������������Ҫ�۵�:1)��������˹�������������������ѧϰ����,ѧϰ�õ��������������и����ʵĿ̻�,�Ӷ������ڿ��ӻ������;2)�����������ѵ���ϵ��Ѷ�,����ͨ��������ʼ����(layer-wisepre-training)����Ч�˷�,����ƪ������,����ʼ����ͨ���ලѧϰʵ�ֵġ�
��ǰ�������ࡢ�ع��ѧϰ����Ϊdz��ṹ�㷨,��������������������ͼ��㵥Ԫ����¶Ը��Ӻ����ı�ʾ��������,��Ը��ӷ��������䷺�������ܵ�һ����Լ��
���ѧϰ��ͨ��ѧϰһ��������������ṹ,ʵ�ָ��Ӻ����ƽ�,�����������ݷֲ�ʽ��ʾ,��չ����ǿ��Ĵ�������������ѧϰ���ݼ�����������������
(���ĺô��ǿ����ý��ٵIJ�����ʾ���ӵĺ���)���ѧϰ��ʵ��,��ͨ���������кܶ�����Ļ���ѧϰģ�ͺͺ�����ѵ������,��ѧϰ�����õ�����,�Ӷ��������������Ԥ���ȷ�ԡ�
���,�����ģ�͡����ֶ�,������ѧϰ����Ŀ�ġ�
�����ڴ�ͳ��dz��ѧϰ,���ѧϰ�IJ�ͬ����:1)ǿ����ģ�ͽṹ�����,ͨ����5�㡢6��,����10��������ڵ�;2)��ȷͻ��������ѧϰ����Ҫ��,Ҳ����˵,ͨ����������任,��������ԭ�ռ��������ʾ�任��һ���������ռ�,�Ӷ�ʹ�����Ԥ��������ס�
���˹������������ķ������,���ô�������ѧϰ����,���ܹ��̻����ݵķḻ������Ϣ��
�ߡ�Deeplearning��NeuralNetwork���ѧϰ�ǻ���ѧϰ�о��е�һ���µ�����,�䶯�����ڽ�����ģ�����Խ��з���ѧϰ��������,��ģ�����ԵĻ�������������,����ͼ��,�������ı���
���ѧϰ���ලѧϰ��һ�֡����ѧϰ�ĸ���Դ���˹���������о�����������Ķ���֪������һ�����ѧϰ�ṹ�����ѧϰͨ����ϵͲ������γɸ��ӳ���ĸ߲��ʾ������������,�Է������ݵķֲ�ʽ������ʾ��
Deeplearning��������machinelearning��һ����֧,��������Ϊneuralnetwork�ķ�չ��
��Լ����ʮ��ǰ,neuralnetwork������ML�����ر���ȵ�һ������,���Ǻ���ȷ����������,ԭ��������¼�������:1)�Ƚ��������,�����Ƚ���tune,������Ҫ����trick;2)ѵ���ٶȱȽ���,�ڲ�αȽ���(С�ڵ���3)�������Ч��������������������;�����м��д�Լ20�����ʱ��,�����类��ע����,���ʱ���������SVM��boosting�㷨�����¡�
����,һ�����ĵ�������Hinton,�����������,������(��������һ��Bengio��Yann.lecun��)�����һ��ʵ�ʿ��е�deeplearning��ܡ�
Deeplearning�봫ͳ��������֮������ͬ�ĵط�Ҳ�кܶͬ��
���ߵ���ͬ����deeplearning���������������Ƶķֲ�ṹ,ϵͳ�ɰ�������㡢����(���)���������ɵĶ������,ֻ�����ڲ�ڵ�֮��������,ͬһ���Լ����ڵ�֮���������,ÿһ����Կ�����һ��logisticregressionģ��;���ֲַ�ṹ,�DZȽϽӽ�������ԵĽṹ�ġ�
��Ϊ�˿˷�������ѵ���е�����,DL��������������ܲ�ͬ��ѵ�����ơ�
��ͳ������(����������Ҫָǰ��������)��,���õ���backpropagation�ķ�ʽ����,���������Dz��õ������㷨��ѵ����������,����趨��ֵ,���㵱ǰ��������,Ȼ����ݵ�ǰ�����label֮��IJ�ȥ�ı�ǰ�����IJ���,ֱ������(������һ���ݶ��½���)��
��deeplearning��������һ��layer-wise��ѵ�����ơ�
��������ԭ������Ϊ,�������backpropagation�Ļ���,����һ��deepnetwork(7������),�в������ǰ��IJ��Ѿ����̫С,������ν��gradientdiffusion(�ݶ���ɢ)��
����������ǽ��������ۡ�
�ˡ�Deeplearningѵ������8.1����ͳ�������ѵ������Ϊʲô�����������������BP�㷨��Ϊ��ͳѵ���������ĵ����㷨,ʵ���϶Խ�����������,��ѵ���������Ѿ��ܲ����롣
��Ƚṹ(�漰��������Դ�����Ԫ��)��Ŀ����ۺ������ձ���ڵľֲ���С��ѵ�����ѵ���Ҫ��Դ��
BP�㷨���ڵ�����:(1)�ݶ�Խ��Խϡ��:�Ӷ���Խ����,���У���ź�Խ��ԽС;(2)�������ֲ���Сֵ:�����Ǵ�Զ����������ʼ��ʱ��(���ֵ��ʼ���ᵼ����������ķ���);(3)һ��,����ֻ�����б�ǩ��������ѵ��:���ֵ�������û��ǩ��,�����Կ��Դ�û�б�ǩ�ĵ�������ѧϰ;8.2��deeplearningѵ��������������в�ͬʱѵ��,ʱ�临�ӶȻ�̫��;���ÿ��ѵ��һ��,ƫ��ͻ���㴫�ݡ�
������ٸ�����ලѧϰ���෴������,������Ƿ���(��Ϊ����������Ԫ�Ͳ���̫����)��
2006��,hinton������ڷǼල�����Ͻ�������������һ����Ч����,��˵,��Ϊ����,һ��ÿ��ѵ��һ������,���ǵ���,ʹԭʼ��ʾx�������ɵĸ���ʾr�ø���ʾr�������ɵ�x'������һ�¡�
������:1)������㹹��������Ԫ,����ÿ�ζ���ѵ��һ���������硣2)�����в�ѵ�����,Hintonʹ��wake-sleep�㷨���е��š�
����������������Ȩ�ر�Ϊ˫���,���������Ȼ��һ������������,�����������Ϊ��ͼģ�͡����ϵ�Ȩ�����ڡ���֪��,���µ�Ȩ�����ڡ����ɡ���Ȼ��ʹ��Wake-Sleep�㷨�������е�Ȩ�ء�
����֪�����ɴ��һ��,Ҳ���DZ�֤���ɵ�����ʾ�ܹ���������ȷ�ĸ�ԭ�ײ�Ľ�㡣
���綥���һ������ʾ����,��ô����������ͼ��Ӧ�ü���������,�����������������ɵ�ͼ��Ӧ���ܹ�����Ϊһ����ŵ�����ͼ��Wake-Sleep�㷨��Ϊ��(wake)��˯(sleep)�������֡�
1)wake��:��֪����,ͨ���������������ϵ�Ȩ��(��֪Ȩ��)����ÿһ��ij����ʾ(���״̬),����ʹ���ݶ��½��IJ�������Ȩ��(����Ȩ��)��
Ҳ���ǡ������ʵ��������IJ�һ��,�ı��ҵ�Ȩ��ʹ��������Ķ������������ġ���2)sleep��:���ɹ���,ͨ�������ʾ(��ʱѧ�õĸ���)������Ȩ��,���ɵײ��״̬,ͬʱ�IJ�����ϵ�Ȩ�ء�
Ҳ���ǡ�������еľ����������е���Ӧ����,�ı��ҵ���֪Ȩ��ʹ�����־������ҿ���������������
deeplearningѵ�����̾�������:1)ʹ�����������Ǽලѧϰ(���Ǵӵײ㿪ʼ,һ��һ���������ѵ��):�����ޱ궨����(�б궨����Ҳ��)�ֲ�ѵ���������,��һ�����Կ�����һ���ලѵ������,�Ǻʹ�ͳ�������������IJ���(������̿��Կ�����featurelearning����):�����,�����ޱ궨����ѵ����һ��,ѵ��ʱ��ѧϰ��һ��IJ���(��һ����Կ����ǵõ�һ��ʹ���������������С�����������������),����ģ��capacity�������Լ�ϡ����Լ��,ʹ�õõ���ģ���ܹ�ѧϰ�����ݱ����Ľṹ,�Ӷ��õ�����������б�ʾ����������;��ѧϰ�õ���n-1���,��n-1��������Ϊ��n�������,ѵ����n��,�ɴ˷ֱ�õ�����IJ���;2)�Զ����µļලѧϰ(����ͨ������ǩ������ȥѵ��,����Զ����´���,�����������):���ڵ�һ���õ��ĸ��������һ��fine-tune�������ģ�͵IJ���,��һ����һ���мලѵ������;��һ������������������ʼ����ֵ����,����DL�ĵ�һ�����������ʼ��,����ͨ��ѧϰ�������ݵĽṹ�õ���,��������ֵ���ӽ�ȫ������,�Ӷ��ܹ�ȡ�ø��õ�Ч��;����deeplearningЧ���úܴ�̶��Ϲ鹦�ڵ�һ����featurelearning���̡�
���ѧϰ���������������ʲô?
��
����������ʵ�����ǻ��ཻ���,����,����������(Convolutionalneuralnetworks,���CNNs)����һ����ȵļලѧϰ�µĻ���ѧϰģ��,�����������(DeepBeliefNets,���DBNs)����һ���ලѧϰ�µĻ���ѧϰģ�͡�
���ѧϰ�ĸ���Դ���˹���������о�����������Ķ���֪������һ�����ѧϰ�ṹ�����ѧϰͨ����ϵͲ������γɸ��ӳ���ĸ߲��ʾ������������,�Է������ݵķֲ�ʽ������ʾ��
���ѧϰ�ĸ�����Hinton������2006��������������Ŷ���(DBN)����Ǽල̰�����ѵ���㷨,Ϊ������ṹ��ص��Ż��������ϣ��,����������Զ����������ṹ��
����Lecun��������ľ����������ǵ�һ���������ṹѧϰ�㷨,�����ÿռ���Թ�ϵ���ٲ�����Ŀ�����ѵ�����ܡ�
�����硢���ѧϰ������ѧϰ��ʲô?��ʲô�������ϵ?
���ѧϰ�������������+����ѧϰ������Ĵʡ�������������deepbeliefnetwork(���(��)��������)�������ʹ�ó��Ŷ�����������ֻ������ഺ��
GPUʹ��������������ʼ��ѵ����Ϊ���ܡ�resnet�ij��ִ����˲�����Ƶ�ħ��,ʹ��ѵ�������ε��������Ϊ���ܡ����ѧϰ���������Ψһ��չ��������
�����ڵ����Ի�����,���ѧϰ��ָ������,�����緺ָ���ѧϰ���ڵ�ǰ���ᄈ��û�����𡣶���������������Ҫ��ָ���Ե�������,�����˹�������ļ���ԭ�͡�
����������˼ά�����ʻ���,˼ά�Ĺ��ܶ�λ�ڴ���Ƥ��,���ߺ��д�Լ10^11����Ԫ,ÿ����Ԫ��ͨ����ͻ�����Լ103��������Ԫ����,�γ�һ���߶ȸ��Ӹ߶����Ķ�̬���硣
��Ϊһ��ѧ��,������������Ҫ�о�����������Ľṹ�����ܼ��乤������,����̽������˼ά�����ܻ�Ĺ��ɡ�
�˹���������������������ij�ּ������µļ�������,��Ϊһ��ѧ��,������Ҫ�����Ǹ��������������ԭ����ʵ��Ӧ�õ���Ҫ����ʵ�õ��˹�������ģ��,�����Ӧ��ѧϰ�㷨,ģ�����Ե�ij�����ܻ,Ȼ���ڼ�����ʵ�ֳ������Խ��ʵ�����⡣
���,������������Ҫ�о����ܵĻ���;�˹���������Ҫ�о����ܻ�����ʵ��,�����ศ��ɡ�
���ѧϰ���������������ʲô
��
����������ʵ�����ǻ��ཻ���,����,����������(Convolutionalneuralnetworks,���CNNs)����һ����ȵļලѧϰ�µĻ���ѧϰģ��,�����������(DeepBeliefNets,���DBNs)����һ���ලѧϰ�µĻ���ѧϰģ�͡�
���ѧϰ�ĸ���Դ���˹���������о�����������Ķ���֪������һ�����ѧϰ�ṹ�����ѧϰͨ����ϵͲ������γɸ��ӳ���ĸ߲��ʾ������������,�Է������ݵķֲ�ʽ������ʾ��
���ѧϰ�ĸ�����Hinton������2006��������������Ŷ���(DBN)����Ǽල̰�����ѵ���㷨,Ϊ������ṹ��ص��Ż��������ϣ��,����������Զ����������ṹ��
����Lecun��������ľ����������ǵ�һ���������ṹѧϰ�㷨,�����ÿռ���Թ�ϵ���ٲ�����Ŀ�����ѵ�����ܡ�
���ѧϰ���������������ʲô?
�ӹ�����˵���ѧϰ������ṹҲ�Ƕ���������һ�֡���ͳ�����ϵĶ����������ֻ������㡢���ز㡢����㡣�������ز�IJ���������Ҫ����,û����ȷ�������Ƶ���˵�������ٲ���ʡ�
�����ѧϰ���������ľ���������CNN,��ԭ�����������Ļ�����,����������ѧϰ����,�ⲿ����ģ�����Զ��źŴ����ϵķּ��ġ�
�������������ԭ����ȫ���ӵIJ�ǰ������˲������ӵľ������뽵ά��,���Ҽ������һ���㼶��
�����-������-��ά��-������-��ά��--....--���ز�-��������˵,ԭ��������������IJ�����:����ӳ�䵽ֵ���������˹���ѡ�����ѧϰ���IJ������ź�->����->ֵ��
�������������Լ�ѡ��
�����ѧϰ���͡���������硱������
BP������,ָ�������ˡ�BP�㷨������ѵ���ġ�����֪��ģ�͡���
����֪��(MLP,MultilayerPerceptron)��һ��ǰ���˹�������ģ��,�佫����Ķ�����ݼ�ӳ�䵽��һ����������ݼ���,���Խ���κ����Բ��ɷ����⡣��Ҫ���㷨���������ˡ�
ʲô��BP������?
��
BP�㷨�Ļ���˼����:ѧϰ�������ź����������ķ���ش������������;����ʱ,��������������㴫��,��������������㴦��,���������,��������������������,�������Ϊ�����ź���㷴��ش�,����Ԫ֮�������Ȩ������������,ʹ����С��
������ѧϰ,����ʹ����С���ɽ��ܵķ�Χ�����岽������:1����ѵ������ȡ��ijһ����,����Ϣ���������С�2��ͨ�����ڵ����������������㴦����,�õ��������ʵ�������
3����������ʵ������������������4���������㷴��ش���֮ǰ����,����һ��ԭ������źż��ص�����Ȩֵ��,ʹ���������������Ȩֵ������С�ķ���ת����
5����ѵ������ÿһ�����롪����������ظ����ϲ���,ֱ������ѵ��������������С������Ҫ��Ϊֹ��
ǰ�������硢BP�����硢�������������������ϵ
һ�����㷽����ͬ1��ǰ��������:һ�����������,����Ԫ�ֲ����С�ÿ����Ԫֻ��ǰһ�����Ԫ����������ǰһ������,���������һ��.�����û�з�����
2��BP������:��һ�ְ�����������㷨ѵ���Ķ��ǰ�������硣3������������:�������������Ҿ�����Ƚṹ��ǰ�������硣
������;��ͬ1��ǰ��������:��ҪӦ�ð�����֪�����硢BP�����RBF���硣
2��BP������:(1)�����ƽ�:��������������Ӧ���������ѵ��һ������ƽ�һ������;(2)ģʽʶ��:��һ�������������������������������ϵ����;(3)����:����������������ĺ��ʷ�ʽ���з���;(4)����ѹ��:�����������ά���Ա��ڴ����洢��
3������������:��Ӧ����ͼ��ʶ������ʶ��ȼ�����Ӿ�����Ȼ���Դ���������ѧ��ң�п�ѧ��������ϵ:BP������;��������綼����ǰ��������,���߶������˹������硣���,����ԭ���ͽṹ��ͬ��
�������ò�ͬ1��ǰ��������:�ṹ��,Ӧ�ù㷺,�ܹ������⾫�ȱƽ���������������ƽ���ɻ�����.���ҿ��Ծ�ȷʵ����������ѵ����������2��BP������:���к�ǿ�ķ�����ӳ�����������Ե�����ṹ��
������м�������������Ԫ�����ɸ��ݾ�����������趨,�������Žṹ�IJ���������Ҳ������ͬ��3������������:���б���ѧϰ����,�ܹ�����ײ�ṹ��������Ϣ����ƽ�Ʋ�����ࡣ
��չ����:1��BP������������BP�������������������ۻ��������ܷ����ѱȽϳ��졣��ͻ���ŵ���Ǿ��к�ǿ�ķ�����ӳ�����������Ե�����ṹ��
������м�������������Ԫ�����ɸ��ݾ�����������趨,�������Žṹ�IJ���������Ҳ������ͬ������BP������Ҳ�������µ�һЩ��Ҫȱ�ݡ�
��ѧϰ�ٶ���,��ʹ��һ��������,һ��Ҳ��Ҫ���ٴ�������ǧ�ε�ѧϰ��������������������ֲ���Сֵ���������������Ԫ������ѡ��û����Ӧ������ָ�����������ƹ��������ޡ�
2���˹���������ص����Խ��,��Ҫ������������������پ�����ѧϰ���ܡ�
����ʵ��ͼ��ʶ��ʱ,ֻ���Ȱ����ͬ��ͼ������Ͷ�Ӧ��Ӧʶ��Ľ�������˹�������,����ͻ�ͨ����ѧϰ����,����ѧ��ʶ�����Ƶ�ͼ����ѧϰ���ܶ���Ԥ�����ر���Ҫ�����塣
Ԥ��δ�����˹�������������Ϊ�����ṩ����Ԥ�⡢Ч��Ԥ��,��Ӧ��ǰ;�Ǻ�Զ��ġ��ھ�������洢���ܡ����˹�������ķ�������Ϳ���ʵ���������롣�۾��и���Ѱ���Ż����������
Ѱ��һ������������Ż���,������Ҫ�ܴ�ļ�����,����һ�����ij�������Ƶķ������˹�������,���Ӽ�����ĸ�����������,���ܺܿ��ҵ��Ż��⡣
�ο�����:�ٶȰٿơ�ǰ��������ٶȰٿơ�BP������ٶȰٿơ�����������ٶȰٿơ��˹������硣
���ѧϰ����ѧʲô?
���ѧϰ���嶼��ѧ�����硢BP�����㷨��TensorFlow���ѧϰ���ߵȡ�
����������Ҫѧϰ����:��������Ԫ���˹���Ԫ�����Relu��Tanh��Sigmoid�������������������ع��������������������Softmax�ع���������������ز�������ά��ά�������ز㼤��������Ƿ����Ե�ԭ����������sklearnģ���е�ʹ��ˮ��ǿ��Ԥ�ⰸ������������������BP�����㷨��Ҫѧϰ����:BP����Ŀ����ʽ����BP�����Ƶ���ͬ������ڷ���Ӧ�ò�ͬ��ʧ�����ڷ���Ӧ��Pythonʵ��������ʵս����TensorFlow���ѧϰ������Ƶ�:TF��װ(����CUDA��cudnn��װ)TFʵ�ֶ�Ԫ���Իع�֮���������TFʵ�ֶ�Ԫ���Իع�֮�ݶ��½����TFԤ��california���۰���TFʵ��Softmax�ع�Softmax����MNIST��д����ʶ����Ŀ����TF���ģ�͵ı���ͼ���8)TFʵ��DNN���������9)DNN����MNIST��д����ʶ����Ŀ����10)Tensorboardģ����ӻ���Щ�������ѧϰ�漰����һЩ֪ʶ,һ����˵���������������㷨�����Ż��㷨,����TensorFlow��������,ͨ��ʵ����������ɻع�ͷ�������
TensorFlow���ѧ����,�������ѧϰ��ܱ���Keras��PyTorch�����������練�ơ�������Խ���һЩʵս,�����Ÿ�������
?