引言
本文会结合论文UNETR: Transformers for 3D Medical Image Segmentation和代码深入讲解。阅读这篇文章之前最好了解UNET网络和Transformer网络,我之前的博文有总结过,可以参考下。动手实现基于pytorch框架的UNet模型以及Transformer 代码详解(Pytorch版)
推荐阅读的UNETR代码实现
- 官方Code:https://github.com/Project-MONAI/research-contributions/tree/master/UNETR/BTCV
- self-attention-cv:https://github.com/The-AI-Summer/self-attention-cv
- tamasino52:https://github.com/tamasino52/UNETR
本文采用的tamasino52实现的UNETR来讲解的,主要原因是tamasino52主要用pytorch中的API实现,而且只有一个py文件,也比较简单,方便学习,环境安装简单。官方代码是放在MONAI库中了,你需要安装MONAI环境才能运行,但是不是所有的读者都需要了解MONAI。如果你想学习MONAI中的源码实现,读了这篇文章再去看MONIA中UNETR,也是没有任何压力的。
摘要
近年来,具有收缩路径和扩展路径(例如编码器和解码器)的全卷积神经网络(FCNN)在各种医学图像分割应用中表现出突出的地位。在这些架构中编码器通过学习全局上下文语义特征,发挥了不可或缺的重要作用,这将进一步用于解码器的语义输出预测。尽管它们取得了成功。但作为fcnn的主要构件,卷积层的局部性限制了在这类网络中学习远程空间依赖性的能力(图像中相距较远的两个像素之间的相关性)。受最近自然语言处理(NLP)转换器在远程序列学习中的成功的启发,我们将体积(3D)医学图像分割的任务重新表述为一个序列到序列的预测问题。特别地,我们引入了一种新的架构,称为UNEt转换器(UNETR),它利用一个纯transformer作为编码器来学习输入体数据的序列表示,并有效地捕获全局多尺度信息。transformer码器通过不同分辨率的跳过连接直接连接到解码器
相关工作
在一个典型的U-Net架构中,编码器负责通过逐步降低提取特征的采样来学习全局上下文表示,而解码器负责将提取的表示采样到输入分辨率,以进行像素/体素的语义预测。此外,跳过连接合并编码器的输出和解码器在不同的分辨率,因此允许恢复在降采样期间丢失的空间信息。虽然这种基于FCN的方法具有强大的表示学习能力,但它们在远程依赖学习中的表现,仅限于它们的局部接受域。因此,这种在多尺度信息捕获方面的缺陷导致了对不同形状和尺度的结构(如不同大小的脑损伤)的次优分割存在不足。这些网络的一个局限性是它们在学习全局环境和长期空间依赖方面的表现较差,这将严重影响对具有挑战性的任务的分割性能
视觉Transformers最近获得了计算机视觉任务的关注。Dosovitskiy等人通过对纯Transformers进行大规模的预训练和微调,展示了图像分类数据的最先进性能。最近有人探索使用基于Transformers的模型进行二维图像分割的可能性,Zheng等人引入了SETR模型,其中预训练的Transformers编码器与不同的基于CNN的解码器被提出用于语义分割任务。
作者的模型与这些工作有关键的区别:
- UNETR是为3D分割而量身定制的,并直接利用体积数据
- UNETR使用transformer作为分割网络的主要编码器,并通过跳过连接将其直接连接到解码器,而不是使用其作为分割网络中的注意层
- UNETR不依赖于主干CNN来生成输入序列,而是直接利用标记化的补丁。
方法论
架构设计
我们提出的模型由一个直接利用三维补丁的transformer编码器组成,并通过跳过连接连接到一个基于cnn的解码器。
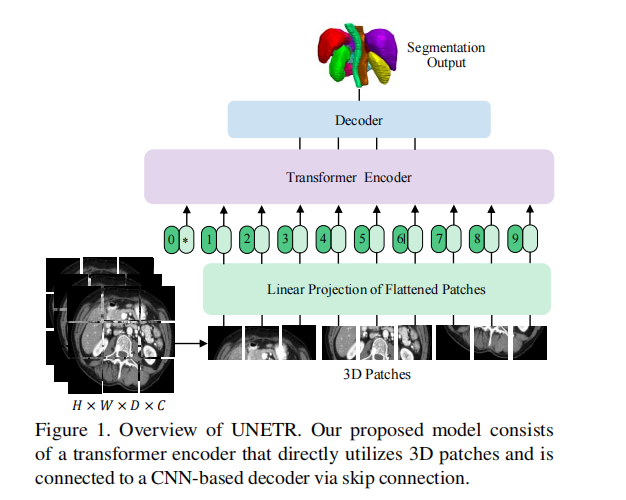
一个三维输入体(例如,MRI图像的C=4通道),被划分为一系列均匀的不重叠的斑块,并使用一个线性层投影到一个嵌入空间中。该序列在添加时嵌入了一个位置,并被用作变压器模型的输入。提取变压器中不同层的编码表示,并通过跳过连接与解码器合并,以预测最终的分割。输出大小给出了补丁分辨率P=16和嵌入大小K=768。
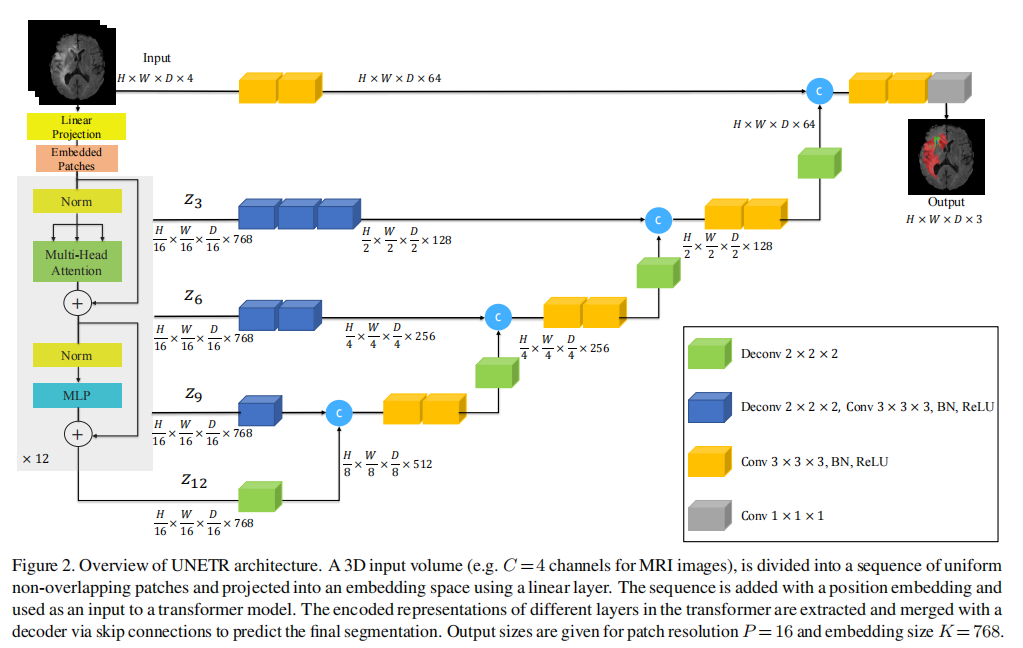
下面结合代码代码讲解架构图中的各个部分
架构图中几个基本单元的实现
SingleDeconv3DBlock

class SingleDeconv3DBlock(nn.Module):
'''
使用转置卷积来实现上采样
'''
def __init__(self, in_planes, out_planes):
super().__init__()
self.block = nn.ConvTranspose3d(in_planes, out_planes, kernel_size=2, stride=2, padding=0, output_padding=0)
def forward(self, x):
return self.block(x)
SingleConv3DBlock
class SingleConv3DBlock(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size):
super().__init__()
self.block = nn.Conv3d(in_planes, out_planes, kernel_size=kernel_size, stride=1,
padding=((kernel_size - 1) // 2))
def forward(self, x):
return self.block(x)
Conv3DBlock

class Conv3DBlock(nn.Module):
'''
decoder的三维卷积模块
conv3x3x3,BN,Relu
'''
def __init__(self, in_planes, out_planes, kernel_size=3):
super().__init__()
self.block = nn.Sequential(
SingleConv3DBlock(in_planes, out_planes, kernel_size),
nn.BatchNorm3d(out_planes),
nn.ReLU(True)
)
def forward(self, x):
return self.block(x)
Deconv3DBlock
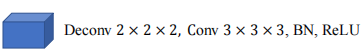
class Deconv3DBlock(nn.Module):
'''
反卷积上采样模块
deconv2x2x2,conv3x3x3,BN,Relu
'''
def __init__(self, in_planes, out_planes, kernel_size=3):
super().__init__()
self.block = nn.Sequential(
SingleDeconv3DBlock(in_planes, out_planes),
SingleConv3DBlock(out_planes, out_planes, kernel_size),
nn.BatchNorm3d(out_planes),
nn.ReLU(True)
)
def forward(self, x):
return self.block(x)
transformer 编码器部分
embedded patches
class Embeddings(nn.Module):
'''
embedded patches
'''
def __init__(self, input_dim, embed_dim, cube_size, patch_size, dropout):
super().__init__()
#计算有多少个patch
self.n_patches = int((cube_size[0] * cube_size[1] * cube_size[2]) / (patch_size * patch_size * patch_size))
# patch的大小
self.patch_size = patch_size
# 嵌入的尺寸大小,默认768
self.embed_dim = embed_dim
#使用3D卷积计算patch embedding
# 在NLP中语言序列是1D的序列使用朋友torch中的nn.Embedding()
self.patch_embeddings = nn.Conv3d(in_channels=input_dim, out_channels=embed_dim,
kernel_size=patch_size, stride=patch_size)
# 设置一个可以学习的嵌入位置参数
#将一个固定不可训练的tensor转换成可以训练的类型parameter,并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),
# 所以经过类型转换这个self.position_embeddings变成了模型的一部分,成为了模型中根据训练可以改动的参数了。
# 使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化
self.position_embeddings = nn.Parameter(torch.zeros(1, self.n_patches, embed_dim))
#dropout 层
self.dropout = nn.Dropout(dropout)
def forward(self, x):
#[1,4,128,128,128]->[1,768,8,8,8]
x = self.patch_embeddings(x)
#从dim=2开始展平->[1,768,512]
x = x.flatten(2)
x = x.transpose(-1, -2) #[1,512,768]
# 直接加上位置信息
embeddings = x + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings
SelfAttention
多头自注意力模块实现
class SelfAttention(nn.Module):
'''
transformer结构的核心模块:自注意力模块
学习Wq,Wk,Wv矩阵
# 输入和输出是相同的的尺寸[B,Seq_dim,embded_dim]
'''
def __init__(self, num_heads, embed_dim, dropout):
super().__init__()
self.num_attention_heads = num_heads
self.attention_head_size = int(embed_dim / num_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
#query,key,value 具体实现是一个线性层(全量就层) 输入维度是K/n,输出维度是K
self.query = nn.Linear(embed_dim, self.all_head_size)
self.key = nn.Linear(embed_dim, self.all_head_size)
self.value = nn.Linear(embed_dim, self.all_head_size)
self.out = nn.Linear(embed_dim, embed_dim)
self.attn_dropout = nn.Dropout(dropout)
self.proj_dropout = nn.Dropout(dropout)
self.softmax = nn.Softmax(dim=-1)
self.vis = False
def transpose_for_scores(self, x):
#x.shape=[1,512,768]
# reshape tensor 到需要的维度[B,embded_dim,heads,head_size] torch.Size([1, 512, 12, 64])
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Q 和 K 计算出 scores,然后将 scores 和 V 相乘,得到每个patch的context vector
#1.SA(z) = Softmax( qk> √Ch )v,计算出 scores
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) # torch.Size([1, 12, 512, 512])
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = self.softmax(attention_scores)
weights = attention_probs if self.vis else None
attention_probs = self.attn_dropout(attention_probs)
#2.scores 和 V 相乘
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()#torch.Size([1, 12, 512, 64])
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)#torch.Size([1, 512, 768])
context_layer = context_layer.view(*new_context_layer_shape)
# 最后的一个线性输出层
attention_output = self.out(context_layer)
#加了一个dropout层
attention_output = self.proj_dropout(attention_output)
return attention_output, weights
Transformer Block
class TransformerBlock(nn.Module):
'''
可重复的transformer block
Norm->MSA->Norm->MLP
'''
def __init__(self, embed_dim, num_heads, dropout, cube_size, patch_size):
super().__init__()
#归一化,在一个样本上做归一化操作这里是laerNorm 而不是BatchNorm
self.attention_norm = nn.LayerNorm(embed_dim, eps=1e-6)
self.mlp_norm = nn.LayerNorm(embed_dim, eps=1e-6)
#mlp dim
self.mlp_dim = int((cube_size[0] * cube_size[1] * cube_size[2]) / (patch_size * patch_size * patch_size))
self.mlp = PositionwiseFeedForward(embed_dim, 2048)
self.attn = SelfAttention(num_heads, embed_dim, dropout)
def forward(self, x):
h = x
#1.NORM
x = self.attention_norm(x)
#2.MSA
x, weights = self.attn(x)
# 残差链接
x = x + h
h = x
#3.MLP
x = self.mlp_norm(x)
x = self.mlp(x)
#残差链接
x = x + h
return x, weights
MLP
作者实现了2个版本
class PositionwiseFeedForward(nn.Module):
'''
位置级前馈网络
除了注意子层外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络.
它分别和相同地应用于每个位置。这由两个线性变换组成.中间有一个ReLU激活。
FFN(x) = max(0, xW1 + b1)W2 + b2 (2)
'''
def __init__(self, d_model=786, d_ff=2048, dropout=0.1):
super().__init__()
# Torch linears have a `b` by default.
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
#Residual Dropout
self.dropout = nn.Dropout(dropout)
class Mlp(nn.Module):
'''
MLP 层
采用高斯误差线性单元激活函数GELU
zi = MLP(Norm(z0i)) + z0i,
'''
def __init__(self, in_features, act_layer=nn.GELU, drop=0.):
super().__init__()
self.fc1 = nn.Linear(in_features, in_features)
self.act = act_layer()
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1()
x = self.act(x)
x = self.drop(x)
return x
TransformerBlock
class TransformerBlock(nn.Module):
'''
可重复的transformer block
Norm->MSA->Norm->MLP
'''
def __init__(self, embed_dim, num_heads, dropout, cube_size, patch_size):
super().__init__()
#归一化,在一个样本上做归一化操作这里是laerNorm 而不是BatchNorm
self.attention_norm = nn.LayerNorm(embed_dim, eps=1e-6)
self.mlp_norm = nn.LayerNorm(embed_dim, eps=1e-6)
#mlp dim
self.mlp_dim = int((cube_size[0] * cube_size[1] * cube_size[2]) / (patch_size * patch_size * patch_size))
self.mlp = PositionwiseFeedForward(embed_dim, 2048)
self.attn = SelfAttention(num_heads, embed_dim, dropout)
def forward(self, x):
h = x
#1.NORM
x = self.attention_norm(x)
#2.MSA
x, weights = self.attn(x)
# 残差链接
x = x + h
h = x
#3.MLP
x = self.mlp_norm(x)
x = self.mlp(x)
#残差链接
x = x + h
return x, weights
Transformer
class Transformer(nn.Module):
"""
tansformer as the encoder:
Args:
input_dim:=4(MRI数据,多channel)
输入数据的channel
embed_dim:=768
embedding 的尺寸
cube_size:
体数据的尺寸
patch_size:=16
补丁的个数
num_heads:=12
有多少个Multi-Head
num_layers:
layer的数目对应num_heads
dropout:0.1
随机dropout的概率
extract_layers:=[3,6,9,12]
提取特征的层
"""
def __init__(self, input_dim, embed_dim, cube_size, patch_size, num_heads, num_layers, dropout, extract_layers):
super().__init__()
self.embeddings = Embeddings(input_dim, embed_dim, cube_size, patch_size, dropout)
self.layer = nn.ModuleList()
self.encoder_norm = nn.LayerNorm(embed_dim, eps=1e-6)
self.extract_layers = extract_layers
for _ in range(num_layers):
layer = TransformerBlock(embed_dim, num_heads, dropout, cube_size, patch_size)
self.layer.append(copy.deepcopy(layer))
def forward(self, x):
extract_layers = []
hidden_states = self.embeddings(x)
for depth, layer_block in enumerate(self.layer):
hidden_states, _ = layer_block(hidden_states)
if depth + 1 in self.extract_layers:
extract_layers.append(hidden_states)
return extract_layers
解码器和最总的UNET类
UNETR
class UNETR
(nn.Module):
def __init__(self, img_shape=(128, 128, 128), in_channels=4, out_channels=3, embed_dim=768, patch_size=16, num_heads=12, dropout=0.1):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.embed_dim = embed_dim
self.img_shape = img_shape
self.patch_size = patch_size
self.num_heads = num_heads
self.dropout = dropout
self.num_layers = 12
self.ext_layers = [3, 6, 9, 12]
self.patch_dim = [int(x / patch_size) for x in img_shape]
# Transformer Encoder
self.transformer = \
Transformer(
in_channels,
embed_dim,
img_shape,
patch_size,
num_heads,
self.num_layers,
dropout,
self.ext_layers
)
# U-Net Decoder
self.decoder0 = \
nn.Sequential(
Conv3DBlock(in_channels, 32, 3),
Conv3DBlock(32, 64, 3)
)
self.decoder3 = \
nn.Sequential(
Deconv3DBlock(embed_dim, 512),
Deconv3DBlock(512, 256),
Deconv3DBlock(256, 128)
)
self.decoder6 = \
nn.Sequential(
Deconv3DBlock(embed_dim, 512),
Deconv3DBlock(512, 256),
)
self.decoder9 = \
Deconv3DBlock(embed_dim, 512)
self.decoder12_upsampler = \
SingleDeconv3DBlock(embed_dim, 512)
self.decoder9_upsampler = \
nn.Sequential(
Conv3DBlock(1024, 512),
Conv3DBlock(512, 512),
#Conv3DBlock(512, 512),
SingleDeconv3DBlock(512, 256)
)
self.decoder6_upsampler = \
nn.Sequential(
Conv3DBlock(512, 256),
Conv3DBlock(256, 256),
SingleDeconv3DBlock(256, 128)
)
self.decoder3_upsampler = \
nn.Sequential(
Conv3DBlock(256, 128),
Conv3DBlock(128, 128),
SingleDeconv3DBlock(128, 64)
)
self.decoder0_header = \
nn.Sequential(
Conv3DBlock(128, 64),
Conv3DBlock(64, 64),
SingleConv3DBlock(64, out_channels, 1)
)
def forward(self, x):
z = self.transformer(x)#z=[4,1,512,768]
z0, z3, z6, z9, z12 = x, *z
#[1,512,768]->[1,768,8,8,8]
z3 = z3.transpose(-1, -2).view(-1, self.embed_dim, *self.patch_dim)
z6 = z6.transpose(-1, -2).view(-1, self.embed_dim, *self.patch_dim)
z9 = z9.transpose(-1, -2).view(-1, self.embed_dim, *self.patch_dim)
z12 = z12.transpose(-1, -2).view(-1, self.embed_dim, *self.patch_dim)
z12 = self.decoder12_upsampler(z12)
z9 = self.decoder9(z9)
z9 = self.decoder9_upsampler(torch.cat([z9, z12], dim=1))
z6 = self.decoder6(z6)
z6 = self.decoder6_upsampler(torch.cat([z6, z9], dim=1))
z3 = self.decoder3(z3)
z3 = self.decoder3_upsampler(torch.cat([z3, z6], dim=1))
z0 = self.decoder0(z0)
output = self.decoder0_header(torch.cat([z0, z3], dim=1))
return output
模型的可学习参数和尺寸信息如下:
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
UNETR [1, 3, 128, 128, 128] --
├─Transformer: 1-1 [1, 512, 768] 66,169,344
│ └─Embeddings: 2-1 [1, 512, 768] --
│ │ └─Conv3d: 3-1 [1, 768, 8, 8, 8] 12,583,680
│ │ └─Dropout: 3-2 [1, 512, 768] --
│ └─ModuleList: 2 -- --
│ │ └─TransformerBlock: 3-3 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-4 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-5 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-6 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-7 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-8 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-9 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-10 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-11 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-12 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-13 [1, 512, 768] 5,513,984
│ │ └─TransformerBlock: 3-14 [1, 512, 768] 5,513,984
├─SingleDeconv3DBlock: 1-2 [1, 512, 16, 16, 16] --
│ └─ConvTranspose3d: 2-2 [1, 512, 16, 16, 16] 3,146,240
├─Deconv3DBlock: 1-3 [1, 512, 16, 16, 16] --
│ └─Sequential: 2-3 [1, 512, 16, 16, 16] --
│ │ └─SingleDeconv3DBlock: 3-15 [1, 512, 16, 16, 16] 3,146,240
│ │ └─SingleConv3DBlock: 3-16 [1, 512, 16, 16, 16] 7,078,400
│ │ └─BatchNorm3d: 3-17 [1, 512, 16, 16, 16] 1,024
│ │ └─ReLU: 3-18 [1, 512, 16, 16, 16] --
├─Sequential: 1-4 [1, 256, 32, 32, 32] --
│ └─Conv3DBlock: 2-4 [1, 512, 16, 16, 16] --
│ │ └─Sequential: 3-19 [1, 512, 16, 16, 16] 14,157,312
│ └─Conv3DBlock: 2-5 [1, 512, 16, 16, 16] --
│ │ └─Sequential: 3-20 [1, 512, 16, 16, 16] 7,079,424
│ └─SingleDeconv3DBlock: 2-6 [1, 256, 32, 32, 32] --
│ │ └─ConvTranspose3d: 3-21 [1, 256, 32, 32, 32] 1,048,832
├─Sequential: 1-5 [1, 256, 32, 32, 32] --
│ └─Deconv3DBlock: 2-7 [1, 512, 16, 16, 16] --
│ │ └─Sequential: 3-22 [1, 512, 16, 16, 16] 10,225,664
│ └─Deconv3DBlock: 2-8 [1, 256, 32, 32, 32] --
│ │ └─Sequential: 3-23 [1, 256, 32, 32, 32] 2,819,072
├─Sequential: 1-6 [1, 128, 64, 64, 64] --
│ └─Conv3DBlock: 2-9 [1, 256, 32, 32, 32] --
│ │ └─Sequential: 3-24 [1, 256, 32, 32, 32] 3,539,712
│ └─Conv3DBlock: 2-10 [1, 256, 32, 32, 32] --
│ │ └─Sequential: 3-25 [1, 256, 32, 32, 32] 1,770,240
│ └─SingleDeconv3DBlock: 2-11 [1, 128, 64, 64, 64] --
│ │ └─ConvTranspose3d: 3-26 [1, 128, 64, 64, 64] 262,272
├─Sequential: 1-7 [1, 128, 64, 64, 64] --
│ └─Deconv3DBlock: 2-12 [1, 512, 16, 16, 16] --
│ │ └─Sequential: 3-27 [1, 512, 16, 16, 16] 10,225,664
│ └─Deconv3DBlock: 2-13 [1, 256, 32, 32, 32] --
│ │ └─Sequential: 3-28 [1, 256, 32, 32, 32] 2,819,072
│ └─Deconv3DBlock: 2-14 [1, 128, 64, 64, 64] --
│ │ └─Sequential: 3-29 [1, 128, 64, 64, 64] 705,024
├─Sequential: 1-8 [1, 64, 128, 128, 128] --
│ └─Conv3DBlock: 2-15 [1, 128, 64, 64, 64] --
│ │ └─Sequential: 3-30 [1, 128, 64, 64, 64] 885,120
│ └─Conv3DBlock: 2-16 [1, 128, 64, 64, 64] --
│ │ └─Sequential: 3-31 [1, 128, 64, 64, 64] 442,752
│ └─SingleDeconv3DBlock: 2-17 [1, 64, 128, 128, 128] --
│ │ └─ConvTranspose3d: 3-32 [1, 64, 128, 128, 128] 65,600
├─Sequential: 1-9 [1, 64, 128, 128, 128] --
│ └─Conv3DBlock: 2-18 [1, 32, 128, 128, 128] --
│ │ └─Sequential: 3-33 [1, 32, 128, 128, 128] 3,552
│ └─Conv3DBlock: 2-19 [1, 64, 128, 128, 128] --
│ │ └─Sequential: 3-34 [1, 64, 128, 128, 128] 55,488
├─Sequential: 1-10 [1, 3, 128, 128, 128] --
│ └─Conv3DBlock: 2-20 [1, 64, 128, 128, 128] --
│ │ └─Sequential: 3-35 [1, 64, 128, 128, 128] 221,376
│ └─Conv3DBlock: 2-21 [1, 64, 128, 128, 128] --
│ │ └─Sequential: 3-36 [1, 64, 128, 128, 128] 110,784
│ └─SingleConv3DBlock: 2-22 [1, 3, 128, 128, 128] --
│ │ └─Conv3d: 3-37 [1, 3, 128, 128, 128] 195
====================================================================================================
Total params: 148,955,299
Trainable params: 148,955,299
Non-trainable params: 0
Total mult-adds (T): 2.18
====================================================================================================
Input size (MB): 33.55
Forward/backward pass size (MB): 12128.88
Params size (MB): 594.24
Estimated Total Size (MB): 12756.68
====================================================================================================
另外代码放在了github上
结论
- 本文介绍了一种新颖的基于Transformer的结构,称为UNETR,用于体积医学图像的语义分割,将该任务重新定义为一个一维序列到序列的预测问题。作者建议使用Transformers编码器来提高模型的能力,以学习远程依赖关系,并在多个尺度上有效地捕获全局上下文表示。
- 验证了UNETR在CT和MRI不同体积分割任务中的有效性。在BTCV多器官分割排行榜上,UNETR竞赛中取得了最新的水平表现,并在MSD数据集上优于脑肿瘤和脾脏分割的竞争方法。该方法可作为医学图像分析中一类新的基于Transformers的分割模型的基础。
写在最后
更多详细信息可查阅论文:UNETR: Transformers for 3D Medical Image Segmentation
参考博文:
- https://blog.csdn.net/weixin_49627776/article/details/123831261
- https://blog.csdn.net/weixin_42046845/article/details/115156902