GLENet: Boosting 3D Object Detectors with Generative Label Uncertainty Estimation
GLENet:增强型3D 目标检测网络-利用生成标签不确定估计法
作者:张一凡、张其安、朱志宇、侯俊辉(香港城市大学计算机科学系)
这篇论文来自CVPR 2022 7月的会议第2466号论文,该论文提出了一种GLENet网络,在KITTI数据集上进行实验,并且取得了牛逼的成果!下面分别是KITTI数据集简单、中等、困难三个难度的跑分,可见GLENet几乎屠榜!
easy

middle
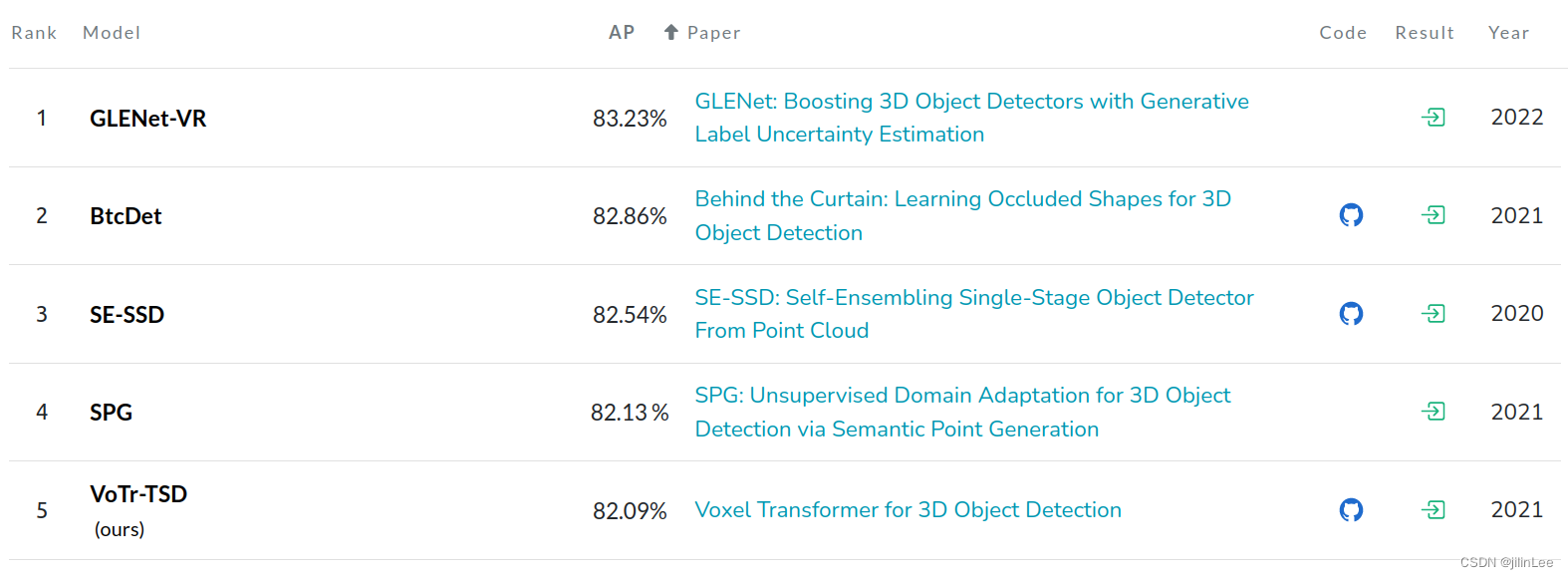
hard
 下面,我们来看一下论文提供的数据
下面,我们来看一下论文提供的数据
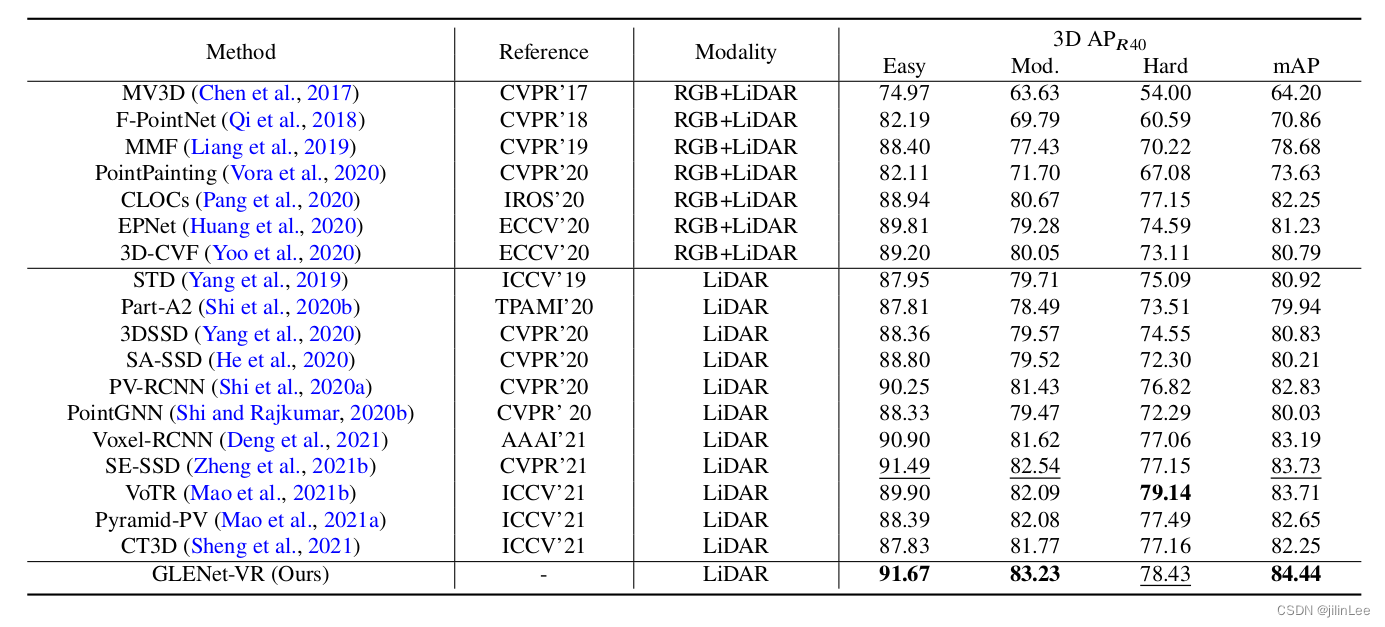 很牛B,对吧?可惜,没有公开源代码,残念!!!
很牛B,对吧?可惜,没有公开源代码,残念!!!
OK,让我们进入正文。
摘要
由于遮挡、信号丢失或手动标注错误,引起的 3D 真实标签的模糊,会在训练期间使 3D 对象检测网络混淆,从而降低检测精度。然而,现有检测方法基本忽略了这个问题,并将所有标签视为确定的。在本文中,我们将标签不确定性问题表述为对象潜在合理边界框的多样性,然后提出了 GLENet,一种适应于变分自动编码器的生成框架,并将 3D 实际目标与其有一定变化的标注框之间,一对多的关系模型化的一个网络。GLENet 中标签不确定性生成器是一个即插即用模块,可以方便地集成到现有的3D检测网络中,以构建概率探测器并监督定位不确定性的学习。此外,我们提出了一种概率检测器中的不确定性感知质量估计器架构,以指导具有预测定位不确定性的IoU分支的训练。我们将所提出的方法整合到各种流行的基础 3D 检测器中,并在 KITTI 和 Waymo 基准数据集上展示了显着且一致的性能提升。特别是,所提出的 GLENet-VR 大大优于所有已发表的基于 LiDAR 的方法,并且在具有挑战性的 KITTI 测试集上的单模态方法中排名 1st。我们将公开源代码和预训练模型。(真的吗?激动!!)
1.引言
作为计算机视觉最实际的应用场景之一,随着自动驾驶的兴起和大规模标注数据集(例如、KITTI和 Waymo),三维物体检测在当前深度学习时代吸引了学术界和工业界的广泛关注。
当前,尽管各种基于深度学习的 3D 检测方法激增,但主流 3D 对象检测器通常被设计为确定性模型,而没有考虑带注释的真实标签模糊性的关键问题。然而,模糊或不准确的问题不可避免地存在于对象级边界框的真实标签中,这会影响这类确定性的检测器的整个学习过程。例如,在数据收集阶段,由于激光雷达传感器的固有特性以及不可控的环境遮挡,原始点云很有可能会不完整。此外,在数据标记阶段,不同的标注人员主观估计2D图像和3D点云中目标的形状和位置时,自然会出现歧义。为了便于直观理解,我们在图 1 中提供了典型示例,从图中我们可以看到,一个不完整的 LiDAR 观测图可以对应于多个可能合理的标签,并且较为相似的点云目标可以用显著变化的边界框进行注释。
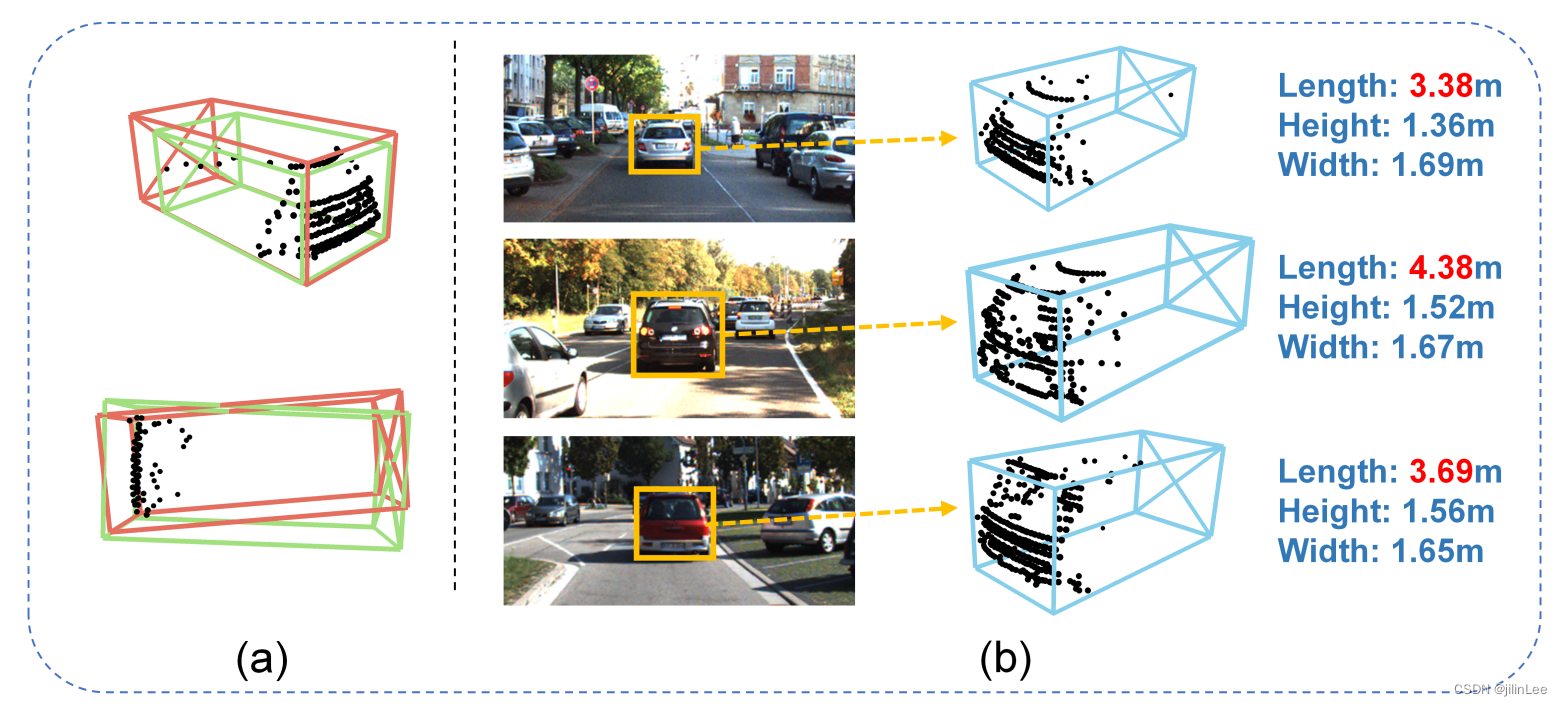 图 1:(a) 给定一个不完整 LiDAR 观测的对象,可能存在多个具有不同大小和形状的潜在合理的真实边界框。 (b) 当注释来自 2D 图像和部分点时,标签过程中的模糊和不准确是不可避免的。在给定的情况下,只有后部的汽车类别的类似点云可以用不同长度的不同真实值框进行注释,长度Length有非常明显的变化。
图 1:(a) 给定一个不完整 LiDAR 观测的对象,可能存在多个具有不同大小和形状的潜在合理的真实边界框。 (b) 当注释来自 2D 图像和部分点时,标签过程中的模糊和不准确是不可避免的。在给定的情况下,只有后部的汽车类别的类似点云可以用不同长度的不同真实值框进行注释,长度Length有非常明显的变化。
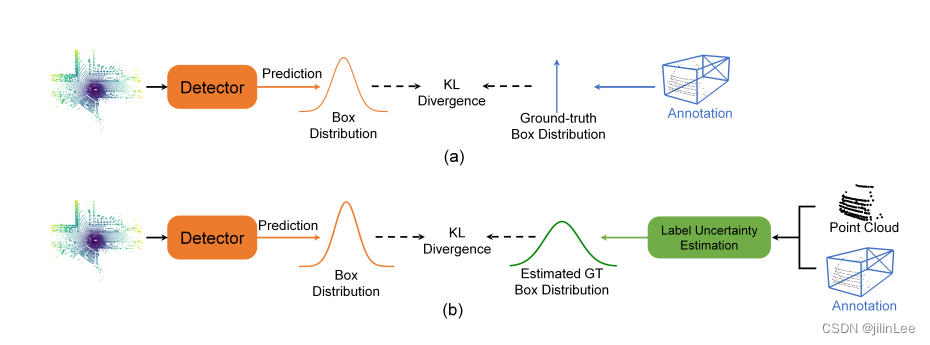 图 2:概率对象检测器的两种不同学习范式的图示。 (a) 在检测头中采用概率建模但本质上仍然忽略地面实况边界框模糊性问题的方法。 (b) 明确估计真实边界框分布以用作更可靠的监督信号的方法。
图 2:概率对象检测器的两种不同学习范式的图示。 (a) 在检测头中采用概率建模但本质上仍然忽略地面实况边界框模糊性问题的方法。 (b) 明确估计真实边界框分布以用作更可靠的监督信号的方法。
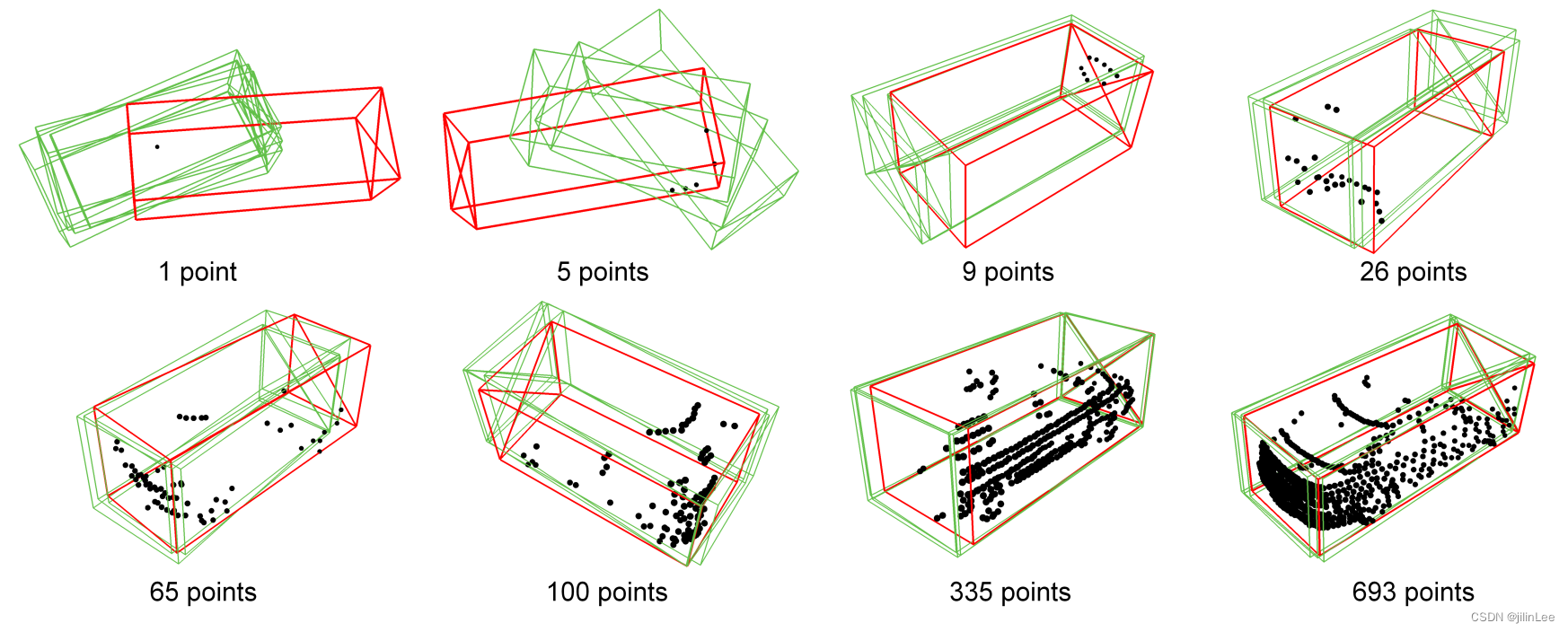 图 3:通过多次采样 latext 变量来说明 GLENet 中多个可能合理的边界框。 GLENet 的点云、带注释的真实框和预测分别用黑色、红色和绿色着色。 GLENet 为用稀疏点云和不完整轮廓表示的对象生成不同的预测,并为具有高质量点云的对象生成一致的边界框。 GLENet 的多个预测的方差用于估计带注释的真实边界框的不确定性。
图 3:通过多次采样 latext 变量来说明 GLENet 中多个可能合理的边界框。 GLENet 的点云、带注释的真实框和预测分别用黑色、红色和绿色着色。 GLENet 为用稀疏点云和不完整轮廓表示的对象生成不同的预测,并为具有高质量点云的对象生成一致的边界框。 GLENet 的多个预测的方差用于估计带注释的真实边界框的不确定性。
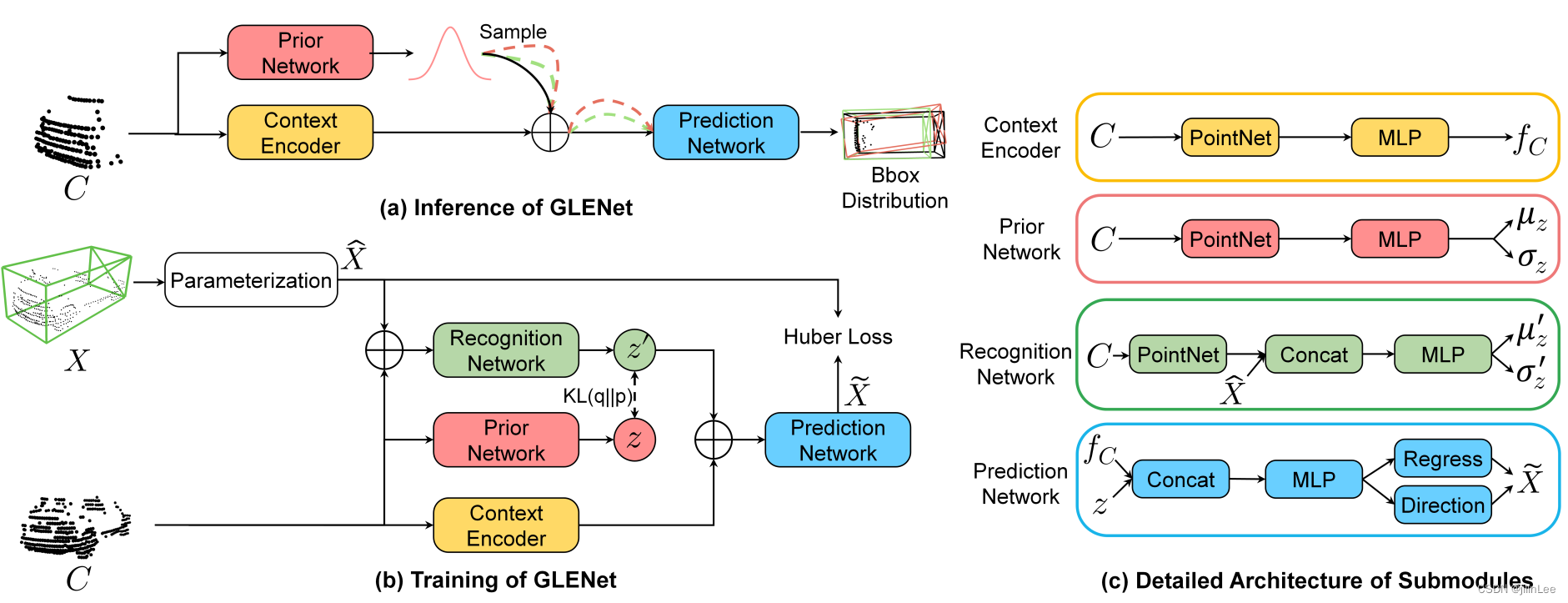 图 4:GLENet 的整体工作流程。在训练阶段,我们通过先验网络(resp.识别网络)学习潜在变量𝑧(resp.𝑧0)的参数𝜇和𝜎(分别是𝜇0和𝜎0),然后是𝑧0的样本和由上下文编码器产生的相应几何嵌入被联合用于估计边界框分布。在推理阶段,我们从 𝑧 的分布中多次采样以生成不同的边界框,我们将其方差用作标签不确定性。
图 4:GLENet 的整体工作流程。在训练阶段,我们通过先验网络(resp.识别网络)学习潜在变量𝑧(resp.𝑧0)的参数𝜇和𝜎(分别是𝜇0和𝜎0),然后是𝑧0的样本和由上下文编码器产生的相应几何嵌入被联合用于估计边界框分布。在推理阶段,我们从 𝑧 的分布中多次采样以生成不同的边界框,我们将其方差用作标签不确定性。
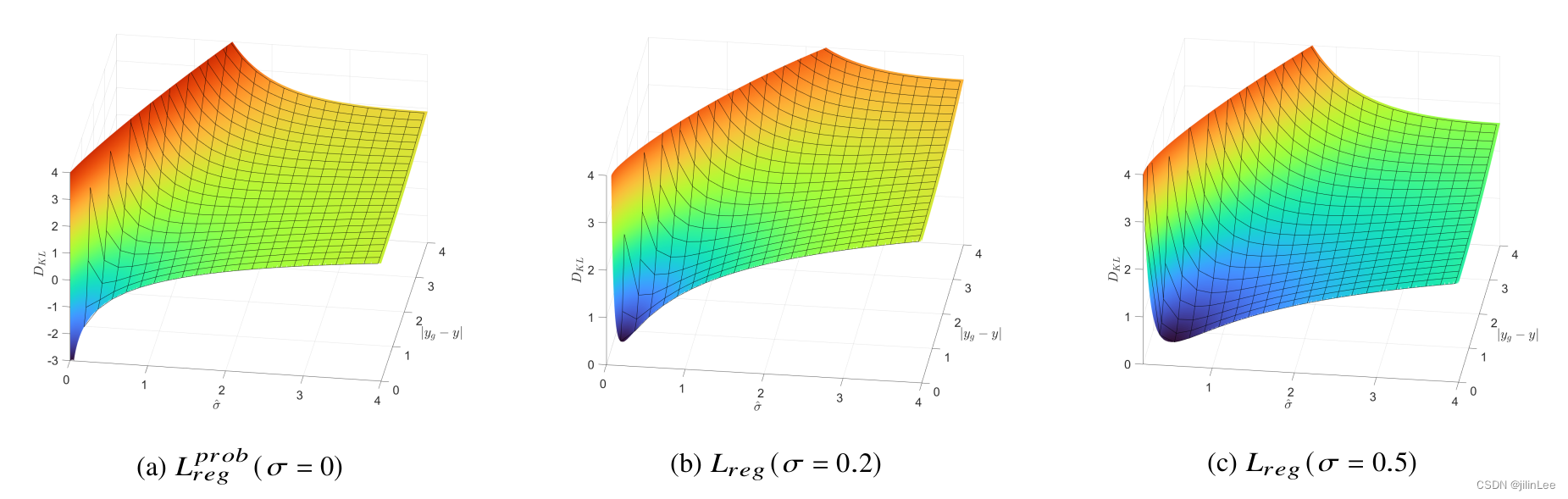 图 5:作为定位误差函数的分布之间的 KL 散度图示 |𝑦 𝑔 ? 𝑦 ^ |和估计的定位方差 𝜎 ^ 给定不同的标签不确定性𝜎。使用 GLENet 估计的标签不确定性 𝜎 而不是零,当损失收敛到最小值时梯度更平滑。此外,当 𝜎 较大时,𝐿 𝑟 𝑒𝑔 更小,这可以防止模型过度拟合不确定的注释。
图 5:作为定位误差函数的分布之间的 KL 散度图示 |𝑦 𝑔 ? 𝑦 ^ |和估计的定位方差 𝜎 ^ 给定不同的标签不确定性𝜎。使用 GLENet 估计的标签不确定性 𝜎 而不是零,当损失收敛到最小值时梯度更平滑。此外,当 𝜎 较大时,𝐿 𝑟 𝑒𝑔 更小,这可以防止模型过度拟合不确定的注释。
 图 6:(a) 实际定位精度(即预测和真实边界框之间的 IoU)与概率检测器预测的方差之间关系的图示。在这里,我们使用 PCA 降低方差的维度以促进可视化。 (b) 两个例子:对于稀疏样本,预测具有高不确定性和低定位质量,而对于密集样本,预测具有高定位质量和低不确定性估计。
图 6:(a) 实际定位精度(即预测和真实边界框之间的 IoU)与概率检测器预测的方差之间关系的图示。在这里,我们使用 PCA 降低方差的维度以促进可视化。 (b) 两个例子:对于稀疏样本,预测具有高不确定性和低定位质量,而对于密集样本,预测具有高定位质量和低不确定性估计。
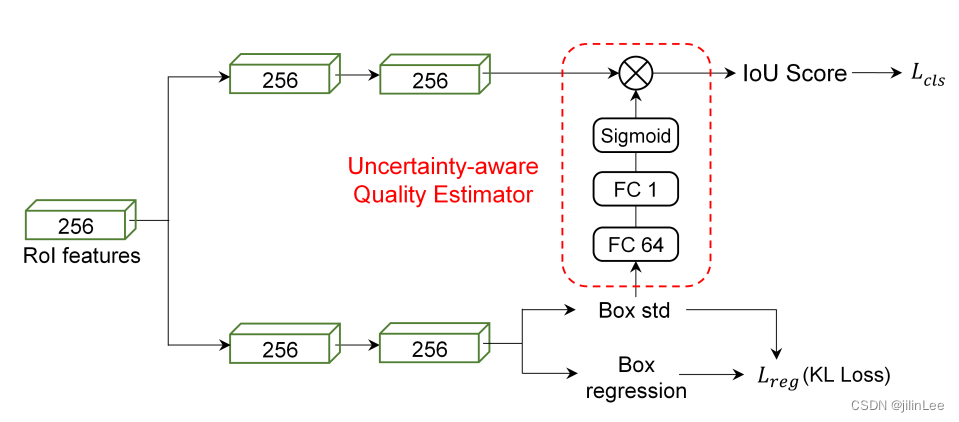 图 7:使用学习的定位方差来辅助定位质量(IoU)估计分支的训练的检测头中提出的 UAQE 模块的图示。
图 7:使用学习的定位方差来辅助定位质量(IoU)估计分支的训练的检测头中提出的 UAQE 模块的图示。
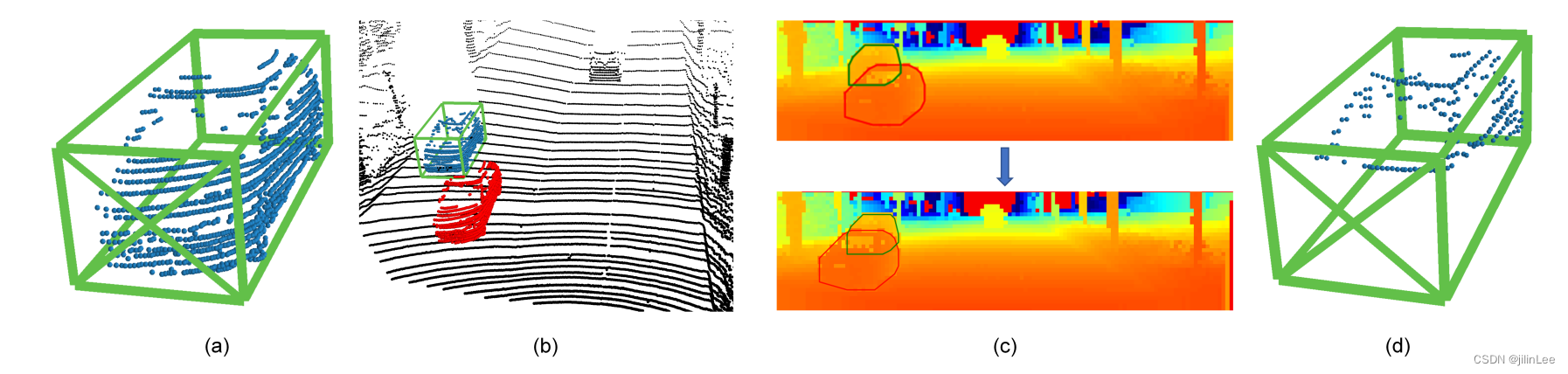 图 8:遮挡数据增强的图示。 (a) 与带注释的真实边界框相关联的原始对象的点云。 (b) 在 LiDAR 传感器和原始物体 (蓝色) 之间放置一个采样的密集物体 (红色)。 ? (b)中点云的投影距离图像,其中计算采样对象的凸包(红色多边形)并进一步抖动以增加被遮挡样本的多样性。基于原始点云的凸包(蓝色多边形),可以得到遮挡区域。被遮挡区域对应的原始对象的点云被移除。 (d) 带有注释的真实边界框的最终增强对象。
图 8:遮挡数据增强的图示。 (a) 与带注释的真实边界框相关联的原始对象的点云。 (b) 在 LiDAR 传感器和原始物体 (蓝色) 之间放置一个采样的密集物体 (红色)。 ? (b)中点云的投影距离图像,其中计算采样对象的凸包(红色多边形)并进一步抖动以增加被遮挡样本的多样性。基于原始点云的凸包(蓝色多边形),可以得到遮挡区域。被遮挡区域对应的原始对象的点云被移除。 (d) 带有注释的真实边界框的最终增强对象。
 图 10:GLENet-VR 和 Voxel R-CNN 在 KITTI 数据集上的结果视觉比较。在点云和图像上,ground-truth、true positive 和 false positive 边界框分别以红色、绿色和黄色显示。最好以彩色观看。
图 10:GLENet-VR 和 Voxel R-CNN 在 KITTI 数据集上的结果视觉比较。在点云和图像上,ground-truth、true positive 和 false positive 边界框分别以红色、绿色和黄色显示。最好以彩色观看。
 图 11:SECOND 和 GLENet-S 在 Waymo 验证集上的结果的视觉比较。真实情况、真阳性和假阳性边界框分别以红色、绿色和黄色显示。最好以彩色查看并放大以获取更多详细信息。额外的 NMS 进行了更好的可视化。
图 11:SECOND 和 GLENet-S 在 Waymo 验证集上的结果的视觉比较。真实情况、真阳性和假阳性边界框分别以红色、绿色和黄色显示。最好以彩色查看并放大以获取更多详细信息。额外的 NMS 进行了更好的可视化。
进一步的有关该论文详解和代码复现,移步这里