Ŀ¼
������������
�������Ԥ��: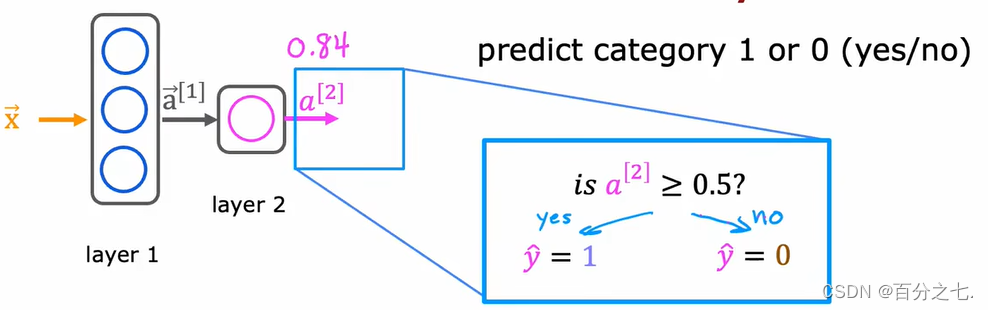 ÿһ�㶼����һ����������,������Ӧ�����ع鵥Ԫ,Ȼ��������һ����������,��һ�㵽��һ��,ֱ���õ����յ������ļ������������Խ���ֵ��Ϊ0.5,�ó����յ�Ԥ�⡣
ÿһ�㶼����һ����������,������Ӧ�����ع鵥Ԫ,Ȼ��������һ����������,��һ�㵽��һ��,ֱ���õ����յ������ļ������������Խ���ֵ��Ϊ0.5,�ó����յ�Ԥ�⡣
�����ӵ�������:
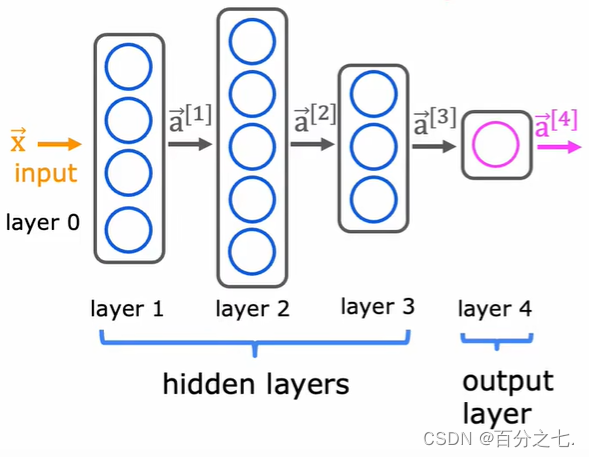
���������4��,��0���������,1��2��3�����ز�,4��������㡣
a
j
[
l
]
=
g
(
w
?
j
[
l
]
?
a
?
[
l
?
1
]
+
b
j
l
[
l
]
)
a_{j}^{[l]}=g\left(\vec{w}_{j}^{[l]} \cdot \vec{a}^{[l-1]}+b_{j l}^{[l]}\right)
aj[l]?=g(wj[l]??a[l?1]+bjl[l]?)
g�Ǽ����(activation function),��Ϊg����������ֵ������������������ֵ�ĺ�����
sigmoid��������������
1.ReLU�����:
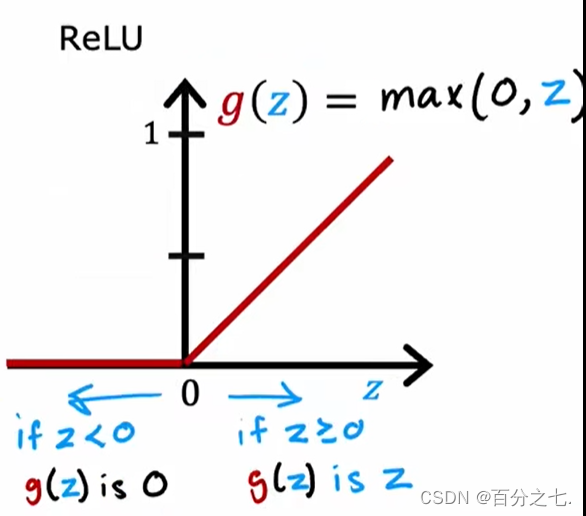
2.���Լ����:
g(z)=z
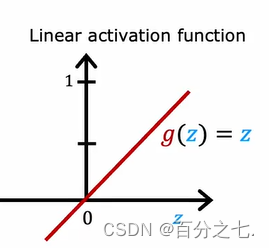
���ѡ���
���ǿ������������еIJ�ͬ��Ԫ��ѡ��ͬ�ļ����,���ڿ��Ǽ��������������Ԥ���ǩʱ,���ǻ���һ���൱��Ȼ��ѡ��������ڴ�������һ������������,��ô���������ʹ��sigmiod�����;������ڴ����ع�����,��ô�����õ���ͬ�ļ����,�����Լ���������������ֵֻ��ȡ�Ǹ�ֵ,��ô����Ȼ��ѡ����ReLU�������
��ʵ֤��,ReLU�����������Ϊֹ�������������ѡ������һ��ԭ�������ļ����ٶ�Ҫ��һЩ,Ч�ʸߡ�����Ҫ��һ��ԭ����ReUL�������ͼ�����ͼ�ε���벿���б�ƽ,��sigmoid�������ͼ�ε����������ƽ,���ʹ���ݶ��½���ѵ�������罫���ú���������ReUL����������ز�������ļ������
Ϊʲôģ����Ҫ�����?
����������������е����нڵ�ʹ�����Լ����,��ô������������罫���������Իع�û��ʲô��ͬ��
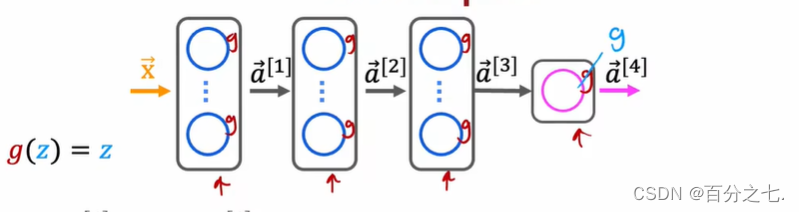
�����������,���ģ�͵�ͬ�����ع�,�����������������û�����κβ��������ع���������,�����Ϊʲôһ�������ľ��鷨���Dz�Ҫ������������ز���ʹ�����Լ������
���������:
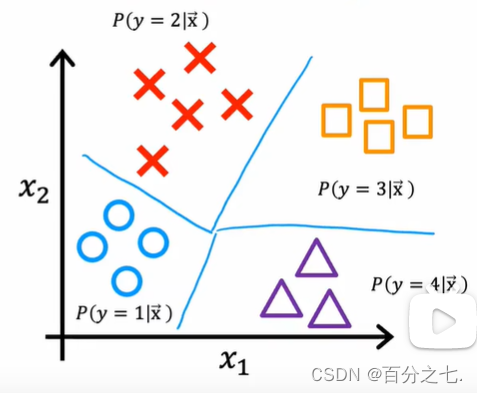
Softmax�ع��㷨
softmax�ع��㷨�����ع���ƹ㡣
���ع����ʧ����:
loss
?
=
?
y
log
?
a
1
?
(
1
?
y
)
log
?
(
1
?
a
1
)
\operatorname{loss}=-y \log a_{1}-(1-y) \log \left(1-a_{1}\right)
loss=?yloga1??(1?y)log(1?a1?)�ɱ�����:
J
(
w
��
,
b
)
=
?average?loss?
J(\overrightarrow{\mathrm{w}}, b)=\text { average loss }
J(w,b)=?average?loss?softmax�ع鷽��:
a
1
=
e
z
1
e
z
1
+
e
z
2
+
?
+
e
z
N
=
P
(
y
=
1
�O
x
��
)
?
a
N
=
e
z
N
e
z
1
+
e
z
2
+
?
+
e
z
N
=
P
(
y
=
N
�O
x
��
)
\begin{gathered} a_{1}=\frac{e^{z_{1}}}{e^{z_{1}}+e^{z_{2}}+\cdots+e^{z_{N}}}=P(y=1 \mid \overrightarrow{\mathrm{x}}) \\ \vdots \\ a_{N}=\frac{e^{z_{N}}}{e^{z_{1}}+e^{z_{2}}+\cdots+e^{z_{N}}}=P(y=N \mid \overrightarrow{\mathrm{x}}) \end{gathered}
a1?=ez1?+ez2?+?+ezN?ez1??=P(y=1�Ox)?aN?=ez1?+ez2?+?+ezN?ezN??=P(y=N�Ox)?��ʧ����:
loss
?
(
a
1
,
��
,
a
N
,
y
)
=
{
?
log
?
a
1
?if?
y
=
1
?
log
?
a
2
?if?
y
=
2
?
?
log
?
a
N
?if?
y
=
N
\operatorname{loss}\left(a_{1}, \ldots, a_{N}, y\right)=\left\{\begin{array}{cc} -\log a_{1} & \text { if } y=1 \\ -\log a_{2} & \text { if } y=2 \\ & \vdots \\ -\log a_{N} & \text { if } y=N \end{array}\right.
loss(a1?,��,aN?,y)=?
?
???loga1??loga2??logaN???if?y=1?if?y=2??if?y=N? 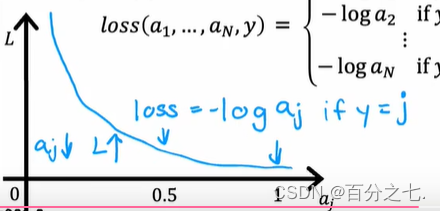
���ǩ��������
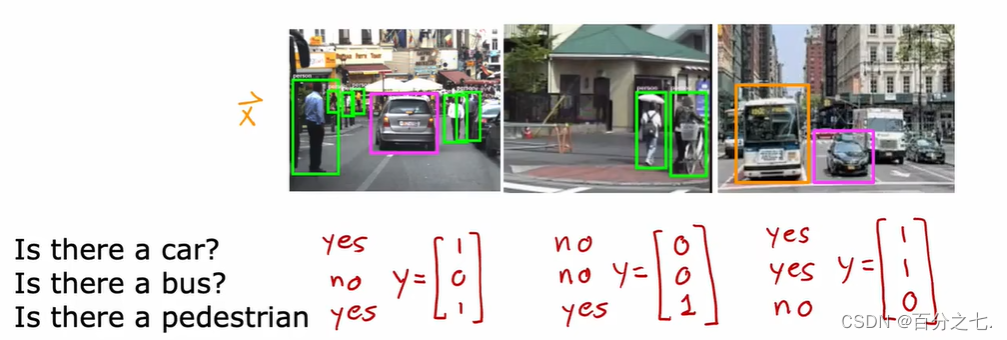
���Ϊ���ǩ���ཨ��һ��������?
һ�ֽ�������ǽ�����Ϊ������ȫ�����Ļ���ѧϰ����,���Խ���һ���������ж���û������,�ڶ���������,������������ˡ�

����һ�ַ�������ͬʱ������һ��,��ѵ������������ͬʱ����������������������ˡ�
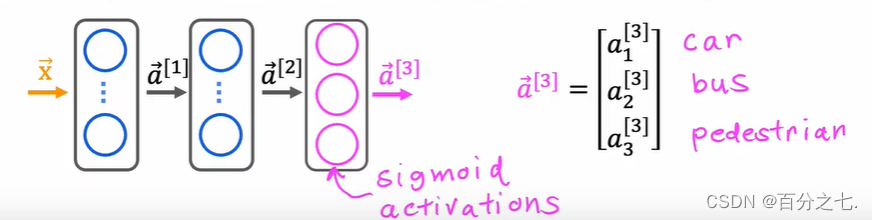
ֻ������������������,��������е������ڵ�ʹ��sigmoid�������
���Ż�����
Adam�Ż��㷨��������Ӧѧϰ��,���ݶ��½��㷨��öࡣ
�ݶ��½��ı���ʽ:
w
j
=
w
j
?
��
?
?
w
j
J
(
W
?
,
b
)
w_{j}=w_{j}-\alpha \frac{\partial}{\partial w_{j}} J(\vec{W}, b)
wj?=wj??��?wj???J(W,b) �ɱ�������ͼ��:�����̫С: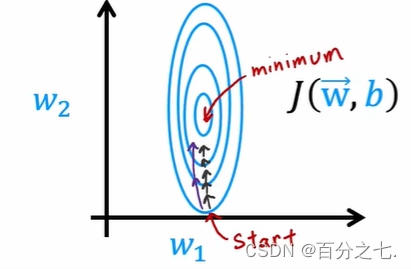
Adam�㷨�����Զ����Ӧ�,������ȡ����IJ��貢����شﵽ��С�ɱ���
�����̫��:
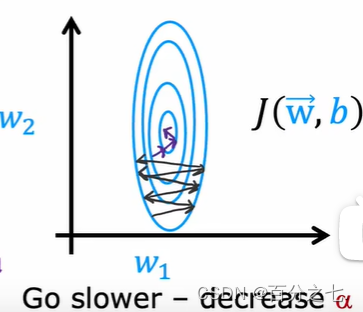
��ʱAdam�㷨�����Զ���С����
�������������
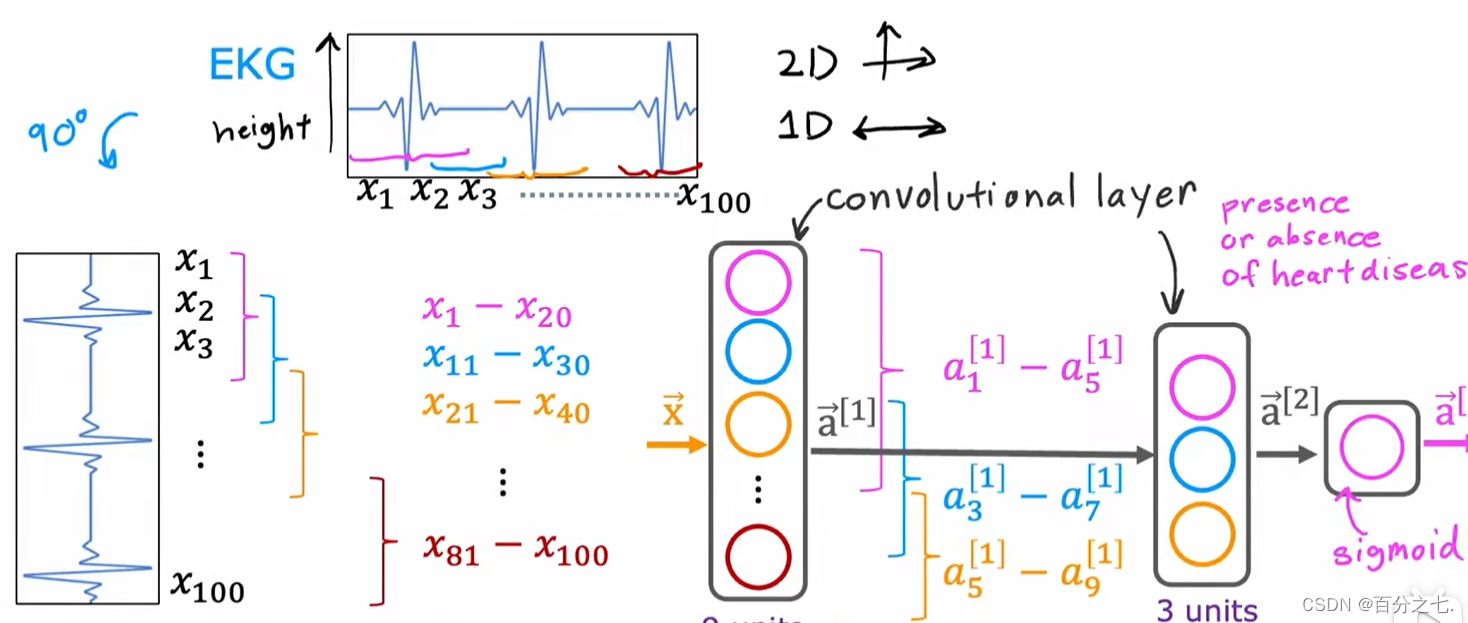
ǰ������һֱʹ�õ�����Ԫ������ܼ���,����ڶ������ز�������ǰһ���ÿ������ֵ�ĺ�����
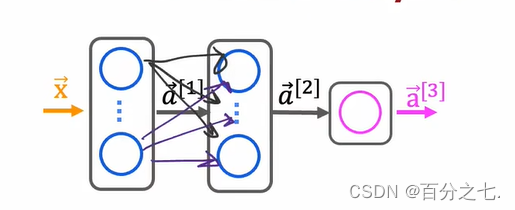
�������������˿��ܻ�ѡ��ʹ�ò�ͬ���͵IJ�,��������㡣��������������ж��������,��Ϊ���������硣
Ϊʲôʹ�þ�����?
1.�ӿ�����ٶ�
2.��Ҫ���ٵ�ѵ������,����������ϡ�
���ز��еĵ�Ԫֻ�鿴�����������: