����Ŀ¼
Abstract
һ�ַdz���ľ���������(CNN)�����ͼ�ֱ���(SR)����ȡ���˾�ɹ�,���ṩ�˷ֲ�������Ȼ��,������������CNN��SRģ��û�г������ԭʼ�ͷֱ���(LR)ͼ��ķֲ�����,�Ӷ�ʵ����Խϵ͵����ܡ��ڱ�����,���������һ���µIJв��ܼ�����(RDN)�����ͼ��SR�е�������⡣���dz�����������о�����IJ�������������˵,���������ʣ���ܼ���(RDB)��ͨ���ܼ����Ӿ�������ȡ�ḻ�ľֲ�������RDB��������ǰһ��RDB��״ֱ̬�����ӵ���ǰRDB�����в�,�Ӷ��γ������ڴ�(CM)���ơ�Ȼ��,ʹ��RDB�еľֲ������ںϴ���ǰ�͵�ǰ�ֲ�����������Ӧ��ѧϰ����Ч������,���ȶ����������ѵ�����ڳ�ֻ�ó��ܵľֲ�������,����ʹ��ȫ�������ں������巽ʽ��������Ӧ��ѧϰȫ�ֲ���������ھ��в�ͬ�˻�ģ�͵Ļ����ݼ��ϵ�ʵ�����,���ǵ�RDN��������Ƚ��ķ����������õ����ܡ�
1. Introduction
��ͼ�ֱ���(SISR)ּ�ڴ��併���ĵͷֱ���(LR)�����������Ӿ����������õĸ߷ֱ���(HR)ͼ��SISR���ڸ��ּ�����Ӿ�����,�簲ȫ�ͼ��ӳ���[42]��ҽѧ����[23]��ͼ������[9]����ͼ��SR�Dz��ʶ������,��Ϊ�����κ�LR������ڶ��ֽ⡣Ϊ�˽�����������,�Ѿ�����˺ܶ�ͼ��SR�㷨,�������ڲ�ֵ��[40]�������ؽ���[37]�ͻ���ѧϰ�ķ���[28��29��20��2��21��8��10��31��39]��
����,Dong����[2]���Ƚ����˽�3�����������(CNN)���뵽ͼ��SR��,�봫ͳ�������ȡ���������ĸĽ���Kim������VDSR[10]��DRCN[11]��ͨ��ʹ���ݶȼ��á��������ӻ�ݹ�ල�������������,�Լ���ѵ�����������Ѷȡ�ͨ��ʹ����Ч�Ĺ���ģ��,ͼ��SR����������롢����,���ܸ��á�Lim����ʹ�òв��(ͼ1(a))���������вв�����[24]�ķdz���������EDSR[17],�Լ��dz��������MDSR[17]��Tai��������˹���MemNet���ڴ��[26]������������ȵ�����,ÿ���������е����������в�ͬ�ĸ���Ұ��Ȼ��,��Щ���������˳������ÿ�����������Ϣ�����ܴ洢�����е��ŵ�Ԫ���������ڿ��ƶ��ڴ洢��[26],���ֲ������㲻��ֱ�ӷ��ʺ����㡣���Ժ���˵�ڴ�����������������в����Ϣ��
����,ͼ���еĶ�����в�ͬ�ı������ӽǺ��ݺ�ȡ����Էdz��������ķֲ�������Ϊ�ؽ��ṩ������������������������ѧϰ(DL)�ķ���(��VDSR[10]��LapSRN[13]��EDSR[17])������ʹ�÷ֲ����������ؽ������ܴ洢����[26]Ҳ��������ǰ�洢�������Ϣ��Ϊ����,��δ��ԭʼLRͼ������ȡ�༶������MemNet��ԭʼLRͼ���ֵ�������С���γ����롣��Ԥ�������費�����������˼��㸴�Ӷ�,���Ҷ�ʧ��ԭʼLRͼ���һЩϸ�ڡ�Tong��������Ե͵�������(����16)Ϊͼ��SR�������ܼ���(ͼ1(b))���������ǵ�ʵ��(����5.2��),���ߵ������ʿ��Խ�һ�������������ܡ�����ͼ1(b)������ѵ�������ܼ���ĸ������硣
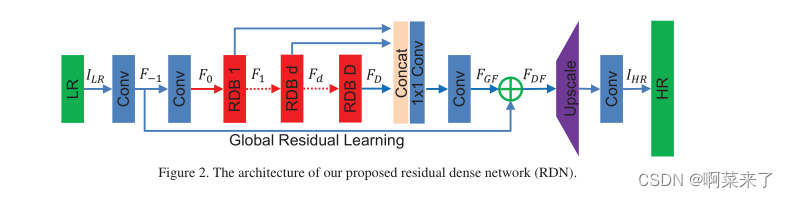
Ϊ�˽����Щȱ��,��������˲в��ܼ�����(RDN)(ͼ2),��������������IJв��ܼ���(ͼ1(c))�������ԭʼLRͼ������зֲ����������ڷdz����������˵,ֱ����ȡLR�ռ���ÿ�������������������ֲ���ʵ�ʡ����������ʣ���ܼ���(RDB)��ΪRDN�Ĺ���ģ�顣RDB���ܼ����Ӳ�;ֲ������ں�(LFF)��ֲ��в�ѧϰ(LRL)��ɡ����ǵ�RDB��֧��RDB֮��������ڴ档һ��RDB�������ֱ�ӷ�����һ��RDA��ÿһ��,�Ӷ�����������״̬���ݡ�RDB�е�ÿ��������ɷ������к�����,��������Ҫ��������Ϣ[7]��LFF��ǰһ��RDB��״̬�͵�ǰRDB�е�����ǰһ����������,ͨ������Ӧ�ر�����Ϣ����ȡ�ֲ��ܼ�����������,LFFͨ���ȶ����㷺�����ѵ��,�����dz��ߵ������ʡ�����ȡ���ξֲ��ܼ�������,���ǽ�һ������ȫ�������ں�(GFF),��ȫ�ַ�ʽ����Ӧ�ر��������������ͼ1��2��ʾ����ͼ2��ͼ3��,ÿһ�㶼����ֱ�ӷ���ԭʼLR����,�Ӷ�ʵ����ʽ��ȼල[15]��
��֮,���ǵ���Ҫ��������������:
- ���������һ��ͳһ�Ŀ��ʣ���ܼ�����(RDN),���ڲ�ͬ�˻�ģ�͵ĸ�����ͼ��SR����������������ԭʼLRͼ������в������
- ���������ʣ���ܼ���(RDB),����������ͨ�������洢��(CM)���ƴ�ǰ���RDB��ȡ״̬,������ͨ���ֲ��ܼ����ӳ���������е����в㡣Ȼ��ͨ���ֲ������ں�(LFF)����Ӧ�ر����ۻ�������
- ���������ȫ�������ں�,������Ӧ���ں�LR�ռ�������RDB�ķֲ�������ͨ��ȫ�ֲв�ѧϰ,���ǽ�dz�����������������һ��,��ԭʼLRͼ���л��ȫ���ܼ�������
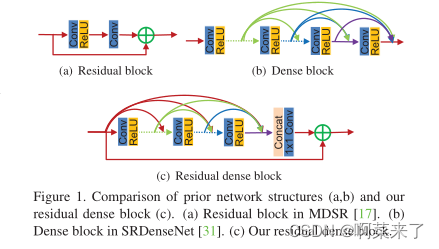
��ͼ1.��ǰ����ṹ(a,b)��ʣ���ܼ���(c)�ıȽϡ�(a) MDSR�е�ʣ���[17]��(b) SRDenseNet�еij��ܿ�[31]��(c) ����ʣ����ܼ��顣��
2. Related Work
���,�������ѧϰ(DL)�ķ����������Ӿ��еĴ�ͳ�������ȡ���˾������[36,35,34,16]�����ڿռ�����,���ǽ�������SR.Dong���������SRCNN[2]�й���ͼ���һЩ����,�״��ڲ�ֵ��LRͼ������HR��Ӧͼ��֮�佨���˶˵���ӳ�䡣Ȼ����Ҫͨ������������Ȼ�������Ȩ������һ�����Ƹû��ߡ�VDSR[10]��IRCNN[38]ͨ��ʹ��ʣ��ѧϰ�ѵ����������������������ȡ�DRCN[11]������һ���dz��������������ݹ�ѧϰ��ʵ�ֲ���������Tai������DRRN[25]�������˵ݹ��,����Memnet[26]�������ڴ��,��ʵ�ָ����ε����硣������Щ��������Ҫ�ڽ�ԭʼLRͼ��Ӧ�õ�������֮ǰ�����ֵ�������С����Ԥ�������費���Զ��η�ʽ�����˼��㸴�Ӷ�[4],������ƽ����ģ����ԭʼLRͼ��,�Ӷ���ʧ��һЩϸ�ڡ����,��Щ�����Ӳ�ֵ��LRͼ������ȡ����,��������ԭʼLR��HRͼ��Ķ˵���ӳ�䡣
Ϊ�˽����������,Dong����[4]ֱ�ӽ�ԭʼLRͼ����Ϊ����,��������ת�þ�����(Ҳ��Ϊ��������),�������ϲ�������ϸ�ֱ��ʡ�Shi���������ESPCN[22],������������Ч�������ؾ�����,�Խ�����LR����ӳ��������HR����С�Ȼ����SRResNet[14]��EDSR[17]�в�������Ч�������ؾ�����,������ʣ����б[6]��������Щ��������LR�ռ�����ȡ����,��ʹ��ת�û������ؾ�����Ŵ�����LR������ͨ��������,��Щ����Ҫô�ܹ�����ʵʱSR(��FSRCNN��ESPCN),Ҫô�����÷dz���\��(��SRResNet��EDSR)��Ȼ��,������Щ����������ʽ��ʽ�ѵ�����ģ��(����,FSRCNN�е�Conv�㡢SRResNet��EDSR�е�ʣ���)�����Ǻ����˳����������ÿ��Conv�����Ϣ,��������LR�ռ������һ��Conv���е�CNN�������зŴ�
���,Huang���������DenseNet,������ͬһ�ܼ���������������֮���ֱ������[7]��ͨ���ֲ��ܼ�����,ÿһ���ͬһ�ܼ����е�������ǰ���ȡ��Ϣ���ڴ洢��[26]���ܼ���[31]֮���������ܼ����ӡ���4�ڽ�����Denset/SrDenset/MemNet�����ǵ�RDN֮��ĸ�����졣
��������DL��ͼ��SR�����봫ͳSR�������ȡ���������ĸĽ�,�����Ƕ�ʧȥ��һЩ���õIJ�νṹ��ԭʼLRͼ����ʧȥ��һЩ���õIJ�νṹ�������ɷdz������������ķֲ���������ͼ��ָ�����(����ͼ��SR)�dz����á�Ϊ�˽���������,���������ʣ���ܼ�����(RDN)����Ч����ȡ������Ӧ�ں�LR�ռ������в�����������ǽ�����һ������ϸ����RDN��
3. Residual Dense Network for Image SR
3.1. Network Structure
��ͼ2��ʾ,���ǵ�RDN��Ҫ���ĸ��������:dz������ȡ����(SFENet)��˫�ܼ���(RDB)���ܼ������ں�(DFF),������ϲ�������(UPNet)�������ǽ�ILR��ISR��ʾΪRDN������������������˵,����ʹ������Conv������ȡdz����������һConv����ȡ����F?1��LR���롣
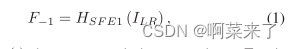
����HSF E1(��)��ʾ�������㡣F?1���ڽ�һ����dz��������ȡ��ȫ�ֲв�ѧϰ���������ǿ��Խ�һ����
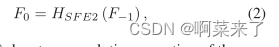
����HSF E2(��)��ʾ�ڶ�dz������ȡ��ľ�������,������ʣ���ܼ�������롣����������D��ʣ���ܼ���,��D��RDB�����Fd����ͨ�����¹�ʽ���:
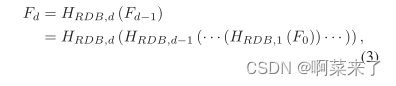
����HRDB��d��ʾ��d��RDB�IJ�����HRDB,d����������ĸ��Ϻ���,���������У�����Ե�Ԫ(ReLU)[5]������Fd���ɵ�d��RDB������ÿ��ڵ�ÿ�����������ɵ�,������ǿ��Խ�Fd��Ϊ�ֲ�����������RDB�ĸ���ϸ�ڽ��ڵ�3.2���и�����
��ʹ��һ��RDB��ȡ�ֲ�������,���ǽ�һ�������ܼ������ں�(DFF),����ȫ�������ں�(GFF)��ȫ�ֲв�ѧϰ(GRL)��DFF���������ǰ�����в������,���Ա�ʾΪ:
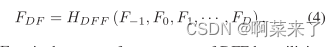
����,FDF�����ø��Ϻ���HDF��DFF�������ͼ���й�DFF�ĸ�����ϸ��Ϣ,��μ���3.3�ڡ�
��LR�ռ�����ȡ�ֲ���ȫ��������,������HR�ռ��жѵ��ϲ�������(UPNet)����[17]������,������UPNet��ʹ��ESPCN[22],Ȼ����һ��Conv�㡣RDN�������ͨ�����·�ʽ���:
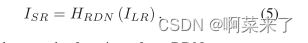
����HRDN��ʾ���ǵ�RDN�Ĺ��ܡ�
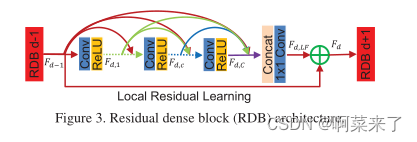
3.2. Residual Dense Block
����,������ͼ3��չʾ����������IJв��ܼ���(RDB)����ϸ��Ϣ�����ǵ�RDB�����ܼ����Ӳ㡢�ֲ������ں�(LFF)�;ֲ��в�ѧϰ,�Ӷ��γ��������洢(CM)���ơ�
�����洢����ͨ����ǰһ��RDB��״̬���ݸ���ǰRDB��ÿһ����ʵ�֡���Fd?1��Fd�ֱ��ǵ�d��RDB����������,�������Ƕ�����G0����ӳ�䡣��d��RDB�ĵ�c��Conv���������Թ�ʽ��Ϊ:
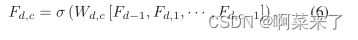
���Цұ�ʾReLU[5]�������Wd,c�ǵ�c��Conv���Ȩ��,����Ϊ�˼����ʡ����ƫ������Ǽ���Fd,c��G(Ҳ��Ϊ������[7])����ӳ����ɡ�[Fd?1,Fd,1,��Fd,c?1] ָ��(d? 1) -������RDB,������1,��,(c? 1) �ڵ�d��RDB�в���G0+(c? 1) ��G����ͼ��ǰһ��RDB��ÿһ������ֱ�����ӵ����к�����,�ⲻ��������ǰ������,������ȡ�˾ֲ��ܼ�������
Ȼ��Ӧ�þֲ������ں�������Ӧ���ں�������ǰRDB��״̬�͵�ǰRDB�е�����Conv�㡣��������? 1) ���ĸ�RDB�Դ�����ʽֱ�����뵽���ĸ�RDB��,��˼�����������������Ҫ����һ����,��MemNet[26]������,����������1��1������������Ӧ���������Ϣ�����ǽ��˲�������Ϊ�ֲ������ں�(LFF),��ʽ����:
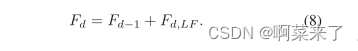
Ӧ��ע�����,LRL�����Խ�һ����������ʾ����,�Ӷ���ø��õ����ܡ������ڵ�5���н����˹���LRL�ĸ������������ܼ���ͨ�Ժ;ֲ��в�ѧϰ,���ǽ����ֿ�ṹ��Ϊ�в��ܼ���(RDB)����4���ܽ���RDB��ԭʼ��������[7]֮��ĸ�����졣
3.3. Dense Feature Fusion
��ʹ��һ��RDB��ȡ�ֲ��ܼ�������,���ǽ�һ��������ܼ������ں�(DFF),��ȫ�ַ�ʽ���÷ֲ����������ǵ�DFF����ȫ�������ں�(GFF)��ȫ�ֲв�ѧϰ��
ȫ�������ں�ͨ���ں�����RDB�е���������ȡȫ������FGF
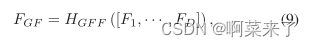
����[F1,����,FD]��ָ��ʣ���ܼ���1,����D����������ӳ��Ĵ�����HGF��1��1��3��3�����ĸ��Ϻ�����1��1��������������Ӧ���ںϲ�ͬ�����һϵ����������������3��3������,�Խ�һ����ȡȫ�ֲв�ѧϰ������,����[14]���ѱ�֤������Ч�ġ�
Ȼ������ȫ�ֲв�ѧϰ���������ͼ,Ȼ��ͨ��
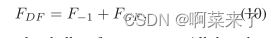
����F?1��ʾdz����ͼ����ȫ�������ں�֮ǰ,���������ʣ���ܼ���(RDB)������������������㡣RDB�����༶�ֲ���������,����һ������Ӧ�ں��γ�FGF����ȫ�ֲв�ѧϰ��,���ǻ�ó�������FDF��
Ӧ��ע�����,Tai����[26]����MemNet�еij����ܼ��������ָ�����ĸ�Ƶ��Ϣ��Ȼ��,�ڴ洢����[26]��,ǰ��IJ㲻��ֱ�ӷ������к����㡣�ֲ�������Ϣû�еõ��������,�����˳������ӵ�����������,MemNet��HR�ռ�����ȡ����,�����˼��㸴�Ӷȡ�ͬʱ,��[4,22,13,17]������,������LR�ռ�����ȡ�ֲ���ȫ����������4�ڽ�չʾ���ǵ�ʣ���ܼ������MemNet֮��ĸ�����졣��5�ڻ���չʾȫ�������ںϵ���Ч�ԡ�
3.4. Implementation Details
�����������RDN��,���ǽ�3��3����Ϊ���о�����Ĵ�С,���ھֲ���ȫ�������ں���,��˴�СΪ1��1�����ں˴�СΪ3��3�ľ�����,�����������ÿһ��������Ա��ִ�С�̶���dz������ȡ�㡢�ֲ���ȫ�������ںϲ����G0=64���˲�����ÿ��RDB�е������㶼��G��������,������ReLU[5]����[17]֮��,����ʹ��ESPCNN[22]���ֱַ�����������ΪUPNet�ľ�ϸ�����������������ɫHRͼ��ʱ,���һ��Conv����3�����ͨ����Ȼ��,������Ҳ���Դ����Ҷ�ͼ��
4. Discussions
��DenseNet��ͬ����DenseNet[7]������,���ǽ��ֲ����������������������ʣ����ܿ�(RDB)��һ����˵,DenseNet�㷺���ڸ�������Ӿ�����(����,����ʶ��)����RDN��Ϊͼ��SR��Ƶġ�����,�����Ƴ����������淶��(BN)��,������������ĵ�GPU�ڴ�����ͬ,�����˼��㸴�Ӷ�,���谭����������ܡ����ǻ�ɾ���˳ز�,����ܻᶪ��һЩ���ؼ���Ϣ������,��DenseNet�н����ɲ���õ��������ڵ��ܼ����С�����RDN��,����ͨ��ʹ�þֲ��в�ѧϰ���ܼ����Ӳ���ֲ������ں�(LFF)����,���ڵ�5���н���֤������Ч�ġ� ���,(d? 1)-RDBֱ�����ӵ���d��RDB�е�ÿһ��,����Ҳ�����ڵ�(d+1)��RDB�����롣���,���Dz���ȫ�������ں����������Denset�к��ԵIJ��������
��SRDenseNet������SRDenseNet[31]�����ǵ�RDN֮����������Ҫ���𡣵�һ���ǻ������������ơ�SRDenseNet������DenseNet[7]�еĻ����ܼ��顣���ǵ�ʣ���ܼ���(RDB)�����������������˸Ľ�:(1)�����������������ڴ�(CM)����,������ǰ��RDB��״ֱ̬�ӷ��ʵ�ǰRDB��ÿһ�㡣(2). ͨ��ʹ�þֲ������ں�(LFF),���ǵ�RDB���������������,�Ӷ��ȶ��˿������ѵ����(3). �ֲ�ʣ��ѧϰ(LRL)������RDB��,�Խ�һ��������Ϣ�����ݶȡ��ڶ���������RDB֮��û���ܼ����ӡ��෴,����ʹ��ȫ�������ں�(GFF)��ȫ�ֲв�ѧϰ����ȡȫ������,��Ϊ���ǵľ��������ڴ��RDB�Ѿ��ڱ�����ȫ��ȡ�����������5.2�ں͵�5.3����ʾ,������Щ�����������������ܡ���������SRDenseNetʹ��L2��ʧ����������������L1��ʧ����,�ú����ѱ�֤�������ܺ����������ǿ��[17]�����,���������RDN��SRDenseNet���и��õ����ܡ�
��MemNet�����𡣳�����ʧ�����IJ�ͬѡ��(MemNet[26]�е�L2),������Ҫ�ܽ���MemNet�����ǵ�RDN֮��������������졣����,MemNet��Ҫʹ��˫���β�ֵ��ԭʼLRͼ���ϲ����������С���ù��̵�����HR�ռ��н���������ȡ���ؽ���ͬʱ,RDN��ԭʼLRͼ������ȡ�������,���������˼��㸴�Ӷ�,��������ܡ����,MemNet�е��ڴ������ݹ����ŵ�Ԫ��һ���ݹ鵥Ԫ�еĴ�����㲻����������ǰһ����ڴ�����Ϣ���������������RDN��,RDB���������ֱ�ӷ�����һ��RDB��ÿһ�㡣����,ÿ�����������Ϣ����һ��RDB�ڵ����к����㡣����,RDB�еľֲ��в�ѧϰ��������Ϣ�����ݶȺ�����,���5����ʾ������,��������,��ǰ�洢��δ�������ǰһ�鼰���������Ϣ������MemNet��HR�ռ��в������ܼ����ڴ������,��MemNet����ԭʼLR��������ȫ��ȡ�ֲ�����������ʹ��RDB��ȡ�ֲ��ܼ�������,���ǵ�RDN��LR�ռ�����ȫ�ַ�ʽ��һ���ں���������ǰһ��ķֲ�������
5. Experimental Results
���鷽����Դ�����������λ������:https://github.com/yulunzhang/RDN
5.1. Settings
���ݼ��Ͷ��������,Timofte���˷���������ͼ��ָ�Ӧ�õĸ�����(2K�ֱ���)���ݼ�DIV2K[27]��DIV2K��800��ѵ��ͼ��100����֤ͼ���100������ͼ����ɡ�������800��ѵ��ͼ��ѵ������ģ��,����ѵ��������ʹ��5����֤ͼ��Ϊ�˽��в���,����ʹ��������������ݼ�:Set5[1]��Set14[33]��B100[18]��Urban100[8]��Manga109[19]���ڱ任��YCbCr�ռ��Yͨ��(������)��,ʹ��PSNR��SSIM[32]����SR�����
�˻�ģ�͡�Ϊ�˳��֤�����������RDN����Ч��,����ʹ�������˻�ģ����ģ��LRͼ��һ����˫�����²���,����Matlab����imresize��ѡ��bicubic(���ΪBI)������ʹ��BIģ��ģ����б������ӡ�2����3�͡�4��LRͼ����[38]����,�ڶ��ַ�����ʹ�ô�СΪ7��7�ĸ�˹��ģ��HRͼ��,��ƫ��Ϊ1.6��Ȼ��ʹ�ñ������ӡ�3��ģ��ͼ������²���(���ΪBD)�����ǽ�һ���Ը�����ս�Եķ�ʽ����LRͼ�������������������ӡ�3��HRͼ�����˫�����²���,Ȼ������������Ϊ30�ĸ�˹����(���DN)��
��ѵ����������[17]������,��ÿ��ѵ��������,���������ȡ16����СΪ32��32��LR RGB��Ƭ��Ϊ���롣����ͨ��ˮƽ��ֱ��ת����ת90?. 1000�η�����������һ���¼�Ԫ������ʹ��Torch7���ʵ��RDN,��ʹ��Adam�Ż���������и���[12]��ѧϰ���ʱ���ʼ��Ϊ10?4,ÿ200����Ԫ����һ�롣ʹ��Titan Xp GPUѵ��һ��RDN��Լ��Ҫ1���ʱ��,��ʱ200�����Ρ�
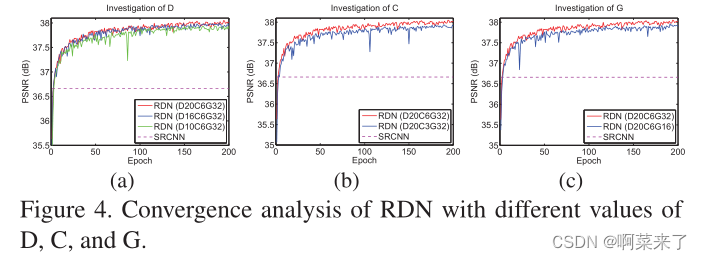
5.2. Study of D, C, and G.
�ڱ�С����,�����о��˻����������:RDB������(���D)��ÿ��RDB��Conv������(���C)��������(���G)������ʹ��SRCNN[3]��������Ϊ�ο�����ͼ1��2��ʾ��D��CԽ��,����Խ�ߡ�
����Ҫ����Ϊ����D��C������,�����ø���������������LFF���������G,���ǻ��۲쵽�����G(��ͼ4(C))������������ܡ���һ����,D��C��G��С��RND��ѵ���л����һЩ�����½�,��RDN������SRCNN[3]������Ҫ����,���ǵ�RDN����������������,������ȡ�����������Ի�ø��ߵ����ܡ�

����1.��������(CM)���ֲ�ʣ��ѧϰ(LRL)��ȫ�������ں�(GFF)�������о������ǹ۲쵽,��200����Ԫ��,����������Ϊ��2��Set5�ϵ�����(PSNR)��ѡ���
5.3. Ablation Investigation
��1��ʾ�˶���������(CM)���ֲ�ʣ��ѧϰ(LRL)��ȫ�������ں�(GFF)Ӱ��������о�����˸����������ͬ��RDB��(D=20)��ÿ��RDB��Conv��(C=6)��������(G=32)�����Ƿ�����Ҫ�ֲ������ں�(LFF)����ȷѵ����Щ����,���Ĭ������²����Ƴ�LFF������(��ʾΪRDN CM0LRL0GFF0)��û��CM��LRL��GFF������»��,���ܷdz���(PSNR=34.87 dB)��������ѵ��[3]��������ɵ�,���һ�֤�����ڷdz���������жѵ���������ܼ���[7]����������õ����ܡ�
Ȼ��,���ǽ�CM��LRL��GFF�е�һ�����ӵ�������,�ֱ�õ�RDN CM1LR0GFF0��RDN CM0LRL1GFF0��RDN CM0 LRL0GFF1(��1�еĵڶ��������ĸ����)�����ǿ�����֤ÿ�������������Ч������ߵ����ܡ�����Ҫ����Ϊÿ���������������Ϣ�����ݶȡ�
���ǽ�һ������������������ɷ�,�ֱ�õ���RDN CM1LR1GFF0��RDN CM1 LR0GFF1��RDN CM0LRL1GFF1(��1�дӵ�5������7�����)�����Կ���,����������������ڽ�һ�������������ͬʱʹ�����������(��ʾΪRDN CM1LR1GFF1)ʱ,���Կ������Ƶ�����ʹ�����������RDN������á�
���ǻ���ͼ5�п��ӻ����������ϵ��������̡�������������������һ��,����CM��LRL��GFF���Խ�һ���ȶ�ѵ������,������������Ե������½�����Щ�����Ϳ��ӻ�����֤�������������CM��LRL��GFF����Ч�Ժ��洦��
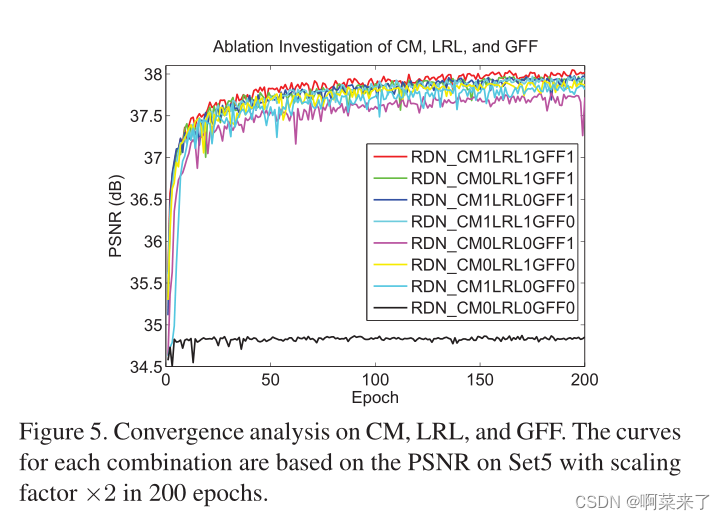
��ͼ5.CM��LRL��GFF�������Է�����ÿ����ϵ�������Set5�ϵķ�ֵ�����,��������Ϊ200����Ԫ�еġ�2����
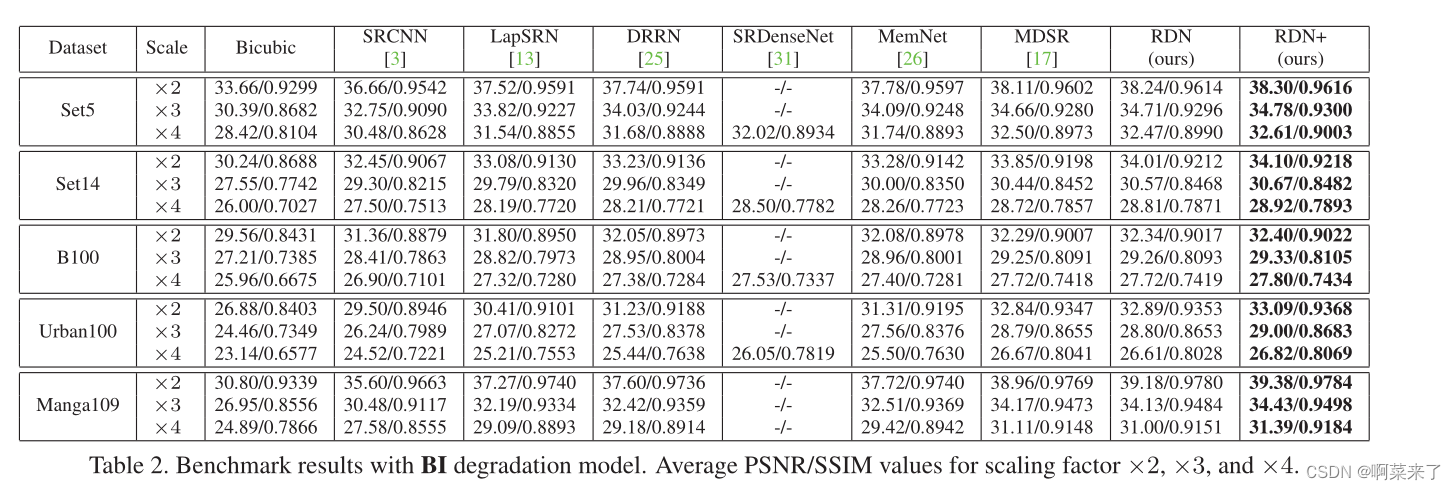
5.4. Results with BI Degradation Model
��˫�˻�ģ��ģ��LRͼ��㷺����ͼ��SR���á�����˫�˻�ģ��,���ǽ����ǵ�RDN��6�����Ƚ���ͼ��SR�������бȽ�:SRCNN[3]��LapSRN[13]��DRRN[25]��SRDenseNet[31]��MemNet[26]��MDSR[17]����[30,17]����,���ǻ��������Լ��ɲ���[17]����һ���Ľ����ǵ�RDN,�����Լ���RDN��ʾΪRDN+����������,��������RDN���������õ����ܡ���һ����,���ڴ�����ȽϷ���ÿ��Conv���ʹ�ô�Լ64��������,����ͨ��ʹ��D=16��C=8��G=64���й�ƽ�Ƚ�������RDN�Ľ�����˴�����EDSR[17],��Ϊ����ÿ��Conv��ʹ���˸�����˲���(��256��),�Ӷ��γ��˾��д��������ķdz��������硣Ȼ��,���ǵ�RDNҲ�������EDSR�൱�������õĽ��[17]��
��2��ʾ�ˡ�2����3�͡�4 SR�Ķ����Ƚϡ�SRDenseNet[31]�Ľ�����������ǵ����ġ���־���CNNģ��(SRDenseNet[31]��MemNet[26])���,���ǵ�RDN�ھ��������������ӵ��������ݼ��ϱ�����á���������ǵ�ʣ���ܼ���(RDB)��SRDensenet[31]�е��ܼ����MemNet[26]�еĴ洢�����Ч��������ģ�����,���ǵ�RDN�ڴ�������ݼ���Ҳ�������ѵ�ƽ��������������,���ڱ������ӡ�2,���ǵ�RDN���������ݼ��϶�������á����������ӱ�ø���ʱ(����,��3�͡�4),RDN����������MDSR���Ƶ�����[17]�����������Ҫ������ԭ������,MDSR����(160 v.s.128),�д�Լ160������ȡLR�ռ��е����������,MDSR��VDSRһ�����ö�߶�����[10]������,MDSRʹ�ýϴ��������С(65 v.s.32)����ѵ��������Urban100�еĴ����ͼ���������ƽṹ,�������ѵ���Ľϴ�������С�����dz����������õ����ýϴ�ĸ���Ұ�����ո�����Ϣ������������Ҫ��ע��RDN����Ч�Ժ�ƽ�Ƚ�,����û��ʹ�ø�������硢��߶���Ϣ���������벹����С������,���ǵ�RDN+����ͨ���Լ���ʵ�ֽ�һ���Ľ�[17]��

��ͼ6��,������ʾ�˶�ͼ��119082���ı����ߡ�4.F���Ӿ��Ƚ�,���ǹ۲쵽������ȽϷ�����������Ե�αӰ������ģ����Ե���෴,���ǵ�RDN���Իָ��������ı�Ե,����ʵ�ڵ���ʵ��������ͼ��img 043���е�ϸ��(��ɫ��ͷ��ָ),���бȽϵķ��������ָ����������ǵ�RDN�������Եػָ���������Ҫ����ΪRDNͨ���ܼ������ں�ʹ�ò��������
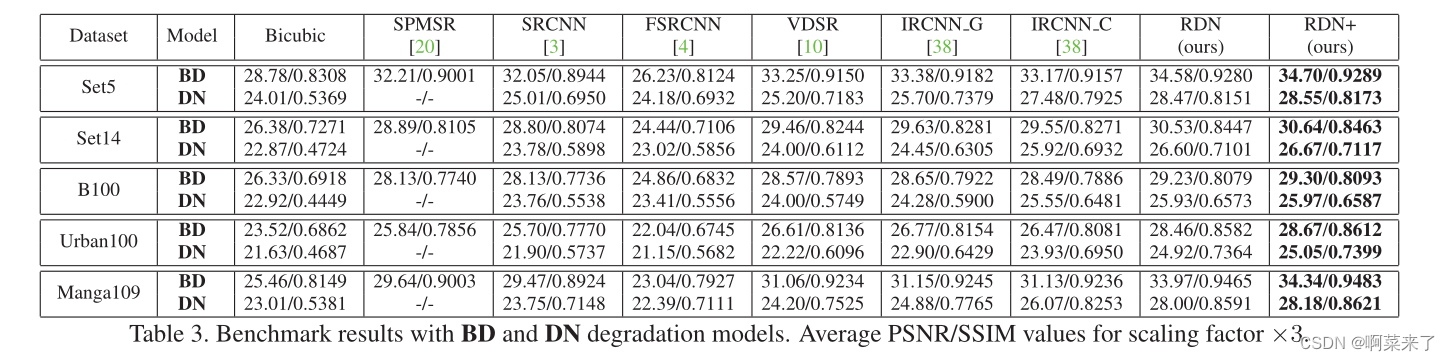
5.5. Results with BD and DN Degradation Models
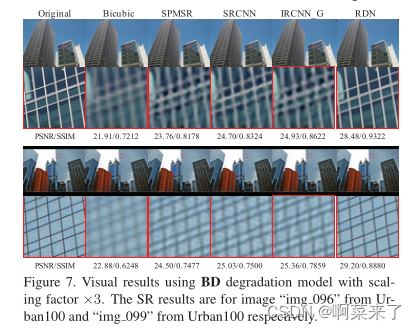
��[38]֮��,���ǻ�չʾ��BD�˻�ģ�͵�SR���,����һ��������DN�˻�ģ�͡����ǵ�RDN��SPMSR[20]��SRCNN[3]��FSRCNN[4]��VDSR[10]��IRCNN G[38]��IRCNN C[38]�����˱Ƚϡ�����Ϊÿ���˻�ģ������ѵ��SRCNN��FSRCNN��VDSR����3��ʾ��Set5��Set14��B100��Urban100��Manga109��ƽ��PSNR��SSIM���,��������Ϊ��3�����ǵ�RDN��RDN+�����о���BD��DN�˻�ģ�͵����ݼ��ϱ�����á����������Ƚ��ķ������,����������ͼ��7��8��
����BD�˻�ģ��(ͼ7),ʹ�ò�ֵLRͼ����Ϊ����ķ������������Ե�αӰ,������ȥ��ģ��αӰ���෴,���ǵ�RDN������ģ��αӰ���ָ��˸������ı�Ե���ñȽϱ���,��ԭʼLRͼ������ȡ�ֲ�����������ģ��αӰ����Ҳ֤����RDN��BD�˻�ģ�͵�ǿ��������
����DN�˻�ģ��(ͼ8),����LRͼ�������ƻ�����ʧһЩϸ�ڡ����ǹ۲쵽,����ϸ�ں���ͨ�����������ָ�[3,10,38]��Ȼ��,���ǵ�RDN����������Ч�ش�������,�����Իָ�����ϸ�ڡ���һ�Ƚϱ���,RDN����������ͼ��ȥ���SR����BD��DN�˻�ģ�͵���Щ���֤�������ǵ�RDNģ�͵���Ч�Ժ�³���ԡ�

5.6. Super-Resolving Real-World Images
���ǻ����������д����Ե���ʵͼ��оƬ��(244��200����)�͡�hatc��(133��174����)[41]������SRʵ�顣�����������HRͼ����,�˻�ģ��Ҳδ֪�����ǽ����ǵ�RND��VDSR[10]��LapSRN[13]��MemNet[26]�����˱Ƚϡ���ͼ9��ʾ,���������Ƚ��ķ������,���ǵ�RDN�ָ��˸������ı�Ե����ϸ��ϸ�ڡ���Щ�����һ�������˴�ԭʼ����ͼ��ѧϰ�ܼ������ĺô������ڲ�ͬ��δ֪���˻�ģ��,�ֲ���������ǿ����
6. Conclusions
�ڱ�����,���������һ������ͼ��SR������в��ܼ�����(RDN),���вв��ܼ���(RDB)��Ϊ��������ģ�顣��ÿ��RDB��,ÿ����֮����ܼ���������������þֲ��㡣�ֲ������ں�(LFF)�����ȶ���ѵ������,��������Ӧ�ؿ����˵�ǰ����ǰRDB����Ϣ�ı��档RDB��������ǰ���RDB�͵�ǰ���ÿһ��֮�����ֱ������,�Ӷ��γ������ڴ�(CM)���ơ��ֲ�ʣ��ѧϰ(LRL)��һ����������Ϣ�����ݶȡ�����,���������ȫ�������ں�(GFF)����ȡLR�ռ��еķֲ�������ͨ��������þֲ���ȫ������,���ǵ�RDNʵ�����ܼ��������ںϺ���ȼ�ء�����ʹ����ͬ��RDN�ṹ�����������˻�ģ�ͺ���ʵ�������ݡ��㷺�Ļ������ܺõ�֤�������ǵ�RDN�����з����������ơ�
7. Acknowledgements
���о����ֵõ���NSF IIS��1651902��ONR Young����Ա��N00014-14-10484������½���о��칫�ҽ�W911NF-171-0367��֧�֡�
References
[1] M. Bevilacqua, A. Roumy, C. Guillemot, and M. L. Alberi-
Morel. Low-complexity single-image super-resolution based
on nonnegative neighbor embedding. In BMVC, 2012.
[2] C. Dong, C. C. Loy, K. He, and X. Tang. Learning a deep
convolutional network for image super-resolution. In ECCV,
2014.
[3] C. Dong, C. C. Loy, K. He, and X. Tang. Image super-
resolution using deep convolutional networks. TPAMI, 2016.
[4] C. Dong, C. C. Loy, and X. Tang. Accelerating the super-
resolution convolutional neural network. In ECCV, 2016.
[5] X. Glorot, A. Bordes, and Y . Bengio. Deep sparse rectifier
neural networks. In AISTATS, 2011.
[6] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning
for image recognition. In CVPR, 2016.
[7] G. Huang, Z. Liu, K. Q. Weinberger, and L. van der Maaten.
Densely connected convolutional networks. In CVPR, 2017.
[8] J.-B. Huang, A. Singh, and N. Ahuja. Single image super-
resolution from transformed self-exemplars. In CVPR, 2015.
[9] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive
growing of gans for improved quality, stability, and variation.
submitted to ICLR 2018, 2017.
[10] J. Kim, J. Kwon Lee, and K. Mu Lee. Accurate image super-
resolution using very deep convolutional networks. In CVPR,
2016.
[11] J. Kim, J. Kwon Lee, and K. Mu Lee. Deeply-recursive
convolutional network for image super-resolution. In CVPR,
2016.
[12] D. Kingma and J. Ba. Adam: A method for stochastic opti-
mization. In ICLR, 2014.
[13] W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Y ang. Deep
laplacian pyramid networks for fast and accurate super-
resolution. In CVPR, 2017.
[14] C. Ledig, L. Theis, F. Husz��r, J. Caballero, A. Cunning-
ham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and
W. Shi. Photo-realistic single image super-resolution using a
generative adversarial network. In CVPR, 2017.
[15] C.-Y . Lee, S. Xie, P . Gallagher, Z. Zhang, and Z. Tu. Deeply-
supervised nets. In AISTATS, 2015.
[16] K. Li, Z. Wu, K.-C. Peng, J. Ernst, and Y . Fu. Tell me where
to look: Guided attention inference network. arXiv preprint
arXiv:1802.10171, 2018.
[17] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee. Enhanced
deep residual networks for single image super-resolution. In
CVPRW, 2017.
[18] D. Martin, C. Fowlkes, D. Tal, and J. Malik. A database
of human segmented natural images and its application to
evaluating segmentation algorithms and measuring ecologi-
cal statistics. In ICCV, 2001.
[19] Y . Matsui, K. Ito, Y . Aramaki, A. Fujimoto, T. Ogawa, T. Ya-
masaki, and K. Aizawa. Sketch-based manga retrieval us-
ing manga109 dataset. Multimedia Tools and Applications,
2017.
[20] T. Peleg and M. Elad. A statistical prediction model based
on sparse representations for single image super-resolution.
TIP, 2014.
[21] S. Schulter, C. Leistner, and H. Bischof. Fast and accu-
rate image upscaling with super-resolution forests. In CVPR,
2015.
[22] W. Shi, J. Caballero, F. Husz��r, J. Totz, A. P . Aitken,
R. Bishop, D. Rueckert, and Z. Wang. Real-time single im-
age and video super-resolution using an efficient sub-pixel
convolutional neural network. In CVPR, 2016.
[23] W. Shi, J. Caballero, C. Ledig, X. Zhuang, W. Bai, K. Bha-
tia, A. M. S. M. de Marvao, T. Dawes, D. ORegan, and
D. Rueckert. Cardiac image super-resolution with global
correspondence using multi-atlas patchmatch. In MICCAI,
2013.
[24] C. Szegedy, S. Ioffe, V . V anhoucke, and A. A. Alemi.
Inception-v4, inception-resnet and the impact of residual
connections on learning. In AAAI, 2017.
[25] Y . Tai, J. Y ang, and X. Liu. Image super-resolution via deep
recursive residual network. In CVPR, 2017.
[26] Y . Tai, J. Y ang, X. Liu, and C. Xu. Memnet: A persistent
memory network for image restoration. In ICCV, 2017.
[27] R. Timofte, E. Agustsson, L. V an Gool, M.-H. Y ang,
L. Zhang, B. Lim, S. Son, H. Kim, S. Nah, K. M. Lee,
et al. Ntire 2017 challenge on single image super-resolution:
Methods and results. In CVPRW, 2017.
[28] R. Timofte, V . De, and L. V . Gool. Anchored neighborhood
regression for fast example-based super-resolution. In ICCV,
2013.
[29] R. Timofte, V . De Smet, and L. V an Gool. A+: Adjusted
anchored neighborhood regression for fast super-resolution.
In ACCV, 2014.
[30] R. Timofte, R. Rothe, and L. V an Gool. Seven ways to
improve example-based single image super resolution. In
CVPR, 2016.
[31] T. Tong, G. Li, X. Liu, and Q. Gao. Image super-resolution
using dense skip connections. In ICCV, 2017.
[32] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P . Simoncelli.
Image quality assessment: from error visibility to structural
similarity. TIP, 2004.
[33] R. Zeyde, M. Elad, and M. Protter. On single image scale-up
using sparse-representations. In Proc. 7th Int. Conf. Curves
Surf., 2010.
[34] H. Zhang and V . M. Patel. Densely connected pyramid de-
hazing network. In CVPR, 2018.
[35] H. Zhang and V . M. Patel. Density-aware single image de-
raining using a multi-stream dense network. In CVPR, 2018.
[36] H. Zhang, V . Sindagi, and V . M. Patel. Image de-raining
using a conditional generative adversarial network. arXiv
preprint arXiv:1701.05957, 2017.
[37] K. Zhang, X. Gao, D. Tao, and X. Li. Single image super-
resolution with non-local means and steering kernel regres-
sion. TIP, 2012.
[38] K. Zhang, W. Zuo, S. Gu, and L. Zhang. Learning deep cnn
denoiser prior for image restoration. In CVPR, 2017.
[39] K. Zhang, W. Zuo, and L. Zhang. Learning a single convo-
lutional super-resolution network for multiple degradations.
In CVPR, 2018.
[40] L. Zhang and X. Wu. An edge-guided image interpolation al-
gorithm via directional filtering and data fusion. TIP, 2006.
2480
[41] Y . Zhang, Y . Zhang, J. Zhang, D. Xu, Y . Fu, Y . Wang, X. Ji,
and Q. Dai. Collaborative representation cascade for single
image super-resolution. IEEE Trans. Syst., Man, Cybern.,
Syst., PP(99):1�C11, 2017.
[42] W. W. Zou and P . C. Y uen. V ery low resolution face recog-
nition problem. TIP, 2012.