ЁЖScatter Component Analysis: A Unified Framework for Domain Adaptation and Domain GeneralizationЁЗбЇЯА
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
ЮФеТФПТМ
еЊвЊ
СНИіУмЧаЯрЙиЕФПђМм,гђздЪЪгІКЭгђЗКЛЏ,гыДЫРрШЮЮёгаЙи,ЦфжаетаЉПђМмжЎМфЕФЮЈвЛЧјБ№ЪЧЮДБъМЧФПБъЪ§ОнЕФПЩгУад:гђздЪЪгІПЩвдРћгУЮДБъМЧФПБъаХЯЂ,ЖјгђЗКЛЏВЛФмЁЃ
ЮвУЧЬсГіСЫЩЂЩфЗжСПЗжЮі(SCA),етЪЧвЛжжПьЫйБэЪОбЇЯАЫуЗЈ,ПЩгІгУгкгђздЪЪгІКЭгђЗКЛЏЁЃSCAЛљгквЛИіМђЕЅЕФМИКЮЖШСП,МДЩЂЩф,ЫќдкдйЩњКЫЯЃЖћВЎЬиПеМфЩЯдЫааЁЃ
SCAевЕНСЫвЛжждкзюДѓЛЏРрЕФПЩЗжРыадЁЂзюаЁЛЏгђжЎМфЕФВЛЦЅХфКЭзюДѓЛЏЪ§ОнЕФПЩЗжРыаджЎМфНјааШЈКтЕФБэЪО;ЦфжаУПвЛИіЖМЭЈЙ§ЗжЩЂСПЛЏЁЃ
SCAЕФгХЛЏЮЪЬтПЩвдМђЛЏЮЊЙувхЬиеїжЕЮЪЬт,ДгЖјЕУЕНПьЫйОЋШЗЕФНтЁЃдкЛљзМПчгђЖдЯѓЪЖБ№Ъ§ОнМЏЩЯНјааЕФзлКЯЪЕбщбщжЄСЫSCAЕФадФмБШМИжжзюЯШНјЕФЫуЗЈПьЕУЖр,ВЂЧвдкгђздЪЪгІКЭгђЗКЛЏЗНУцЖМЬсЙЉСЫзюЯШНјЕФЗжРрОЋЖШЁЃЮвУЧЛЙБэУї,дкгђздЪЪгІЕФЧщПіЯТ,ЩЂЩфПЩвдгУРДНЈСЂРэТлЗКЛЏНчЁЃ
Ыїв§Яю:СьгђздЪЪгІЁЂСьгђЗКЛЏЁЂЬиеїбЇЯАЁЂКЫаФЗНЗЈЁЂЗжЩЂадКЭЖдЯѓЪЖБ№
вЛЁЂНщЩм
ПЊЗЂЖдБъМЧЯЁШБадКЭЪ§ОнМЏЦЋВюОпгаТГАєадЕФбЇЯАЫуЗЈЪЧвЛИіживЊЖјНєЦШЕФЮЪЬтЁЃ
ЬсГіСЫгђздЪЪгІ[10]КЭгђЗКЛЏ[11]РДПЫЗўЩЯЪіЮЪЬтЁЃдкетжжЧщПіЯТ,гђБэЪОДгжаЬсШЁбљБОЕФИХТЪЗжВМ,ЭЈГЃЕШЭЌгкЪ§ОнМЏЁЃ
гђздЪЪгІЕФФПБъЪЧЭЈЙ§ЖддДгђЕФБъЧЉНјаабЕСЗ,ВЂдкбЕСЗЦкМфРћгУФПБъгђЕФЮДБъМЧбљБОзїЮЊИЈжњаХЯЂ,дкФПБъгђЩЯЩњГЩСМКУЕФФЃаЭ
гђЗКЛЏЮЪЬтГіЯждкЮДБъМЧЕФФПБъбљБОВЛПЩгУ,ЕЋПЩвдЗУЮЪЖрИідДгђЕФбљБОЕФЧщПіЯТЁЃ
ОЁЙмгђздЪЪгІКЭгђЗКЛЏЪЧУмЧаЯрЙиЕФЮЪЬт,ЕЋгђздЪЪгІЫуЗЈЭЈГЃВЛФмжБНггІгУгкгђЗКЛЏ,вђЮЊЫќУЧвРРЕгкФПБъгђжа(ЮДБъМЧ)бљБОЕФПЩгУадЁЃ
ЗЧГЃашвЊПЊЗЂФмЙЛИќИпаЇЕиМЦЫуЁЂгыгђздЪЪгІКЭгђЩњГЩМцШнВЂЬсЙЉзюЯШНјадФмЕФЫуЗЈЁЃ
1.1ФПБъКЭФПЕФ
ЮвУЧЫуЗЈЕФЛљБОЫМЯыЪЧбЇЯАБэЪОзїЮЊЗжРрЦїЕФЪфШы,ИУЗжРрЦїЖдЪ§ОнМЏЦЋВюБЃГжВЛБфЁЃжБОѕЩЯ,бЇЯАЕНЕФБэДягІАќКЌЫФИівЊЧѓ:
- ЪЙгУВЛЭЌБъЧЉЗжРыЕу,
- НЋЪ§ОнзїЮЊвЛИіећЬхЗжРы(ИпЗНВю),
- ВЛЗжРыЙВЯэБъЧЉЕФЕу,
- МѕЩйСНИіЛђЖрИігђжЎМфЕФВЛЦЅХфЁЃ
БОЮФЕФжївЊЙБЯзШчЯТ:
- ЕквЛИіЙБЯзЪЧЩЂЩф,етЪЧвЛИіМђЕЅЕФМИКЮКЏЪ§,СПЛЏСЫЗжВМОрЦфжЪаФЕФОљЗНОрРыЁЃЮвУЧБэУї,ЩЯЪіЫФЯювЊЧѓПЩвдЭЈЙ§РыЩЂЖШНјааБрТы,ВЂгыЯпадХаБ№ЗжЮіЁЂжїГЩЗжЗжЮіЁЂзюДѓОљжЕВювь(MMD)КЭЗжВМЗНВюНЈСЂЙиЯЕ
- ЕкЖўИіЙБЯзЪЧвЛжжПьЫйЕФЛљгкЗжЩЂЕФЬиеїбЇЯАЫуЗЈ,ПЩгІгУгкСьгђздЪЪгІКЭСьгђЗКЛЏЮЪЬт,МДЗжЩЂзщМўЗжЮі(SCA),МћЫуЗЈ1ЁЃОнЮвУЧЫљжЊ,SCAЪЧЕквЛИіЪЪгУгквЛЯЕСаСьгђздЪЪгІКЭЗКЛЏШЮЮёЕФЖргУЭОЫуЗЈЁЃSCAгХЛЏМђЛЏЮЊЙувхЬиеїЮЪЬт,дкЪБМфИДдгЖШЗНУцдЪаэгыКЫPCA[26]ЯрЭЌЕФПьЫйОЋШЗНтЁЃ
- ЕкШ§ИіЙБЯзЪЧЭЦЕМСЫгђздЪЪгІЧщПіЯТSCAЕФРэТлНчЁЃЮвУЧЕФРэТлЗжЮіБэУї,гђЗжЩЂПижЦзХSCAЕФЗКЛЏадФмЁЃЮвУЧжЄУїСЫдквЛЖЈЬѕМўЯТ,гђЩЂЩфПижЦРыЩЂОрРыЁЃЯШЧАвбОжЄУї,РыЩЂОрРыПЩвдПижЦгђздЪЪгІЫуЗЈЕФЗКЛЏадФм
ЮвУЧНјааСЫЙуЗКЕФЪЕбщ,вдЦРЙРSCAдкгђЪЪХфКЭгђЗКЛЏЩшжУжаЯрЖдгквЛДѓЬзБИбЁЗНАИЕФадФмЁЃЮвУЧЗЂЯж,дквЛЯЕСаЪгОѕЖдЯѓПчгђЪЖБ№жа,SCAЕФжДааЫйЖШдЖдЖПьгкЯжгаММЪѕ,дкзМШЗадЗНУцОпгаОКељСІЛђИќКУЕФадФм
1.2ЮФеТЕФзщжЏ
Ек2НкУшЪіСЫЮЪЬтЕФЖЈвх,ВЂЛиЙЫСЫСьгђздЪЪгІКЭСьгђЗКЛЏЗНУцЕФЯжгаЙЄзїЁЃ
Ек3НкКЭЕк4НкУшЪіСЫЮвУЧЬсГіЕФЙЄОп,вдМАЯргІЕФЬиеїбЇЯАЫуЗЈ,МДЩЂЩфзщМўЗжЮіЁЃ
Ек5НкНщЩмСЫSCAЕФРэТлгђздЪЪгІЗЖЮЇЁЃ
Ек6НкКЭЕк7НкЬсЙЉСЫзлКЯЦРЙРНсЙћКЭЗжЮіЁЃ
зюКѓ,Ек8НкзмНсСЫБОЮФЁЃ
ЖўЁЂБГОАгыЮФЯззлЪі
Щш
S
=
{
x
i
,
y
i
}
i
=
1
n
ЁЋ
P
S=\{x_i,y_i\}^n_{i=1}\sim\mathbb{P}
S={xi?,yi?}i=1n?ЁЋPПЩвдЪЧРДздгђЕФбљБОЁЃЖдгкЯргІЕФОбщЗжВМ
P
^
(
x
,
y
)
=
1
n
ЁЦ
i
=
1
n
ІФ
(
x
i
,
y
i
)
(
x
,
y
)
\mathbb{\hat P}(x,y)=\frac{1}{n}\sum^n_{i=1}\delta_{(x_i,y_i)}(x,y)
P^(x,y)=n1?ЁЦi=1n?ІФ(xi?,yi?)?(x,y),ЪЙгУЗћКХ
P
^
\mathbb{\hat P}
P^ЪЧКмЗНБуЕФ;ЦфжаdЪЧDirac deltaЁЃЮвУЧЖЈвхгђздЪЪгІКЭгђЗКЛЏШчЯТ,
ЖЈвх1(гђЪЪХф)
Щш
P
s
\mathbb{P}^s
PsКЭ
P
t
\mathbb{P}^t
PtЗжБ№ЮЊдДгђКЭФПБъгђ,Цфжа
P
s
Ёй
P
t
\mathbb{P}^s\ne\mathbb{P}^t
PsЊС=PtЁЃ
ДгСНИігђжаГщШЁбљБО,БэЪОЮЊ
S
s
=
{
x
i
s
,
y
i
s
}
i
=
1
n
s
ЁЋ
P
s
S^s=\{x^s_i,y^s_i\}^{n_s}_{i=1}\sim\mathbb{P}^s
Ss={xis?,yis?}i=1ns??ЁЋPsКЭ
S
u
t
=
{
x
i
t
}
i
=
1
n
t
ЁЋ
P
X
t
S^t_u=\{x^t_i\}^{n_t}_{i=1}\sim\mathbb{P}^t_X
Sut?={xit?}i=1nt??ЁЋPXt?ЁЃгђздЪЪгІЕФШЮЮёЪЧбЇЯАСМКУЕФБъМЧКЏЪ§
f
P
t
f_{\mathbb{P}^t}
fPt?:
X
Ёњ
Y
X\rightarrow Y
XЁњYИјГі
S
s
S^s
SsКЭ
S
u
t
S^t_u
Sut?зїЮЊбЕСЗЪОР§ЁЃ
ЖЈвх2(гђЗКЛЏ)
ІЄ
=
{
P
1
,
Ё
,
P
m
}
\Delta=\{\mathbb{P}^1,\dots,\mathbb{P}^m\}
ІЄ={P1,Ё,Pm}ПЩвдЪЧmИідДгђЕФМЏКЯ,
P
t
?
ІЄ
\mathbb{P}^t\notin\Delta
PtЁЪ/ІЄЪЧФПБъгђЁЃБэЪОЮЊ
S
d
=
{
x
i
d
,
y
i
d
}
i
=
1
n
d
ЁЋ
P
d
S^d=\{x^d_i,y^d_i\}^{n_d}_{i=1}\sim\mathbb{P}^d
Sd={xid?,yid?}i=1nd??ЁЋPdбљБОШЁздmИідДгђЁЃгђЗКЛЏЕФШЮЮёЪЧбЇЯАБъМЧКЏЪ§
f
P
t
f_{\mathbb{P}^t}
fPt?:
X
Ёњ
Y
X\rightarrow Y
XЁњYИјГі
S
d
,
?
d
=
1
,
Ё
,
m
S^d,\forall d=1,\dots,m
Sd,?d=1,Ё,mзїЮЊбЕСЗЪОР§ЁЃ
дкЪЕМљжа,гђЗКЛЏвЊЧѓ
m
>
1
m>1
m>1ВХФме§ГЃЙЄзї,ОЁЙм
m
=
1
m=1
m=1ПЩФмВЛЛсЮЅЗДЖЈвх2ЁЃЧызЂвт,ШчЙћ
m
=
2
m=2
m=2КЭ
P
X
t
ЁЪ
ІЄ
\mathbb{P}^t_X\in\Delta
PXt?ЁЪІЄ,дђгђЗКЛЏПЩвдОЋШЗЕиМђЛЏЮЊгђздЪЪгІЁЃ
2.1гђздЪЪгІ
ЮвУЧНЋгђздЪЪгІЫуЗЈЗжЮЊШ§Рр:
- ЗжРрЦїздЪЪгІЗНЗЈ
- бЁдё/жиМгШЈЗНЗЈ
- ЛљгкЬиеїБфЛЛЕФЗНЗЈЁЃ
ЗжРрЦїздЪЪгІЗНЗЈжМдкЭЈЙ§РћгУдДгђЛђИЈжњгђЕФжЊЪЖ,дкФПБъгђЩЯбЇЯАСМКУЕФздЪЪгІЗжРрЦїЁЃ
жиаТМгШЈ(бЁдёЗНЗЈ)ЭЈЙ§жиаТМгШЈ(бЁдё)гыФПБъЪЕР§ЁАНгНќЁБЕФдДЪЕР§РДМѕЩйбљБОЦЋВюЁЃбЁдёПЩБЛЪгЮЊжиаТМгШЈЕФЁАгВЁБАцБОЁЃвдаБфСПзЊвЦЕФУћвхбаОПСЫетвЛЛљБОЫМЯыЁЃ
ЛљгкЬиеїБфЛЛЕФЗНЗЈПЩФмЪЧСьгђздЪЪгІжазюСїааЕФЗНЗЈЁЃ
вЛаЉЙЄзївбОНтОіСЫгђздЪЪгІЕФНќЫЦе§ШЗЕФРэТлНчЯоЁЃ
2.2СьгђЗКЛЏ
BlanchardЕШШЫ[11]ЪзЯШбаОПСЫетИіЮЪЬт,ВЂЬсГіСЫвЛжждіЧПЕФжЇГжЯђСПЛњ,НЋОбщБпдЕЗжВМБрТыЕНФкКЫжа,гУгкНтОіСїЪНЯИАћЪѕЕФздЖЏбЁЭЈЮЪЬтЁЃ
СьгђЗКЛЏЫуЗЈвВвбгУгкЖдЯѓЪЖБ№ЁЃ
зюНќ,ЬсГіСЫвЛжжЛљгкздЖЏБрТыЦїЕФЫуЗЈ,ЭЈЙ§ЖрШЮЮёбЇЯАЬсШЁгђВЛБфЬиеї
ОЁЙмгђздЪЪгІКЭгђЗКЛЏОпгаЯрЭЌЕФФПБъ(МѕЩйЪ§ОнМЏЦЋВю),ЕЋетаЉЗНЗЈЭЈГЃЛЅВЛМцШн-гђздЪЪгІЗНЗЈВЛФмжБНггІгУгкгђЗКЛЏ,ЗДжЎврШЛ
ОнЮвУЧЫљжЊ,жЛгаLRE-SVMПЩвдгІгУгкгђздЪЪгІКЭгђЗКЛЏЁЃ
DICAЁЂГЗЯњЦЋВюЛђUMLжаЕФгђЗКЛЏЫуЗЈЙЋЪНЭЈГЃВЛдЪаэПМТЧРДздФПБъгђЕФЮДБъМЧЪ§ОнЁЃ
ДЫЭт,вЛаЉзюЯШНјЕФСьгђздЪЪгІКЭСьгђЗКЛЏЫуЗЈ,ШчTJMКЭLRE-SVM,ашвЊНтОіМЦЫуИДдгЕФгХЛЏЮЪЬт,етЛсЕМжТНЯИпЕФЪБМфЩЯЕФИДдгадЁЃ
дкетЯюЙЄзїжа,ЮвУЧНЈСЂСЫвЛжжПЫЗўЩЯЪіЮЪЬтЕФПьЫйЫуЗЈЁЃ
Ш§ЁЂЩЂЖШ
ЮвУЧдквЛИіЬиеїПеМфжаЙЄзї,ИУПеМфЪЧвЛИідйЩњКЫЯЃЖћВЎЬиПеМф(RKHS)
H
\mathcal{H}
HЁЃжївЊЖЏЛњЪЧНЋдЪМЪфШызЊЛЛЕН
H
\mathcal{H}
HЩЯ,
H
\mathcal{H}
HЪЧИпЮЌЛђПЩФмЪЧЮоЯоЮЌПеМф,ЯЃЭћаТЬиеїЪЧЯпадПЩЗжРыЕФЁЃRKHSзюживЊЕФЬиадПЩФмЪЧЭЈЙ§КЫММЧЩдЪаэЖд
H
\mathcal{H}
HНјааМЦЫуЩЯПЩааЕФзЊЛЛЁЃ
ЖЈвх3(ЯЃЖћВЎЬиПеМфжаЕФдйЩњКЫ)ЁЃ
Щш
X
\mathcal X
XЮЊШЮвтМЏ,КЭ
H
?
{
f
:
X
Ёњ
R
}
\mathcal H\subset\{f:\mathcal X\rightarrow\mathbb R\}
H?{f:XЁњR}ЪЧ
X
\mathcal X
XЩЯЕФHilbertКЏЪ§ПеМфЁЃ
ЖЈвхЦРЙРКЏЪ§
L
x
:
H
Ёњ
R
L_x:\mathcal H\rightarrow\mathbb R
Lx?:HЁњR,ЭЈЙ§
L
x
[
h
]
:
=
h
(
x
)
,
?
h
ЁЪ
H
L_x[h]:=h(x),\forall h\in\mathcal H
Lx?[h]:=h(x),?hЁЪH
ШчЙћКЏЪ§
L
x
L_x
Lx?змЪЧгаНчЕФ,дђ
H
\mathcal H
HЪЧдйЩњКЫHilbertПеМф:
ЖдгкЫљгаЕФ
x
ЁЪ
X
x\in\mathcal X
xЁЪXДцдквЛИі
ІЫ
>
0
\lambda>0
ІЫ>0
ЈO
L
x
[
h
]
ЈO
=
ЈO
h
(
x
)
ЈO
Ём
ІЫ
ЁЮ
h
ЁЮ
H
(1)
|L_x[h]|=|h(x)|\le\lambda\|h\|_{\mathcal H}\tag{1}
ЈOLx?[h]ЈO=ЈOh(x)ЈOЁмІЫЁЮhЁЮH?(1)
вђДЫ,ДцдкКЏЪ§
?
:
X
Ёњ
H
\phi:\mathcal X\rightarrow\mathcal H
?:XЁњH(ГЦЮЊЙцЗЖЬиеїгГЩф)Тњзу:
ЈO
L
x
[
h
]
ЈO
=
?
h
,
?
(
x
)
?
=
h
(
x
)
ЖдЫљгаЕФ
h
ЁЪ
H
,
x
ЁЪ
X
(2)
|L_x[h]|=\langle h,\phi(x)\rangle=h(x)ЖдЫљгаЕФh\in\mathcal H,x\in\mathcal X\tag{2}
ЈOLx?[h]ЈO=?h,?(x)?=h(x)ЖдЫљгаЕФhЁЪH,xЁЪX(2)
вђДЫ,ЖдгкУПИі
t
ЁЪ
X
t\in\mathcal X
tЁЪX,ПЩвдаДШы
?
?
(
t
)
,
?
(
x
)
?
=
:
ІЪ
(
t
,
x
)
\langle \phi(t),\phi(x)\rangle=:\kappa(t,x)
??(t),?(x)?=:ІЪ(t,x)
КЏЪ§
ІЪ
:
X
ЁС
X
Ёњ
R
\kappa:\mathcal X\times\mathcal X\rightarrow\mathbb R
ІЪ:XЁСXЁњRБЛГЦЮЊдйЩњФкКЫ
БэДяЪН(1)ЪЧШЗБЃФкЛ§ДцдквдМАдкгђжаЕФУПИіЕуМЦЫуHжаУПИіКЏЪ§ЕФФмСІЕФзюШѕЬѕМў,Жј(2)дкЪЕМљжаЬсЙЉСЫИќгагУЕФИХФюЁЃ
дкв§ШыЩЂЩфжЎЧА,ПЩвдЗНБуЕиЪзЯШЪЙгУОљжЕгГЩфНЋЗЂЫЭгђБэЪОЮЊRKHSжаЕФЕу
ЖЈвх4(ОљжЕгГЩф)ЁЃ
МйЩш
X
\mathcal X
XХфБИСЫвЛИіФкКЫ,
H
\mathcal H
HЪЧОпгаЬиеїгГЩфЕФЯргІRKHS,
?
:
X
Ёњ
H
\phi:\mathcal X\rightarrow\mathcal H
?:XЁњH
Щш
ІЄ
X
\Delta_{\mathcal X}
ІЄX?БэЪО
X
\mathcal X
XЩЯЕФИХТЪЗжВММЏЁЃОљжЕгГЩфНЋ
X
\mathcal X
XЩЯЕФЗжВМШЁЮЊ
H
\mathcal H
HжаЕФЕу:
ІЬ
:
ІЄ
X
Ёњ
H
:
P
?
E
x
ЁЋ
P
[
?
(
x
)
]
=
:
ІЬ
P
\mu:\Delta_{\mathcal X}\rightarrow\mathcal H:\mathbb P\mapsto\mathbb E_{x\sim\mathbb P}[\phi(x)]=:\mu_{\mathbb P}
ІЬ:ІЄX?ЁњH:P?ExЁЋP?[?(x)]=:ІЬP?
МИКЮЩЯ,ЦНОљЭМЪЧ
?
\phi
?ЯТЗжВМЭМЯёЕФжЪаФЁЃЮвУЧНЋЩЂЩфЖЈвхЮЊЭМЯёжаЮЇШЦЦфжЪаФЕФЕуЕФЗНВю:
ЖЈвх5(ЩЂЖШ)
ЗжВМ
P
\mathbb P
Pдк
X
\mathcal X
XЩЯЯрЖдгк
?
\phi
?ЕФЩЂЩфЮЊ:
ІЗ
?
(
P
)
:
=
E
x
ЁЋ
P
[
ЁЮ
ІЬ
P
?
?
(
x
)
ЁЮ
H
2
]
\Psi_{\phi}(\mathbb P):=\mathbb E_{x\sim\mathbb P}\left[\|\mu_{\mathbb P}-\phi(x)\|^2_{\mathcal H}\right]
ІЗ??(P):=ExЁЋP?[ЁЮІЬP???(x)ЁЮH2?]
Цфжа
ЁЮ
?
ЁЮ
H
\|\cdot\|_{\mathcal H}
ЁЮ?ЁЮH?ЪЧ
H
\mathcal H
HЩЯЕФЗЖЪ§ЁЃ
гђЕФЩЂЩфВЛФмжБНгМЦЫу;ЯрЗД,ЫќЪЧИљОнЙлВьНсЙћЙРМЦЕФЁЃгаЯоЙлВтМЏ
{
x
1
,
Ё
,
x
n
}
\{x_1,\dots,x_n\}
{x1?,Ё,xn?}ЕФЩЂЩф;ЯрЖдгкОбщЗжВММЦЫу
P
^
(
x
)
:
=
1
n
ЁЦ
i
=
1
n
ІФ
x
i
(
x
)
Цфжа
ІФ
x
i
(
x
)
=
{
1
if
x
i
=
x
0
else.
\hat{\mathbb{P}}(x):=\frac{1}{n}\sum^{n}_{i=1}\delta_{x_i}(x)Цфжа\delta_{x_i}(x)=\begin{cases}1&\text{if}\quad x_i=x\\0&\text{else.}\end{cases}
P^(x):=n1?i=1ЁЦn?ІФxi??(x)ЦфжаІФxi??(x)={10?ifxi?=xelse.?
ЮвУЧЬсЙЉСЫвЛИіЖЈРэ,ЫЕУїСЫецЪЕЩЂЩфКЭгаЯобљБОЙРМЦжЎМфЕФВювьШчКЮЫцзХбљБОДѓаЁЖјМѕаЁЁЃ
ЖЈРэ1(ЩЂЩфНч)ЁЃ
МйЩш
P
\mathbb{P}
PЪЧДѓаЁЮЊnЕФЫљгабљБОЕФецЪЕЗжВМ,
P
^
\hat{\mathbb{P}}
P^ЪЧЦфОбщЗжВМЁЃ
НјвЛВНМйЩш
ЁЮ
?
(
x
)
ЁЮ
2
Ём
M
\|\phi(x)\|^2\le M
ЁЮ?(x)ЁЮ2ЁмMЖдгкЫљга
x
ЁЪ
X
x\in\mathcal X
xЁЪXЁЃШЛКѓ,
p
r
o
b
a
b
i
l
i
t
y
Ён
1
?
ІФ
probability\ge 1-\delta
probabilityЁн1?ІФ,
ЈO
ІЗ
?
(
P
)
?
ІЗ
?
(
P
^
)
ЈO
Ём
M
2
l
o
g
(
2
ІФ
)
n
|\Psi_{\phi}(\mathbb P)-\Psi_{\phi}(\hat{\mathbb P})|\le M\sqrt{\frac{2log(\frac{2}{\delta})}{n}}
ЈOІЗ??(P)?ІЗ??(P^)ЈOЁмMn2log(ІФ2?)??
зЂвт,Ждгк
M
M
MЕФНЯЕЭжЕКЭ
n
n
nЕФНЯИпжЕ,БпНчЕФгвВрЮЛжУНЯаЁЁЃДЫЭт,ШчЙћ
ІЪ
\kappa
ІЪЪЧИпЫЙКЫЕФаЮЪН,дђБпНчНіШЁОігк
n
n
n,вђЮЊ
M
=
1
M=1
M=1
ШчЙћЪфШыПеМфЪЧЯђСППеМф,Чв
?
\phi
?ЪЧКуЕШЪН,дђжБНгШчЯТ:
в§Рэ2(змЗНВюЮЊЩЂВМ)
pЮЌЕуМЏЕФЩЂВМ(ОиеѓаЮЪН)
X
=
[
x
1
,
Ё
,
x
n
]
T
ЁЪ
R
n
ЁС
p
\mathrm X=[\mathrm x_1,\dots,\mathrm x_n]^T\in\mathbb{R}^{n\times p}
X=[x1?,Ё,xn?]TЁЪRnЁСpЯрЖдгкЕЅЮЛгГЩф
?
(
x
)
:
=
x
\phi(\mathrm x):=\mathrm x
?(x):=x,ЪЧзмЗНВю:
ІЗ
(
X
)
=
1
n
T
r
(
X
?
X
ЁЅ
)
T
(
X
?
X
ЁЅ
)
=
Tr?Cov
(
X
)
\Psi(\mathrm X)=\frac{1}{n}Tr(\mathrm X-\bar {\mathrm X})^T(\mathrm X-\bar {\mathrm X})=\text{Tr Cov}(\mathrm X)
ІЗ(X)=n1?Tr(X?XЁЅ)T(X?XЁЅ)=Tr?Cov(X)
Цфжа
T
r
(
?
)
Tr(\cdot)
Tr(?)БэЪОМЃВйзї,
X
ЁЅ
=
[
x
ЁЅ
,
Ё
,
x
ЁЅ
]
T
\bar {\mathrm X}=[\bar {\mathrm x},\dots,\bar {\mathrm x}]^T
XЁЅ=[xЁЅ,Ё,xЁЅ]TЦфжа
x
ЁЅ
=
ЁЦ
i
=
1
n
x
i
ЁЅ
\bar {\mathrm x}=\sum^n_{i=1}\bar {\mathrm x_i}
xЁЅ=ЁЦi=1n?xi?ЁЅ?
ЮвУЧРћгУЗжЩЂРДжЦЖЈвЛжжГЦЮЊЗжЩЂзщМўЗжЮіЕФЬиеїбЇЯАЫуЗЈЁЃОпЬхЖјбд,ЗжЩЂзщМўЗжЮіСПЛЏСЫSCAжаЫљашЕФашЧѓ,вдПЊЗЂгђздЪЪгІКЭЗКЛЏЕФгааЇНтОіЗНАИ,етНЋдкЯТвЛНкжаУшЪіЁЃ
ЫФЁЂЩЂЩфГЩЗжЗжЮі
SCAЕФФПБъЪЧгааЇЕибЇЯАвЛжжБэЪОЗЈ,вдИФНјгђздЪЪгІКЭгђЗКЛЏЁЃИУВпТдЪЧНЋЙлВтжЕзЊЛЛЮЊЬиеїПеМфжаЕФЕуХфжУ,ДгЖјМѕЩйгђЪЇХфЁЃШЛКѓ,SCAевЕНЮЪЬтЕФБэЪОаЮЪН(МДЬиеїПеМфЕФЯпадБфЛЛ)
- дДгђКЭФПБъгђЯрЫЦ
- ОпгаЯрЭЌБъЧЉЕФдЊЫиЯрЫЦ
- ОпгаВЛЭЌБъЧЉЕФдЊЫиБЛКмКУЕиЗжРы
- ећИіЪ§ОнЕФЗНВюБЛзюДѓЛЏЁЃ
УПИіашЧѓЖМПЩвдЭЈЙ§ЕМжТЫФжжНсЙћЕФЗжЩЂРДСПЛЏ:
- гђЗжЩЂ,
- РрМфЗжЩЂ
- РрФкЗжЩЂ
- змЗжЩЂ
ЮвУЧЛЙНЋПДЕН,ЭЈЙ§аоИФЪфШыгђЕФХфжУ,SCAПЩвдЧсЫЩЧаЛЛЕНгђздЪЪгІЛђгђЗКЛЏЁЃ
4.1змЩЂЩф
ИјЖЈmИігђ
P
X
1
,
Ё
,
P
X
m
дк
X
\mathbb{P}^1_X,\dots,\mathbb{P}^m_Xдк\mathcal X
PX1?,Ё,PXm?дкX,ЮвУЧНЋзмгђЖЈвхЮЊЦНОљжЕ
P
ЁЅ
X
=
1
m
ЁЦ
d
=
1
m
P
X
d
\bar{\mathbb{P}}_X=\frac{1}{m}\sum^m_{d=1}\mathbb{P}^d_X
PЁЅX?=m1?ЁЦd=1m?PXd? ЁЃзмЩЂЩфЖЈвхЮЊ
total?scatter
=
ІЗ
?
(
P
ЁЅ
X
)
(3)
\text{total scatter}=\Psi_{\phi}(\bar{\mathbb{P}}_X)\tag{3}
total?scatter=ІЗ??(PЁЅX?)(3)
жЕЕУЧПЕїЕФЪЧ,ИУЖЈвхЪЧвЛАуадЕФ,вђЮЊЫќКИЧСЫгђЪЪгІ(
m
=
2
m=2
m=2,ЦфжавЛИіЪЧФПБъгђ)КЭгђЗКЛЏ(
m
>
2
m>2
m>2)ЁЃ
ИљОнвдЯТЪ§ОнЙРМЦзмЩЂЩф,Щш
X
=
[
x
1
,
Ё
,
x
n
]
T
ЁЪ
R
n
ЁС
p
X=[x_1,\dots,x_n]^T\in\mathbb R^{n\times p}
X=[x1?,Ё,xn?]TЁЪRnЁСpЪЧРДздЫљга
m
m
mИігђЕФЮДБъМЧбљБОЕФОиеѓ(
n
=
ЁЦ
d
=
1
m
n
d
n=\sum^m_{d=1}n_d
n=ЁЦd=1m?nd?,Цфжа
n
d
n_d
nd?ЪЧЕкdЮЌгђжаЕФЪОР§Ъ§)ЁЃ
ИјЖЈвЛИіЬиеїгГЩф
?
:
R
p
Ёњ
H
\phi:\mathbb{R}^p\rightarrow\mathcal H
?:RpЁњHЖдгІКЫ
ІЪ
\kappa
ІЪ,ЖЈвхвЛзщАДСаЯђСПХХСаЕФКЏЪ§
ІЕ
=
[
?
(
x
1
)
,
Ё
,
?
(
x
n
)
]
T
\Phi=[\phi(x_1),\dots,\phi(x_n)]^T
ІЕ=[?(x1?),Ё,?(xn?)]T,ШЁ
{
?
(
x
i
)
}
i
=
1
n
\{\phi(x_i)\}^n_{i=1}
{?(xi?)}i=1n?ЮЊжааФ,МѕШЅЦНОљжЕ,аЗНВюОиеѓЮЊ
Cov
(
ІЕ
)
=
1
n
ІЕ
T
ІЕ
\text{Cov}(\Phi)=\frac{1}{n}\Phi^T\Phi
Cov(ІЕ)=n1?ІЕTІЕЁЃгЩв§Рэ2,
ІЗ
?
(
P
ЁЅ
^
X
)
=
Tr?Cov
(
ІЕ
)
(4)
\Psi_{\phi}(\hat{\bar{\mathbb{P}}}_X)=\text{Tr Cov}(\Phi)\tag{4}
ІЗ??(PЁЅ^X?)=Tr?Cov(ІЕ)(4)
ЮвУЧИааЫШЄЕФЪЧЖдгаЯоЯрЙизгПеМфгІгУЯпадБфЛЛКѓЕФзмЩЂЕу
W
:
H
Ёњ
R
k
W:\mathcal H\rightarrow\mathbb R^k
W:HЁњRk,БмУтжБНгМЦЫу
?
:
X
Ёњ
H
\phi:\mathcal X\rightarrow\mathcal H
?:XЁњH,етПЩФмЪЧАКЙѓЕФЛђВЛПЩГЗЯћЕФ,ЮвУЧЪЙгУФкКЫММЧЩЁЃ
ШУ
Z
=
ІЕ
W
ЁЪ
R
n
ЁС
k
Z=\Phi W\in\mathbb R^{n\times k}
Z=ІЕWЁЪRnЁСkЪЧnИіБфЛЛКѓЕФЬиеїЯђСП,
[
K
]
i
,
j
=
[
ІЕ
ІЕ
T
]
i
,
j
=
[
ІЪ
(
x
i
,
x
j
)
]
[K]_{i,j}=[\Phi\Phi^T]_{i,j}=[\kappa(x_i,x_j)]
[K]i,j?=[ІЕІЕT]i,j?=[ІЪ(xi?,xj?)],ШЗЖЈСЫ
B
ЁЪ
R
n
ЁС
k
B\in\mathbb R^{n\times k}
BЁЪRnЁСkжЎКѓЪЙ
W
=
ІЕ
T
B
W=\Phi^TB
W=ІЕTB,БфЛЛКѓЕФЩЂЕузмЪ§ЮЊ
ІЗ
B
Ёу
?
(
P
Ѓў
^
X
)
=
Tr
?
(
1
n
B
?
K
K
B
)
(5)
\Psi_{\mathbf{B} \circ \phi}\left(\hat{\overline{\mathbb{P}}}_{X}\right)=\operatorname{Tr}\left(\frac{1}{n} \mathbf{B}^{\top} \mathbf{K K B}\right)\tag{5}
ІЗBЁу??(P^X?)=Tr(n1?B?KKB)(5)
ЮвУЧзЂвтЕН,дкЮвУЧЕФЗћКХжа,КЫжїГЩЗжЗжЮі(KPCA)ЖдгІгкгХЛЏЮЪЬт
max
?
ІЗ
B
Ёу
?
(
P
Ѓў
^
X
)
(6)
\max\Psi_{\mathbf{B} \circ \phi}\left(\hat{\overline{\mathbb{P}}}_{X}\right)\tag{6}
maxІЗBЁу??(P^X?)(6)
4.2гђЩЂЩф
МйЩшвбжЊmИіЖЈвхгђ
P
X
1
,
Ё
,
P
X
m
\mathbb P^1_X,\dots,\mathbb P^m_X
PX1?,Ё,PXm?дк
X
\mathcal X
X,ЮвУЧПЩвдАбМЏКЯ
{
ІЬ
P
X
1
,
Ё
,
ІЬ
P
X
m
}
?
H
\{\mu_{\mathbb P^1_X},\dots,\mu_{\mathbb P^m_X}\}\subset\mathcal H
{ІЬPX1??,Ё,ІЬPXm??}?HзїЮЊвЛИіРДздФГаЉЧјгђЧБдкЗжВМЕФбљБО,НЋбљБОХфжУЮЊОбщЗжВМ,МЦЫуЩЂЕуЯрЖдгкHВњТЪгђЩЂЕуЩЯЕФКуЕШЭМ:
ІЗ
(
{
ІЬ
P
X
1
,
Ё
,
ІЬ
P
X
m
}
)
=
1
m
ЁЦ
i
=
1
m
ЁЮ
ІЬ
ЁЅ
?
ІЬ
P
i
ЁЮ
2
(7)
\Psi(\{\mu_{\mathbb P^1_X},\dots,\mu_{\mathbb P^m_X}\})=\frac{1}{m}\sum^m_{i=1}\|\bar\mu-\mu_{\mathbb P^i}\|^2\tag{7}
ІЗ({ІЬPX1??,Ё,ІЬPXm??})=m1?i=1ЁЦm?ЁЮІЬЁЅ??ІЬPi?ЁЮ2(7)
Цфжа
ІЬ
ЁЅ
=
1
m
ЁЦ
i
=
1
m
ІЬ
P
i
\bar\mu=\frac{1}{m}\sum^m_{i=1}\mu_{\mathbb P^i}
ІЬЁЅ?=m1?ЁЦi=1m?ІЬPi?ЁЃзЂвт,гђЩЂЩфгы[19]жав§ШыЕФЗжВМЗНВювЛжТЁЃдквЛаЉгђЪЪгІЫуЗЈжа,гђЩЂЩфгызюДѓОљжЕВювьвВгаУмЧаЙиЯЕЁЃ
ЖЈвх6:
FЩшЮЊКЏЪ§
f
:
X
Ёњ
R
f:\mathcal X\rightarrow\mathbb R
f:XЁњRЕФМЏКЯ,Чјгђ
P
\mathbb P
PКЭ
Q
\mathbb Q
QжЎМфЕФзюДѓОљжЕВювьЮЊ
M
M
D
F
[
P
,
Q
]
:
=
sup
?
f
ЁЪ
F
(
E
P
[
f
(
x
)
]
?
E
Q
[
f
(
x
)
]
)
MMD_{\mathcal F}[\mathbb{P,Q}]:=\sup_{f\in\mathcal F}\left(\mathbb E_{\mathbb P}[f(x)]-\mathbb E_{\mathbb Q}[f(x)]\right)
MMDF?[P,Q]:=fЁЪFsup?(EP?[f(x)]?EQ?[f(x)])
MMDДгКЏЪ§РрFЕФНЧЖШКтСПСНИігђБЫДЫЯрЫЦЕФГЬЖШЁЃвдЯТЖЈРэНЋЧјгђЩЂЕугыИјЖЈЕФСНИігђЕФMMDСЊЯЕЦ№РД,ЦфжаИааЫШЄЕФЧщПіЪЧЬиеїПеМфЩЯЕФгаНчЯпадКЏЪ§:
в§Рэ3(ЩЂЩфЛжИДMMD)
гђ
P
\mathbb P
PКЭ
Q
\mathbb Q
Qдк
X
\mathcal X
XЩЯЕФЩЂЖШЮЊЦф(ЦНЗН)зюДѓОљжЕВювь:
ІЗ
(
{
ІЬ
P
,
ІЬ
Q
}
)
=
1
4
M
M
D
F
2
[
P
,
Q
]
\Psi(\{\mu_{\mathbb P},\mu_{\mathbb Q}\})=\frac{1}{4}MMD^2_{\mathcal F}[\mathbb P,\mathbb Q]
ІЗ({ІЬP?,ІЬQ?})=41?MMDF2?[P,Q]
Цфжа
F
=
{
f
:
X
Ёњ
R
ЈO
f
ЪЧЯпадЕФ,ВЂЧв
ЁЮ
f
ЁЮ
F
Ём
1
}
\mathcal F=\{f:\mathcal X\rightarrow\mathbb R|fЪЧЯпадЕФ,ВЂЧв\|f\|_{\mathcal F}\le 1\}
F={f:XЁњRЈOfЪЧЯпадЕФ,ВЂЧвЁЮfЁЮF?Ём1}
ЬиБ№Еи,ШчЙћ
?
\phi
?ЪЧгЩ
X
\mathcal X
XЩЯЕФЬиеїКЫгеЕМЕФ,ФЧУД
ІЗ
(
{
ІЬ
P
,
ІЬ
Q
}
)
=
0
\Psi(\{\mu_{\mathbb P},\mu_{\mathbb Q}\})=0
ІЗ({ІЬP?,ІЬQ?})=0ЕБЧвНіЕБ
P
=
Q
\mathbb P=\mathbb Q
P=QЁЃ
ЧызЂвт,ИУЖЈРэЩцМАСНМЖИХТЪЗжВМ:
- X \mathcal X XЩЯЕФЧјгђ P \mathbb P PКЭ Q \mathbb Q Q
- F \mathcal F FЩЯЕФОбщЗжВМНЋ p = 1 2 p=\frac{1}{2} p=21?ЕФИХТЪЗжХфИј ІЬ P \mu_{\mathbb P} ІЬP?КЭ ІЬ Q \mu_{\mathbb Q} ІЬQ?Еу, p = 0 p=0 p=0ЗжХфИјЦфЫћЕуЁЃ
ИљОнЖЈвх5,
ІЗ
(
{
ІЬ
P
,
ІЬ
Q
}
)
=
1
2
ЁЮ
ІЬ
ЁЅ
?
ІЬ
P
ЁЮ
F
2
+
1
2
ЁЮ
ІЬ
ЁЅ
?
ІЬ
Q
ЁЮ
F
2
=
1
4
ЁЮ
ІЬ
P
?
ІЬ
Q
ЁЮ
F
2
\Psi(\{\mu_{\mathbb P},\mu_{\mathbb Q}\})=\frac{1}{2}\|\bar\mu-\mu_{\mathbb P}\|^2_{\mathcal F}+\frac{1}{2}\|\bar\mu-\mu_{\mathbb Q}\|^2_{\mathcal F}=\frac{1}{4}\|\mu_{\mathbb P}-\mu_{\mathbb Q}\|^2_{\mathcal F}
ІЗ({ІЬP?,ІЬQ?})=21?ЁЮІЬЁЅ??ІЬP?ЁЮF2?+21?ЁЮІЬЁЅ??ІЬQ?ЁЮF2?=41?ЁЮІЬP??ІЬQ?ЁЮF2?
в§Рэ3ЛЙИцЫпЮвУЧ,ШчЙћXЩЯЕФКЫЪЧЬиеїЕФ,дђгђЩЂЩфЪЧвЛИігааЇЕФЖШСПЁЃЬиеїКЫзюживЊЕФР§згЪЧИпЫЙRBFКЫ,ЫќЪЧЯТУцРэТлНсЙћКЭЪЕбщжаЪЙгУЕФКЫЁЃЮвУЧЛЙзЂвтЕН,MMDПЩвдгЩ[66]жаЬсЙЉЕФгаНчЙлВтЪ§ОнЙРМЦ,етгыЖЈРэ1РрЫЦЁЃ
дк
R
k
\mathbb R^k
Rkжа,ЖдБфЛЛКѓЕФЬиеїПеМфЕФгђЩЂЖШЙРМЦШчЯТЁЃ
МйЩшгаmИібљБО
S
u
d
=
{
x
i
d
}
i
=
1
n
d
ЁЋ
P
X
d
S^d_u=\{\mathbf x^d_i\}^{n_d}_{i=1}\sim\mathbb P^d_{\mathbf X}
Sud?={xid?}i=1nd??ЁЋPXd?ЛиЯывЛЯТ,
Z
=
ІЕ
W
=
K
T
B
\mathbf Z=\mathbf{\Phi W}=\mathbf{K}^T\mathbf{B}
Z=ІЕW=KTB,ЪНжа
Z
=
[
z
1
,
Ё
,
z
n
]
T
\mathbf Z=[\mathbf z_1,\dots,\mathbf z_n]^T
Z=[z1?,Ё,zn?]TАќКЌРДздЫљгагђЕФЭЖгАбљБО:
z
i
=
W
T
?
(
x
i
)
\mathbf z_i=\mathbf W^T\phi(\mathbf x_i)
zi?=WT?(xi?)КЭ
K
=
[
K
11
?
K
1
m
?
?
?
K
m
1
?
K
m
m
]
ЁЪ
R
n
ЁС
n
(8)
\mathbf{K}=\left[\begin{array}{ccc} \mathbf{K}^{11} & \cdots & \mathbf{K}^{1 m} \\ \vdots & \ddots & \vdots \\ \mathbf{K}^{m 1} & \cdots & \mathbf{K}^{m m} \end{array}\right] \in \mathbb{R}^{n \times n}\tag{8}
K=?
??K11?Km1?????K1m?Kmm??
??ЁЪRnЁСn(8)
ЪЧЖдгІЕФКЫОиеѓ,Цфжа
[
K
k
l
]
i
,
j
=
ІЪ
(
x
i
k
,
x
j
l
)
[\mathbf K^{kl}]_{i,j}=\kappa(\mathbf x^k_i,\mathbf x^l_j)
[Kkl]i,j?=ІЪ(xik?,xjl?),ЭЈЙ§ДњЪ§дЫЫу,гђЩЂЩфЪЧ
ІЗ
B
(
{
ІЬ
P
^
X
d
}
d
=
1
m
)
=
Tr
(
B
T
K
L
K
B
)
(9)
\Psi_{\mathbf B}(\{\mu_{\hat{\mathbb P}^d_{X}}\}^m_{d=1})=\text{Tr}(\mathbf B^T\mathbf {KLKB})\tag{9}
ІЗB?({ІЬP^Xd??}d=1m?)=Tr(BTKLKB)(9)
Цфжа
[
L
k
l
]
i
,
j
=
m
?
1
m
2
n
k
2
[\mathbf L^{kl}]_{i,j}=\frac{m-1}{m^2n^2_k}
[Lkl]i,j?=m2nk2?m?1?ЕФЯЕЪ§ОиеѓЪЧ
L
ЁЪ
R
n
ЁС
n
\mathbf L\in\mathbb R^{n\times n}
LЁЪRnЁСnШчЙћ
k
=
l
k=l
k=lКЭ
?
1
m
2
n
k
n
l
-\frac{1}{m^2n_kn_l}
?m2nk?nl?1?ЗёдђЁЃ
4.3РрЩЂЩф
ЖдгкУПвЛРр
k
ЁЪ
{
1
,
Ё
,
C
}
k\in\{1,\dots,C\}
kЁЪ{1,Ё,C},ШУ
P
X
ЈO
k
l
\mathbb P^l_{X|k}
PXЈOkl?БэЪО
Y
=
k
Y=k
Y=kЪБзмБъМЧгђ
P
X
Y
l
=
1
q
ЁЦ
j
=
1
q
P
X
Y
j
\mathbb P^l_{XY}=\frac{1}{q}\sum^q_{j=1}\mathbb P^j_{XY}
PXYl?=q1?ЁЦj=1q?PXYj?дкXЩЯЕФЬѕМўЗжВМ(БъМЧгђЕФЪ§СПqВЛвЛЖЈЕШгкдДгђЕФЪ§СПm)ЁЃ
ЮвУЧНЋРрФкЩЂЩфКЭРрМфЩЂЩфЖЈвхЮЊ
ІЗ
?
(
P
X
ЈO
k
l
)
?
within-class-?
k
?scatter?
?and?
ІЗ
(
{
ІЬ
P
X
ЈO
k
=
1
l
,
Ё
,
ІЬ
P
X
ЈO
k
=
C
l
}
)
?
between-classcatter?
.?
(10)
\underbrace{\Psi_{\phi}\left(\mathbb{P}_{X \mid k}^{l}\right)}_{\text {within-class- } k \text { scatter }} \text { and } \underbrace{\Psi\left(\left\{\mu_{\mathbb{P}_{X \mid k=1}^{l}}, \ldots, \mu_{\mathbb{P}_{X \mid k=C}^{l}}\right\}\right)}_{\text {between-classcatter }} \text {. }\tag{10}
within-class-?k?scatter?
ІЗ??(PXЈOkl?)???and?between-classcatter?
ІЗ({ІЬPXЈOk=1l??,Ё,ІЬPXЈOk=Cl??})??.?(10)
РрЩЂЩфЙРМЦШчЯТЁЃ
ШУ
S
k
w
=
(
?
(
x
j
)
)
x
j
ЁЪ
k
\mathbf S^w_k=(\phi(\mathbf{x}_j))_{\mathbf{x}_j\in k}
Skw?=(?(xj?))xj?ЁЪk?БэЪОРрkжадДбљБОЕФ
n
k
n_k
nk?дЊзщЁЃ
S
k
w
\mathbf S^w_k
Skw?ЕФжЪаФЮЊ
ІЬ
k
=
1
n
k
ЁЦ
x
i
ЁЪ
k
?
(
x
i
)
\mathbf{\mu}_k=\frac{1}{n_k}\sum_{\mathbf x_i\in k}\phi(\mathbf x_i)
ІЬk?=nk?1?ЁЦxi?ЁЪk??(xi?)
ДЫЭт,ШУ
S
b
=
(
ІЬ
1
,
Ё
,
ІЬ
ЈO
C
ЈO
)
\mathbf S^b=(\mu_1,\dots,\mu_{|C|})
Sb=(ІЬ1?,Ё,ІЬЈOCЈO?)БэЪОЫљгаРржЪаФЕФnдЊзщ,ЦфжажЪаФkдк
S
b
\mathbf S^b
SbжаГіЯж
n
k
n_k
nk?ДЮЁЃдђ
S
b
\mathbf S^b
SbЕФжЪаФЮЊдДгђжЪаФ:
1
n
ЁЦ
k
=
1
ЈO
c
ЈO
n
k
ІЬ
k
\frac{1}{n}\sum^{|c|}_{k=1}n_k\mu_k
n1?ЁЦk=1ЈOcЈO?nk?ІЬk?гЩДЫПЩжЊ,РрФкЩЂЖШЮЊ
ІЗ
?
(
P
^
X
ЈO
y
k
l
)
=
Tr
(
ЁЦ
j
=
1
n
k
(
?
(
x
)
j
k
?
ІЬ
k
)
(
?
(
x
)
j
k
?
ІЬ
k
)
T
)
\Psi_{\phi}\left(\hat{\mathbb{P}}_{X \mid y_k}^{l}\right)=\text{Tr}\left(\sum^{n_k}_{j=1}(\phi(\mathbf x)_{jk}-\mu_k)(\phi(\mathbf x)_{jk}-\mu_k)^T\right)
ІЗ??(P^XЈOyk?l?)=Tr(j=1ЁЦnk??(?(x)jk??ІЬk?)(?(x)jk??ІЬk?)T)
РрМфЕФЩЂЖШЪЧ
ІЗ
(
{
ІЬ
P
^
X
ЈO
y
k
l
}
k
=
1
C
)
=
Tr
(
n
k
(
ІЬ
k
?
ІЬ
ЁЅ
)
(
ІЬ
k
?
ІЬ
ЁЅ
)
T
)
\Psi\left(\{\mu_{\hat{\mathbb P}^l_{X \mid y_k}}\}^C_{k=1}\right)=\text{Tr}\left(n_k(\mu_k-\bar{\mu})(\mu_k-\bar{\mu})^T\right)
ІЗ({ІЬP^XЈOyk?l??}k=1C?)=Tr(nk?(ІЬk??ІЬЁЅ?)(ІЬk??ІЬЁЅ?)T)
ЩЯЪіЗНГЬЕФгвБпЪЧРрФкКЭРрМфЩЂЕу[24]ЕФОЕфЖЈвхЁЃвђДЫОЕфЕФЯпадХаБ№ЪНЪЧЩЂЩфБШ
FisherЁЏs?linear?discriminant
=
ІЗ
(
{
ІЬ
P
^
X
ЈO
y
k
l
}
k
=
1
C
)
ЁЦ
k
=
1
C
ІЗ
?
(
P
^
X
ЈO
y
k
l
)
\text{Fisher's linear discriminant}=\frac{\Psi\left(\{\mu_{\hat{\mathbb P}^l_{X \mid y_k}}\}^C_{k=1}\right)}{\sum^C_{k=1}\Psi_{\phi}\left(\hat{\mathbb{P}}_{X \mid y_k}^{l}\right)}
FisherЁЏs?linear?discriminant=ЁЦk=1C?ІЗ??(P^XЈOyk?l?)ІЗ({ІЬP^XЈOyk?l??}k=1C?)?
ИјЖЈвЛИіЯпадБфЛЛ
W
:
H
Ёњ
R
k
\mathbf W:\mathcal H\rightarrow\mathbb R^k
W:HЁњRkгЩв§Рэ2ПЩжЊ,РрдкЭЖгАЬиеїПеМф
H
~
\tilde H
H~жаЕФЩЂЩфЮЊ
ІЗ
B
(
{
ІЬ
P
^
X
ЈO
y
k
l
}
k
=
1
C
)
=
Tr
(
W
T
Cov
(
S
b
)
W
)
=
Tr
(
B
T
P
s
B
)
(11)
\Psi_{\mathbf B}\left(\{\mu_{\hat{\mathbb P}^l_{X \mid y_k}}\}^C_{k=1}\right)=\text{Tr}(\mathbf W^T\text{Cov}(\mathbf S^b)\mathbf W)\\ =\text{Tr}(\mathbf B^T\mathbf{P}_s\mathbf B)\tag{11}
ІЗB?({ІЬP^XЈOyk?l??}k=1C?)=Tr(WTCov(Sb)W)=Tr(BTPs?B)(11)
ЁЦ
k
=
1
C
ІЗ
B
Ёу
?
(
P
^
X
ЈO
y
k
s
)
=
ЁЦ
k
=
1
C
Tr
(
W
T
Cov
(
S
k
w
)
W
)
=
Tr
(
B
T
Q
s
B
)
(12)
\sum^C_{k=1}\Psi_{\mathbf B\circ\phi}\left(\hat{\mathbb{P}}_{X \mid y_k}^{s}\right)=\sum^C_{k=1}\text{Tr}(\mathbf W^T\text{Cov}(\mathbf S^w_k)\mathbf W)\tag{12}\\ =\text{Tr}(\mathbf B^T\mathbf{Q}_s\mathbf B)
k=1ЁЦC?ІЗBЁу??(P^XЈOyk?s?)=k=1ЁЦC?Tr(WTCov(Skw?)W)=Tr(BTQs?B)(12)
P
s
=
ЁЦ
k
=
1
C
n
k
(
m
k
?
m
ЁЅ
)
(
m
k
?
m
ЁЅ
)
T
(13)
\mathbf{P}_s=\sum^C_{k=1}n_k(\mathbf m_k-\bar{\mathbf m})(\mathbf m_k-\bar{\mathbf m})^T\tag{13}
Ps?=k=1ЁЦC?nk?(mk??mЁЅ)(mk??mЁЅ)T(13)
Q
s
=
ЁЦ
k
=
1
C
K
k
H
k
K
k
T
(14)
\mathbf{Q}_s=\sum^C_{k=1}\mathbf K_k\mathbf H_k\mathbf K_k^T\tag{14}
Qs?=k=1ЁЦC?Kk?Hk?KkT?(14)
Цфжа
m
k
=
1
n
k
ЁЦ
j
=
1
n
k
ІЪ
(
?
,
x
j
k
)
,
m
ЁЅ
=
1
n
ЁЦ
j
=
1
n
ІЪ
(
?
,
x
j
)
,
[
K
k
]
i
j
=
[
ІЪ
(
x
i
k
,
x
j
k
)
]
\mathbf m_k=\frac{1}{n_k}\sum^{n_k}_{j=1}\kappa(\cdot,\mathbf x_{jk}),\bar{\mathbf m}=\frac{1}{n}\sum^{n}_{j=1}\kappa(\cdot,\mathbf x_{j}),[\mathbf K_k]_{ij}=[\kappa(\mathbf x_{ik},\mathbf x_{jk})]
mk?=nk?1?ЁЦj=1nk??ІЪ(?,xjk?),mЁЅ=n1?ЁЦj=1n?ІЪ(?,xj?),[Kk?]ij?=[ІЪ(xik?,xjk?)]КЭжааФОиеѓ
H
k
=
I
n
k
?
1
n
k
1
n
k
1
n
k
T
\mathbf H_k=\mathbf I_{n_k}-\frac{1}{n_k}\mathbf 1_{n_k}\mathbf 1_{n_k}^T
Hk?=Ink???nk?1?1nk??1nk?T?,Цфжа
I
n
k
\mathbf I_{n_k}
Ink??БэЪО
n
k
ЁС
n
k
n_k\times n_k
nk?ЁСnk?ЕЅЮЛОиеѓ,
1
n
k
ЁЪ
R
n
k
\mathbf 1_{n_k}\in\mathbb R^{n_k}
1nk??ЁЪRnk?БэЪО1ЕФЯђСПЁЃ
4.4ЫуЗЈ
етРя,ЮвУЧЭЈЙ§КЯВЂЩЯЪіЫФИіСПРДжЦЖЈSCAЕФбЇЯАЫуЗЈЁЃSCAЕФФПБъЪЧЭЈЙ§НтОівдЯТБэДяЪНаЮЪНЕФгХЛЏЮЪЬтРДбАЧѓвЛжжБэЪО
sup
?
{total?scatter}+{between-class?scatter}
{domain?scatter}+{within-class?scatter}
(15)
\sup\frac{\text{\{total scatter\}+\{between-class scatter\}}}{\text{\{domain scatter\}+\{within-class scatter\}}}\tag{15}
sup{domain?scatter}+{within-class?scatter}{total?scatter}+{between-class?scatter}?(15)
ЪЙгУ(5),(9),(11),КЭ(12),ПЩвдИќЯъЯИЕижИЖЈЩЯУцЕФБэДяЪН:
arg?max
?
B
ІЗ
B
Ёу
?
(
P
Ѓў
^
X
)
+
ІЗ
B
(
{
ІЬ
P
^
X
ЈO
y
k
l
}
k
=
1
C
)
ІЗ
B
(
{
ІЬ
P
^
X
d
}
d
=
1
m
)
+
ЁЦ
k
=
1
C
ІЗ
B
Ёу
?
(
P
^
X
ЈO
y
k
s
)
(16)
\argmax_{\mathbf B}\frac{\Psi_{\mathbf{B} \circ \phi}\left(\hat{\overline{\mathbb{P}}}_{X}\right)+\Psi_{\mathbf B}\left(\{\mu_{\hat{\mathbb P}^l_{X \mid y_k}}\}^C_{k=1}\right)}{\Psi_{\mathbf B}(\{\mu_{\hat{\mathbb P}^d_{X}}\}^m_{d=1})+\sum^C_{k=1}\Psi_{\mathbf B\circ\phi}\left(\hat{\mathbb{P}}_{X \mid y_k}^{s}\right)}\tag{16}
Bargmax?ІЗB?({ІЬP^Xd??}d=1m?)+ЁЦk=1C?ІЗBЁу??(P^XЈOyk?s?)ІЗBЁу??(P^X?)+ІЗB?({ІЬP^XЈOyk?l??}k=1C?)?(16)
ЗжзгзюДѓЛЏПЩвдЙФРјSCAБЃГжЪ§ОнЕФзмЬхПЩБфадКЭРрЕФПЩЗжРыадЁЃ
зюаЁЛЏЗжФИПЩвдЙФРјSCAевЕНдДКЭФПБъгђЯрЫЦЕФБэЪОаЮЪН,ВЂЧвЙВЯэвЛИіБъЧЉЕФдДЪОР§вВЯрЫЦЁЃ
ФПБъКЏЪ§ЁЃЮвУЧгУШ§жжЗНЗЈжиаТЙЙдь(16)ЁЃЪзЯШ,ЮвУЧгУЯпадДњЪ§РДБэЪОЫќЁЃЦфДЮ,ЮвУЧВхШыГЌВЮЪ§РДПижЦЩЂЩфжЎМфЕФШЈКт,вђЮЊдкЬиЖЈЧщПіЯТ,вЛИіЩЂЩфСППЩФмБШЦфЫћЩЂЩфСПИќживЊЁЃЕкШ§,ЮвУЧЪЉМг
W
T
W
=
B
T
K
B
\mathbf W^T\mathbf W=\mathbf B^T\mathbf{KB}
WTW=BTKBКмаЁЕФдМЪјРДПижЦНтОіЗНАИЕФЙцФЃЁЃ
УїШЗЕи,SCAевЕНвЛИіЭЖгАОиеѓ
B
=
[
b
1
,
b
2
,
Ё
,
b
k
]
\mathbf B=[\mathbf b_1,\mathbf b_2,\dots,\mathbf b_k]
B=[b1?,b2?,Ё,bk?]НтОіСЫдМЪјгХЛЏЮЪЬт
arg?max
?
B
ЁЪ
R
n
ЁС
k
Tr
(
B
T
(
1
?
ІТ
n
K
K
+
ІТ
P
)
B
)
Tr
(
B
T
(
ІФ
K
L
K
+
Q
+
K
)
B
)
(17)
\argmax_{\mathbf B\in\mathbb R^{n\times k}}\frac{\text{Tr}(\mathbf B^T(\frac{1-\beta}{n}\mathbf {KK}+\beta\mathbf P)\mathbf B)}{\text{Tr}(\mathbf B^T(\delta\mathbf {KLK}+\mathbf Q+\mathbf K)\mathbf B)}\tag{17}
BЁЪRnЁСkargmax?Tr(BT(ІФKLK+Q+K)B)Tr(BT(n1?ІТ?KK+ІТP)B)?(17)
Цфжа
P
=
[
P
s
0
n
s
ЁС
n
t
0
n
t
ЁС
n
s
0
n
t
ЁС
n
t
]
,
Q
=
[
Q
s
0
n
s
ЁС
n
t
0
n
t
ЁС
n
s
0
n
t
ЁС
n
t
]
\mathbf{P}=\left[\begin{array}{cc} \mathbf{P}_{s} & \mathbf{0}_{n_{s} \times n_{t}} \\ \mathbf{0}_{n_{t} \times n_{s}} & \mathbf{0}_{n_{t} \times n_{t}} \end{array}\right], \mathbf{Q}=\left[\begin{array}{cc} \mathbf{Q}_{s} & \mathbf{0}_{n_{s} \times n_{t}} \\ \mathbf{0}_{n_{t} \times n_{s}} & \mathbf{0}_{n_{t} \times n_{t}} \end{array}\right]
P=[Ps?0nt?ЁСns???0ns?ЁСnt??0nt?ЁСnt???],Q=[Qs?0nt?ЁСns???0ns?ЁСnt??0nt?ЁСnt???]
КЭ
ІТ
,
ІФ
>
0
\beta,\delta>0
ІТ,ІФ>0ЗжБ№ЮЊПижЦзмЩЂЕуЁЂРрМфЩЂЕуКЭгђЩЂЕуЕФШЈКтВЮЪ§ЁЃ
зЂвт,ЩЯЪігХЛЏЖдгкЫѕЗХ
B
?
ІС
B
\mathbf B\mapsto \alpha \mathbf B
B?ІСBЪЧВЛБфЕФЁЃвђДЫ,гХЛЏ(17)ПЩвдИФаДЮЊ
arg?max
?
B
ЁЪ
R
n
ЁС
k
Tr
(
B
T
(
1
?
ІТ
n
K
K
+
ІТ
P
)
B
)
s.t.?Tr
(
B
T
(
ІФ
K
L
K
+
Q
+
K
)
B
)
=
1
(18)
\argmax_{\mathbf B\in\mathbb R^{n\times k}}\text{Tr}\left(\mathbf B^T\left(\frac{1-\beta}{n}\mathbf {KK}+\beta\mathbf P\right)\mathbf B\right)\\ \text{s.t. Tr}(\mathbf B^T(\delta\mathbf {KLK}+\mathbf Q+\mathbf K)\mathbf B)=1\tag{18}
BЁЪRnЁСkargmax?Tr(BT(n1?ІТ?KK+ІТP)B)s.t.?Tr(BT(ІФKLK+Q+K)B)=1(18)
ЕУЕНРИёРЪШеСП
J
(
B
)
=
Tr
(
B
T
(
1
?
ІТ
n
K
K
+
ІТ
P
)
B
)
?
Tr
(
(
B
T
(
ІФ
K
L
K
+
Q
+
K
)
B
?
I
k
)
ІЋ
)
(19)
J(\mathbf B)=\text{Tr}\left(\mathbf B^T\left(\frac{1-\beta}{n}\mathbf {KK}+\beta\mathbf P\right)\mathbf B\right)\\ -\text{Tr}((\mathbf B^T(\delta\mathbf {KLK}+\mathbf Q+\mathbf K)\mathbf B-\mathbf I_k)\Lambda)\tag{19}
J(B)=Tr(BT(n1?ІТ?KK+ІТP)B)?Tr((BT(ІФKLK+Q+K)B?Ik?)ІЋ)(19)
ЮЊЧѓНт(17),ЩшвЛНзЕМЪ§
?
J
(
B
)
?
B
=
0
\frac{\partial J(\mathbf B)}{\partial \mathbf B}=0
?B?J(B)?=0,ЕМГіЙувхЬиеїЮЪЬт
(
1
?
ІТ
n
K
K
+
ІТ
P
)
B
?
=
(
ІФ
K
L
K
+
Q
+
K
)
B
?
ІЋ
(20)
\left(\frac{1-\beta}{n}\mathbf {KK}+\beta\mathbf P\right)\mathbf B^*=(\delta\mathbf {KLK}+\mathbf Q+\mathbf K)\mathbf B^*\Lambda\tag{20}
(n1?ІТ?KK+ІТP)B?=(ІФKLK+Q+K)B?ІЋ(20)
Цфжа
ІЋ
=
diag
(
ІЫ
1
,
Ё
,
ІЫ
k
)
\Lambda=\text{diag}(\lambda_1,\dots,\lambda_k)
ІЋ=diag(ІЫ1?,Ё,ІЫk?)kЪЧЧАЕМЬиеїжЕ,
B
=
[
b
1
,
Ё
,
b
k
]
\mathbf B=[\mathbf b_1,\dots,\mathbf b_k]
B=[b1?,Ё,bk?]АќКЌЯргІЕФЬиеїЯђСП,ЫуЗЈ1ЬсЙЉСЫSCAЕФЭъећеЊвЊЁЃ

4.5гыЦфЫћЗНЗЈЕФЙиЯЕ
SCAгыаэЖрЬиадбЇЯАКЭСьгђЪЪгІЗНЗЈУмЧаЯрЙиЁЃ
ЭЈЙ§(19)жаЕФ
ІТ
=
ІФ
=
0
\beta=\delta=0
ІТ=ІФ=0КЭ
Q
=
0
\mathbf Q=0
Q=0ЕФГЌВЮЪ§ЛжИДKPCAЁЃЩшжУ
ІТ
=
1
\beta=1
ІТ=1КЭ
ІФ
=
0
\delta=0
ІФ=0ЛжИДKFD (Kernel Fisher Discriminant)ЗНЗЈ[67]ЁЃ
ОпгаЯпадКЫЕФKFDЕШМлгкFisherЕФЯпадХаБ№ЗЈ,етЪЧ[33]жаЬсГіЕФФПБъМьВтСьгђздЪЪгІЗНЗЈЕФЛљДЁЁЃ
ЩшжУ
ІТ
=
0
\beta=0
ІТ=0КЭ
Q
=
0
\mathbf Q=0
Q=0(МДКіТдРрЗжРы),ОЭВњЩњСЫвЛжжаТЕФЫуЗЈ:гыTCAУмЧаЯрЙиЕФЮоМрЖНЩЂЩфГЩЗжЗжЮі(unsupervised Scatter Component Analysis, uSCA)ЁЃСНжжЫуЗЈжЎМфЕФЧјБ№ЪЧ,TCAдМЪјзмЗНВюКЭе§дђЛЏБфЛЛ,ЖјuSCAШЈКтзмЗНВюКЭдМЪјБфЛЛ(ЛиЯывЛЯТ,
W
T
W
\mathbf W^T\mathbf W
WTWгІИУКмаЁ)ЕФЖЏЛњЪЧЖЈРэ1ЁЃЪТЪЕжЄУї,uSCAдкСьгђЪЪХфЗНУцвЛЙсгХгкTCA
ДгuSCA(17)жаДгЗжФИжаШЅЕє
B
T
K
B
\mathbf B^T\mathbf{KB}
BTKBЯю,ЕУЕНTCA[45]ЁЃTCAЕФАыМрЖНРЉеЙSSTCAгыSCAДцдкЯджјВювьЁЃSSTCAУЛгаНЋРрФкКЭРрМфЕФЗжЩЂКЯВЂЕНФПБъКЏЪ§жа,ЖјЪЧКЯВЂСЫвЛИіХЩЩњздЯЃЖћВЎЬи-ЪЉУмЬиЖРСЂзМдђЕФЯю,ИУЯюзюДѓЯоЖШЕиЬсИпСЫБъЧЉЩЯЧЖШыЕФвРРЕадЁЃ
дкСНИігђ[19]ЕФЧщПіЯТ,uSCAБОжЪЩЯЕШМлгкЮоМрЖНгђВЛБфГЩЗжЗжЮі(uDICA)ЁЃШЛЖј,ЖдгкSSTCA,ЪмМрЖНЕФDICAЭЈЙ§жааФзгПеМфЕФИХФюКЯВЂСЫгыSCAВЛЭЌЕФБъЧЉаХЯЂЁЃЬиБ№ЪЧгаМрЖНЕФDICAвЊЧѓЫљгаЕФЪ§ОнЕуЖМгаБъЧЉ,ЫљвддкЮвУЧЕФЪЕбщжаВЛФмгІгУЁЃ
4.6МЦЫуИДдгЖШ
МЦЫуОиеѓKЁЂLЁЂPКЭQашвЊ
O
(
n
2
)
O(n^2)
O(n2)(ЫуЗЈ1ЕФЕквЛаа)ЁЃ
вђДЫ,дкНтОіЬиеїЗжНтЮЪЬт(Ек2аа)Кѓ,SCAЕФзмИДдгЖШЮЊ
O
(
k
n
2
)
O(kn^2)
O(kn2),ЛђnЕФЖўДЮдЊЁЃетжжИДдгЖШгыKPCAКЭTransfer Component AnalysisРрЫЦ
гыжЎЧАзюЯШНјЕФФПБъЪЖБ№СьгђЪЪгІЫуЗЈЁЊЁЊзЊвЦСЊКЯЦЅХф[15]ЯрБШ,TJMВЩгУНЛЬцЬиеїЗжНтЙ§ГЬ,ЦфжаашвЊНјааTЕќДњЁЃЪЙгУЮвУЧЕФЗћКХ,TJMЕФИДдгадЪЧ
O
(
T
k
n
2
)
O(Tkn^2)
O(Tkn2),
4.7ГЌВЮЪ§ЩшжУ
дкЕк4НкжаУшЪіЕФSCAЙЋЪНгаЫФИіГЌВЮЪ§:
- КЫЕФбЁдё
- згПеМфЛљЪ§k
- РрМфКЭзмЩЂЩфелжд ІТ \beta ІТ
- гђЩЂЩф ІФ \delta ІФ
ЮвУЧДІРэетИіЮЪЬтЕФВпТдЪЧМѕЩйПЩЕїГЌВЮЪ§ЕФЪ§СП
ЖдгкФкКЫЕФбЁдё,ЮвУЧбЁдёСЫRBFФкКЫ
exp
(
?
ЁЮ
a
?
b
ЁЮ
2
Ів
2
)
,
?
a
,
b
ЁЪ
X
\text{exp}(\frac{-\|\mathbf{a-b}\|^2}{\sigma^2}),\forall\mathbf{a,b}\in\mathcal X
exp(Ів2?ЁЮa?bЁЮ2?),?a,bЁЪXЦфжаКЫДјПэ
Ів
\sigma
ІвБЛНтЮіЕиЩшжУЮЊвдЯТОлКЯгђжабљБОжЎМфЕФжажЕОрРы
Ів
=
median
?
(
ЁЮ
a
?
b
ЁЮ
2
2
)
,
?
a
,
b
ЁЪ
S
s
ЁШ
S
t
(21)
\sigma=\operatorname{median}\left(\|\mathbf{a}-\mathbf{b}\|_{2}^{2}\right), \forall \mathbf{a}, \mathbf{b} \in S^{s} \cup S^{t}\tag{21}
Ів=median(ЁЮa?bЁЮ22?),?a,bЁЪSsЁШSt(21)
ЖдгкгђЪЪгІ,
ІФ
\delta
ІФЙЬЖЈЮЊ1ЁЃвђДЫ,жЛгаСНИіГЌВЮЪ§ЪЧПЩЕїЕФ:
k
k
kКЭ
ІТ
\beta
ІТЁЃЖдгкгђЗКЛЏ,
ІТ
\beta
ІТЩшЮЊ1,МДЯћГ§змЕФЩЂЕу,
ІФ
\delta
ІФБЛдЪаэЕїгХ,ПЩЕїГЌВЮЪ§ЕФЪ§СПБЃГжВЛБфЁЃ
ИУХфжУЛљгкОбщЙлВь,ЩшжУ
0
<
ІТ
<
1
0 < \beta< 1
0<ІТ<1ВЂВЛБШЩшжУ
ІТ
=
1
\beta=1
ІТ=1ИќКУ(ШчЙћВЛЪЧИќВюЕФЛА),дкгђЗКЛЏАИР§ЕФНЛВцбщжЄКЭВтЪдадФмЗНУцЁЃдкЫљгаЦРЙРжа,ЮвУЧЪЙгУдДБъМЧЪ§ОнНјаа5ДЮНЛВцбщжЄ,вдевЕНзюгХkКЭ
ІТ
\beta
ІТЁЃЮвУЧЗЂЯж,ИУВпТдзувдЮЊСьгђЪЪгІКЭЗКЛЏЧщПіВњЩњСМКУЕФSCAФЃаЭЁЃ
ЮхЁЂздЪЪгІадФмЗжЮі
ЮвУЧЭЦЕМГівЛИігђздЪЪгІНч,ЯдЪОСЫMMDдкЦНЗНЫ№ЪЇ
l
(
y
,
y
Ёф
)
=
(
y
?
y
Ёф
)
2
l(y,y')=(y-y')^2
l(y,yЁф)=(y?yЁф)2ЧщПіЯТШчКЮПижЦЗКЛЏадФмЁЃЦфжївЊЫМЯыЪЧНЋMMD(МДгђЩЂЩф)ФЩШыВювьОрРы[27]ЕФЪЪгІНчжаЁЃдк[19]жаИљОнгђЩЂЩфИјГіСЫгђЗКЛЏЕФЗКЛЏНч,МћRemark 1ЁЃ

ШУ
Hyp
?
:
=
{
h
:
X
Ёњ
Y
}
\operatorname{Hyp}:=\{h:\mathcal X\rightarrow\mathcal Y\}
Hyp:={h:XЁњY}БэЪОДгXЕНYЕФвЛИіМйЩшКЏЪ§Рр,ЦфжаXЪЧвЛИіНєМЏЁЃИјЖЈвЛИіЖЈвхдкБъЧЉЖдЩЯЕФЫ№ЪЇКЏЪ§
l
:
Y
ЁС
Y
Ёњ
R
+
l:\mathcal Y\times \mathcal Y\rightarrow\mathbb R_+
l:YЁСYЁњR+?КЭЗжВМ
D
\mathbb D
Dдк
X
\mathcal X
X,Щш
L
D
(
h
,
h
Ёф
)
=
E
x
ЁЋ
D
[
?
(
h
(
x
)
,
h
Ёф
(
x
)
)
]
\mathcal{L}_{\mathbb{D}}\left(h, h^{\prime}\right)=\mathbb{E}_{x \sim \mathbb{D}}[\ell(h(x),h'(x))]
LD?(h,hЁф)=ExЁЋD?[?(h(x),hЁф(x))]БэЪОШЮвтСНИіМйЩш
h
,
h
Ёф
ЁЪ
Hyp
?
h,h'\in\operatorname{Hyp}
h,hЁфЁЪHypЕФдЄЦкЫ№ЪЇ;ЮвУЧПМТЧМйЩшМЏ
Hyp
?
\operatorname{Hyp}
HypЪЧRKHS
H
\mathcal H
HЕФзгМЏЕФЧщПіЁЃ
ЮвУЧЪзЯШв§ШыВювьОрРы,
disc
?
H
y
p
(
P
,
Q
)
\operatorname{disc}_{Hyp}(\mathbb{P,Q})
discHyp?(P,Q),ЫќКтСПСНИіЗжВМ
P
\mathbb P
PКЭ
Q
\mathbb Q
QжЎМфЕФВювьЁЃ
ЖЈвх7(ВювьОрРы[27])ЁЃ
Щш
Hyp
?
?
{
f
:
X
Ёњ
Y
}
\operatorname{Hyp}\subset\{f:\mathcal X\rightarrow\mathcal Y\}
Hyp?{f:XЁњY}ЪЧвЛзщКЏЪ§,ДгXгГЩфЕНYЁЃСНИіЗжВМ
P
\mathbb P
PКЭ
Q
\mathbb Q
Qдк
X
\mathcal X
XжЎМфЕФВювьОрРыЖЈвхЮЊ
disc
?
(
P
,
Q
)
=
sup
?
h
,
h
Ёф
ЁЪ
Hyp
?
ЈO
L
P
(
h
,
h
Ёф
)
?
L
Q
(
h
,
h
Ёф
)
ЈO
(22)
\operatorname{disc}(\mathbb{P,Q})=\sup_{h,h'\in\operatorname{Hyp}}|\mathcal{L}_{\mathbb{P}}\left(h, h^{\prime}\right)-\mathcal{L}_{\mathbb{Q}}\left(h, h^{\prime}\right)|\tag{22}
disc(P,Q)=h,hЁфЁЪHypsup?ЈOLP?(h,hЁф)?LQ?(h,hЁф)ЈO(22)
етИіЮѓВюЪЧЖдГЦЕФ,ТњзуШ§НЧаЮВЛЕШЪН,ЕЋЫќвЛАуУЛгаЖЈвхОрРы:
?
P
Ёй
Q
\exist\mathbb P\neq\mathbb Q
?PЊС=Qга
disc
?
H
y
p
(
P
,
Q
)
=
0
\operatorname{disc}_{Hyp}(\mathbb{P,Q})=0
discHyp?(P,Q)=0
ШчЙћЮвУЧМйЩшЮвУЧгавЛИіЭЈгУЕФФкКЫ[69],[70],МД
H
=
C
(
X
)
\mathcal H=C(\mathcal X)
H=C(X)зїЮЊЭиЦЫПеМф,Ы№КФ
l
l
lЪЧЦНЗНЫ№КФ[71],ФЧУДВювьОЭЪЧвЛИіЖШСПЁЃЭЈгУКЫзюживЊЕФР§згЪЧИпЫЙRBFКЫ,ЫќЪЧЯТУцЪЕбщжаЪЙгУЕФКЫЁЃ
жЄУїЕФжївЊВНжшЪЧевГігђЩЂЖШгыЮѓВюОрРыжЎМфЕФЙиЯЕЁЃЮвУЧПЩвддкЬиЪтЧщПіЯТетбљзі,ЦфжаКЫЪЧЭЈгУЕФ,Ы№ЪЇЪЧОљЗНЮѓВюЁЃжївЊЕФММЪѕЬєеНЪЧВювьОрРыдкМйЩшжаЪЧЖўДЮЕФ(АќРЈ
h
(
x
)
2
КЭ
h
(
x
)
h
Ёф
(
x
)
h(x)^2КЭh(x)h'(x)
h(x)2КЭh(x)hЁф(x)ЕФаЮЪН),ЖјMMDЪЧЯпадЕФЁЃ
ЖЈвх8(ГЫЗЈдЫЫуЗћ)
Щш
C
(
X
)
C(\mathcal X)
C(X)ЮЊНєМЏXЩЯОпгаЩЯЗЖЪ§
ЁЮ
?
ЁЮ
Ёо
\|\cdot\|_{\infin}
ЁЮ?ЁЮЁо?ЕФСЌајКЏЪ§ПеМфЁЃИјЖЈ
g
ЁЪ
C
(
X
)
g\in C(\mathcal X)
gЁЪC(X),ЖЈвхГЫЗЈдЫЫуЗћЮЊгаНчЯпаддЫЫуЗћ
M
g
:
C
(
X
)
Ёњ
C
(
X
)
\mathbf M_g:C(\mathcal X)\rightarrow C(\mathcal X)
Mg?:C(X)ЁњC(X)ИјГіЕФ
M
g
(
h
)
(
x
)
=
g
(
x
)
h
(
x
)
\mathbf M_g(h)(x)=g(x)h(x)
Mg?(h)(x)=g(x)h(x)
зЂвт,вЛАуЕФRKHSдкГЫЗЈдЫЫуЗћЯТВЛЪЧЗтБеЕФЁЃШЛЖј,гЩгкФкКЫЪЧЭЈгУЕФ,вђДЫ
H
\mathcal H
HдкГЫЗЈЯТЪЧЗтБеЕФ,вђЮЊСЌајКЏЪ§
C
(
X
)
C(\mathcal X)
C(X)ЕФПеМфдкГЫЗЈЯТЪЧЗтБеЕФЁЃДЫЭт,ЮвУЧЛЙПЩвддк
H
\mathcal H
HЩЯЖЈвхЗЖЪ§
ЁЮ
?
ЁЮ
Ёо
\|\cdot\|_{\infin}
ЁЮ?ЁЮЁо?ЪЙгУЦфЪЖБ№
C
(
X
)
C(\mathcal X)
C(X)
в§Рэ4ЁЃ
ИјЖЈ
g
,
h
ЁЪ
H
g,h\in\mathcal H
g,hЁЪH,Цфжа
H
\mathcal H
HЪЧХфБИСЫЭЈгУФкКЫ,ЫќБЃГж
ЁЮ
M
g
(
h
)
ЁЮ
H
=
ЁЮ
g
?
h
ЁЮ
H
Ём
ЁЮ
g
ЁЮ
Ёо
?
ЁЮ
f
ЁЮ
H
\|\mathbf M_g(h)\|_{\mathcal H}=\|g\cdot h\|_{\mathcal H}\le\|g\|_{\infin}\cdot\|f\|_{\mathcal H}
ЁЮMg?(h)ЁЮH?=ЁЮg?hЁЮH?ЁмЁЮgЁЮЁо??ЁЮfЁЮH?
жЄУї
МђЕЅЕФМЦЫуЁЃв§РэашвЊвЛИіЭЈгУКЫ,вђЮЊ
ЁЮ
g
?
h
ЁЮ
H
\|g\cdot h\|_{\mathcal H}
ЁЮg?hЁЮH?Нідк
g
?
h
ЁЪ
H
g\cdot h\in\mathcal H
g?hЁЪHЁЃ
ЮвУЧЯждкеЙЪОСЫСНИіЗжВМЕФгђЗжЩЂЩЯНчВювьОрРыЁЃ
в§Рэ5(гђЩЂЩфБпНчВювь)
Щш
H
\mathcal H
HЪЧвЛИіОпгаЭЈгУКЫЕФRKHS,МйЩшЕФ
l
(
y
,
y
Ёф
)
=
(
y
?
y
Ёф
)
2
l(y,y')=(y-y')^2
l(y,yЁф)=(y?yЁф)2ЪЧЦНЗНЫ№ЪЇ,ПМТЧМйЩшМЏ
Hyp
?
=
{
f
ЁЪ
H
:
ЁЮ
f
ЁЮ
H
Ём
1
КЭ
ЁЮ
f
ЁЮ
Ёо
Ём
r
}
\operatorname{Hyp}=\{f\in\mathcal H:\|f\|_{\mathcal H}\le 1КЭ\|f\|_{\infin}\le r\}
Hyp={fЁЪH:ЁЮfЁЮH?Ём1КЭЁЮfЁЮЁо?Ёмr}
Цфжа
r
>
0
r>0
r>0ЪЧГЃЪ§Щш
P
\mathbb P
PКЭ
Q
\mathbb Q
QЪЧ
X
\mathcal X
XЩЯЕФСНИігђ,ФЧУДЯТУцЕФВЛЕШЪНГЩСЂ:
disc
?
?
(
P
,
Q
)
?
discrepancy?
Ём
8
r
ІЗ
?
(
{
ІЬ
P
,
ІЬ
Q
}
)
?
domainscatter?
.
(23)
\underbrace{\operatorname{disc}_{\ell}(\mathbb{P}, \mathbb{Q})}_{\text {discrepancy }} \leq \underbrace{8 r \sqrt{\Psi_{\phi}\left(\left\{\mu_{\mathbb{P}}, \mu_{\mathbb{Q}}\right\}\right)}}_{\text {domainscatter }} .\tag{23}
discrepancy?
disc??(P,Q)??Ёмdomainscatter?
8rІЗ??({ІЬP?,ІЬQ?})???.(23)
в§Рэ5дЪаэЮвУЧНЋгђЗжЩЂгы[27]жажЄУїЕФгђЪЪгІЕФЗКЛЏНчЯоСЊЯЕЦ№РДЁЃдкЫЕУїБпНчжЎЧА,ЮвУЧв§ШыСЫRademacherИДдгЖШ[59],ЫќКтСПСЫвЛРрКЏЪ§ЪЪКЯЫцЛњдыЩљЕФГЬЖШЁЃИУВтЖШЪЧНчЖЈОбщЫ№ЪЇКЭдЄЦкЫ№ЪЇЕФЛљДЁ
ЖЈвх9 (Rademacher Complexity)
ЩшGЪЧвЛИіДг
X
ЁС
Y
\mathcal X\times\mathcal Y
XЁСYгГЩфЕН
[
a
,
b
]
[a,b]
[a,b]ЕФКЏЪ§зх,
S
=
(
z
1
,
Ё
,
z
n
)
ЁЪ
X
ЁС
Y
S=(z_1,\dots,z_n)\in\mathcal X\times\mathcal Y
S=(z1?,Ё,zn?)ЁЪXЁСYбљБОДѓаЁЮЊnЁЃGЯрЖдгкбљБОSЕФОбщRademacherИДдгЖШЮЊ
?
^
S
(
G
)
=
E
Ів
[
sup
?
g
ЁЪ
G
1
n
ЁЦ
i
=
1
n
Ів
i
g
(
z
i
)
]
(24)
\hat{\Re}_{S}(G)=\underset{\sigma}{\mathbb{E}}\left[\sup _{g \in G} \frac{1}{n} \sum_{i=1}^{n} \sigma_{i} g\left(z_{i}\right)\right]\tag{24}
?^S?(G)=ІвE?[gЁЪGsup?n1?i=1ЁЦn?Івi?g(zi?)](24)
Цфжа
Ів
=
(
Ів
1
,
Ё
,
Ів
n
)
T
\mathbf{\sigma}=(\sigma_1,\dots,\sigma_n)^T
Ів=(Ів1?,Ё,Івn?)TЮЊRademacherБфСП,
Ів
i
s
\sigma_is
Івi?sЖРСЂЕФОљдШЫцЛњБфСПдк
{
?
1
,
+
1
}
\{-1,+1\}
{?1,+1}жаШЁжЕЁЃЫљгабљБОДѓаЁЮЊnЕФRademacherИДдгЖШЮЊ
?
n
(
G
)
=
E
S
[
?
^
S
(
G
)
]
(25)
\Re_{n}(G)=\underset{S}{\mathbb{E}}[\hat{\Re}_{S}(G)]\tag{25}
?n?(G)=SE?[?^S?(G)](25)
ЮвУЧЯждкгаСЫЫљгаЕФвЊЫиРДИљОнСьгђЗжЩЂРДЭЦЕМСьгђЪЪгІНчЯоЁЃ
Щш
f
P
f_{\mathbb P}
fP?КЭ
f
Q
f_{\mathbb Q}
fQ?ЗжБ№ЮЊгђ
P
\mathbb P
PКЭ
Q
\mathbb Q
QЩЯЕФецБъМЧКЏЪ§,
h
P
?
:
=
arg?min
?
h
ЁЪ
Hyp
L
P
(
h
,
f
P
)
h^*_{\mathbb P}:=\argmin_{h\in\text{Hyp}}\mathcal L_{\mathbb P}(h,f_{\mathbb P})
hP??:=argminhЁЪHyp?LP?(h,fP?)КЭ
h
Q
?
:
=
arg?min
?
h
ЁЪ
Hyp
L
Q
(
h
,
f
Q
)
h^*_{\mathbb Q}:=\argmin_{h\in\text{Hyp}}\mathcal L_{\mathbb Q}(h,f_{\mathbb Q})
hQ??:=argminhЁЪHyp?LQ?(h,fQ?)ГЩЮЊзюаЁЛЏепЁЃЮЊСЫГЩЙІЕиНјаагђЕїећ,ЮвУЧНЋМйЩш
L
P
(
f
P
,
f
Q
)
\mathcal L_{\mathbb P}(f_{\mathbb P},f_{\mathbb Q})
LP?(fP?,fQ?)КмаЁЁЃ
ЖЈРэ6(гђЩЂЩфЪЪгІБпНч)ЁЃ
ЩшHypЮЊДг
X
\mathcal X
XгГЩфЕН
R
\mathbb R
RЕФКЏЪ§зх,
S
X
P
=
(
x
1
t
,
Ё
,
x
n
s
t
)
ЁЋ
P
S^{\mathbb P}_{\mathcal X}=(x^t_1,\dots,x^t_{n_s})\sim\mathbb P
SXP?=(x1t?,Ё,xns?t?)ЁЋPКЭ
S
X
Q
=
(
x
1
t
,
Ё
,
x
n
t
t
)
ЁЋ
Q
S^{\mathbb Q}_{\mathcal X}=(x^t_1,\dots,x^t_{n_t})\sim\mathbb Q
SXQ?=(x1t?,Ё,xnt?t?)ЁЋQЗжБ№ЮЊдДбљБОКЭФПБъбљБОЁЃ
ЖдгкШЮКЮМйЫЕ
h
ЁЪ
Hyp
h\in\text{Hyp}
hЁЪHyp,ИХТЪжСЩйЮЊ
1
?
ІФ
1-\delta
1?ІФ,вдЯТЪЪгІНчЯоГЩСЂ:
L
Q
(
h
,
f
Q
)
?
L
Q
(
h
Q
?
,
f
Q
)
?
regret?on?target?domain?
Ём
L
P
^
(
h
,
h
P
?
)
?
empirical?loss?
+
2
q
R
^
S
X
P
(
H
y
p
)
?
Rademacher?complexity?
+
3
B
log
?
2
ІФ
2
n
t
?
O
(
1
/
?sample?size?
)
+
8
r
ІЗ
?
(
{
ІЬ
Q
,
ІЬ
P
}
)
?
domain?scatter?
+
L
P
(
h
P
?
,
h
Q
?
)
?
deviation?of?optimal?solns?
(26)
\begin{aligned} &\overbrace{\mathcal{L}_{\mathbb{Q}}\left(h, f_{\mathbb{Q}}\right)-\mathcal{L}_{\mathbb{Q}}\left(h_{\mathbb{Q}}^{*}, f_{\mathbb{Q}}\right)}^{\text {regret on target domain }} \leq \overbrace{\mathcal{L}_{\hat{\mathbb{P}}}\left(h, h_{\mathbb{P}}^{*}\right)}^{\text {empirical loss }}+\overbrace{2 q \hat{\mathfrak{R}}_{S_{\mathcal{X}}^{\mathrm{P}}}(\mathrm{Hyp})}^{\text {Rademacher complexity }}\\ &+\underbrace{3 B \sqrt{\frac{\log \frac{2}{\delta}}{2 n_{t}}}}_{O(1 / \sqrt{\text { sample size })}}+\underbrace{8 r \sqrt{\Psi_{\phi}\left(\left\{\mu_{\mathbb{Q}}, \mu_{\mathbb{P}}\right\}\right)}}_{\text {domain scatter }}+\underbrace{\mathcal{L}_{\mathbb{P}}\left(h_{\mathbb{P}}^{*}, h_{\mathbb{Q}}^{*}\right)}_{\text {deviation of optimal solns }} \end{aligned}\tag{26}
?LQ?(h,fQ?)?LQ?(hQ??,fQ?)
?regret?on?target?domain??ЁмLP^?(h,hP??)
?empirical?loss??+2qR^SXP??(Hyp)
?Rademacher?complexity??+O(1/?sample?size?)?
3B2nt?logІФ2?????+domain?scatter?
8rІЗ??({ІЬQ?,ІЬP?})???+deviation?of?optimal?solns?
LP?(hP??,hQ??)???(26)
**жЄУїЁЃ**ЙЬЖЈ
h
=
Hyp
h=\text{Hyp}
h=HypЁЃгЩгкЦНЗНЫ№ЪЇЪЧЖдГЦЕФ,ВЂЧвЗўДгШ§НЧаЮВЛЕШЪН,[27]жаЕФЖЈРэ8(ВЮМћВЙГфВФСЯ,ПЩдкЯпЛёЕУ)АЕЪОСЫетвЛЕу
L
Q
(
h
,
f
Q
)
?
L
Q
(
h
Q
?
,
f
Q
)
Ём
L
P
(
h
,
h
P
?
)
+
disc
l
(
Q
,
P
)
+
L
P
(
h
P
?
,
h
Q
?
)
(27)
\mathcal{L}_{\mathbb{Q}}\left(h, f_{\mathbb{Q}}\right)-\mathcal{L}_{\mathbb{Q}}\left(h_{\mathbb{Q}}^{*}, f_{\mathbb{Q}}\right)\le \mathcal L_{\mathbb P}(h,h^*_{\mathbb P})+ \text{disc}_l(\mathbb Q,\mathbb P)\\ +\mathcal L_{\mathbb P}(h^*_{\mathbb P},h^*_{\mathbb Q})\tag{27}
LQ?(h,fQ?)?LQ?(hQ??,fQ?)ЁмLP?(h,hP??)+discl?(Q,P)+LP?(hP??,hQ??)(27)
НЋЩЯЪіЖЈРэ6гы[27]жаЕФЖЈРэ9НјааБШНЯОпгажИЕМвтвх,[27]ЪЧРЉеЙ
disc
l
(
Q
,
P
)
\text{disc}_l(\mathbb Q,\mathbb P)
discl?(Q,P)дк(27)ЕФЪЕжЄВтСПЁЃгУОбщЩЂЩф
ІЗ
?
(
{
ІЬ
P
^
,
ІЬ
Q
^
}
)
\Psi_{\phi}(\{\mu_{\hat{\mathbb P}},\mu_{\hat{\mathbb Q}}\})
ІЗ??({ІЬP^?,ІЬQ^??}),гІгУЖЈРэ1ЁЃ
ЖЈРэ6ЕФвтвхгаСНЗНУцЁЃЪзЯШ,ЧПЕїСЫЩЂЩф
ІЗ
?
(
{
ІЬ
P
,
ІЬ
Q
}
)
\Psi_{\phi}(\{\mu_{\mathbb P},\mu_{\mathbb Q}\})
ІЗ??({ІЬP?,ІЬQ?})ПижЦСЫгђЪЪгІЕФЗКЛЏадФмЁЃЦфДЮ,ИУБпНчЯдЪОЩЂЩф(вВГЦЮЊMMD)гы[27]жаЬсГіЕФгђЪЪгІРэТлжЎМфЕФжБНгСЊЯЕЁЃЧызЂвт,етИіНчЯоПЩФмЖдЪЕМЪФПЕФУЛгагУДІ,вђЮЊЫќЪЧЫЩЩЂКЭБЏЙлЕФ,вђЮЊЫќУЧЪЪгУгкЫљгаЕФМйЩшКЭЫљгаПЩФмЕФЪ§ОнЗжВМЁЃ
СљЁЂЪЕбщвЛ: гђЪЪХф
ЕквЛзщЪЕбщЦРЙРСЫSCAдкКЯГЩЪ§ОнКЭецЪЕЮяЬхЪЖБ№ШЮЮёЩЯЕФгђЪЪгІадФмЁЃКЯГЩЪ§ОнжМдкРэНтбЇЯАЕНЕФЬиеїгыЦфЫћЫуЗЈЯрБШЕФааЮЊ,ЖјЪЕМЪЭМЯёгУгкбщжЄSCAЕФадФм
6.1КЯГЩЪ§Он
ЭМ1УшЛцСЫКЯГЩЪ§Он,ЫќгЩШ§ИіРрБ№ЯТЕФСљИіОлРрЕФЖўЮЌЪ§ОнЕузщГЩЁЃУПИіОлРржаЕФЪ§ОнЕуЖМЪЧгЩвЛИіИпЫЙЗжВМ
x
c
ЁЋ
N
(
ІЬ
c
,
Ів
c
)
x^c\sim\mathcal N(\mu^c,\sigma^c)
xcЁЋN(ІЬc,Івc),Цфжа
ІЬ
c
\mu^c
ІЬcКЭ
Ів
c
\sigma^c
ІвcЮЊЕкCОлРрЕФОљжЕКЭБъзМВюЁЃ ЫљгаЫуЗЈЖМЪЙгУRBFФкКЫ
k
(
a
,
b
)
=
exp
?
(
?
ЁЮ
a
?
b
ЁЮ
2
2
Ів
2
)
k(\mathbf{a,b})=\operatorname{exp}\left(-\frac{\|\mathbf{a-b}\|^2_2}{\sigma^2}\right)
k(a,b)=exp(?Ів2ЁЮa?bЁЮ22??)
ЫљгаПЩЕїГЌВЮЪ§ОљИљОн1-зюНќСкЕФВтЪдОЋЖШНјаабЁдёЁЃЮвУЧБШНЯСЫКЫжїГЩЗжЗжЮі(Kernel Principal Component Analysis)ЁЂАыМрЖНДЋЪфГЩЗжЗжЮі(Semi-Supervised Transfer Component Analysis, SSTCA)[45]ЁЂДЋЪфСЊКЯЦЅХф[15]КЭSCAЬсШЁЕФЬиеїЁЃ
6.2ецЪЕЪРНчЮяЬхЪЖБ№
ЮвУЧзмНсСЫвЛЯЕСаПчгђФПБъЪЖБ№ШЮЮёЕФЭъећгђЪЪгІНсЙћЁЃРћгУСЫМИИіецЪЕЪРНчЕФЭМЯёЪ§ОнМЏ,ШчЪжаДЪ§зж(MNIST[73]КЭUSPS[74])КЭвЛАуЖдЯѓ(MSRC [75], VOC2007 [6], Caltech-256 [76], Office[16])ЁЃ
ДгетаЉЪ§ОнМЏЙЙНЈСЫШ§ИіПчгђЖд:USPS+MNISTЁЂMSRC+VOC2007КЭOffice+Caltech
6.2.1Ъ§ОнЩшжУ
USPS+MNISTзщКЯгЩЪжаДЪ§зжЪ§ОнМЏЕФЯТВЩбљдЪМЭМЯёзщГЩЁЃ
MSRC+VOC2007зщКЯгЩ240ЮЌЭМЯёзщГЩ,ЙВЯэ6ИіЮяЬхРрБ№
Office+CaltechгЩ10ИіРрБ№ЕФ2,533еХЭМЦЌзщГЩ(УПИігђУћУПИіРрБ№8ЕН151еХЭМЦЌ)
6.2.2.ЛљЯпКЭавщ
ЮвУЧБШНЯСЫвдЯТЫуЗЈЕФЗжРрадФм:
- ЛљгкдЪМЬиеїЕФЗжРрЦї(raw),
- KPCA
- ДЋЪфЗжСПЗжЮі[45],
- SSTCA,
- ВтЕиСїКЫ(GFK)[29],
- ДЋЪфЯЁЪшБрТы[23]
- згПеМфЖдЦы[31]
- TJM[15]
- ЮоМрЖНЗжЩЂЗжСПЗжЮі,
- SCAЁЃ
ЖдгквЛИіецЪЕЕФЩшжУ,ПЩЕїГЌВЮЪ§ЭЈЙ§5ДЮНЛВцбщжЄбЁдё,НіИљОндДгђЕФБъЧЉЁЃ
ЩЯЪіЬиеїбЇЯАЫуЗЈЗжБ№дкШ§жжВЛЭЌЕФЗжРрЦїЩЯНјааЦРМл:
- 1-зюНќСк(1NN),
- ДјЯпадКЫЕФжЇГжЯђСПЛњ(L-SVM)[79],
- гђЪЪгІЛњЦї[36]ЁЃ
6.2.3 1-зюНќСкЗжРрОЋЖШ
Бэ1змНсСЫUSPS +MNISTКЭMSRC+VOC2007ЖдЕФЗжРрОЋЖШЁЃ
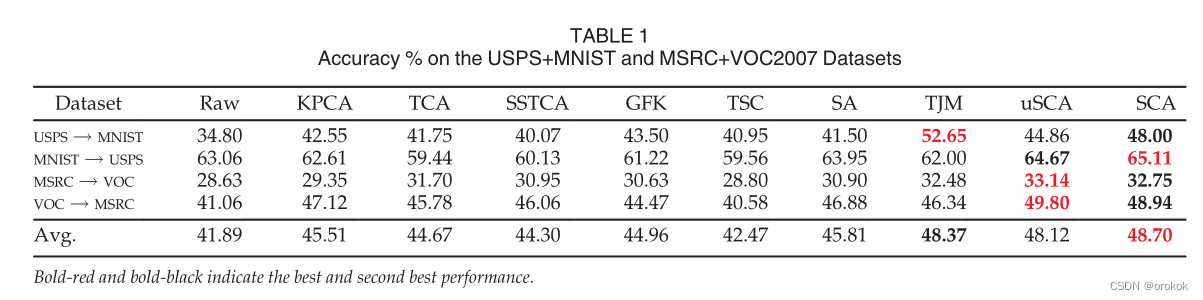
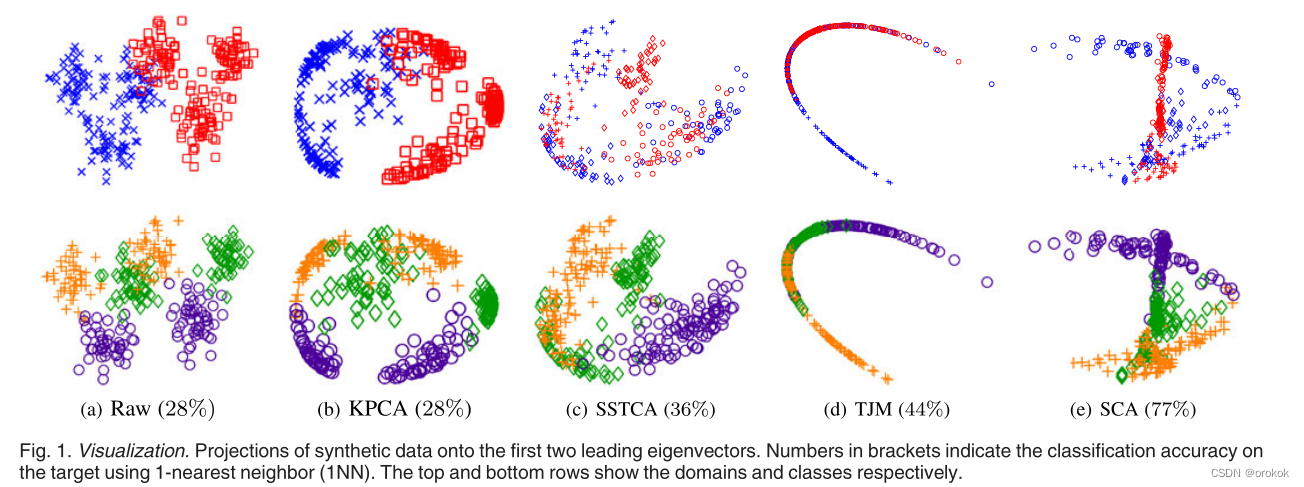
СюШЫОЊбШЕФЪЧ,SSTCAдкХрбЕЦкМфвВКЯВЂСЫБъЧЉаХЯЂ,ЕЋУЛгаБэЯжГіОКељСІЁЃ
Office+CaltechЖдЕФНсЙћЛузмдкБэ2 (SURF-BoW)КЭБэ3 (DeCAF6)жаЁЃ
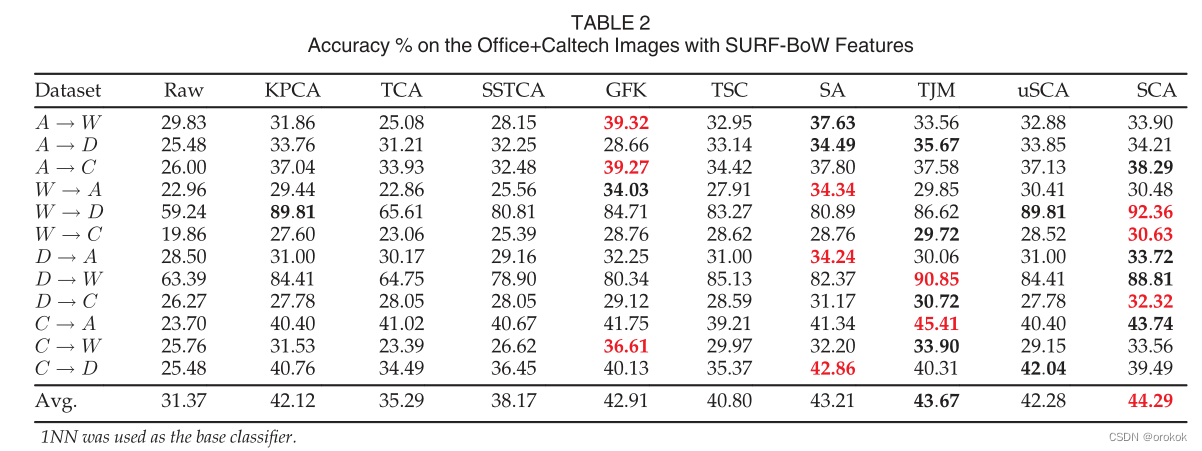
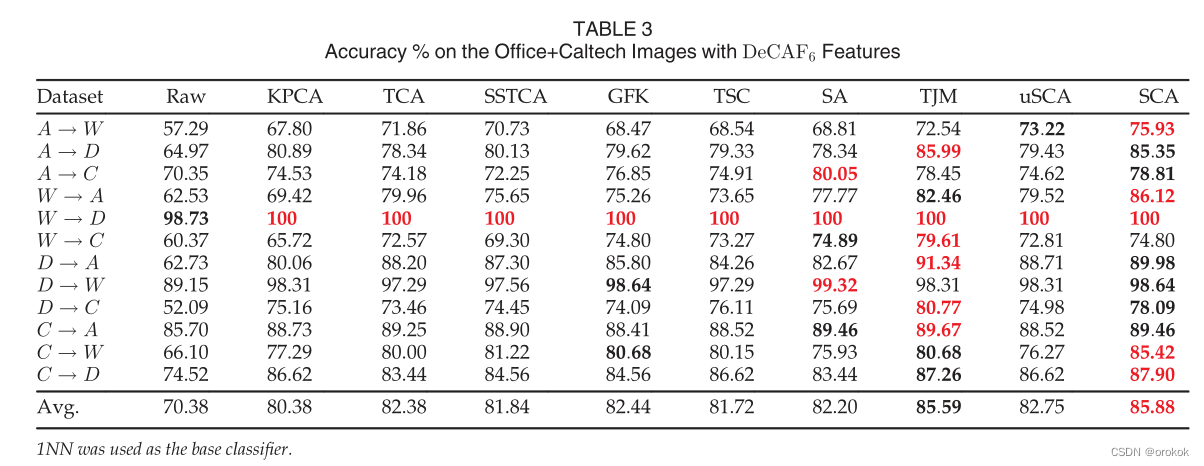 гУгкВњЩњЩЯЪіЫљгаНсЙћЕФЫуЗЈЕФГЌВЮЪ§НіЪЙгУдДгђЕФБъЧЉНјааСЫЕїгХЁЃетЪЧЮоМрЖНгђЪЪгІЩшжУЕФЮЈвЛгааЇЕФЕїгХавщЁЃОЁЙмШчДЫ,дкЮФЯзжаНЈСЂЕФвЛаЉзюКУЕФНсЙћЪЧЪЙгУФПБъБъЧЉЩЯЕФГЌВЮЪ§ЕїећЛёЕУЕФЁЃ
гУгкВњЩњЩЯЪіЫљгаНсЙћЕФЫуЗЈЕФГЌВЮЪ§НіЪЙгУдДгђЕФБъЧЉНјааСЫЕїгХЁЃетЪЧЮоМрЖНгђЪЪгІЩшжУЕФЮЈвЛгааЇЕФЕїгХавщЁЃОЁЙмШчДЫ,дкЮФЯзжаНЈСЂЕФвЛаЉзюКУЕФНсЙћЪЧЪЙгУФПБъБъЧЉЩЯЕФГЌВЮЪ§ЕїећЛёЕУЕФЁЃ
6.2.4.L-SVMКЭDAMЕФЗжРрОЋЖШ
ЮЊСЫМђНрЦ№Мћ,ЮвУЧБШНЯСЫЭМ2ЫљЪОЕФЮхжжЫуЗЈ:KPCAЁЂSSTCAЁЂSAЁЂTJMКЭSCAЕФадФмЁЃ
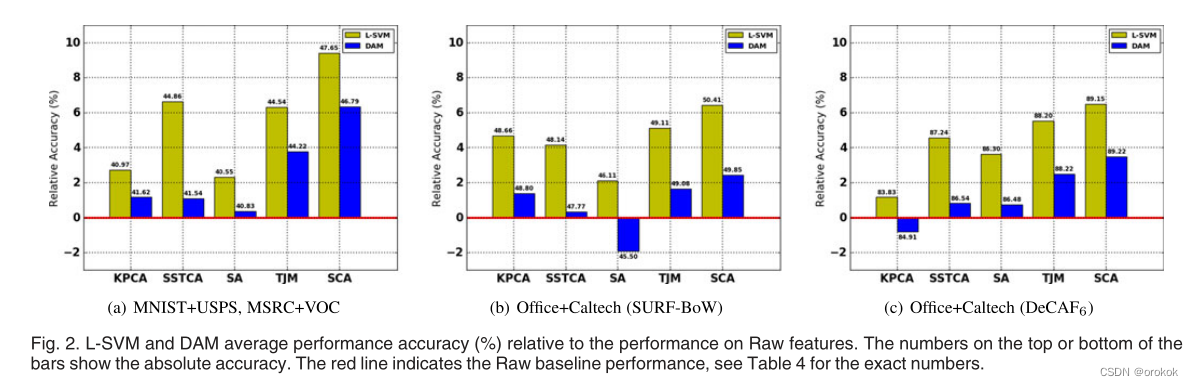
Бэ4змНсСЫRawЬиадЕФОјЖдзМШЗадЁЃ
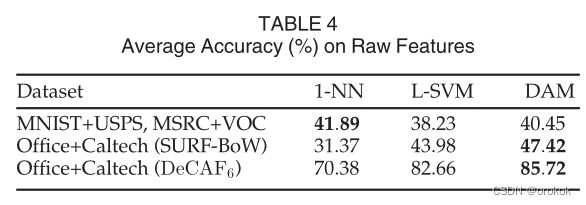
ДгБэ4ПЩвдПДГі,DAMдкRawЬиадЩЯЕФБэЯжгХгкL-SVMЁЃСюШЫОЊбШЕФЪЧ,ЕБЪЙгУЬиеїбЇЯАЫуЗЈЪБ,ЧщПіВЂЗЧзмЪЧШчДЫЁЃДЫЭт,L-SVMзмЪЧВњЩњИќИпЕФадФмдівцЯрЖдгкдЪМЬиеїЁЃетПЩФмЪЧгЩгкЙ§ФтКЯ,вђЮЊDAMБШL-SVMгаИќЖрЕФГЌВЮЪ§ЁЃвВОЭЪЧЫЕ,НЋDAMгыЬиеїбЇЯАЫуЗЈЯрНсКЯЪЙећИіЙ§ГЬБфЕУИДдгЁЊЁЊЛиЯыГЌВЮЪ§ЕФбЁдёЪЧЛљгкЖддДЪ§ОнЕФбщжЄЁЃ
6.2.5дЫааЪБадФм
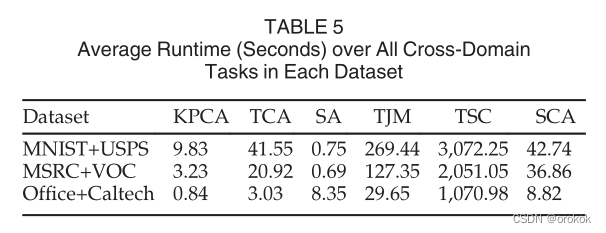
Бэ5БШНЯСЫSCAгыЦфЫћвЛаЉЫуЗЈ:KPCAЁЂTCAЁЂSAЁЂTSCКЭTJMдкMNIST+USPSЁЂMSRC+VOCКЭOffice+Caltech(гыDeCAF6)ЩЯЕФЦНОљдЫааЪБадФмЁЃ
ЦпЁЂЪЕбщЖў:СьгђЗКЛЏ
ЮвУЧдкШ§ИіПчгђЪ§ОнМЏЩЯЦРЙРСЫЮвУЧЕФЫуЗЈ:VLCSЁЂOffice+CaltechКЭIXMAS [80]
7.1Ъ§ОнЩшжУ
ЕквЛИіПчгђЪ§ОнМЏ,ЮвУЧГЦжЎЮЊVLCS,гЩPASCAL VOC2007 (V)[6]ЁЂLabelMe (L)[81]ЁЂCaltech-101 ?[76]КЭSUN09 (S)[82]Ъ§ОнМЏЕФЭМЯёзщГЩ,УПИіЪ§ОнМЏДњБэвЛИігђЁЃ
ЕкЖўИіПчгђЪ§ОнМЏЪЧOffice+CaltechЪ§ОнМЏ
ЕкШ§ИіЪ§ОнМЏЪЧIXMASЪ§ОнМЏ
7.2ЛљЯпКЭавщ
ЮвУЧНЋЮвУЧЕФЫуЗЈгывдЯТЛљЯпНјааСЫБШНЯ:
- 1NN: 1-зюНќСкЗжРрЦїЁЃ
- L-SVM:ДјЯпадКЫЕФSVMЗжРрЦїЁЃ
- КЫжїГЩЗжЗжЮіЁЃ
- Undo-Bias[21]:вЛжжЖрШЮЮёsvmЯћГ§Ъ§ОнМЏЦЋВюЕФЫуЗЈЁЃ
- UML[20]:вЛИіЛљгкНсЙЙЛЏЖШСПбЇЯАЕФЫуЗЈ,жМдкЮЊЗжРрШЮЮёбЇЯАвЛИіИќЩйЦЋВюЕФОрРыЖШСПЁЃ
- DICA[19]:вЛжжгУгкгђЗКЛЏЕФКЫЬиеїЬсШЁЗНЗЈЁЃ
- LRE-SVM[22]:ВЩгУКЫЗЖЪ§е§дђЛЏРДЪЉМгЕЭжШЫЦШЛОиеѓЕФЗЧЯпадЗЖР§- svmФЃаЭЁЃ
ЮвУЧЪЙгУзюНќСкзїЮЊЫљгаЛљгкЬиеїбЇЯАЕФЫуЗЈЕФЛљЗжРрЦї:KPCAЁЂDICAЁЂuSCA/ uDICAКЭSCAЁЃИљОндДгђЕФБъЧЉбЁдёПЩЕїГЌВЮЪ§ЁЃ
ЖдгкЫљгаЛљгкКЫЕФЗНЗЈ,КЫКЏЪ§ЮЊRBFКЫ,
k
(
a
,
b
)
=
exp
?
(
?
ЁЮ
a
?
b
ЁЮ
2
2
Ів
2
)
k(\mathbf{a,b})=\operatorname{exp}\left(-\frac{\|\mathbf{a-b}\|^2_2}{\sigma^2}\right)
k(a,b)=exp(?Ів2ЁЮa?bЁЮ22??),ЭЈЙ§жажЕЦєЗЂЪНМЦЫуФкКЫДјПэ
Ів
\sigma
ІвЁЃзЂвт,дкетжжЧщПіЯТ,ЮоМрЖНЕФDICAМИКѕгыuSCAЯрЭЌЁЃЮЈвЛЕФЧјБ№ЪЧuSCAЖдгкгђЗжЩЂ/ЗжВМЗНВюЯюгавЛИіПижЦВЮЪ§
ІФ
>
0
\delta>0
ІФ>0ЁЃ
7.3VLCSЪ§ОнМЏЩЯЕФНсЙћ
дкетИіЪ§ОнМЏЩЯ,ЮвУЧЪзЯШЪЙгУ1-зюНќСкНјааБъзМЕФбЕСЗВтЪдЦРЙР
groundtruthЦРМлНсЙћШчБэ6ЫљЪОЁЃ
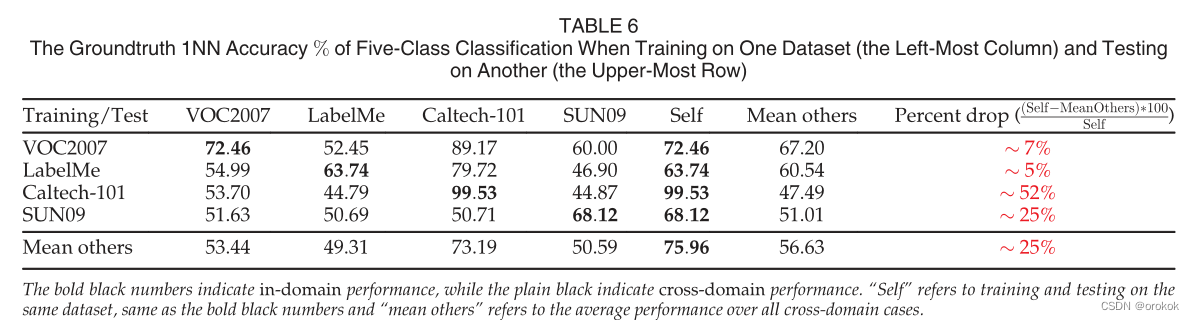
змЕФРДЫЕ,ОЁЙмЪЙгУСЫзюЯШНјЕФЩюЖШОэЛ§ЩёОЭјТчЬиеї
D
e
C
A
F
6
DeCAF_6
DeCAF6?,ЕЋЪ§ОнМЏШЗЪЕДцдкЦЋВю
ШЛКѓ,ЮвУЧдк7ИіПчгђЪЖБ№ШЮЮёжаЦРЙРСЫгђЗКЛЏадФмЁЃЭъећНсЙћЛузмгкБэ7ЁЃ

7.4Office+МгжнРэЙЄбЇдКЪ§ОнМЏЩЯЕФНсЙћ
ЮвУЧдкOffice+CaltechЪ§ОнМЏЙЙНЈЕФМИИіПчСьгђАИР§ЩЯЦРЙРСЫЮвУЧЕФЫуЗЈЁЃБэ8БЈИцСЫ4Р§
D
e
C
A
F
6
DeCAF_6
DeCAF6?ЛМепЕФЯъЯИЦРМлНсЙћЁЃ
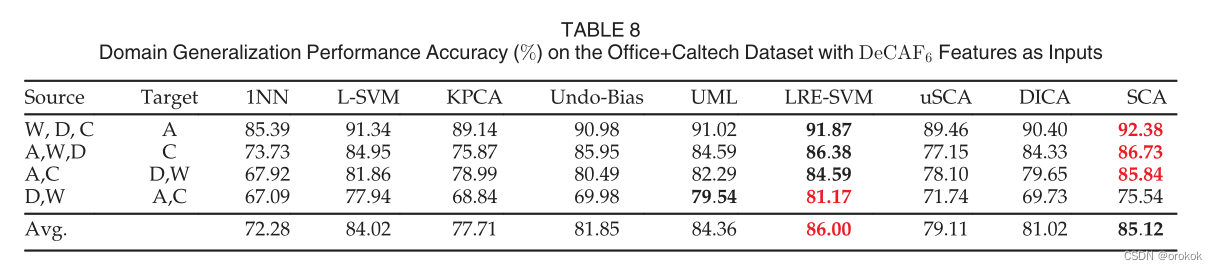
етБэУї,дкЬиеїбЇЯАЙ§ГЬжаНсКЯдДгђЕФБъМЧаХЯЂШЗЪЕПЩвдИФЩЦOffice+CaltechАИР§жаЕФгђЗКЛЏЁЃ
7.5IXMASЪ§ОнМЏЩЯЕФНсЙћ
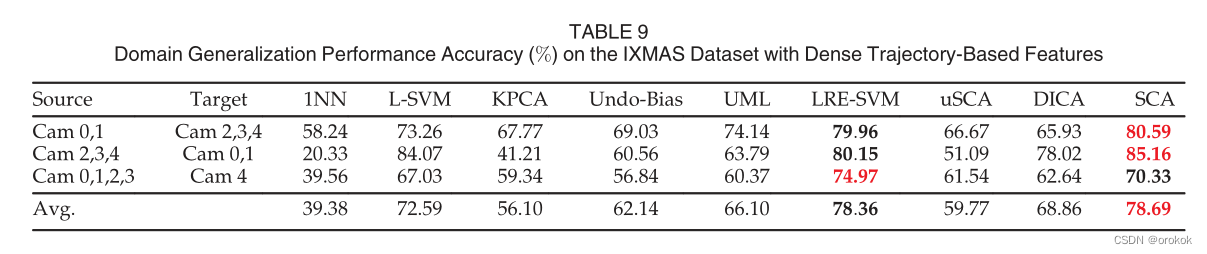
Бэ9змНсСЫдкШ§ИіПчгђАИР§жаIXMASЪ§ОнМЏЩЯЕФЗжРрзМШЗадЁЃ
7.6дЫааЪБадФм
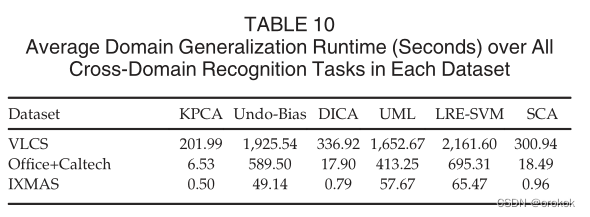
ДгБэ10жа,ЮвУЧПЩвдПДЕНSCAЕФдЫааЪБгыKPCAКЭDICAЯрЕБ,етЪЧвтСЯжЎжаЕФ,вђЮЊЫќУЧРћгУСЫЯрЭЌЕФгХЛЏЙ§ГЬ:ЪЙгУЙувхЬиеїжЕЗжНтНјаавЛДЮдЫааЁЃ
АЫЁЂзмНс
ЛљгкЩЂЩфЕФФПБъКЏЪ§ЪЧЖдгђЪЪгІКЭгђЗКЛЏЮЪЬтЕФЯрЙиНсЙЙНјааБрТыЕФвЛжжжБНгЗНЗЈЁЃ
SCAЪЙгУЪ§ОнзгМЏжЎМфЕФВювьРДЙЙНЈвЛИіЯпадзЊЛЛ,ИУзЊЛЛМѕШѕ(БъЧЉФкКЭгђжЎМф)ВЛживЊЕФВювь,ВЂЗХДѓгагУЕФВювь(БъЧЉжЎМфКЭзмЬхПЩБфад)ЁЃ
ЮвУЧЕФРэТлЗжЮіБэУї,ОпгаСНИіЪфШыгђЕФЩЂЩф,МДгђЩЂЩф,ЮЊгђЪЪгІЬсЙЉСЫЗКЛЏБпНч
SCAЪЧKernel PCAЁЂKernel Fisher DiscriminantКЭTCAЕФздШЛРЉеЙЁЃЯрЗД,аэЖргђЪЪгІЗНЗЈЪЙгУФПБъКЏЪ§,НЋзмЗНВюКЭMMDгыБОжЪЩЯВЛЭЌЕФСПЯрНсКЯ,ШчЭМРЦеРЫЙЫузг[23]ЁЂЯЁЪшаддМЪј[15]ЁЂ[23]ЁЂЯЃЖћВЎЬи-ЪЉУмЬиЖРСЂзМдђ[45]ЛђжааФзгПеМф[19]
ЭЈЙ§НЋФПБъБъЧЉКЯВЂЕНРрЗжЩЂжа,SCAПЩвдКмШнвзЕиРЉеЙЮЊАыМрЖНгђЪЪгІЁЃзюКѓ,ЮвУЧжИГі,ЪЙгУЫцЛњЬиадгІИУПЩвдМгЫйSCAДІРэДѓЙцФЃЮЪЬт[84]ЁЃ
вђДЫ,ПЊЗЂИќЛљБОЕФЬиеїбЇЯАЫуЗЈЪЧжСЙиживЊЕФ,ЫќПЩвддкЙуЗКЕФЧщПіЯТЯджјМѕЩйЪ§ОнМЏЦЋВю
Reference
Scatter Component Analysis: A Unified Framework for Domain Adaptation and Domain Generalization