YOLO v2
相比与yolo v1,yolo v2的更新主要体现在以下几方面:主干网络的更新、引入anchor机制、以及一些小细节比如global avgpooling、类似v3中FPN的passthrough结构、使用了BN层而弃用了dropout等等。
1. 主干网络的更新
使用了darknet19代替了原来的vgg16,mAP基本没变但参数量减少,从而训练和预测的速度提高。我认为主要功劳是通过引入1×1卷积 压缩参数量,实现channel方向的降维(实现对tensor的压缩),对降维后的tensor再通过正常3×3卷积提取特征并重新升维。(与ResNet中的BottleNeck瓶颈结构类似)
两个网络的结构对比:
 vgg16 vgg16
|
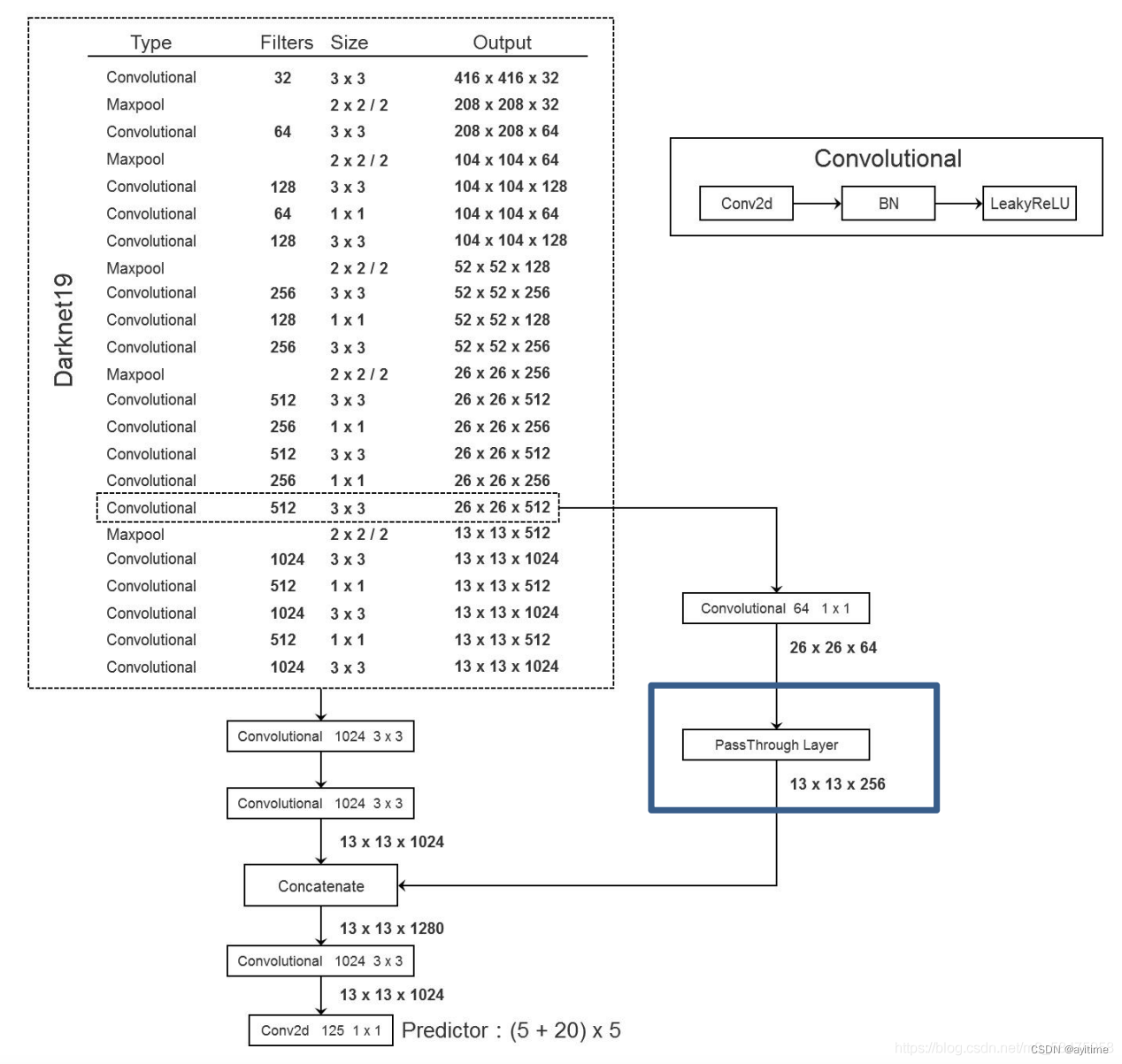 Darknet19 Darknet19
|
同时抛弃了dropout;卷积层之后添加了BN层(正态分布nb),把每一层的输出挤到0附近,防止每一层神经元的输出离0太远造成梯度消失,防止过拟合。
2. 引入anchor机制
yolo v1中每个grid cell的两个bounding box哪一个负责预测物体是不定的,而且形状wh也是随机预测全图跑没有限制,不好训练。yolo v2中引入的anchor机制,每个grid cell有五个尺寸的anchor,bbox实在anchor基础上通过预测结果进行微调的(提前通过k-means在数据集上根据图像尺寸聚5个类得到;相当于考前划重点,让考生熟悉考试要考啥)。
anchor也可以叫 prior bounding box“先验框”或者 anchor box“锚框”,后续统称为anchor;
anchor根据预测结果调整后的框即预测框称为 “bounding box”,简称bbox(如何调整见3)。
anchor匹配原理: 若gt框中心落在某个grid中,计算该grid5个anchor中与gt框iou最大的anchor作为预测该物体的框。如果另外一个gt也落入到了该格子中并匹配到了另外一个尺寸的anchor,那么就由这个anchor来负责预测该gt(即一个grid的5个anchor都能同时预测物体,与yolo v1中一个grid的两个bbox只能有一个负责预测物体不同!!)
选好框之后,模型就在这个anchor的基础上进行微调成bbox,并希望调成gt的xywh

另外anchor机制的引入可以辅助网络更容易地去学习,因此可以将之前负责预测的FC层去掉,换用上图中最下面的1×1卷积实现预测(大快人心!)
另外附上同济子豪兄的一个回答,加深理解:

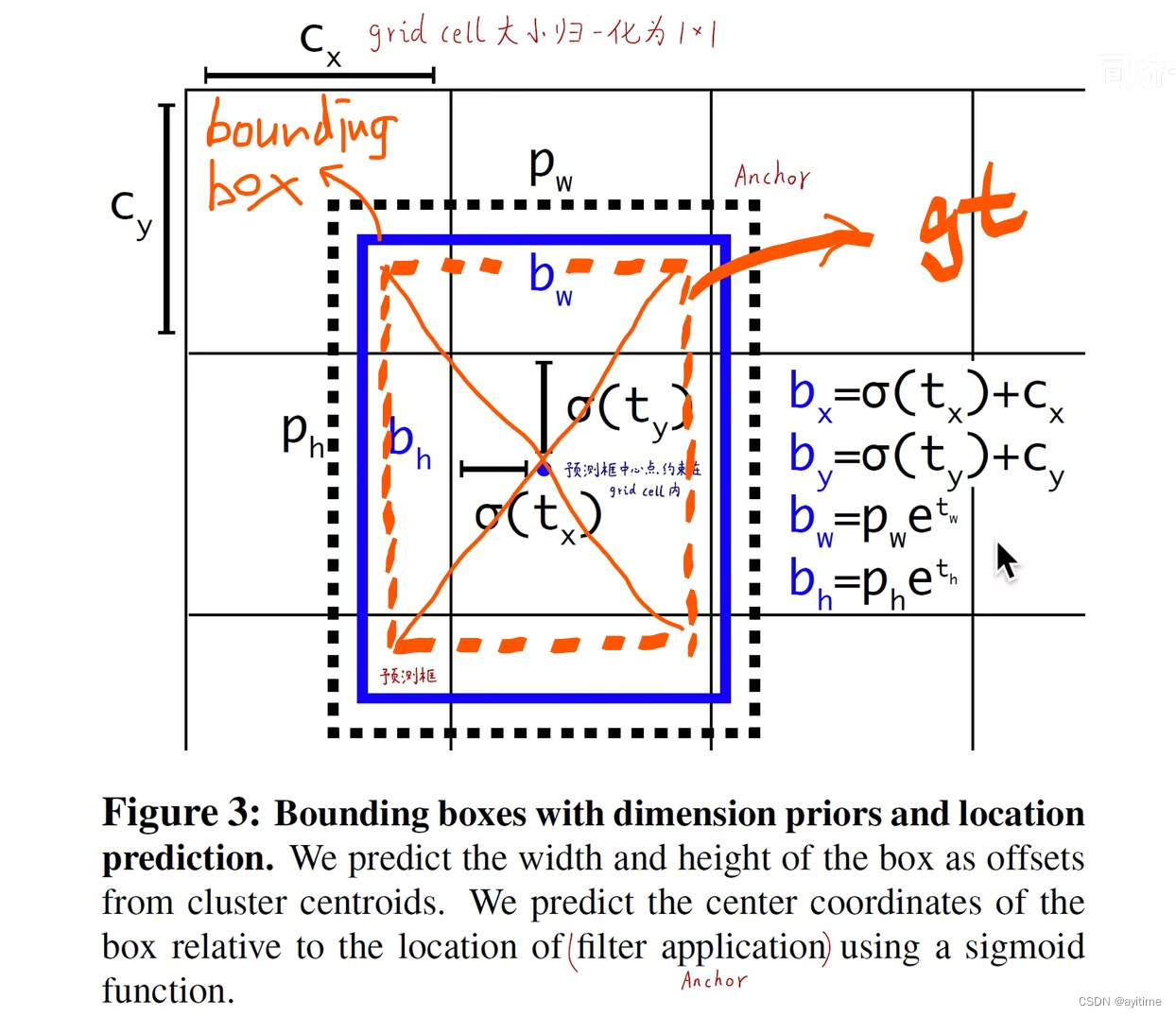
3. Direct location prediction(绝对位置预测)
直接上图,不看代码光看帖子只能理解个毛皮。要提前清楚的一点:anchor仅仅有wh的形状属性,无xy位置属性。下面先介绍测试流程再反过来介绍训练流程:
预测流程:
模型预测的该grid预测出5组 tx ty tw th,和5个anchor的尺寸 根据下图公式计算,可以得到最终的预测框xywh,再经过后续的nms…balabala…
训练流程:
首先肯定有gt框的中心落在该grid中,如图橘色虚线所示;我们如何选取anchor呢?把五个anchor分别与gt框的中心重合,选取iou最大的,即图中最外层的黑色虚线。
之后要对anchor进行位置和大小的调整:anchor的中心我们希望调整到gt框的中心,又因为anchor的中心一定是落在该grid内,且该grid的左上角位置是已知的(根据gt),所以可以通过预测相对grid左上角的归一化偏移量实现,即等价于让网络回归一个0-1之间的浮点数,通过sigmoid来实现(减小灵敏度)。
w和h的调整则是基于anchor的宽高,将yolo v1中的直接做差 转换为 求尺寸变化率, 即让网络来回归一个1附近的浮点数,并使用对数e来实现(减小灵敏度)。
4. 引入anchor后loss的变化
损失在v1的基础上添加了上面两部分:
- 第一行:
对于预测框和gt框iou<0.6的置信度误差(怎么算的,是所有bbox和gt进行iou计算???)。这类框对应背景 应该让他们不负责预测物体,即置信度为0; - 第二行:
如何把让网络每个grid cell生成bounding box(的形状)在anchor(的形状)附近呢,网络训练初期(epoch<12800) 对预测出的bbox形状进行限制(?proir应该本身不带有位置xy信息,难道是把anchor移动到gt框的中心,然后计算此时的anchor和预测出的bbox(anchor+偏移)的位置偏差么??待确认) - 后面和v1基本一样,对于负责预测物体的预测框的三部分损失。
其实预测框可以分为三种,对应差生、中等生、尖子生;差生为bbox和gt的iou小于0.6的bbox,尖子生为负责预测物体的bbox,其余为中等生,只有差生(背景)和优等生(预测物体的bbox)参与损失计算,中等生不去管。(差生的定义我不太清楚,和v3对比后待确认)

5. pass through的使用
在darknet19图中的右面分支,底层细粒度和高层语义特征融合。和v3的FPN一个道理:即保留了深层的语义信息,又融合了浅层的位置信息
6. global avgpooling
全局平均池化(channel方向上),来实现任意尺寸的输入,并取代了FC。
网上帖子都是这么云云的,我找了几个模型也没看到哪里用了这个GAP,有谁比较务实麻烦告知下