😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:??????目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉深度学习(keras、pytorch、yolo),python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。
💛💛💛本文摘要💛💛💛
本文我们将继续讲解计算机视觉领域项目-驾驶员疲劳检测。

🌟项目前言
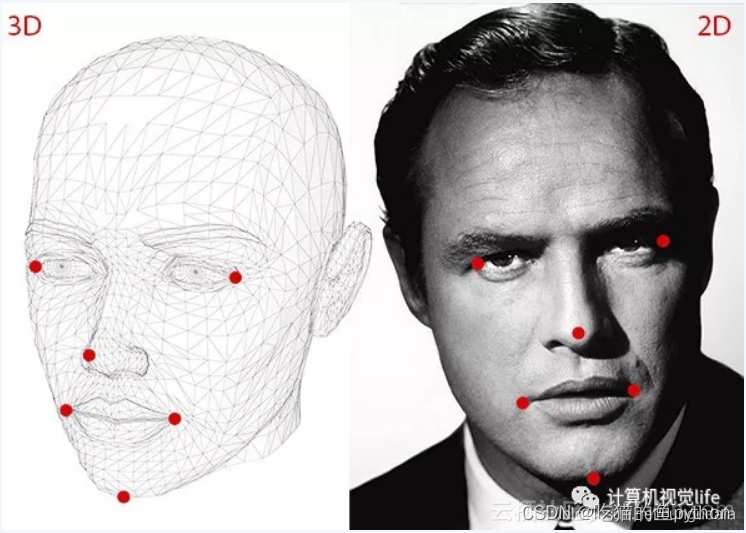
上次博客我们讲到了如何定位人脸,并且在人脸上进行关键点定位。其中包括5点定位和68点定位等,在定位之后呢,我们就可以使用定位信息来做一些相关操作,例如闭眼检测,这里就可以应用到驾驶员的疲劳检测上,或者是经常使用电脑的人,不闭眼可能会导致眼睛干涩等。
🌟项目关键点讲解
我们本次博客主要讲解通过闭眼来检测疲劳驾驶,那么我们首先就要了解怎么让计算机来判断人是否闭了眼睛。我们通过上次的博客可以知道,我们首先要让计算机识别出来人脸,然后在识别出来的人脸上继续做关键点查找。我们这里用的是68关键点检测。

对于眼睛来讲,他每一个眼睛都有6个关键点。这里我们可以通过一种方式来判断是否进行了眨眼。
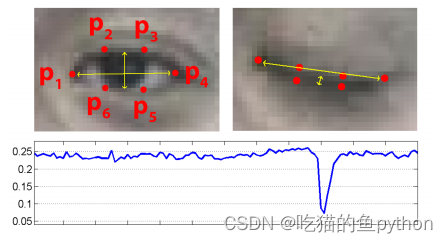
在眼睛的6个关键点中,我们可以发现当睁眼的时候,2和6点以及3和5点的欧氏距离较大。1和4点稍稍距离会增加一点,那么我们可以设定一个公式。
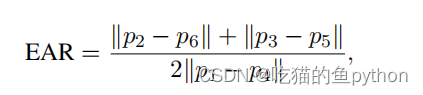

对应在图上就是2点和6点相减,3和5点相减。然后比上2倍的1和4点的差。其中都是绝对值。这样睁眼的时候EAR的数值就会较大,闭眼的时候EAR的数值就会较小。然后我们自己设定一个阈值,如果EAR的数值低于这个阈值超过了视频帧中的几帧。那么我们就认为该驾驶员正在闭眼。
经过了论文验证,说明该方法的准确度是非常可观的,且具有较强的鲁棒性。
🌟项目代码详解
首先我们导入工具包,这里面也包括了计算欧氏距离的工具包。
from scipy.spatial import distance as dist
from collections import OrderedDict
import numpy as np
import argparse
import time
import dlib
import cv2
然后我们把68点关键点定位信息定位好。
FACIAL_LANDMARKS_68_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 36)),
("jaw", (0, 17))
])
这里"jaw", (0, 17)表示的是下巴的位置的关键点标识分别是0-17点。
然后我们将需要的模型和视频导入到程序当中。关键点检测模型。
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-v", "--video", type=str, default="",
help="path to input video file")
args = vars(ap.parse_args())
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
这里这两个参数很重要,其中EYE_AR_THRESH这个表示EAR的阈值。如果高于这个阈值说明人这个时候是睁眼的,如果低于这个阈值的话,那么这个时候就要注意了,驾驶员可能在闭眼。而EYE_AR_CONSEC_FRAMES这个表示如果EAR数值超过了三帧及以上我们就可以把他认定为一次闭眼。为什么是三帧呢?因为如果一帧两帧的话可能是其他因素影响的。
COUNTER = 0
TOTAL = 0
然后我们又设定了两个计数器,如果小于阈值那么COUNTER的数值就加一,知道COUNTER的数值大于等于3的时候,这个TOTAL就加一,就说明记录的闭眼了一次。
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
这里我们就很熟悉了,一个是人脸定位器,一个是关键点检测器。这里分别调出来。
(lStart, lEnd) = FACIAL_LANDMARKS_68_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_68_IDXS["right_eye"]
然后我们通过关键点只取两个ROI区域,就是左眼区域和右眼区域。
print("[INFO] starting video stream thread...")
vs = cv2.VideoCapture(args["video"])
随后我们将视频读进来。
while True:
# 预处理
frame = vs.read()[1]
if frame is None:
break
(h, w) = frame.shape[:2]
width=1200
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
将视频的展示框放大一点,这里很关键就是如果视频的框框设置的太小的话,可能无法检测到人脸。然后我们就把宽设置成了1200,然后对长度也同比例就行resize操作。最后转换成灰度图。
rects = detector(gray, 0)
这里面检测到人脸,将人脸框的四个坐标拿到手。注意就是必须要是对灰度图进行处理。
for rect in rects:
# 获取坐标
shape = predictor(gray, rect)
shape = shape_to_np(shape)
在这里进行人脸框遍历,然后检测68关键点。
def shape_to_np(shape, dtype="int"):
# 创建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
这里就是提取关键点的坐标。
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
然后我们把左眼和右眼分别求了一下EAR数值。这里的eye_aspect_ratio函数就是计算EAR数值的。
def eye_aspect_ratio(eye):
# 计算距离,竖直的
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# 计算距离,水平的
C = dist.euclidean(eye[0], eye[3])
# ear值
ear = (A + B) / (2.0 * C)
return ear
其中dist.euclidean表示计算欧式距离,和公式中计算EAR数值一摸一样。
ear = (leftEAR + rightEAR) / 2.0
# 绘制眼睛区域
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
然后对于左眼和右眼都进行了EAR求解然后求了一个平均值,然后根据凸包的概念,对眼睛区域进行了绘图。将左眼区域和右眼区域绘图出来。
if ear < EYE_AR_THRESH:
COUNTER += 1
else:
# 如果连续几帧都是闭眼的,总数算一次
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# 重置
COUNTER = 0
# 显示
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Frame", frame)
key = cv2.waitKey(10) & 0xFF
if key == 27:
break
vs.release()
cv2.destroyAllWindows()
最后进行了一次阈值判断,如果EAR连续三帧都小于0.3,那么我们就把TOTAL加一,这样记录一次闭眼的过程。然后最后将EAR数值和TOTAL的数值展示在视频当中。最后完成整体的训练。
🌟项目结果展示


🌟项目改进方向(打哈欠检测疲劳方法)
我们知道在疲劳检测当中,光光检测眨眼可能不是特别准确,因此我们还要在其他可以展示驾驶员疲劳的点来结合展示驾驶员是否处于疲劳驾驶阶段。我们了解到还可以通过嘴巴打哈欠,和点头来展示驾驶员是否疲劳。我们首先来考虑嘴巴打哈欠。
首先我们来看一下嘴巴的关键点。
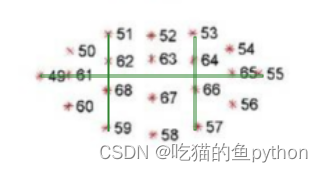
我们使用对眨眼检测的方法继续对嘴巴使用同样的方法检测是否张嘴!对应公式是:
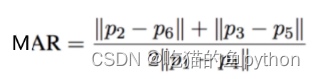
def mouth_aspect_ratio(mouth):
A = np.linalg.norm(mouth[2] - mouth[9]) # 51, 59
B = np.linalg.norm(mouth[4] - mouth[7]) # 53, 57
C = np.linalg.norm(mouth[0] - mouth[6]) # 49, 55
mar = (A + B) / (2.0 * C)
return mar
这里面我们选择的是嘴部区域内的六个点,来判断驾驶员是否进行了张嘴!
MAR_THRESH = 0.5
MOUTH_AR_CONSEC_FRAMES = 3
同样我们也要设置一个阈值,解释同对眨眼检测的时候一样。
(mStart, mEnd) = FACIAL_LANDMARKS_68_IDXS["mouth"]
首先我们取到68关键点中对应的嘴部区域。
mouth = shape[mStart:mEnd]
mar = mouth_aspect_ratio(mouth)
然后通过函数mouth_aspect_ratio来计算出来mar数值!然后进行凸包检测,并且要画出来。
mouthHull = cv2.convexHull(mouth)
cv2.drawContours(frame, [mouthHull], -1, (0, 255, 0), 1)
left = rect.left()#绘制出来人脸框
top = rect.top()
right = rect.right()
bottom = rect.bottom()
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 3)
这里面我们要加上一点就是说我们要绘制出来人脸框框!
if mar > MAR_THRESH: # 张嘴阈值0.5
mCOUNTER += 1
cv2.putText(frame, "Yawning!", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
else:
# 如果连续3次都小于阈值,则表示打了一次哈欠
if mCOUNTER >= MOUTH_AR_CONSEC_FRAMES: # 阈值:3
mTOTAL += 1
# 重置嘴帧计数器
mCOUNTER = 0
cv2.putText(frame, "Yawning: {}".format(mTOTAL), (150, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "mCOUNTER: {}".format(mCOUNTER), (300, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "MAR: {:.2f}".format(mar), (480, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
然后进行判断,并且在视频当中展示出来!
🌟项目改进方向(点头检测疲劳)
检测流程:
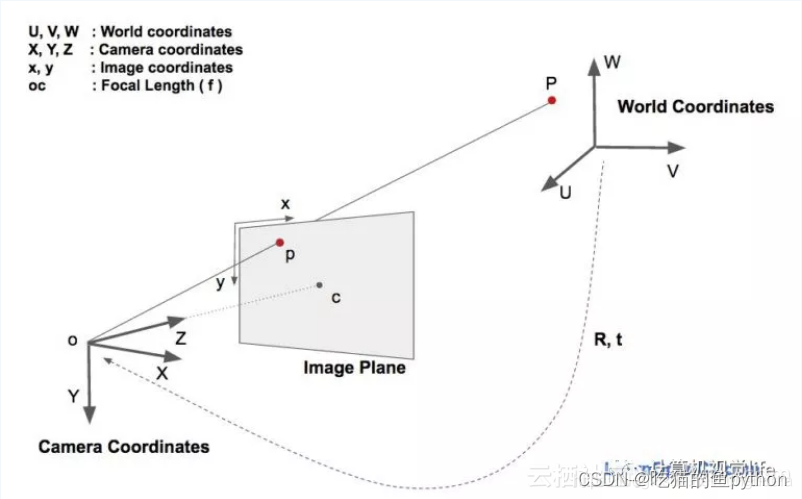
2D人脸关键点检测;3D人脸模型匹配;求解3D点和对应2D点的转换关系;根据旋转矩阵求解欧拉角。
一个物体相对于相机的姿态可以使用旋转矩阵和平移矩阵来表示。
!](https://img-blog.csdnimg.cn/a8286dc98d624f4183eed96daab991e2.png)
- 欧拉角
简单来说,欧拉角就是物体绕坐标系三个坐标轴(x,y,z轴)的旋转角度。 - 世界坐标系和其他坐标系的转换
 世界坐标系到相机坐标系转换:
世界坐标系到相机坐标系转换:
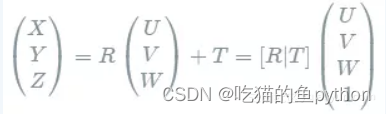
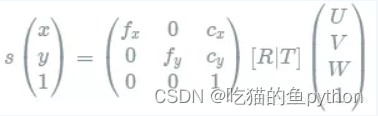
相机坐标系到像素坐标系转换:

因此像素坐标系和世界坐标系的关系如下:
然后我们根据论文来定义一下:
object_pts = np.float32([[6.825897, 6.760612, 4.402142], #33左眉左上角
[1.330353, 7.122144, 6.903745], #29左眉右角
[-1.330353, 7.122144, 6.903745], #34右眉左角
[-6.825897, 6.760612, 4.402142], #38右眉右上角
[5.311432, 5.485328, 3.987654], #13左眼左上角
[1.789930, 5.393625, 4.413414], #17左眼右上角
[-1.789930, 5.393625, 4.413414], #25右眼左上角
[-5.311432, 5.485328, 3.987654], #21右眼右上角
[2.005628, 1.409845, 6.165652], #55鼻子左上角
[-2.005628, 1.409845, 6.165652], #49鼻子右上角
[2.774015, -2.080775, 5.048531], #43嘴左上角
[-2.774015, -2.080775, 5.048531],#39嘴右上角
[0.000000, -3.116408, 6.097667], #45嘴中央下角
[0.000000, -7.415691, 4.070434]])#6下巴角
K = [6.5308391993466671e+002, 0.0, 3.1950000000000000e+002,
0.0, 6.5308391993466671e+002, 2.3950000000000000e+002,
0.0, 0.0, 1.0]# 等价于矩阵[fx, 0, cx; 0, fy, cy; 0, 0, 1]
# 图像中心坐标系(uv):相机畸变参数[k1, k2, p1, p2, k3]
D = [7.0834633684407095e-002, 6.9140193737175351e-002, 0.0, 0.0, -1.3073460323689292e+000]
reprojectsrc = np.float32([[10.0, 10.0, 10.0],
[10.0, 10.0, -10.0],
[10.0, -10.0, -10.0],
[10.0, -10.0, 10.0],
[-10.0, 10.0, 10.0],
[-10.0, 10.0, -10.0],
[-10.0, -10.0, -10.0],
[-10.0, -10.0, 10.0]])
# 绘制正方体12轴
line_pairs = [[0, 1], [1, 2], [2, 3], [3, 0],
[4, 5], [5, 6], [6, 7], [7, 4],
[0, 4], [1, 5], [2, 6], [3, 7]]
其中reprojectsrc和line_pairs这两个属于矩形和矩形连接框框的操作。后续会用得到。
cam_matrix = np.array(K).reshape(3, 3).astype(np.float32)
dist_coeffs = np.array(D).reshape(5, 1).astype(np.float32)
这里我们对K和D矩阵进行了reshape了一下!
def get_head_pose(shape): # 头部姿态估计
# (像素坐标集合)填写2D参考点,注释遵循https://ibug.doc.ic.ac.uk/resources/300-W/
# 17左眉左上角/21左眉右角/22右眉左上角/26右眉右上角/36左眼左上角/39左眼右上角/42右眼左上角/
# 45右眼右上角/31鼻子左上角/35鼻子右上角/48左上角/54嘴右上角/57嘴中央下角/8下巴角
image_pts = np.float32([shape[17], shape[21], shape[22], shape[26], shape[36],
shape[39], shape[42], shape[45], shape[31], shape[35],
shape[48], shape[54], shape[57], shape[8]])
# solvePnP计算姿势――求解旋转和平移矩阵:
# rotation_vec表示旋转矩阵,translation_vec表示平移矩阵,cam_matrix与K矩阵对应,dist_coeffs与D矩阵对应。
_, rotation_vec, translation_vec = cv2.solvePnP(object_pts, image_pts, cam_matrix, dist_coeffs)
# projectPoints重新投影误差:原2d点和重投影2d点的距离(输入3d点、相机内参、相机畸变、r、t,输出重投影2d点)
reprojectdst, _ = cv2.projectPoints(reprojectsrc, rotation_vec, translation_vec, cam_matrix, dist_coeffs)
reprojectdst = tuple(map(tuple, reprojectdst.reshape(8, 2))) # 以8行2列显示
# 计算欧拉角calc euler angle
# 参考https://docs.opencv.org/2.4/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html#decomposeprojectionmatrix
rotation_mat, _ = cv2.Rodrigues(rotation_vec) # 罗德里格斯公式(将旋转矩阵转换为旋转向量)
pose_mat = cv2.hconcat((rotation_mat, translation_vec)) # 水平拼接,vconcat垂直拼接
# decomposeProjectionMatrix将投影矩阵分解为旋转矩阵和相机矩阵
_, _, _, _, _, _, euler_angle = cv2.decomposeProjectionMatrix(pose_mat)
pitch, yaw, roll = [math.radians(_) for _ in euler_angle]
pitch = math.degrees(math.asin(math.sin(pitch)))
roll = -math.degrees(math.asin(math.sin(roll)))
yaw = math.degrees(math.asin(math.sin(yaw)))
print('pitch:{}, yaw:{}, roll:{}'.format(pitch, yaw, roll))
return reprojectdst, euler_angle # 投影误差,欧拉角
这里我们对一些关键点进行了定位,并且我们将世界坐标系转化成了2D上的坐标。最后我们通过CV2计算出来了欧拉角,这样我们就可以判断司机是否点头了!
HAR_THRESH = 0.3
NOD_AR_CONSEC_FRAMES = 3
hCOUNTER = 0
hTOTAL = 0
同样这里我们也要设定一个阈值和计数器!
reprojectdst, euler_angle = get_head_pose(shape)
har = euler_angle[0, 0] # 取pitch旋转角度
if har > HAR_THRESH: # 点头阈值0.3
hCOUNTER += 1
else:
# 如果连续3次都小于阈值,则表示瞌睡点头一次
if hCOUNTER >= NOD_AR_CONSEC_FRAMES: # 阈值:3
hTOTAL += 1
# 重置点头帧计数器
hCOUNTER = 0
# 绘制正方体12轴
for start, end in line_pairs:
cv2.line(frame, (int(reprojectdst[start][0]),int(reprojectdst[start][1])), (int(reprojectdst[end][0]),int(reprojectdst[end][1])), (0, 0, 255))
# 显示角度结果
cv2.putText(frame, "X: " + "{:7.2f}".format(euler_angle[0, 0]), (10, 90), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
(0, 255, 0), thickness=2) # GREEN
cv2.putText(frame, "Y: " + "{:7.2f}".format(euler_angle[1, 0]), (150, 90), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
(255, 0, 0), thickness=2) # BLUE
cv2.putText(frame, "Z: " + "{:7.2f}".format(euler_angle[2, 0]), (300, 90), cv2.FONT_HERSHEY_SIMPLEX, 0.75,
(0, 0, 255), thickness=2) # RED
cv2.putText(frame, "Nod: {}".format(hTOTAL), (450, 90), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 0), 2)
for (x, y) in shape:
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
if TOTAL >= 50 or mTOTAL >= 15:
cv2.putText(frame, "SLEEP!!!", (100, 200), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
这里也是一些判断操作和将信息在视频中展示出来。
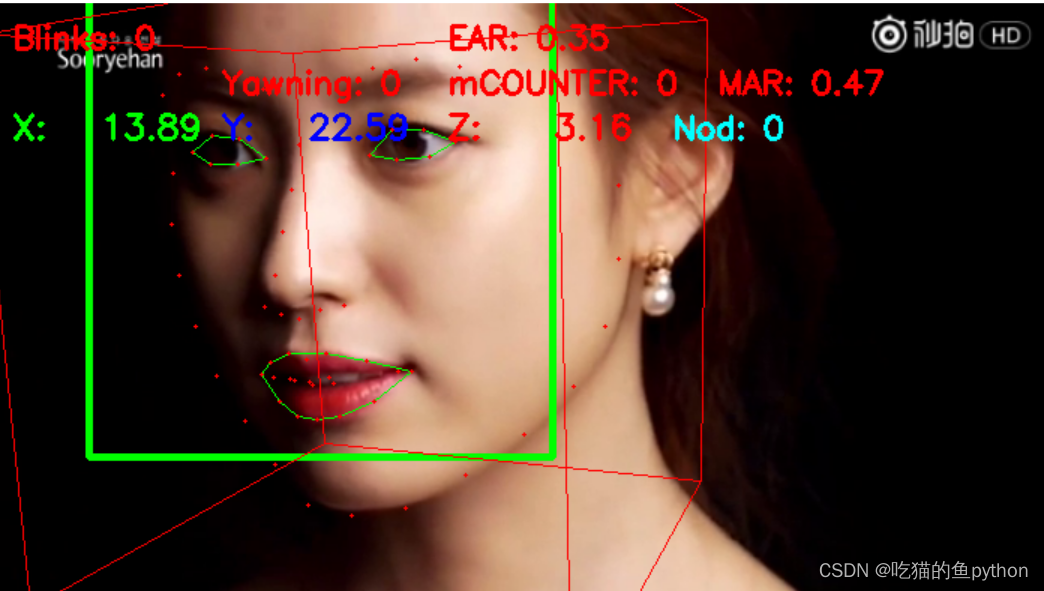
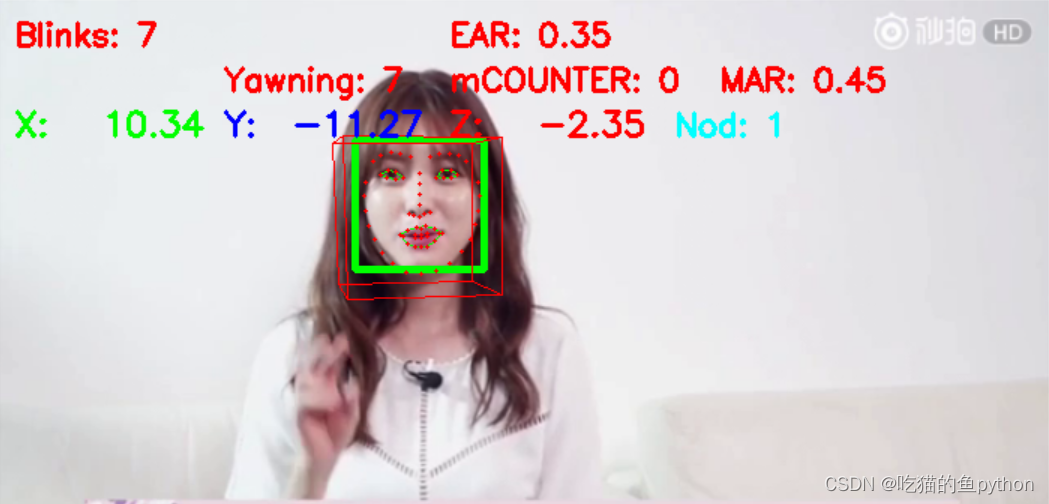
最后的效果如下:
🌟GUI界面设计展示
并且可以完成摄像头检测!
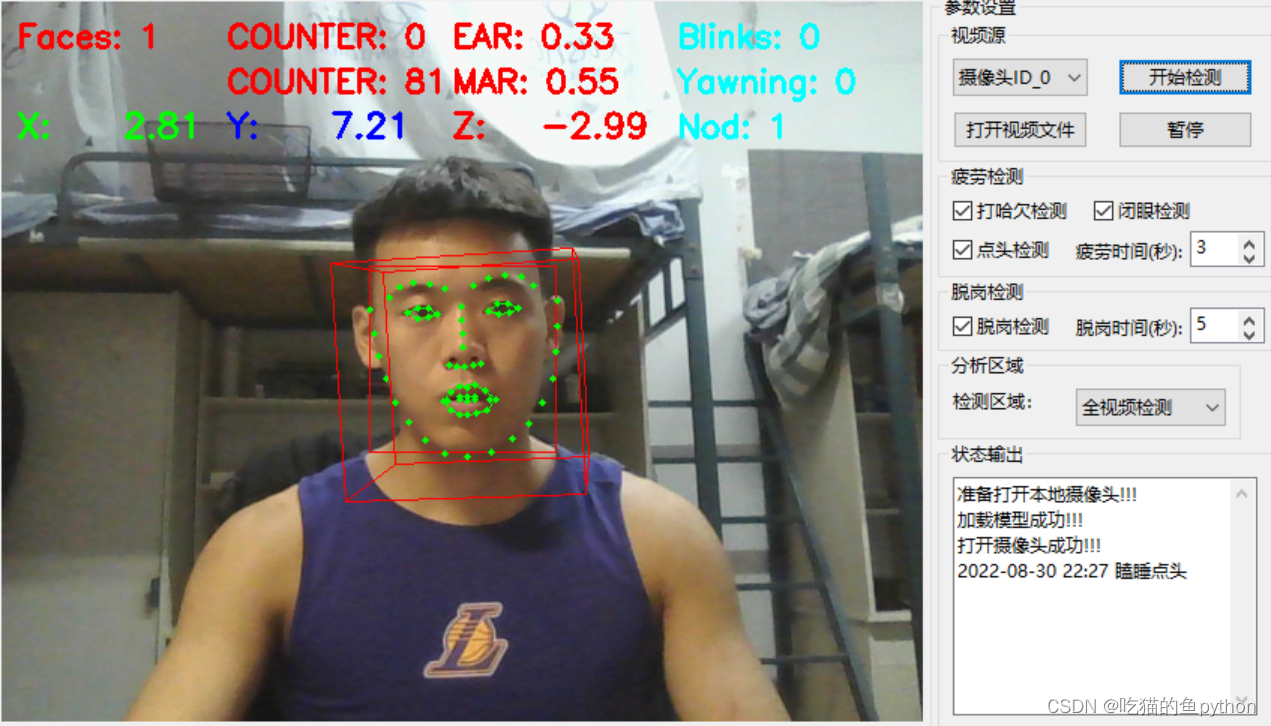
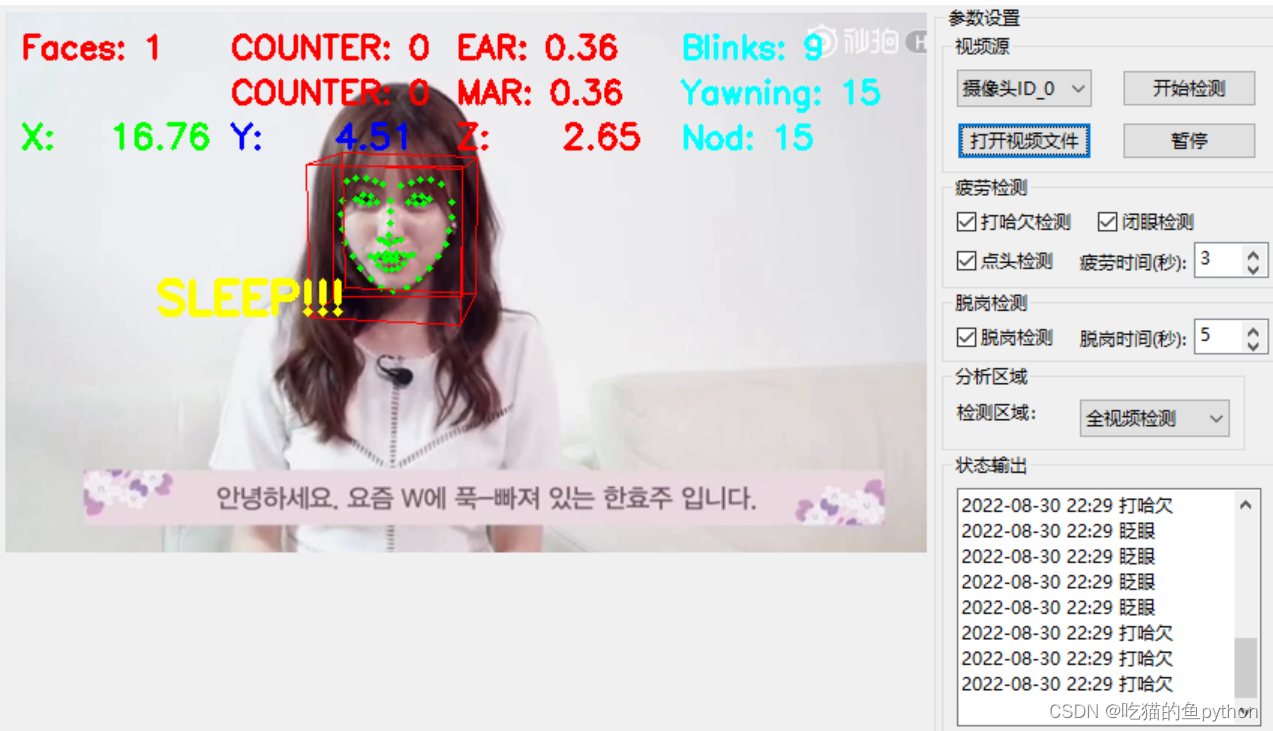
🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!