
基于补丁的任意风格的快速迁移
文章目录
Abstract
艺术风格转移是一个图像合成问题,即用另一个图像的风格来再现图像的内容。最近的工作表明,通过使用预先训练的卷积神经网络的隐藏激活,可以实现视觉上吸引人的风格转移。然而,现有的方法要么应用
(i)一个对任何风格的图像都有效但非常昂贵的优化程序,要么
(ii)一个有效的前馈网络,只允许有限数量的训练风格。
在这项工作中,我们提出了一个更简单的基于局部匹配的操作目标,将内容结构和风格纹理结合在预训练网络的单一层中。我们表明,我们的目标具有良好的特性,如更简单的优化环境,直观的参数调整,以及在视频中逐帧表现的一致性。此外,我们使用80,000幅自然图像和80,000幅绘画来训练一个近似于优化结果的逆向网络。这就产生了一个高效的艺术风格转移程序,但也允许任意的内容和风格图像。
1. Introduction
著名艺术家通常以特定的艺术风格而闻名,这需要多年的发展。即使一旦被发现,一件艺术作品也可能需要几天甚至几个月的时间来创作。这促使我们去探索创造艺术图像的有效计算策略。虽然有大量关于纹理合成方法的经典文献,从一张空白的画布上创造出艺术品[8, 20, 22, 35],但最近的一些方法研究了将一个图像的理想风格转移到另一个图像的结构内容上的问题。这种方法被称为艺术风格转换法。
艺术风格的模糊概念很难被量化。早期的工作是用相似度或基于像素值的局部统计来定义风格[7, 8, 13, 14, 20, 24]。然而,最近取得令人印象深刻的视觉质量的方法来自于使用卷积神经网络(CNN)进行特征提取[9, 10, 11, 21]。这些方法的成功甚至创造了一个可以按需对用户提供的图像进行风格化的移动应用市场[15, 29, 32]。
尽管有这种新的兴趣,但实际的风格转移过程是基于解决一个复杂的优化程序,这在今天的硬件上可能需要几分钟。一个典型的加速解决方案是训练另一个神经网络,在一个简单的前馈通道中接近优化的最佳状态[6, 17, 33, 34]。虽然速度更快,但使用这种方法的现有作品牺牲了能够对任何给定的风格图像进行风格转换的通用性,因为前馈网络不能超越其训练的图像集的范围。由于这一限制,前述应用要么耗时,要么在提供的风格数量上受到限制,这取决于风格转换的方法。
在这项工作中,我们提出了一种解决这些限制的方法:一种新的艺术风格转移方法,它是有效的,但不局限于有限的风格集合。为了实现这一点,我们为风格转换定义了一个新的优化目标,该目标显然只取决于CNN的一个层(与现有的使用多层的方法相反)。新的目标导致了视觉上吸引人的结果,而这个简单的限制允许我们使用一个 "反转网络 "来确定地反转来自风格化层的激活,以产生风格化的图像。
第2节回顾了相关的工作,而第3-4节描述了我们新的优化目标,即在一个激活层中结合风格和内容统计。然后,我们提出了一种训练神经网络的方法,它可以在激活层中产生一个图像。第5节介绍了新方法的实验,表明它具有现有公式中所没有的理想特性。
2. Related Work
作为优化的风格转移(Style Transfer as Optimization)。Gatys等人[11]将风格转移作为一个优化问题,将纹理合成与内容重建结合起来。他们的表述涉及放置在预训练的CNN的多个层上的加性损失函数,其中一些损失函数用于合成风格图像的纹理,另一些损失函数用于重建内容图像。梯度是通过反向传播计算的,基于梯度的运算被用来解决风格化图像的问题。另一种方法是在内容和风格图像之间使用基于补丁的相似性匹配[9, 10, 21]。特别是,Li和Wand[21]构建了基于补丁的损失函数,其中每个合成补丁都有一个必须匹配的最近邻目标补丁。这种补丁匹配损失函数然后与Gatys等人的公式相加。虽然这些方法允许任意风格的图像,但这些方法所使用的优化框架使得生成风格化图像的速度很慢。这对于我们要对大量的帧进行风格化的视频来说尤其重要。
前馈风格网络(Feed-forward Style Networks) 前面提到,可以训练一个神经网络,该网络近似于Gatys等人对一种或多种固定风格的损失函数的最佳值[6, 17, 33, 34]。这产生了一个更快的方法,但这些方法需要为每个新的风格重新训练。
视频的风格转移(Style Transfer for Video)。Ruder等人[30]引入了一个时间损失函数,当与Gatys等人的损失函数叠加使用时,可以对视频进行具有时间一致性的风格转移。他们的损失函数重新在于光流算法,用于将风格粘在附近的帧上。与逐帧应用的风格转移相比,这导致了一个数量级的减慢。
反转深度表示(Inverting Deep Representations) 有几项工作为实现可视化的目标,训练了预训练卷积神经网络的逆向网络[3, 26]。其他的工作是将逆向网络作为自动编码器的一部分来训练[19, 27, 36]。据我们所知,所有现有的逆向网络都是用一个图像数据集和一个置于RGB空间的损失函数进行训练。
与现有的风格转移方法相比,我们提出了一种直接构建预训练的CNN中单层目标行为的方法。与Li和Wand[21]一样,我们使用了一个标准来寻找激活空间中的最佳匹配斑块。然而,我们的方法能够直接构建整个激活目标。这种确定性的程序使我们能够轻松地适应视频,而不需要依靠光流来解决一致性问题。除了优化,我们还提出了一个前馈式风格转移程序,即倒置预先训练的CNN。与现有的前馈式风格转移方法不同,我们的方法不局限于专门训练的风格,可以很容易地适应任意的内容和风格印象。与现有的CNN反转方法不同,我们的训练方法不使用像素级损失,而是使用激活的损失。通过使用一个特殊的训练设置(见第4.1节),这个反转网络甚至能够反转超出CNN激活通常范围的激活。
3. 风格迁移的新目标
我们的风格转换方法的主要组成部分是一个基于补丁的操作,用于在单层中构建目标激活,给定风格和内容图像。我们把这个过程重新称为图像的 “风格转换”,因为内容图像被风格图像逐片替换。我们首先在高层次上介绍这一操作,然后是关于我们实现的更多细节。
3.1. 风格互换(Style Swap)
让C和S分别表示内容和style图像的RGB表示,让Φ(-)是预先训练好的CNN的完全卷积部分所代表的函数,它将图像从RGB映射到一些中间激活空间。在计算了激活,Φ(C )和Φ(S)之后,风格交换程序如下:
-
- 为内容和风格激活提取一组补丁,用{φi(C )}i∈nc和{φj(S)}j∈ns表示,其中nc和ns是提取补丁的数量。提取的斑块应该有足够的重叠,并包含激活的所有通道。
-
- 对于每个内容激活补丁,根据归一化的交叉相关度,确定一个最匹配的风格补丁,
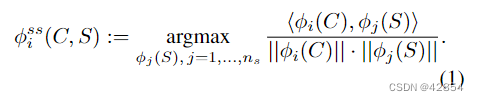
- 对于每个内容激活补丁,根据归一化的交叉相关度,确定一个最匹配的风格补丁,
-
- 将每个内容激活补丁φi(C )与其最相近的样式补丁φssi(C,S)进行交换。
-
- 重建完整的内容激活,我们用Φss(C,S)表示,通过对可能因步骤3而有不同数值的重叠阵列进行平均化。
这种操作的结果是对应于具有内容图像结构的单一图像的隐藏激活,但其纹理取自风格图像。
3.2. 可并行化的实现
为了给出一个有效的实现方法,我们表明全部风格互换操作可以作为一个具有三种操作的网络来实现:
(i)一个二维卷积层,
(ii)一个通道方式 argmax,
(iii)一个二维转置的卷积层。
这样,风格互换的实现就像使用现有的二维卷积和转置卷积的有效实现一样简单。
为了简明扼要地描述执行情况,我们对内容激活斑块进行重新索引,以明确表示空间结构。特别是,我们让d为Φ(C )的特征通道数,让φa,b(C )表示Φ(C )a:a+s, b:b+s, 1:d的补丁,其中s是补丁大小。
请注意,内容激活补丁的归一化项φi(C )相对于argmax操作而言是常数,因此(1)可以改写为
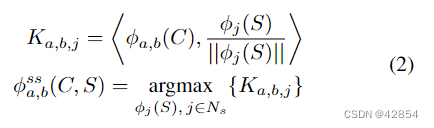
由于没有对内容激活斑块进行归一化处理,因此简化了计算,并允许我们使用二维卷积层。以下三个步骤描述了我们的实现,并在图2中得到了说明:

图2:风格互换操作的图示。二维卷积提取大小为3×3、步长为1的斑块,并对归一化的交叉关系进行分析。在进行通道的argmax操作前后,有nc=9个空间位置和ns=4个特征通道。二维转置卷积通过将每个最佳匹配的样式补丁放在响应的空间位置来重建完整的行为。
- 张量K可以通过使用归一化的样式激活补丁{φj(S)/||φj(S)||}作为卷积滤波器和Φ(C )作为输入,通过单个二维卷积计算出来。计算出的K有nc个空间位置和ns个特征通道。在每个空间位置,Ka,b是一个内容激活斑块和所有样式激活斑块之间的交叉相关的向量。
- 为了准备二维转置卷积,我们将每个向量Ka,b重新置于一个对应于最佳匹配风格激活斑块的单热向量。
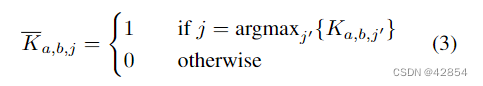
- 构建Φss(C,S)的最后一个操作是二维转置卷积,以K为输入,以非正常化的风格激活斑块{φj(S)}为过滤器。在每个空间位置,只有最匹配的风格激活补丁在输出中,因为其他补丁被乘以零。
请注意,转置的卷积会将重叠斑块的值加起来。为了平均这些值,我们对输出的每个间隔位置进行元素除法,即重叠斑块的数量。因此,我们不需要规定(3)中的argmax有一个唯一的解决方案,因为多个 argmax 解决方案可以简单地解释为添加更多的重叠补丁。
3.3. 优化公式
风格化图像的像素表示可以通过在激活空间上放置一个损失函数与目标激活Φss(C,S)来计算。与先前关于风格转移的工作[11, 21]类似,我们使用平方误差损失,并将我们的优化目标定义为:
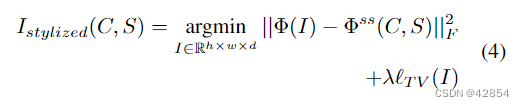
其中,我们说合成图像的维度是h乘w乘d,||-||F是Frobenius规范,`TV(-)是图像生成方法中广泛使用的总变化正则化项[1, 17, 26]。由于Φ(-)包含多个对图像进行降采样的maxpooling操作,我们将这个正则化作为一个自然的图像先验,为重新升采样的图像获得空间上更平滑的结果。总变异正则化如下:
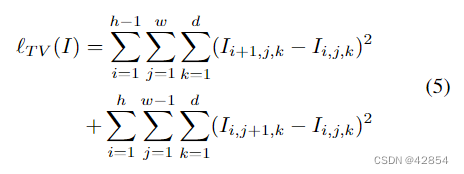
由于函数Φ(-)是预训练的CNN的一部分,并且至少是一次可微分的,(4)可以使用标准的基于子梯度的优化方法来计算。
4. 逆向网络(Inverse Network)
不幸的是,在视频风格化等应用中,解决优化问题以计算风格化图像的成本可能太高。我们可以通过使用其他神经网络近似优化来提高运算速度。一旦经过训练,这个网络就可以更快地生成风格化图像,我们将特别训练这个网络的通用性,使其能够使用新的内容和新的风格图像。
我们的逆向网络的主要目的是为任何目标激活接近(4)中损失函数的最优。因此,我们将最优的反函数定义为:
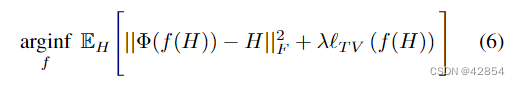
其中f代表一个确定性的函数,H是一个代表目标激活的运行变量。总变量正则化项被添加为类似于(4)的自然图像先验。
4.1. 训练逆向网络
由于预先训练的卷积神经网络的特性,出现了几个问题。
非注入式(Non-injective)。定义Φ(-)的CNN包含convolutional, maxpooling, 和ReLU层。这些函数是多对一的,因此没有明确的反函数。与现有的使用逆向网络的工作相似[4, 25, 36],我们改用参数化的神经网络来训练逆向关系的近似。
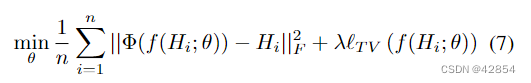
其中θ表示神经网络f的参数,Hi是来自大小为n的数据集的激活特征。这个目标函数导致了神经网络的无监督训练,因为(4)的最佳值不需要知道。我们将逆向网络结构的描述放在附录中。
非射影的(Non-surjective)。由于插值的原因,风格互换操作产生的目标激活可能在Φ(-)的范围之外。这意味着,如果反演网络只用真实图像进行训练,那么反演网络可能只能反演Φ(-)范围内的激活。由于我们希望反转网络能够反转风格互换的激活,所以我们增加了训练集以包括这些激活。更确切地说,给定一组训练图像(和它们相应的激活),我们用基于图像对的风格互换的激活来增强这个训练集。
4.2. 前馈风格转移过程
一旦经过训练,逆向网络就可以用来取代优化程序。因此,我们提出的前馈程序包括以下步骤:
- 计算Φ(C)和Φ(S)。
- 通过风格互换获得Φss(C,S)。
- 将Φss(C,S)送入训练好的逆向网络。
这个过程如图4所示。如第3.2节所述,风格互换可以作为一个(不可微分的)卷积神经网络来实现。因此,整个前馈程序可以被看作是一个具有单独训练部分的神经网络。与现有的前馈方法[6, 17, 33, 34]相比,我们的前馈程序最大的优势是能够使用新的风格图像,只需要一个训练好的逆向网络。

图4:我们提出了第一个可用于任意风格图像的风格转换前馈方法。我们用一个建设性的程序(风格互换)来模拟风格转换,并训练一个反转网络来生成图像。
5. 实验
在本节中,我们分析了所提出的风格转移和反转方法的特性。我们使用Torch7框架[2]来实现我们的方法2,并使用先前工作的现有开源实现[16, 21, 30]进行比较。
5.1. Style Swap Results
目标层。图3显示了VGG-19网络中不同层的风格互换的效果。在这个图中,RGB图像是通过第3节中描述的优化计算出来的。我们看到,虽然我们可以直接在RGB空间中进行风格交换,但其结果不过是重新着色而已。当我们选择一个在网络中更深的目标层时,风格图像的纹理会更加明显。我们发现,在 "relu3 1 "层上进行风格互换可以提供最令人愉悦的视觉效果,同时在结构上与内容保持一致。在下面的实验和反演网络训练中,我们把我们的方法限制在 "relu3 1 "层。定性结果显示在图10中。

图3:在VGG-19[31]的不同层中风格互换的效果,也是在RGB空间中。由于VGG-19的命名惯例,"reluX 1 "指的是(X -1)-th maxpooling层之后的第一个ReLU层。风格互换操作使用大小为3×3、跨度为1的补丁,然后用优化方法构建RGB图像。
一致性。我们的风格互换方法将内容和风格信息串联成一个单一的目标特征向量,与其他方法相比,导致了一个更容易的优化表述。因此,我们发现,与现有的公式相比,我们的优化算法能够以更少的迭代次数达到最优,同时持续地达到相同的最优。图5和图6显示了在随机初始化的情况下,我们的公式与现有作品之间的优化差异。这里我们看到,随机初始化对风格化的结果几乎没有影响,表明我们的局部优化比其他风格的转移目标少得多。

图5:与现有的优化公式相比,我们的方法取得了一致的结果。我们看到Gatys等人的公式[11]有多个局部最优,而我们能够在随机初始化的情况下持续实现相同风格的转移效果。图6显示了这个数量。
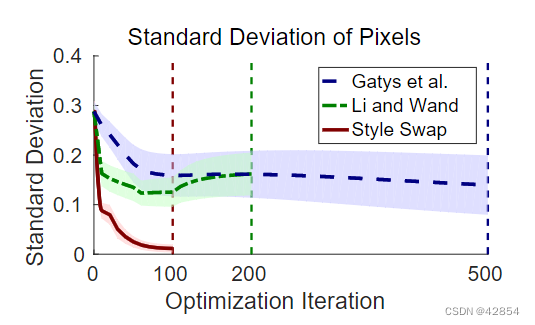
图6:在优化过程中,40个随机初始化的RGB像素的标准偏差显示。线条显示的是平均值,阴影部分是在平均值的一个标准差之内。垂直的虚线表示优化的结束。图5显示了优化结果的例子。
直接适应于视频。在对视频逐帧进行风格化时,这种一致性属性是很有利的。相同的帧将产生相同的风格化结果,而连续的帧将以类似的方式被风格化。因此,我们的方法能够适应视频,而不需要像光流[30]那样的明确胶合程序。我们将风格化的视频放在代码库中。
简单直观的调校。在提议的方法中,调整风格化程度(与保留内容相比)的一个自然方法是修改补丁的大小。图7定性地显示了补丁大小和风格交换结果之间的关系。随着补丁大小的增加,更多的内容图像的结构被丢失并被风格图像的纹理所取代。

图7:我们可以通过调整补丁的大小在内容结构和风格纹理之间进行权衡。风格图像,星空(上)和小世界I(下),显示在图10中。
5.2. CNN反转(CNN Inversion)
在这里,我们描述了我们对一个反向网络的训练,该网络可以计算出预先训练好的VGG-19网络的近似反向函数[31]。更具体地说,我们从输入层到 "relu3 1 "层对截断的网络进行训练。该网络结构被放在附录中。
数据集。我们使用微软COCO(MSCOCO)数据集[23]和来自wikiart.org并由Kaggle[5]托管的绘画数据集进行训练。每个数据集分别有大约80,000张自然图像和绘画。由于典型的内容图像是自然图像,而风格图像是绘画,我们将这两个数据集结合起来,使网络能够学习重新创建这两类图像的结构和纹理。此外,自然图像和绘画的明确分类为第4.1节中描述的扩展提供了相应的内容和风格候选。
训练。我们将每张图片的大小调整为256×256像素(对应于64×64大小的激活),并对每个数据集进行大约2个周期的训练。请注意,即使我们限制了训练图像的大小(和响应的激活),逆向网络是完全卷积的,在训练后可以应用于任意大小的激活。
我们通过从自然图像中提取2个激活样本和从绘画中提取2个样本来构建每个minibatch。我们用4个风格互换的激活来增强minibatch,使用minibatch中的所有自然图像和绘画对。我们在(7)的基础上使用反推法计算子梯度,总方差正则化系数λ=10-6(该方法对这个选择并不特别敏感),我们使用亚当优化器[18]更新网络的参数,固定学习率为10-3。
结果。图8显示了使用MSCOCO的2000张全尺寸验证图像和6张全尺寸风格图像的定量近似结果。尽管只在256×256的图像上进行了训练,但我们对任意全尺寸的图像都能取得合理的结果。我们还与一个具有相同结构但没有经过增强训练的逆向网络进行比较。正如预期的那样,在训练期间从未看到样式交换激活的网络比具有增强训练集的网络表现更差。
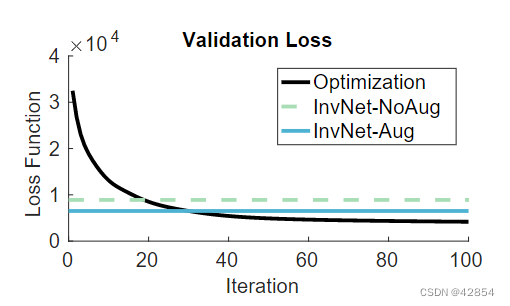
图8:我们比较了在2000张可变大小的验证图像和6张可变大小的风格图像上,使用3×3的补丁尺寸,由操作计时器和我们的逆向网络实现的平均损失(7)。在训练过程中,出现在绘画数据集中的风格图像被移除。
5.3. 计算时间(Computation Time)
现有风格转换方法的计算时间列于表1。与基于优化的方法相比,我们的优化公式更容易解决,每次迭代所需的时间更少,这可能是由于只使用了预训练的VGG-19网络的一个层。其他方法使用多层,也比我们使用的层数更深。
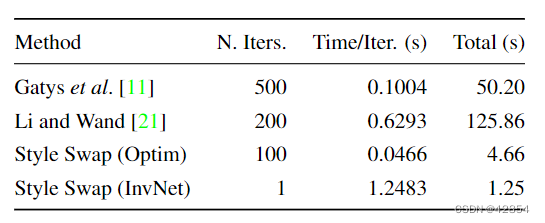
表1:可以处理任意风格图像的风格转移方法的平均计算时间。时间是在GeForce GTX 980 Ti上拍摄的分辨率为300×500的图像。请注意,基于优化的方法的迭代次数只能被视为一个非常粗略的估计。
我们在图9a和9c中显示了我们前馈程序的不同部分所花费的计算时间的百分比。对于任何非微不足道的图像尺寸,风格互换程序比其他神经网络需要更多时间。这是由于风格互换程序包含两个卷积层,过滤器的数量是风格补丁的数量。补丁的数量与图像的像素数呈线性增长,其常数取决于汇集层的数量和提取补丁的步幅。因此,样式图像大小对计算时间的影响最大,这并不奇怪(如图9a和9b所示)。
有趣的是,即使在内容图像尺寸增加时,计算时间似乎也停止了增加(图9d),这可能是由于实现了并行性。这表明我们的程序可以处理大的图像尺寸,只要风格补丁的数量是可控的。也许应该对风格补丁进行聚类,以减少补丁的数量,或者使用其他的实现方法,如快速近似近邻搜索方法[12, 28]。

图9:计算时间随着(a,b)风格图像大小的增加和(c,d)内容图像大小的增加而增加。不可变的图像大小保持在500×500。如(a,c)所示,大部分的计算都花在样式交换程序上。
6. 讨论
我们提出了一种新的基于CNN的艺术风格转换方法,其目的是既快速又能适应任意的风格。我们的方法通过将内容图像的纹理与风格图像的纹理互换,将内容和风格的形成并入CNN的单一层。我们方法的简单性使我们能够训练一个逆向网络,该网络不仅能够在更短的时间内获得近似的结果,而且还能在其训练的风格集之外进行泛化。尽管有单层的限制,我们的方法仍然可以产生视觉上令人愉悦的图像。此外,该方法有一个直观的调整参数(补丁大小),其一致性允许简单地逐帧应用于视频。
虽然我们的前馈方法在速度上无法与Johnson等人[17]的前馈方法竞争,但应该指出,我们的方法最大的优势是能够使用新的风格图像进行风格化,而Johnson等人的方法需要为每个风格图像训练一个新的神经网络。我们已经表明,我们的逆向方法可以在其训练集之外进行泛化(图8),而另一个有用的应用是能够改变风格图像的大小而不需要重新训练逆向网络。
所提出的风格互换程序的一些缺点包括缺乏全局风格测量和缺乏相邻斑块的相似度测量,无论是在空间域还是时间域。这些简化为提高效率而牺牲了质量,但在逐帧应用于视频时,偶尔会导致局部闪烁的效果。在保持我们算法的高效和通用性的同时,寻找提高质量的方法可能是可取的。