前言
作为初始深度学习领域的小白,仅仅接触过图像分类,所以目标检测我会详细做笔记并记录不理解的地方,有错误理解请指正。本实践案例参考AI Gallery-开发者-华为云编程知识中的实践案例进行学习总结。
案例实践
简单了解何为目标检测
相比于图像分类问题,目标检测多了一项确定物体位置信息的任务,即结合了目标分类和定位两个任务。
初始YOLOV3
YOLOV3是YOLO网络系列中一个网络结构,因此算法的思路是单阶段方法(one stage),它将检测任务表述成一个统一的、端到端的回归问题,并且只处理一次图片就能同时得到位置和分类。
YOLOV3的特点
YOLOv3相比YOLOv2最大的改进点在于借鉴了SSD的多尺度判别,即在不同大小的特征图上进行预测。对于网络前几层的大尺寸特征图,可以有效地检测出小目标,对于网络最后的小尺寸特征图可以有效地检测出大目标。此外,YOLOv3的backbone选择了DarkNet53网络,网络结构更深,特征提取能力更强了。
理解:
- 何为单阶段(one stage):和图像分类步骤类似,先进行特征提取,再进行分类/定位回归;然而,有one必有two, two stage的步骤呢,为特征提取--->生成预选框(简称RP,一个有可能包含待检物体的预选框)--->分类/定位回归。
- 何为多尺度判别:在目标检测任务中,比如在一张图片中,要判别的目标不止一个,多个目标的大小(相对比例或者实际绝对大小)尺度有大有小,但不论大小,都要将其识别出来。(参考:http://t.csdn.cn/0hLaE)
YOLOV3的图示结构
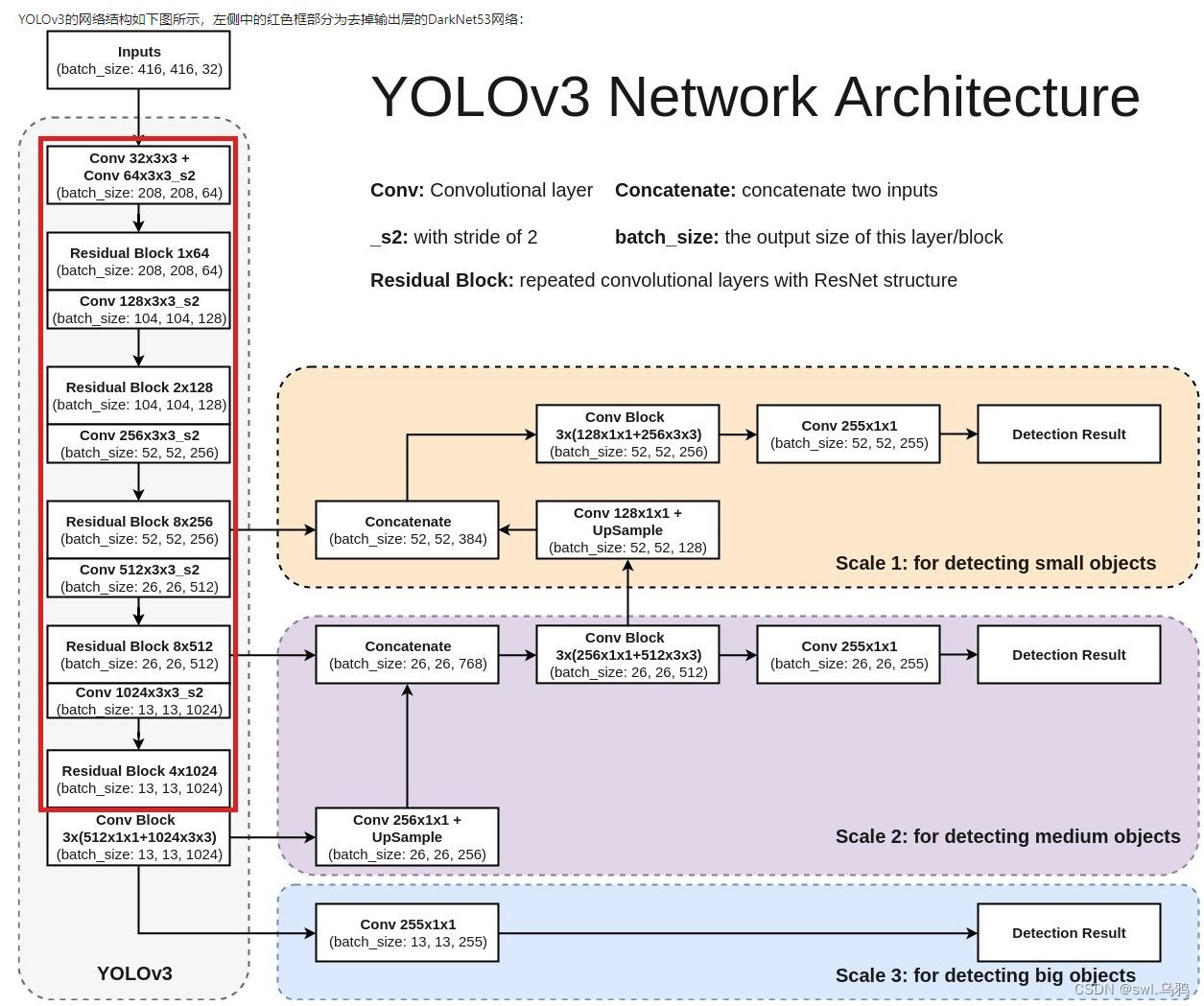
?【YOLOV3结构的几点注意】
- 由于网络结构较深,才有残差结构
- DarkNet53网络用步长为2的卷积代替了池化层
- 所有的网络层不包含全连接层,因此,输入图像的大小也是可以调整的(有些地方看到的可能是608x608,其实是一样的,而输入图像的大小同样是最小的输出特征图的32倍
- ?YOLOv3分别在三个尺寸的特征图进行了预测,每个尺寸的特征图使用了3个锚点。因此,输出层的维度计算方法为:(4+1+80)x3=255,因此,最后一层1x1的卷积层的数量为255
- ? 13 x 13的特征图会通过上采样层和之前的26 x 26的特征图在通道维度拼接在一起,26 x 26的特征图再经过上采样和52 x 52的特征图拼接。
对于第3、4点有点不太理解,存疑此处 ?未来解决理解。。。如有大佬看到,还请能解答。
?关于目标检测中的锚点和锚框理解参考http://t.csdn.cn/qBNyK、http://t.csdn.cn/NDK7k
?理解:
- 何为锚点、锚框:按我的理解,就是在图像中生成几个点,这几个点是按照一定的设计规则分布的,然后围绕这些点(作为中心点)生成几个框,框的大小尺度也是有一定设计规则,但要保证能覆盖整个识别区域。而表现在代码中,锚点就成了矩阵、锚框根据每个矩阵中设置的数值偏移量形成框:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
有一句话也许有利于理解:根据Anchor的生成过程和深度学习没有任何的关系,他的本质只是你设定好一些规则,并依据这些规则,在图像中生成不同尺寸,不同长宽比的框,并希望这些框能够最终覆盖你的物体。
【注】这个结构得好好研究分析。。。。
实践步骤
实践前创建存放实现代码功能代码脚本的文件夹
#创建文件夹,存放即将写的各功能的代码脚本
import os
code_dir = "./code/src"
if not os.path.exists(code_dir):
os.makedirs(code_dir)准备数据集
#准备数据集
import os
import moxing as mox //华为云Modelart平台的一个进行模型训练API
if not os.path.exists("./data"):
mox.file.copy_parallel(src_url = "obs://modelarts-labs-bj4/course/hwc_edu/python_module_framework/datasets/mindspore_data/yolov3/data/", dst_url = "./data")?mox可以参考MoXing Framework简介_AI开发平台ModelArts_MoXing开发指南_华为云