Towards Optimal Fine Grained Retrieval via Decorrelated Centralized Loss
with Normalize-Scale layer?
Xiawu Zheng1 , Rongrong Ji1? , Xiaoshuai Sun1 , Baochang Zhang2 , Yongjian Wu3 , Feiyue Huang 3
1 Fujian Key Laboratory of Sensing and Computing for Smart City,
School of Information Science and Engineering, Xiamen University
2 Beihang University, 3 Tencent Youtu Lab, Tencent Technology (Shanghai) Co.,Ltd
AAA2019
一、摘要
?? ?? ??细粒度图像检索(FGIR)的最新进展倾向于学习具有特定全连接层设计损失函数的CNN,以有效地区分细粒度类别的高维特征,但现有损失函数有两个方面的缺陷:
(a)特征关系被编码在训练批内。这样的局部范围导致精度低。
(b)误差由均方确定,在训练集中需要成对计算距离,导致效率低下。
? ? ?? ?本文提出的方法为标准化规模层和与去除相关的全局中心排名损失(DGCRL loss):方法源自经典的softmax损失,该损失具有全局结构,但没有直接优化距离度量以及类间/类内距离。提出的损失函数解决方法:
(a)通过超球体层和全球成对排名损失以及成对的去相关学习来优化度量距离以及类内/间距离。
(b)特征关系编码是基于全局CRL损失之下的,目的是在全局范围内优化距离问题,加速学习过程。
(c)使用Gram-Schmidt进行去除相关,实现高效率的训练,并使特征在学习的过程中更具可分辨性。
二、介绍
? ??? ? FGIR是在同一元类别的多个子类别里进行图像搜索,由于子类实例在图片中会产生不同姿势、光照等这些细微的差别,使得FGIR比传统的CBIR更具挑战。
?? ??? ?最近的趋势是采用具有距离度量学习的CNN提取区分性和生成性特征,旨在区分细粒度类别的高维特征。但仍然存在一些挑战,FGIR仍旧是一个开放待解决的问题。
1.局部结构挑战: 全局结构的学习在图像分类/识别/细分中有很好的应用,通常使用交叉熵+ softmax损失,即最后一个完全连接层的权重可以视为全局类中心。 这种全局优化机制无法直接在FGIR中实现,因为其内积运算在理论上不是距离度量,因此无法强制执行特征可辨性。 为了进一步说明,同一类别中的要素可能位于不同的超球面上,因此彼此分开,而在不同类别的困难示例中则更接近。
2.缓慢的训练速度: 培训速度不理想的主要原因在于培训/测试与MSE使用之间的差异。?特别是,由于数据集包含具有不同质量的图像,因此响应特征往往位于球体的不同部位上。 因此,在训练中,很难使类间距离最小化,在测试中,在没有使用L2标准化的情况下很难有效的衡量特征之间的相似性,这进一步导致了训练和测试之间的差距。即,在训练中没有L2标准化的情况下特征能优化,而相似度
是在测试归一化后进行测量。 更重要的是,MSE将很快陷入局部极小值,这进一步降低了训练效率。
? ? ?? ?提出的方案:
(a)N-S Layer:消除training和testing直接的差异,消除内积、欧式距离。提出的归一化尺度(N-S)层在图像特征中采用归一化和尺度运算,将内积和欧几里得距离度量联系起来,以通过softmax损失很好地加速DGCRL。
(b)DGCRL:鼓励学习嵌入式功能,优化类内紧凑性和类间可分离性。由两部分组成:特征空间中的全局感知排名损失和中心空间的Gram Schmidt独立运算,从而解决了特征挑战 可分辨性和概括性。?
? ? ?? ?性能比较:新方案比GRL-WSL提高15%,运行速度比triplet loss提高了五倍。
三、最近的研究
?? ??? ?FGIR中的现有的研究工作可以分为两部分:第一部分依赖于手工定义特征(handcraft feature),第二部分将深度度量学习应用到FGIR中,试图通过设计用于训练深度神经网络的特定损失函数来学习判别特征。
(a)这些方法对特征之间的局部关系进行编码,从而降低了特征的可分辨性和学习效率。
(b)没有解决训练和测试之间的差异问题。
四、提出方案
?? ??? ?提出的模型在两个方面进行了创新,即标准化规模层(N-S Layer)和去相关全局感知的集中化排名损失(DGCRL)。
(a)N-S层通过L2标准化和缩放层将特征要素投影到一个超球面上。?
(b)DGCRL由两部分组成:在全局范围内,它们直接优化类内部的紧凑性(通过中心空间中的Gram-Schmidt去相关操作)和类间的可分离性(通过特征空间中的全局集中排名损失(GCRL))。这与以前的方法有所不同,以前的方法倾向于使用成对/三元组丢失来关注嵌入空间的局部结构,因此提高了特征可辨性和学习效率。
定义问题和总流程:
?? ??? ?令Ⅱ={I1,....,In}∈I,是一个细粒度图像的标记集合,其中I是所有可能图像的原始输入空间。 根据应用,在训练集中,每个图像都有其对应的标记y∈{1,...,K},共有K个类别/簇。 函数f(・;θ):I→Rd在d维嵌入空间X中将图像I映射到向量xi=f(Ii,θ)。θ是要学习的CNN参数。
?? ??? ?我们首先总结了用于细粒度图像检索的一般l流程。 给定具有细粒度图像和相应标签的训练集,没有特征标准化训练的CNN。 在测试阶段,从图像Ii中提取特征描述符xi并标准化为单位长度。 然后,根据使用欧几里得距离计算出的相似度对返回列表进行排序。 请注意,在线阶段不可避免地要进行标准化。 由于这些功能位于不同的领域,因此在没有图像失真的情况下检索图像可以极大地提高性能。
?? ??? ?此流程中有两个问题。 首先,将细粒度图像检索的训练和测试阶段分离。 不能保证训练步骤直接优化欧几里得空间中的排序功能,即某些检索任务遵循内积+ softmax损失流水线,这与训练中的损失设计不同。 第二,现有的深度度量学习无法提取不同超球面上的判别特征。 一些先前的工作提出了特征归一化方法来解决这些问题。 然而,如图3所示,将单位长度的特征标准化也不会导致“退化”问题,即,由于单位球面上的微小空间,损失无法收敛。 此外,具有特征归一化的内积不是欧几里得距离,这意味着训练和测试步骤之间仍然存在差距。 我们提出了一种新颖的规范化尺度(N-S)层来解决上述问题,该层通过规范化消除了内积与欧几里得距离之间的间隙,并通过尺度操作扩展了表示空间。
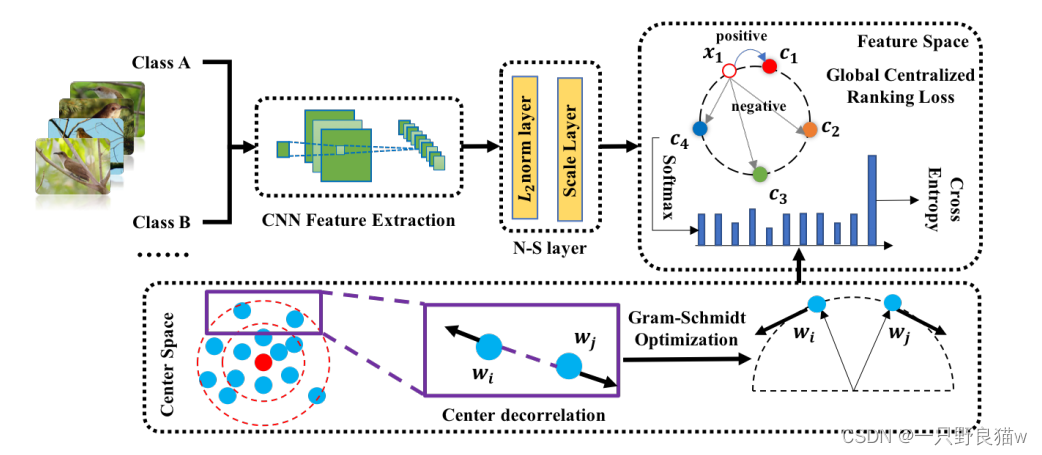
Normalize-Scale Layer:
?? ??? ?N-S层将要素分布在超球面上。 对于输入向量x,可以如下定义层:
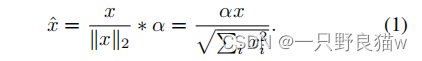
?? ??? ?在此,x可以是特征向量或中心。 可以通过公开可用的深度学习框架例如MXNet或Caffe轻松实现该层。??N-S层通过归一化和缩放层来放置特征,如图1所示。 值得注意的是,不应将中心投影在超球面上,因为中心将通过反向传播逐渐靠近特征超球面,并且“退化”问题仅存在于原始特征空间中。此外,距离计算可以转换为内积形式(将在下一部分中进行描述)。 因此,在特征空间中采用映射操作会使数值计算更加容易。
Decorrelated Global Centralized Ranking Loss:
?? ??? ?由于巨大的搜索空间和本地感知的结构,以前的深度度量学习方法的训练效果较差,无法为细粒度工作学习到代表性的区分特征。主要原因是局部结构学习区分特征是不足的。 此外,直接最小化欧几里得距离会导致非常缓慢的收敛。 因此,通过全球可学习的中心向后传播是合理的。 结合N-S层,提出的GCRL方案直接优化了以下损失:
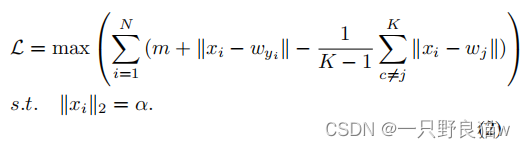
对于给定的特征xi,损失函数由三部分组成:边缘量m,对应中心距离wyi和负对之间的距离。 梯度定义为:
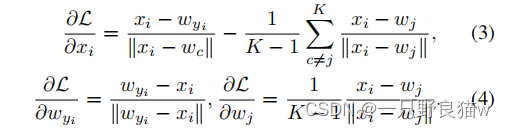
如等式3所示,GCRL强制特征xi接近目标类别的中心,同时远离无关类别的中心。 同时,在等式4中,由xi生成的信息更新中心,该信息逐渐接近全局中心,从而导致在测试阶段更加紧凑和可分离的特征表示。 但是,由于均方损失,提出的损失函数也存在训练效率问题。 考虑到FGIR通常会处理大型训练集,因此必须进行修改以加速GCRL。
Accelerating GCRL:
?? ??? ?交叉熵准则比均方损失能找到更好的局部最优和收敛速度。 与softmax一起,它已成为各种任务(包括检索)中最常用的损失函数。 但是,在这些方法中,损失函数仅用作辅助函数,这在细粒度图像检索中是不足的。 结合N-S层,我们将全局感知的集中式损失重新配置为等效的softmax损失,从而保留了全局结构,距离度量和GCRL中的较大余量,同时兼顾了softmax损失的优点。
?? ??? ?Softmax损失已被认为是分类中必不可少的组成部分。 对于具有相应中心/标签/聚类yi的输入特征xi,可以表示为:
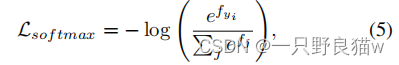
其中fj是类向量f的第j个元素。 在大多数CNN结构中,f通常是完全连接层W的输出。因此fj可以写成fj = WTj xi,其中Wj是W的第j列。为简单起见我们定义第yi类的概率为pyi = efyi Pj efj。 在向后传播的过程中,对fj的梯度可以通过链规则获得。
如果j=yi,则我们有:
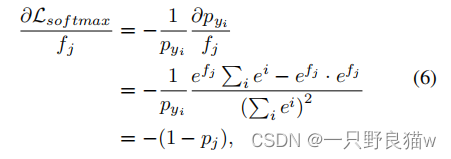
如果j≠yi,则梯度变为:
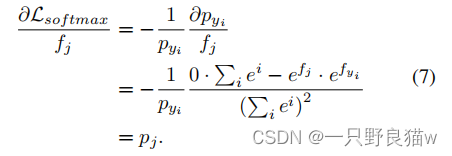
如等式6和等式7所示,在训练步骤中,如果我们将内积视为相似性度量标准,则当特征xi属于yi类时,softmax损失会提高相似性值并发地降低与其他类的相似性。 值得注意的是,具有特征和中心的L2范数的值在训练中是不变的,这意味着欧几里得距离与内积成反比,即
![]()
因此,除了边界参数m之外,我们将拟议的GCRL重新配置为softmax。 对于softmax形式,可以通过大多数深度学习框架轻松实现。 对于边界参数m,仍然无法优化类内部的紧凑性和类间的可分离性。
Center Decorrelation:
?? ??? ?设计了一个新的中心去相关运算,以扩大不同中心之间的距离。考虑方程7和方程6,关于xi的梯度可以通过链法则获得:
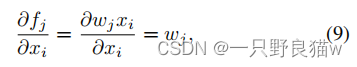
这表明在训练中,特征正朝着中心wj移动,最终指向与wj相同的方向。 因此,边缘量也可以带有以下目标函数的解相关中心来获得
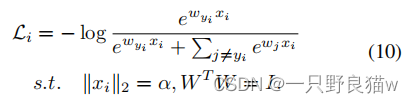
约束WT W = I要求中心彼此正交,这是中心应成对解相关的要求的隐式版本。由于中心w的标准化的值在我们的公式中并不重要,为了进一步简化计算,我们使用带约束WT W = I的拉格朗日乘数,最终DGCRL可以得出:
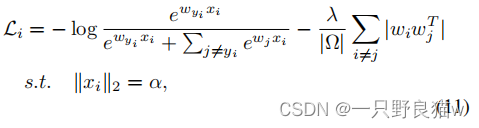
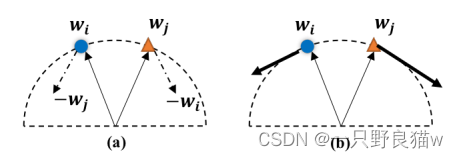
其中,Ω表示不同的成对中心, 对于绝对运算,式(11)要求中心是垂直的,这同时提高了特征的可分辨性(较大的中心距离)和泛化性(较宽的特征表示空间)。 但是,等式11中存在优化问题。 如图2所示,直接将| wiwj |最小化是 无效(梯度将通过功能归一化衰减)并且不稳定(当wiwj接近零时很难最小化)。
Gram-Schmidt Optimization:
在本文中,我们采用Gram-Schmidt过程来解决上述问题。 令{ui|i=1,2,...,n}为m个向量的集合,我们希望获得m-的等价正交集{vi | i = 1,2,...,n} 向量。 可以通过以下连续操作来构造Gram-Schmidt过程(Schmidt 1908):
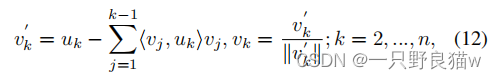
??![]()
使用Gram-Schmidt有两个原因。 一个是该过程可以将原始梯度正交化为具有相应中心的垂直方向,这使优化更加有效,如图2b所示。 另一个是由于<vj uk>操作(第二项变为零)时,当两个中心垂直时,操作是稳定的。 此外,当处理两个向量时,公式12可以轻松实现为:
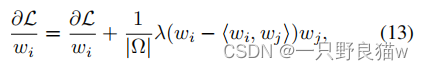
?Lwi的计算与原始softmax相同。 显然,在等式13中,更新是由类间的紧密度?Lwi和类内的分离度(wi-hwi,wj i)wj共同确定的。 这意味着可分辨性和概括性将得到显着增强。整个算法框架如下:

六、实验
1.数据集:CUB-200-2011、CARS196
2.评估协议:Recall @ K
3.实施细节:我们在实验中应用了广泛使用的Resnet-50,解决深层网络梯度消失问题,引入恒等快捷键,直接跳过一个或者多个层。
4.方法对比:Contrastive, Triplet,??PDDM+Quadruplet,liftedStruct:这些方法旨在使用具有不同数量的示例的局部感知度量学习来训练CNN。
?? ??? ??? ?? ? ?Facility Location:引入了一种新的度量学习方法,该方法能够按设备位置学习全局结构。
?? ??? ??? ?? ? ?Histogram Loss,Binomial Deviance:提出评估正对距离和负对距离分布之间的重叠成本,这对异常值具有鲁棒性。
?? ??? ??? ?? ? ?SCDA:使用网络显着性来生成可区分的代表性特征。
? ?? ??? ??? ??? CRL-WSL:将集中排名损失与弱监督的定位方法相结合,仅使用图像级标签获得对象特征。
5.细粒度检索结果:
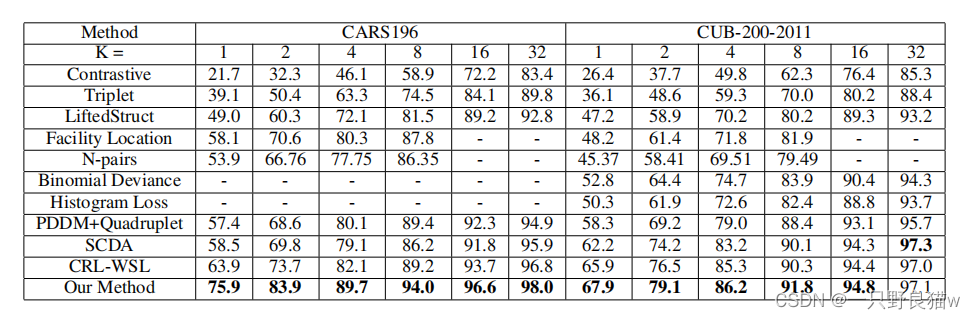
?? ??? ?在CUB200-2011(上)和CARS196(下)上使用t-SNE对我们的方法进行可视化。根据我们的方法,尽管视点,姿势和配置有所不同,具有相似对象的图像也更有可能组合在一起。
6.标度α和因子λ参数研究:
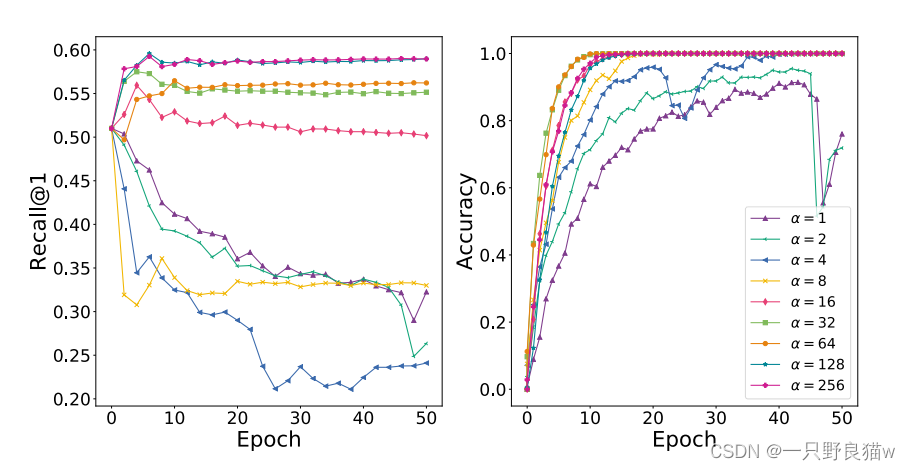
?? ??? ?不同参数α在CUB200-2011中的FGIR性能变化,当α较小时,性能较差;当α大于16时,性能将保持稳定。我们观察到图3中的“退化”问题,即类间的紧密度和类内的分离可以达到容易在训练集中获得,而不是在不相交的测试集中。 实际上,α决定了特征表示空间的大小。 因此,可以通过较高的α来减轻过拟合。 另一方面,当α大于128时,性能是一致的,这主要是由于输入的数值约束(输入图像的范围为[-128,+128])引起的。
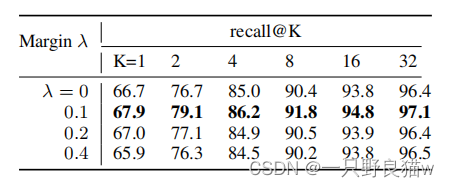
? ? ? ?在CUB-200-2011上以不同λ的Recall@K结果。λ是DGCRL中Gram-Schmidt优化的权重。λ= 0.1是最佳值,我们还观察到,由于太严格的Gram-Schmidt条件,对于较大的λ,结果将减少。
7.不同的损失函数:
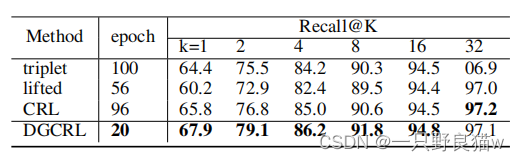
?? ??? ?如表所示,我们的方法在不同的损失函数中是最好的。 请注意,与表1中的相同方法相比,表3中的性能更高,这证明了所提出的N-S层的有效性。 此外,在表3中,我们进一步介绍了针对不同损失功能的训练时期。? CRL,三元组,liftedstruct非常耗时。 相反,我们提出的DGCRL训练阶段只有20个纪元。
七、总结
?? ??? ?在本文中,我们解决了FGIR中的两个关键问题:
(1)局部结构:仅通过小批量使用关系而引起的。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
?(2)慢速训练:涉及到均方误差的使用而引起的。?
?? ??? ?为了解决局部结构问题,我们提出了以全球为中心的全局排名损失,以便以全局方式学习该特征,这可以通过Gram-Schmidt后期去优化来进一步增强。?
?? ??? ?为了解决慢速训练问题,我们提出了一个归一化尺度层,以消除内积和欧氏距离之间的差距,因此,可以通过使用softmax损失来进一步加速损失函数。
?? ??? ?我们在广泛使用的CUB200-2011和CARS196基准测试中获得最佳检索性能。 从数量上讲,它在CARS196中比CRL-WSL(Zheng et al.2018)增长了12.0%,并且在训练中比三重态损失快5倍。