����������
������Ҫ����:�������������,���û���CNN��LeNet��AlexNet��VGGNet��InceptionNet��ResNetʵ��ͼ��ʶ��
1��ȫ��������ع�
ȫ����NN�ص�:ÿ����Ԫ��ǰ�����ڲ��ÿһ����Ԫ�������ӹ�ϵ��(����ʵ�ַ����Ԥ��)
ȫ��������IJ�������:��(ǰ�� ? ��� + ���)
��ͼ5-1��ʾ,���һ�ŷֱ��ʽ�Ϊ28 * 28�ĺڰ�ͼ��(����ֵ����Ϊ28 * 28 * 1 = 784),ȫ��������IJ����������н���40�����
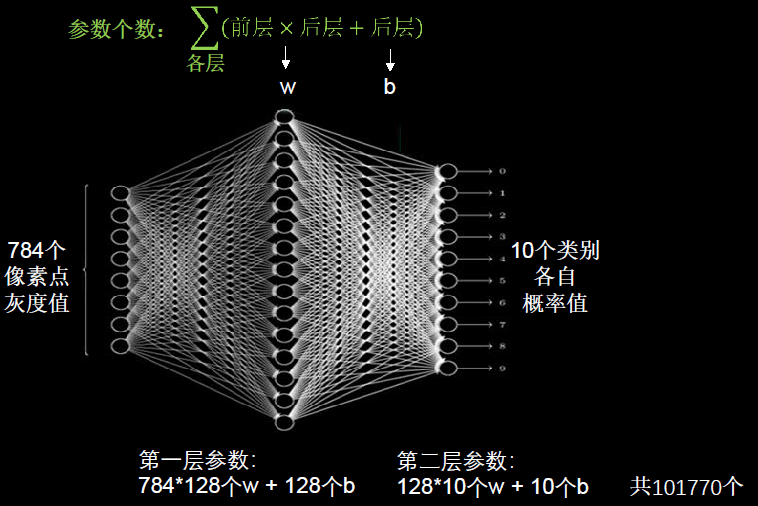
��ʵ��Ӧ����,ͼ��ķֱ���Զ���ڴ�,�Ҵ�����Dz�ɫͼ��,��ͼ5-2��ʾ����Ȼȫ��������һ�㱻��Ϊ�Ƿ���Ԥ����������,�����Ż��IJ�������,������ģ����ϡ�

Ϊ�˽�����������������ģ����ϵ�����,һ�㲻�Ὣԭʼͼ��ֱ������,�����ȶ�ͼ�����������ȡ,�ٽ���ȡ�õ�����������ȫ��������,��ͼ5-3��ʾ,���ǽ�����ͼƬ�������������ȡ����ι��ȫ�������硣

2������������
2.1 �����ĸ���
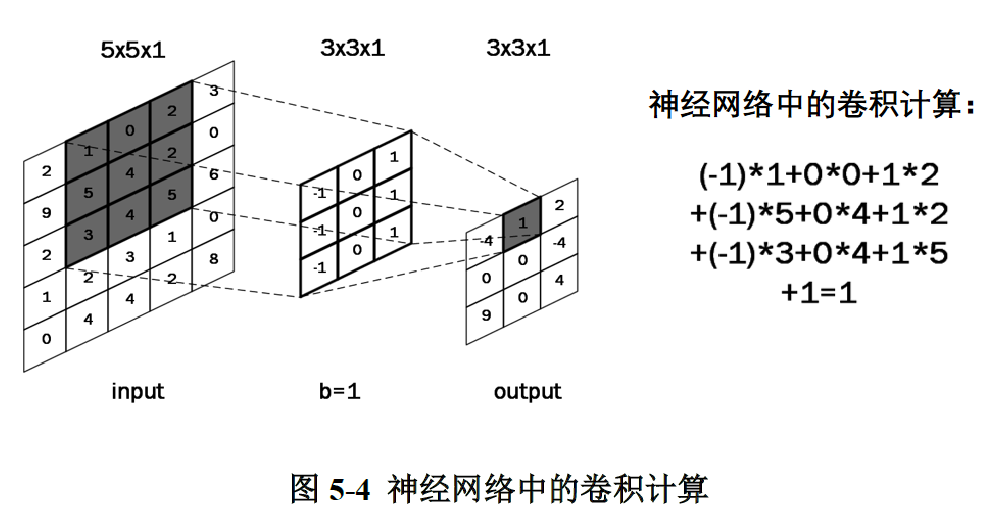
����(Convolutional)������Ϊ��һ����Ч����ȡͼ�������ķ�����һ�����һ�������εľ�����,��ָ������,����������ͼ�ϻ���,������������ͼ�е�ÿ�����ص㡣ÿһ������,�����˻�����������ͼ�����غ�����,�غ������ӦԪ����ˡ�����ټ���ƫ����õ����������һ�����ص�,��ͼ5-4��ʾ,���ô�СΪ3��3��1�ľ����˶�5��5��1�ĵ�ͨ��ͼ������������õ���Ӧ�����
2.2 ��ͨ���;�����
������ɫͼ��ͨ��(channel),������ͨ����(���)����������һ��,�Ӻ��ڶ�Ӧλ���Ͻ��г˼ӺͲ�������ͼ5-5��ʾ,������ͨ�������˶���ͨ���IJ�ɫ����ͼ����������
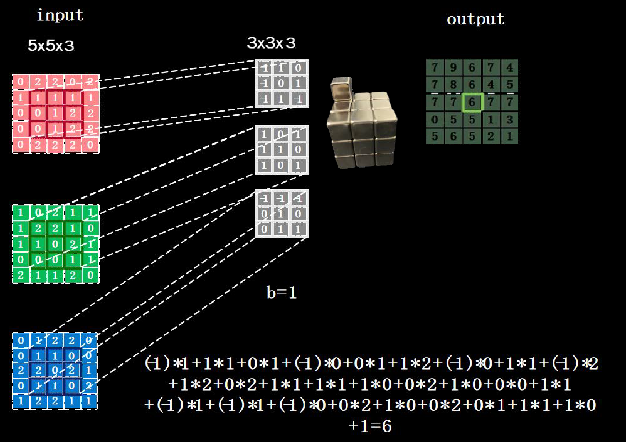
- ����������˿�ʵ�ֶ�ͬһ��������������Ķ��������ȡ,�����˵ĸ�������������ͨ����,���������ͼ(feature map)�����
2.3����Ұ (Receptive Field)
����Ұ (Receptive Field)�ĸ���:����������������ÿ�����ص���ԭʼͼ���ϵ�ӳ�������С,��ͼ5-7��ʾ:
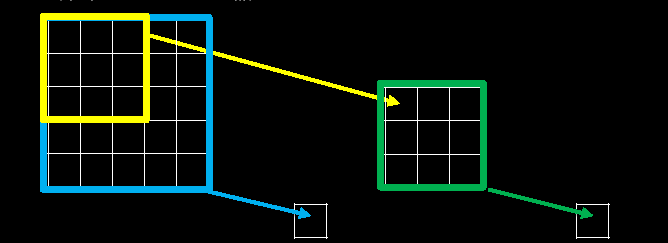 �����Dz��óߴ粻ͬ�ľ�����ʱ,����������Ǹ���Ұ�Ĵ�С��ͬ,���Ծ�������ö��С���������滻һ��������,�ڱ��ָ���Ұ��ͬ������¼��ٲ������ͼ�����,����ʮ�ֳ�������2��3 * 3���������滻1��5 * 5�����˵ķ���,��ͼ5-7��ʾ��
�����Dz��óߴ粻ͬ�ľ�����ʱ,����������Ǹ���Ұ�Ĵ�С��ͬ,���Ծ�������ö��С���������滻һ��������,�ڱ��ָ���Ұ��ͬ������¼��ٲ������ͼ�����,����ʮ�ֳ�������2��3 * 3���������滻1��5 * 5�����˵ķ���,��ͼ5-7��ʾ��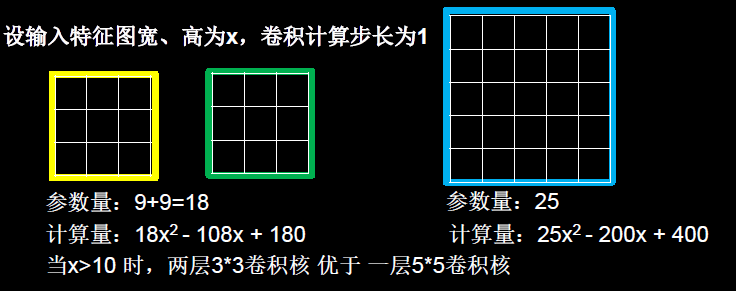
���������ϸ�Ƶ�:��������������ͼ�Ŀ����߾�Ϊx,��������IJ���Ϊ1,��Ȼ,����3 * 3�����˵IJ�����Ϊ9 + 9 = 18,С��5 * 5�����˵�25,ǰ�ߵIJ��������١�
�ڼ�������,����ͼ5-8��ʾ����������ߴ���㹫ʽ,����5 * 5��������˵,�������ͼ����(x �C 5 + 1)^2�����ص�,ÿ�����ص���Ҫ����5 * 5 = 25�γ˼�����,���ܼ�����Ϊ25 * (x �C 5 + 1)^2 = 25x^2 �C 200x + 400;
��������3 * 3��������˵,��һ��3 * 3�������������ͼ����(x �C 3 + 1)^2�����ص�,ÿ�����ص���Ҫ����3 * 3 = 9�γ˼�����,,�ڶ���3 * 3�������������ͼ����(x �C 3 + 1 �C 3 + 1)^2�����ص�,ÿ�����ص�ͬ����Ҫ����9�γ˼�����,���ܼ�����Ϊ9 * (x �C 3 + 1)^2 + 9 * (x �C 3 + 1 �C 3 + 1)^2 = 18 x^2 �C 108x + 180;
�Զ��ߵ��ܼ�����(�˼�����Ĵ���)���жԱ�,18 x^2 �C 200x + 400 < 25x^2 �C 200x + 400,��������ѧ����ɵ�x < 22/7 or x > 10,x��Ϊ����ͼ�ı߳�,�ڴ�����������Ȼ����һ������10��ֵ(�dz���MNIST���ݼ��ijߴ�Ҳ�ﵽ��28 * 28),��������3 * 3�����˵IJ������ͼ�����,��ͨ������¶�����һ��5 * 5������,�����ǵ�����ͼ�ߴ�Ƚϴ�������,����3 * 3�������ڼ������ϵ����ƻ�������ԡ�
2.4 �������ͼ(feature map)
��������ߴ����:���˽��������о���������������̺�,�Ϳ��Զ��������ͼ�ijߴ���м���,��ͼ5-8��ʾ,5��5��ͼ��3��3��С�ľ������������������������ߴ�Ϊ3��3��

2.5 ȫ�����(padding)
ȫ�����(padding):Ϊ�˱������ͼ��ߴ�������ͼ��һ��,������������ͼ����Χ����ȫ�����,��ͼ5-9��ʾ,��5��5������ͼ����Χ��0,����������ߴ�ͬΪ5��5��
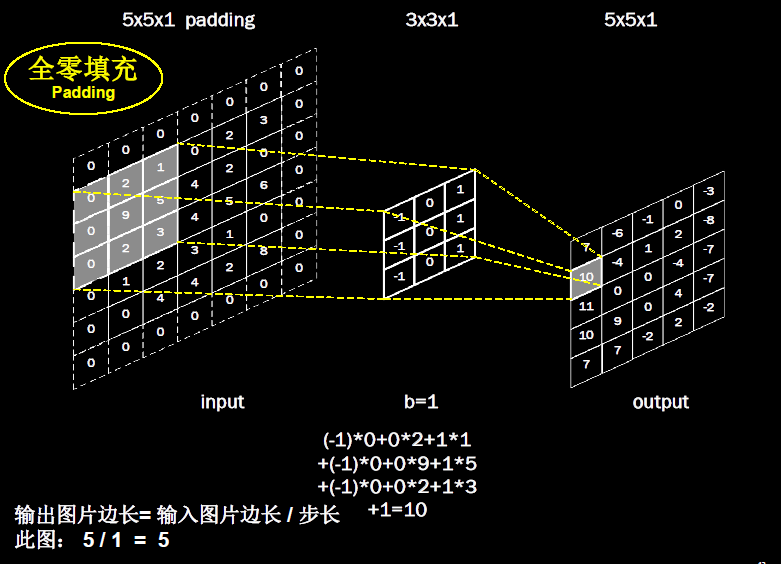
��Tensorflow�����,�ò���padding = ��SAME����padding = ��VALID����ʾ�Ƿ����ȫ�����,�����������ߴ��С��Ӱ������:

�������зֱ����������ͼ�����ȫ�����������,����5��5��1��ͼ����˵,��padding = ��SAME��ʱ,���ͼ��߳�Ϊ5;��padding = ��VALID��ʱ,���ͼ��߳�Ϊ3��
�߱�����֪ʶ��,�Ϳ�����Tensorflow���������Keras������CNN�еľ�����,ʹ�õ���tf.keras.layers.Conv2D����,�����ʹ�÷�������:
tf.keras.layers.Conv2D(
input_shape = (��, ��, ͨ����), #���ڵ�һ����
filters = �����˸���,
kernel_size = �����˳ߴ�,
strides = ��������,
padding = ��SAME�� or ��VALID��,
activation = ��relu�� or ��sigmoid�� or ��tanh�� or ��softmax����#����BN��˴�����д
)
ʹ�ô˺�������������ʱ,��Ҫ��������Ϣ��:
A)����ͼ�����Ϣ,�����ߺ�ͨ����;
B)�����˵ĸ����Լ��ߴ�,��filters = 16, kernel_size = (3, 3)��������16����СΪ3��3�ľ�����;
C)��������,��������������ͼ���ϻ����IJ���,���������ͨ������ͬ��,Ĭ��ֵΪ1;
D)�Ƿ����ȫ�����,ȫ�����ľ�����������������;
E)�������ּ����,����relu��softmax��,���ֺ����ľ���Ч����ǰ���½�������ϸ����
������Ҫע�����,������Tensorflow��ܹ�����������ʱ,һ�������BatchNormalization����������BN��,��������һ������,������Conv2D�����о�����дBN��BN�����ľ��庬������ü����ġ�
2.6 Batch Normalization(������)
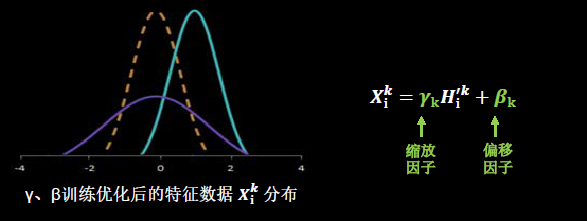
Batch Normalization(������):��һС�����������������������������,�����ʵ�ַ�ʽ��ͼ5-10��ʾ��( ����:ʹ���ݷ���0��ֵ,1Ϊ����ķֲ�;������:��һС������(batch),������������)
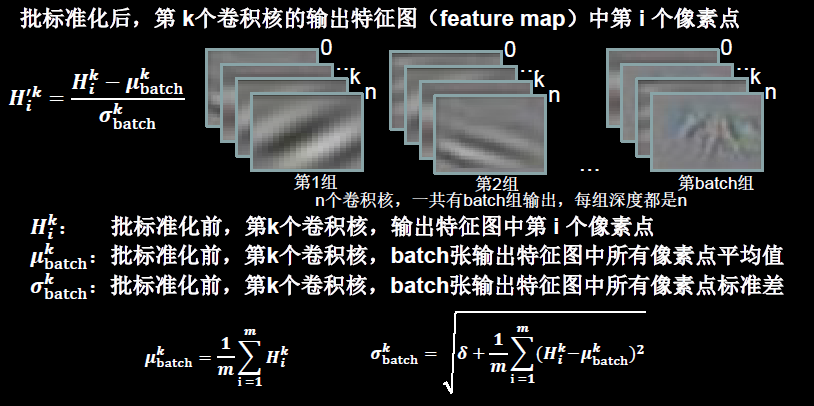
Batch Normalization��������ÿ������붼��������ֵΪ0,����Ϊ1�ı���̬�ֲ�,��Ŀ���ǽ�����������ݶ���ʧ������,��ͼ5-11��ʾ��
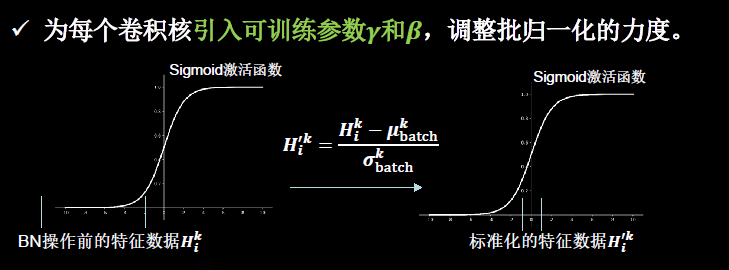
BN��������һ����Ҫ���������ź�ƫ��,ֵ��ע�����,�������Ӧ��Լ�ƫ�����Ӧ¶��ǿ�ѵ������,��������ͼ5-12��ʾ��
BN����ͨ��λ�ھ�����֮��,�����֮ǰ,��Tensorflow�����,ͨ��ʹ��Keras��
�� tf.keras.layers.BatchNormalization����������BN�㡣
�ڵ��ô˺���ʱ,��Ҫע���һ��������training,�˲���ֻ�ڵ���ʱָ��,��ģ�ͽ���ǰ������ʱ��������,��training = Trueʱ,BN�������õ�ǰbatch�ľ�ֵ�ͱ���;��training = Falseʱ,BN�������û���ƽ��(running)�ľ�ֵ�ͱ����Tensorflow��,ͨ����ָ��training = False,���Ը��õط�ӳģ���ڲ��Լ��ϵ���ʵЧ����
����ƽ��(running)�Ľ���:����ƽ��,��ͨ��һ����batch��ʷ�ĵ���,�����������ݼ�����ֲ��Ĺ���,�ڲ��Լ��Ͻ�������ʱ,����ƽ���IJ���Ҳ�������ձ���IJ���������,Tensorflow�е�BN������ʵ���кܶ����,���бȽϳ��õ���momentum,����������,��sgd�Ż����еĶ��������������Ƶ���������,��������Ϊ����ƽ��running = momentum * running + (1 �C momentum) * batch,һ������һ���Ƚϴ��ֵ,��Tensorflow�����Ĭ��Ϊ0.99��

2.7 �ػ�(pooling)
�ػ�(pooling):�ػ��������Ǽ�����������(��ά)�����ֵ�ػ�����ȡͼƬ����,��ֵ�ػ��ɱ�����������,��ͼ5-13��ʾ

��Tensorflow�����,��������Keras�������ػ���,ʹ�õ���tf.keras.layers.MaxPool2D������tf.keras.layers.AveragePooling2D����,�����ʹ�÷�������:
tf.keras.layers.MaxPool2D(
pool_size=�ػ��˳ߴ�,#������д�˳�����,��(�˸�h,�˿�w)
strides=�ػ�����,#��������,��(����h,����w),Ĭ��Ϊpool_size
padding=��valid��or��same��#ʹ��ȫ������ǡ�same��,��ʹ���ǡ�valid��(Ĭ��)
)
tf.keras.layers.AveragePooling2D(
pool_size=�ػ��˳ߴ�,#������д�˳�����,��(�˸�h,�˿�w)
strides=�ػ�����,#��������,��(����h,����w),Ĭ��Ϊpool_size
padding=��valid��or��same��#ʹ��ȫ������ǡ�same��,��ʹ���ǡ�valid��(Ĭ��)
)
model = tf.keras.models.Sequential([
Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # ������
BatchNormalization(), # BN��Activation('relu'), # �����
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # �ػ���
Dropout(0.2), # dropout��
])
2.8 ����(Dropout)
����(Dropout):���������ѵ��������,��һ������Ԫ����һ�����ʴ�����������ʱ����,ʹ��ʱ����������Ԫ�ָ�����,��ͼ5-14��ʾ��
��Tensorflow�����,����tf.keras.layers.Dropout��������Dropout��,����Ϊ�����ĸ���(����0С��1)��
��������֪ʶ,�Ϳ��Թ����������ľ���������(CNN)��,�����˼·Ϊ��CNN�����þ�����(kernel)��ȡ������,����ȫ�������硣
2.9 CNNģ�͵���Ҫģ��
CNNģ�͵���Ҫģ��:һ����������ľ����㡢BN�㡢��������ػ����Լ�ȫ���Ӳ�,��ͼ5-15��ʾ

�ڴ˻�����,�����ܽ����Tensorflow�����,����Keras���������ġ��˹ɡ���·,�����ɵĻ�����,������������������,������������Ĺ���,�������Լ���ͼƬ�ͱ�ǩ�ļ����������ݼ�;ͨ����ת�����š�ƽ�ƵȲ��������ݼ�����������ǿ;����ģ���ļ����жϵ���ѵ;��ȡѵ����õ���ģ�Ͳ����Լ�ȷ������,ʵ�ֿ��ӻ��ȡ�
����������ġ��˹ɡ���·:
A)import����tensorflow��keras��numpy������ģ�顣
B)��ȡ���ݼ�,�γ��������õ�MNIST��cifar10�����ݼ��Ƚϻ���,����ֱ�Ӵ�sklearn��ģ��������,������ʵ��Ӧ����,�����Ҫ��ͼƬ�ͱ�ǩ�ļ��ж�ȡ��������ݼ���
C)����������ṹ,������ṹ�Ƚϼ�ʱ,��������kerasģ���е�tf.keras.Sequential���˳������ģ��;���ǵ����粻���Ǽ�˳��ṹ,��������������ṹ����ʱ(����ResNet�е������ṹ),����Ҫ����class�������Լ�������ṹ��ǰ��ʹ���������ӷ���,��ʵ��Ӧ����������Ҫ���ú���������硣
D)�Դ�õ�������б���(compile),ͨ������һ��ָ�������õ��Ż���(��Adam��sgd��RMSdrop��)�Լ���ʧ����(�罻���غ��������������),ѡ�������Ż�������ʧ����������ѵ�����ٶȺ�Ч���кܴ��Ӱ��,���ھ�����ν���ѡ��,ǰ����½����бȽ���ϸ�Ľ��ܡ�
E)�������������õ�����������ѵ��(model.fit),����һ����ָ��ѵ������epochs�Լ�batch_size����Ϣ,����������IJ������ͼ�����һ�㶼�Ƚϴ�,ѵ�������ʱ��Ҳ��Ƚϳ�,��������Ӳ���������������,��������һ����ͨ�������ϵ���ѵ�Լ�ģ�Ͳ�������ȹ���,ʹѵ�����ӷ���,ͬʱ��ֹ��������ֹͣ�������ݶ�ʧ�����������
F)��������ģ�͵ľ�����Ϣ��ӡ����(model.summary),��������ṹ���������IJ�����,���ڶ������������ͼ�顣
2.10 cifar10 ���ݼ�����
cifar10 ���ݼ�����:
�����ݼ����� 60000 �Ų�ɫͼ��,ÿ�ųߴ�Ϊ 32 * 32,��Ϊ 10 ��,ÿ�� 6000 �š�
ѵ���� 50000 ��,��Ϊ 5 ��ѵ����,ÿ�� 10000 ��;
��ÿһ�����ȡ 1000 �Ź��ɲ��Լ�,�� 10000 ��,ʣ�µ�����������ѵ����,��ͼ 5-16 ��ʾ

cifar10 ���ݼ��Ķ�ȡ:
�� ���ݼ�����:
cifar10 = tf.keras.datasets.cifar10
�� ����ѵ�����Ͳ��Լ�:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
�� ��ӡѵ��������Լ�������ά��, ��ӡ���Ϊ:
��Ȼ, cifar10 ��һ������ͼ���������ݼ�,���� 10 ��,����� mnist ���ݼ������
��һЩ,ѵ���Ѷ�Ҳ����,����ͼ��ߴ��С,��Ϊ 32 * 32,��Ȼ���ڱȽϻ��������ݼ�,����һЩ CNN ��������ṹ(�� VGGNet�� ResNet ��,��һС�ڻ�������)����ѵ���Ļ�ȷ�ʺ������ܳ��� 90%,���ʺϳ�ѧ��������ϰ��Ŀǰѧ������� cifar10 ���ݼ��ķ���ȷ���Ѿ��ﵽ���൱�ߵ�ˮ,ͼ 5-17 ��Ϊ Github ��վ�� cifar10 ���ݼ�����ȷ�ʵ����а�
�ο���ַ: http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# ���ӻ�ѵ�������������ĵ�һ��Ԫ��
plt.imshow(x_train[0]) # ����ͼƬ
plt.show()
# ��ӡ��ѵ�������������ĵ�һ��Ԫ��
print("x_train[0]:\n", x_train[0])
# ��ӡ��ѵ������ǩ�ĵ�һ��Ԫ��
print("y_train[0]:\n", y_train[0])
# ��ӡ������ѵ��������������״
print("x_train.shape:\n", x_train.shape)
# ��ӡ������ѵ������ǩ����״
print("y_train.shape:\n", y_train.shape)
# ��ӡ���������Լ�������������״
print("x_test.shape:\n", x_test.shape)
# ��ӡ���������Լ���ǩ����״
print("y_test.shape:\n", y_test.shape)
x_train.shape:
(50000, 32, 32, 3)
y_train.shape:
(50000, 1)
x_test.shape:
(10000, 32, 32, 3)
y_test.shape:
(10000, 1)
2.11 ������ʾ��
���������� tf.keras ���������İ˹�֮��,�Ϳ��Դ�Լ�����������������
������ѵ����,�����ṩһ��ʵ��,����һ���ṹ�Ļ�������������(CNN)����cifar10 ���ݼ�����ѵ��,����ṹ��ͼ 5-18 ��ʾ��

���� tf.keras.Sequentialģ���Լ� class �������ַ�ʽ�����Թ�����ͼ 5-18 �еĻ��� CNN����,�ڴ����ж��ߵ�Ч������ȫ��ͬ��,ǰ�߿�����������һЩ,��������ʵ��Ӧ���и��ӳ���,��Ϊ�������һ���dz�����������,��һЩ���ӵ����羭������ Sequential ģ��������Ľṹ�����,������������ú���,��ͼ 5-19 ��ʾ��
3 CNN��������
�ھ���������ķ�չ������,���ֹ����ྭ�������ṹ,��ЩCNN��������������������شٽ�������ķ�չ,�����5�������CNN����ṹ��һ������,��1998����Yann LeCun�����LeNetֱ��2015���ɺ����������ResNet,��ͼ5-20��ʾ��
ֵ��һ�����,���˾�������ġ���ƪ֮����LeNet����,AlexNet��VGGNet��InceptionNet�Լ�ResNet�����־�������ȫ�����ڵ����ImageNet������������,������Ϊ���ѧϰ�ľ������,ʹ��ImageNet���ݼ��ϵĴ��������꽵�͡����潫��������־���������һ���н���:

��:CNN�����������ij���
LeNet-5:
Yann Lecun, Leon Bottou, Y. Bengio, Patrick Haffner. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 1998.
AlexNet:
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. In NIPS, 2012.
VGG16:
K. Simonyan, A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.In ICLR, 2015.
Inception-v1:
Szegedy C, Liu W, Jia Y, et al. Going Deeper with Convolutions. In CVPR, 2015.
ResNet:
Kaiming He, Xiangyu Zhang, Shaoqing Ren. Deep Residual Learning for Image Recognition. In CPVR, 2016.
3.1 LeNet
ģ��ʵ�ִ���:p31_cifar10_lenet5.py
�����:����������,�������������
LeNet��LeNet5,��Yann LeCun��1998�����,��Ϊ����ľ���������֮һ,������������ܹ������,������ṹ��ͼ5-21��ʾ��
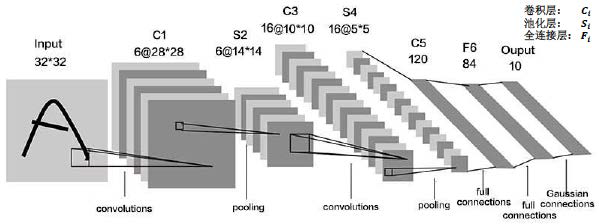
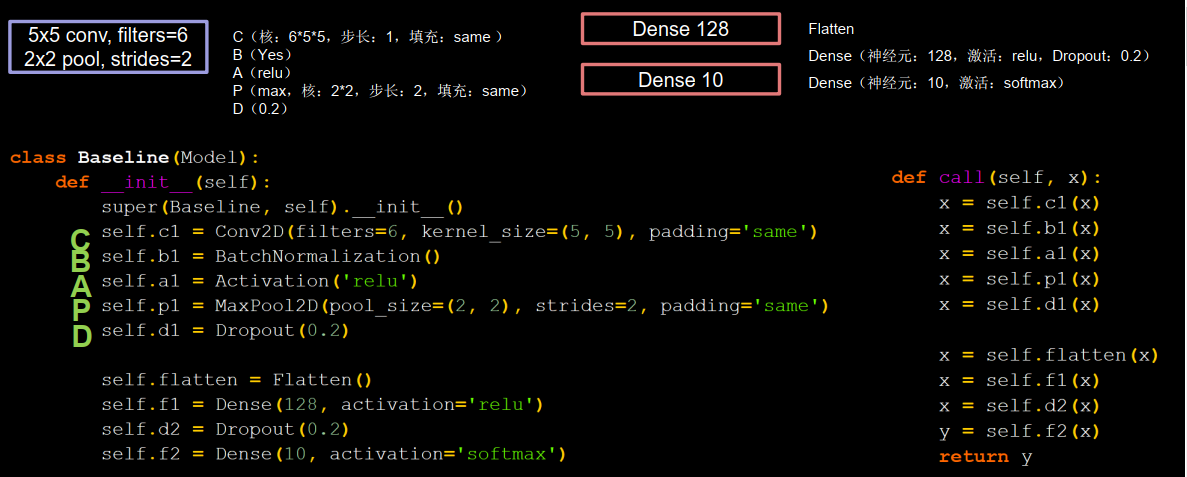
����������Ϣ,�Ϳ��Ը�����һ�����ܽ�����ķ���,��Tensorflow���������tf.Keras������LeNet5ģ��,��ͼ5-22��ʾ��
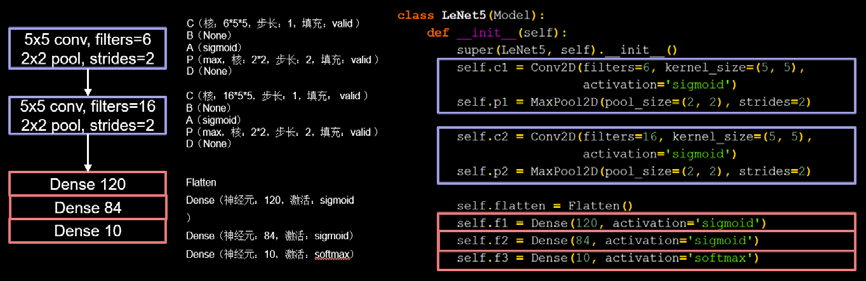
ͼ����ɫ����Ϊ������,��ɫ����Ϊȫ���Ӳ�,ģ��ͼ�����һһ��Ӧ,ģ�ʹ������������(�������ʵ�ֺ�����5.2���о��н���):
A)����ͼ���СΪ32 * 32 * 3,��ͨ����ɫͼ������;
B)���о���,�����˴�СΪ5 * 5,����Ϊ6,����Ϊ1,������ȫ�����;
C)�������������sigmoid�����(�����Ժ���)���м���;
D)�������ػ�,�ػ��˴�СΪ2 * 2,����Ϊ2;

E)���о���,�����˴�СΪ5 * 5,����Ϊ16,����Ϊ1,������ȫ�����;
F)�������������sigmoid����������;
G)�������ػ�,�ػ��˴�СΪ2 * 2,����Ϊ2;

H)��������ȫ�����������10���ࡣ

�������LeNet5����ṹ���,��������һ����,����ͼ��ߴ�Ϊ32 * 32 * 3,����Ӧcifar10���ݼ�(�����ݼ���5.2����Ҳ�о������)��ģ���в��õļ������sigmoid��softmax,�ػ�����������ػ�,�Ա�����Ե������
�����Ͽ�,������1998���LeNet5�����һЩ������CNN�������,��ṹ����˵���൱��,�������ɹ������á�������ȡ������ȫ���ӷ��ࡱ�ľ���˼·�������д����ʶ�������,���������о��ķ�չ���ź���Ҫ�����塣
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5),
activation='sigmoid')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.f1 = Dense(120, activation='sigmoid')
self.f2 = Dense(84, activation='sigmoid')
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
model = LeNet5()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/LeNet5.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# ��ʾѵ��������֤����acc��loss����
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
3.2 AlexNet
ģ��ʵ�ִ���:p34_cifar10_alexnet8.py
�����:�����ʹ��Relu,����ѵ���ٶ�;Dropout��ֹ����ϡ�
AlexNet���絮����2012��,��ImageNet Top5������Ϊ16.4 %,����˵AlexNet�ij���ʹ���Ѿ����Ŷ�������ѧϰ�������˻ƽ�ʱ����
AlexNet������ṹ��LeNet5������֮��,������һЩ����Ҫ�ĸĽ�:
A) ��������������ȫ�������,����ߴ�Ϊ2242243,�����ģԶ����LeNet5
B) ������Relu�����
C)������Dropout����,�Է�ֹģ�����,����³����
D)������һЩѵ���ϵļ���,����������ǿ��ѧϰ��˥����Ȩ��˥��(L2����)
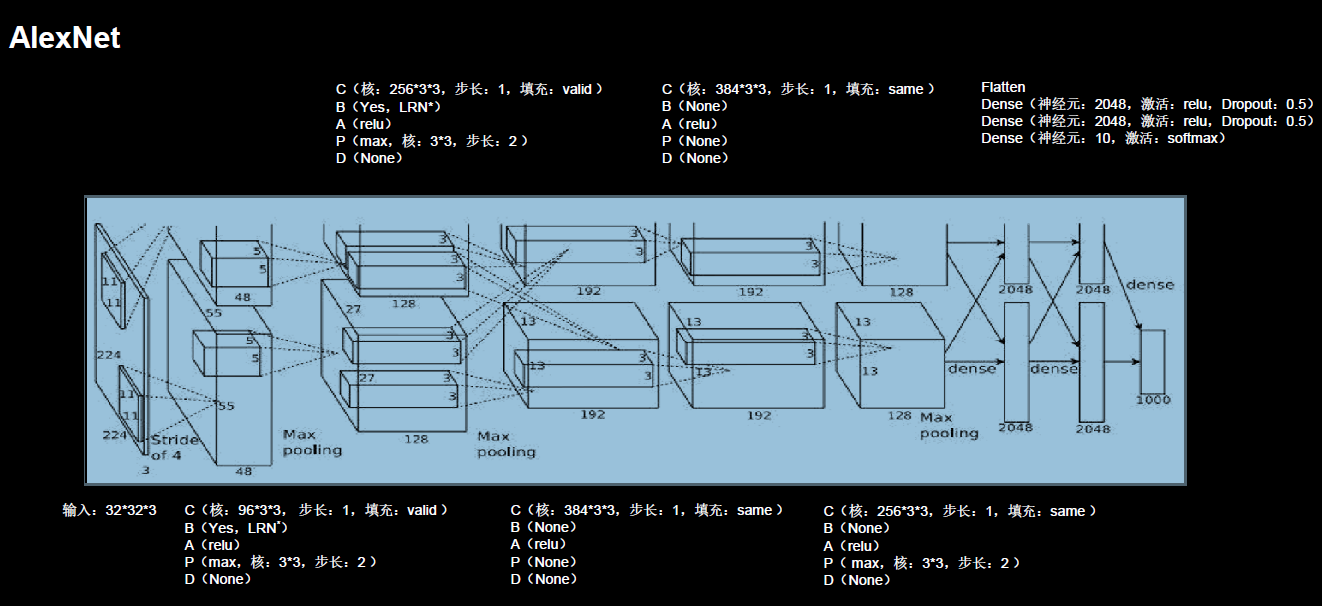
���Կ���,ͼ5-20��ʾ������ṹ��ģ�ͷֳ���������,�������ڵ�ʱ����ѵ��AlexNet���Կ�ΪGTX 580(�Դ�Ϊ3GB),�����Կ�������Դ�����ԭ��
��Tensorflow���������Keras���AlexNetģ��,��������һЩ����,������ͼ��ߴ��Ϊ32 * 32 * 3����Ӧcifar10���ݼ�,���ҽ�ԭʼ��AlexNetģ���е�11 * 11��7 * 7��5 * 5�ȴ�ߴ�����˾��滻����3 * 3��С������,��ͼ��ʾ��
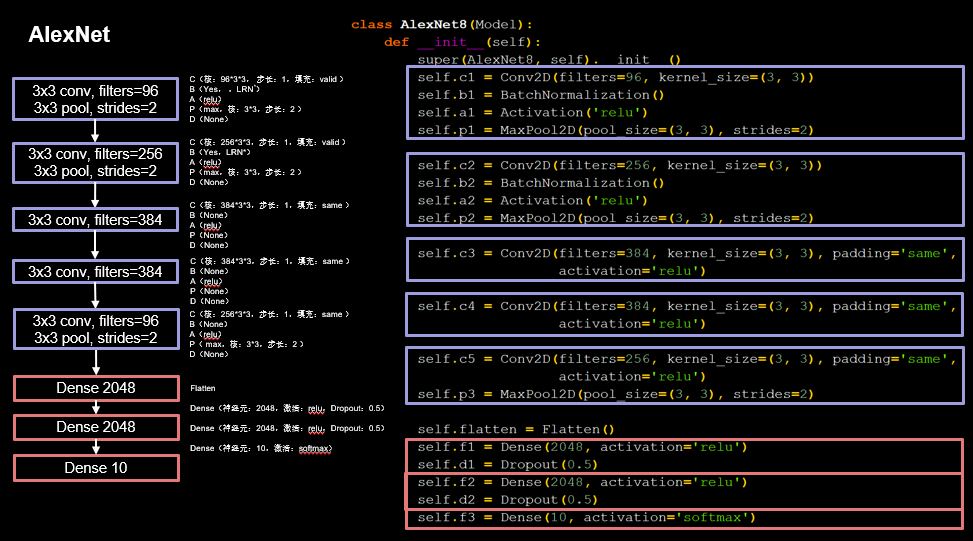
ͼ����ɫ�������������,���Կ�������������������5��:
A)��1�ξ���:����96��3 * 3�ľ�����,������ȫ�����,����BN����,�����ΪRelu,�������ػ�,�ػ��˳ߴ�Ϊ3 * 3,����Ϊ2

B)��2�ξ���:���1�ξ�������,�������˸�����96���ӵ�256֮�⼸����ͬ;

C)��3�ξ���:����384��3 * 3�ľ�����,����ȫ�����,�����ΪRelu,������BN�����Լ����ػ�;
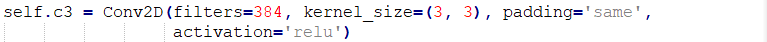
D)��4�ξ���:���3�ξ���������ȫ��ͬ;

E)��5�ξ���:����96��3 * 3�ľ�����,����ȫ�����,�����ΪRelu,������BN����,�������ػ�,�ػ��˳ߴ�Ϊ3 * 3,����Ϊ2��

ͼ�к�ɫ�����ȫ���Ӳ���,��������:
A)��һ�㹲2048����Ԫ,�����ΪRelu,����0.5��dropout;

B)�ڶ������һ�㼸����ȫ��ͬ;

C)�����㹲10����Ԫ,����10���ࡣ
���Կ���,��ṹ���Ƶ�LeNet5���,AlexNetģ�͵IJ��������˷dz����Ե�����,��������IJ���Ҳ������,�������ڸ��õ���ȡ����;Relu�������ʹ�üӿ���ģ�͵�ѵ���ٶ�;Dropout��ʹ��������ģ�͵�³����,��Щ����ʹ��AlexNet�����ܴ��������
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/AlexNet8.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# ��ʾѵ��������֤����acc��loss����
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
This message will be only logged once.
1563/1563 [] - 81s 34ms/step - loss: 1.8704 - sparse_categorical_accuracy: 0.3089 - val_loss: 1.5785 - val_sparse_categorical_accuracy: 0.4525
Epoch 2/5
1563/1563 [] - 19s 12ms/step - loss: 1.3179 - sparse_categorical_accuracy: 0.5318 - val_loss: 1.2620 - val_sparse_categorical_accuracy: 0.5439
Epoch 3/5
1563/1563 [] - 19s 12ms/step - loss: 1.1636 - sparse_categorical_accuracy: 0.5988 - val_loss: 1.1881 - val_sparse_categorical_accuracy: 0.5826
Epoch 4/5
1563/1563 [] - 20s 13ms/step - loss: 1.0627 - sparse_categorical_accuracy: 0.6309 - val_loss: 1.1078 - val_sparse_categorical_accuracy: 0.6114
Epoch 5/5
1563/1563 [==============================] - 20s 13ms/step - loss: 0.9856 - sparse_categorical_accuracy: 0.6625 - val_loss: 1.0130 - val_sparse_categorical_accuracy: 0.6519
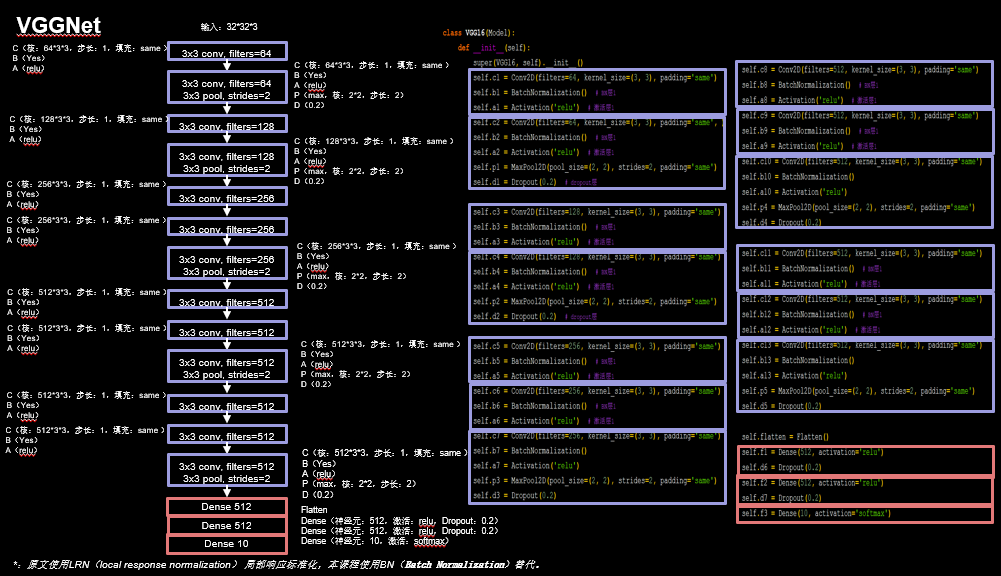
3.3 VGGNet
ģ��ʵ�ִ���:p36_cifar10_vgg16.py
�����:С�����˼��ٲ�����ͬʱ,���ʶ��ȷ��;����ṹ����,�ʺϲ��м��١�
��AlexNet֮��,��һ�����������ϴ�������ǵ�����2014���VGGNet,��ImageNet Top5�����ʼ�С����7.3 %��
VGGNet��������Ľ���������������,��AlexNet��8�����ӵ���16���19��,�����������ζ�Ÿ�ǿ�ı�������,�������ǿ�����������֧�֡�VGGNet����һ�������ص��ǽ�ʹ���˵�һ�ߴ��3 * 3������,��ʵ��,3 * 3��С�������ںܶ���������ж�������ʹ��,���������ڸ���Ұ��ͬ�������,С�����˶ѻ���Ч��Ҫ���ڴ������,ͬʱ������Ҳ���١�VGGNet��ʹ����3 * 3�ľ����������AlexNet�еĴ������(11 * 11��7 * 7��5 * 5),ȡ���˽Ϻõ�Ч��(��ʵ�Ͽγ�������Kerasʵ��AlexNetʱ�Ѿ���ȡ�����ַ�ʽ),VGGNet16������ṹ��ͼ5-25��ʾ��
VGGNet16��VGGNet19��û�б����ϵ�����,ֻ��������Ȳ�ͬ,ǰ��16��(13�������3��ȫ����),����19��(16�������3��ȫ����)��
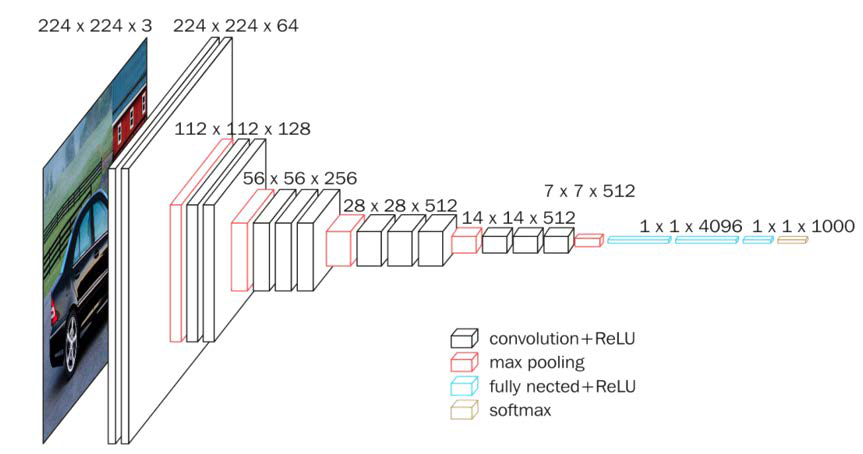
��Tensorflow���������Keras��ʵ��VGG16����,Ϊ��Ӧcifar10���ݼ�,������ͼ��ߴ���224 * 244 * 3����Ϊ32 * 32 * 3,��ͼ5-26��ʾ��
��������ͼ�ߴ�ı仯,���Խ�VGG16ģ�ͷ�Ϊ��������(��VGG16��,ÿ����һ�γػ�����,����ͼ�ı߳���СΪ1/2,���������δӰ������ͼ�ߴ�):
A)��һ����:���ξ���(64��3 * 3�����ˡ�BN��Relu����)�����ػ���Dropout

B)�ڶ�����:���ξ���(128��3 * 3�����ˡ�BN��Relu����)�����ػ���Dropout

C)��������:���ξ���(256��3 * 3�����ˡ�BN��Relu����)�����ػ���Dropout

D)���IJ���:���ξ���(512��3 * 3�����ˡ�BN��Relu����)�����ػ���Dropout

E)���岿��:���ξ���(512��3 * 3�����ˡ�BN��Relu����)�����ػ���Dropout

F)��������:ȫ����(512����Ԫ)��Dropout��ȫ����(512����Ԫ)��Dropout��ȫ����(10����Ԫ)

��������,VGGNet�Ľṹ���൱������,���̳���AlexNet�е�Relu�������Dropout��������Ч�ķ���,ͬʱ�����˵�һ�ߴ��3 * 3С������,�γ��˹�����C(Convolution,����)��B(Batch normalization)��A(Activation,����)��P(Pooling,�ػ�)��D(Dropout)�ṹ,��һ���ͽṹ�ھ����������е�Ӧ���Ƿdz���ġ�
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class VGG16(Model):
def __init__(self):
super().__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3,3), padding='same')
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters=64, kernel_size=(3,3), padding='same')
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(2,2), strides=2, padding='same')
self.d2 = Dropout(0.2)
self.c3 = Conv2D(filters=128, kernel_size=(3,3), padding='same')
self.b3 = BatchNormalization()
self.a3 = Activation('relu')
self.c4 = Conv2D(filters= 128, kernel_size=(3,3), padding='same')
self.b4 = BatchNormalization()
self.a4 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2,2), strides=2, padding='same')
self.d4 = Dropout(0.2)
self.c5 = Conv2D(filters=256, kernel_size=(3,3), padding='same')
self.b5 = BatchNormalization()
self.a5 = Activation('relu')
self.c6 = Conv2D(filters=256, kernel_size=(3,3), padding='same')
self.b6 = BatchNormalization()
self.a6 = Activation('relu')
self.c7 = Conv2D(filters=256, kernel_size=(3,3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p7 = MaxPool2D(pool_size=(2,2), strides=2, padding='same')
self.d7 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b8 = BatchNormalization()
self.a8 = Activation('relu')
self.c9 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b9 = BatchNormalization()
self.a9 = Activation('relu')
self.c10 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p10 = MaxPool2D(pool_size=(2,2), strides=2, padding='same')
self.d10 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b11 = BatchNormalization()
self.a11 = Activation('relu')
self.c12 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b12 = BatchNormalization()
self.a12 = Activation('relu')
self.c13 = Conv2D(filters=512, kernel_size=(3,3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p13 = MaxPool2D(pool_size=(2,2), strides=2, padding='same')
self.d13 = Dropout(0.2)
self.flatten = Flatten()
self.f14 = Dense(512, activation='relu')
self.d14 = Dropout(0.2)
self.f15 = Dense(512, activation='relu')
self.d15 = Dropout(0.2)
self.f16 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.d2(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p4(x)
x = self.d4(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p7(x)
x = self.d7(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p10(x)
x = self.d10(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p13(x)
x = self.d13(x)
x = self.flatten(x)
x = self.f14(x)
x = self.d14(x)
x = self.f15(x)
x = self.d15(x)
y = self.f16(x)
return y
model = VGG16()
model.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics = ['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/VGG10.ckpt"
if os.path.exists(checkpoint_save_path):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath = checkpoint_save_path,
save_weights_only = True,
save_best_only = True)
history = model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data=(x_test, y_test), validation_freq=1, callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape)+'\n')
file.write(str(v.numpy()) + '\n')
flie.close()
############################################### show ###############################################
# ��ʾѵ��������֤����acc��loss����
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
tegorical_accuracy: 0.7033 - val_loss: 0.8291 - val_sparse_categorical_accuracy: 0.7198
Model: ��vg_g16��
3.4 InceptionNet
ģ��ʵ�ִ���:p40_cifar10_inception26.py
�����:һ����ʹ�ò�ͬ�ߴ�ľ�����,������֪��(ͨ��paddingʵ������������һ��);ʹ��1 * 1������,�ı��������channel��(�����������)��
InceptionNet��GoogLeNet,������2015��,ּ��ͨ����������Ŀ������������������,��VGGNetͨ��������ѵ��ķ�ʽ(����)���,��һ����ͬ�ķ���(����)��
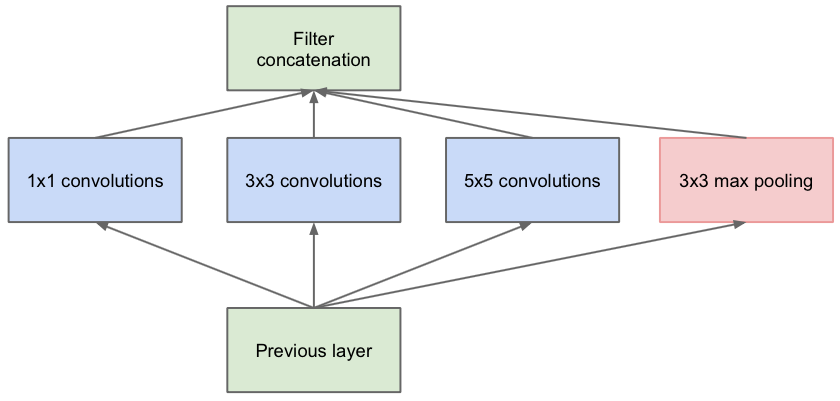
��Ȼ,InceptionNetģ�͵Ĺ�����VGGNet��֮ǰ���������������,�����Ǽ�����ѵ�,Ҫ����InceptionNet�Ľṹ,����Ҫ�������Ļ�����Ԫ,��ͼ5-27��ʾ��
���Կ���,InceptionNet�Ļ�����Ԫ��,���������DZȽ�ͳһ��C��B��A���ͽṹ,��������BN������,���������Relu�����,ͬʱ�������ػ�������
��Tensorflow���������Keras����InceptionNetģ��ʱ,���Խ�C��B��A�ṹ��װ��һ��,�����һ���µ�ConvBNRelu��,�Լ��ٴ�����,ͬʱ�������Ķ���

����ch��������ͼ��ͨ����,Ҳ�������˸���;kernelsz���������˳ߴ�;strides������������;padding�����Ƿ����ȫ����䡣
�������һ����,�Ϳ��Կ�ʼ����InceptionNet�Ļ�����Ԫ��,ͬ������class����ķ�ʽ,����һ���µ�InceptionBlk��,��5-28��ʾ��

����ch�Դ���ͨ����,strides������������,��ConvBNRelu����һ��;tf.concat�������ĸ����������һ��,x1��x2_2��x3_2��x4_2�ֱ����ͼ5-27�е��������,��Ͻṹͼ�ʹ�������������ߵĶ�Ӧ��ϵ��
���Կ���,InceptionNet��һ�������ص��Ǵ���ʹ����1 * 1�ľ�����,��ʵ��,��ԭʼ��InceptionNet�Ľṹ�Dz�����1 * 1������,��ͼ5-29��ʾ
��ͼ5-29���Ը�����ؿ���InceptionNet��������˼��,��ͨ����ͬ�ߴ������ͳػ���ĺ������(�������ػ���ijߴ���ͬ,ͨ���������)���ؿ��������,������������Գߴ����Ӧ�ԡ���������Ҳ����һ������,���еľ����˶�������һ��������ֱ������������,�ᵼ�²������ͼ���������(�����Ƕ���5 * 5�ľ�������˵)�����,InceptionNet��3 * 3��5 * 5�ľ�������ǰ�����ػ����������1 * 1�ľ�����,�γ���ͼ5-24�еĽṹ,�������Խ��������ĺ��,һ���̶��ϱ����������������⡣
��ô1 * 1�ľ�����������ν���������ȵ���?������5 * 5�ľ�������Ϊ��˵��������⡣����������һ������Ϊ100 * 100 * 128(H *W * C),ͨ��32 * 5 * 5(32����СΪ5 * 5�ľ�����)�ľ�����(����Ϊ1��ȫ�����)��,���Ϊ100 * 100 * 32,������IJ�����Ϊ32 * 5 * 5 * 128 = 102400;�����ͨ��32 * 1 * 1�ľ�����(���Ϊ100 * 100 * 32),��ͨ��32 * 5 * 5�ľ�����,�����Ϊ100 * 100 * 32,��������IJ�������Ϊ32 * 1 * 1 * 128 + 32 * 5 * 5 * 32 = 29696,��Ϊԭ��������30 %����,�����С�����˵Ľ�ά���á�
InceptionNet���������������������Ԫ���ɵ�,��ģ�ͽṹ��ͼ5-30��ʾ��
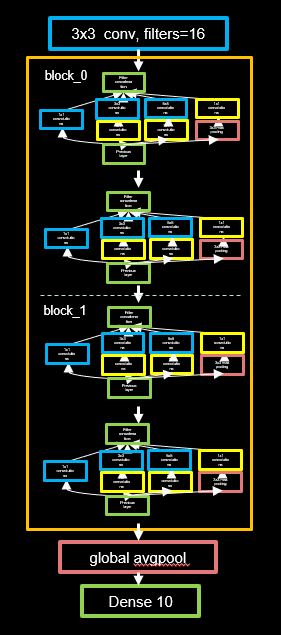
ͼ�г�ɫ���ڼ�ΪInceptionNet�Ļ�����Ԫ,����֮ǰ����õ�InceptionBlk��ѵ�����,ģ�͵�ʵ�ִ������¡�
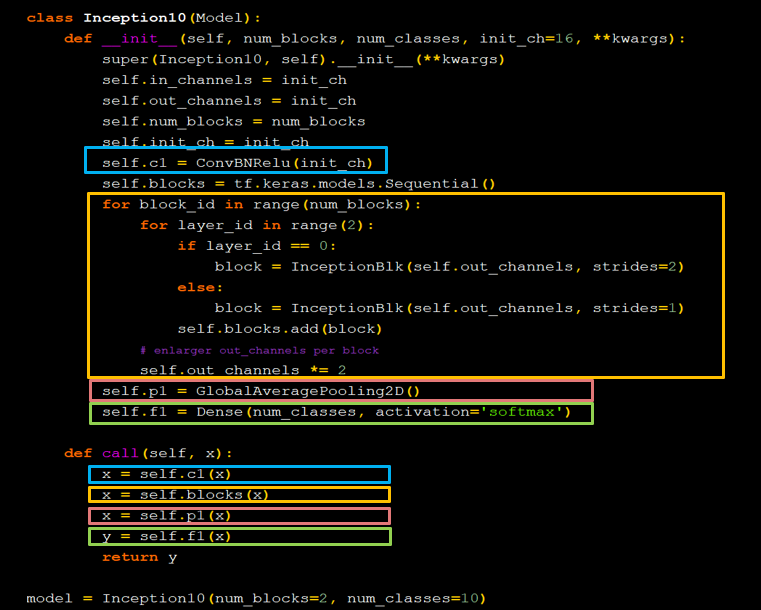
����num_layers����InceptionNet��Block��,ÿ��Block������������Ԫ����,ÿ����һ��Block,����ͼ�ߴ��Ϊ1/2,ͨ������Ϊ2��;num_classes����������,����cifar10���ݼ���˵��Ϊ10;init_ch������ʼͨ����,Ҳ��InceptionNet������Ԫ�ij�ʼ�����˸�����
InceptionNet���粻����VGGNetһ��������ȫ���Ӳ�(ȫ���Ӳ�IJ�����ռVGGNet�ܲ�������90 %),���Dz��á�ȫ��ƽ���ػ�+ȫ���Ӳ㡱�ķ�ʽ,������˴����IJ�����
�������һ��ȫ��ƽ���ػ�,��tf.keras����GlobalAveragePooling2D����ʵ��,�����ƽ���ػ�(������ͼ���Դ��ڵ���ʽ����,ȡ�����ڵ�ƽ��ֵΪ����ֵ),ȫ��ƽ���ػ������Դ��ڻ�������ʽȡ��ֵ,����ֱ���������ͼȡƽ��ֵ,��ÿ������ͼ���һ��ֵ��ͨ�����ַ�ʽ,ÿ������ͼ����������ֱ����ϵ����,�������ȫ���Ӳ�Ĺ���,���Ҳ����������ѵ������,��С�˹���ϵĿ���,����Ҫע�����,ʹ��ȫ��ƽ���ػ��ᵼ�������������ٶȱ�����
��������,InceptionNet��ȡ�˶�ߴ�����پۺϵķ�ʽ�ؿ�����ṹ,��ͨ��1 * 1�ľ�����������С������,ȡ���˱ȽϺõ�Ч��,��ͬ�굮����VGGNet���,�ṩ�˾��������繹������һ��˼·����InceptionNet��������,��������Ȳ�������ʱ,ѵ����ʮ������,����������(��һ�㱻ResNet�ܺõؽ����)��
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense, GlobalAveragePooling2D
from tensorflow.keras import Model
np.set_printoptions(threshold = np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super().__init__()
self.model = tf.keras.Sequential([
Conv2D(filters=ch, kernel_size=kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
#��training=Falseʱ,BNͨ������ѵ���������ֵ������ȥ������һ��,training=Trueʱ,ͨ����ǰbatch�ľ�ֵ������ȥ������һ��������ʱ training=FalseЧ����
x = self.model(x, training = False)
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super().__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1,padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis = 3)
return x
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super().__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.in_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
model.compile(optimizer = 'adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = './checkpoint/Inception10,ckpt'
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5,
validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# ��ʾѵ��������֤����acc��loss����
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
797 - val_loss: 0.9224 - val_sparse_categorical_accuracy: 0.6707
Model: "inception10"
______________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_bn_relu (ConvBNRelu) multiple 512
_________________________________________________________________
sequential_1 (Sequential) (None, 8, 8, 64) 84832
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 650
=================================================================
Total params: 85,994
Trainable params: 85,002
Non-trainable params: 992
____________________________