one-stage 与 tow-stage

本篇博客主要介绍经典检测方法中的one-stage(单阶段),在这里给自己埋个坑,整理完Yolo再去搞tow-stage。
| one-stage: | tow-stage |
|---|---|
| 速度非常快适合做实时检测任务 | 效果通常还是不错的 |
| 效果通常情况下不会太好 | 速度通常较慢(5FPS) |
评价指标
回顾准确率、精确率、召回率
1.准确率(Accuracy) ,顾名思义,就是所有的预测正确(正类负类)的占总的比重。
2.精确率(Precision),查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。
3.召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。
我觉得这里利用医生看病更好理解。医院来了一个人,医生判断其是否患病(患病为正类),若其患病被检查有病,即为TP(True Positives),患病被查无病,即为FN(False Negatives),未患病被检查有病,即为FP(False Positives),未患病被查无病,即为TN(True Negatives)。
可以看到在这例子中,首先定义了正类(患病),第一个字母是T则代表分类正确,反之分类错误;然后看P,在T中则是正类,在F中则实际为负类分成了正的。若为N,在T中则为负类,在F中则为正类。(类似负负得正)
精确率 (Precision):你诊断的病人中,有多少是真的病人(准确度是多高)。
召回率 (Recall):该类病人有多少被找出来了(召回了多少)。
4.IOU交并比

下图为例,综合衡量检测效果;单看精度和recall是不行的。
虽然准确率很高,但是查全率(召回率)很低,即露漏检的有很多。
Precision: TP / (TP + FP) 模型预测的所有目标中,预测正确的比例 (查准率)
Recall: TP / (TP + FN) 所有真实目标中,模型预测正确的目标比例 (查全率)
TP: True Positive, IoU>0.5的检测框数量(同一Ground Truth只计算一次)
FP: False Positive, IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
FN: False Negative, 没有检测到的GT的数量
5.mAP指标:(mean Average Precision) 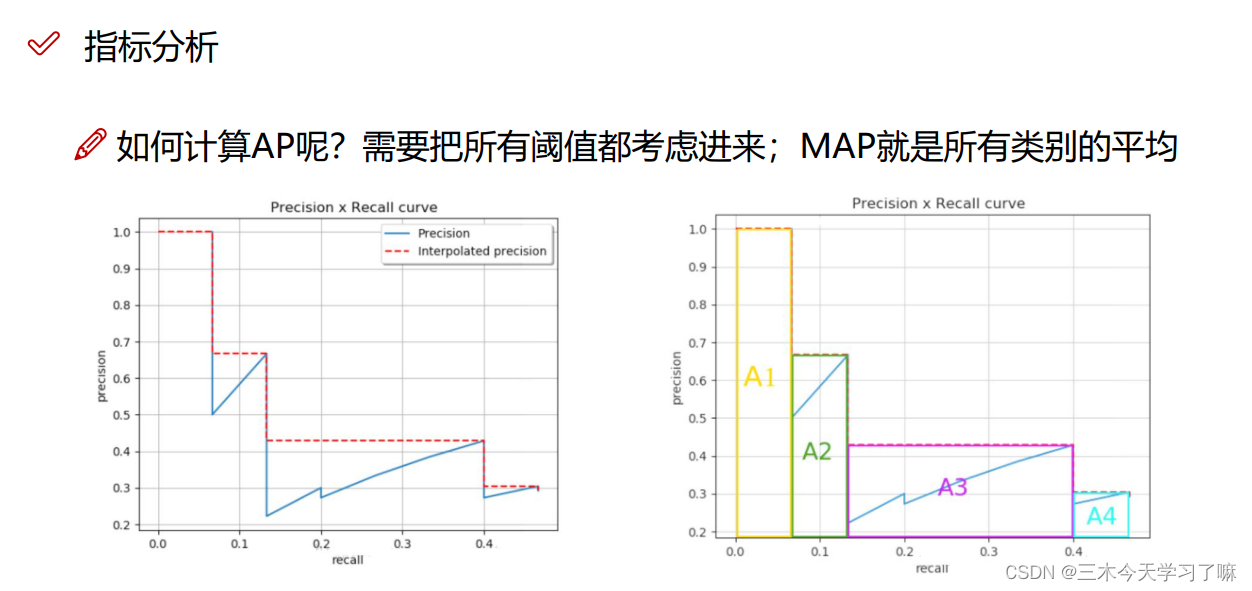
YOLO算法整体思路解读
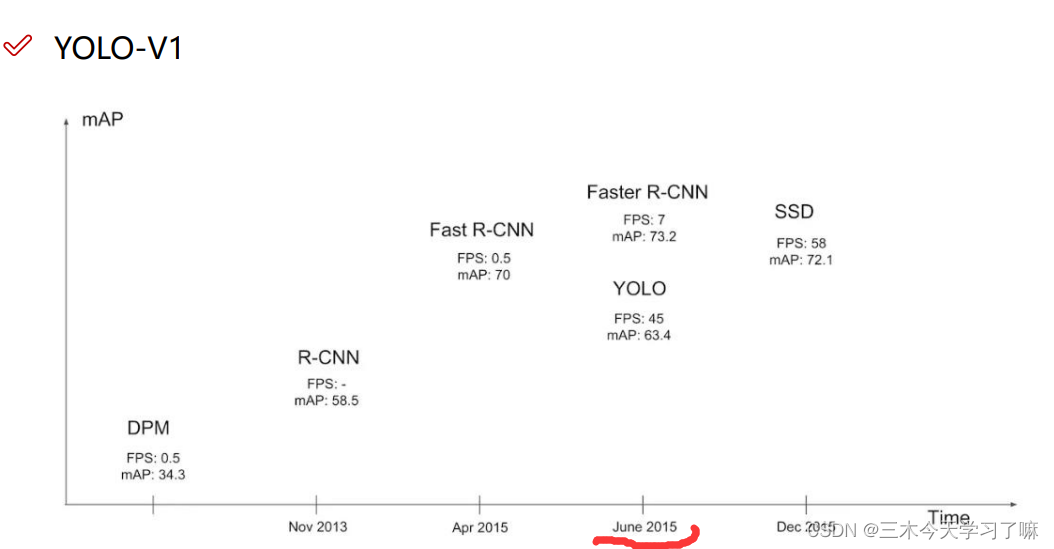
YOLO-V1

YOLO相较与Faster R-CNN相比有更高的FPS值,意味着可以更快的处理图片,可以应用于视频中的实时检测。
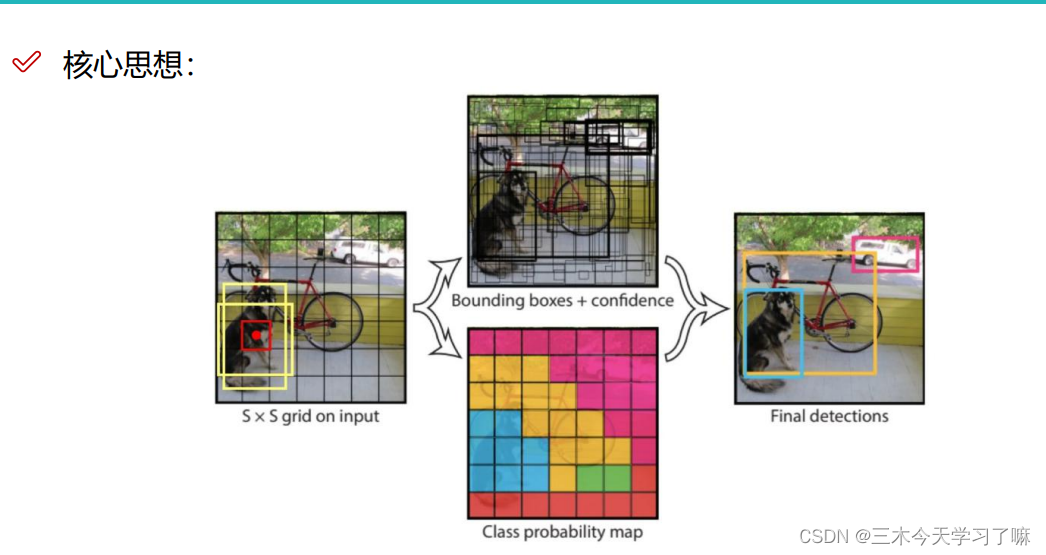
将图片划分为S×S的格子,每个格子生成两个候选框(x,y,w,h),基于与原图片中标注的实际框做IOU,进而做筛选和微调(即回归)。当然,不是每个框都做微调,在此之前,网络会基于置信度来选择实际有物体的格子。
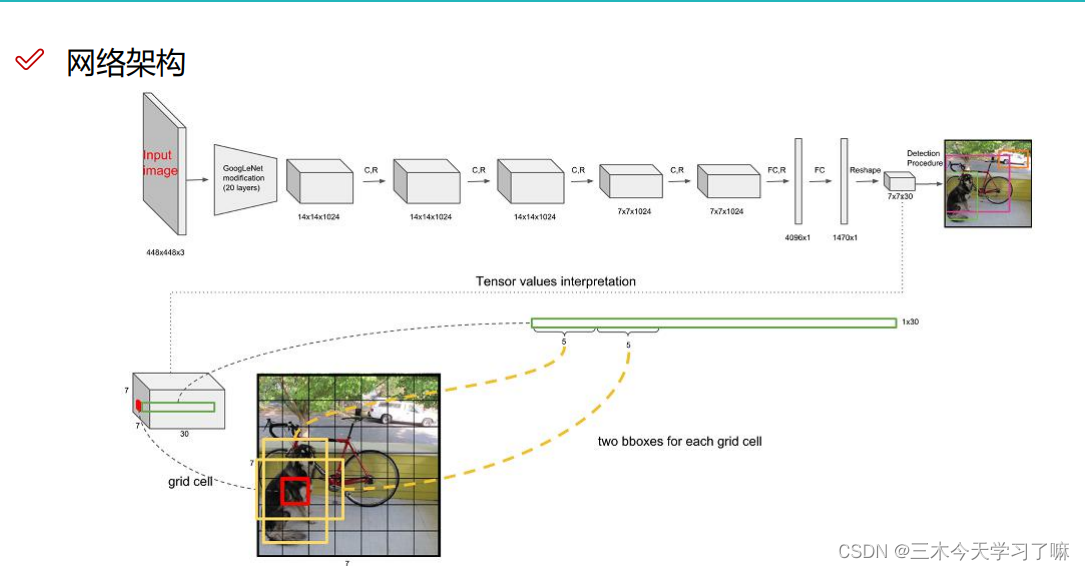
输入4484483的图片,经过一系列卷积池化提取特征后,输出771024的特征向量,经过2全连接层和reshape成7730的图片。7*7是图片中的格子数,30是每一个格子中占有的数据。
在7730的图片中,在每个格子上生成2个预选框B1(x1,y1,w1,h1,c1)和B2(x2,y2,w2,h2,c2),一共5*2个数据,同时会对目标进行预测分类。一共有20个分类目标。

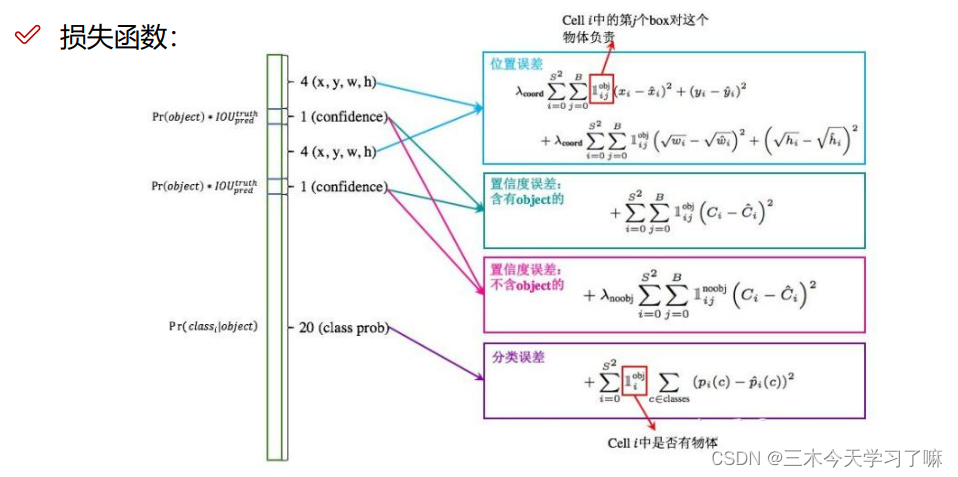
位置损失中,对宽和高加根号限制,即希望网络对小物体更敏感,对大物体减小敏感性。
在不含object的置信度误差中,加入了权重(例如:0.1)来告诉网络,背景的误差相较于物体的误差微不足道。
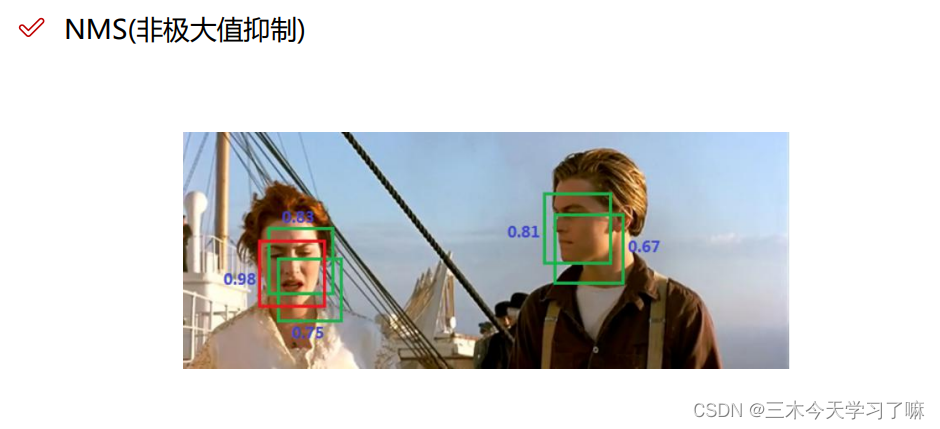
针对一个物体上有多个框,我们选择IOU最大的框,把其他框过滤除去。
YOLOV1中存在的问题:
- 无法处理重叠的物体的识别。
- 小物体检测不到。
- 多标签问题无法解决。

YOLO-V2
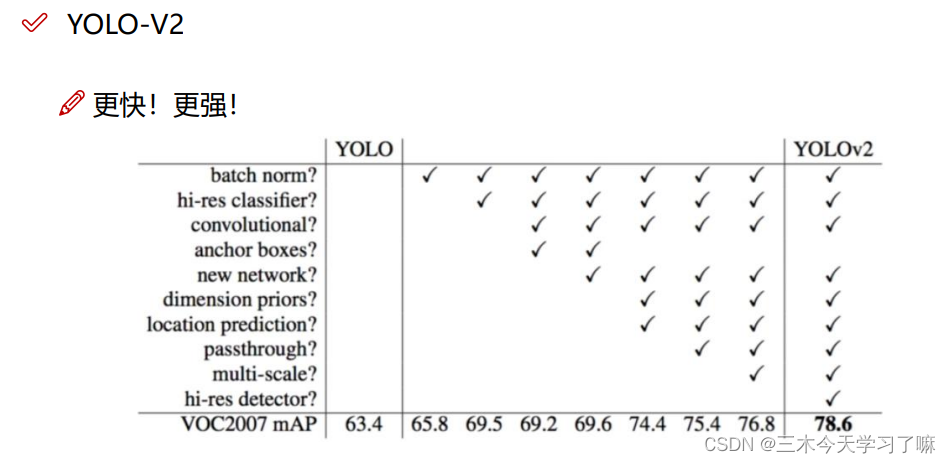

批归一化简称BN,是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散(特征分布较散)”的问题,从而使得训练深层网络模型更加容易和稳定。所以目前BN已经成为几乎所有卷积神经网络的标配技巧了。


全连接层缺点:训练参数大而且容易过拟合。
5次降采样,最终输出图片的尺寸是原图片宽和高除以32。并且希望最终的输出图片是一个奇数的尺寸,这也方便确定中心点,不会出现一个物体四个中心点的场面。
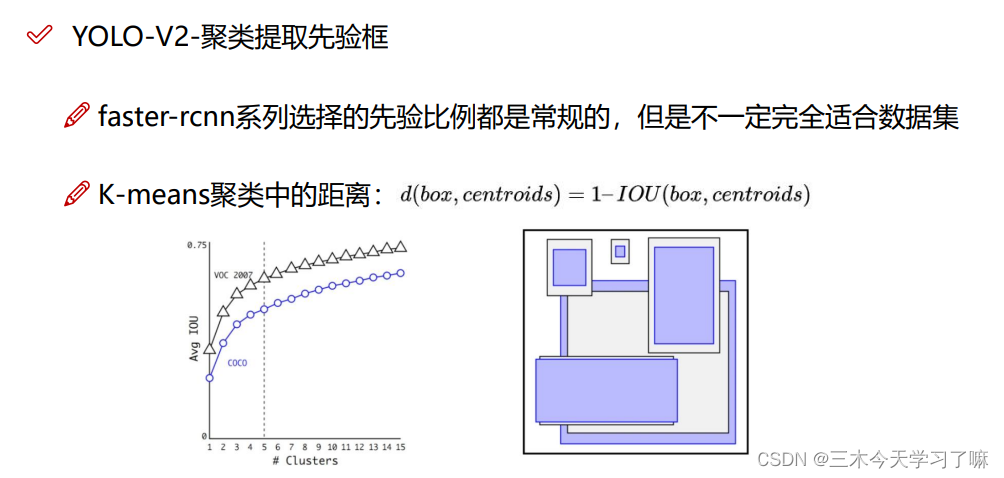
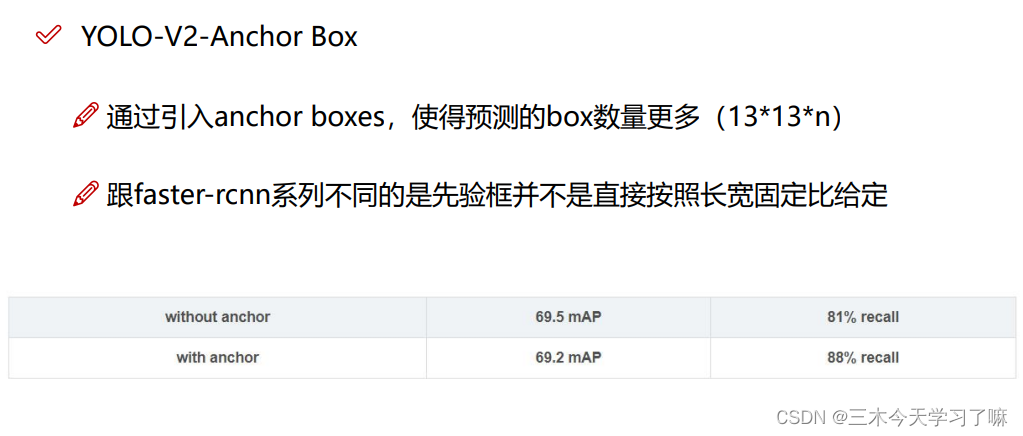
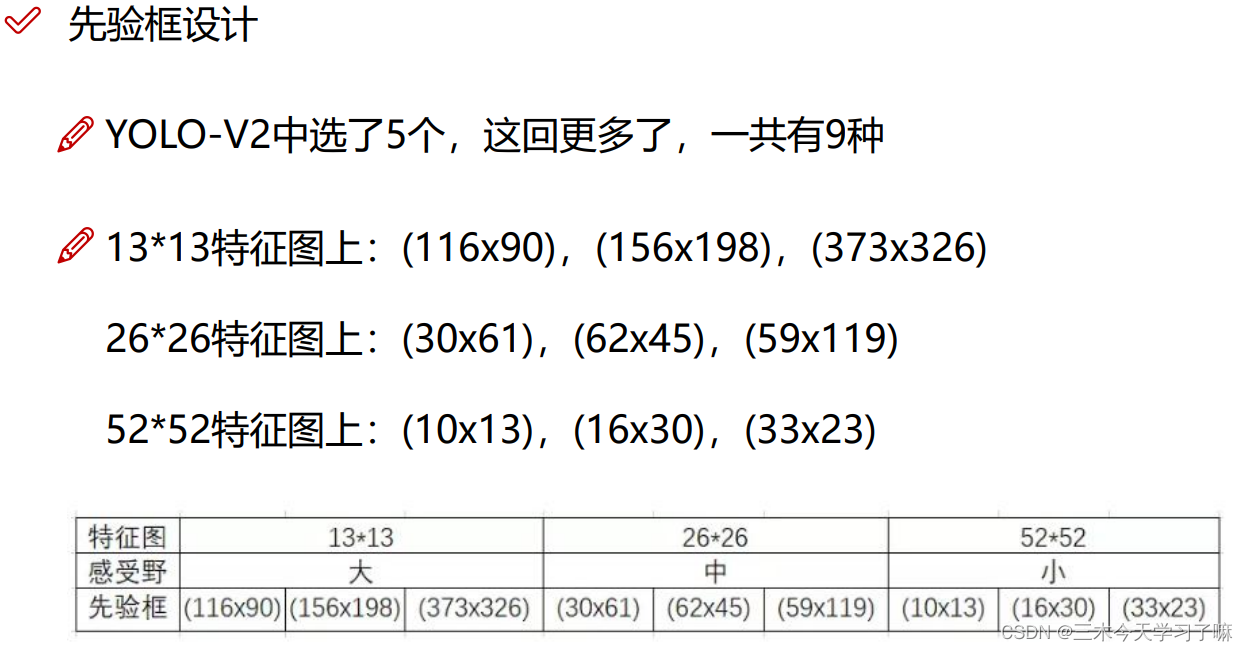
先验框Anchor Box,由聚类得到的符合物体实际大小的框。即每个点预先生成的框。

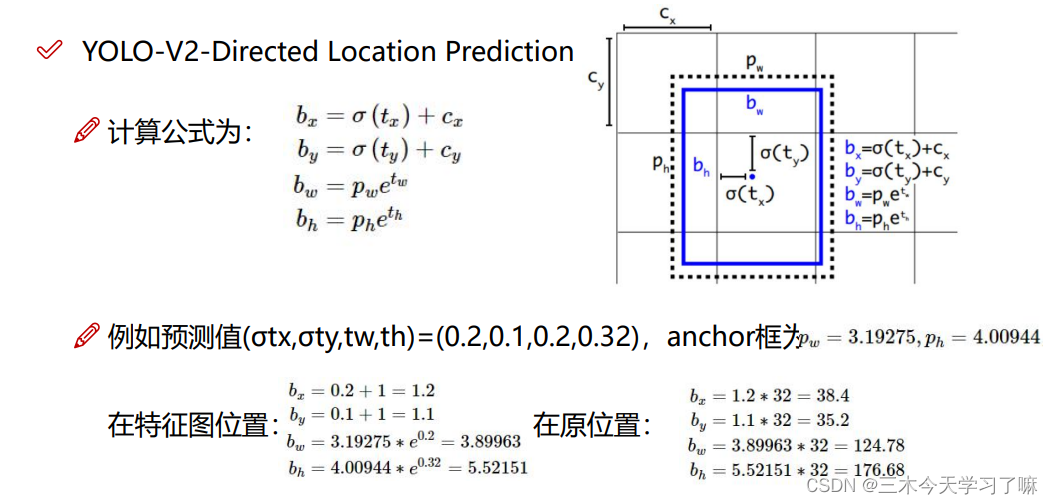
坐标的映射与还原。V2改进在于,bx与by的确定经过sigmoid函数映射在0-1之间,再加上基准值(cx,cy),即为坐标点。而宽和高则由先验框Anchor Box经过公式得到。
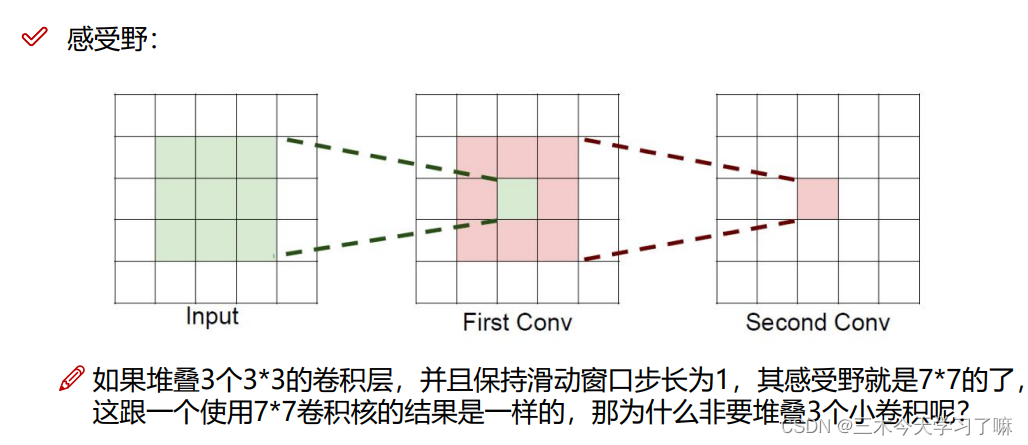
2个卷积是5*5。

并且每一个卷积核后面加一个BN,可以有效防止过拟合。
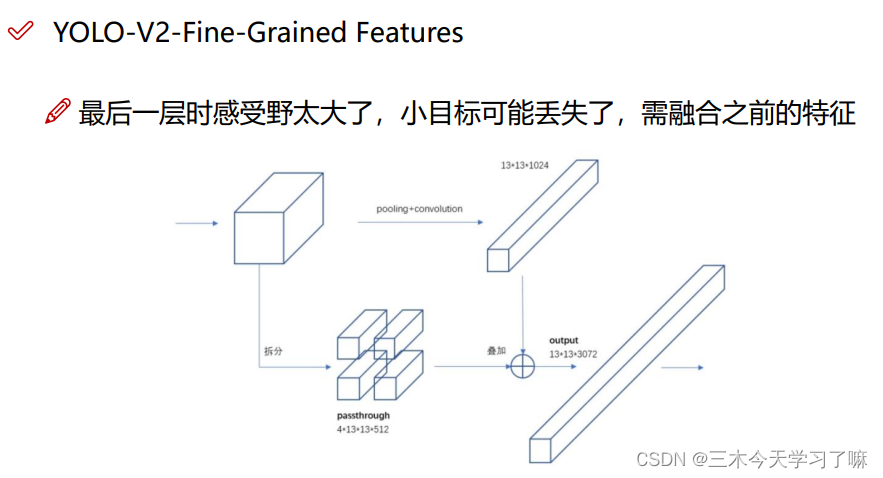
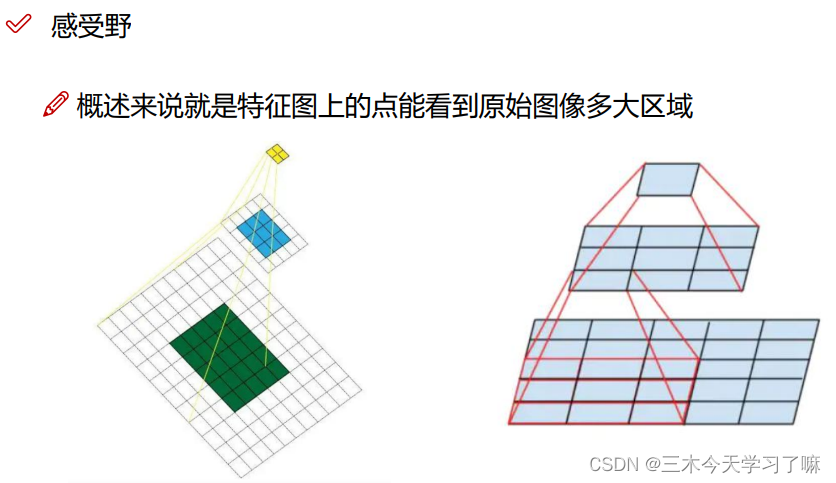
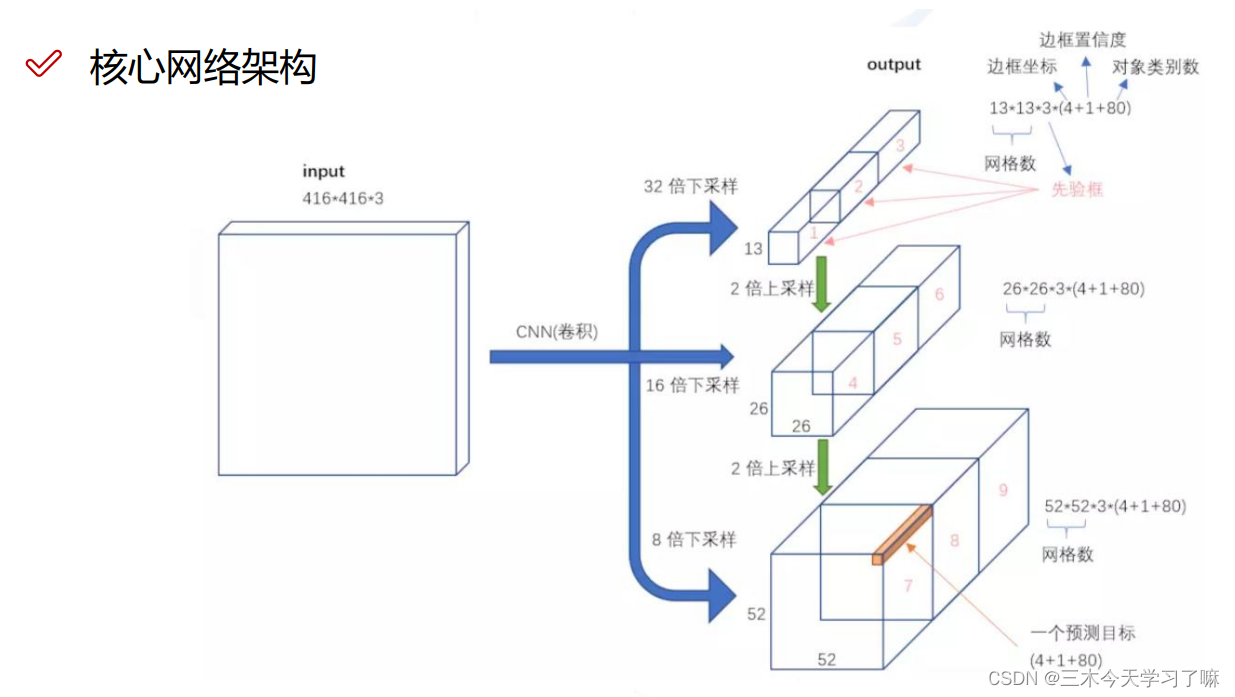
较大的感受野可能只关注了大物体而忽略了小物体。如果在卷积到最后一步之前进行拆分(感受野较小)再与最终结果融合,则经过特征融合的改进后,网络可以做到大小通吃。
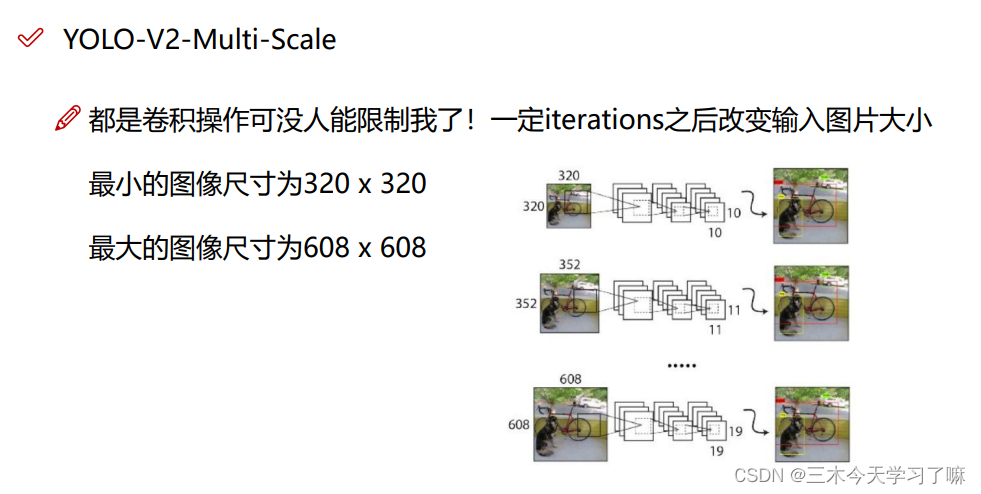
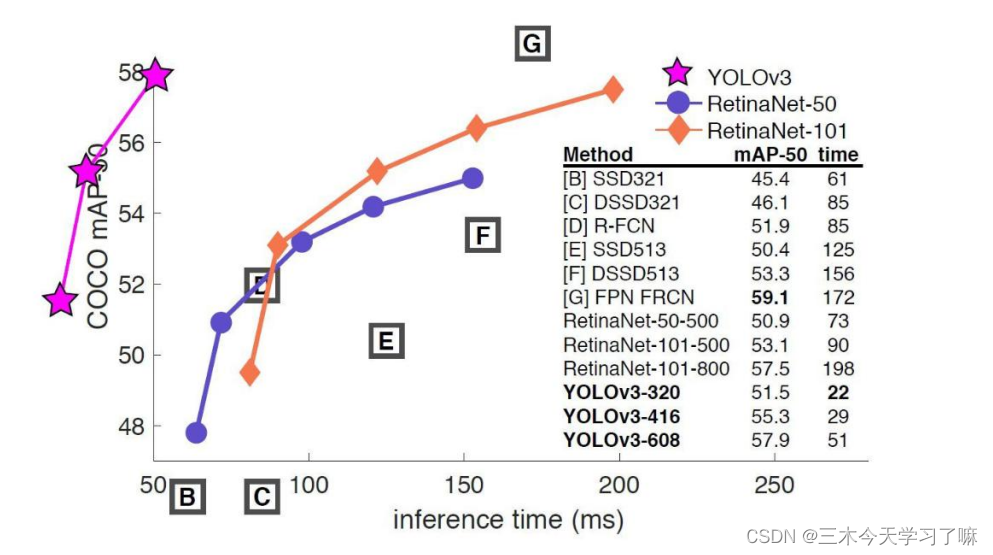
YOLO-V3

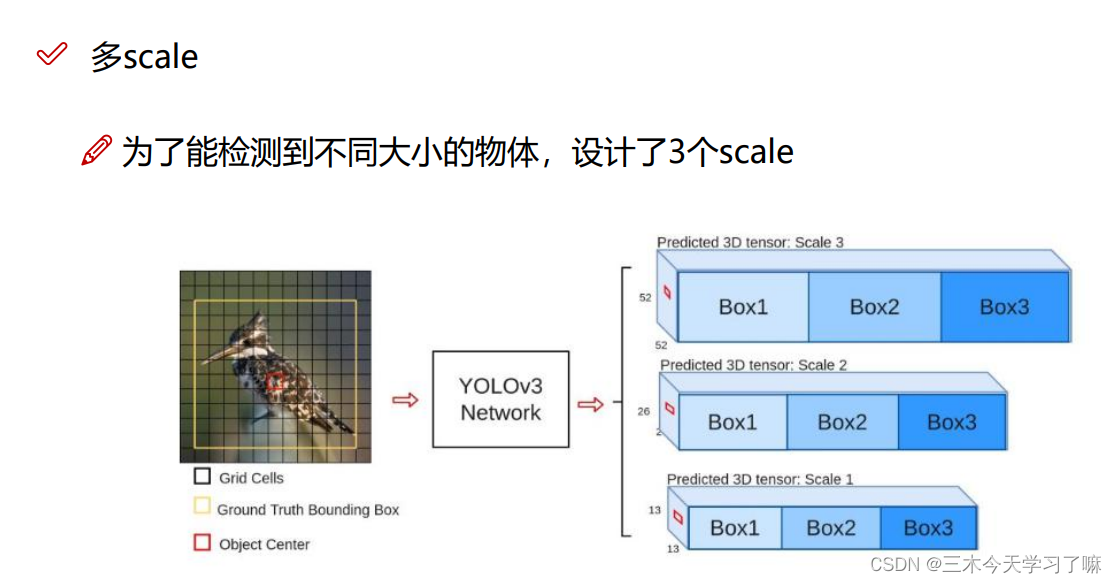
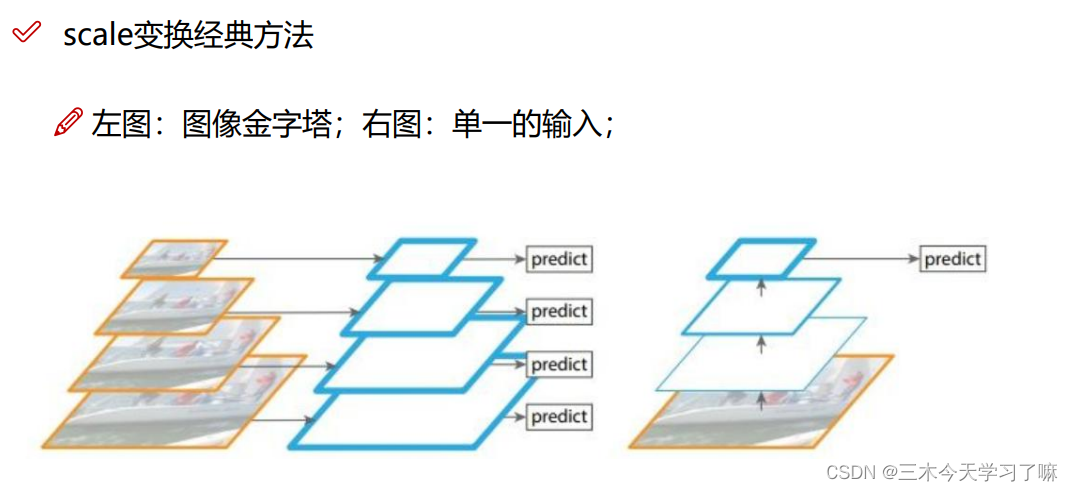
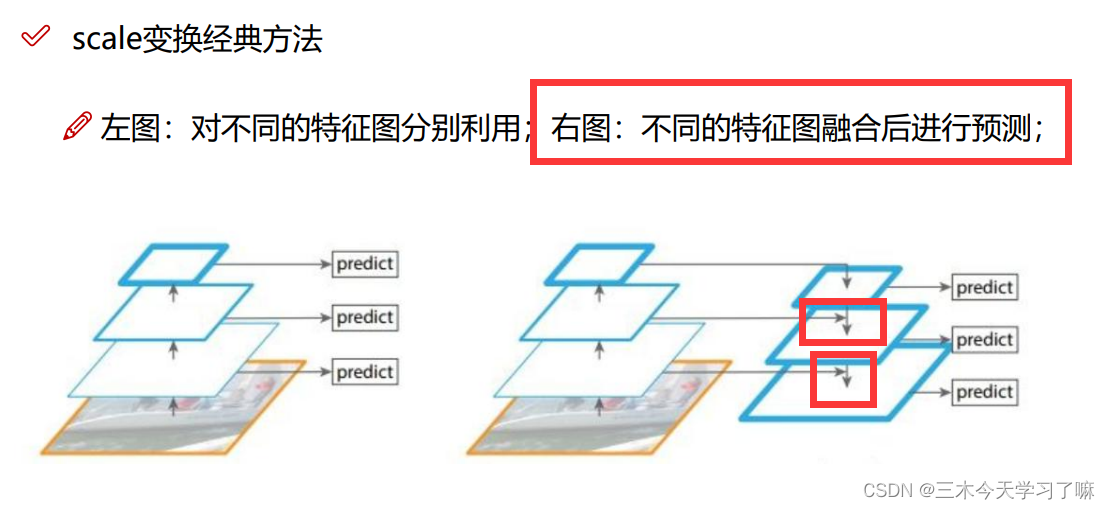
主要阐述一件事情,大感受野的先验框需要融合到小感受野的先验框中。
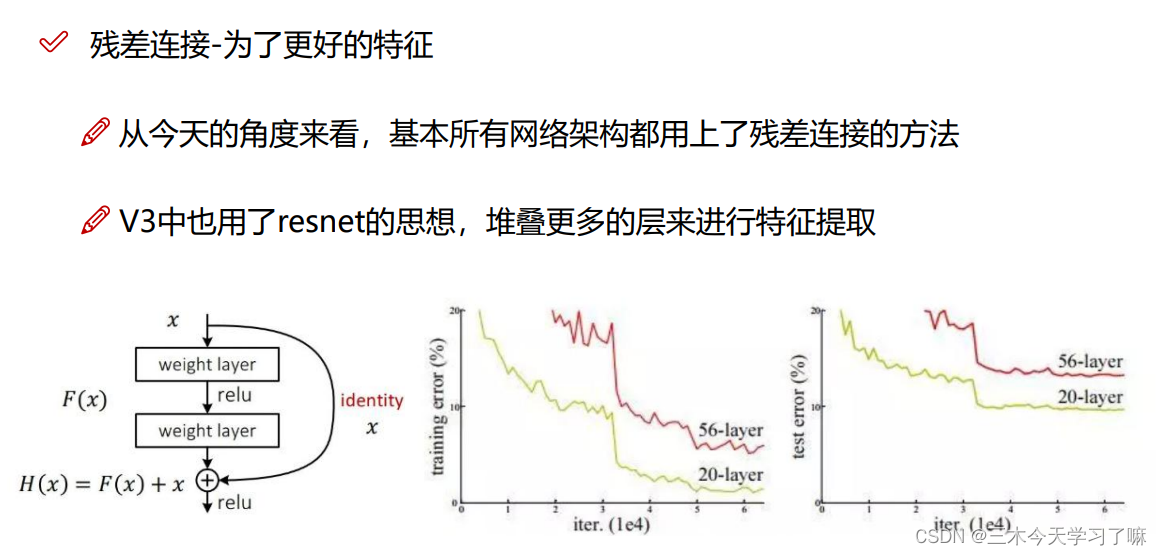
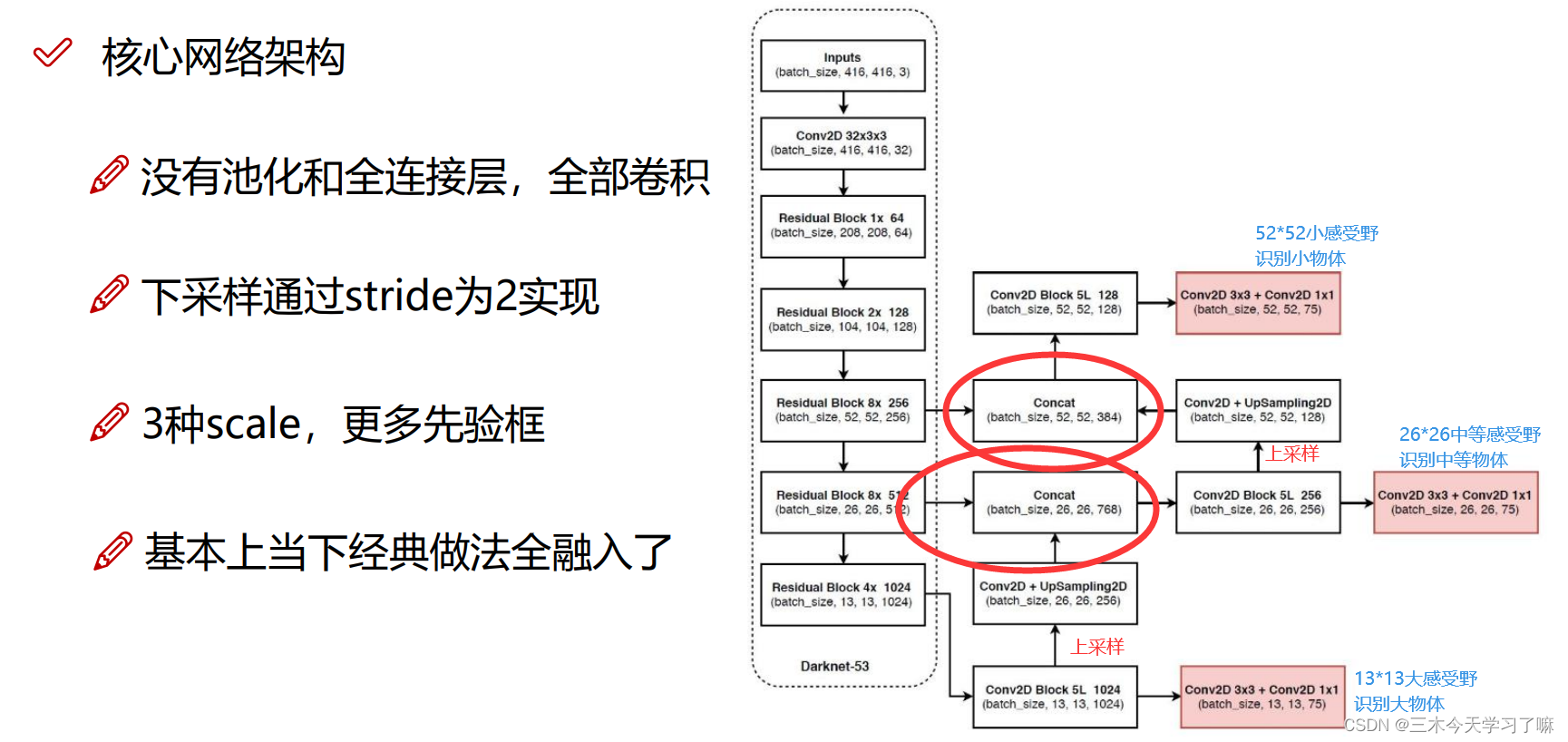

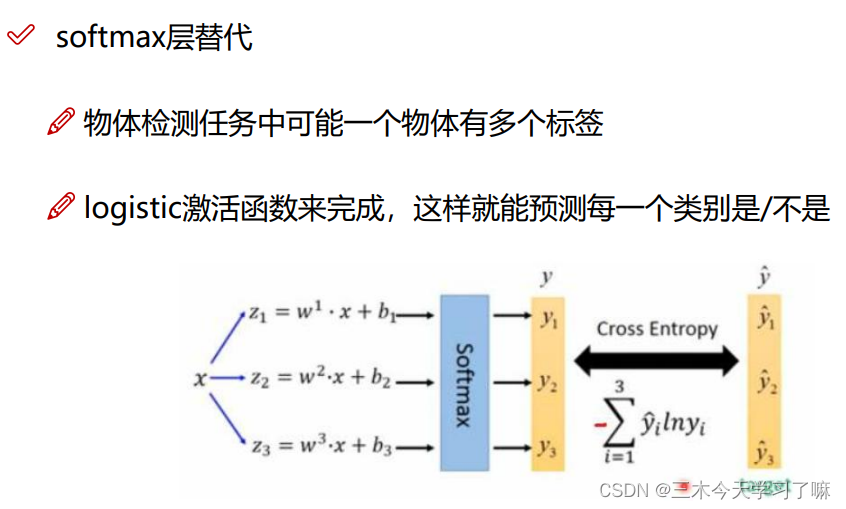
对每一个分类结果做二分类,判断是或不是。并在最终设置阈值,最终实现多标签分类。